
光度鲁棒的违章压线检测系统
2021-02-25 03:37于润润朱凯赢蒋光好
智能计算机与应用 2021年10期
于润润, 朱凯赢, 蒋光好, 吴 益, 周 伟
(上海工程技术大学 电子电气工程学院, 上海 201620)
0 引 言
车辆压线检测是指使用摄像机采集道路视频数据,并针对视频中车辆压线的行为进行检测。 已有的压线检测研究使用的大部分方法为传统检测方法,并且只能适用于固定摄像头的静止场景。 文献[1]使用一定先验知识划定感兴趣区,使用边缘检测和Hough 变换拟合出车道线,用判断车道线区域是否有车辆来判定是否压线。 文献[2]使用连续图像帧间的灰度平均差计算得到黄线残缺信息,并设置残缺长度阈值来判断是否有车辆违章压线。 文献[3]提出了使用黄线区域多角度拍摄,使用小波变换分割算法,对比相邻帧图像对应像素的方法来辨别是否有压线行为。 这类方法应对不同天气,光照等,都会出现较大误差。
实际场景中经常会出现光照变化的情况,比如相机与点光源的相对位置发生了变化,相机不断地调整自身的曝光时间,光源本身的亮度发生变化。针对光照变化的问题,常见的解决方法有2 个方向,分别是:相机参数的标定和调整图像的亮度。 其中,相机参数的标定主要针对相机曝光时间不固定的情况,需要在线标定相机的曝光时间,这种方法常见于机器人自主定位导航中[4-5]。 但这种方法并不适用于基于深度学习构建的方法,因此在本文提出的违章压线检测系统中,本文使用图像亮度调整方法对输入的图像进行预处理,保证连续图像之间亮度始终保持相对一致。 最后,使用空间卷积模块和像素统计的方法对存在遮挡下的车道线分割结果进行补全,优化了车道线分割结果。 本文创新点总结如下:
(1)在基于视觉的深度学习方法中加入图像亮度调整方法,使前后图像的亮度始终保持一致。
(2)使用深度神经网络进行车道线语义分割和车辆目标检测,并设计了感兴趣区域以及像素统计方法用来提高车道线分割在遮挡情况下的鲁棒性。
1 图像亮度调整
对于图像中景物差异不大的情况,适合用直方图匹配法对图像进行亮度调整。 首先计算参考图像的像素直方图H ={h0,h1,…,hl-1},其中l表示图像的灰度值范围,对于本文中所用的灰度图像,l =255。hi表示像素值等于i的像素的数量,其中i∈[0,l -1]。 再对需要调整亮度的图像的所有像素根据各自的像素值大小进行排序。 最后按照参考图像的直方图对排好序的像素进行分组。 为排序后的像素重新分配像素值的过程见图1。 由图1 可知,按从小到大排列的像素中最小的前h0个像素被分为第一组,并对这一组中所有像素分配像素值0,接着再从序列中取后h2个像素分为第二组,并对第二组中的每个像素分配像素值1。 依次类推,排好序的像素最终都会根据参考的像素直方图被分配到相对应所属的组,并被重新分配像素值。
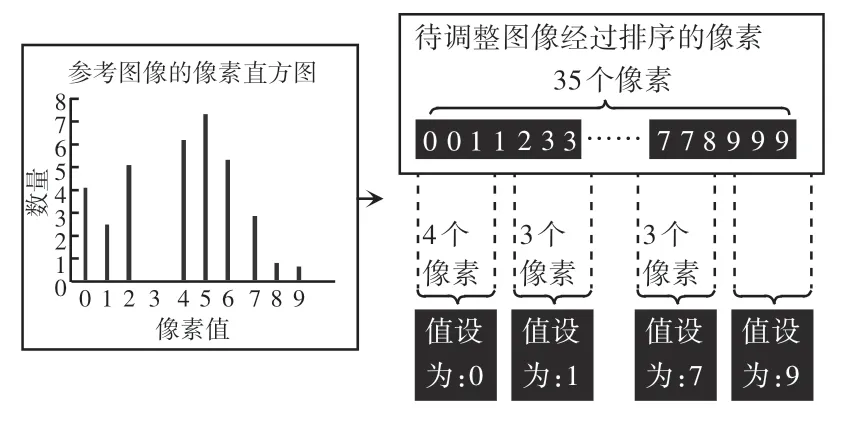
图1 图像像素值重分配过程Fig.1 Image pixel value redistribution process
为了对具有相同像素值的像素进行严格的排序,对于这些像素值相同的像素,去计算这些像素邻域的像素值的均值,再用相对应的均值进行比较。当存在一些像素的邻域均值也相等时,扩大邻域选取范围,再次计算均值进行比较,反复上述比较步骤,直至每个像素都被严格地排序。 基于直方图的图像亮度调整效果如图2 所示。

图2 基于直方图的图像亮度调整效果Fig.2 Image brightness adjustment effect based on histogram
2 压线检测模型
2.1 车辆检测和车道线分割
常用的目标检测算法可分为:一阶段法[6-9]和两阶段法[10-12]。 其中,一阶段法让检测任务集成在一个模型中,模型直接估计目标的检测概率和位置坐标,检测速度更快。 本文选用一阶段法中的YOLOv3[13]来进行车辆目标检测。 在预测过程中不需要候选区域的选择,模型根据提取的高维特征进行目标位置和类别的判定,相比两阶段法、如Faster R-CNN[12]快100 倍。 研究中使用大量车辆数据对预训练好的YOLOv3 模型的参数进行微调,让模型进一步学习车辆数据的特征。
基于深度学习的车道线分割方法中,SCNN[14]使用一种空间卷积层模块,通过对每个特征层上特征点间的信息进行交互加强空间特征的提取。 该方法使用4 种卷积核分别对上、下、左、右四个方向的信息进行提取和融合,使模型加深,但训练预测速度下降,并且多卷积核的累加,有概率丢失重要特征信息,导致车道线分割中细节部分效果差。 针对这个问题,本文设计了更轻量的空间卷积结构,不再使用4 个方向的卷积核,而只使用向下和向左的卷积核进行特征加强。 并且本文提出的方法将该轻量化的空间卷积模块变为一种注意力机制,让模型使用空间卷积模块对提取的特征进行自我校正。 轻量级空间卷积结构如图3 所示。
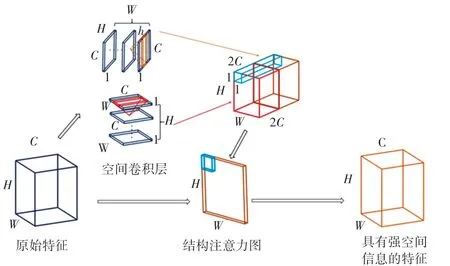
图3 轻量级空间卷积结构Fig.3 Light-weight spatial convolution structure
在空间卷积模块中,大小为H*W*C的输入特征图被分割成为H个1*W*C的特征图,使用1*w*c的卷积核对该特征进行计算,其中则满足w <W,在本次的实验中将w设为9。 同时也对该输入特征从上到下以相似的方式进行卷积运算。 此后,将2 次卷积运算的结果直接堆叠成一组特征图,再进行1*1*2C的卷积运算,提取出结构注意力图。 最后将原始的特征图和得到的结构注意力图进行一一对应地相乘,得到特征的自校正量,并将自校正量累加到原始特征上,得到具有强注意力机制的高维特征。 经过结构注意力机制的空间信息加强,模型中提取的特征就会具有足够的结构信息来帮助提高车道线检测的结果。
2.2 车辆压线判断模型
得到车辆检测图和车道线分割图后,进行车辆压线判断。 如果车辆的特定位置出现在车道线分割结果上,就判断为出现压线行为[15]。 在对车辆进行目标检测时,被检测出的车辆会在图像上有一个二维的矩形框,研究中设定该矩形框的底边的左侧区域和右侧区域为2 个感兴趣区域, 在检测车辆是否压线的同时判断是左转压线、还是右转压线。 并且,为了适用于任何尺寸的输入图像,感兴趣区域的大小设置成输入图像尺寸的20%。
3 实验
为了验证本文设计的系统的有效性,通过车载行车记录仪采集车辆行驶视频,共计12 000张图像,用于实验,为保证实验数据的多样性,额外加入了10 段网络上违章压线视频来扩充测试数据集。
对于车辆压线检测方法,文献[15]使用图像分割技术进行判断。 本文对此方法和本文所提出的方法进行了对比实验。 具体结果见表1。 由于文献[15]使用较深的神经网络模型来分割车道线,所以推断时间更长;又由于在真实场景中,由于光照影响和实际照片成片中存在成像模糊的问题,导致在进行车道线分割时,车道线分割的边缘比较模糊,最终使检测效果下降。 本文采用的图像亮度调整、目标检测和语义分割技术相结合的方法,在复杂的场景下也可以保持目标检测和车道线分割的准确性。 本文设计的方法对于车辆压线检测的准确率达到了96%以上,满足实际需求。 具体压线检测结果如图4 所示。
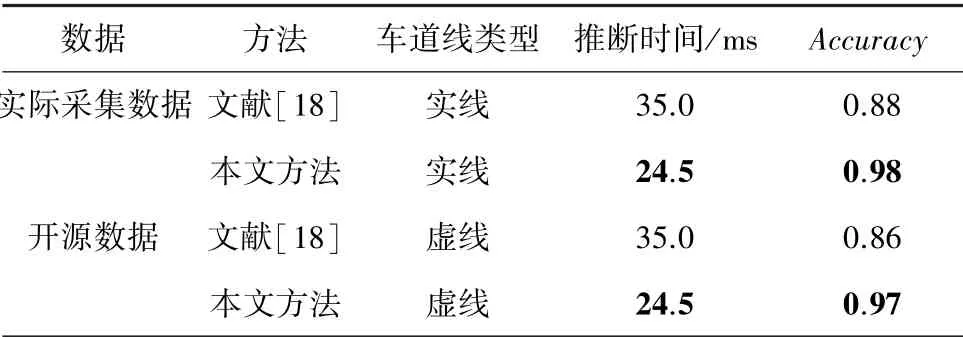
表1 移动端车辆压线检测对比结果Tab.1 Comparison results of vehicle lane-crossing detection at mobile end

图4 压线检测结果Fig.4 Results of vehicle lane-crossing detection
4 结束语
本文提出了一种车辆压线检测系统,利用深度学习算法和传统算法相结合,能够在不同光照条件下检测车辆压线行为。 设计了轻量级的空间卷积模块使得车道线分割网络能够准确地提取到车道线特征。 最终的实验表明本文提出的方法能够在复杂场景中准确地检测出车辆压线行为。 然而,由于车道线检测和车辆检测没有进一步整合到一个模型中,系统的计算效率还没有达到最高。 未来,希望将车辆检测任务和车道线分割任务融合进一个模型中,使得整个系统的训练过程更加容易,计算效率进一步提高。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
汽车实用技术(2022年5期)2022-04-02
红蜻蜓·中年级(2021年6期)2021-09-10
计算机与网络(2021年9期)2021-08-03
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电脑知识与技术·经验技巧(2018年2期)2018-05-21
小天使·六年级语数英综合(2017年5期)2017-05-27
中国新通信(2017年9期)2017-05-27
小天使·四年级语数英综合(2011年4期)2011-06-30
