
基于记忆增强的对抗自编码器异常检测算法
2021-02-24 13:04:04成卫青
南京邮电大学学报(自然科学版) 2021年6期
蔚 焘,成卫青
(南京邮电大学计算机学院、软件学院、网络空间安全学院,江苏 南京 210023)
异常检测(Anomaly detection)[1],又称离群点检测(Outlier detecion),是检测不匹配预期模式或与大多数数据实例显著不同的数据点,这些被检测出的数据点被称为异常点。随着人工智能的快速发展,异常检测在计算机视觉[2]、数据挖掘[3]、自然语言处理等实际应用领域发挥着越来越重要的作用。例如,从监控视频中检测出不符合常规模式的行为[4-5],金融企业根据信用卡交易记录识别出欺诈行为[6],网络安全领域中的攻击检测[7],这些领域的数据在维度和规模上都在迅速增长,因此需要更高效和准确的方法检测数据中的异常。由于异常的罕见性,数据集中正常数据往往占据绝大多数,这就导致获取足够异常数据的高成本和困难性,所以在实际应用中采用监督学习通常不切实际。
近些年来,国内外针对异常检测问题的研究主要集中于半监督[8]方式与无监督方式。通常来说,异常检测所采用的技术大致可以分为基于统计的方法、基于距离的方法、基于密度的方法和深度学习方法。由于深度学习在处理高维数据、时序数据和空间数据等复杂数据的优异表现,深度学习开始应用于解决现实世界中各种具有挑战性的异常检测问题,并且相较于其他方法其性能有了大幅提高。其中最具代表性的深度异常检测方法就是自编码器,自编码器不仅能够对数据进行降维,还能将降维数据重新构造为原始输入。这一特性成为自编码器应用于异常检测的关键原因,自编码器异常检测技术通过学习到的低维特征对训练数据的某些内在规律进行表示,当输入异常样本时产生更大的重构误差,异常样本得以检测成功。
自编码器作为一种无监督的人工神经网络,将重构输入数据作为训练目标,忽略数据中存在的噪声进行表征学习。自编码器主要应用于数据降维和异常检测,它的一系列变体能够使其具有更丰富的特征表示能力,能够更好地解决自编码器泛化能力过强的问题。稀疏自编码器(Sparse Autoencoder,SAE)[9]鼓励以稀疏性的方式进行特征学习,对隐藏层的节点添加稀疏性约束,即只允许隐藏层同时激活更少的单元,这种稀疏性约束迫使神经网络学习到训练数据中更具代表性的特征。降噪自编码器(Denoising AE,DAE)[10]通过向输入数据添加一些随机噪点,然后让其重构没有噪声的原始数据。这种情况下,模型能够迫使隐藏层学习更具鲁棒性的特征。变分自编码器(Variational Autoencoder,VAE)[11]是一种生成模型,通过学习用于对数据进行建模的概率分布参数,使用潜在空间上的先验分布将输入数据映射到一个分布,其编码分布在训练过程中会引入正则化,确保学习结构良好的潜在空间并减少训练过程中的过拟合,从而能够生成新的数据样本。Gong等人于2019年提出了一种将记忆增强模块用于改进传统的自编码器无监督异常检测模型MemAE[12],该模型旨在解决自编码器在进行异常检测时所面临的泛化能力过强的问题,提高异常检测性能。
虽然MemAE有效提高了异常检测性能,但是受限于自编码器对于正常数据的编码能力,对于部分测试数据依然难以实现较好的重构。基于先前的研究,对抗自编码器[13]融合了生成式对抗网络的思想,使得解码器学习成为一个表现良好的深度生成模型。受此启发,本文提出一种基于记忆增强的对抗自编码器异常检测模型。
在一系列异常检测数据集上的实验结果表明,本文提出的MemAAE模型相较于其他异常检测模型拥有更好的结果,证明了方法的有效性。
1 相关工作
1.1 MemAE 模型
随着深度学习被广泛应用于解决各种复杂问题,那些不具备捕获数据间依赖关系的神经网络模型难以满足需求。循环神经网络(Recurrent Neural Network,RNN)[14]的提出使得网络具有短期记忆的功能,相较于传统模型的隐节点输出仅取决于当前的输入特征,而RNN网络的当前输出也包含了记忆信息。在此基础上,Hochreiter等人提出的长短期记忆(Long Short⁃Term Memory,LSTM)[15]神经网络进一步提升了记忆能力。它们被广泛应用于自然语言处理、机器翻译和推荐算法等领域并取得了巨大的成功[16]。但是LSTM网络通过隐藏层或注意力机制实现的记忆功能有限,因此有研究使用外部记忆保存训练信息并在需要时进行读取。
2014年,Facebook人工智能实验室提出一种新的学习模型,将其命名为 MemNN(Memory Neural Network)[17]。该模型的核心思想是将用于推理的机器学习策略与可读写的长期记忆模块相结合,构建一个动态的知识库。MemNN在问答数据集bAbl上的表现远远超过其他模型,受到了广泛关注。由于该篇论文提出的是一种普适性的架构,之后有很多论文提出了多种改进方式[18],记忆神经网络得到了快速发展并成为机器学习领域中不可或缺的分支。
2019年提出的MemAE[12]模型主要由3个组件组成:编码器、解码器和记忆增强模块。编码器用于将输入数据进行编码并生成查询项,解码器用于重构编码输入,而记忆增强模块包括用于记录各种正常模式的记忆项和读取记忆项的寻址操作,算法的具体流程如图1所示。该算法通过在自编码器中引入记忆增强模块,不直接将编码结果进行解码,而将其作为查询项通过基于注意力机制的寻址操作检索记忆增强模块中的正常模式并对记忆项进行更新,最后将查询结果输入解码器进行重构。在训练过程中,算法通过最小化重构误差和记忆项查询权值的熵损失对模型进行训练。在测试阶段,固定记忆矩阵参数,根据编码器的编码结果对记忆矩阵的寻址结果将记忆项进行组合,组合结果将通过解码器进行重构,重建误差将作为量化异常程度的标准。
1.2 AAE 模型
生成式对抗网络(GenerativeAdversarial Networks,GAN)由Goodfellow等人于2014年提出,自提出以来迅速成为一种流行的生成式模型[19]。生成式对抗网络的核心思想源自于零和博弈(Two⁃player game),该模型由生成模型G和判别模型D组成。生成模型G通过学习捕捉真实数据的分布,将随机噪声映射为分布与真实样本一致的伪样本,目的是最大程度地混淆鉴别器D。鉴别器是一个判断样本是否来自于真实样本的神经网络。模型的训练过程视为生成器和判别器的交替更新,直到判别器难以区分样本来自于真实样本还是生成的伪样本,此时模型达到了纳什均衡,说明生成器学习到了训练数据的潜在特征空间。真实样本与生成样本的重构误差可以被定义为异常分数,用于解决异常检测问题[20]。
2015年,Makhzani等人通过将自编码器网络与GAN网络引入的对抗性损失训练相融合提出了对抗自编码器 (Adversarial Autoencoder,AAE)[13]。AAE网络使用了类似于变分自编码器(VAE)的思想,不同之处是AAE使用对抗损失代替KL散度进行正则化。AAE模型有两个训练目标:一个是最小化传统自编码器的重构误差,另一个是将自编码器隐变量的聚合后验分布与任意的先验分布相匹配。
如图2所示,AAE模型由两个部分组成:自编码器和生成对抗网络GAN。自编码器中的编码器既承担着将输入数据编码到低维特征空间中,作为解码器的输入,同时又作为对抗网络中的生成器生成伪样本。设x为输入数据,z为经过编码器得到的编码向量。q(z|x)表示编码分布函数,pd(x)表示真实的数据分布,那么编码器隐藏层的聚合后验分布q(z) 为
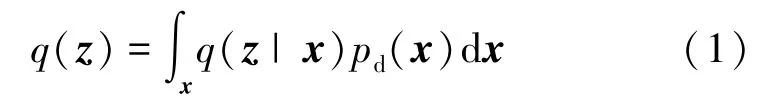
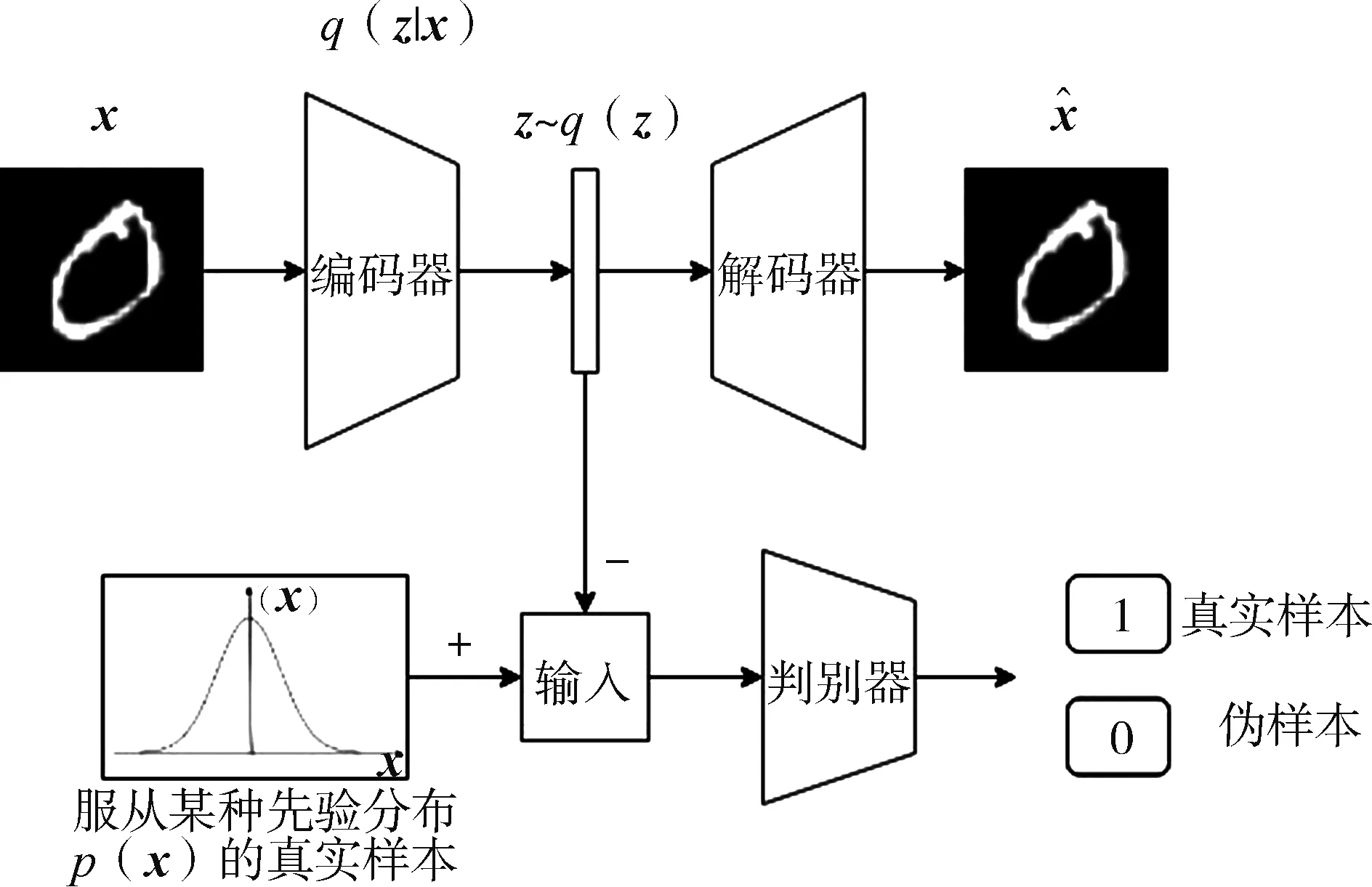
图2 对抗自编码器模型
对抗自编码器在训练过程中引入了生成对抗网络的正则化,目的是使聚合后验分布q(z)与先验分布p(z)相匹配。编码器将生成的服从聚合后验分布q(z)的样本连同服从先验分布p(z)的样本发送给判别器,首先判别器将更新自身参数,提高判别能力,然后将判别结果进行反馈,编码器将根据反馈结果更新参数,生成能够混淆判别网络的样本。当训练结束后,判别网络将难以判别样本来自于先验分布还是聚合后验分布,编码器将引导编码结果的聚合后验分布q(z)匹配先验分布p(z)。
2 异常检测模型
2.1 模型结构
AAE的编码器和解码器使用对称的前馈非循环网络,当模型被应用于处理图像数据时,将图像像素值堆叠到一列数据之中,将其作为标准的全连接神经网络的输入。但是像素值的堆叠会导致图像空间信息的丢失,深度神经网络对于高维数据的非线性映射表现一般,并且这种处理方式需要计算大量的神经网络参数,为实验带来了更大的计算压力。因此当数据集为图像数据时,本文使用卷积神经网络(Convolutional Neural Networks,CNN)代替原先的全连接神经网络,卷积将有效提取隐藏于图像中的空间信息。当AAE模型运用于异常检测时,由于自编码器的泛化能力过强使得异常数据也能够较好地重构,为此引入记忆增强模块。
记忆增强的对抗自编码器结构如图3所示。MemAAE模型由4部分组成:编码器、记忆增强模块、解码器和判别器。与传统自编码器模型相比,该模型在编码器之后增加记忆增强模块,使用存储的记忆项聚合结果代替编码结果进行解码。该模型的对抗训练过程与GAN网络类似,MemAAE将编码器与记忆增强模块作为生成器,训练过程的目标为记忆模块输出的编码向量所服从的分布尽可能与某一先验分布接近。
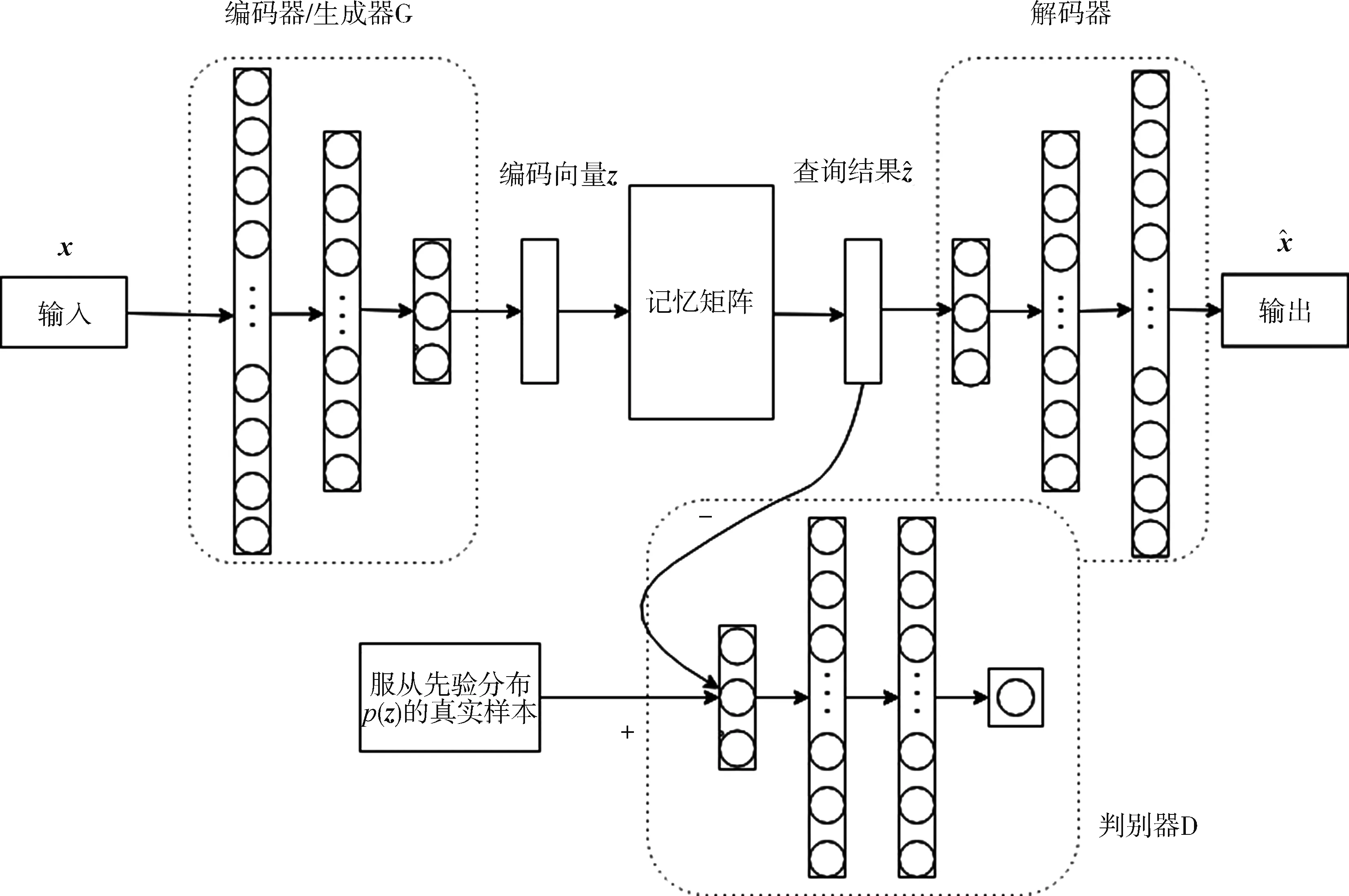
图3 记忆增强的对抗自编码器模型
判别器是一个全连接的前馈神经网络,并且判别器的输出层仅由一个神经元组成,并使用Sigmoid函数作为激活函数。对于任何输入,判别器将输出范围在(0,1)之间的值,该值表示输入来自于某一先验分布p(z)的概率。在训练过程中,判别器将首先更新自身参数,提高判别能力,并赋予自编码器生成的样本更低的评分,然后将判别结果反馈给编码器,编码器将据此更新自身参数生成“以假乱真”的样本来欺骗判别器。
2.2 算法详情
本文提出的异常检测算法训练过程主要可分为两个阶段:自编码器通过最小化重构误差更新自身参数,以及生成器与判别器的对抗过程。
2.2.1 重构阶段
本文将输入的原始数据集样本空间表示为X,当给定一个输入x∈X,经过编码器fe(x)编码将其转换为低维特征空间中的编码z∈Z,然后解码fd(z)将其重构为输出。 以上过程可表达为
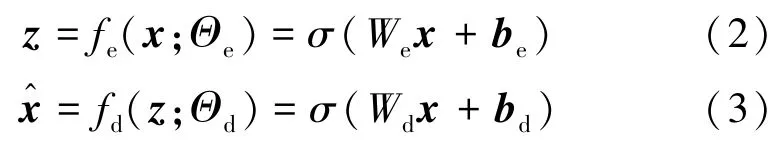
式中,Θe和Θd分别代表编码器和解码器的参数,We和Wd分别表示编码器和解码器神经单元之间的连接参数,be和bd则表示神经元的偏置项,σ表示激活函数。重构误差由均方误差(Mean⁃Square Error,MSE)进行度量,作为异常程度判别的依据。
记忆增强模块设计为一个大小为N×C的矩阵M,即N个维数固定为C的实值向量,每个记忆项维数C与自编码器编码结果z的维数相同。使用pi∈RC(i=1,…,N) 表示记忆矩阵中第i个行向量,即第i个记忆项。如上文所述,假设给定某一输入,经过编码器编码的结果为z∈RC,通过计算查询项z和记忆矩阵中每一记忆项pi之间的余弦相似度获取注意力权重系数,获取记忆模块的查询结果。假定余弦相似度计算公式为cos(·,·),余弦相似度表达式为
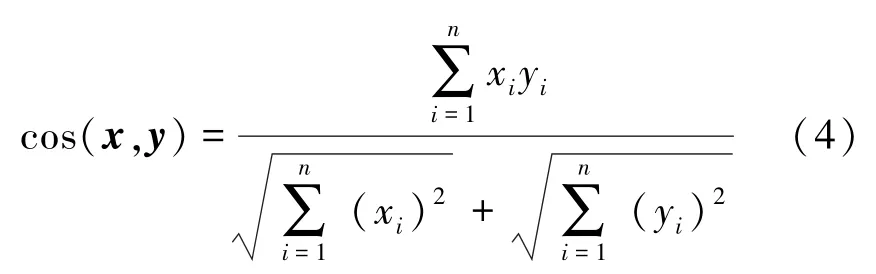
将得到大小为1×N的表示查询z和记忆项pi相关性的一维向量,然后对向量应用softmax函数获取注意力权重
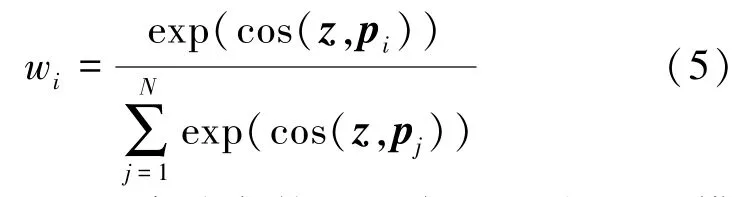
如式(5)所示,当给定某一查询项z时,记忆模块将检索与z相似度最高的记忆项,获得查询结果。 在训练阶段,由于记忆矩阵的大小受到限制,而重构输出是解码器对查询结果z^进行解码的结果,这就潜在要求了记忆矩阵保存最具代表性的原型模式。
然而,某些异常数据仍然可能通过记忆项的复杂组合使得最终得到的重构误差较小。文献[12]提出一种收缩机制提高注意力权重系数w的稀疏性,因为稀疏性鼓励使用更少的记忆项表示查询结果,这将提高记忆项的表示精度。其公式为
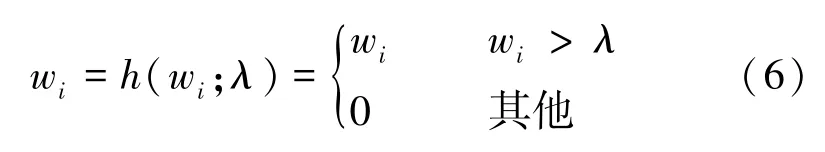
式中,λ表示收缩阈值,将权重系数w中小于或等于阈值的元素赋值为0,实现系数的稀疏性,表示稀疏化后的权重系数。但是计算不连续函数的反向传播并不容易,为了计算的简便性,本文使用连续的ReLU函数实现收缩操作,其公式为
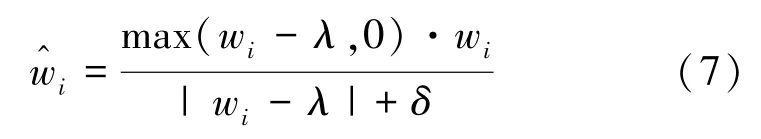
式中,δ表示一个极小的常量。当收缩完成后,重新进行标准化操作
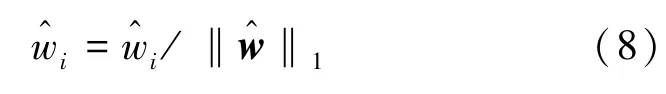
假设最终获取的寻址向量为w=(w1,…,wN)∈R1×N,将寻址向量w作为N个原型向量的权重进行加权求和运算读取记忆模块,获得如下查询结果计算过程由式(9)表示。
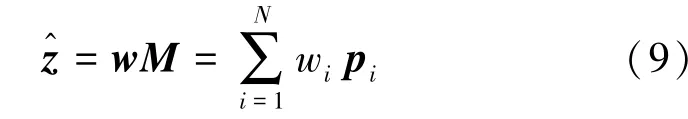
式中寻址向量w为非负向量。
如式(9)所示,最终的查询结果考虑到所有的原型向量而非距离最近的某一原型,记忆原型在训练过程中得到了优化,在理解训练样本正常性的同时,解决了自编码器的泛化能力过强的问题,使得异常样本重构损失明显大于正常样本重构损失。
2.2.2 对抗训练阶段
本阶段的训练过程与GAN网络相类似,自编码器中的编码器与记忆矩阵一起充当生成器,判别器将区分数据是否来源于服从某一先验分布的真实样本。
在经过一次自编码器最小化重构误差的基础上,判别器将收到服从于某一真实先验分布的样本以及由编码器和记忆增强矩阵组成的生成器所生成的伪样本。相较于AAE的对抗训练过程,因为记忆增强矩阵具有的记忆特性,在一定程度上弥补了单一自编码器作为生成器生成能力不足的问题,提高了判别器的判别能力。判别器将通过最小化式(10)提高判别器的判别能力,以区分生成的伪样本和真实样本,此阶段生成器G不参与训练,即
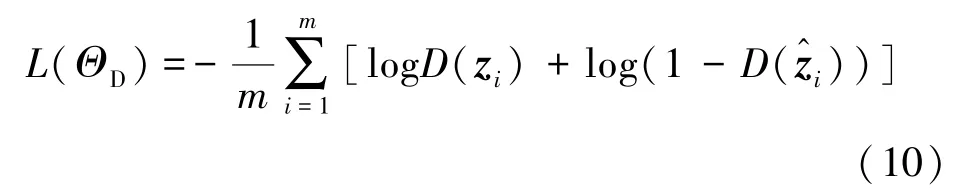
式中,ΘD表示判别器参数,表示生成器G生成的伪样本,zi表示服从于某一先验分布的真实样本。生成器G将参与训练过程,通过最小化二值交叉熵损失提高生成器的生成能力,以根据先验分布p(z)生成样本,公式为
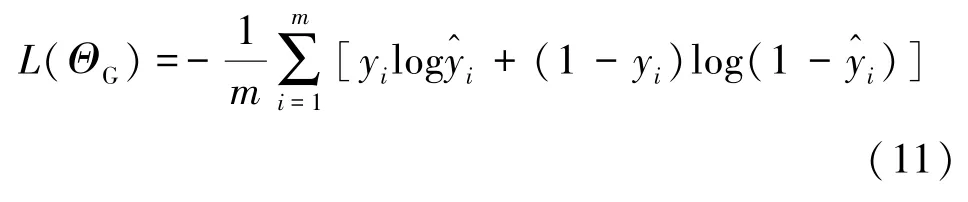
式中,ΘG表示生成器的参数,表示判别器对于输入样本的判别结果,所以式(11)等价于
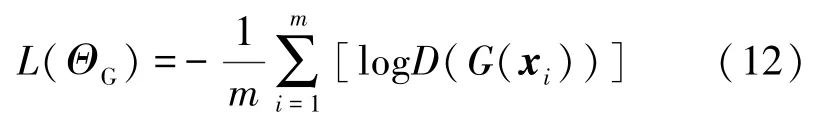
式中,xi表示编码器输入,G和D分别表示生成器与判别器。
当训练结束时,判别器将难以区分输入来自于生成器输出的伪样本还是服从某种先验分布的真实样本。相较于MemAE模型的记忆矩阵在训练过程中提取训练数据中的正常模式,MemAAE模型中的记忆矩阵在提取正常模式的基础上同时具有满足先验分布的特性。在之后的重构阶段,解码器能够将任意的服从某一先验分布的数据解码为正常样本,这将在一定程度上增大输入异常数据时的重构误差。同时记忆增强模块的加入降低了对抗自编码器的过拟合风险以及可能出现的模式崩溃问题。以上这些因素说明了MemAE模型引入对抗训练过程的合理性和必要性。测试阶段仅使用自编码器进行测试,此时记忆矩阵中存储着从训练数据提取的正常模式,测试时保持记忆矩阵参数不变,使用均方误差度量输入和输出之间的重构误差。当输入异常数据时,编码结果会被检索到的正常模式所取代,这会使得异常数据的重构误差大于正常数据的重构误差,优于传统的自编码器方法。此外,经过对抗训练任何服从先验分布的样本都会成为有意义的样本,这在一定程度上优化了解码器的生成效果,提高了异常检测结果。
3 实验与结果分析
3.1 实验设置
为验证MemAAE模型的有效性,本文将在文本数据集和图像数据集分别进行测试。文本数据集选用来自于异常检测数据集网站OODS[21]的8个数据集进行实验,这些数据集均来自于真实世界。8种文本数据集的详细信息见表1。文本数据集描述如下:
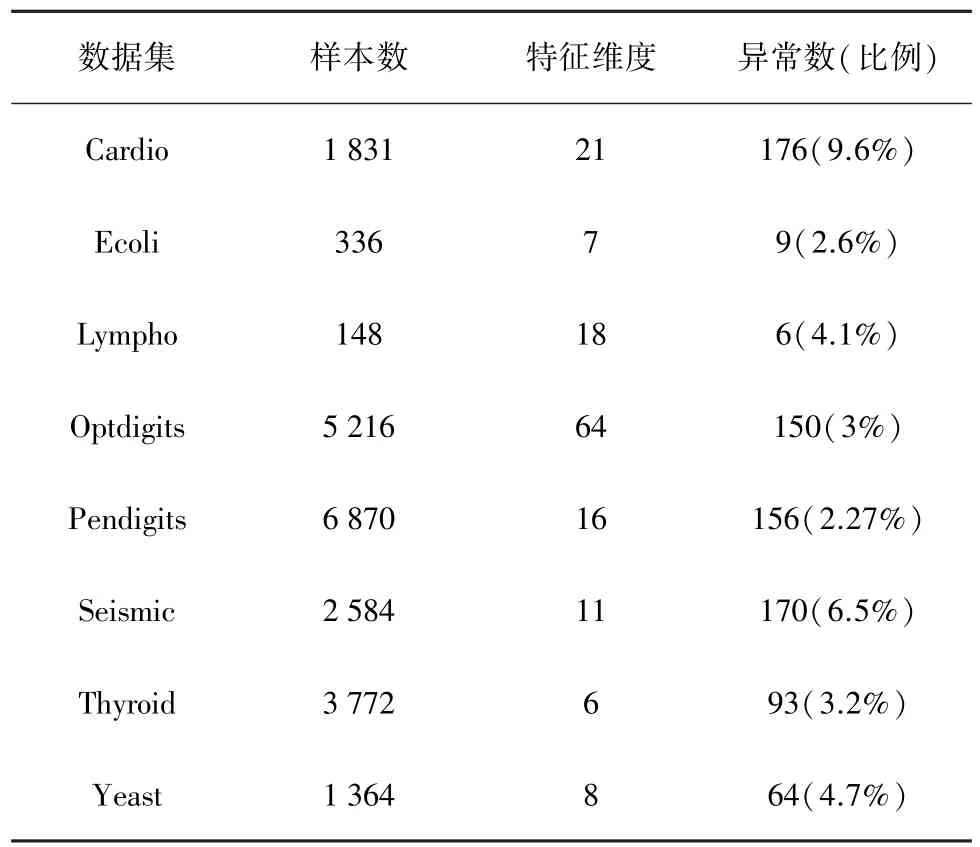
表1 数据集统计信息
(1)分娩心电图描记法(Cardio)数据集是记录胎儿心率数据的分类数据集。数据集包含正常、可疑和非正常3个类别。本文实验舍去了类别为可疑的数据,非正常类别被标记为异常数据。
(2)大肠杆菌(Ecoli)数据集记录了蛋白质定位信息。其中将omL、imL和imS类别数据标记为异常数据,其余类别标记为正常数据。
(3)淋巴系造影(Lympho)数据集是记录患者淋巴影像信息用于肿瘤诊断的数据集。它包含了4个类别,将其中两个较小类别标记为异常数据,其余标记为正常数据。
(4)手写数字(Optdigits)数据集包含了对数千条手写数字0~9的图像进行预处理之后的标准化位图。其中将数字1~9标记为正常数据,提取150条数字0实例标记为异常。
(5)钢笔手写数字(Pendigits)数据集是从44位不同书写者的手写数字收集的,数据集包含了数字0~9,将数字0视为异常样本。
(6)地震预测(Seismic)数据集是来自于波兰某处煤矿所记录的一系列地质数据,用于预测未来可能出现的地震活动。它是一个不平衡数据集,其中“危险”为少数类,将视为异常类别。
(7)甲状腺疾病(Thyroid)数据集来自于澳大利亚Garavan研究所记录的甲状腺疾病的诊断档案。其中将功能亢进类别视作异常数据,其余视为正常数据。
(8)酵母(Yeast)数据集来自于日本一所研究院对于酵母细胞的蛋白质定位位点与细胞化学分析指标关系的研究。将原始数据集中类别为ME3、MIT、NUC和CYT的数据视为正常样本,随机抽取其他类别的5%标记为异常样本。
本文选用的图像数据集为MNIST[22]。该数据集来自于美国国家标准与技术研究所,MNIST[22]包含了250个人的手写数字,其中50%的人是高中学生,其余50%来自于人口普查局。该数据集包含了数字0~9共计70 000张手写数字的灰度图像,图像大小均为28像素×28像素,其中的60 000张图像组成训练集,其余的10 000张图像组成测试集。
3.2 模型设置及评价指标
对于文本异常数据,MemAAE异常检测模型中的编码器和解码器均使用全连接层实现。在MemAAE模型中,自编码器采用对称设计,编码器输入和解码器输出的维度均与数据集特征维数相同,对于隐藏层节点的个数,通常设置为前一层神经元数量的1/2或2/3,但是为了避免数据被过度压缩,难以重建,隐藏层的节点个数不少于3个。以数据集Optdigits为例,原始数据特征维数为64,编码器的隐藏层节点个数分别设置为32、16和8。判别器设置为3层前馈神经网络,隐藏层使用Relu激活函数,输出层为单一神经元节点,使用Sigmoid激活函数将结果转化为0到1之间,表示输入为异常的概率。
对于原始数据集,类别属性值为0表示正常数据,1表示异常数据。本文将随机抽取80%的正常数据组成训练集,将其余20%的正常数据与全部的异常数据组成测试集。本文选择Adma算法作为深度神经网络的优化算法,学习率设置为0.001。
对于图像数据,本文使用简单的卷积神经网络代替原先的全连接神经网络实现自编码器。相较于全连接网络,卷积神经网络能够有效提取图像中的空间信息,而且大大减少了训练过程中的参数以及可能出现的过拟合问题。对于MNIST数据集,编码器和解码器分别用三层卷积层和反卷积层实现,除去最后的反卷积层,每一层之后都经过批量标准化处理(Batch Normalization,BN)和ReLU激活函数。对于编码器的输出,将其变换为一维行向量作为查询项。判别器模型的设置与文本异常检测相类似。
对于MNIST数据集的10个不同类别,将其中的一个类别视为正常样本,其余9个类别视为异常样本,将训练得到10个异常检测模型。本文将采用MNIST数据集的初始分割,将某一类别大约6 000张图像作为训练集,测试集中的10 000张图像全部作为测试样本。同样选择Adam算法进行训练,学习率设置为0.000 1,记忆矩阵大小固定为100,单次训练选取样本数为32。
本文将以AUC值作为模型的评价指标。AUC值通过计算ROC曲线与坐标轴形成的图形面积得到,ROC曲线通过真正例率(TPR)和假正例率(FPR)绘制。
3.3 实验结果与分析
3.3.1 文本数据
为验证本文提出方法的有效性,选择了4种具有代表性的异常检测算法进行对比,采用AUC值作为异常检测性能的评判指标。5种模型在8个真实文本数据集上的测试结果见表2。每一数据集下取得的最优实验结果用粗体标记。
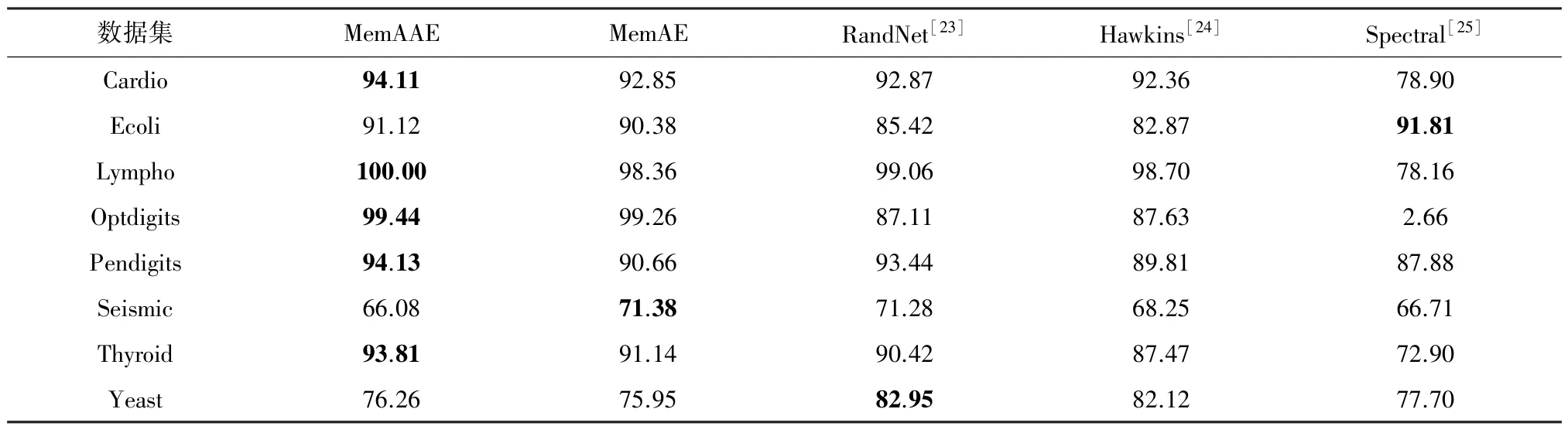
表2 异常检测性能比较
从8个文本数据集的实验结果可以看出,MemAAE模型在5个数据集上取得了相较于其他4种模型更好的结果,证明了MemAAE模型在文本异常检测任务中的有效性。相较于MemAE模型,MemAAE模型引入了对抗训练过程,增强了自编码器及记忆矩阵对于正常样本的编码能力,使记忆矩阵中存储的记忆项更具代表性,提高了模型对于异常样本的检测能力。
对于MemAAE的训练过程,可以分为2个阶段:自编码器更新自身参数最小化重构误差以及生成器和判别器的对抗过程。为了探寻对抗过程的增加对于原始MemAE模型训练过程的影响,MemAE模型和MemAAE模型的自编码器重构误差随迭代次数增加而不断变化的过程如图4所示。除此之外,通过将记忆矩阵大小设置为不同的值进行实验,使用折线图表示记忆矩阵大小对实验结果的影响,实验结果如图5所示。以上过程将使用Thyroid数据集进行实验。
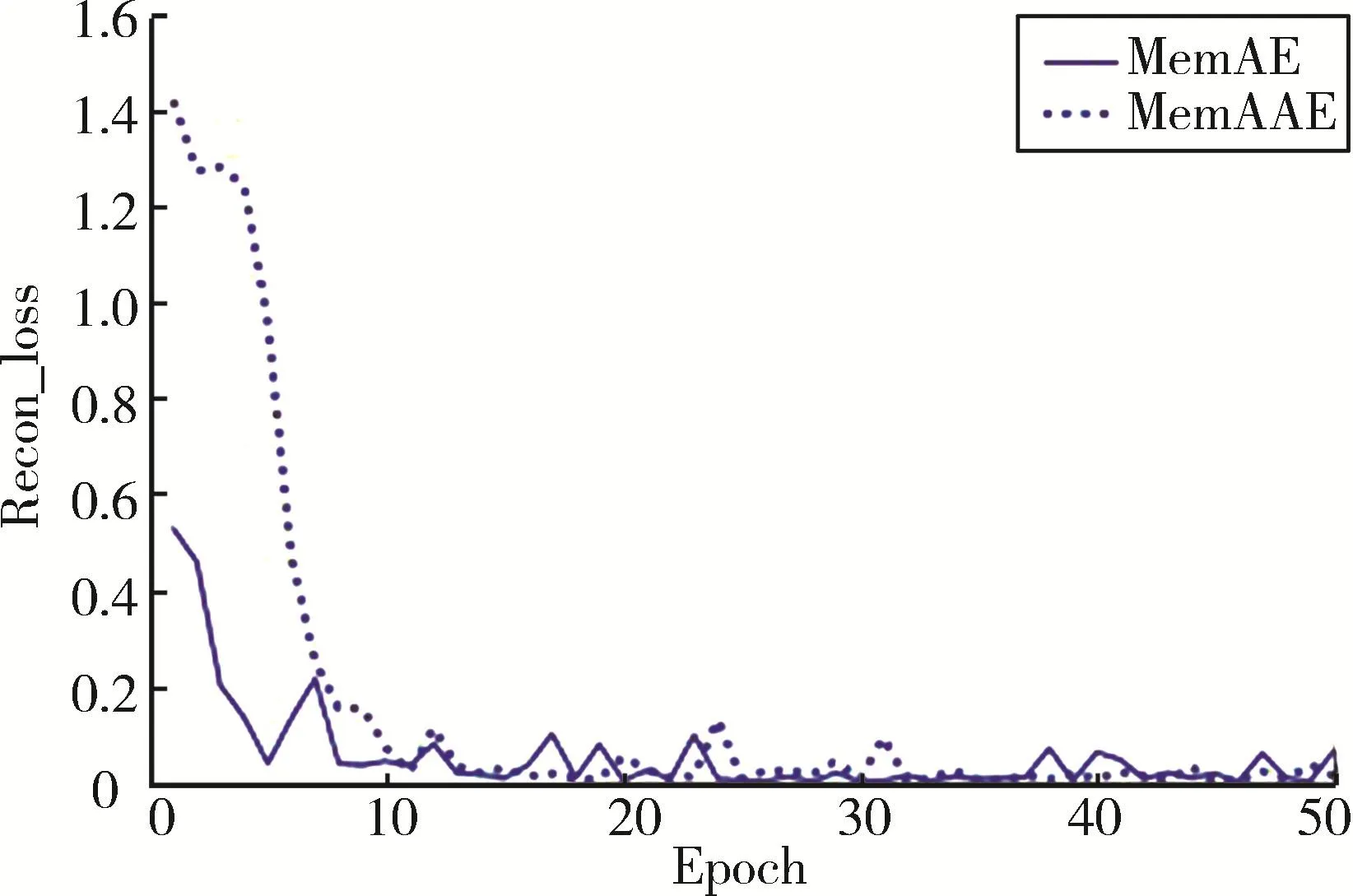
图4 MemAAE模型训练过程中重构误差的变化曲线
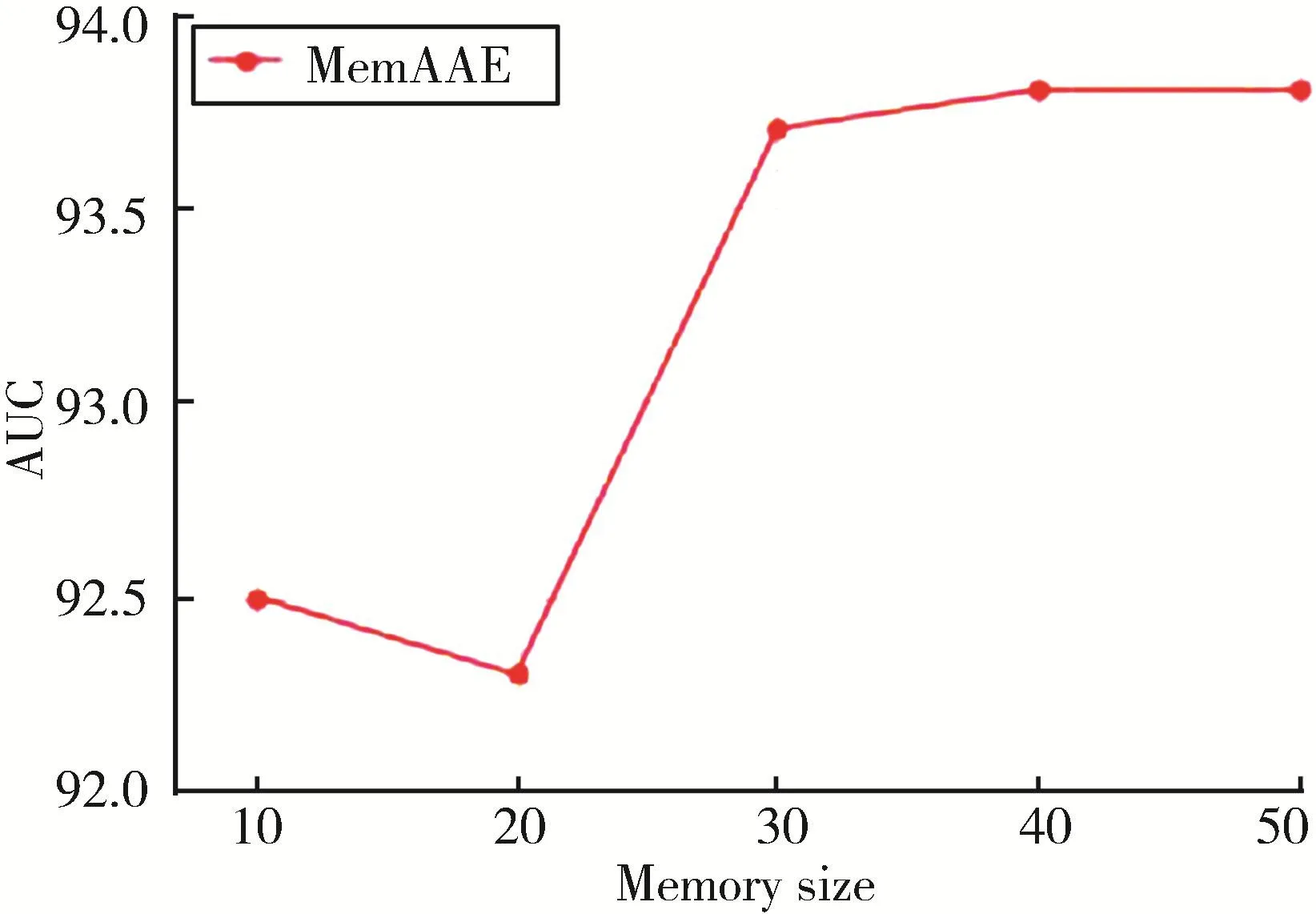
图5 记忆增强模块的大小设置为不同的值对实验结果的影响
如图4所示,根据Thyroid数据集训练过程中重构损失的变化图像,MemAAE模型在训练初始阶段的重构误差远大于MemAE,但是其损失的下降速度远大于MemAE模型,在大约10次迭代之后两者的重构损失开始趋于稳定并且收敛值大致相同。这表明MemAAE模型增加了对抗训练过程之后,会影响训练初始过程的重构损失,但对于收敛速度和收敛值的影响较小,证明本文提出的改进方法的有效性。通过改变记忆矩阵维数这个超参数,对MemAAE模型的鲁棒性进行研究,如图5所示,对于文本异常检测数据集,随着记忆矩阵维度的增加,模型的AUC值将趋于稳定,说明当记忆矩阵维度大于某一阈值时,MemAAE对于这个超参数的设置并不敏感。
3.3.2 图像数据
为了验证MemAAE模型在图像数据集上依然有着良好的表现,选择MNIST数据集进行实验。为了验证本文提出的改进方案的有效性,选择以下异常模型作为对比。
一类支持向量机(One Class Support Vector Machine,OC⁃SVM)/支持向量数据描述(Support Vector Data Description,SVDD)[26]通过将数据映射到高维特征空间中学习正常数据的边界,测试时将处于边界之外的数据视为异常数据。
深度支持向量数据描述(Deep Support Vector Data Description,Deep SVDD)[27]将原 SVDD 利用核函数提取特征改进为利用神经网络提取特征,将正常样本收缩于超球面,异常样本远离超球面。
孤立森林(Isolation Forest,IF)[28]将异常定义为远离高密度数据的容易被孤立的样本,该算法通过多次随机分割数据集直至所有样本点孤立,而异常样本相较正常样本可以通过更少的次数被分割孤立。
深度卷积自编码器(Deep Convolutional Autoen⁃coder,DCAE)的编码器采用了与Deep SVDD一样的神经网络结构,解码器采用对称结构,通过最小化均方损失误差进行训练,利用重构误差作为异常程度的判别标准。
AnoGAN[29]是一种利用GAN网络实现异常检测的方法,该模型对于给定的任何数据实例x,它的训练目标是在生成网络G学习到的潜在特征空间中搜索实例z,使得相应的生成实例G(z)和x尽可能相似。异常分数由测试样本与生成实例的重构误差以及判别器的判别分数组成。
对于MNIST数据集,将10个数字分别视为正常数据,训练相应的异常检测模型。以上的异常检测方法在该数据集上的测试结果如表3所示,其中加粗结果为该数据集在不同方法下取得的最优结果。
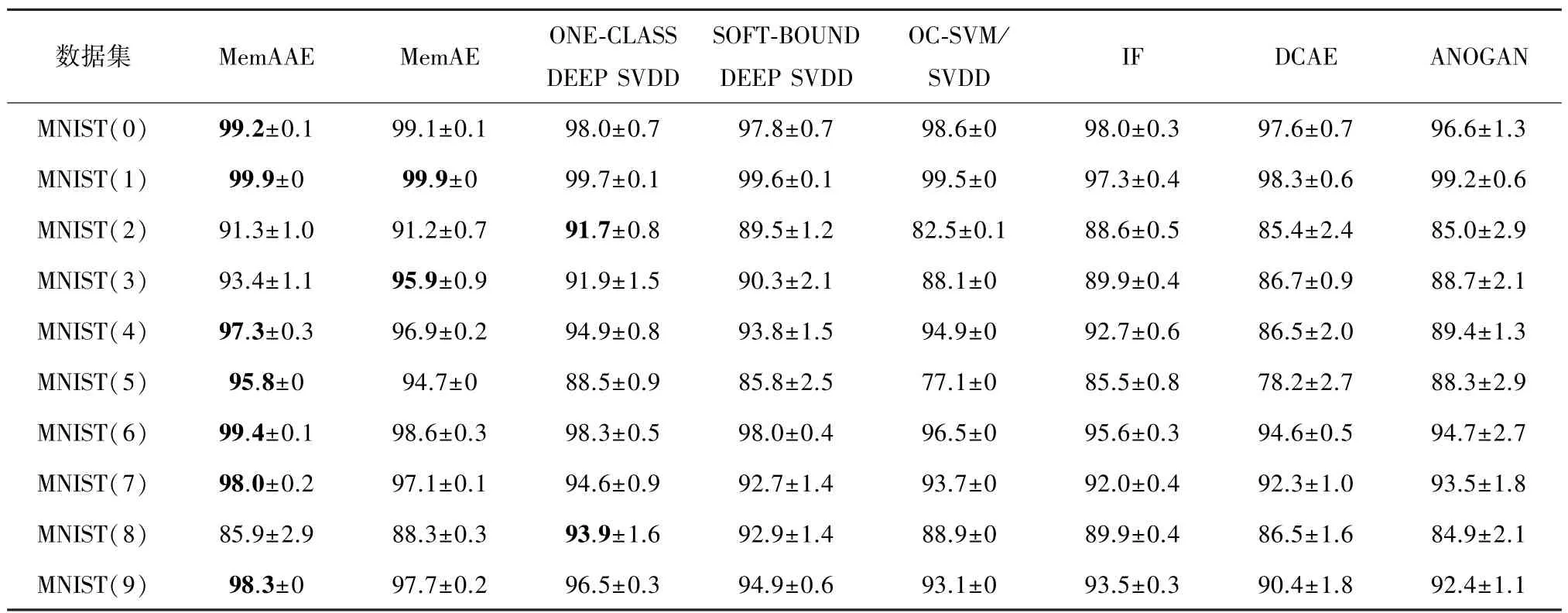
表3 各异常检测模型在MNIST数据集上的结果比较
如表3所示,本文所提出的MemAAE模型在MNIST数据集的7个数字上取得了优于其他方法的性能,表明了MemAAE模型在图像数据集上依然能够有良好的表现。与MemAE模型相比,对抗训练过程的引入使得编码器和记忆矩阵输出的编码向量符合某一先验分布。此时的解码器可以视为生成式对抗网络的深度生成网络,它可以将服从先验分布的隐向量重新映射回原始的数据空间,重构误差可以作为判别输入数据是否为异常的依据。由实验结果可知,对抗过程的引入一定程度上提高了检测性能,证明了本文所提改进方案的有效性。
为了观察引入对抗训练对于自编码器训练过程产生的影响,以MNIST数据集中数字1的训练过程为例进行对比,两个模型保持结构、参数相同,训练次数设置为100次。最终自编码器训练过程中的重构损失如图6所示,可以看到MemAAE模型在训练初期的重构损失远大于MemAE模型,但其训练损失下降较快,最终收敛的重构损失稍大于对比模型。图7(a)显示了判别器通过最小化式(10)所示的判别损失提高判别能力的过程,此阶段自编码器不参与训练过程。而图7(b)则展示了编码器参与训练过程,判别器对应的判别损失随迭代次数增加的变化曲线,判别损失的计算如式(12)所示。由此可知,判别器的判别损失在大约40次迭代后开始趋于稳定,表示此时的编码器能够使得输出的编码结果与某一先验分布相匹配,证明了本文引入对抗训练过程的有效性。
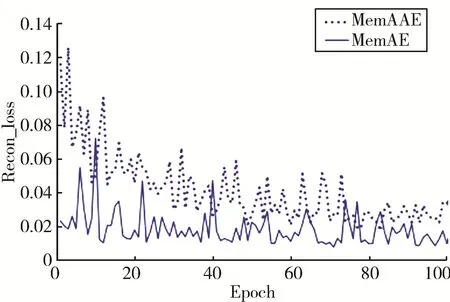
图6 训练过程中重构误差变化曲线的对比
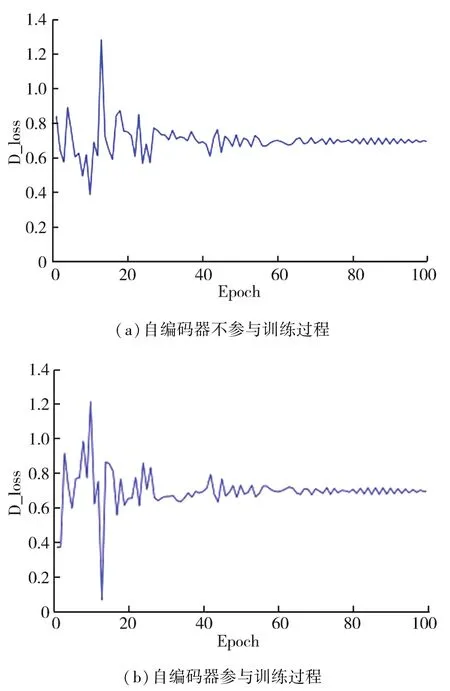
图7 MemAAE模型的判别器在训练过程中判别损失的变化曲线
同样地,为了研究记忆模块大小对于实验结果的影响,将记忆矩阵大小分别设置为不同的值进行实验,最终的结果取5次实验的平均值。如图8所示,当记忆矩阵的大小为100时,AUC值最高,获得最佳结果。综上,MemAAE模型在图像数据集上的结果表明模型对于记忆增强模块大小设置的敏感性,这与模型在文本数据集上的表现不同。
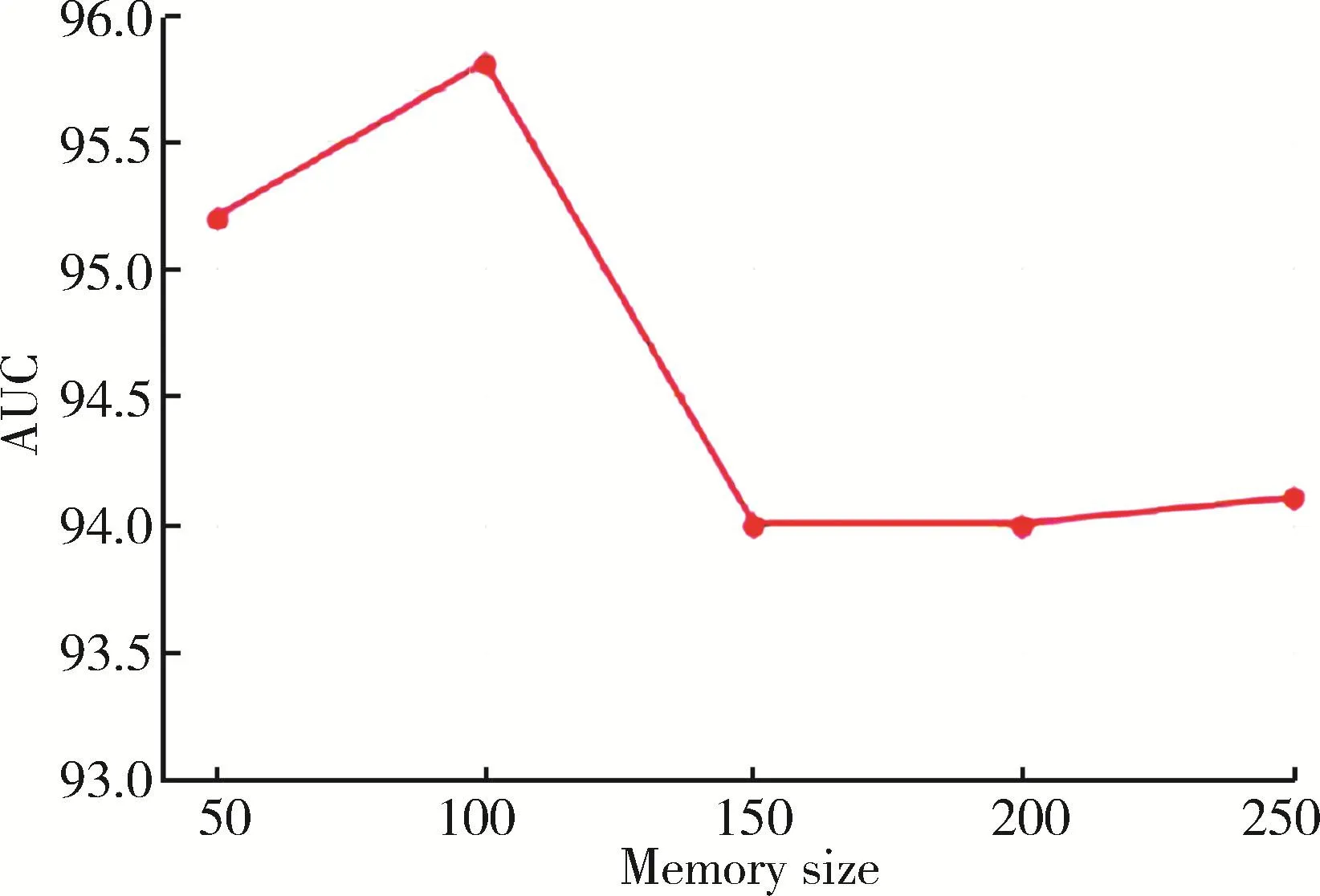
图8 记忆增强模块的维数设置为不同的值对实验结果的影响
4 结束语
针对已有基于记忆增强的自编码器异常检测模型不能很好地重构输入数据的问题,本文提出了基于记忆增强的对抗自编码器异常检测模型。在多个公共数据集上的实验结果表明了MemAAE模型在异常检测领域的有效性。其中针对图像数据集的实验结果说明将卷积神经网络与AAE网络相结合依然能够取得良好的结果,拓展了AAE的模型结构与应用范围。在未来的研究工作可以针对模型训练过程中的不稳定问题进行改进,另外可以进一步拓展MemAAE模型的实际应用场景。
猜你喜欢
摄影世界(2022年1期)2022-01-21 10:50:14
知识经济·中国直销(2018年12期)2018-12-29 12:22:14
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
商周刊(2017年6期)2017-08-22 03:42:36
电子设计工程(2017年20期)2017-02-10 03:39:29
山东大学法律评论(2016年0期)2016-08-16 03:24:12
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
电子器件(2015年5期)2015-12-29 08:42:24
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
