
基于图信号处理的MVDR波束形成多通道语音增强
2021-02-24 13:03杨洋,杨震,2
南京邮电大学学报(自然科学版) 2021年6期
杨 洋,杨 震,2
1.南京邮电大学通信与信息工程学院,江苏 南京 210003
2.南京邮电大学通信与网络技术国家地方联合工程研究中心,江苏 南京 210003
近年来,随着技术不断革新,大量的数据信息驻留在不规则且复杂的结构网络中,导致传统的数字信号处理技术不再适用,进而催生了新兴的技术——图信号处理(Graph Signal Processing,GSP)技术的研究热潮,文献[1-3]介绍了图信号处理的众多应用与挑战。目前,图信号处理已广泛应用在诸如传感器网络[4]、生物网络[5]、图像处理[6]、机器学习[7]等领域。
相较于传统数字信号处理(Digital Signal Processing,DSP)的固定离散傅里叶基,图傅里叶的基底可以有多种选择,故对于处理各种信号更加灵活。例如对于边的权重为实数且非负的无向图,常常选用的是拉普拉斯矩阵L的特征值分解来定义图傅里叶基[1],图拉普拉斯矩阵常定义为L=D-A,其中D为度矩阵,其为对角阵,对角线上的元素表示与该顶点相关联边的数量,A为邻接矩阵,表示为顶点之间的关系,而选用邻接矩阵的特征值分解或约旦分解来定义图傅里叶基则不需要考虑图边的权重是否实复和正负,以及是否带有方向[3,8-10]。
对于语音信号,文献[11-12]提出利用有向循环图作为有限长周期时间序列的图,一旦图确定,选择合适的方法来进行图傅里叶变换是很重要的,若选用约旦分解来定义图傅里叶基底,则需要预先考虑和调整图的结构,这会改变图结构,导致后续处理的错误,此外若对有向循环图进行特征分解,已经证明,得到的图频率和相应的频谱特性与经典数字信号处理一致,所以选用奇异值分解无须对图结构先验已知,且不用考虑因图矩阵非负元素为负导致的部分语音信号移动或丢失[13]。
在语音增强方面,文献[14-15]提出了GSP在单通道语音信号中的增强处理,而传统上对于多通道语音增强大多用麦克风阵列的波束形成来实现[16]。近年来,众多研究者常对最小方差无失真响应(Minimum Variance Distortionless Response,MVDR)波束形成的目标信号的掩膜或噪声功率谱密度估计进行处理,如文献[17]利用生成对抗网络生成掩膜,文献[18]利用单调算子分裂来改善噪声功率谱密度估计的精确性,文献[19]提出了一种基于麦克风观测值来递归估计空间相干矩阵的方法,进而提高了语音和噪声功率谱密度估计的精确性。
以上工作利用GSP技术提升了单通道语音增强性能,但还未将图信号处理技术应用于多通道语音增强中,文献[16-19]仍然是在传统DSP域进行多通道语音增强。鉴于采用GSP技术能提升语音增强性能[14-15],本文将从多通道信号转换到图频域的角度出发,考虑帧内语音信号的逻辑关系和各传感器之间的逻辑关系,将多通道语音信号从经典的时域变换到图频域进行处理。仿真实验表明,相较于传统DSP方法处理的MVDR波束形成语音增强,在语音质量和语音可懂性方面有显著提升。
1 基本原理
1.1 GSP 基础理论
本节简要介绍图信号的概念。通常,图用G={V,E,W}[1]表示,其中V表示有限点的集合|V|=N,E为边的集合,W表示加权邻接矩阵。如果在点i,j之间有边ei,j,那么Wi,j表示该边上的权重,即两点的相关性。 若Wi,j=0,则说明点i,j无关系。一般而言,为方便说明,若两点直接有关系即两点有边,权重为1,否则为0。对于帧内的语音信号而言,语音信号可表示为N个采样点的一维有向信号
对于语音信号,其图信号可表示为G={V,E,Af},其中点集V表示语音信号时域上对应的采样点nN,边集E表示前后信号相邻的关系,ei,j∈{0,1}。 加权邻接矩阵Af可由文献[8]中的定义2得出,文献[8]中指出,对于一维有限长离散时间信号,其邻接矩阵为
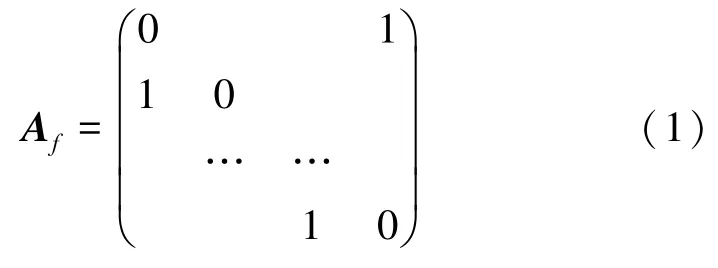
其可视化图如图1所示。
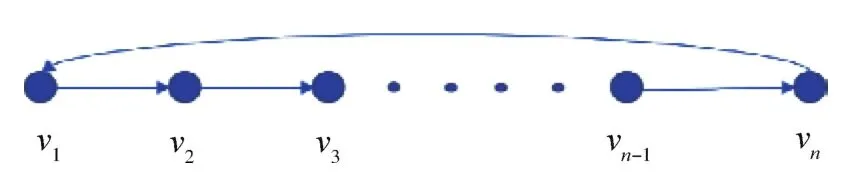
图1 一维有限长时间序列的可视化模型[8]
对于通道之间的语音信号而言,由于麦克风之间的相对位置不同,对声源的接受有时间差τij=其中ds为两个传感器之间的间距,θ为声波到达线性阵列的传感器之间形成的夹角,c为空气中的声速。则该阵列的导向矢量为
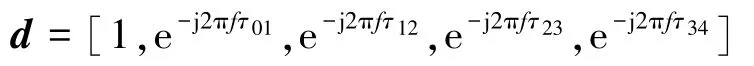
传感器结构如图2所示。
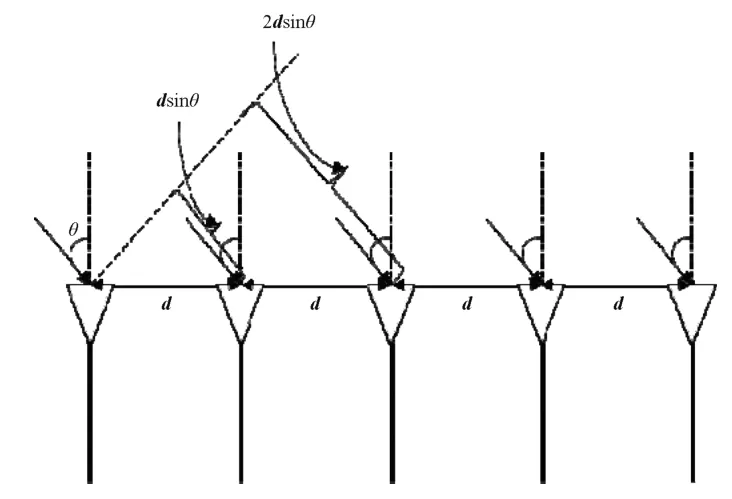
图2 均匀线性麦克风阵列[20]
语音信号在麦克风阵列接收到的信号中,通道的图邻接矩阵Ac可由传感器之间的相对距离以及它们的导向矢量的联合图来表示,具体如下
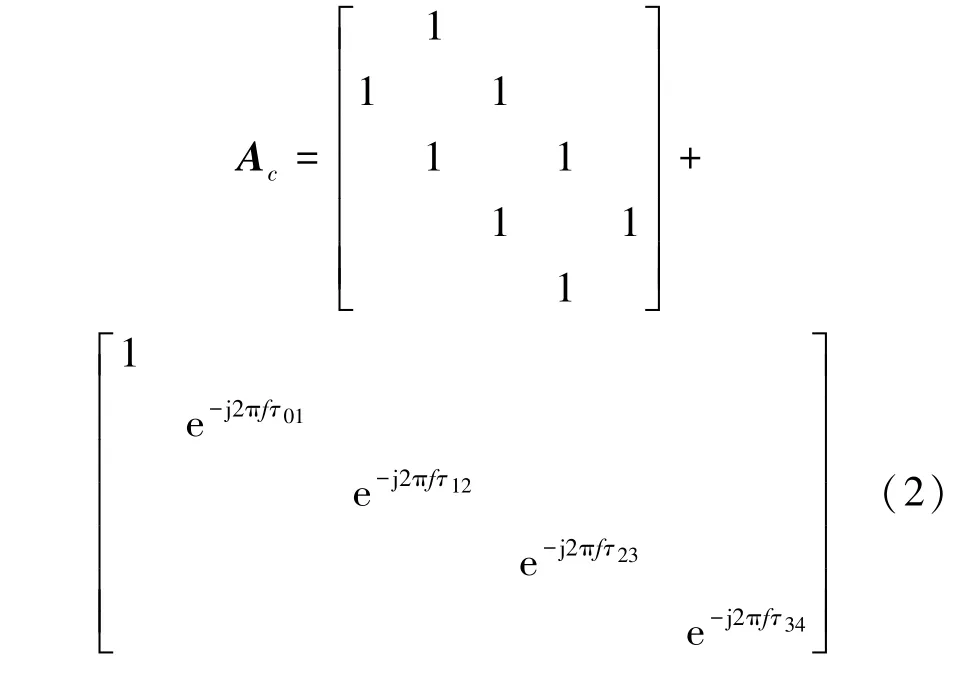
其中与主对角线平行的元素表示相邻传感器之间位置关系,即若两传感器相邻为1,否则为0;主对角线表示以第一个传感器为参考点,该阵列的导向矢量,反映了阵列之间的相位差。
通过图傅里叶变换(Graph Fourier Transform,GFT),可以使信号变换到图频域中进行分析,对邻接矩阵A进行特征分解有A=VΛV-1,其中V为特征向量组成的矩阵,为由特征值组成的对角矩阵,称λk为图频率[9]。将V-1视为GFT矩阵,则GFT定义为其图逆GFT(Inverse GFT,IGFT)定义为作者团队已经证明,当邻接矩阵A为1-shift的情况时,经典DSP为GSP的特殊情况,本文对邻接矩阵A进行奇异值分解得到A=VΛD∗[16],则 GFT 为IGFT 为
1.2 多通道 GFT
将多通道信号分帧,得到M×T×F的矩阵,其中,M为通道数量,T为帧数,F为帧长,如图 3所示。
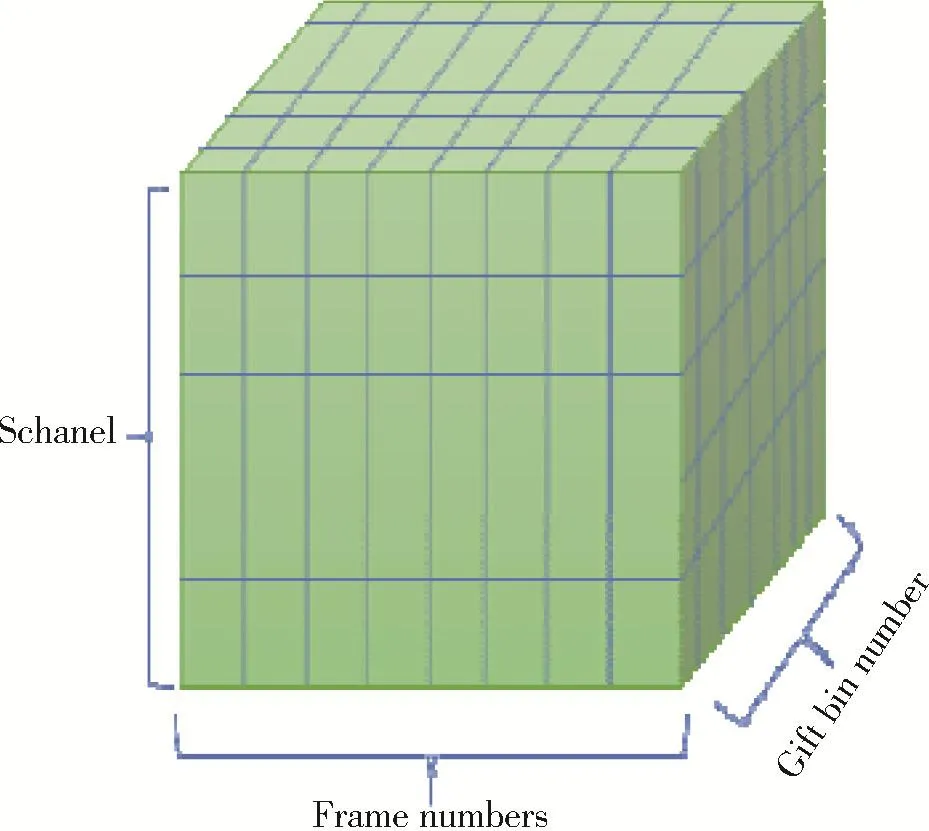
图3 多通道语音信号
首先,进行帧内的GFT。具体地,对Af进行奇异值分解,得到左奇异值向量U,取出其中一个通道内的帧内数据与U-1相乘进行GFT,依次循环得到一个通道内的 GFT,帧内 GFT的过程如图 4所示。
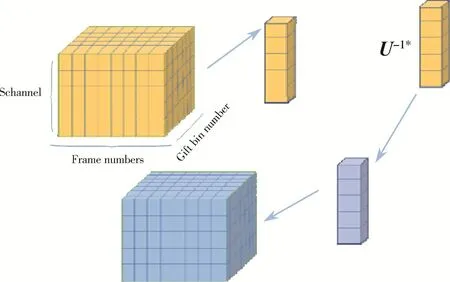
图4 帧内GFT
然后,进行通道内的GFT,过程与帧内GFT类似。具体地,对Ac进行奇异值分解得到U矩阵,取出一帧内的全部通道数据与U-1相乘再放回,依次循环得到整个数据的GFT,通道内的GFT过程如图5所示。至此,将多通道时域语音信号变换到图频域中。
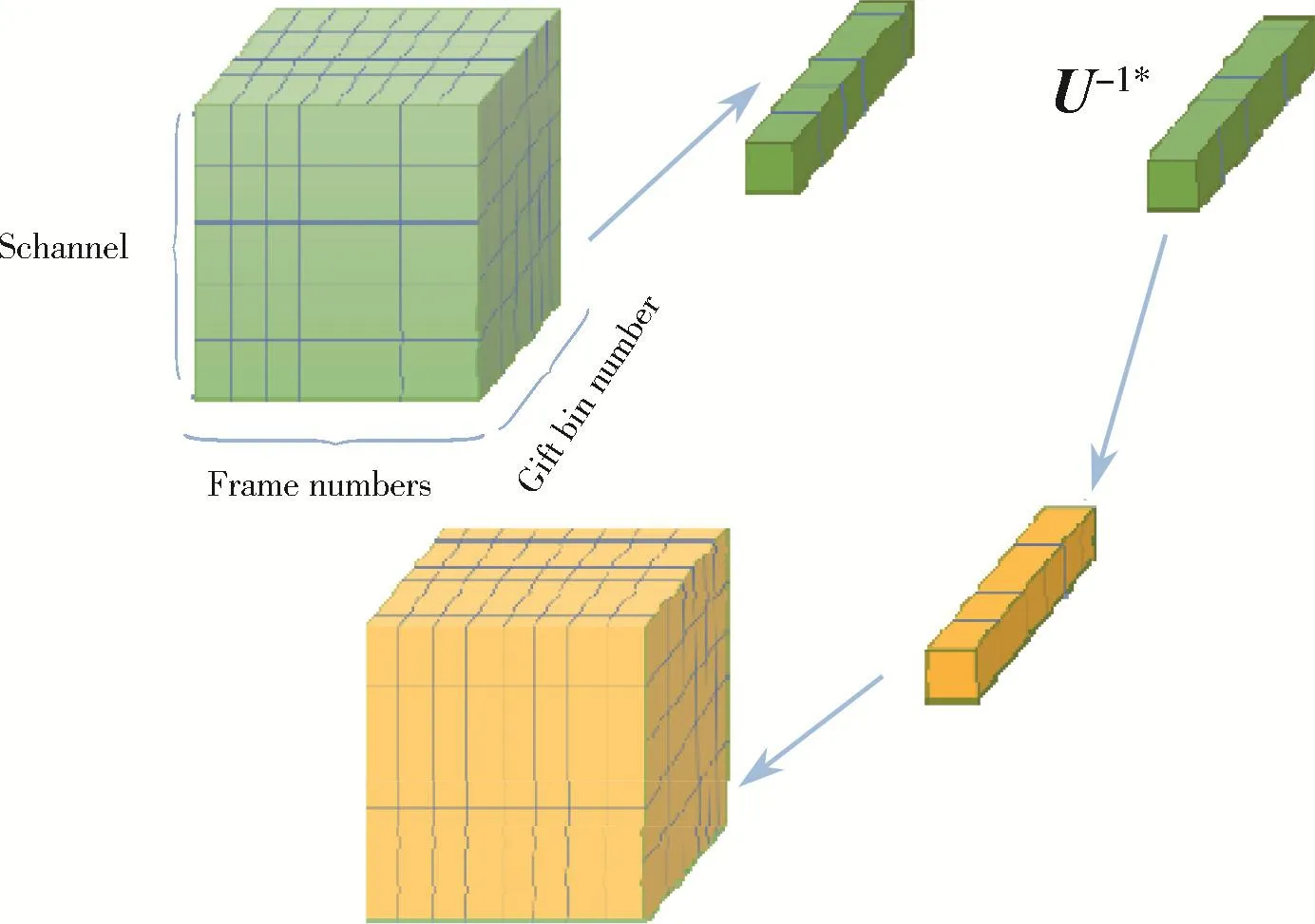
图5 通道内GFT
1.3 MVDR 波束形成
对于麦克风阵列,在t时刻,麦克风n(n=1,2,…,N)采集到的含噪语音信号可以表示为yn(t)=xn(t)+vn(t),其中vn(t) 为加性噪声,xn(t)为声源到达麦克风的信号,它们由同一个图得出。由于麦克风之间的空间分布,声源到达各个麦克风的衰减和延迟是不同的,即xn(t)=αn·s(t-τn),其中αn为衰减因子,τn为相对时延。
将含噪图语音信号进行GFT,得到

其中
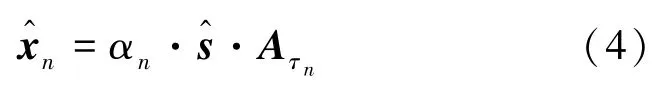
式中Aτn为移位算子[21]。
令
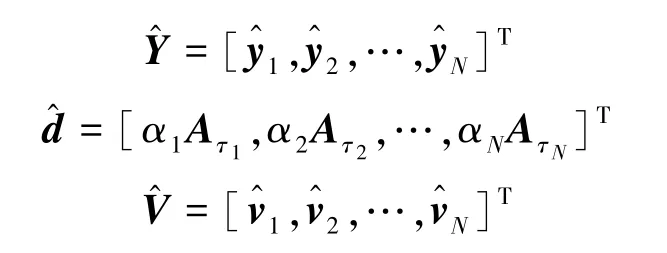

通过设计滤波器
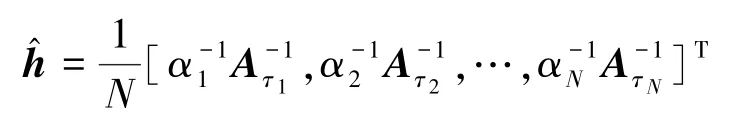
对含噪图语音信号进行滤波,得到增强后的图语音信号

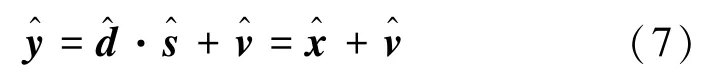
结合式(6)和(7)得
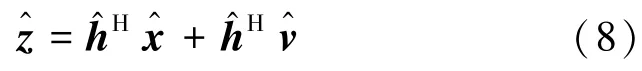
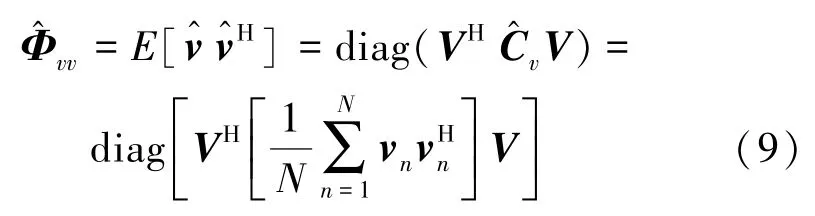
式中,Cv为协方差矩阵。假设噪声与原始信号不相干,那么之间的 PSD 满足
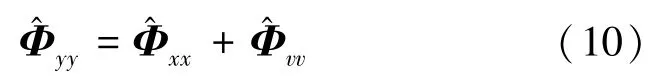
结合式(8)和(10),有
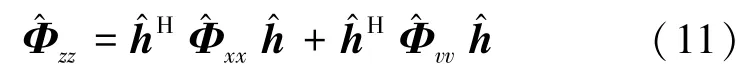
定义局部信噪比为
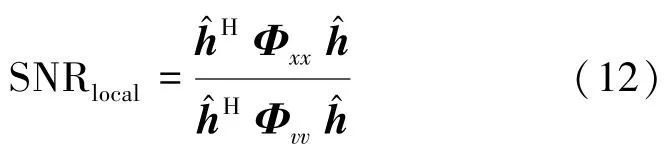
则MVDR的求解问题可以表示为
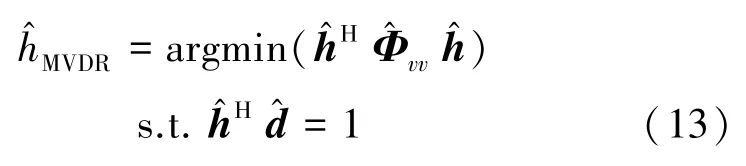
其最优解为
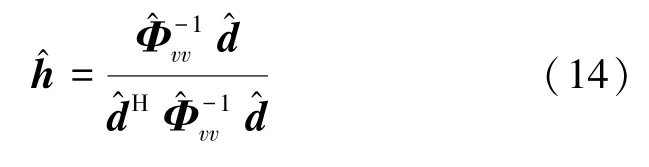
2 实验仿真与结果分析
本节对所提的基于GSP的MVDR波束形成多通道语音增强方法进行仿真,并与文献[17]提出的传统DSP域的MVDR波束形成多通道语音增强方法和文献[23]提出的基于深度神经网络的语音活动检测支持的波束形成多通道语音增强方法进行比较。为简便起见,将本文提出的基于GSP的MVDR波束形成多通道语音增强方法记为图傅里叶变换多通道语音处理(Graph Fourier Transform Multi⁃Channel Speech Processing,GFT⁃MCSP)方法。 采用的评价指标为客观语音质量评估(Perceptual Evaluation of Speech Quality,PESQ)[24]和短时客观可懂度(Short⁃Time Objective Intelligibility,STOI)[25],对本文提出的方法以及参考实验的性能进行评估。对于PESQ,其范围在1.0~4.5,数值越大,语音信号的感知质量越好,当低于1.0时即为失真严重。而STOI范围在0~1,且值越大,语音信号的可懂度越好。
在本节仿真实验中,多通道语音信号是由麦克风阵列模拟平台 SMARD[26]生成,房间设置为长3 m,宽4 m,高3 m,房间墙壁的吸收系数设置为1,以确保数据集在实验中没有混响影响。纯净语音信号来源于TIMIT语音库,且采样频率为16 000 Hz。将纯净语音信号分别加上白噪声和babble噪声(随机选自于 NOISEX⁃92)[27]干扰,构成不同信噪比下的含噪语音信号。
图6和图7分别为不同方法在白噪声环境下PESQ、STOI与输入信噪比的性能曲线。由图6和图7可以看出,在白噪声环境下,所提的GFT⁃MCSP方法得到的PESQ和STOI均优于两种参考方案。另外,从图6和图7还可以看出,考虑传感器之间的位置关系与相位差联合构建的图对语音质量与可懂度的提升优于仅考虑单一关系构建的图。
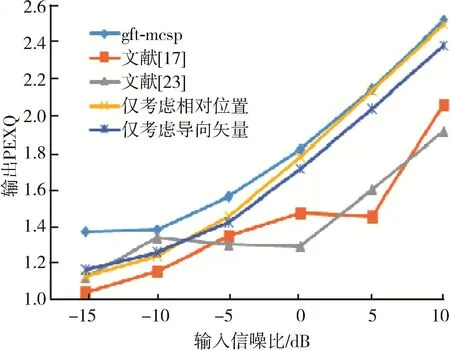
图6 白噪声下不同方法的PESQ对比
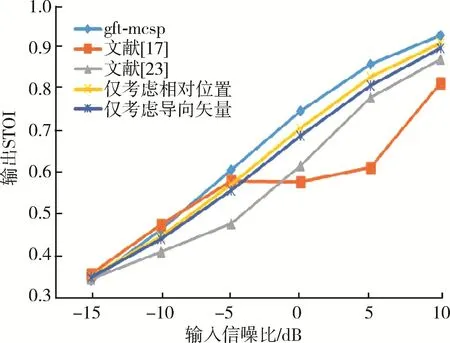
图7 白噪声下不同方法的STOI对比
图8和图9分别为不同方法在babble噪声环境下PESQ、STOI与输入信噪比的性能曲线。从图8和图9可以看出,在babble噪声下,低信噪比时GFT⁃MCSP的PESQ与文献[17]和文献[23]差距不大,而在高信噪比下本文所提的GFT⁃MCSP方法得到的PESQ远优于文献[17]和文献[23]中的方法。并且,在babble噪声环境下,本文所提的GFT⁃MCSP方法得到的STOI优于文献[17]和文献[23]中的方法。同时,从图8和图9可以看出,babble噪声环境下,考虑传感器之间的位置关系与相位差联合构建的图对语音质量与可懂度的提升也优于仅考虑单一关系构建的图。
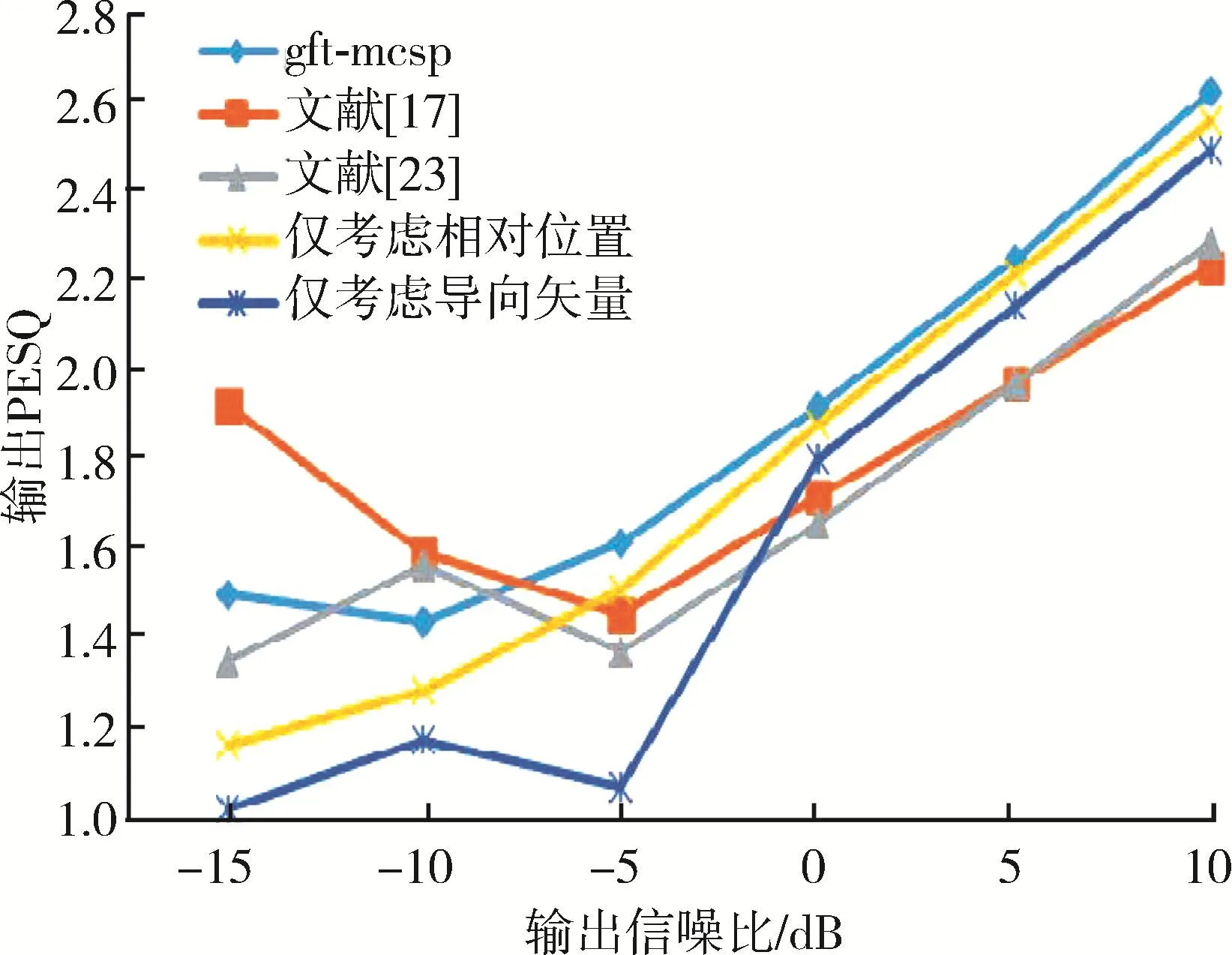
图8 babble噪声下不同方法的PESQ对比
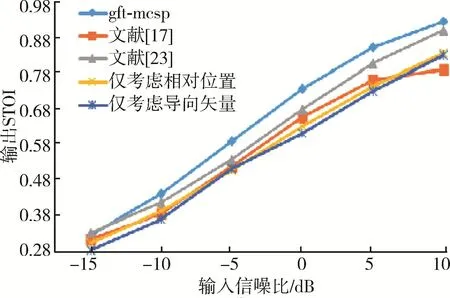
图9 babble噪声下不同方法的STOI对比
3 结束语
本文提出了一种基于GSP的MVDR波束形成多通道语音增强方法,该方法联合考虑语音帧内关系与各通道间传感器关系来构建图语音信号。具体地,在通道内利用传感器相对位置关系与导向矢量结合的方式构建通道内的图,对帧内采用1-shift的方式构建帧内图。在此基础上,将多通道语音信号通过联合 GFT映射到图频域,利用图频域中的MVDR波束形成器对语音信号进行增强。仿真表明,本文提出的基于GSP的MVDR波束形成多通道语音增强方法在语音质量评估和可懂度方面有显著的提高。
猜你喜欢
舰船科学技术(2021年12期)2021-03-29
成都信息工程大学学报(2021年6期)2021-02-12
数字海洋与水下攻防(2020年6期)2020-12-25
现代电子技术(2020年3期)2020-08-04
科技与创新(2020年8期)2020-05-08
舰船科学技术(2020年3期)2020-04-22
劳动保护(2019年3期)2019-05-16
小学科学(2016年12期)2017-01-06
电脑爱好者(2016年24期)2017-01-05
饮食科学(2016年7期)2016-07-27
