
基于特征多样化的恶意域名检测
2021-02-24 13:04刘善玲祁正华
南京邮电大学学报(自然科学版) 2021年6期
刘善玲,祁正华
(南京邮电大学计算机学院、软件学院、网络空间安全学院,江苏 南京 210023)
域名系统(Domain Name System,DNS)作为互联网的重要组成部分,实现域名和IP地址的相互映射,是各个信息系统协调与合作的中枢神经。近年来,随着互联网的快速发展,网络对全球组织和个人日常活动的影响呈指数增长。与此同时,由于域名协议本身安全运行机制并不健全,域名系统在提供正常的网络服务外,也被网络攻击者利用,进行违法违纪活动(如垃圾邮件、僵尸网络、钓鱼软件等),通过分析发现许多移动通信终端、PC机和服务器被植入了木马病毒后会包含大量恶意域名链接。《2020年我国互联网网络安全态势》报告[1]指出,全年捕获恶意程序样本数量超过4 200万个,日均传播次数达482万余次,控制我国境内约3.3万台IPv6地址主机。目前互联网中较为常见的利用DNS产生恶意域名的异常行为是DGA(Domain Generation Algorithms)域名和DNS隐蔽通道。网络钓鱼者可以利用多种技术使网络站点看起来合法,它诱骗受害者点击这些链接从而获取受害者的信息或控制受害者的计算机。
随着恶意域名造成的经济损失越来越大,人们对于网络安全的意识也逐渐增强,各种检测方法层出不穷。现有的检测方法主要存在以下不足:一,采用复杂特征提取的办法,并且结合多种检测系统进行多重检测。虽然在检测准确率上有很好的效果,但在系统开销、检测速度上花费过大;二,对域名类型的检测,目前大多的检测方法主要是针对DGA域名的检测,当产生新的域名类型时,检测性能不佳。本文的主要贡献如下:
(1)在进行域名特征提取前,对域名进行分词格式化处理,可以增加数据集的通用性,提高模型的泛化能力,同时简化后续域名特征提取过程。本文提取的特征和现有的复杂特征组合(时间向量、地理位置向量、注册信息等)相比,在达到相同的检测效果下,需要提取的特征数量有一定减少,同时提高了特征提取速度。
(2)由DGA算法生成的恶意域名,与正常域名在形式上有很大的差异,因此网络攻击者可以利用这一特征来逃避检测。针对现有检测方法在域名类型上的单一性,本文通过构建不同时间段域名访问量的变化发现,常规域名和恶意域名在各个时间段访问量存在很大的差异。网络攻击者在利用DGA算法生成恶意域名时,很容易规避常规特征,但访问量是不可规避的。
1 相关研究
针对恶意域名的检测,最原始的方法是基于黑名单检测,Kührer等[2]发现所有公共黑名单的联合覆盖率不到20%,提出一种基于图的方法来识别黑名单中的漏洞。由于黑名单方法存在的缺陷,提出了一种基于域名特征的检测方法[3-4],依赖于 url词汇特征进行提取,张维维等[5]通过挖掘域名字面蕴含的词素(词缀、拼音及缩写)特征,能够快速锁定域名。Schiavoni等[6]提出了一种名为Phoenix的检测机制,使用字符串和基于IP的特征对域名家族进行分类。后续的研究中发现域名的主机中也包含着许多隐藏信息[7-8]。 袁福祥等[9]通过挖掘域名的历史信息例如DNS注册信息、whois更新信息、被动DNS数据等构造合法域名与恶意域名的数据差异,进行域名的全局特征提取。目前最常用的检测方法是基于模型的检测,除了机器学习的检测方法[10-12]外,也可以利用深度学习方法[13-14]进行检测。
2 系统设计
本文在分析多种域名检测算法的基础上,从域名字符和访问量两方面提取有用特征,设计一种基于特征多样化的域名检测方法。本文方法主要分为4个模块:数据集获取、数据预处理、特征提取和分类器模型训练。算法框架如图1所示。

图1 算法框架
2.1 数据预处理
首先将获取到的域名进行分词格式化处理,处理后的域名如表1所示。通过这步操作,在特征提取的过程中可以将原本时间复杂度为O(m∗n)的字符串比较问题,转化为时间复杂度为O(n)的匹配问题,同时可以达到一个扩充模型通用性的目的。域名作为一种无空格间隔的特殊字符串,既具有英文文本的特征,又具有中文文本的特征,分词时需要考虑到域名单词间的无间隔性,也要考虑到词语的连贯性。本文对字符串的分词采用双向最大匹配算法和概率模型方法。双向最大匹配算法操作如下:
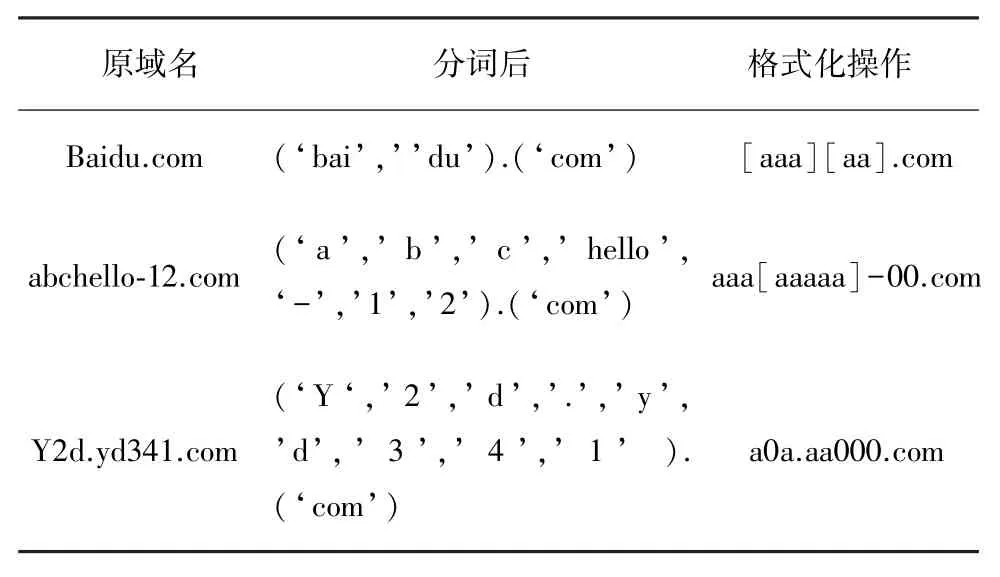
表1 分词处理结果
(1)给定需要分割的字符串S;
(2)先对字符串S进行正向最大匹配,得到分词结果PC;
(3)再对字符串S进行反向最大匹配,得到分词结果RC;
(4)利用概率模型函数Fit分别计算PC和RC的概率;
(5)选择概率大的作为分词输出结果。
概率模型函数计算方法为
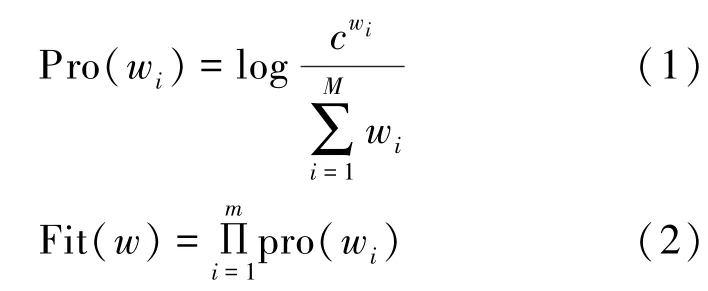
式中,M为词集大小,cwi为词wi的数目。然后,针对分词序列如w=w1,w2,…,wm,使用拟合函数Fit计算分析结果。分词之后进行格式化操作,将所有字母用“a”替代,所有数字用“0”替代。在2.2节特征提取过程计算域名长度时,只需匹配“[”、“]”即可。
2.2 特征提取
2.2.1 基本字符特征
(1)域名长度
由于IP地址不易被记住,为了访问方便,引入了域名。常规域名为了便于记忆,注册时选择为短域名,一般情况下由一个或两个英文单词或者中文拼音组成,例如google.com,baidu.com。然而攻击者在利用算法生成恶意域名时,域名的长度通常设置为16位、32位等,长度一般较长,如 apple⁃mac911.onlinesoftware.info。因此可以基于域名长度度量构建域名长度特征。如图2所示,正常域名长度大部分在5~10之内,恶意域名主要集中图形的后半部分,长度值较大。
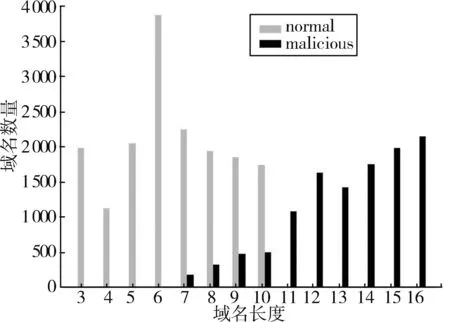
图2 域名长度分布特征
(2)数字个数
恶意域名通常由域名生成算法生成,作为恶意软件的域名存在,域名内容一般不具有可记忆性,此外,恶意域名一般会在正常域名之后加入数字来误导用户,因此数字的随机出现也是恶意域名的一个重要特征。正常域名极少包含数字或者包含很少的数字。分布特征如图3所示。
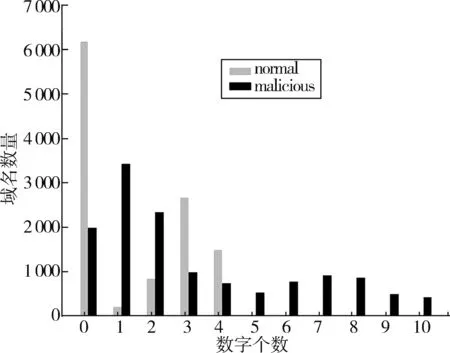
图3 域名中数字分布特征
(3) 随机性
随机性作为域名的基本特征,代表了域名的混乱程度。DGA算法利用随机字符串生成恶意域名,在数学上表示为不确定度,在这里可以用香农熵公式H(X)来表示不确定度。字符随机性越大,熵值越高,是恶意域名的可能性就更大。
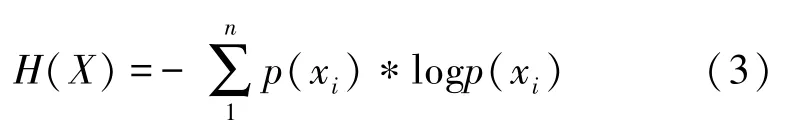
式中,X为域名;xi为X中的某一个字符,p(xi)为该字符出现的概率。分布特征如图4所示。
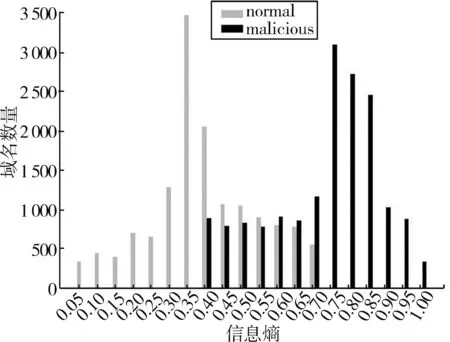
图4 信息熵分布图
(4)最长有意义字符串长度
常规域名通常具有一定的代表意义,可能是相应的英文单词,或者中文拼音,因此正常域名的有意义字符串长度值偏大,作为随机生成的恶意域名,算法在生成时,一般未考虑到域名的可读性以及域名代表的意义,通常由英文字母和数字混合在一起组成,因此最长有意义字符串长度值偏小。分布特征如图5所示。
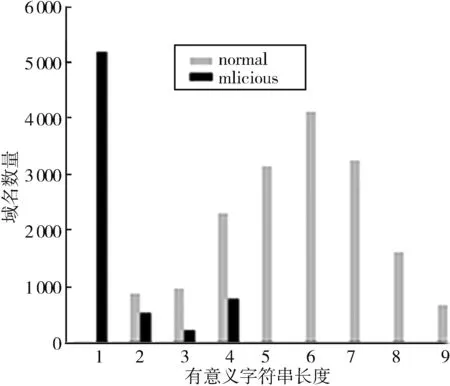
图5 最长有意义字符串长度分布
2.2.2 访问特征
传统检测方法基于人工特征的提取,在检测方法不断更新发展的同时,网络攻击者也发现通过分析域名字符特征就可以轻易辨别出恶意域名,随着恶意域名生成算法的不断更新,攻击者在生成恶意域名时很容易规避这些特征,生成一类新的家族域名。
本文从域名解析访问特征角度出发,对域名访问量特征(request_cnt)计算均值、方差最大值、最小值等数值统计特征,但因为均值不能描述数据的离散程度,当数据分布不均时,采用均值特征不能展示真实的数据分布情况,因此根据时间段划分,再对request_cnt做分位数特征提取,刻画不同时间段的变化情况,减小异常值对模型的干扰。因此访问量不仅可以作为识别DGA域名的一个重要特征,同样也可以作为识别生存时间较长恶意域名的特征,主要因为访问量是无法规避的特征。图6为各个时间段域名的访问情况,可以看出常规域名因为生存周期长,且有访问意义,一般都是访问量较大,并且呈现出白天多晚上少的特征。而恶意域名,生存周期较短,访问量大幅减少,并且考虑到隐蔽性等原因,呈现出聚集于晚上访问的特征。

图6 访问量分布图
2.3 分类器模型训练
本文方法使用黑白样本集,将域名数据分为训练集21 000个和测试集100 000个(具体分布如表2所示),训练集的数据均是由真实网络数据提供,其中测试集的数据集一部分来源为从未公开过的DGA域名和非DGA域名。首先从域名数据集中提取相关特征,再构造域名访问量分位数特征,按域名编号顺序合并成二维向量。
本文采用随机森林分类算法,训练过程采用有放回的样本选取,每次训练生成的决策树都不同,可以避免模型过拟合的问题。同时随机森林算法实现简单,对噪声数据不敏感,本文使用随机森林算法利用训练集数据训练模型,达到模型检测最优效果后,利用训练好的模型对测试集数据进行分类检测,观察分类结果。
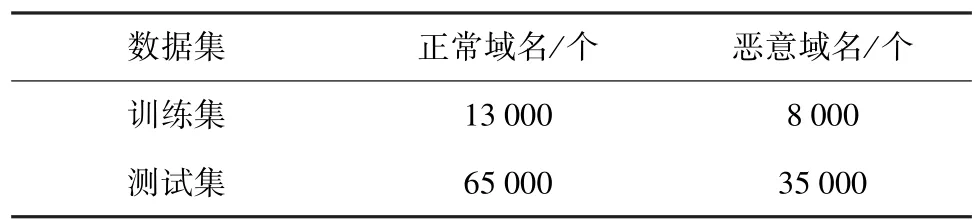
表2 数据集
3 实验与分析
3.1 性能评估
为验证本文恶意域名检测算法的有效性,将本实验所用到的域名作为对比实验的数据集,在相同的实验环境下根据条件分别复现检测恶意域名经典方法、文献[15]Exposure方法和文献[16]基于域名词法特征的恶意域名检测算法。对比实验结果如图7所示。文献[15]在原文中的准确率可以达到98%,使用相同的数据集,在本实验当中检测效果有所下降,说明该方法存在一定的稳定性问题。而文献[16]单纯基于词法特征的检测算法,在准确率、召回率等方面,检测效果远远不如本文,而在加入本文的域名处理和访问特征之后,准确率提高了7.9%。说明本文方法具有良好的稳定性与准确性。
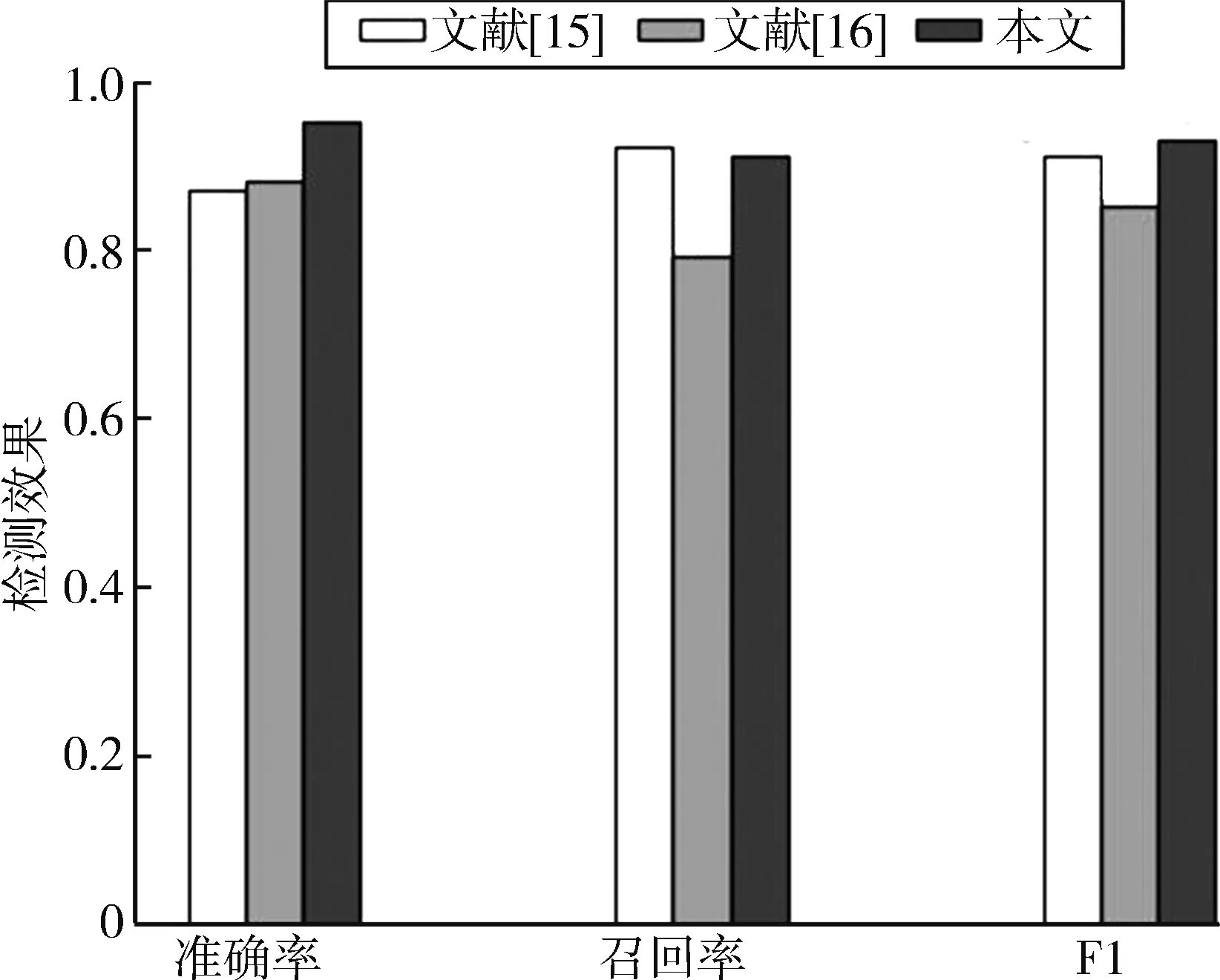
图7 不同方法的检测效果
3.2 资源开销
恶意域名的检测,除保证准确率外,控制资源开销也十分重要。本文从检测时间、内存开销两方面与文献[7]采用的基于聚类和分类的检测思路,利用SVM分类器过滤恶意域名,以及文献[17]采用的基于DNS流量的检测方法进行比较,使用相同数量的实验数集来验证本文方法的性能问题。分析结果如表3所示。从表3可以看出,与文献[7]、文献[17]相比,本文算法在检测时间与内存开销方面都有良好的实验效果,导致这一结果的主要原因是文献[7]使用组合分类方法,先使用聚类关联疑似恶意域名之后,再利用分类器检测聚类集合的域名,文献[17]虽然有着较高的准确率,但是在检测方法上较为复杂,先采用关联匹配方法,再提取特征,随后采用深度学习、机器学习等方法进行检测,开销较大。本文在检测方法上只需提取特征,训练随机森林模型即可。同时,在提取特征之前对域名做了相关处理,从根本上降低了时间复杂度,在特征提取方面多次实验,在保证实验效果的情况下,选择了系统开销最小、提取时间最短的相关特征进行模型训练。结合对比实验的检测结果,本文的检测准确率在现有方法中虽然不是最高,但综合考虑具有一定的优势。
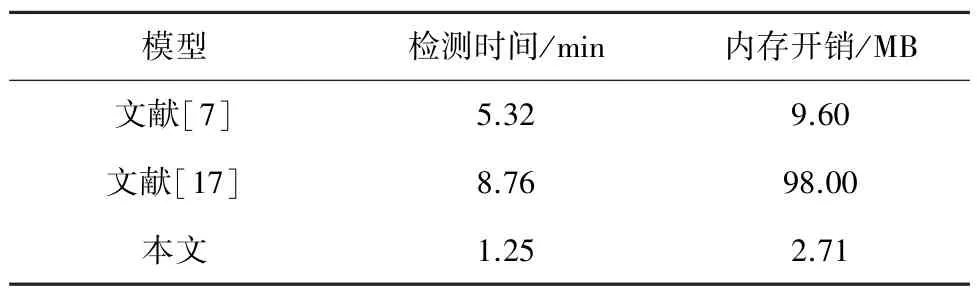
表3 性能比较结果
4 结束语
本文提出了基于特征多样化的恶意域名检测方法,将域名特征与访问特征一起应用到模型中训练,提高了系统的泛化能力,增加了模型的通用性,针对不同类型的恶意域名都可以达到良好的检测效果。在对方法的分析中,发现本文的检测模型体现出整体更高的检测性能。另外,本方法也存在着一定的不足,在分词过程当中,没有达到更加全面的效果,对于类似于中文拼音的域名,在分词方面存在一定误差,需要进一步改进。另一方面,可以对域名其他不易改变的特征进行进一步挖掘,提高检测效果。
猜你喜欢
无线互联科技(2020年11期)2020-12-01
江苏教育研究(2020年2期)2020-04-10
江苏教育研究(2020年1期)2020-04-10
卷宗(2016年12期)2017-04-19
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
活力(2016年9期)2016-08-01
活力(2016年9期)2016-08-01
健康管理(2016年7期)2016-05-14
中国信息技术教育(2015年21期)2015-09-10
