
一种基于多元数据的假位置筛选算法
2021-02-24 13:03:56张鸿刚刘茜萍
南京邮电大学学报(自然科学版) 2021年6期
张 琳,张鸿刚,刘茜萍
1.南京邮电大学计算机学院、软件学院、网络空间安全学院,江苏 南京 210023
2.南京邮电大学江苏省无线传感网高技术研究重点实验室,江苏 南京 210023
随着智能手机,平板电脑和其他物联网(Internet of Things,IoT)设备的激增,基于位置的服务(Location⁃Based Services,LBS) 已变得越来越流行,并开始改变使用互联网的方式,在社会生活中发挥着极其重要的作用。
然而,LBS为用户提供便利的同时也带来了隐私泄露的风险,用户获取LBS服务后,需要提交位置信息。通过收集用户的位置信息,攻击者可以用获取到的用户位置数据来跟踪用户的移动,或者进一步推知出用户的工作场所、家庭住址、社会关系、身体状况和爱好等私人信息,将其卖给第三方以获取经济利益[1]。
因此,用户在使用LBS时必须保护其位置隐私。近年来,世界各地的研究人员已经提出了许多解决位置隐私保护问题的技术,例如位置扰动和混淆[2-3]、区域匿名[4-6]和假位置[7]。 较为常用的区域匿名技术将一块包含k个用户的匿名区域发送给LBS服务器,使得识别真实用户的概率降低到1/k,然而,这种方法过于依赖可信第三方(Trusted Third Party,TTP),容易造成单点故障,而且大量查询信息也会造成性能瓶颈。而假位置技术则没有这些限制和问题,该技术依赖客户端生成额外的假位置来隐匿用户真实位置,实现了位置匿名,因此很好地弥补了空间匿名技术的各种不足。而现有研究中基于假位置的隐私保护技术在选择假位置时,或者没有充分考虑到背景知识等辅助信息,或者只能工作在特定的环境下,不具备一般通用性,用户的位置隐私也因此很难得到预期的隐私保护效果。
本文充分考虑访问概率、位置语义等地理位置的信息特征,提出了一种基于多元数据的假位置选择 (Multidata⁃based Dummy Location Selection,MDLS)算法。该方案首先基于大顶堆初步筛选出与用户真实位置相似的位置,构成假位置候选集,然后根据候选位置与用户真实位置语义信息的Jaro⁃Winkler相似度筛除掉语义相似的位置,最后综合考虑候选位置与真实位置的物理距离以及语义距离选择假位置。在保证提交的假位置间物理距离尽量分散,以及用户实际位置访问概率相似的同时,还要保证提交的假位置集合尽量分散且位置语义信息尽量丰富。本文使用真实轨迹数据集进行实验,从生成时间、位置熵、物理距离、语义相似度以及识别率5个方面评估了提出的假位置生成方案,并将其与已有的其他算法相比较,结果表明,提出的算法能够快速有效地生成物理分散且语义多样的假位置集合。
1 相关工作
为了解决基于位置服务的隐私问题,国内外学者在先前的工作中已经提出了数种不同的方法。现有的大多数研究都关注于通过位置扰动和混淆[8-10]的方法来保护用户的位置隐私,这些方法通常采用诸如k⁃匿名[11]之类的隐私度量。 Gruteser 等[12]首次将k⁃匿名这一概念引入了位置隐私领域并提出了一种自适应隐匿算法,该算法可以将用户位置隐匿于至少包含k个用户的区域中,使攻击者难以从至少包含k个用户的隐藏区域中识别出真实的用户位置。Bamba等[13]提出了一种网格划分方法,该方法提供了两种算法:自上而下的网格隐藏算法和自下而上的网格算法,可以根据用户的需要进行选择。Xu等[14]证明了k⁃匿名区域的大小对查询结果的一致性有很大影响,为匿名区域划分的研究提供了指导。在此基础上,文献[15-18]提出了多种几何形状的匿名区域构造方法。但是,这些方法过于依赖TTP[19-20],容易造成单点故障,而且大量查询信息也会造成性能瓶颈。
文献[10]和文献[21]中提出的解决方案通过在对等(P2P)用户网络中传输信息来避免通过TTP隐藏位置。然而,移动设备交换信息所需的额外资源花销使得该方案难以实施。为了解决这个问题,Kido等[22]提出在一组虚拟位置中隐藏用户位置的方法。Lu等[23]提出类似的方法,该方法在覆盖用户位置的虚拟圆或网格内生成k-1个虚拟位置,同时考虑隐藏区域的面积。Niu等[24]通过位置熵度量假位置集的不确定性,通过最大化位置熵实现了假位置集的构建。Sun等[25]针对统计攻击,根据隐私需求将地图区域分为不同的保护要求等级,通过概率估计选择虚拟位置,可以防止攻击者通过分析历史记录判断真实位置信息。夏兴有等[26]基于半可信第三方服务的隐私保护系统结构,提出了一种根据用户历史查询概率分布选择假位置的匿名算法,并基于Stackelberg博弈对匿名结果进行优化。然而以上方案都没有考虑到用户位置的语义信息,不能保证构造假位置集的语义多样性。王洁等[27]在构造假位置集时则综合考虑了假位置的语义信息、查询概率以及地理位置,但是该方案需要提前构造好地区的位置语义树,而且只适用于POI类型较多的地区,实现匿名的条件较为苛刻,也很难达到预期的隐私保护效果。
本文将在这些文献的基础上进行改进和完善,提出的算法在充分考虑用户位置背景知识的同时,还可以适用于不同的环境,有效抵御基于位置语义等信息的背景知识攻击,保护用户的位置隐私。
2 预备知识
2.1 系统架构
首先,用户使用移动设备或本地网络基础结构来确定他们的位置,用户的位置信息使用二维坐标(x,y)表示,即用户的纬度和经度。LBS请求由位置信息(x,y)提交请求的日期和时间以及请求内容的查询内容组成。用户将这些信息发送到LBS服务器,最终收到适当的基于位置的响应,完整的过程如图1所示。
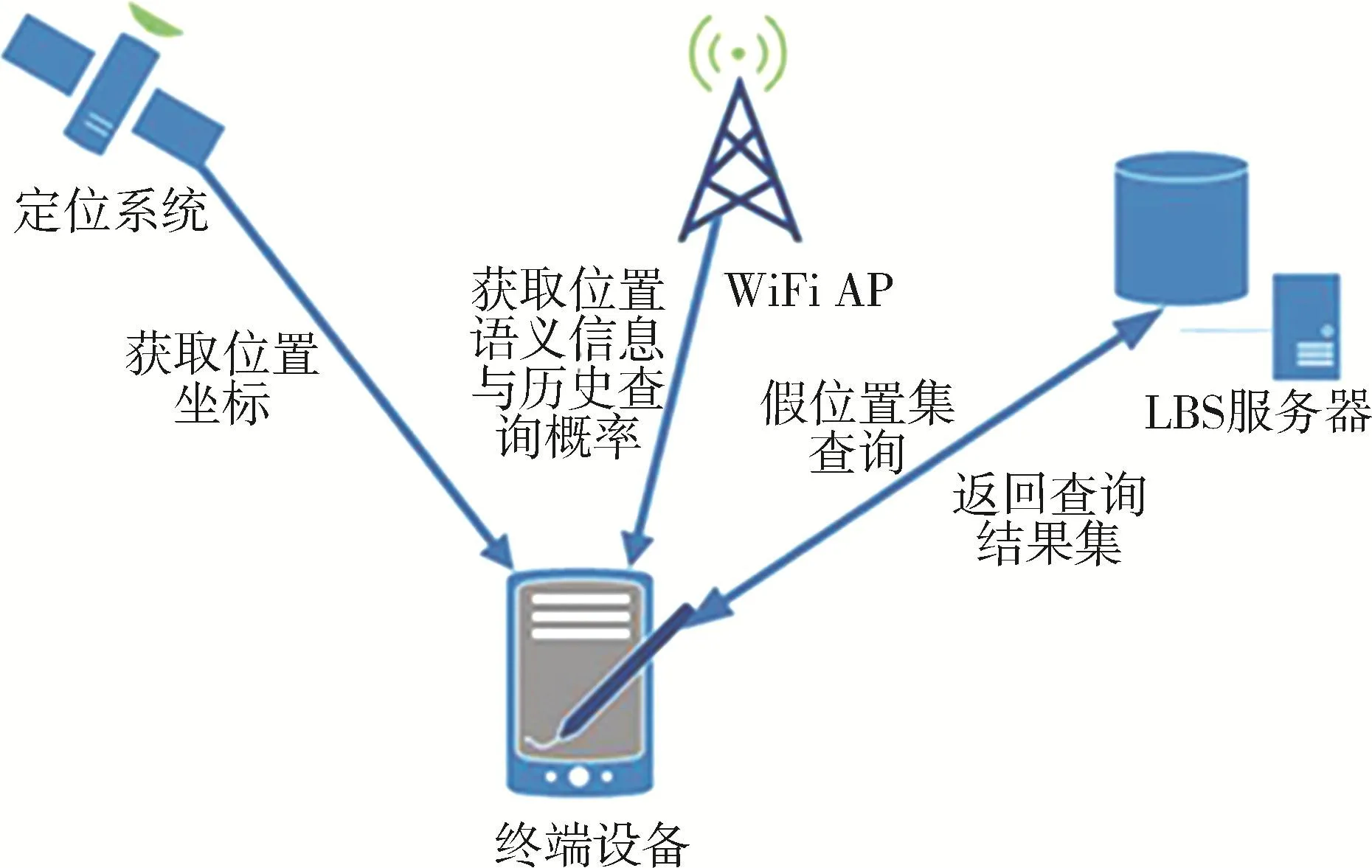
图1 系统架构
基于位置的服务可以通过在LBS请求中使用的通信机制直接向用户分发历史查询概率等背景信息。由于历史查询概率之类的背景信息不会随着时间变化太多,传播之间的间隔可能会很长,因此开销不会很大。在文献[24]的另一种方法中,用户能够通过WiFi接入点(Access Point,AP)彼此共享各自的信息。AP收集他们通信范围内的历史查询概率,然后用户可以下载这些信息并与他们连接的其他接入点共享。本文采用后一种方法,通过AP共享AP覆盖范围内位置的历史查询概率以及语义信息。
2.2 攻击模型
攻击者的目标是获取有关特定用户的敏感信息,按照攻击的类型可将其分为被动攻击者和主动攻击者。被动攻击者可以通过监视和窃听用户之间的无线渠道,获取用户的敏感信息。主动攻击者可能会破坏LBS服务器并获取该服务器存储的所有信息,这些信息包括用户发送的当前查询假位置集以及该用户的历史查询数据。攻击者根据获取的用户发送的假位置集,并结合有关背景知识,可以尝试推断有关用户的其他敏感信息。常见的背景知识攻击方式包括同源攻击、概率分布攻击和位置相似性攻击,这些攻击通过分析用户历史请求数据、查询概率分布以及语义信息,不难推断出用户的真实位置。
2.3 筛选准则
令Rlocal={n×n,Slocal}表示实验中所选取的矩形区域,该区域由n×n个大小相同的网格组成,Slocal表示该区域的所有位置点集合。lreal表示用户当前所处真实位置,dque表示与真实位置历史查询概率之差,dphy表示两位置之间的物理距离,即欧式距离,dsem表示两位置之间的语义距离,本文中则是由两位置之间的Jaro⁃Winkler相似度计算得出。
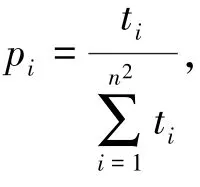
定义 2Jaro⁃Winkler相似度[28]是一种度量两个字符串序列之间编辑距离的指标。给定字符串s1和s2之间的Jaro相似度simj定义为
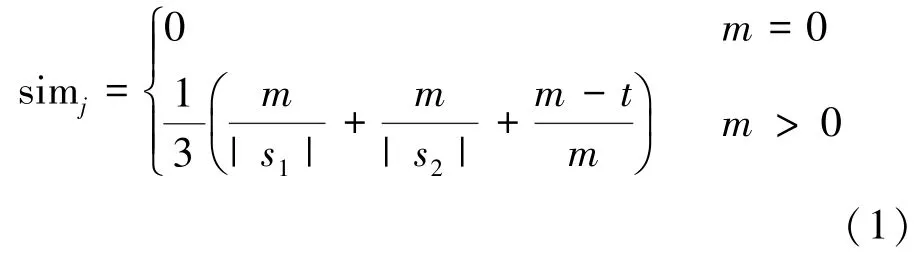
Jaro⁃Winkler相似性进一步考虑了字符串的公共前缀长度对字符串语义的影响,给定字符串s1和s2之间的 Jaro⁃Winkler相似度 simw, 定义为
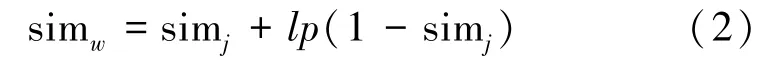
式中,simj为字符串s1和s2之间的Jaro相似度;l为字符串公共前缀长度,最大值为4;p为一个常量因子,不超过0.25,默认为0.1。
2.4 评估指标
定义3 熵H表示系统内部的混乱和不确定程度,可以用来度量包含k个位置的假位置集Sdummy的不确定性,其定义为
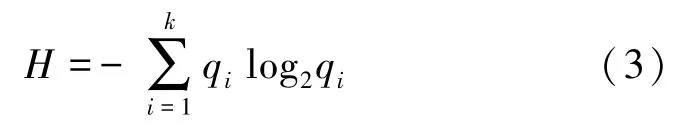
定义4匿名区域面积D表示假位置集中k个位置点中最外层点围成的凸包(凸多边形)面积。凸包的面积可以根据鞋带公式[29]求出,表示为
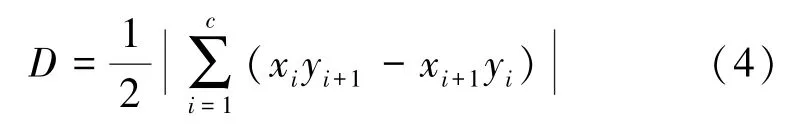
式中,c表示假位置集Sdummy中最外层位置点的个数。假位置集凸包面积示意图见图2。
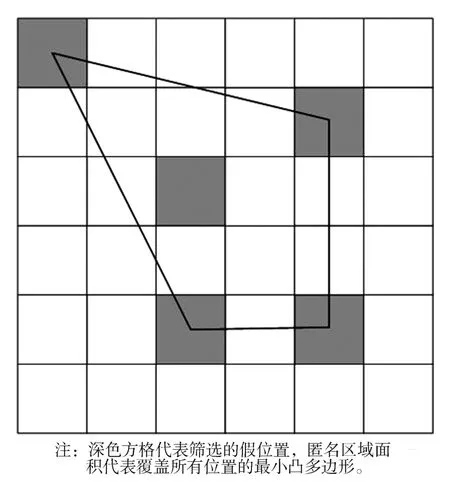
图2 假位置集凸包面积
定义5θ-安全值是用来度量生成假位置集语义差异性的一个指标。其定义为

3 MDLS算法
本文提出了一种基于多元数据的假位置选择(MDLS)算法,该算法根据位置查询概率、位置语义等地理位置的信息特征筛选出与用户真实位置查询概率相近且物理与语义距离较远的位置。MDLS算法采用了边筛选边判断的策略,首先基于大顶堆选择查询与用户真实位置查询概率接近的位置构成假位置候选集,然后分别考虑候选位置与真实位置的物理距离以及语义距离筛选假位置,最后生成一个包含用户真实位置且大小为k的假位置集Sdummy。算法1给出了MDLS算法的伪代码表示。
算法1MDLS算法


该算法除需要输入选取区域地理信息和用户所处位置外,还需要提前定义好隐私需求相关的参数匿名度k以及比例系数r。 匿名度k表示生成结果集Sdummy的大小,k越大,攻击者越难从结果集Sdummy中确定用户的真实位置,隐私保护效果也越好;比例系数r用来调整综合距离中语义距离的占比,r越大,语义距离在选择假位置时越重要。
1~15步构建了一个大顶堆Sc,筛选出与用户真实位置查询概率差距最小的4k个位置,作为候选集。首先,2~8步依次将位置集合Slocal的前4k个位置加入候选集Sc,添加完后从最底层的双亲节点开始根据每个位置的dque自上而下地进行堆调整,直到根节点结束,至此,初始大顶堆就构建完成了。10~13步将小于堆顶位置dque的待添加位置与堆顶位置进行替换,并从根节点开始自上而下地堆调整。
17~34步综合考虑候选位置之间的物理距离和语义距离,记录并筛选出分散且多样的假位置。最后返回结果集Sdummy。 18~25步分别算出lcandi与用户所处位置lreal,最近添加位置llast以及随机候选位置lrand之间的物理距离dphy,语义距离dsem以及综合距离并使用dsmin,dmin记录dsem和d的最小值。
26~32步分别使用lbest和lworst表示最佳候选位置以及最差候选位置,lworst是上文记录的最小语义距离dsmin对应的位置,该位置与假位置集中用户真实位置以及其他位置的语义距离最近,容易被攻击者获知位置语义信息,需要从候选集中删除;lbest则是上文记录的最小综合距离dmin对应的位置,该位置与假位置集中用户真实位置以及其他位置的综合距离最远,将其加入假位置集Sdummy中,能使集合中的位置最为分散且多样。经过k轮筛选后,返回假位置集Sdummy。
其中,两个位置之间的语义距离dsem可以用位置之间的 Jaro⁃Winkler距离来计算和表示。由于Jaro⁃Winkler距离既考虑了一定范围内的匹配字符个数,又考虑了字符串的公共前缀长度对字符串语义的影响,能够仅从地名较为准确地度量不同位置的语义距离,同时又避免了在POI较少的环境下匿名失败的可能。位置语义距离范围为[0,1],其伪代码如算法2所示。
算法2getJWDistance算法


由式(1,2)可知,决定两字符串语义距离大小的是匹配窗口内的匹配字符数matches、匹配字符换位数transposition以及匹配前缀长度prefix,对3个变量的计数操作分别对应算法2的12~21步、25~35步以及36~41步。
3.1 复杂度分析
算法首先构造了一个大小为4k的大顶堆,用来筛选与用户真实位置历史查询概率最为相近的4k个位置。假设选取区域包含n个位置,在遍历这些位置的同时,还需要调整堆,而调整堆的时间复杂度为O(logk),因此,通过最大堆筛选候选集的复杂度为O(nlogk)。然后将用户真实位置lreal加入结果集,遍历大小为4k的候选集,综合考虑候选位置之间的物理距离和语义距离,记录并筛选假位置。因为n≫k,所以后面从大小为4k的候选集筛选假位置的时间可以忽略不计。因此,该算法的时间复杂度为O(nlogk)。由于本算法中间只构建了大小为4k的候选集,因此,该算法空间复杂度为O(k)。
3.2 安全度分析
当算法生成的假位置集中在一小块区域,假位置构成的匿名区域面积也相应地变小,使得用户的真实位置更难隐藏。此时,k匿名只能满足数量上的要求,而不能真正达到匿名的效果。本文提出的算法尽可能选择与用户真实位置距离较远的位置加入假位置集,使得生成的假位置尽量分散,从而使攻击者难以确定用户的真实位置。
类似地,当算法生成的假位置集只含有一两种语义信息,即使不能确定用户所处的真实位置,用户所处位置的语义信息也很容易推知,假位置集中单一的位置类型同样也难以保证用户的位置隐私安全。本文提出的算法筛除了与用户真实位置的语义信息几乎相同的位置,从而保证了假位置集语义信息的多样,使得攻击者难以确定用户所处位置的语义信息。
另外,本算法生成假位置的查询概率几乎相同,分布均匀,每个位置能被区分于其他位置的概率均为1/k,使得攻击者难以从假位置的概率分布上推测出用户真实位置。而且,即使攻击者已经直接得知本文的算法,结果集的随机性也使攻击者难以确定用户真实位置。
4 实验结果与分析
4.1 实验设置
实验使用真实数据集Geolife[30]来模拟地图不同区域内的用户历史查询概率,该数据集是微软亚洲研究院在2007年4月到2012年8月期间记录的轨迹数据,包含了182名用户这5年内的17 621条GPS轨迹。
图3中的热图(heatmap)显示了Geolife数据集大部分的轨迹数据,其中较亮的区域代表人口密度相对较高的地区。实验选取的模拟区域的纬度坐标范围为 39.95°N至 40.00°N,经度坐标范围为116.30°E,至116.35°E,位于北京五环内的一个面积约为23.7平方千米的方形区域(图3方框区域)。该区域被划分为200×200 的网格(c1,c2,…,c40000),分为100组,每个网格用每个网格中心的(纬度,经度)坐标表示。数据集中每名用户的轨迹数据都包含位置点的纬度、经度和时间数据,将每条轨迹数据都统计到最近的网格,计算用户在每个网格中花费的时间,从而得到所有网格的历史查询概率。此外,由于Geolife数据集并没有提供位置相关的语义信息,本实验还通过百度地图API获取所有网格的语义信息。
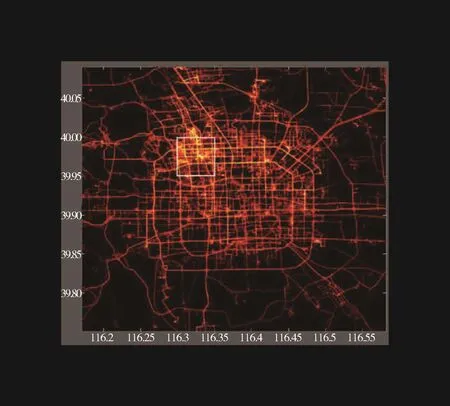
图3 Geolife轨迹数据热图
实验采用 Java语言编程实现,运行环境为Windows 10操作系统,2.30 GHz Intel Core i5处理器,8 GB内存。实验默认参数配置如表1所示。
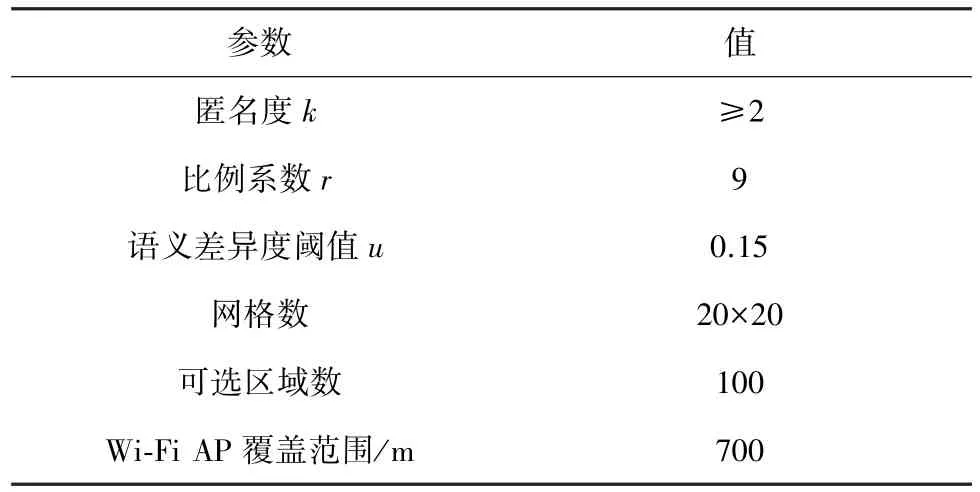
表1 实验默认参数配置
4.2 结果分析
实验从假位置集生成效率、物理分散性、语义多样性、不确定性以及识别率这5个方面评估本文提出的算法,并将其与同样使用假位置技术的DLS算法[24]、enhanced⁃DLS 算法[25]、MMDS 算法[27]在这 5个方面的表现进行比较。
4.2.1 生成效率
从图4(a)可以看出,随着k值的增加,4种算法生成假位置的时间都呈现缓慢上升的总体趋势,而MMDS算法和本文提出的MDLS算法生成假位置集的花时却远小于DLS和enhanced⁃DLS算法。这主要是因为后两种算法都需要对区域内每个位置的查询概率进行排序,而另外两个算法并不是通过排序筛选与用户真实位置查询概率相近的位置:MMDS算法定义了查询概率距离,并作为选择假位置公式的分母;本文提出的MDLS算法则是通过定义的用户位置查询概率差距小顶堆筛选出概率相近的位置,用空间换时间,在充分考虑背景知识的同时大大提升了假位置集生成的效率。
作为图4(a)的补充,图 4(b)展示了当k值进一步增加时,各个算法生成假位置时间不同的上升趋势。当k≥10时,由于POI类别的数目有限,MMDS算法能够匿名成功的几率特别低,因此图4(b)只对比了另外3种算法生成假位置集的时间。
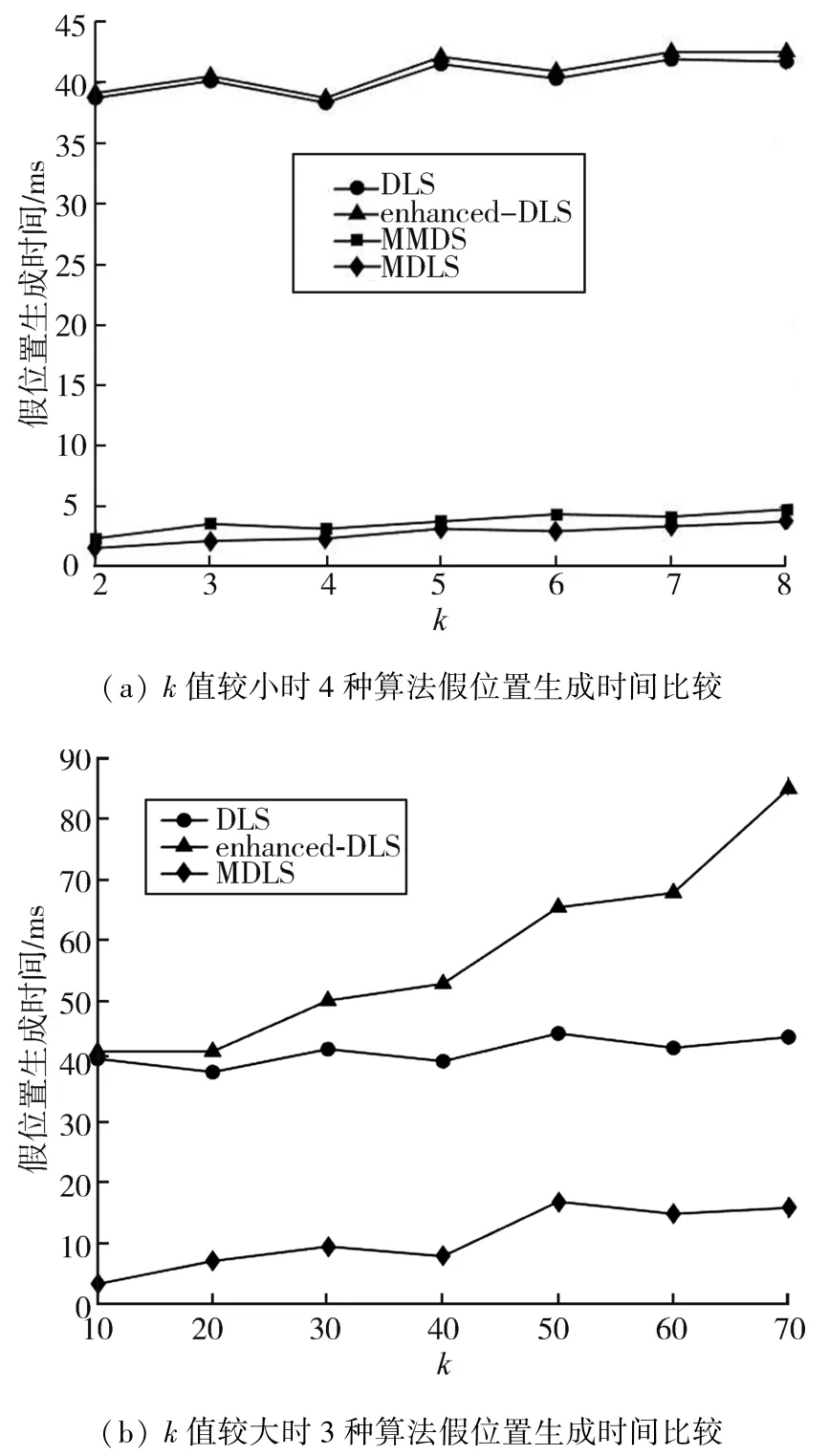
图4 假位置生成时间
从图 4(b)可以看出,DLS、enhanced⁃DLS 以及本文提出的MDLS算法呈现不同幅度的上升趋势:DLS算法的上升趋势最为平缓,几乎没有变化;enhanced⁃DLS算法的上升幅度最大,前后相差40 ms之多;本文提出的MDLS算法上升速度则介于两者之间。DLS算法生成假位置集的花时主要在于排序,之后选择假位置只需要花费常数级的时间,所以k值的增加对于DLS算法生成假位置集几乎没有影响;enhanced⁃DLS算法除了排序花时,因为考虑到覆盖面积的大小,需要多次反复遍历候选集和结果集来计算权值,因此k值的增加对于enhanced⁃DLS算法生成假位置集影响较大;而本文提出的MDLS算法采用了边选择边判断的策略,只需要遍历k次候选集按照公式筛选假位置,所以生成假位置的涨幅较为缓慢。
4.2.2 物理分散性
评估算法生成假位置集的物理分散程度可以从两个方面入手:匿名区域面积和最小距离。生成假位置间的最小距离和构成的匿名区域面积越大,表示生成的假位置分布越均匀分散。
图5是4种算法生成结果集中假位置间的最小距离,可以发现,这4种算法都是随着k值增加而逐渐下降并趋于平缓。当k≤4时,本文提出的MDLS算法生成假位置间的最小距离明显大于DLS和enhanced⁃DLS算法,前后者的区别主要在于除了最小距离是否还考虑了语义信息。MDLS算法和MMDS算法都综合考虑了位置间的物理距离和语义距离,这说明保证位置语义的多样性也能在一定程度上使得生成的假位置更加分散。
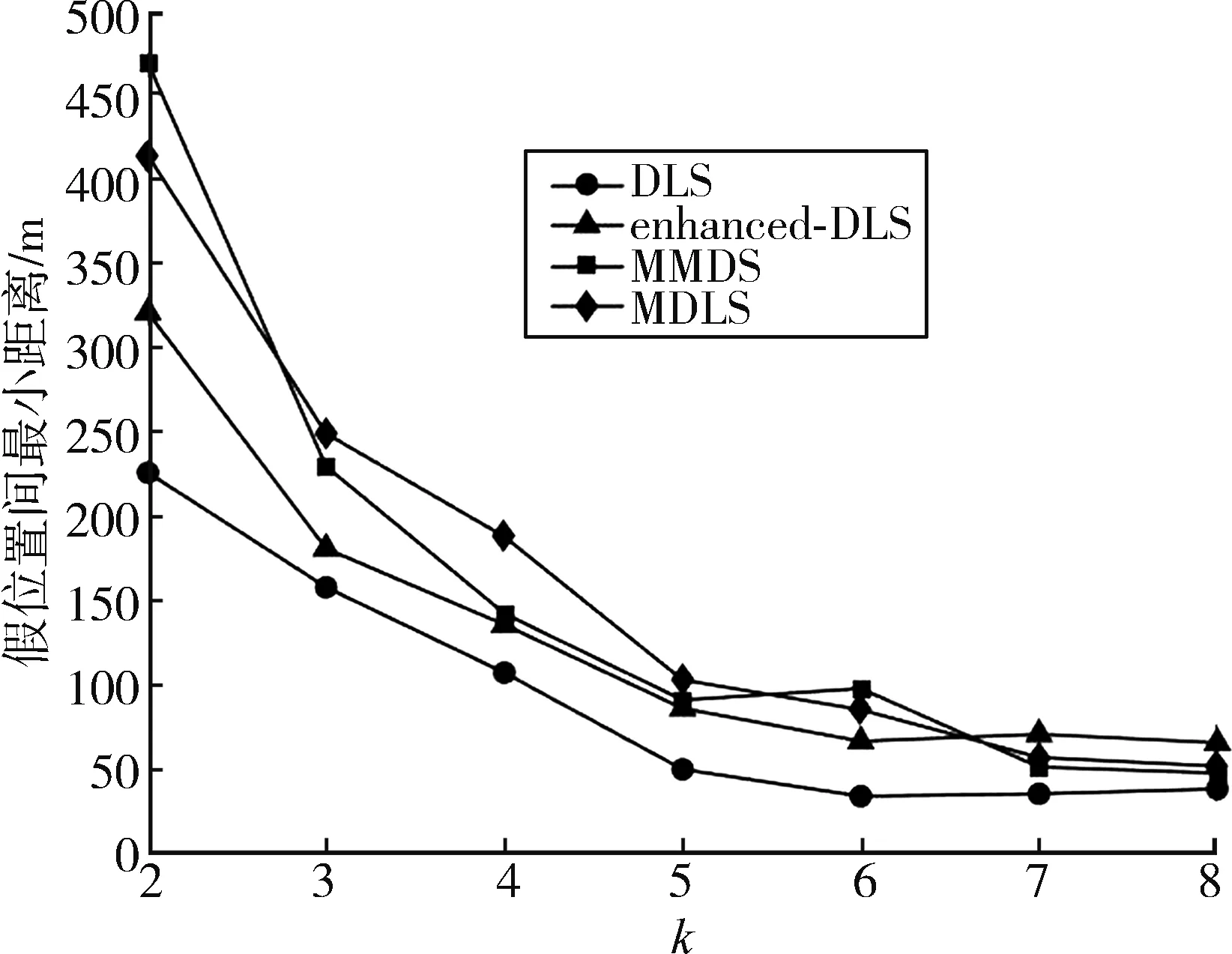
图5 假位置间最小距离
不过随着k值进一步增加,4种算法生成假位置间的最小距离的差距也越来越小。这时最小距离也难以评估这些算法生成假位置分散程度,而匿名区域面积依然能很清楚地比较出4种算法生成假位置的分散程度差异。如图6所示,当k>5时 MMDS算法假位置集构成的匿名区域面积远远大于其他算法,这主要因为该算法首先需要保证生成的假位置的兴趣点POI类别不同,这也保证了位置之间的距离,而其他3个算法都优先考虑了位置的历史查询概率。不过,与另外两种算法相比,本文提出算法生成的假位置依然具有较好的物理分散性。
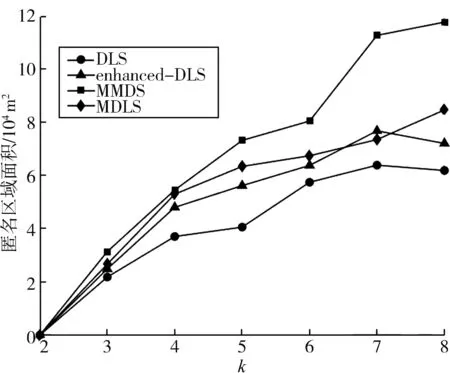
图6 覆盖假位置的匿名区域面积
4.2.3 语义多样性
实验采用θ-安全值评估算法生成假位置的语义多样性,θ-安全值越大就表示生成假位置集的语义信息越丰富多样,攻击者越难确定用户所处位置的语义信息。
从图7可以看出,MMDS算法生成假位置的语义信息最为丰富多样,θ-安全值都在0.9以上,接近于1。而本文提出的MDLS算法同样考虑了位置的语义信息,但θ-安全值却处于0.8~0.9之间,稍低于MMDS算法,主要原因在于两种算法优先考虑的因素不同。MMDS算法首先就筛除了POI类型接近的位置,在此基础上再进行选择,从而保证了位置语义的多样性。但随着k值不断增加,由于POI类型有限,MMDS算法匿名失败的几率越来越大,最终根本无法进行匿名。DLS和enhanced⁃DLS算法都没有考虑过位置的语义信息,θ-安全值在0.7左右,远低于前两种算法。而enhanced⁃DLS算法的θ-安全值略高于DLS算法,DLS算法和enhanced⁃DLS算法的主要区别在于enhanced⁃DLS算法额外考虑了匿名面积这一因素,因此,可以发现物理分散性和语义多样性呈正相关。
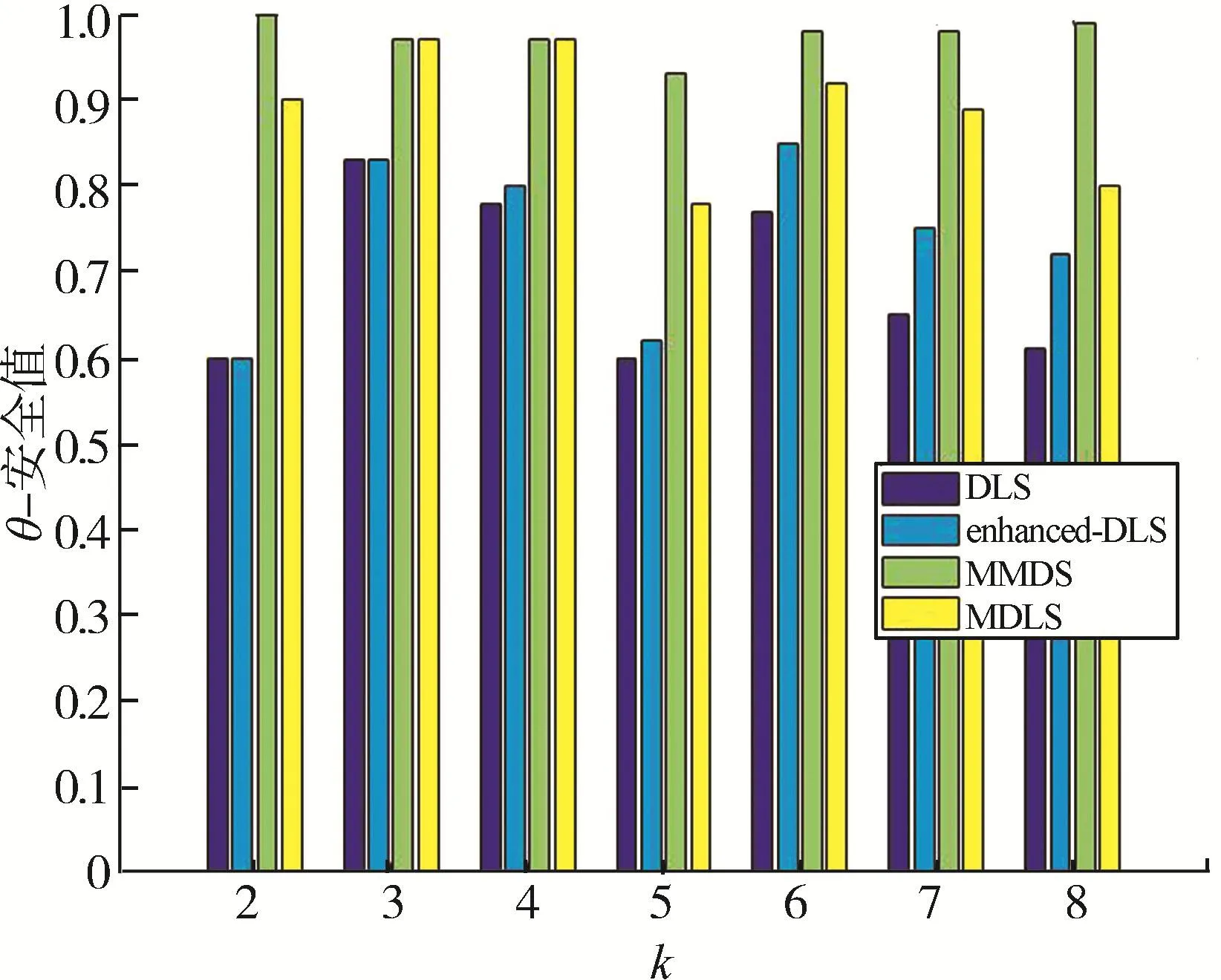
图7 假位置集的θ-安全值
4.2.4 不确定性
熵代表了系统内部的混乱程度,而位置熵是由位置集合内位置的历史查询概率分布决定的,可以用来度量用户所处位置的不确定性。位置熵越大,位置集合内位置的历史查询概率越接近,用户所处位置就越难以确定。
4种算法生成假位置集在不同k值下的位置熵如图8所示,除了MMDS算法,其他3种算法的位置熵都随着k增加而稳步上升,而且都接近位置熵的最大值log2k。 一方面,因为 DLS、enhanced⁃DLS以及本文提出的MDLS算法都是优先将位置历史查询概率相近的位置筛选出再选择,另一方面,MMDS算法优先筛除POI类型相近的位置,随着k增加反而更难找到与用户真实位置历史查询概率类似的位置。
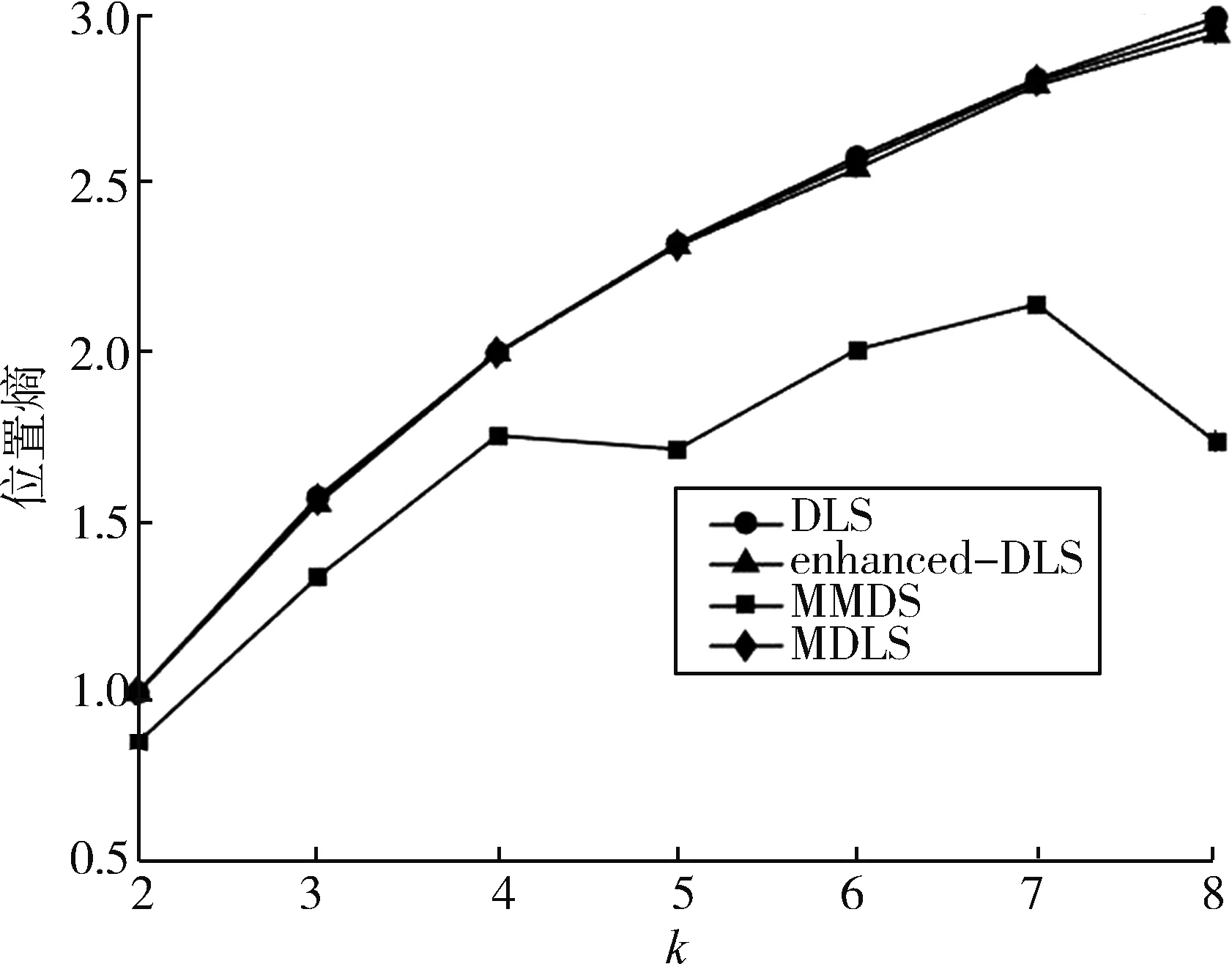
图8 假位置集位置熵
通过以上实验可以发现,本文提出的MDLS算法能够快速生成物理分散且语义多样的假位置集,从而有效地防范攻击者的各种背景知识攻击,保护用户的位置隐私安全,使其获得更安全更优质的服务。
4.2.5 识别率
虽然 DLS、enhanced⁃DLS以及本文提出的MDLS算法由于优先考虑位置的历史查询概率都有着接近最大值的熵,攻击者很难仅仅通过位置的历史查询概率推知用户的真实位置,但是一旦攻击者知道生成假位置集所用的算法,攻击者就能针对算法的特点进行推断,使得用户真实位置的识别率大大提升。文献[31]通过分析DLS算法,设计了一种专门针对攻击的算法ADLS。
ADLS算法通过反复遍历用户提交的假位置集和本地地图的位置集,根据位置的历史查询概率查找本地地图位置集中与假位置构成集合熵最大的组合,最后根据式(6),(7)选出与用户提交假位置集最为接近的组合假位置,推断出用户的真实位置。
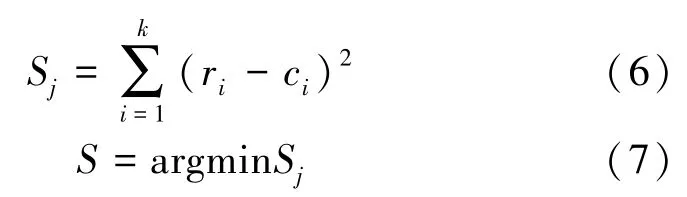
式中,ri表示用户提交的假位置,ci表示ADLS算法预测的假位置,根据与提交假位置集差距最小的集合确定用户真实位置。
由于MMDS算法在k值较大时匿名成功的几率特别低,图9只比较了ADLS算法对DLS、enhanced⁃DLS以及MDLS 3种算法不同的识别率:3种算法被ADLS识别的概率都随着k的增加而减小,其中DLS算法的识别率最高,enhanced⁃DLS算法和本文提出的MDLS算法的识别率则低了不少,这是因为enhanced⁃DLS算法除了位置的历史查询概率外还考虑了其他因素,并随机选择比较,使得ADLS算法更难通过生成的假位置集确定用户真实位置。
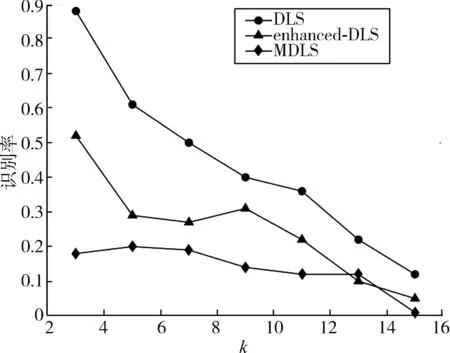
图9 假位置集识别率
5 结束语
针对当前大多数假位置隐私保护方案没有充分考虑攻击者具有的背景知识这一问题,本文综合考虑位置的查询概率、语义信息以及物理分布,提出了一种基于多元数据的位置隐私保护方案MDLS。首先基于大顶堆选择查询与用户真实位置查询概率接近的位置构成假位置候选集;然后通过计算候选位置与真实位置的物理距离以及语义距离筛选出物理分散且语义多样的假位置;最后生成一个包含用户真实位置且大小为k的假位置集。实验分别从假位置集生成效率、物理分散性、语义多样性、不确定性以及识别率这5个维度将本文提出的算法与另外几种位置隐私保护方案进行比较,证明了本文提出算法不仅能快速生成假位置集,而且能在很大程度上满足用户的位置隐私保护需求。然而本文只研究了快照位置隐私保护,没有考虑时间这一因素,而短时间内用户位置具有相关性,因此关于连续时间的位置隐私保护还有待进一步研究。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
自动化学报(2021年8期)2021-09-28 07:20:18
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
开放教育研究(2020年2期)2020-03-31 01:54:14
爱你(2018年16期)2018-06-21 03:28:44
现代语文(2016年21期)2016-05-25 13:13:44
指挥与控制学报(2015年4期)2015-11-01 10:09:34
大连民族大学学报(2015年2期)2015-02-27 08:28:11
