
商用车用户使用工况数据采集路线策划研究
2021-02-24 07:10陈世栋张立博连俊锋何思泉王连磊
汽车工程学报 2021年1期
陈世栋,张立博,连俊锋,何思泉,王连磊,郑 勇
(北汽福田汽车股份有限公司 工程研究总院,北京 102206)
商用车作为重要的运输工具,在可靠性、耐久性、油耗和排放等方面都有很高的要求。为了确保性能指标在满足特定测试条件下的要求的同时,也能满足一般用户工况条件下的使用要求,制造商必须在实际使用情况下测量和验证其车辆的性能。因此,制造商会使用特定路线(如工厂附近)来采集耐久性载荷(车轮和悬挂力、加速度、应变等)数据,测试发动机排放和油耗情况,或进行耐久性测试。根据长期的经验,固定路线采集的结果在某种程度上与车辆在现场的性能相关。例如,耐久性特定线路上的负荷密度是平均现场使用的3 倍,或者在相应线路上测量的油耗量接近现场的预期平均值[1-2]。
然而,现有的路线存在许多缺点,如无法复现真实使用情况,不能适应新概念汽车或新市场的测试要求等。这使评估现有路线是否科学合理和定义新路线成为一项重要的研发任务。
为了完成上述科研任务,需要开展以下4 项工作:(1)确定与耐久性或油耗有关的所有运行状态。通过建立要素模型的方式列出运行状态的影响量和级别,如有效载荷(空载或满载),道路类型(一般道路、城市道路、高速公路),地理地势(平路或起伏路、直路或弯曲路)等。(2)要确保一条路线能够充分提供所有这些状态。(3)了解运行状态在市场和特定用户群中的分布情况,建立相应的用户模型。(4)将在参考路线上测得的结果外推到实际应用中的车辆性能,必须通过对路线各路段的适当加权来利用这种用户模型。
本文未完全论述上述工作的整个过程,仅集中在以下两个方面开展研究:(1)基于VMC 软件,利用现有的地理参考信息,分析特定区域或市场状况,寻找具有代表性的路段子集,使其充分覆盖所有特定区域或市场用户的行驶路线。(2)建立要素模型并计算采集里程,利用前文得到的路段子集确定一条试验测试路线。
本文最后对商用车用户使用工况采集路线策划方法进行了总结,并对耐久性载荷和油耗应用给出了更多的建议,如用于耐久性相关车辆载荷测量的路线策划。
1 地理参考分析
1.1 分析方法概述
利用德国ITWM 公司的VMC 软件进行道路数据分析,该软件中数据库的基础层是道路网络,包含了各个国家、地区的驾驶规则和限制以及交通标志、交叉路口等法律数据。此外,还提供了诸如居民区、工业区或森林等土地使用信息,并且能够提供不同来源(卫星数据或其它特定来源)的高度、道路质量或交通信息[3]。基于该软件定义规则如下。
1.1.1 路和路段的划分
某个区域的路网由“路”和“路段”组成。“路”是具有唯一道路类型和编号的最大长度的连续“路段”。例如,“G6 高速公路”为一条长达数千公里的“路”。它的道路类型是“高速公路”,它的道路编号是“G6”。然而,道路类型和编号会随着城乡属性的变化而发生改变。在乡村,特别是在城市,“路”通常要短得多。由于弯道或坡度等性质可能会随道路而改变,所以较长的“路”被分为更短的“路段”。根据道路类型不同,最长路段(即道路片段)的长度规则为:高速公路为10 km,一般道路(国道和省道)为5 km,城市道路和乡村公路为2 km。
1.1.2 坡度定义及路段信息表
上文所述路段包含长度、道路类型、路段上所有道路节点的坐标、单行道、红绿灯等信息。根据需要,对沿路段纵切面方向的斜率进行度量,得到坡度分数(通常为“高、中、低”3 个水平)。将路段信息进行统计制表后形成“道路统计表”(表1),通过该表可以对区域和路线进行比较,检查路线是否覆盖所有感兴趣的道路工况状态,得到道路间相似性或差异性的量化比较结果。
1.2 中国路网分析
通过VMC 软件并应用本文1.1 所述的分析方法,可以得到全国各省的各类型道路总长,再按地区进行统计分类,得到各道路类型总长统计结果(表1 和图1),以及各地区道路类型占比,如图1 和图2 所示。由结果可知,华东地区的道路总长最长,东北、华南、华中地区道路总长较短;各地区道路类型占比有差异,总体呈现省道、国道和县道占比较大,高速路和城市路占比较小。
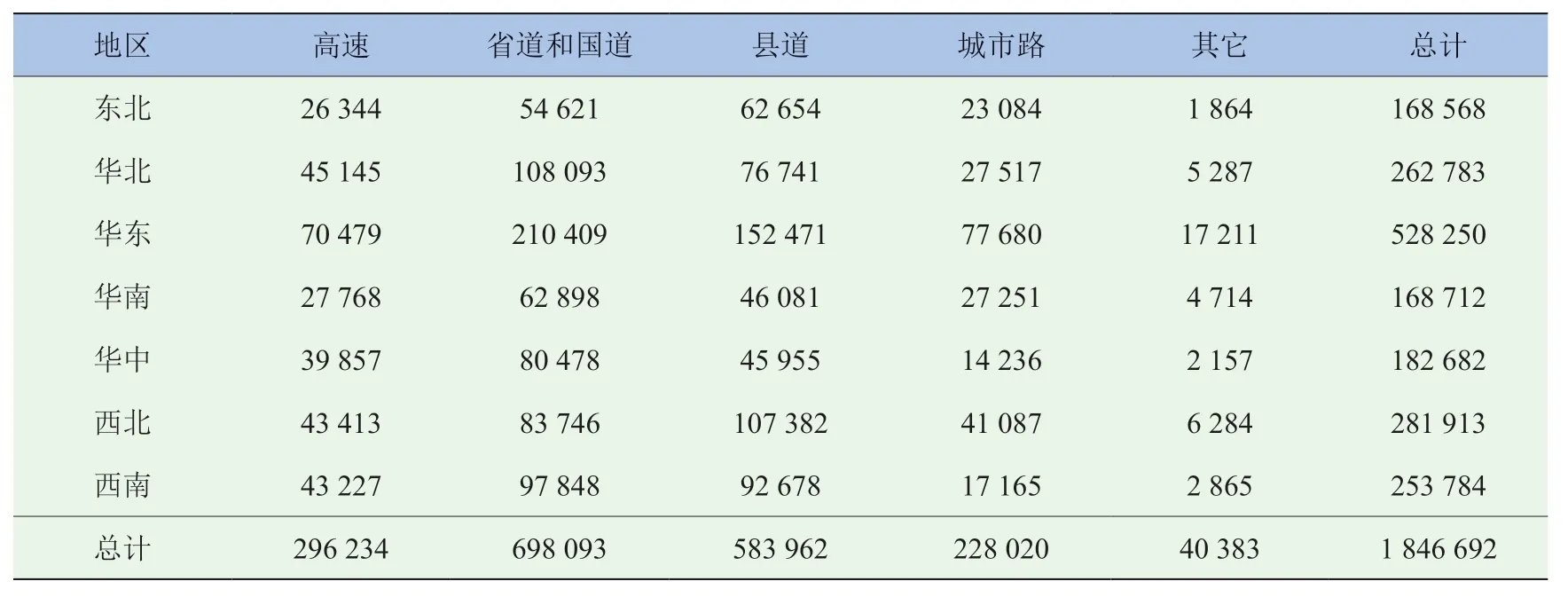
表1 中国道路网络统计表(按地区) 单位:km

图1 中国道路网络统计(按地区)
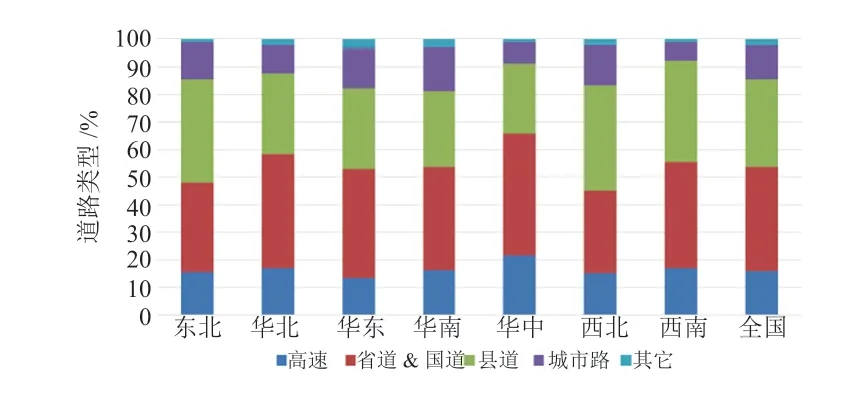
图2 中国道路特征分析(按道路类型)
1.3 中国道路特征分析
根据不同的道路类型,给定不同的判定规则(如坡度和曲率),可以将道路再分为坡度和弯度两个维度,每个维度两个水平,即坡道、平坦路和弯道、直道。可以通过某区域坡道(图3)与弯道占比(图4)来评估该区域道路的多样性情况,坡道占比和弯道占比越大,道路越复杂,涵盖路况更丰富。由图可知,西南地区(云南、贵州、重庆等)的坡道和弯道占比较大,地理地形最复杂;华北(河北、河南、天津等)、华东地区(上海、江苏等)坡道和弯道占比较小,地理地形相对简单。

图3 中国道路特征分析(坡度)
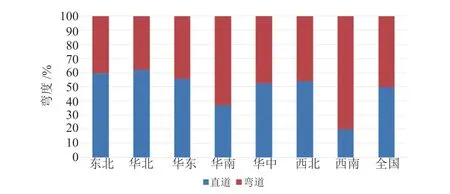
图4 中国道路特征分析(弯道)
2 路线策划
2.1 要素模型
通过要素模型的方式,将现场使用工况进行划分,得到定量的影响量和分布情况的数值,从而使采集的数据能够覆盖所有道路类型、道路质量、载荷状况及驾驶习惯等工况,并且确保采集量能够充分保证数据外推的质量。
上文所述的要素模型是特定车型所有操作状态定义和标记的一个DOE 结构表(表2),包含了所有相关[这里的“相关”意味着该要素对我们感兴趣的功性能产生了影响,在本文中指的是“整车耐久性(伪损伤值)”]的要素,这些要素可以准确地进行控制和描述,如道路类型、坡度、弯度、载荷和驾驶风格等,每个要素都被划分成多个不连续的要素水平(或级别)。本研究中的要素水平为:3 种道路类型(将国道和省道合并,统称为“一般道路”),2 种坡度级别,2 种弯度级别,2 种载荷和2 种驾驶风格。各要素水平组合(单元或操作状态)的个数为:3×2×2×2×2=48 个[4]。每辆车(无论怎样使用)将会经历所有不同的操作状态。为简化试验,忽略了驾驶风格的影响,设计了如表2 所示的要素模型DOE 结构表。数据采集结束后,根据1.1节中的分析方法,将采集路线按照最长路段以及上述要素模型,分成不同操作状态下的道路片段。

表2 要素模型DOE 结构
通过市场销售数据,不但要确定车型主销区域(即测试重点关注区域)和车辆类型,还要确定采集样车的具体车型和配置。
以主销区域、货物类型和用户分布情况为基础,在全国范围内随机地按一定权重选取目标用户采集TBOX 数据,采集数量不少于200 条,采集时间不少于1 个月。采集的信息包括:车辆行驶车速、GPS 信息、车辆状态以及驾驶员操作状态等相关信号。通过下载、筛选提取与用户使用特征相关的数据,并分析出道路类型、车速分布、行驶里程及时间、驾驶习惯等定量化的信息。
通过典型用户调研,收集典型用户群体的货物类型、载荷状态及驾驶风格等信息。调研地点选择特定车型的主销区域,针对目标用户设计调研问卷,问卷的内容包含与关注工况相关的影响因素(如货物类型、载荷状况、行驶里程及道路类别等)。调研完成后,统计出货物类型、载荷比例、道路类型比例等关键要素信息。将收集的信息与表2 要素模型对应并以百分比的形式进行量化,以便形成用户模型。
2.2 最小测试里程计算
2.2.1 道路片段损伤(或油耗)值的预期变化
固定一种车辆操作状态,例如以满载和普通驾驶风格在高速公路上行驶。在该操作状态下,在对等长度l0的许多道路片段k=1, 2, 3,…,N上测出的一个信号,并计算它的损伤(或油耗)值Xk,Xk因道路质量和交通影响等不受控制的要素而变化。可以计算对数损伤(或油耗)值的标准差,这取决于道路片段的长度l0。当l0=1 km 时,对于大多数被测信号,基于以往的测试经验,期望和=1.5 之间变化。值的大小取决于操作状态的多少,操作状态越多,则对应的越高。
2.2.2 确定最小采集距离
想要估计Xk的分布情况,即中位数(50 百分位,q50%)以及一些更高的百分位qp(如p=90%),需要采集足够数量的数据样本,假设对数损伤值Xk是正态分布的,计算qp的置信区间,并推导出qp估计值的不确定度:

式中:Rqp为qp百分位下的不确定度,如Rqp=0.5=50%,代表qp可以估计达到50%的不确定度;α为显著水平;N为测量数据段个数,当l0=1 km 时,N为最小测试里程数。
以上理论仅用于粗略估计。当显著水平α≈30%时,,则式(1)简化为:
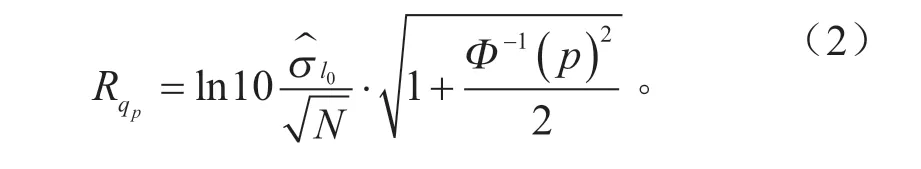
当l0=1 km时,对数损伤值的标准差=0.7~1.5。当l0变化较大时,=1.5,对应50百分位(q50%)和90 百分位(q90%)下不确定度Rqp和所需最小测试里程可参照图5 中的数值进行选择。
2.2.3 要素模型的应用
2.2.3.1 载荷和驾驶风格—短距离路线
通过以不同级别的载荷和驾驶风格,对同一路线(短距离路线)进行多次行驶测试,计算出不同级别载荷和驾驶风格的损伤值[5]。固定一种载荷和驾驶风格进行全国路线采集测试后,通过转换因子得到其它级别的载荷和驾驶风格组合的相应数据。为了获取某采集路线的长度,需充分准确地估计中位数(q50%)最小测试里程。假设3 个道路类型级别(城市道路、国家道路和高速公路)充分准确,接受q50%存在25%的不确定度,则根据图5 可以得到短距离采集路线的总长度为3×200=600 km。
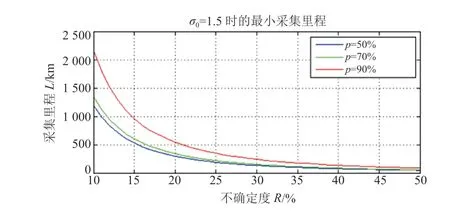
图5 不确定度对应测试里程关系曲线
2.2.3.2 道路类型、地形地势和区域—长距离路线
在固定一种载荷和驾驶风格的情况下开展全国采集路线策划,通过采集数据外推的方式可以获取特定用户的载荷分布情况。例如,使用3 个级别的道路类型和2 个地形地势水平,并且考虑分析3 个区域的影响时,可得到3×2×3=18 个操作状态。选择接受q90%存在20%的不确定度,根据图5 所示,可以得到全国采集路线的总长度为18×550=9 900 km。
2.3 路线选择
根据2.2节中描述的要素模型和路线里程结果,设定北京为起始点,结合1.3 节中国道路特征分析的结论,将西南地区作为重点关注区域纳入本次路线策划中,筛选出以下可供选择路线(图6~8),3 条路线的总长分别为:28 707 km、15 293 km、14 803 km,满足计算最小测试里程的要求。
分别对3 条策划路线的道路类型、起伏路占比和弯曲路占比情况进行统计分析,得到表3 所示的结果。根据道路类型分布对比结果,路线B 和路线C 的各道路类型占比情况与全国的比例相当,适合通用物流类型工况道路载荷和油耗数据的采集;起伏路和弯曲路分布的对比结果显示,路线B 与路线C 的起伏路和弯曲路占比相对比例较高,表明地理地形变化相对复杂;相对于路线C,路线B 的区域覆盖面更广,且包含本次采集关注的东部地区,便于提高路线多样性;此外,路线A 涉及的采集区域虽广,但存在连通性差的问题,不利于采集工作开展。基于上述原因,最终选择路线B 进行全国通用物流类型工况耐久性载荷谱和油耗数据采集。

图6 策划路线A

图7 策划路线B

图8 策划路线C

表3 策划路线道路特征分析
4 结论
本文论述了在采用特定路线开展油耗测试和整车耐久性载荷谱采集试验时存在的问题,提出一种全新的商用车用户使用工况采集路线测试方法,创新性地提出了路和路段的概念,在此基础上,建立了要素模型并对商用车用户使用工况数据采集路线进行了策划。重点论述了要素模型的建立和最小采集里程计算的方法,通过将道路类型及操作状态进行细分归类的方式建立特定用户工况的要素模型;建立了最小采集里程的计算模型,得到显著水平为30%时,q50%和q90%分布值与不确定度的对应采集里程曲线;策划形成了以北京为起点,涵盖地理地形复杂的中国西南地区的3 条测试路线,通过对道路类型、起伏路和弯曲路占比等情况进行分析,确定了适合全国通用物流类型道路载荷和油耗数据的采集路线。
通过本文的论述,形成了一套系统的商用车用户使用工况采集路线策划方法,为车辆伪损伤和油耗分布估计,以及试验场道路关联计算和车辆油耗特征统计提供科学的数据支持。路线片段数据的伪损伤、油耗计算以及要素模型修正等作为本文的非重点内容,未做详细论述,将在后续研究中进行完善。
猜你喜欢
水上消防(2022年2期)2022-07-22
北京航空航天大学学报(2021年9期)2021-11-02
舰船科学技术(2021年12期)2021-03-29
舰船科学技术(2021年12期)2021-03-29
学苑创造·B版(2019年11期)2019-12-05
小猕猴智力画刊(2018年3期)2018-06-12
小学生导刊(低年级)(2016年8期)2016-09-24
消费者报道(2014年13期)2015-03-19
人民交通(2009年1期)2009-01-19
