
Providing Guaranteed Network Performance across Tenants:Advances,Challenges and Opportunities
2021-02-26 07:39ChengyuanHuangJiaoZhangTaoHuangYunjieLiu
China Communications 2021年2期
Chengyuan Huang,Jiao Zhang*,Tao Huang,Yunjie Liu
1 State Key Laboratory of Networking and Switching Technology,BUPT,Beijing,China
2 Purple Mountain Laboratories,Nanjing,China
Abstract:The varied network performance in the cloud hurts application performance.This increases the tenant’s cost and becomes the key hindrance to cloud adoption.It is because virtual machines(VMs)belonging to one tenant can reside in multiple physical servers and communication interference across tenants occasionally occurs when encountering network congestion.In order to prevent such unpredictability,it is critical for cloud providers to offer the guaranteed network performance at tenant level.
Keywords:cloud computing;network performance;guaranteed bandwidth;guaranteed delay
I.INTRODUCTION
Nowadays,there is a growing trend for consumers to move their applications to the cloud and providers have gained tremendous profits from it,e.g.,the annual revenue of Amazon Web Services(AWS)in 2019 has grown to $ 35 billion [1].Such a big success of cloud computing should give credit to its ability of sharing and multiplexing resources across multiple tenants.In the past decade,server virtualization has become the dominant approach to manage local resources of a single server and it can offer elastic and guaranteed performance in computing and storage.
Similarly,network virtualization is proposed to provide a tenant with a virtual network regardless of physical network topology and address space.Today several tunnel protocols,such as Virtual eXtensible Local Area Network(VXLAN)[2]and Network Virtualization using Generic Routing Encapsulation (NVGRE)[3],are used in production cloud datacenter[4]to support virtual network.With the virtual network,each tenant can configure her private network address flexibly and ensure her VMs will never receive traffic from others.Therefore,current network overlay techniques have offered support to strong network security and flexible network management.With so many advantages,we ask a bold question:Do distributed applica-tions running atop a virtual network perform like atop a dedicated physical network?
The answer is no.Actually,dedicated network infrastructure can provide not only strong security and flexible management,but also guaranteed performance.If an application utilizes a physical network exclusively,network resources are consumed by this application completely and it can control the realtime resource occupation to obtain the desired performance.However,most of the existing mature network virtualization mechanisms concentrate on management in the control plane,but pay little attention to performance guarantee in the data plane.Even though the big giants including AWS and Microsoft now realize the importance of the problem,it is still a rapidly evolving topic under discussion and there are still no mature specifications yet.
As [5]has revealed that due to the across-tenant interference in production cloud datacenters,the obtained bandwidth for the same kind of VM instances can be varied as much as 16X over time.As a result,a malicious tenant can easily disturb others,e.g.,she can flood traffic over the network and block traffic transmission of others by causing congestion on the link.Meanwhile,popular applications like data mining and distributed machine learning are sensitive to packet delay and loss.For consistent network performance,a tenant has to pay additional costs for services that provide dedicated physical clusters like dedicated AWS EC2 instance.To overcome this serious dilemma,the network performance guarantee (NPG)mechanisms become arguably the most critical issue and attract a substantial amount of research attention recently.
However,achieving guaranteed network performance is very challenging because of the limited capabilities of commodity hardware (the solutions desire the new and powerful hardware support) and intrinsic complexities (the solutions cost too much for the objectives) of these mechanisms.For instance,a switched-based mechanism,per-tenant fair queue(FQ),is considered as an ideal solution to provide guaranteed performance in network as the traffic from different tenants is isolated physically in separated switch queues.However,now commodity switches only support up to eight queues per port [6],thus it lacks scalability to accommodate tenants at large scale.
Existing surveys [4,7–11]on network virtualization either focus on the implementation of commodity network virtualization to enable network quality of service (QoS) or give a broad review of works in a specific field like software-defined networking(SDN).Different from them,we aim to give a structured review of the state of the arts in the public cloud.Instead of configuring or modifying the existing virtualization technologies to enable QoS-aware resource allocation,we concentrate on the root cause of the performance anomalies and give a structured explanation of the proposed architectures.
An existing advance usually strives to solve the network performance anomalies from a specific aspect,e.g.,one may focus on developing a sophisticated VM placement algorithm to avoid resource collision.However,the partial solution lacks a big picture of the NPG problem and is prone to encountering practical issues.Therefore,instead of solving the problem on a case-by-case basis,solving such a complex problem should be considered as system engineering and designers should take many factors into account.In this paper,we survey the latest development of the guaranteed network performance area and the main contributions can be summarized as:
• We present the common architecture of the current advances and give a structured explanation of it,including network abstraction model,VM placement and rate enforcer.Moreover,we discuss the design philosophies behind the components of the representative advances and discuss the pros and cons of them.
• We summarize the challenges when adopting current advances in real datacenters and explain the root cause of each deficiency.Moreover,we reveal that current advances not only have the common deficiencies as the traditional distributed systems,but also have new challenges with emerging network environments.
• We follow the latest development of emerging technologies and explore the possibilities of using them as knobs to improve performance or overcome the inherent shortcomings of current advances.
In Section II,we introduce the concept of the multitenant datacenter network and reveal the relations between the virtualized environments and the NPG problem.Later,we summarize the general enforcement model of the NPG problem and discuss the pros and cons in Section III.Later,we provide a selective survey of recent advances and reveal the key technologies behind existing advances in Section IV.Next,we introduce current challenges and new opportunities brought by the development of emerging technologies in Section V and conclude in Section VI.
II.MULTI-TENANT DATACENTER NETWORK
In this section,we firstly give an overview of current multi-tenant datacenter architecture and introduce the main elements of it.Later,we focus on the network virtualization techniques in the virtualized multitenant datacenter network.Next,we point out that even though the access of the network is restricted in theory,the virtualized tenant-specific network still suffers the unpredicted network performance.Finally,we propose the general objectives of the NPG problem.
2.1 Multi-tenant Datacenter Architecture
Public cloud computing now becomes the cheap and valid alternative for many small businesses,because of the high expense of building their own private datacenters.To overcome this problem,many giant companies such as Google,Microsoft and Amazon construct a number of Infrastructure-as-a-Service (IaaS) public clouds to host multiple tenants simultaneously.Multitenancy in public cloud means that tenants in the same datacenter share the infrastructure and require for their own exclusive virtual environments(called virtual datacenter),e.g.,Cisco refers to its “multi-tenancy” as“the logical isolation of shared virtual compute,storage and network resources”.
For the ease of usage,public cloud providers offer a simple interface to create the virtual datacenter with compute,storage,network resources and a flexible pay-per-use pricing model.The shared nature of the resources reduces the cost on the infrastructure greatly and enables one tenant to scale her virtual datacenter from tens to thousands of VMs within several seconds,at the cost of 10-20 cents per VM per hour[12].This practice of multi-tenancy makes the resources more affordable for tenants and enables cloud providers to host more tenants,thus achieving higher resource utilization.
Current cloud datacenter topology is usually treebased.As depicted in Figure1,there are three layers in the topology,i.e.,the spine,leaf switch and the server layer.In the physical server,the network,compute and storage resources are virtualized and are allocated to different VMs based on the requirements of tenants and the strategies of providers.
Compute virtualizationis a combination of software and hardware protection mechanisms that provide an abstraction enabling resources sharing among multiple VMs,which enhances the efficiency and reduces the cost of IT infrastructure.It provides a flexible model for VMs and physical servers are treated as a pool of resources.The system software that manages the VMs is called a hypervisor.The hypervisors are responsible for sharing resources and isolation between separated VMs.Now the most popular hypervisors can be categorized as:1)bared-metal hypervisors that run directly on physical hardware,e.g.,Xen[13]and KVM[14].2)hosted hypervisors that run atop a host OS using nested virtualization hardware support[15]or binary translation support[16].Different popular cloud providers utilize different hypervisors,e.g.,Google GCE,Microsoft Azure and Amazon EC2 use KVM,Hyper-V and Xen,respectively.
Storage virtualizationis an array of servers that are managed by a virtual storage system.It manages storage from multiple sources as a single repository.These servers are not aware of exactly where their data is stored.Specifically,current public clouds increasingly provide network-attached disks,where a virtual block-storage driver on the host emulates a local disk partition communicating with a physical disk cluster.The disk cluster currently can be part of a Storage Area Network(SAN)or a Network-Attached Storage(NAS).For instance,AWS EC2 offers their disk storage service (Elastic Block Store),and multiple EC2 instance can fetch data from the same datastore isolated by the cloud virtual storage system.
Network virtualizationis a set of virtual network resources,e.g.,virtual nodes (endhosts,switches,routers)and virtual links.Different from the compute and storage virtualization which can be handled by corresponding systems locally,the network resources should be shared globally and can be accessed by any VM in the datacenter.This makes the network virtualization becomes a more challenging task for public cloud providers and we will elaborate it in the next section.
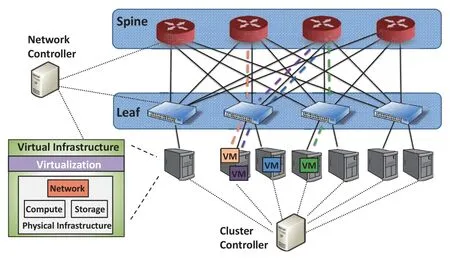
Figure1.An overview of the multi-tenant datacenter.
2.2 Network Virtualization
A virtual network can be considered as a configurable network overlay and it has the capability to use virtual nodes and virtual links from physical infrastructure while keeping them isolated.Figure2 shows an example of two overlay networks running atop one physical infrastructure.We can see that different overlay networks can have different virtual network topologies,e.g.,overlay network 1 is two-layer while overlay network 1 is one-layer.Moreover,physical nodes can belong to different virtual networks simultaneously and physical links are shared by different virtual networks,i.e.,becomes bottlenecks.
Thus,network virtualization provides the ability to run multiple virtual networks and each virtual network has separated control and data plane.A network virtualization layer allows for the creation of virtual networks,each with an independent service model,topology and addressing space,over the same physical network.Further,the creation,configuration and management of these virtual networks is done through global abstractions rather than pieced together through box-by-box configuration[17].On one hand,network virtualization at endhosts is mainly accomplished by the virtual devices,e.g.virtual switches and routers.Multiple VMs running on a single physical server communicate with each other through virtual devices integrated by hypervisors.In this case,the functionality of a virtual device is emulated by virtualization software.As a result,a physical host can be turned into a networking device and there are several solutions that provide such functionality,e.g.,Open vSwitch[18]and Quagga[19].
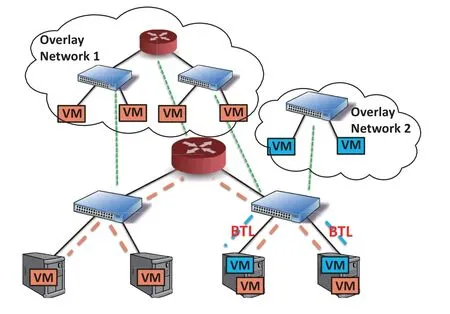
Figure2.Two overlay networks coexist in the same physical infrastructure.
On the other hand,network virtualization in the network is more challenging and the global network fabrics should be shared carefully across arbitrary tenants.Imagine that a tenant owns an exclusive network,she can assign the address of every VM to simplify management and control the traffic in the network to avoid serious traffic collision.This requires a fully controlled data and control plane for each tenant.For the virtualized control plane,the network virtualization solutions ought to compute routing strategy for each tenant,which provides the flexibility of configuration of each virtual network.It remembers important information of VMs automatically to avoid the errorprone box-by-box configuration.For example,in NVP[17],a centralized SDN controller cluster is responsible for configuring virtual switches and it computes appropriate forwarding rules for available tenants in the network continuously.
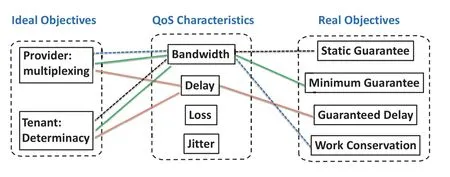
Figure3.The relations between the ideal and real objectives in the NPG problem.
Moreover,to support high security and avoid the malicious access of tenants coexisting in the same physical infrastructure,different tenants strive for individual address spaces.As a result,Virtual Private Cloud (VPC) is proposed to offer secure,simple and customized virtual network for various demands from tenants.The VPC approach configures each VM with two IP addresses,a public IP address for communication over the physical network and a private IP address for emulating the communication pattern in a virtualized network defined by a tenant.Because the large scale of current cloud datacenter,which hosts hundreds of thousands of VMs simultaneously,the traditional network virtualization protocol,Virtual Local Area Network(VLAN),cannot be adopted directly in the cloud.VLAN lacks scalability and can only support up to 4096 virtual network,which is far less than the requirement in public cloud.New network overlay protocols,such as VXLAN [2]and NVGRE [3],are utilized by commodity cloud providers.The hypervisor encapsulates each packet to a pre-configured tunnel between different VMs and adds a new header containing a public IP address to the original packet.In this way,each packet can be routed to corresponding destinations in the physical layer 3 network.Later,the added header is removed automatically at destination to have no impact on the normal transmission.
However,different from the strong support for the control plane and the secure routing in the date plane,there is still no mature solutions to guarantee the network performance in the data plane and we will elaborate it in the next section.
2.3 The NPG Problem
For coexisting tenants in the multiplexed public cloud,the allocated resources can determine their application performance largely.However,commodity public cloud providers,e.g.,AWS,do not make any promise about the amount of network resources allocated to each tenant.Interference among tenants’ traffic happens occasionally which results in the varied network performance,as exemplified by the fact that in Alibaba cloud,the obtained bandwidth for the same kind of VM instances can be varied as much as 16X over time[5].
To illustrate the NPG problem,we use a simple example composed of two tenants,i.e.,tenant A and B.Consider tenant A establishes a TCP connection between two VMs.Meanwhile,a greedy tenant B builds two TCP connections between her VMs.These connections share the same bottleneck in the network.Without careful network resource allocation,the greedy tenant B will easily violate the fair sharing of the bandwidth resource and cause the undesired network performance.
Such a critical issue has drawn an increasing attention from industry and academia.To make the readers have a precise understanding of the NPG problem,here we define the NPG problem as“providing the predictable Quality of Service (QoS)performance in the data plane at the VM/tenant level”.Thus,when we refer to the NPG problem in the following,the immediate focus is the QoS performance,e.g.,bandwidth,delay,loss and jitter.It implies that a small-scale system composed of a limited number of devices is also in the scope of this paper.When the scale of the system grows,the desired QoS performance may not be achieved with the old implementation.Thus,practical issues such as system complexity and scalability may arise,and then many existing works take these practical challenges into account.However,we can consider the practical issues as the challenges when deploying the design to the large-scale cloud environment.Hence,at the high level,the NPG problem mainly concerns the QoS characteristics,which will be elaborated in the next section.
2.4 The Objectives of the NPG Problem
Ideally,the tenant in the cloud requires the perfect performance isolation,i.e.,the deterministic QoS performance.For instance,two VMs belonging to the same tenant can obtain a deterministic and constant end-toend delay without the undesired packet loss and jitter,regardless of the interference with others.Hence,from the tenants’perspective,the determinacy is what they want,e.g.,the deterministic bandwidth,delay,loss and jitter.However,realizing such determinacy may come with an unacceptable cost for both tenants and providers.For instance,to obtain the deterministic bandwidth at any time,the most straightforward way is to reserve the required network resources along the path in advance.However,the rigid reservation makes it difficult for other VMs to reuse the unutilized resources,thus increasing the costs for tenants and reducing the number of tenants a provider can serve.Therefore,from the providers’perspective,the resource multiplexing is highly required.If we comprehensively consider the ideal objectives of the tenant and provider,several compromised and acceptable objectives are proposed in practice,i.e.,static guarantee,minimum guarantee,guaranteed delay and work conservation.Note that deterministic loss and jitter can be achieved automatically with deterministic bandwidth and delay,respectively.For instance,the deterministic end-to-end delay means that every two packets arrive in a constant interval,which results in no packet jitter.Therefore,as shown in Figure3,deterministic loss and jitter are not under discussion currently.
Next,we categorize four typical objectives of previous works and elaborate them in this section.
Static guaranteeis proposed from the tenant’s perspective and it is the first kind of objective used by the state of the arts.It ignores the resource multiplexing and reserves fixed bandwidth for every VM statically.As shown in Figure3,the dotted black line connects the determinacy to the bandwidth,resulting in the static guarantee objective.It is useful in the small-scale prototype and can be easily accomplished by current hypervisors.For example,VMware ESX and Xen have already bandwidth capping mechanisms that limit a maximum transmission rate for each virtual network interface(vNIC)associated with a VM.
Minimum guaranteecan be considered as a relaxed version of static guarantee and it allows tenants to obtain more bandwidth beyond their guarantees temporarily when there is available bandwidth,which leads to higher bandwidth utilization.It improves bandwidth utilization by partially allowing bandwidth multiplexing.As shown in Figure3,the green lines connect the multiplexing and determinacy to the bandwidth,resulting in the minimum guarantee objective.By contrast,static guarantee mechanism ignores realtime bandwidth utilization.In total,static guarantee and minimum guarantee can be categorized as a higher-level concept,bandwidth guarantee.
Compared with minimum guarantee,work conservation takes one step further in terms of bandwidth utilization and it is proposed from the provider’s perspective.As depicted in Figure3,the dotted blue line connects the multiplexing to the bandwidth,resulting in the work conservation objective.Work conservation aims to fully utilize spare bandwidth and allocates bandwidth to the VMs whose demands are not satisfied,but it does not provide any guarantee for VMs.By contrast,minimum guarantee only ensures that the actual bandwidth occupation of a VM can exceed its guarantee and it does not claim of full utilization.Note that work conservation is orthogonal to minimum guarantee,thus both objectives can be considered together to achieve better network utilization and guaranteed performance.
All the above objectives are related to bandwidth allocation,but in terms of network performance,the network delay,is also the spotlight of researches.Therefore,guaranteed delay is becoming one of the most appealing objectives and a virtual network with guaranteed end-to-end delay becomes the key demand for tenants.It specifies the maximum end-to-end delay that a tenant can allow and cannot remove the packet jitter,thus it guarantees the worst performance.As depicted in Figure3,the orange lines connect the determinacy and multiplexing to the delay,resulting in the guaranteed delay objective.As we know,some popular applications like key-value store and remote procedure call(RPC)usually consume a small amount of bandwidth,but have a strict requirement for network delay.The wildly varied delay can hurt the performance of time-sensitive applications and [20]shows that an additional 500us delay can degrade the performance of the distributed machine learning application(Spark MLlib)by 60%.
III.THE NPG ENFORCEMENT
To enforce network performance guarantee,some level of coordination is required across different network elements.In general,we consider the entities which make resources allocation decisions and categorize existing advances into two parts:centralized and distributed.Table1 provides a summary of the NPG enforcement schemes.
3.1 Centralized
In a centralized approach,a centralized unit is responsible for computing the network resource allocation and distributes the instruction to cooperate the distributed rate enforcers in the cloud datacenter.Usually,the centralized controller has a global view of network topology,residual link bandwidth,real-time demands from VMs,etc.It can allocate resources temporally and spatially (e.g.,different time slots and link as-signments) and monitors the global network resource utilization continuously,which has proven to mitigate serious traffic contention across tenants significantly.This makes the centralized controller a simple and effective entity to schedule the resource across tenants.

Table1.A summary of NPG enforcement schemes.
SecondNet [21]and Oktopus [22]are the pioneer works striving for network performance guarantee in a centralized way.They proposed the virtual network cluster abstraction that allows tenants to specify not only the type and number of VMs that tenants use,but also the bandwidth requirements of VMs.Specifically,tenants in both systems need to register their bandwidth requirements to the centralized controller when VMs launch.In this way,tenants expose the required bandwidth precisely,and then controllers can reserve bandwidth resource along paths in advance.Later,Proteus[23]is proposed to overcome the static bandwidth reservation and allocation.Proteus considers the time-varying bandwidth utilization in different applications and it estimates the bandwidth utilization based on the profiling of VMs.SoftBW [5]and Qshare [24]resort to the centralized controller to allocate bandwidth in an indirect way.The controllers of them monitor the real-time utilization and configure the weights of different queues in weighted fair queues (WFQ).Then WFQ schedules packets from different tenants according to their priorities and tenants who pay more for network resources will obtain more bandwidth when multiple tenants compete.NVP[17]and NetLord[25]focus on the implementation of network isolation.Specifically,they discuss the usage of virtual switch and network controller and design the isolation protocols to provide flexible private IP assignments by tenants.HUG [26]discusses the tradeoff between global utilization and optimal isolation.HUG can be implemented atop existing monitoring infrastructure and tenants need to periodically update their profiling to the centralized controller.Pulsar[27]focuses on the end-to-end performance isolation including compute,network and appliance performance.Pulsar proposes a token-based approach to quantify the utilization of all resources and uses a centralized controller to compute and assign tokens to different tenants continuously.Resource Central[28]and Cicada[29]resorts to data-driven methods to infer the traffic pattern in the network.They collect the traffic trace from hypervisors periodically and analyze the real bandwidth usage to improve their previous decisions,thus achieving higher bandwidth utilization.
Advantages:The centralized approach theoretically can obtain higher performance with a global view of network resources.With the precise information about the global link utilization and queue occupancy,the centralized approach can easily compute a global optimal strategy.Moreover,the central management can improve the flexibility and ease of network management.For example,the upgrade of the centralized management can easily be achieved by changing the single centralized controller,without the involvement of a large number of endhosts.
Drawbacks:The centralized approach is obviously prone to single point of failure.For instance,if the centralized controller is attacked by malicious users,the whole system may become invalid.Moreover,the centralized approach lacks scalability.Because the controller has to determine resource allocation for each VM in the cloud,it may become the hotspot of the whole system and cannot handle the increasing number of VMs.Finally,the centralized method may result in performance degradation.For example,a local rate enforcer has no knowledge of the newly generated flow.In this case,it has to report the information to the controller and waits for the respond.In the ultralow latency datacenter,the extra one round trip time is very expensive and increases the flow completion time greatly.
3.2 Distributed
Different from the dumb rate enforcers that are completely guided by a controller in the centralized approach,the local rate enforcers coordinate with each other to determine the resource occupancy in the distributed approach.A distributed method can be implemented in hypervisors or switches.Multiple rate enforcers at endhosts communicate with each other and use specific protocols to notify their real resource demands.
Gatekeeper[30],Netshare[31]and Seawall[32]are the pioneer works striving for guarantee network performance in distributed ways.They allocate bandwidth for tenants in a proportional way and achieve high link utilization for cloud providers.Specifically,the rate enforcer in Gatekeeper limits the minimum and maximum bandwidth utilization for each VM.Netshare uses the Deficit Round Robin (DRR)to maintain fairness among flows at endhosts.Seawall groups all flows from one VM into a logical flow and makes the logical flow mimic the Additive increase/multiplicative decrease (AIMD) behavior of TCP.Cloudmirror [33]proposes a new network abstraction and uses hypervisors to reserve bandwidth statically for each VM.Faircloud [34]discusses the tradeoff between high utilization and network proportionality and the tradeoff between network proportionality and minimum guarantee.PS-N and PS-P in Cloudmirror can be implemented through a distributed mechanism similar to Seawall.ElasticSwitch[35]and Trinity [36]are the two-layer bandwidth allocation methods.They mimic the AIMD behavior of TCP as Seawall.The difference is that their traffic is categorized into the guaranteed and work conservation traffic.The guaranteed layer needs to grab bandwidth for the guaranteed performance quickly and the work conservation layer probes free bandwidth conservatively.EyeQ[37]and eBA[38]improves the bandwidth allocation algorithms in distributed rate enforcers.Specifically,EyeQ assumes a congestion-free network core and uses the congestion signals at edge switches to evolve its bandwidth allocation following a RCP-like way.eBA modifies physical switches and uses explicit bandwidth information of physical links to enforce accurate rate control for traffic between VMs,which overcomes the performance fluctuation with the high dynamics of datacenter traffic.[39]exploits the multipath characteristic of multipath TCP (MPTCP).It distributes the guaranteed and work conservation traffic into different subflows in the same MPTCP connection.The guaranteed subflow has higher priority,thus will not be interfered by work conservation traffic.The work conservation is tuned to be more aggressive because it is already isolated in the priority queue in switches.LaaS [40]is a solution striving for slicing physical network in the whole datacenter topology.LaaS constrains the routing of traffic from different tenants and assigns physical servers and links to form a small physical network for tenants.This achieves the pure physical isolation,but loses the advantage of multiplexing too.Falloc[41]takes advantage of the game theory.It firstly models the bandwidth allocation process as a Nash bargaining game,where all VMs are cooperative to maximize the network utilization,with fairness among VMs being guaranteed.Silo [42]focuses on the bursty characteristic of datacenter traffic.It controls the traffic burst to avoid undesired queue buildup in the network,thus reducing the end-to-end latency.
Advantages:The rate enforcers in a distributed approach can determine local resource occupancy by themselves and communicate with other rate enforcers to allocate global resources,which achieves high robustness and avoids single point of failure.Besides,a rate enforcer computes allocation on its own and does not need to monitor all the VMs globally.This makes the distributed approaches achieve high scalability than the centralized ones.Finally,the instant bandwidth allocation locally overcomes the one RTT wait in the centralized approach,thus improving performance to some degree.
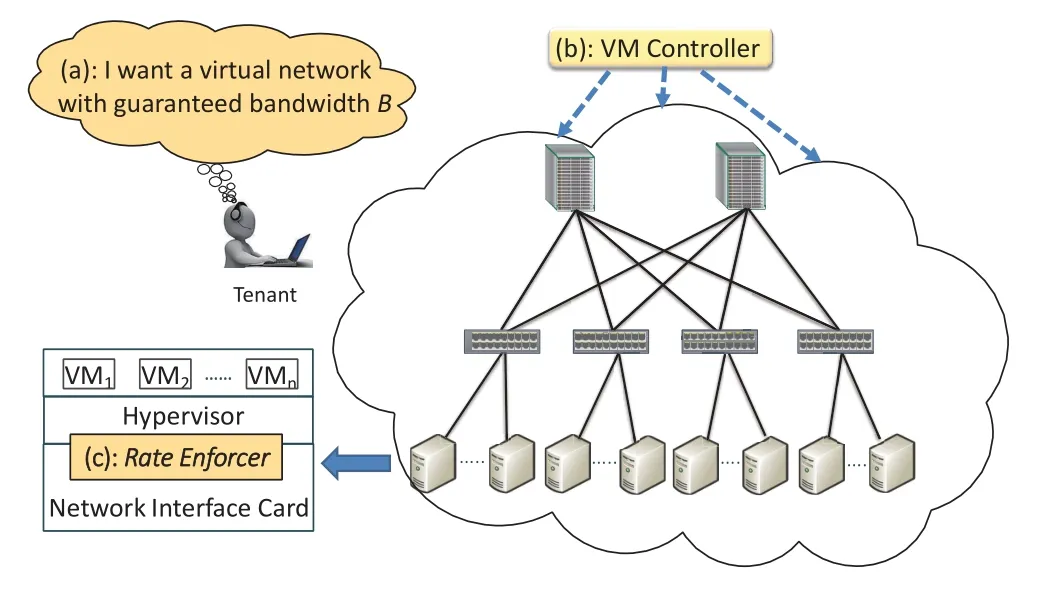
Figure4.The structure of the NPG problem.
Drawbacks:Local view of network statuses and flow properties results in sub-optimal solutions.Specifically,the rate enforcers have to probe and estimate the network utilization along its path to destinations,which takes several rounds to converge,thus causing long convergence time.Further,the busty nature of datacenter traffic occasionally causes network congestion in the network.The distributed rate enforcer has to wait for congestion signals and reduces its utilization,thus causing performance fluctuation.Finally,the larger number of rate enforcers complicates the management,e.g.,if we want to upgrade the bandwidth allocation algorithm,we have to manipulate all rate enforcers.
IV.THE BUILDING BLOCKS OF THE NPG PROBLEM
Existing works aim to solve the NPG problem from different perspectives.We summarize the common model and give an overview of the NPG problem.Later,we elaborate the elements of the structure and introduce representative advances of them.
4.1 Overview
As depicted in Figure4,the architecture includes three components:(a) an easy-to-use network abstraction model that is presented to tenants and it allows tenants to express their requirements accurately.(b) a VM placement algorithm that allocates VMs to physical servers with sufficient network resources and this ensures that the static resource reservation will not violate the constraints of abstraction model and physical infrastructure.(c) an efficient rate enforcer that controls the resource consumptions of connections between VMs in order to allocate bandwidth or burst dynamically.
Let us recall the virtual network in Section I and readers may ask an important question:what should a guaranteed virtual network be like?The abstraction model is proposed to exactly answer this question.By leveraging it,providers give an illusion that a tenant can specify how her instances are connected and how to guarantee bandwidth or delay.As shown in Figure4,when a tenant applies a virtual network,she will be asked to expose her network requirements to the provider.This helps the provider understand the tenant’s requirements accurately and will facilitate easy translation of the requirements to an efficient deployment on the low-level infrastructure,and we will elaborate it in Section 4.2.
VM placementis a classic and efficient approach to mitigate resource collision in the cloud and it effectively reduces the complexity of bandwidth or burst allocation across tenants.Let us consider a situation that all VMs belonging to one tenant reside in the same physical server and they communicate with each other through the virtual switch inside the hypervisor.The capacity of the internal virtual link connecting to the virtual switch can be as high as tens of Gbps and a VM can occupy one virtual link exclusively.Hereby we can regard that the communication between VMs will never be disturbed.As a result,a simple and effective VM placement approach can cluster more VMs belonging to the same tenant in one server to consume less bandwidth on external physical links,which reduces traffic collision in the network greatly.In total,a sophisticated VM placement algorithm can mitigate resource collision effectively and we will elaborate it in Section 4.3.
However,if a physical server cannot accommodate all of a tenant’s VMs,which is the common case in production datacenters,inevitably the traffic will go through the external physical link whose capacity is limited.In order to avoid the uncontrollable interference across tenants,network resources across tenants have to be allocated smartly and quickly according to the tenants’requirements,VM placement,network topology and capacity.The rate enforcer residing in the hypervisor,as shown in Figure4,exactly takes responsibility for this.It allocates bandwidth or burst to meet the tenants’ performance objectives while providing a unified transport infrastructure to minimize malicious behaviors.Currently,the rate enforcer adjusts its behavior either in a centralized manner(under the instruction of a centralized controller)or in a distributed manner (the intrinsic control algorithm running in distributed rate enforcers),and we will elaborate it in Section 4.4.
4.2 Abstraction Model
Among a number of proposals,three abstraction models,i.e.,the pipe model,hose model and tenant application graph (TAG) model,are the most representative.
The pipe model provides an interface for tenants to specify bandwidth guarantees between every pair of VMs as virtual pipes.It is the simplest model which can be borrowed to expose the tenant’s requirement,e.g.,SecondNet [21]reserves bandwidth for every VM-pair path in advance.Given the required bandwidth for every pair of VMs,reservation can be achieved with several kinds of solutions,e.g.,the simple admission control.However,without prior knowledge of communication patterns,a static reserved virtual pipe can be idle while other busy virtual pipes cannot borrow bandwidth from it.Specifically,this model has two main drawbacks:1)bandwidth waste.Bandwidth reservation for every VM pair should be determined once the model is built,which ignores the real traffic matrix.2) operational complexity.To reduce the bandwidth waste,a tenant has to infer the communication pattern between VMs and specifies the capacity for every virtual pipe to approach the real bandwidth consumption.However,the complexity of the pre-defined allocation on pipes grows dramatically with the number of VMs increases,as a tenant has to specify bandwidth for each VM pair.For instance,a typical bandwidth isolation method that utilizes the pipe model is Cicada[29].Initially,the administrator needs to specify bandwidth reservation on every VM pair channel among different VMs.Later,the controller collects the running logs from VMs all over the datacenter and uses the statistics to improve the previous reservation decisions.By this means,the excessively reserved bandwidth will be used,thus bandwidth waste resulted from the rigid reservation on VM pairs can be reduced.Besides,Choreo [43]is another approach to improve applications’ requirement by placing tasks to corresponding VMs.It uses the network monitoring tools such as sFlow or tcpdump to collect application communication patterns continuously.Later,it profiles applications offline to place them to the available pipes that can satisfy their needs.Compared with Cicada which changes the capacities of virtual pipes by prediction,Choreo changes the placements of applications to adapt to the real-time pipe capacities.
The hose model [44]is used to provide flexibility and statistical multiplexing.It offers an elastic and easy-to-use model for tenants.Instead of specifying bandwidth in a pairwise manner,the hose model aggregates multiple virtual pipes through the same physical link into one hose.When a virtual pipe is idle or not fully utilized,other virtual pipes in the same hose can borrow unutilized bandwidth temporarily to achieve better performance.The main benefits of the hose model lie in its simplicity and userfriendliness.A tenant only needs to specify an overall bandwidth for a VM on the operation interface,then the rate enforcer will physically divide the overall bandwidth across multiple virtual pipes without bothering the tenants.Indeed,most existing works can be categorized into the hose model.With the hose model,the administrator only needs to specify the total network requirement for a VM.The centralized network controller in Oktopus [22]multiplexes the aggregated bandwidth and divides it among different VM-pair channels.On the flip side,to overcome the single point of failure in the centralized methods,EyeQ [37],ElasticSwitch [35],Trinity[36],Gatekeeper [30],MPTCP [39],Faircloud [34],eBA [38],Falloc [41],Silo [42],aim to guarantee the bandwidth or delay for the whole VM with different kinds of distributed rate enforcers across the datacenter.Finally,Qshare [24]and LaaS [40]resort to the existing WFQ scheduling mechanism and physical link allocation to achieve the absolute network performance isolation.Because of the physical queue separation and exclusive link occupancy,these methods can guarantee the bandwidth or delay for the whole VM naturally.There are many variants of the hose model,such as virtual oversubscription cluster(VOC) [22]and temporally interleaved virtual cluster (TIVC) [23].They improve the hose model to adapt to the characteristics of bandwidth oversubscription and time-varying traffic,respectively.While the hose model well describes batch applications with homogeneous all-to-all communication patterns,it does not accurately express the requirements for applications composed of multiple tiers with complex traffic interactions.
To overcome the shortcomings of the hose model,the TAG model [33]is proposed to provide a more flexible structure to represent the virtual network based on the application communication structure.If the operator can ensure that a certain group of VMs never communicates with each other,the virtual connections between them can be skipped in advance.This can present a clearer model to help the providers have a better understanding of the tenant’s requirement.The main advantage of the TAG model lies in its flexibility in modeling the tenant’s virtual network.For example,in MapReduce,communication only happens between the VMs in the Mapper tier and the Reducer tier,so there is no need to reserve bandwidth for intra-tier traffic.The TAG model takes both the intra- and inter-tier communication into account.The difference between it and the hose model is that the pipe model is introduced in the TAG model to represent the one-way communication.While the TAG model firstly exposes the need for the mixed use of the hose and pipe model,it makes an implicit assumption that tenants know the communication patterns of all their applications in advance,which may be unpractical in some cases.For example,a cloud VM may host multiple applications,which makes it impossible to block the whole connections between VMs just for a certain application.Moreover,even a VM hosts one application,the demand of this application may vary greatly over time which is reported in[5].
4.3 VM Placement
In traditional VM placement,the VM controller only takes in-server resources,such as empty VM slots in a server or free CPU cores,into consideration,i.e.,network-agnostic VM placement.If a VM placement algorithm takes the network resources into consideration,it is possible to adapt the existing algorithms to meet the network requirement directly,i.e.,
bandwidth-aware VM placement.The advantages of the VM placement lie in its simplicity and efficiency to manipulate resources.Because current VM controllers have a global view of resources across the whole datacenter,they can monitor real-time resource consumption consistently.Therefore,when a request with a guarantee comes,the VM controller can find suitable empty VM slots for the request.
A pioneer advance aiming for bandwidth guarantee is Oktopus[22].The intuition behind this bandwidthaware placement is that the number of VMs that can be allocated to a datacenter subtree is constrained by two factors:1) the VM constraint:the number of empty VM slots in the subtree,which is very straightforward to obtain since the VM controller keeps monitoring every server.2) the residual bandwidth constraint:the residual bandwidth on the physical link connecting a subtree to the rest of the network.An outbound link of a subtree should be able to satisfy the bandwidth requirements of the VMs placed inside the subtree.As a result,the VM controller is aware of bandwidth and can allocate VMs to the hosts connecting with enough free bandwidth.The main shortcoming of Oktopus lies in the static reservation on network links and cannot adapt to the network dynamics.Proteus[23]can be viewed as an improvement of Oktopus.It not only consider s the datacenter network spatially as Oktopus,but also considers the time-varying nature of datacenter traffic.It proposes a time-varying reservation algorithm based on the bandwidth requirement of the Mapreduce application.The main drawback of Proteus is that public cloud can host a large number of applications simultaneously and the pattern of the mixed traffic is hard to predict.As a result,Proteus is limited to clusters that run the big data analysis application.
Cloudmirror[33]takes one step further and aims for the efficient and high available VM placement.Cloudmirror points out that excessive colocation increases the chance for applications to experience downtime with a single server or switch failure.Therefore,efficiency and high availability are not always in agreement with the bandwidth-saving advantage brought by colocation.Cloudmirror proposes a balanced VM placement considering multiple resources utilization and high availability.The key intuition behind Cloudmirror is that placing high-bandwidth and low-bandwidth demanding VMs together,even though they do not communicate with each other.In this way,Cloudmirror can achieve efficient and balanced VM placement.SVCE[45]also focuses on the survivability of tenant services against physical failures.Previous literature has studied virtual cluster backup provisioning to mitigate the negative impact of physical failures.However,they do not consider the impact of VM placement on backup resource consumption.SVCE studies how to place virtual clusters survivably in the cloud,by jointly optimizing primary and backup resource consumption of virtual clusters.In particular,it aims at embedding tenants’requests survivably such that they can recover from any single physical server failure,meanwhile minimizing the total amount of bandwidth reserved by each tenant.
Qshare [24]is an in-network solution to achieve minimum guarantee and work conservation simultaneously.Instead of using only one queue in a switch,Qshare leverages multiple WFQs to slice network bandwidth for tenants.The key challenge of Qshare is to address the problem of the queue scarcity:the number of queues on each switch port (typically 8)is very likely less than the number of tenants served by this port and therefore it cannot reserve a dedicated queue for each tenant.Thus,Qshare takes the number of tenants that each port serves into consideration and uses it as an additional restriction to model a queue-aware VM placement.Later,it designs a novel balanced placement to alleviate the queue scarcity.
LaaS[40]resorts to the routing control and exploits the exclusive resource reservation to isolate the traffic of the tenants.All advances above cannot provide an instant guarantee as if she were alone in the shared cloud.They only consider satisfying the static requirement first,later rely on other schemes to allocate bandwidth across tenants dynamically.As a result,it still take a few milliseconds to get converged [37],while the lifetime of some cloud traffic is 2 to 3 orders of magnitude shorter.The dilemma motivates the design of making the exclusive reservation on physical hosts and links.The main idea of LaaS is that each tenant should receive her own dedicated physical subtree network,i.e.,exclusive access to a subset of the datacenter links.As a result,LaaS avoids using the slow rate enforcers since the traffic from different tenants will never meet on a link.This exclusive reservation obviously can offer ultra-stable performance,but it is difficult to find an exclusive subtree for every tenant in today’s crowded public cloud,thus it fails to achieve high scalability.
Silo [42]is a system that allows operators to give tenants the delay guarantee between their VMs.The key insight behind Silo’s design is that end-to-end packet delay can be bounded through fine-grained burst control at endhosts.As we know,the queueing delay is the main component of delay in cloud datacenters and if we can control the queue length between two endpoints,then the guaranteed delay can be achieved [46].Therefore,Silo takes the queue buildup into consideration and develops a novel burst-aware VM placement algorithm.
Cicada [29]is a data-driven advance and it places VMs by precisely predicting the tenant’s demand.As introduced in Proteus [23],the reserved bandwidth may not be fully utilized because traffic surges frequently.Different from predicting real-time traffic matrix with prior knowledge of specific applications as Proteus,Cicada collects real-time traces monitored by hypervisors at endhosts and daemon processes at switches.Cicada analyses these traces and learns to modify its previous prediction.Similarly,[28,47,48]take a step further to build a more sophisticated data-driven resource management system.They not only predict the resource utilization,but also manage VM lifetime,deployment size,job scheduling,etc.The data-driven approaches get over the rigid assumption of static resource reservation and it learns from the datacenter infrastructure and tenants gradually.By this means,it can adapt to the high dynamics in the real environment.However,current data-driven approaches still rely on centralized controllers.Thus,it lacks scalability and take a very long time to learn from the environment.
4.4 Rate Enforcer
After tenants use appropriate network models exposing her requirements and use VM placement algorithms ensuring static guarantee,the fine-grained network resource allocation is achieved with the help of rate enforcers.In this section,we elaborate the most representative rate enforcers and discuss their pros and cons.
At the early stage of researches,proposals only strive for the achievement of bandwidth guarantee in a simple and straightforward manner.Following this principle,Oktopus [22]uses a centralized network controller to determine the available bandwidth between VM-to-VM pairs.Oktopus implements the rate enforcers by the hypervisor-based rate limiters.Similar centralized approaches are adopted by Second-Net [21],Proteus [23],Pulsar [27],HUG [26]and SoftBW [5].These methods rely on centralized controllers computing results for all rate enforcers and it is the simplest way to enforce bandwidth allocation in a small testbed.However,such centralized methods are unlikely to scale up to the production cloud network,thus it is prone to the single point of failure and lacks scalability.
Different from the static bandwidth reservation before,Gatekeeper [30]improves overall utilization by defining both the minimum guaranteed rate and maximum allowed rate for each VM’s vNIC.It provides per-vNIC bandwidth guarantees in both directions of the network link at each physical server,i.e.,for both egress and ingress traffic.The rate control logic of Gatekeeper runs in the distributed vNICs.Therefore,Gatekeeper overcomes the low scalability of the centralized approaches.However,even though the bandwidth consumption of Gatekeeper can exceed the minimum guarantee,the extremes(maximum and minimum guarantees) are still configured statically.Thus,Gatekeeper is unlikely to fully utilize free bandwidth.Moreover,Gatekeeper and other mechanisms such as EyeQ [37],HUG [26]and SoftBW[5]make an assumption of congestion-free network core which is arguably not always practical.
Seawall [32]utilizes a TCP-like mechanism to allocate bandwidth across VMs in the max-min fairness fashion.Seawall adds a shim layer in the hypervisor and aggregates all traffic flowing between a VM pair into one logical flow.The rate control logic of Seawall evolves in the weighted AIMD fashion like TCP.Different from Gatekeeper which specifies the maximum and minimum guarantee in advance,Seawall evolves its rate independently in the TCP-like manner.By this means,Seawall can grab free bandwidth even it is beyond the VM’s guarantee,thus improves the overall bandwidth utilization.Due to the distributed nature of Seawall,it is independent of the infrastructure and can easily scale to a large number of tenants.However,Seawall only aims for VM-level fairness but ignores the bandwidth guarantee.In essence,Seawall [32],VCC [49],AC/DC TCP [50],Falloc[41]and eBA[38]share the similar design philosophy.They develop distributed VM-level congestion control algorithms that form unified traffic control frameworks.
ElasticSwitch[35]is proposed to overcome the deficiency of lack of bandwidth guarantee as Seawall[32].It is a distributed mechanism,which uses two-layer rate control in the hypervisor.The high layer of guarantee partitioning(GP)communicates with each other to divide VMs’ guarantees into VM-pair guarantees.The low layer of rate allocation (RA) adopts a TCPlike control logic at the granularity of VM-to-VM pairs.Unlike Seawall which is a single-layer mechanism,the two layers in ElasticSwitch work together to achieve the work conservation and bandwidth guarantee simultaneously.The shortcomings of Elastic-Switch mainly lies in the complex maintenance of VM-to-VM channels,as ElasticSwitch has to compute rate for every channel consistently.Moreover,ElasticSwitch also suffers the varied performance resulted from severe interference between work conservation and bandwidth guarantee traffic.
Trinity[36]can be considered as a variant of ElasticSwitch and it takes advantage of the priority queue in network switches.Trinity moves one step further to complement ElasticSwitch with the simple in-network support.If the bandwidth consumption is less than the bandwidth guarantee,the traffic is labeled with high priority.For the bandwidth consumption beyond bandwidth guarantee,Trinity generates explicit lowpriority work conservation traffic.Therefore,Trinity overcomes the interference between guaranteed and work conservation traffic,which leads to fast convergence of the bandwidth allocation.However,when the mix of guaranteed and work conservation traffic overwhelms a port,the work conservation traffic may be excessively dropped when encountering congestion.Moreover,the dynamic assignment of priorities easily results in the frequent trap of lowpriority traffic.
To overcome the serious issue of excessively dropping of work conservation traffic mentioned before,B.Ali,et al [39]take advantage of multi-path TCP(MPTCP).Different from exploiting a single path between VM pairs,they develop a customized MPTCP to alleviate the negative impact of the excessive packet losses.For each TCP connection,MPTCP generates two subflows.One is used for bandwidth guarantee traffic and the other one is used for work conservation traffic.Each subflow in MPTCP handles packet loss separately,thus the excessively dropped work con-servation traffic resulting from the aggressive probing does not cause the drastic shrink of congestion window for guaranteed traffic.The main advantage of [39]lies in the smart usage of the characteristic of MPTCP,i.e.,the separation of subflows ensures that the aggressive probing traffic only impacts one subflow,not the whole connection.However,it still takes tens of rounds to converge to the desired bandwidth.
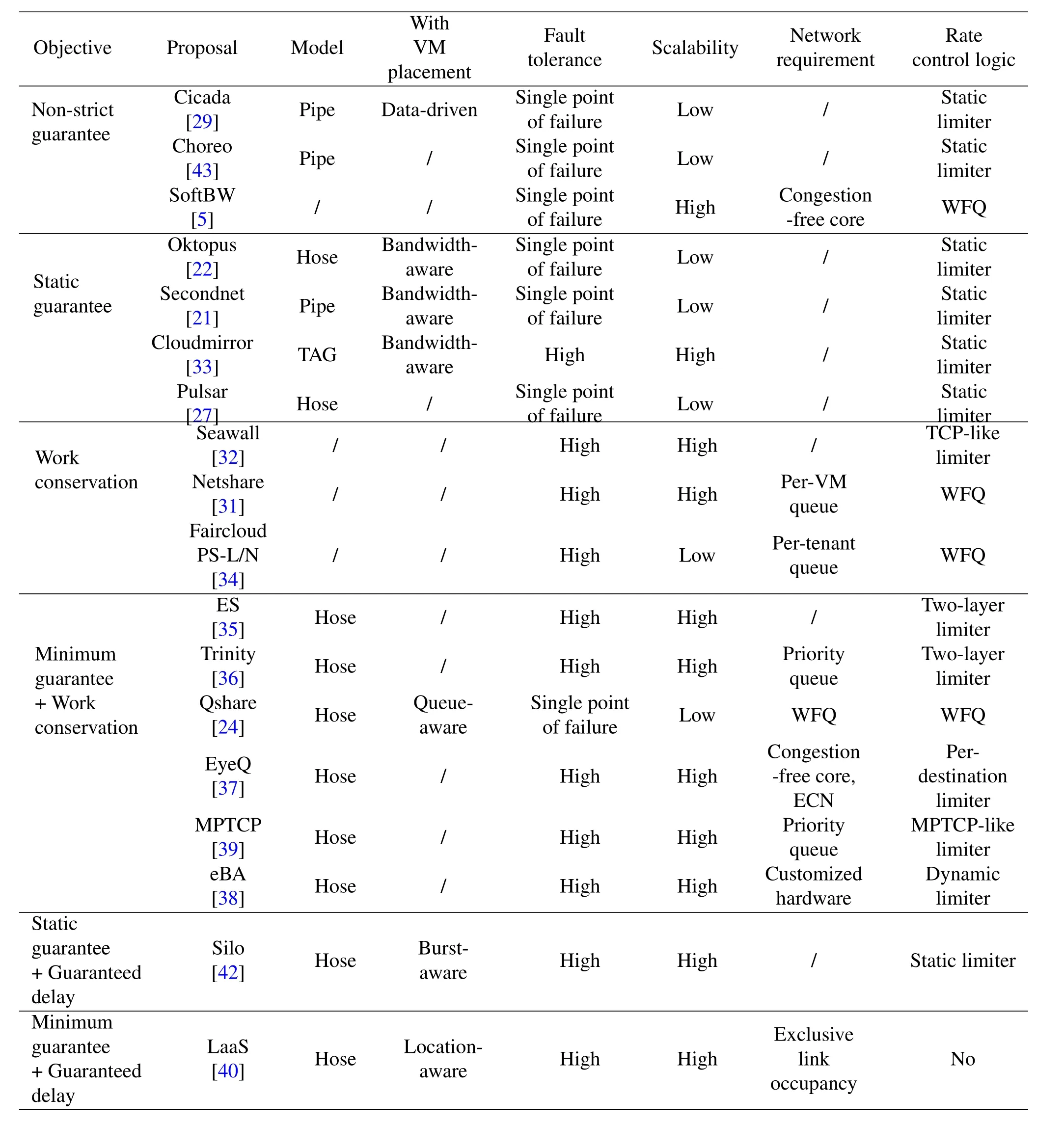
Table2.A summary of current advances.
Qshare [24]is proposed to overcome the deficiencies of the previous endhost-based approaches such as slow convergence and performance variability.Similar to Trinity[36],Qshare is also a switch-assisted approach,but it takes one step further and moves the rate control logic to the network switch completely.The packet scheduling at the congested switches can allocate bandwidth across tenants instantaneously,without the estimation at endhosts.Further,Qshare does not depend on the dynamic assignment of priorities,thus it will not cause out-of-order packets.However,though Qshare leverages the VM placement to alleviate the queue scarcity,it still cannot overcome this fundamental shortcoming,which causes low scalability.
For convenience,we summarize the main advances in the NPG problem and list them in Table2 in the following.
V.CURRENT CHALLENGES AND BROADER PERSPECTIVES
We have introduced the state of the arts and summarized the common pattern of the guaranteed network performance problem in previous sections.To make a better understanding of the development of the guaranteed network performance across tenants,we make the developing flowchart in Figure5.
However,due to the unpractical issues such as high cost and low scalability,even the cloud providers pay more attention to QoS in network now,few of them achieve a stable network performance.For instance,recent studies of the internal network in cloud datacenters(AWS and Microsoft Azure)show that the packet delay between VMs can vary significantly [20]and 99.9th percentile packet delay is an order of magnitude more the median.In this section,we summarize the challenges when deploying the state of the arts and bring forward some potential solutions and opportunities worthy of further researching.Specifically,we summarize the potential solutions and opportunities into three parts,i.e.,the advanced hardware and algorithm,new forms of cloud computing and intra-DC traffic and routing control,which is also shown in Figure6.
5.1 Coexisting with RDMA
A recent trend in the modern cloud is the rapid deployment of many customized hardware to offload some functions off CPUs.The current network stack realizes complex functions such as admission control and traffic shaping.However,the stack is becoming more complex since more features are added and the speed of network links is rapidly increasing from tens of Gbps to 400 Gbps in the near future.The complex functions and ultra-fast speed put tremendous pressure on CPU that runs software-based network stack,which inevitably takes away a large number of CPU cycles from VMs.As reported in [51],the transmission of the messages sized of 4 KB on a 40 Gbps link will burn one CPU completely.
To relieve the burden on CPU,more customized hardware,e.g.,remote direct memory access(RDMA),are designed to undertake more networking jobs [52],[53].The RDMA network interface(RNIC) can access the main memory directly from one computer into that of another without involving either one’s operating system.This greatly improves the throughput and reduces the network delay of an application in a dedicated cluster.
However,the power of pure hardware-based transmission comes at the cost of losing flexibility.The offloading of packet transmission implies that CPU lacks the capability of traffic control until the whole memory is moved.This makes it harder to adopt existing network performance isolation advances in the RDMA environment as they all require the real-time involvement of CPU.What’s worse,recent work[54]shows the message size has a great impact on the throughput and end-to-end delay of competing flows.This means that one tenant now can enlarge the message size to obtain excessive occupancy over others,which results in performance anomalies easily.For example,if the message sizes are 1 GB and 1 MB,the former flow can grab 40%bandwidth more than the other[54].
To address the above difficulties,we argue that a novel hardware abstraction and control layer should be added to the hypervisor.This layer should provide the capability to access the memory inside a VM.As we know,the memory region inside a VM is independent of that of the server.Therefore,when a VM requests the transmission of its memory pages,the shim layer should resolve the virtual address inside a VM and guide the RNIC to access the real physical memory.Later,to overcome the different message size problem,the shim layer needs to split the large message into identical message fragments.Then the shim layer should call the RNIC to transmit these fragments in a round-robin fashion to achieve fairness among VMs.
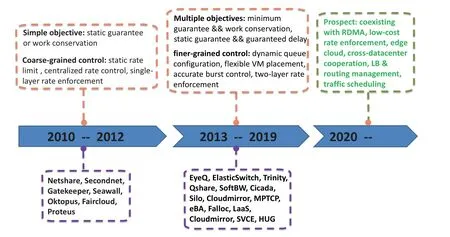
Figure5.Evolution of the NPG paradigm.
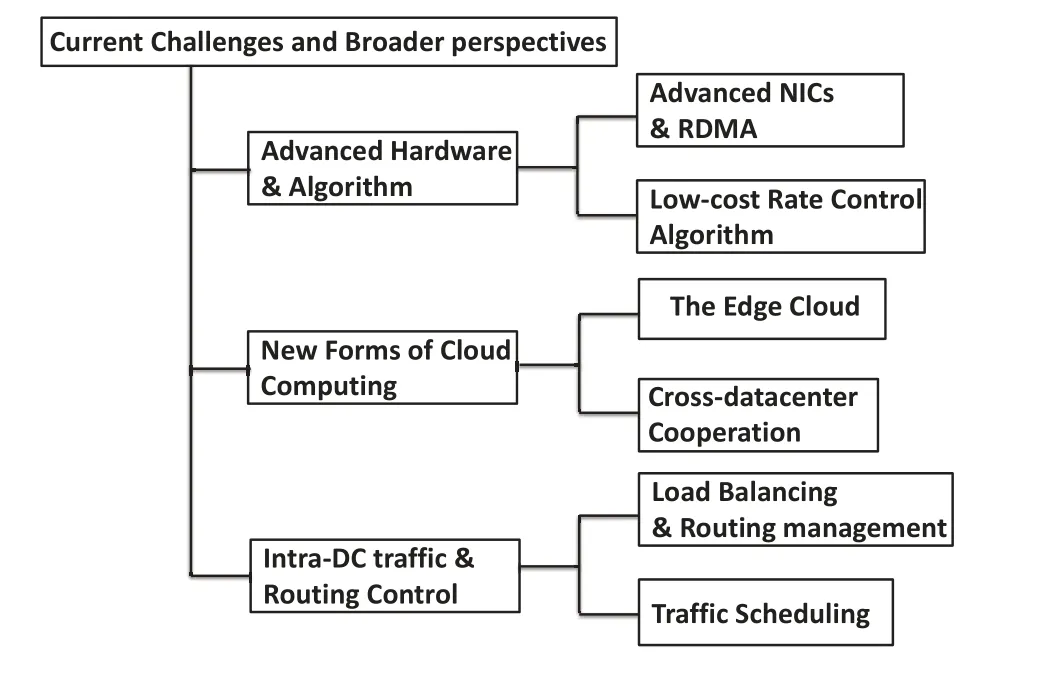
Figure6.The high-level breakdown of current challenges and broader perspectives.
5.2 Low-cost Rate Enforcement
The major deficiency of current rate enforcers is the high cost of rate limiting.First,the overhead of enforcers grows dramatically with the increasing number of connections,which hurts the providers’profit significantly.As [55]shows,the FQ rate limiter which is implemented in the Linux network stack causes 40%CPU cycle consumption at the rate of 40 Gbps.With the increase of the link rates,it is expected that traditional network limiters will burn the whole CPU in the future 400 Gbps link.Because CPU is a valuable property in the cloud,the high CPU cost becomes the key hindrance to the adoption of traditional rate limiters in production.
Second,the VM-level communication pattern in existing works puts significant pressure on the channel management.For example,if a tenant ownsNVMs,a VM needs to maintainN −1 VM-to-VM channels.As a result,a tenant should keep(N −1)2channels.When a tenant makes a large-scale deployment,a large number of states should be stored in memory.To avoid pairwise channel management,the tenant-level queue scheduling mechanism is introduced.Many works adopt the per-tenant queue to isolate traffic among tenants.However,as [6]reported,only 2 or 3 priority levels are available in production,which makes it impossible to leverage WFQ to isolate traffic.
Some works may be borrowed to solve the above problems partly.For example,a number of research efforts have been made to design efficient traffic shapers [55–57].Carousel [55]is reported to shape traffic effectively while reducing the overall CPU utilization by 8% relative to HTB and with an improvement of 20% in the CPU utilization attributed to networking.However,it still cannot solve the complexity of channel management and the wasted CPU cycles are considerable.One may want to resort to the powerful switches to overcome the queue scarcity.An emerging programmable hardware like Barefoot Tofino provides several useful hardware features to support efficient bandwidth allocation.1)a relatively large amount of stateful memory,which can be accessed and updated to maintain states across packets.As reported in[58],the commodity programmable switch now can support thousands of queues concurrently.2) multiple kinds of computation primitives,such as addition and bit-shifts,which can perform a limited amount of processing on header fields.This can impose computation on packets directly in ASIC without involvement of the CPU,which leads to process many packets at high rate.However,the number of queues is still not enough for production cloud.Because a real AWS datacenter holds hundreds of thousands of tenants simultaneously,even the novel switches cannot satisfy the requirement.
To overcome the above shortcomings,a solution needs to be highly scalable and low-cost.We propose a hybrid method that is composed of in-network queue scheduling and endhost-based packet labeling.It can mimic the behavior of WFQ in a switch by cooperating with the distributed VMs with the dynamic labeling.Moreover,it is a stateless approach which does not need to keep states in switches and offers fast VM-level performance guarantee,thus achieving high scalability and performance.Let us recall the workflow of WFQ:the WFQ scheduling selects transmission order for packets by modeling their finish time as if they were transmitted in the roundrobin manner.The packet with the earliest finish time is selected for transmission.To reduce the overhead of computing real finish time for every packet,WFQ records a monotonically increasing virtual finish time to schedule packets.All queued packets in the switch are labeled with their virtual finish time when they enter the switch.Later,WFQ schedules these packets in the ascending order of their virtual finish time.
As described above,to get the virtual finish time,the WFQ scheduler needs to keep states for each flow.For example,for a new arrival packet,the WFQ scheduler has to remember the virtual finish time of its previous packet belonging to the same flow.By this means,the WFQ needs to keep and update states for every flow individually.One may want to adopt the WFQ directly to maintain fairness across VMs.WFQ can consider traffic flowing between a pair of VMs as a VM-level flow and isolate traffic from different VM-level flows into separated physical queues.Later,WFQ schedules packets across queues accordingly and achieves VM-level fairness naturally.However,as reported in[6],the number of available queues is usually 2 or 3,which means the number of queues that can be used to separate traffic is 2 or 3.Meanwhile,a physical server may host tens of VM instances or containers simultaneously [59].Thus,even a leaf switch at the edge has to serve hundreds to thousands of VM instances,which makes it impossible for directed WFQ adoption to compute and keep states in switches.
To solve such a dilemma,we can mimic the behavior of WFQ and propose a distributed VM-level WFQ.It is noteworthy that the inherent shortcoming of the WFQ lies in the fact that it keeps states for all flows in a centralized fashion.Instead of keeping and updating states in the centralized switch,we offload this job to the endhosts.As a result,the distributed endhosts can approximate the WFQ by cooperation.Concretely,the hypervisor inside a host can mimic and label each outgoing packet based on its real-time bandwidth consumption and the guaranteed bandwidth.In this way,each packet carries the flow states itself.Thus,when packets enter a switch,the switch can dequeue the packets in the ascending order of their labels to obtain desired bandwidth.For example,consider there are two VMs (VM A and B) connecting to a switch and their guaranteed bandwidth are 1 and 0.5 pkt/sec,respectively.They send their traffic at the rate of 1 pkt/sec simultaneously and every packet is labeled with its guaranteed scheduling time.As a result,the packets from VM A are labeled with 1,2,3,etc.The packets from VM B are labeled with 2,4,6,etc.When they enter a switch,the switch sorts the packets based on their labels.As a result,it firstly schedules the packets with label 1 and 2 from VM A,then schedules the packet with label 2 from VM B.The scheduler dequeues two packets from VM A and then dequeues one packet from VM B,which is in agreement with their guaranteed bandwidth.Moreover,what we need is a simple FIFO (First-In-First-Out) queue that can contain all the packets.Later,the packet scheduler dequeues the packets in ascending order of their guaranteed scheduling time.By this distributed VM-level WFQ mechanism,we can easily emulate the WFQ in a distributed way without the requirement of multiple physical queues.
In a nutshell,this hybrid approach does not need to store and manage of the pairwise states at endhosts,thus it avoids useless CPU costs and memory occupancy.Meanwhile,the switch only requires one single FIFO queue,thus achieving high scalability and performance.
5.3 The Edge Cloud
While the traditional cloud excels at performing complex computations,sending data from all devices to traditional cloud datacenters for processing is too slow for real-time workflows.Moreover,data is increasingly produced at the edge of the network.It is expected that the amount of data produced by Internet of Things(IoT)is expected to reach 4.4 zettabytes by 2020,from just 0.1 zettabytes in 2013.Moving so much data on the Internet is very expensive,thus it would be more efficient to process data at the edge of the network.
The edge cloud is proposed to overcome the above problems.However,the network performance guarantee in the edge cloud has not drawn enough attention from academia yet.Imagine an industrial cloud where a robot arm in a factory is cutting a piece of glass under the real-time instruction of an industrial control unit,one single delayed instruction may result in a wrong move on the glass,which destroys the entire glass.Therefore,it is critical to provide guaranteed network performance in the edge cloud.
However,to guarantee network performance in the edge cloud is even harder than that in traditional cloud.First,there is a big difference between the edge and traditional cloud.Traditional cloud paradigms which are prompted by giant companies such as Amazon,Microsoft and Alibaba,have some de facto standards.For example,big cloud datacenters have the common tree-based topologies and use high-speed Ethernet to connect servers,which cannot be held in the edge cloud.As a result,the existing performance guarantee approaches cannot be borrowed directly.Second,the heterogeneity of the edge cloud makes it difficult to develop a universal method to achieve the performance guarantee.Various platforms are available,e.g.,both the cloudlet [60]and CORD project can use resource-rich machines near users to offer typical services in traditional cloud.Finally,the communication protocols are diverse even inside an edge cloud.For example,in a smart home environment,the IoT devices may communicate with the smart gateway by Wifi,Bluetooth,and Zigbee protocols.
With so many challenges needed to be addressed,delivering guaranteed network performance in the edge cloud is full of research opportunities.For example,a universal standard for building edge cloud infrastructure is highly desired.The intelligent spectrum control is also required because wireless communication can interfere with each other easily.
5.4 Cross-datacenter Cooperation
Large-scale cloud providers are building datacenters globally to offer their user low latency to their services.Moreover,there is a growing trend for clients to deploy their business across multiple datacenters.By this means,they improve the reliability and reduce the response time of their applications[61–64].
Most of existing advances strive to guarantee the performance for the east-west traffic which is inside a datacenter.However,not considering the geodistributed characteristics may incur a serious performance degradation.For example,a tenant is running her mapreduce query across sites.If one mapper task on a site that has a large amount of intermediate data but low uplink bandwidth,all data on this site has to be uploaded to other sites over its narrow uplink.This will significantly affect the response time of the whole job.Therefore,it is critical to provide guaranteed network performance across sites.
Instead of providing the guaranteed performance for the east-west traffic,a few works take the south-north traffic cross sites into account.Amoeba [65]aims to provide deadline guarantees for inter-DC transfers,but it focuses on the coarse-grained traffic scheduling,i.e.,interactive,bulk,and background traffic scheduling.It cannot guarantee flexible performance as that inside a datacenter.ADMM [66]takes one step further to think about the usage of expensive inter-DC WAN and it minimizes the cost of total inter-DC WAN while offering static guarantees for specific applications.
Providing guaranteed performance across sites is a very challenging task.The reasons include:1)the heterogeneity of the inter-DC network.Different from the intra-DC tree-based topology,each cloud provider builds and connects datacenters independently.Some providers build dedicated links between their datacenters,but others lease bandwidth from Internet service providers (ISPs) to deliver the traffic among datacenters.For the leased links,cloud providers usually lack the full control of these links.2) the high scalability demand.The gateway switches connecting to other datacenters have to serve a larger number of tenants than that inside a datacenter.The queue scarcity problem is more severe in the inter-DC situation and high scalability is required.3) the end-to-end delay guarantee.Existing works focus on bandwidth guarantee across sites.However,the guaranteed delay is not fully discussed.Guaranteeing end-to-end delay on WAN links is more difficult since these links carry more kinds of traffic and the traffic varies significantly over time.
To solve the above challenges,one of the solutions can be a new tunnel-based resource reservation protocol combined with a new queue scheduling algorithm.When a new request comes,an endto-end tunnel should be built hop-by-hop.Meanwhile,each switch along the tunnel reserves the required resource for this request,which avoids the uncontrolled resource contention.Such a distributed resource management improves the scalability greatly and it can make a decision that whether a request can be satisfied or not.Then the queue scheduling algorithm can schedule packets from different tenants based on their service-level agreement.
5.5 Load Balancing and Routing Management
Current datacenter network topologies are variants of multi-rooted trees and it can provide a large degree of path redundancy.Distributing traffic across multiple paths properly can mitigate hotspots in the network and increase global network utilization.As a result,a large number of load balancing approaches are proposed to improve the network performance in the public cloud.
The most widely used load balancing approach is the Equal-cost multi-path routing(ECMP).ECMP assigns traffic across multiple available paths by hashing specific fields in packet headers statically.Because of its simplicity,ECMP is widely deployed in the network switches and it achieves high availability and practicality.
However,ECMP ignores the real-time network conditions and it may distribute traffic to a path with heavy load.To avoid the static path selecting,dynamic load balancing approaches are proposed [67–69,39,70].Planck [67]uses a controller to monitor traffic and generate congestion events.It is a simple centralized approach to migrate the traffic away from congested hotspots.Hedera[68]is also a centralized method and it takes advantage of ECMP to offload some functionalities to switches.Hedera initially distributes traffic via hashing and monitors the network continuously.It only migrates the elephant flows to a light loaded link.MPTCP [39]establishes multiple subflows in one connection and it can shifts load across multiple subflows to utilize network resources along multiple paths.CONGA[69]can react to network dynamics in a two-layer leaf-spine network.The leaf switch keeps a table for recording the historic loads in its outgoing ports.It tags the load information to packets,then switches collect such information to facilitate routing decisions.
However,many previous NPG works neglect the tenant-level routing management and only take efforts on management at hypervisors for the sake of easy configuration and implementation [17],[25].They control the virtual switches at hypervisors and leverage a set of tunnels between each pair of hypervisors.The actual tenant traffic forwarding is ignored.This may cause that the pre-computed resource reservation on specific paths conflicts with load balancing mechanisms.For instance,the ECMP may blindly route the traffic from a tenant away from the reserved path.The lack of tenant-level traffic and routing management results in various limitations.First,a tenant suffers varied in-network performance and its required performance (e.g.,delay,bandwidth and jitter) cannot be guaranteed.Second,without explicit route control,cloud providers cannot reroute traffic to a light loaded path to guarantee performance,thus violating the service-level agreement with tenants.
As a result,an explicit routing management is highly required in NPG problem.A number of previous advances consider explicit routing control to reserve network resource in advance,e.g.,Oktopus[22],Silo [42]and Qshare [24].However,these works make an implicit assumption that network routing and configuration remain static all the time.However,this assumption cannot be held in current public cloud.[71,72]reveal that network update can be triggered by various events,such as switch failures,VM migration and switch firmware upgrade.A recent tenant-level routing management advance,OpReduce[73],is proposed to tackle the recurrent network update while providing guaranteed network performance.OpReduce is a two-phase approach and it controls the routing continuously for each tenant-routing update.
5.6 Traffic Scheduling
The traffic scheduling aims to optimize for a set of performance metrics,such as throughput,delay and fairness.Among the performance objectives,fairness is the key characteristic in the NPG problem.Maintaining tenant-level fairness obviously can avoid the excessive resource occupancy over others and achieve a predictable performance.Therefore,existing flowlevel traffic scheduling methods can be borrowed and should be studied to provide better bandwidth or delay guarantee to tenants’traffic.
To provide better bandwidth guarantee and prevent creation of congestion spots resources,scheduling techniques can be accomplished in a centralized or distributed manner.Pulsar [27]resorts to the centralized controller to release some tokens for every VM and only a VM obtaining enough tokens can consume the resources.TDMA [74]uses a centralized controller to collect the demands of different endhosts and allocates different endhosts to use specific network resources exclusively in a specific time slot.FastPass[75]provides a finer-grained traffic scheduling in a centralized method.It controls traffic transmission on a per-packet basis to improve utilization and considers variations in packet size.Flow-Tune [76]performs centralized rate allocation on a per-flowlet basis.
On the other hand,scheduling can be done in a distributed manner.RCP [77]and PDQ [78]use the switch to allocate bandwidth and schedule packets from different flows.Recently,there is a growing trend to develop receiver-driven traffic scheduling methods.Receivers take multiple incoming flows into account and allow one of these flows to transmit at one time.pHost [79]is a representative receiver-driven approach.A receiver in pHost sends a token to the corresponding sender to allow for a packet transmission.The receiver-driven approaches are proven effective in addressing the network congestion and they control the sending rate by manipulating the token releasing rate at receivers.pHost has shown its potential to provide fairness among different tenants and guarantee bandwidth with a congestion-free network core.Similarity,NDP [80],Homa [81]and Express-Pass [82]are also the receiver-driven approaches that can be used to alleviate uncontrolled congestion and provide predictable network performance.
The other way worthy of exploring is to tradeoff redundant resources in the cloud for guaranteed performance.As we know,current cloud network is connected by multiple redundant paths and the whole utilization is rather low,i.e.,99% links are less than 10% loaded [83].Thus,it is reasonable to waste some useless network resources for predictable performance.For example,C3 [84]adaptively selects replica to provide guaranteed delay for a delaysensitive cloud storage task.RC3 [85]combines the usage of priority queues and traffic redundancy.In particular,RC3 runs the same congestion control as normal TCP at highest priority and schedules backup traffic at lower priority to grab free bandwidth aggressively.
The guarantee of network performance can be viewed as finishing a transmission job at or before a promised time point.Therefore,scheduling that guarantees deadline is also critical to provide predictable performance.D2TCP [86],D3 [87],PDQ[78],Tempus [76]and Amoeba [65]are the representative advances that are aware of deadline.They schedule traffic to minimize the deadline miss ratio.D3 and PDQ rely on a centralized rate allocator,e.g.,switch,to explicitly reserve bandwidth for flows.D2TCP,on the other hand,adapts sender’s outstanding window size to accelerate the transmission of flows closing to their deadlines implicitly.Tempus strives to maximize the fraction of flows completed prior to their deadlines while maintaining fairness among flows.Amoeba uses a centralized controller to guarantee inter-datacenter transmission by modeling a novel optimization problem.
VI.CONCLUSION
In this article,we walk through existing efforts in providing network performance guarantee in public cloud datacenters and summarize the common pattern of them.Moreover,we reveal their design principles and discuss their pros and cons.Finally,we pose challenges for current advances and shed light on the opportunities brought by new technologies.
ACKNOWLEDGEMENT
This project is partially supported by the National Natural Science Foundation of China(No.61872401)and Fok Ying Tung Education Foundation(No.171059).

- China Communications的其它文章
- Future 5G-Oriented System for Urban Rail Transit:Opportunities and Challenges
- Multi-Stage Hierarchical Channel Allocation in UAV-Assisted D2D Networks:A Stackelberg Game Approach
- Performance Analysis of Uplink Massive Spatial Modulation MIMO Systems in Transmit-Correlated Rayleigh Channels
- Development of Hybrid ARQ Protocol for the Quantum Communication System on Stabilizer Codes
- Coded Modulation Faster-than-Nyquist Transmission with Precoder and Channel Shortening Optimization
- Analysis and Design of Scheduling Schemes for Wireless Networks with Unsaturated Traffic