
Multi-Person Device-Free Gesture Recognition Using mmWave Signals
2021-02-26 07:39JieWangZhouhuaRanQinghuaGaoXiaoruiMaMiaoPanKaipingXue
China Communications 2021年2期
Jie Wang,Zhouhua Ran,Qinghua Gao,Xiaorui Ma,Miao Pan,Kaiping Xue
1 School of Information Science and Technology,Dalian Maritime University,Dalian 116026,China
2 Faculty of Electronic Information and Electrical Engineering,Dalian University of Technology,Dalian 116023,China
3 Department of Electrical and Computer Engineering,University of Houston,Houston 77004,USA
4 Department of Information Security,University of Science and Technology of China,Hefei 230027,China
Abstract:Device-free gesture recognition is an emerging wireless sensing technique which could recognize gestures by analyzing its influence on surrounding wireless signals,it may empower wireless networks with the augmented sensing ability.Researchers have made great achievements for singleperson device-free gesture recognition.However,when multiple persons conduct gestures simultaneously,the received signals will be mixed together,and thus traditional methods would not work well anymore.Moreover,the anonymity of persons and the change in the surrounding environment would cause feature shift and mismatch,and thus the recognition accuracy would degrade remarkably.To address these problems,we explore and exploit the diversity of spatial information and propose a multidimensional analysis method to separate the gesture feature of each person using a focusing sensing strategy.Meanwhile,we also present a deep-learning based robust device free gesture recognition framework,which leverages an adversarial approach to extract robust gesture feature that is insensitive to the change of persons and environment.Furthermore,we also develop a 77GHz mmWave prototype system and evaluate the proposed methods extensively.Experimental results reveal that the proposed system can achieve average accuracies of 93% and 84% when 10 gestures are conducted in different environmentsby two and four persons simultaneously,respectively.
Keywords:device-free;gesture recognition;wireless sensing;multi-person;deep-learning
I.INTRODUCTION
Device-free wireless sensing (DFWS) [1–7]is an emerging technique which utilizes wireless signals to sense surrounding target information,such as location [8–12],gesture [13–19],vital sign [20–22],etc.,by analyzing the influence of the target on surrounding wireless signals.It may empower wireless networks with the augmented sensing ability,and would evolve traditional communication networks into intelligent networks.Among all these DFWS techniques,device-free gesture recognition is a promising technique which can be applied in a wide range of applications,such as virtual reality,human-computer interaction,and smart home,etc..Compared with traditional computer vision and wearable sensors based gesture recognition methods,device-free gesture recognition technique is robust to the working environment such as light or smog,and does not bring in privacy leakage,which make it an ideal technique to realize gesture recognition in future smart applications.
Researchers have conducted valuable exploration and made considerable achievements in the field of device-free gesture recognition.Many pioneering systems [13–19]have been successfully developed to recognize gestures by leveraging WiFi or mmWave[23,24]signals.These systems have achieved excellent performance when recognizing gestures conducted by a single person only.However,many smart applications,such as smart home,require recognizing multi-person gestures simultaneously.Therefore,how to realize multi-person device-free gesture recognition becomes an emerging task.
However,multi-person device-free gesture recognition is a challenging problem to solve.Firstly,when there are multiple persons conduct gestures simultaneously,the received signals from multiple persons will be mixed together,which makes it hard to separate the gesture feature of each person from the mixed signals,and thus traditional single-person device-free gesture recognition systems would not work well anymore.Moreover,since device-free gesture recognition systems are designed based on pattern recognition method,thus,the consistency of the gesture feature is essential for guaranteeing a good recognition accuracy.However,wireless gesture features usually carry substantial information that is specific to the person who conducts the gesture and the surrounding environment where the gesture is conducted.The anonymity of different persons in multi-person device-free gesture recognition exacerbates the feature shift and feature mismatch problem,and thus the recognition accuracy would degrade remarkably.
To solve the problem of separating the gesture feature of each person from the mixed signals,we explore and exploit the diversity of spatial information and propose a multi-dimensional analysis(MDA)strategy to separate the gesture feature of each person.As we know,if we observe multiple persons from one dimension only,i.e.,observe two persons with the same angle from the angle dimension,these persons maybe overlapped.However,if we can observe multiple persons from a multi-dimensional point of view,i.e.,from angle dimension,range dimension,doppler dimension,polarization dimension,etc.,we can differentiate multiple persons with a larger probability.Inspired by this idea and by the fact that commercial hardware could provide range,angle,and doppler dimensional information,in this paper,we try to analyze the mixed signals from multi-person by performing MDA.Specifically,we separate the reflection signals from each target by jointly leveraging the range and angel of arrival (AOA) dimensions which form a plane polar coordinate system,and utilize doppler information as features to characterize each gesture.With the MDA strategy,we reduce the complex multiperson gesture recognition problem to a relatively simple multiple single-person gesture recognition problem.
To mitigate the feature shift incurred by the anonymity of multi-person and the change of surrounding environment,we present a deep-learning based robust device free gesture recognition framework,which leverages an adversarial approach to extract robust gesture feature that is insensitive to the change of persons and environment.Essentially,we try to map the same gesture features from different persons or different surrounding environment to the same feature space.To realize this goal,we design a deep adversarial network which consists of two feature extractors,a classifier,and a domain discriminator.The feature extractors strive to generate features those could confuse the discriminator,while the discriminator attempts to discriminate which domain the features are generated from.With the constantly minimax game competing of the feature extractors and discriminator,eventually the deep network reaches a dynamic equilibrium,i.e.,the feature extractor could generate robust features those could not be discriminated which person or environment the features are from.With the deep-learning based robust device free gesture recognition framework,we could solve the feature shift problem,and thus make the developed multi-person device-free gesture recognition system achieve robust and good accuracy.
With the aforementioned two strategies,we design and implement a multi-person device-free gesture recognition mmWave prototype system using a 77GHz FMCW chipset,and evaluate the proposed methods extensively.The main contributions of the paper are summarized as follows.
1.To solve the mixed signal problem encountered by multi-person device-free gesture recognition,we explore and exploit the diversity of spatial information and propose a multi-dimensional analysis strategy to separate the gesture feature of each person from the mixed signals in a plane polar coordinate system by focusing sensing.
2.To mitigate the feature shift incurred by the anonymity of persons and the change of surrounding environment,we develop a deep-learning based robust device free gesture recognition framework,which could map features from different persons or surrounding environment to the same feature space through an adversarial approach,and thus extract robust features and guarantee a good recognition accuracy.
3.To evaluate the effectiveness of the proposed methods,we design a 77GHz FMCW based mmWave prototype system,and evaluate the proposed methods extensively.
The rest of this paper is organized as follows.Section II reviews the related work.Section III introduces the problem formulation and the key idea behind the proposed system.Section IV presents the detailed implementation of the multi-person device-free gesture recognition system.Section V validates the proposed system with extensive evaluations.Finally,we draw the conclusion in section VI.
II.RELATED WORK
The research of device-free wireless sensing[1–7]begin with the exploration on what will happen when a person shields a wireless link.Researchers discover that when the person stand at different locations,its shadowing effect on the wireless link will be different.Thus,it is feasible to realize device-free localization [8–12].Liuet al.[11]propose to characterize the shadowing effect using the distribution of the influenced RSS measurements,and achieve excellent location estimation performance.Wanget al.[10]further propose to leverage fine-grained subcarrier information to realize device-free localization,and achieve high localization accuracy with low human effort.Gaoet al.[8]transform the CSI measurements from multiple channels into a radio image,and estimate locations robustly by leveraging deep learning technique.Changet al.[9]design a systems which could localize new users using the knowledge learned from the trained users based on transfer learning technique,and improve the adaptability of the device-free localization system.These systems make valuable exploration on the shadowing effect of persons on wireless links,and lay solid foundation for other device-free wireless sensing techniques.
Inspired by the success of device-free localization,researchers explore to accomplish other sensing tasks,such as gesture recognition[13–18].Puet al.[13]design WiSee which utilizes an USRP to extract doppler profiles from wireless signals to recognize gestures.Heet al.[14]further design a WiG system which could achieve gesture recognition in a simplicity,low cost,and high practicability way.Moreover,Abdelnasseret al.[15]develop the WiGest system which leverages the changes in WiFi signal strength to sense hand gestures.With the popular of mmWave,researchers begin to utilize FMCW to sense gestures.Lienet al.[16]present Soli,a robust high-resolution gesture recognition system for human-computer interaction.Zhouet al.[17]leverage a 3-D convolutional neural network to extract discriminative wireless features and achieve good gesture recognition accuracy.These pioneer systems have made valuable contribution and effectively promoted the development of single-person device-free gesture recognition technique.However,many practical applications require realizing multi-person device-free gesture recognition.Penget al.[19]conduct valuable exploration on this interesting idea,and utilize the range difference between multiple persons to realize multi-person gesture recognition.This method could work well when there are only very few number of persons.However,when there are more number of persons,the range information maybe not sufficient for differentiating the persons anymore.Meanwhile,the aforementioned work does not consider the feature shift problem which must be solved for practical application.Following their pioneering exploration,this paper tries to provide a system solution for multi-person devicefree gesture recognition problem.
III.PROBLEM FORMULATION AND MOTIVATION
3.1 Problem Formulation
In this paper,we consider the task of recognizing gestures conducted by multiple persons simultaneously in a device-free manner by analyzing the mmWave signals.As shown in Figure1,each receiver could measure the raw data of a frame S,which can indicate the range and doppler information of the surrounding persons by performing 2D-FFT operation on S.With the consecutive frames measured by multiple receivers,our goal is to recognize the gestures conducted by multi-persons simultaneously.
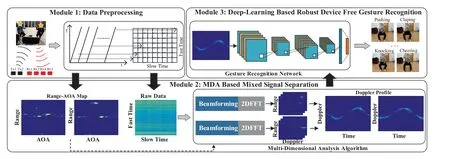
Figure1.System architecture of the proposed MGRS.
3.2 Motivation
Generally,different human gestures will incur different doppler information,thus,doppler information is ideal for realizing device-free gesture recognition[3].When there is only a single person performing gestures,it is easy and straightforward to extract the doppler information from the measurement S.However,when there are multiple persons performing gestures simultaneously,the reflection signals from multiple persons will be mixed together with a large probability.Thus,it becomes extremely hard to separate the doppler information incurred by each person.Therefore,traditional single-person device-free gesture recognition systems would not work well anymore.Moreover,since gesture recognition systems are designed based on pattern recognition method,the consistency of doppler features is vital for guaranteeing a good recognition accuracy.However,in multiperson scenarios,the anonymity of persons and the change in the surrounding environment would cause larger feature shift and feature mismatch than those of the single-person scenarios,and thus the recognition accuracy would degrade remarkably.
Motivated by the idea that mixed signals in a lower dimensional space will become separable in a higher dimensional space with a larger probability,we try to explore whether it is feasible to separate the reflection signal of each person from the mixed signals.Fortunately,state-of-the-art commercial FMCW chipset could provide range,AOA,and doppler dimensional information,which enables us to analyze the mixed signals using the multi-dimensional analysis method.Therefore,in this paper,we try to separate every person in a plane polar coordinate system by jointly leveraging the range and AOA dimensions,and thus get the doppler information of each person.With the multi-dimensional analysis based mixed signal separation operation,we could reduce the complex multiperson gesture recognition problem to a relatively simple multiple single-person gesture recognition problem,and thus make the multi-person gesture recognition problem possible and easy to solve.
Motivated by the successful application of deep adversarial learning networks in solving the feature shift and feature mismatch problem in computer vision,we try to exploit whether it is possible to utilize it to mitigate the feature shift and mismatch incurred by the change of persons and environment in the multiperson device-free gesture recognition system.Specifically,we develop a deep adversarial network which consists of two feature extractors,a classifier,and a domain discriminator.We train the network in an adversarial way to map the same gesture features from different persons or different surrounding environment to the same feature space,and thus extract robust gesture features and guarantee a good recognition accuracy.
IV.IMPLEMENTATION
4.1 System Architecture
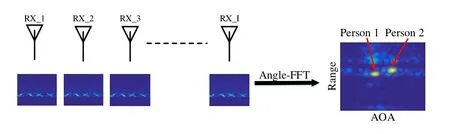
Figure2.Construction of the range-AOA map.
The architecture of the proposed multi-person devicefree gesture recognition system is illustrated in Figure1,which is consist of three functional modules,i.e.,data preprocessing module,multi-dimensional analysis based mixed signal separation module,and the deep-learning based robust device free gesture recognition module.The data preprocessing module collects the reflected signals from the persons by using a FMCW which has 2 transmitters and 4 receivers,eliminates surrounding static interference by performing the moving targets indication (MTI) algorithm [25],and acquires the raw data of consecutive frames by multiple receivers simultaneously.The multi-dimensional analysis based mixed signal separation module constructs range-AOA map by performing 2D-FFT along the fast time axis and across multiple receivers in turn,adopts constant false-alarm rate(CFAR)method[25,26]to filter the range-AOA map and locate each person in the map,and performs multidimensional analysis on the raw measurements to separate the signals from each target.The deep-learning based robust device free gesture recognition module leverages an adversarial approach to extract robust features insensitive to the change of persons and environment from the separated wireless signal,and realizes the gesture recognition task through the deep learning framework.
4.2 Signal Preprocessing
The data preprocessing module collects the reflected signals from the persons by using a FMCW which could form a virtual receiving array by leveraging multiple transmitters and receivers,and thus guarantee a good AOA resolution.For each receiver,we construct a matrix-form frame S,which can indicate the range and doppler information of the surrounding persons by performing 2D-FFT operation on S along the fast time axis and slow time axis,respectively.As we know,there are many static reflections,such as the reflections from wall and furniture.These reflection signals are harmful for the gesture recognition task.Therefore,we adopt the MTI denoising algorithm [25]to eliminate the surrounding static interference.We feed the consecutive denoised frames measured by multiple receivers to the subsequent modules.
4.3 Multi-dimensional Analysis Based Mixed Signal Separation
4.3.1 Range-AOA Map Construction and Analysis
To discover the distribution of the persons in the plane polar coordinate system,we construct a range-AOA map by jointly estimating the range and AOA information of the surrounding persons.We firstly get the range information by performing FFT on the fast time axis and achieve the range profile on every receiver,which is termed as the Range FFT operation defined by
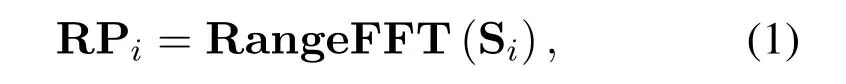
where Siand RPiindicate the acquired matrix-form frame and the range profile of theith receiver,respectively.With the range profile of every receiver,we further conduct Angle FFT operation,i.e.,utilize the range profile of each receiver to form a new matrix and conduct FFT along the receiver axis for each range bin,as shown in Figure2 to construct the range-AOA map RAM by
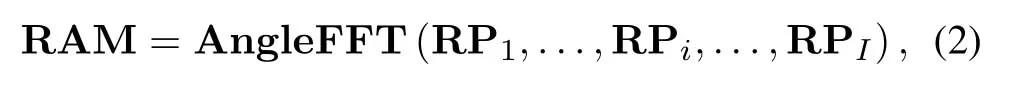
whereIdenotes the total number of receivers.
Generally,in addition to the useful reflections from the persons,there still exists background clutter in the constructed range-AOA map,we leverage the classical CFAR [26,27]algorithm to eliminate the clutter and search the range-AOA map to determine the range and AOA of each person by finding out the extreme values.We record the rangerjand AOAθjfor thejth person and get the total number of personsJ.As long as the coordinate difference between any two persons is larger than the resolution of the corresponding axis,we could separate the persons in the plane polar coordinate system.With the range and AOA information of the persons,we perform multi-dimensional analysis on both the range dimension and the AOA dimension,so as to observe the reflection signals from only a specific scope of ranges and AOAs which tightly surround the coordinate of the person.This operation is similar to the spotlight effect in the plays,we leverage multidimensional analysis method to focus on the reflection signals from one person only,so as to suppress the interference from all other persons and realize focusing sensing,and thus make it feasible to separate the mixed signals.
4.3.2 Multi-dimensional analysis
With the range and AOA of each person estimated in the previous subsection,we will leverage the multidimensional analysis method as illustrated in Figure3 to realize focusing sensing and to extract the reflection signal from each person.For thejth person with a range ofrjand AOA ofθj,we firstly perform beamforming on the raw frame Siof each receiver as follows
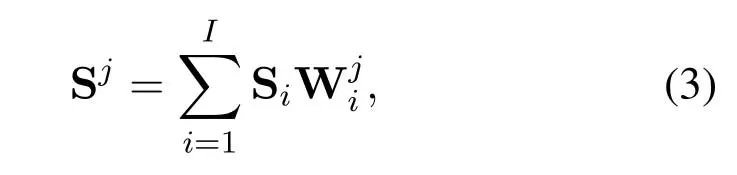
where Sjrepresents the filtered signal for thejth person,anddenotes the beamforming weights of theith receiver for thejth person defined by[28]
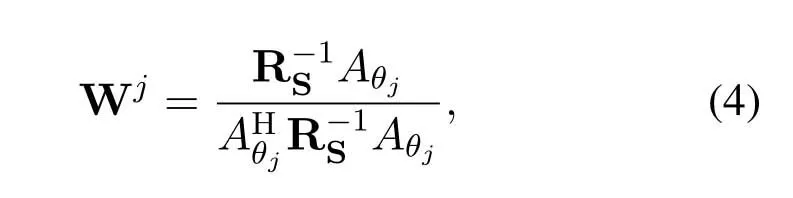
where RSdenotes the covariance of the receiver output signals,andAθjindicates the steering vector in the AOA ofθj.
With the beamforming operation,only the reflection signals with an arrival angle close toθjare reserved,while the reflection signals from all other angles are suppressed.Then,we perform 2D-FFT along the fast time axis and slow time axis of Sjin turn,and achieve the range doppler profile of thejth person RDjas follows
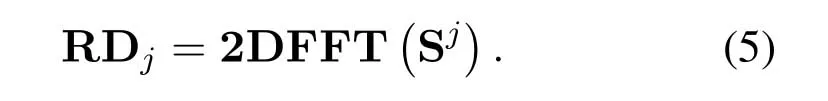
Since we have the range informationrjof thejth person,we further utilize a threshold integration technique to build the doppler profile vector DPjfor thejth person as follows
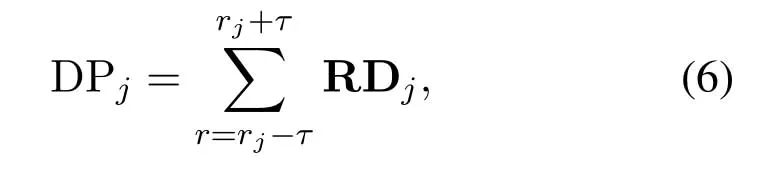
whereτindicates the integration threshold.

?
The doppler profile vector DPjcontains only the reflection signals focusing on thejth person at a time instant,with consecutive doppler profile vectors within a period of time,we could build the matrix form doppler profile DPjfor thejth person.The doppler profile DPjcharacterizes the moving pattern of the gestures conducted by thejth person,thus,it is ideal to leverage it to realize the gesture recognition task.As shown in Figure3,with the multi-dimensional analysis based focusing sensing method,we could get the high quality doppler profiles for each person.Therefore,the complex multi-person gesture recognition problem is reduced to a relatively simple multiple single-person gesture recognition problem.For the sake of clarity,we summarize the proposed method in Algorithm 1.
4.4 Deep-learning Based Robust Device Free Gesture Recognition
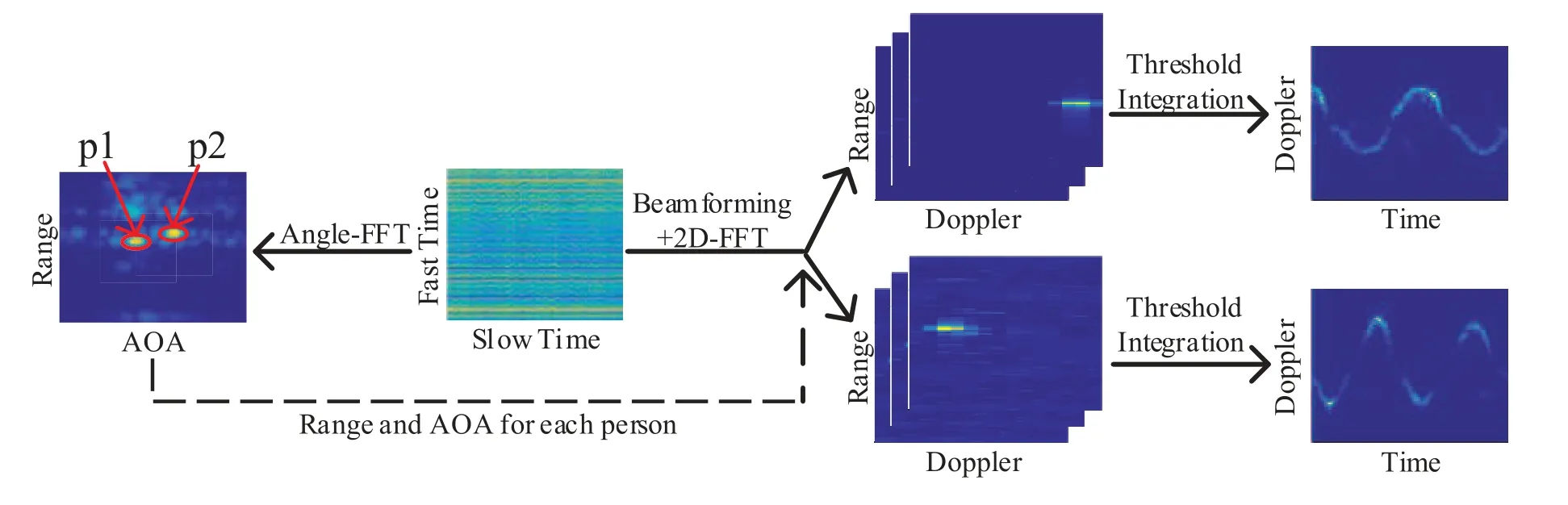
Figure3.Multi-dimensional analysis based focusing sensing method.
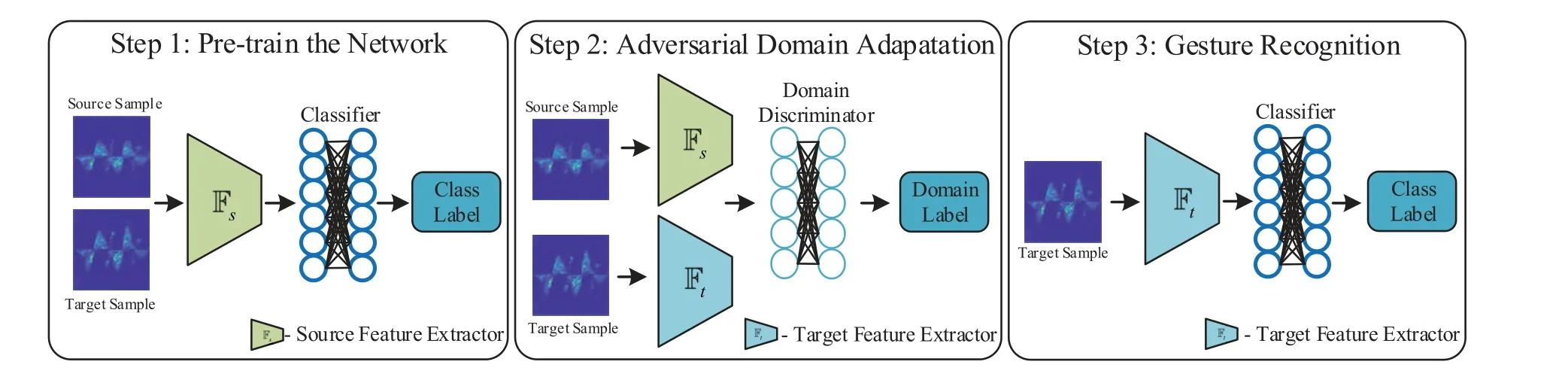
Figure4.Working principle of the developed deep adversarial network.Step 1:Source feature extractor Fs and classifier C are trained with the labeled source samples xs and unlabeled target samples xt.Step 2:Target feature extractor Ft and domain discriminator D are trained through an adversarial approach.Step 3:Recognize the label of the target samples using target feature extractor Ft and classifier C.
Inspired by the successful application of deep adversarial network in solving domain shift problem in computer vision,in this paper,we try to design a deep adversarial network to mitigate the feature shift incurred by the anonymity of persons and the change of surrounding environment.Essentially,we try to map the features of the doppler profiles from different persons or surrounding environment to the same feature space through an adversarial approach,and thus extract robust features and guarantee a good recognition accuracy.
The input of the deep network is the doppler profile DP for a gesture performed by a person,the task of the deep network is to recognize the gesture type.We define the doppler profile as the samplex,and the corresponding gesture type as the labely.We have collected some labeled samples from some persons to build the source sample set (xs,ys),with some unlabeled target samplesxtfrom a new person or a new environment,our goal is to estimate the labelytforxt,so as to recognize the gesture type of the person.
The working principle of the developed deep adversarial network is shown in Figure4,which is made up of a source feature extractor Fs,a target feature extractor Ft,a domain discriminator D,and a classifier C.Fsand Ftare convolutional neural networks with the same network structure,C and D are fully connected networks.Fs,Ft,and D form an adversarial architecture.Fsand Ftstrive to generate features those could confuse the discriminator D,while D attempts to discriminate which domain the features are generated from.With the constantly minimax game competing of the feature extractors and discriminator,eventually the adversarial network reaches a dynamic equilibrium,i.e.,the feature extractor could generate robust features insensitive to the change of persons and environment.The working procedure of the developed deep adversarial network is mainly consisted of three steps.We firstly pre-train the source feature extractor Fsand the classifier C using the labeled source sample set(xs,ys),which could guarantee a good recognition performance for the source samples.Then,we train the target feature extractor Ftand the domain discriminator D in an adversarial way while keeping Fsremain unchanged,which could make Ftand Fshave the same feature space.Finally,with the trained target feature extractor Ftand classifier C,we could recognize gesture performed in the target domain.The detailed working principle is as follows.
4.4.1 Pre-train the Network
We try to train the source feature extractor Fsand the classifier C by making full use of not only the labeled source samples (xs,ys),but also the unlabeled target samplesxt.For the labeled source samples,we try to minimize the loss functionLsdefined by
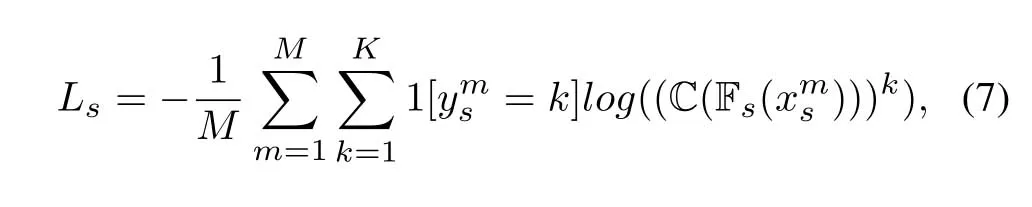
whereMindicates the total number of labeled source domain samples,Kdenotes the total type of gestures,ymsrepresents the true label of the samplexms,1[yms=k]is an indicator function which returns 1 if the equation is true and 0 otherwise,and (C(Fs(xms)))kdenotes thekth element of the network predicted label vector.
Lsinsures that the network could recognize gestures correctly in the source domain.Meanwhile,for the unlabeled target samplesxt,we leverage the trained Fsand C to predict their pseudo labels.Then,we try to minimize the distribution difference between the features of the two domains for the same gesture as follows
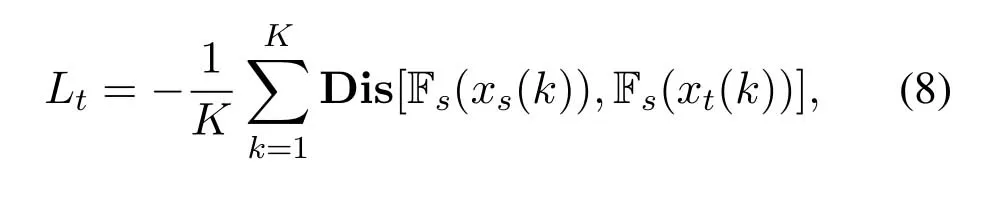
where Dis[a,b]returns the mean square distance betweenaandb,andxs(k)andxt(k)represent samples belonging tokth type of gesture from the source domain and target domain,respectively.By minimizingLt,the feature space of the target domain and source domain move close to each other.
4.4.2 Adversarial Domain Adaptation
We realize domain adaptation by training the target feature extractor Ftand the domain discriminator D in an adversarial way while keeping Fsremain unchanged,which could make the features extracted by Ftand Fsbelong to the same feature space.In the adversarial procedure,the feature extractors and discriminator compete with each other.The domain discriminator D tries to distinguish which domain the sample is from by minimizing the loss function as follows
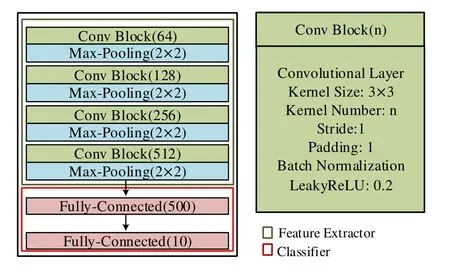
Figure5.Network architecture of the gesture recognition system.
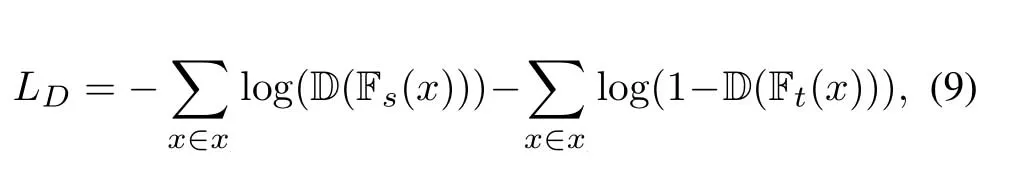
where the domain discriminator D() outputs 1 if it identifies that the sample is from the source domain and 0 otherwise.The target feature extractor Ftstrives to generate features those could confuse the discriminator by minimizing the following loss function
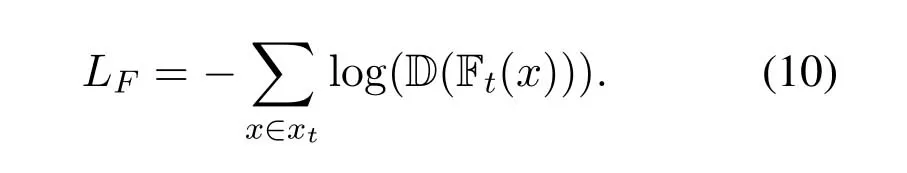
With the constantly competing of the target feature extractor and discriminator,eventually the deep adversarial network reaches a dynamic equilibrium,i.e.,the feature extractor could generate robust features those could not be discriminated which person or environment the features are from.The training process of the developed deep network is summarized in Algorithm 2.It should be noted that the parameters of the target feature extractorFtare initialized with the source feature extractorFs,and the parameters ofFsare fixed in the adversarial procedure.
4.4.3 Gesture Recognition
With the trained target feature extractor Ftand classifier C,in the online gesture recognition phase,we could recognize the gestures performed by a new person or in a new environment.After getting the doppler profile DP for a gesture performed by a person,we feed it to the feature extractor Ftto extract robust feature,then,we leverage the classifier C to recognize the gesture type.The network architecture of the online gesture recognition system is shown in Figure5,where Ftis mainly composed of some convolution blocks and pooling layers,and C is a two layer fully connected network.

?
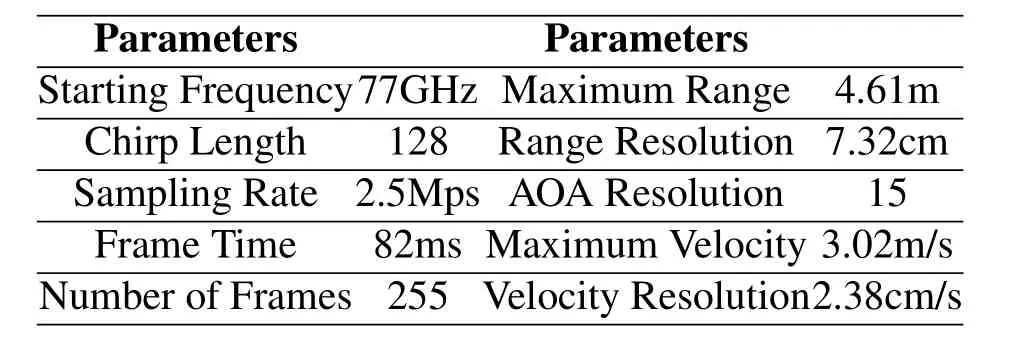
Table1.Parameter setting of FMCW hardware.
V.EXPERIMENTAL EVALUATIONS
5.1 Experiment Setup
We design an AWR1443 single-chip sensor based mmWave system to evaluate the proposed methods in different scenarios as shown in Figure6.We evaluate the developed system in 3 indoor scenarios and 3 outdoor scenarios termed as s1 to s6,respectively.In the experiments,we conduct 10 types of gestures as shown in Figure7,i.e.,push,double push,knock,sliding left to right,drawing X,clap,good,cheer,spoof,and menace,which are abbreviated as P,D-P,K,RL,X,C,G,CH,S,and M,respectively.The system works on 77GHz with a bandwidth of 2.05GHz.It has 2 transmitters and 4 receivers which could formulate an 8 elements virtual array in a TDM-MIMO mode to provide an AOA resolution of 15 degrees.The range resolution of the system is 7.32cm.We leverage the sensitive phase information to realize gesture recognition.The detailed parameter setting of the hardware is shown in Table1.
With the data generated by the mmWave hardware,we construct the doppler profile DP with a size of 96×96,and feed it to the deep network to realize gesture recognition.The deep network is implemented using PyTorch and runs on Intel i5-8300H CPU with GTX 2070 Ti GPU and 20GB RAM.The network is trained for 500 epochs with a mini-batch size of 8 using Adam training algorithm with a learning rate initialized to 0.001.Meanwhile,batch normalization and Leakly-ReLU are employed for stable training.We take the percentage of correct recognition as the accuracy metric to evaluate the algorithms.
5.2 Performance Evaluation
In this section,we firstly evaluate the effectiveness of the proposed MDA scheme and deep adversarial network in detail based on the data collected in s1 to s4.Then,we test the overall performance of the proposed system in the 4 persons s5 and s6 scenarios.
5.2.1 MDA Performance Evaluation
To evaluate the effectiveness of the proposed MDA scheme,we test the gesture recognition system in s1 and s2 as shown in Figure6(b) and Figure6(c),and compare the performance when using or not using MDA scheme to deal with the mixed signals.Two persons conduct gestures simultaneously with the same AOA but different range in s1,and with the same range but different AOA in s2.We leverage traditional CNN based deep network to realize gesture recognition.The recognition accuracies of each type of gesture under different conditions are summarized in Table2,with the average recognition accuracies shown in Figure8.From the results,we can see that when not using the MDA scheme,the recognition accuracies are generally very low,this is due to the fact that the reflection signals are mixed and thus the doppler profiles could not characterize the gestures anymore.In s1,the two persons have the same AOA,the person p2 is partially sheltered by the person p1,thus p1 has stronger reflection signals than p2 and the mixed signals are mainly determined by p1.Therefore,p1 achieves better accuracy than p2 in s1.With the proposed MDA scheme,we can see that the average accuracies for p1 and p2 are 86.19% and 81.91%,respectively.These results confirm the effectiveness of the proposed MDA scheme.Similar phenomenon can be found in the results of s2.In s2,the two persons have the same range,thus their reflection signals have nearly the same signal strength and the mixed signals are not similar to any of the two reflection signals by p1 and p2 anymore.Therefore,the accuracies by p1 and p2 without MDA scheme are very low.With the signals separation operation by the MDA method,the accuracies for p1 and p2 are 87.62% and 86.67%,respectively.It should be mentioned that we use only the range and AOA dimensions to perform MDA analysis in this paper,thus,we test only the scenarios that persons with the same range or same AOA.From these results,we can conclude that the proposed MDA scheme could separate the mixed signals from multiple persons effectively.Therefore,the proposed MDA scheme could turn a complex multi-person gesture recognition problem into a relatively simple multiple single-person gesture recognition problem.

Figure6.Experiment scenarios.(a) AWR1443 mmWave Testbed.(b) indoor 2 persons scenario s1.(c) indoor 2 persons scenario s2.(d) outdoor 2 persons scenario s3.(e) outdoor 2 persons scenario s4.(f) indoor 4 persons scenario s5.(g)outdoor 4 persons scenario s6.

Figure7.Conducted gestures.(a)P.(b)D-P.(c)K.(d)R-L.(e)X.(f)C.(g)G.(h)CH.(i)S.(j)M.
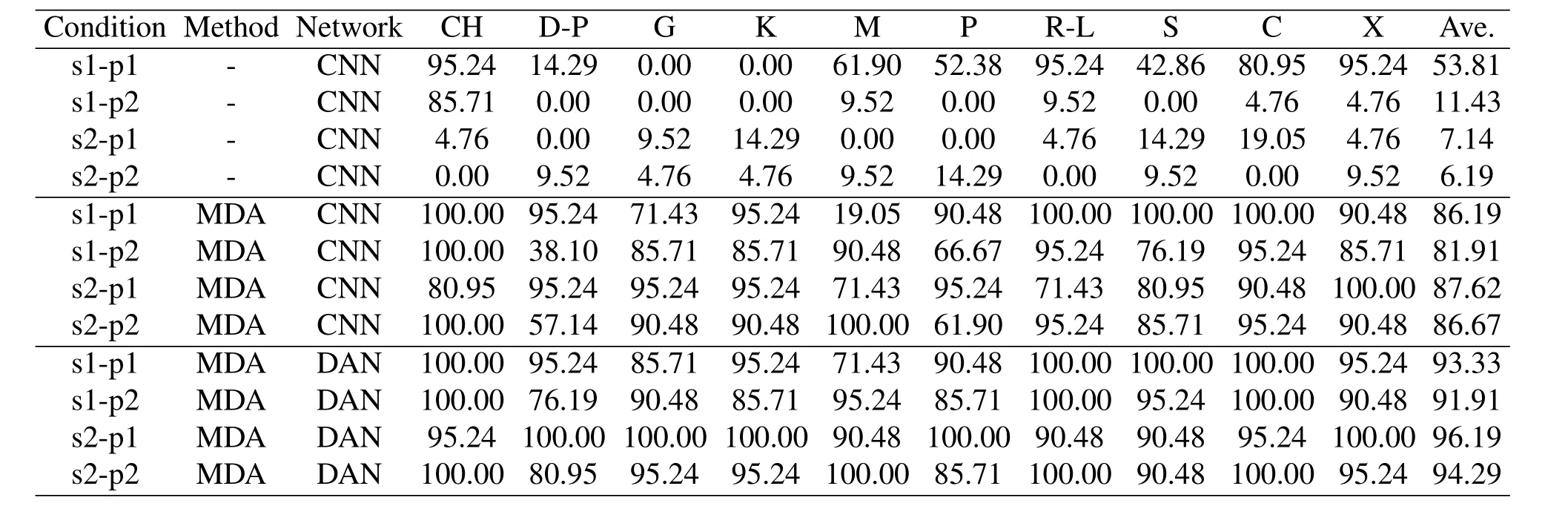
Table2.Recognition accuracy(%)improvement bring by the MDA scheme and the deep adversarial network.
5.2.2 Deep Adversarial Network Performance Evaluation
Although the system achieves better performance with the proposed MDA scheme,the accuracy is still a little low.This is owning to the feature shift problem incurred by the anonymity of persons and the change of surrounding environment.Traditional CNN based deep network could not solve this issue,thus we develop a deep adversarial network(DAN)to tackle this problem.To evaluate the effectiveness of the proposed DAN,we test the performance when using both the MDA and the DAN to realize gesture recognition.The recognition accuracies of each type of gesture under different conditions are summarized in TableII.The average recognition accuracies for the person p1 and p2 in the scenarios s1 and s2 are 93.33%,91.91%,96.19%,and 94.29%,respectively.These results confirm the effectiveness of the proposed DAN in solving feature shift problem.
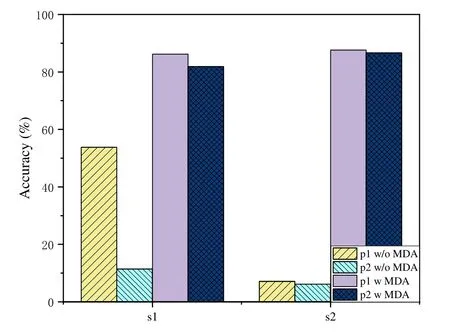
Figure8.Average recognition accuracies with/without MDA scheme.
Furthermore,we also evaluate the gesture recognition performance of the proposed system with MDA and DAN schemes when training the system in one scenario and testing it in another one.The results are summarized in Figure9,where s1-s2 indicates training using the data of s1 (source domain) and testing using the data of s2 (target domain),s1-s4 indicates training using the data of s1 and testing using the data of s4,and so on.We can discover that the proposed DAN based gesture recognition system outperforms the traditional CNN based system remarkably.The average performance improvement is more than 5%.Especially,the performance improvement is more significant when the feature shift is more serious,such as the s1-s4 and s2-s3 conditions,which demonstrates the excellent performing of the proposed DAN in mitigating the feature shift problem.Meanwhile,for all conditions,the proposed DAN based gesture recognition system could achieve an accuracy of more than 90%,which confirms the excellent performance of the proposed DAN in accomplishing the multi-person devicefree gesture recognition task.
5.2.3 System Performance Evaluation
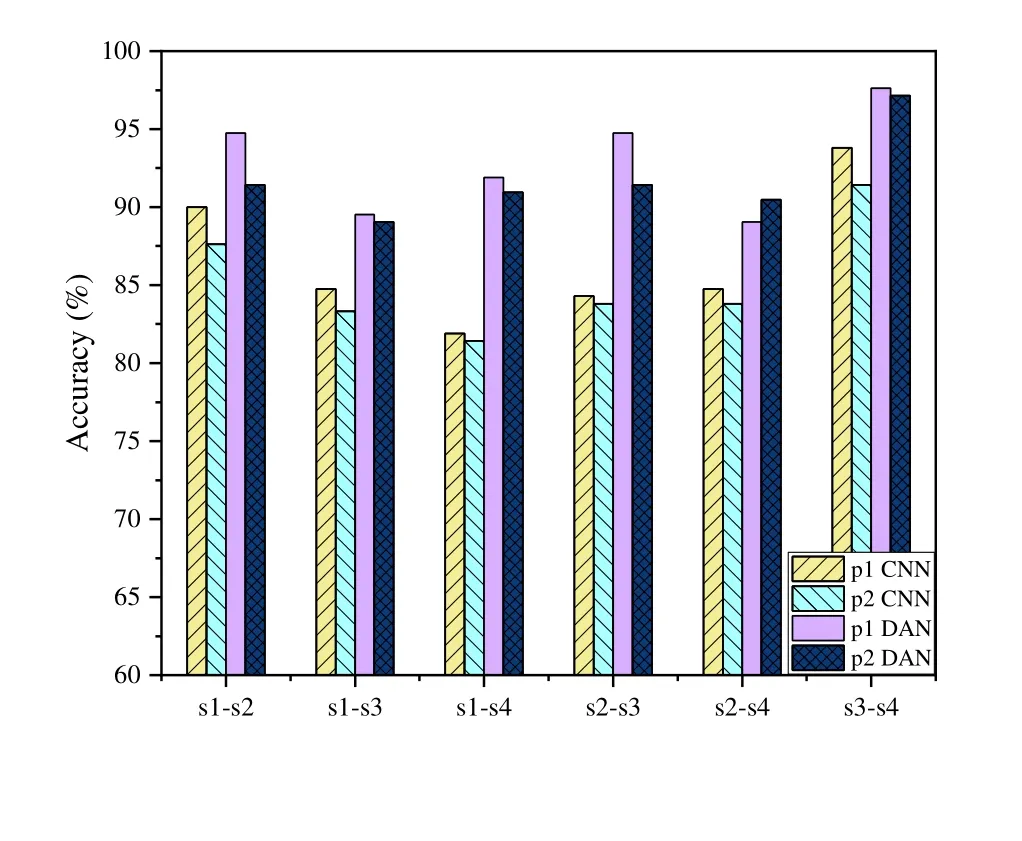
Figure9.Recognition accuracies in different scenarios.
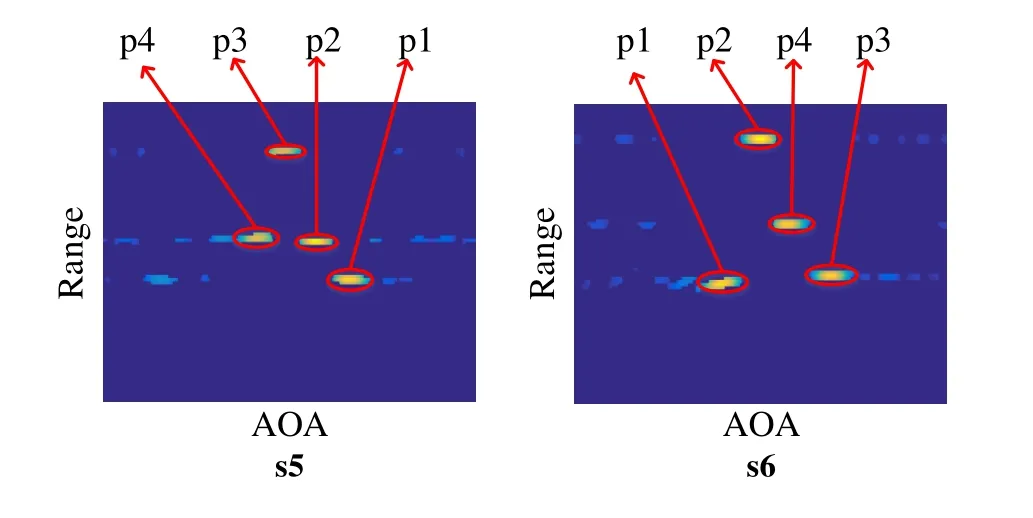
Figure10.Range-AOA maps build for 4 persons in scenarios s5 and s6.
We test the overall system performance in two 4 persons scenarios s5 and s6 as shown in Figure6(f) and Figure6(g).The range-AOA maps build in these two scenarios are illustrated in Figure10.We can see that the 4 persons are easily to be identified and separated in the range and AOA dimensions,which demonstrates the effectiveness of the proposed MDA based mixed signal separation scheme intuitively.The recognition accuracies are summarized in Table3.The developed system can achieve average accuracies of 82.86%,84.76%,86.19%and 83.33%for each person.These results demonstrate the good performance of the developed multi-person device-free gesture recognition system,and confirm that it can be applied in smart home applications where generally there will be no more than 4 persons.
5.3 Discussion
As a multi-person device-free gesture recognition system,the number of simultaneously conducted gestures is determined by the number of dimensions used and the resolution in each dimension.Limited by thehardware,we implement the multi-person device-free gesture recognition system using only the range and AOA dimensions in this paper.It should be mentioned that the proposed multi-dimensional analysis method is general and suitable for any dimensions.When other dimensional information is available,such as the polarization dimension,we can analyse the mixed signals from a higher dimensional perspective,and thus more number of persons can be identified and separated simultaneously.Meanwhile,the resolution is determined by the hardware too.The AOA resolution is determined by the total number of receivers,and the range resolution is limited by the bandwidth of the wireless signal.A better resolution generally leads to a better recognition accuracy.

Table3.Recognition accuracy(%)in 4 persons scenario.
VI.CONCLUSION
In this paper,we proposed a multi-person devicefree gesture recognition system by introducing a novel multi-dimensional analysis method to separate the mixed signal,and a deep adversarial network to mitigate the feature shift problem.We conducted experiments in 6 indoor and outdoor scenarios using a 77GHz FMCW based mmWave prototype system,and tested the performance of the proposed methods extensively.Experimental results showed that the proposed system could recognize gestures with an accuracy of 93%when 2 persons conduct gestures simultaneously,and an accuracy of 84% when there are 4 persons.These results confirm that the developed multi-person device-free gesture recognition system is an effective solution for recognizing the simultaneously conducted gestures.
It should be mentioned that the proposed multidimensional analysis method and deep adversarial network are general strategies which are suitable for other device-free wireless sensing tasks as well.We will explore how to leverage them to solve other wireless sensing tasks in our future work.
ACKNOWLEDGEMENT
This work was supported by National Natural Science Foundation of China under grants U1933104 and 62071081,LiaoNing Revitalization Talents Program under grant XLYC1807019,Liaoning Province Natural Science Foundation under grants 2019-MS-058,Dalian Science and Technology Innovation Foundation under grant 2018J12GX044,Fundamental Research Funds for the Central Universities under grants DUT20LAB113 and DUT20JC07,and Cooperative Scientific Research Project of Chunhui Plan of Ministry of Education.

- China Communications的其它文章
- Future 5G-Oriented System for Urban Rail Transit:Opportunities and Challenges
- Multi-Stage Hierarchical Channel Allocation in UAV-Assisted D2D Networks:A Stackelberg Game Approach
- Performance Analysis of Uplink Massive Spatial Modulation MIMO Systems in Transmit-Correlated Rayleigh Channels
- Development of Hybrid ARQ Protocol for the Quantum Communication System on Stabilizer Codes
- Coded Modulation Faster-than-Nyquist Transmission with Precoder and Channel Shortening Optimization
- Analysis and Design of Scheduling Schemes for Wireless Networks with Unsaturated Traffic