
BiLSTM_DPCNN模型在电力客服工单数据分类中的应用①
2021-02-23 06:30田秀霞
计算机系统应用 2021年2期
李 灿,田秀霞,赵 波
(上海电力大学 计算机科学与技术学院,上海 200090)
电力客服系统作为供电企业与电力客户交流的窗口,不仅为电力客户提供了便捷的服务,还直接客观地反映客户用电诉求[1,2],其工单数据记录着电力客户对供电企业的诉求信息,根据工单信息描述,准确地定位用户所属类别,有利于提升客户满意度.目前对工单数据的分析方式,主要是由调查人员通过对用户诉求数据的分析,来判别用户需求信息所属的服务类型[3,4].这种方式缺乏有效的分析方法,严重影响信息分析和解决问题的效率,直接影响到电力系统的高效运行和发展[5].因此,找到一种高效的工单分类方法来实现对工单数据进行自动、准确的分类,是电力客服系统亟待解决的主要问题[1].
传统的工单分类,主要是采用特征工程和机器学习方法相结合的方式[6].林溪桥等[7]分析各种类型工单的出现规律,结合主成分分析方法,实现客服工单分类模型的优化.Sun 等[8]利用中文数据挖掘的方法,对停电工单进行分析,并结合支持向量机(Support Vector Machine,SVM)构建了故障案例句子分类模型.上述分类模型虽然有着结构简单,训练速度快的优点,但在分类过程中,依赖于特征工程的选择,模型分类效果表现不突出.
近年来,神经网络技术被广泛应用到文本分类任务中[9].谢季川等[10]使用Word2Vec 语言模型训练电力工单数据,得到电力文本词向量,最后构建多分类文本模型,实现95 598 电力工单分类任务.刘梓权等[11]通过分析电力设备缺陷记录,构建了一种基于CNN的电力缺陷文本分类模型.受以上启发,我们将CNN 网络用于工单数据的分类中.然而,分类的效果并不理想,这是因为工单数据存在依赖性强、冗余度高的特征,传统的CNN 网络在处理这些数据时遇到以下问题:
(1)文本表示:由于数据的高依赖性,在特征文本表示时,要考虑前后词语间的语义关系;
(2)特征提取:在句子高级建模阶段,使用CNN 网络只能捕获局部的语义信息,造成隐层语义信息丢失.
为了解决上述问题,本文将BiLSTM 与CNN 混合的神经网络应用到工单分类的任务中,该模型充分利用了BiLSTM 递归序列模型学习句子中的全局语义信息的特点;CNN 结构可以通过卷积运算,挖掘句子局部语义特征的优势.本文从以下3 个方向入手,并进行创新:
(1)词向量标准化:对词向量作标准化处理,去除噪音,加快网络训练收敛速度,提高分类精度;
(2)稀疏特征提取:由于数据稀疏性,包含大量的边际信息,为了提取边际有效信息,利用BiLSTM 代替RNN;
(3)特征融合:本文在卷积网络上进行改进,克服了Max-Pooling 丢失特征信息的问题,保留了强特征词信息,捕获全局深层的隐层语义信息.
1 相关工作
文本分类是将待分类文本数据合理地划分到相应的类别中,是有监督学习的过程.工单文本也是文本分类中的经典问题,通过分析文本特征,本文所采用的文本分类算法是基于BiLSTM 神经网络和CNN 网络这两种模型.以下分别对实验中所涉及的相关技术进行介绍.
1.1 向量模型
2013年,Hinton 提出了Word Embedding 概念,Word Embedding 方法将单词映射到向量空间,不仅可以避免“维度灾害”问题,还能从更深层学习词与词之间的语义信息[12].与此同时,Mikolov 等[13,14]提出了Word2Vec 框架,该神经网络语言在语言训练时,考虑上下词语义间的相关性.基于Word2Vec 模型解决了传统的文本表示中数据稀疏和语义鸿沟的问题[15,16].本文实验部分,采用上述神经网络语言模型得到文本的向量表示.
1.2 BiLSTM 神经网络
循环神经网络LSTM 网络是RNN 网络的扩展,它解决了传统RNN 网络中梯度消失或爆炸问题[17].使用LSTM 网络可以学习到当前文本过去的信息,但无法编码从后到前的信息,因此出现了BiLSTM 神经网络可以更好的捕捉双向的语义依赖[18,19].网络的结构通常包括3 部分:输入层、隐藏层和输出层.BiLSTM 单元示意图,如图1所示.
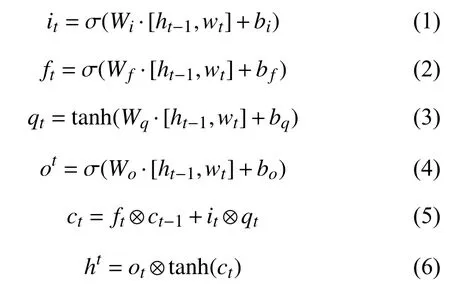
上述计算公式为经过LSTM 三个门信息保留计算表达式,其中,Wj是权重矩阵,bj是偏差向量,j∈{i,f,q,o}·⊗表示逐点相乘,σ是激活函数.ft决定哪些信息需要从单元状态中丢弃,it决定哪些值需要更新,ot决定模型的最终输出.
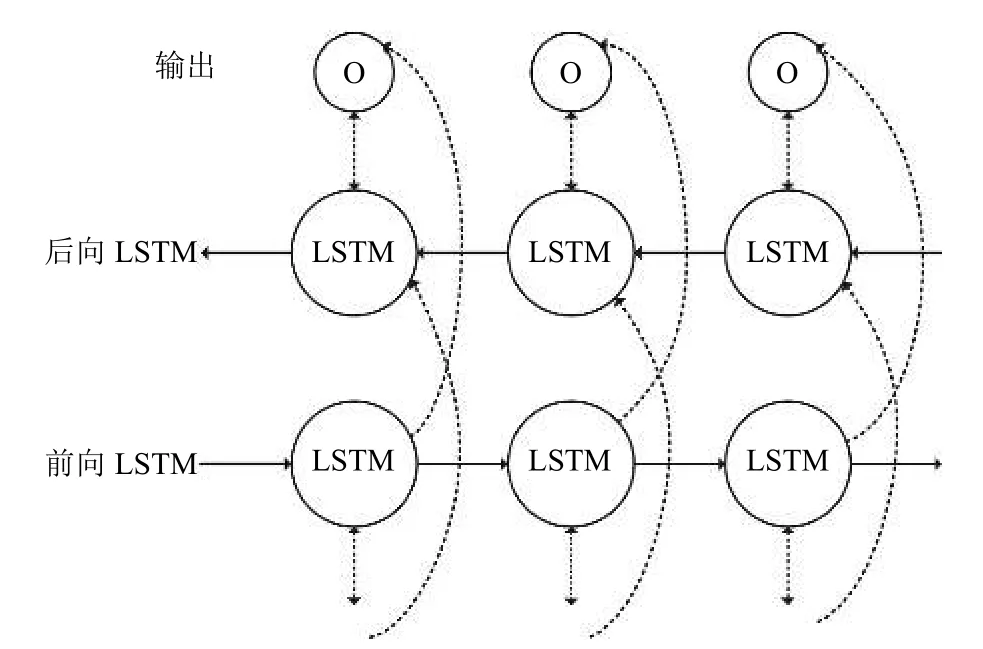
图1 BiLSTM 单元示意图
本文实验中使用BiLSTM 网络是由两个方向的LSTM 组成,使用前向和后向LSTM 网络可以学习句子的上下文信息,得到全局的句子语义信息.
1.3 卷积神经网络
TextCNN是一种前馈神经网络,最初应用于计算机视觉,在图像处理中有突出的表现[20].随着深度学习的发展,CNN 被广泛应用自然语言处理的任务中,如文本分类、情感分析等[21,22].
TextCNN 网络结构主要包括卷积和池化层,实现过程如下:首先,将卷积层输出的特征向量分别输入最大池化层;其次,将池化的输出结果拼接表示最终的句子特征向量.为了提取不同位置的局部信息,实验中同时使用多个通道和不同卷积核大小进行卷积操作.其结构图2所示.
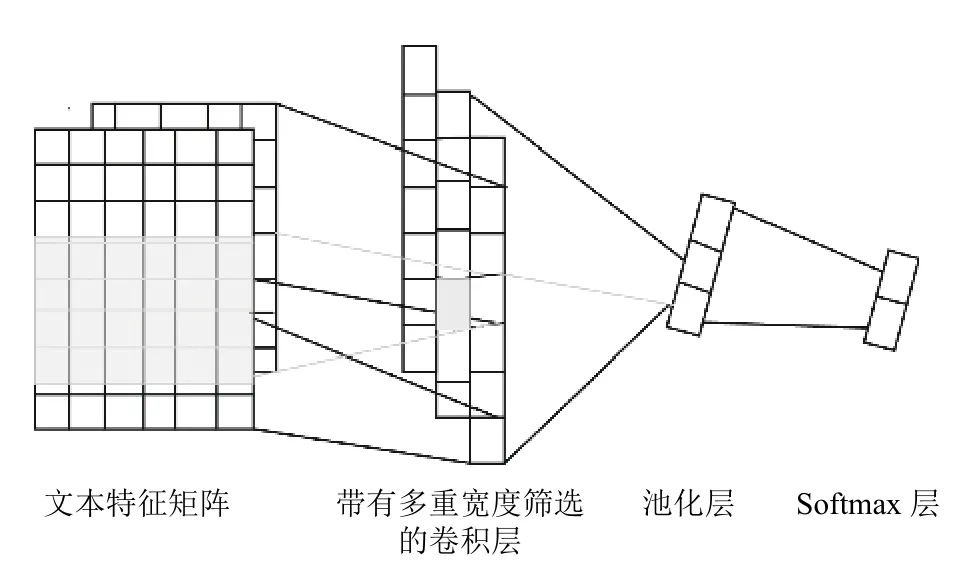
图2 TextCNN 网络结构示意图
设给定矩阵W∈RM×N,卷积核F∈RM×N,且m≪M,n≪N,则卷积的表达式如(7)所示:
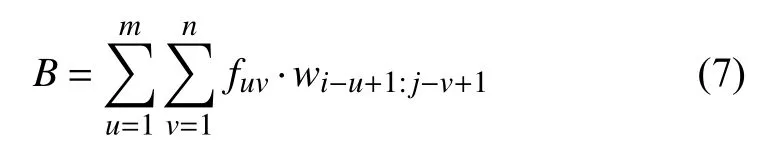
B表示卷积后的结果,卷积后得到由句子局部信息构成的特征矩阵,输入到Max-Pooling 层提取整个矩阵中最大值,作为当前通道的特征信息,再与其他通道的特征信息融合,得到多通道组合筛选后的句子特征向量.
2 模型架构与算法设计
考虑到传统CNN 网络在工单分类中不足,而BiLSTM 神经网络在文本分类中可以很好地提取上下文信息,在高级语义建模阶段,CNN 网络可以凭借多通道组合筛选,对句子进行二次特征提取,从而得到句子特征向量.鉴于以上两种模型的优点,本文在BiLSTM+CNN 组合网络的基础上进行优化.即在TextCNN 网络层中采用双池化操作,我们称之为双池化的卷积神经网络(Double Pooling Convolution Neural Network,DPCNN),并将优化后的组合模型应用到电力客服工单数据的分类中,其模型结构如图3所示.整个分类过程从左向右,包括文本向量化表示和训练BiLSTM_DPCNN分类器两部分,以下按模型的搭建过程逐一论述.
2.1 向量的优化表示
在以往的模型训练过程中,都是直接将训练出的文本词向量输入到模型中,这种方法导致模型难收敛,分类准确率低.究其原因,主要是因为短文本数据的高稀疏性,不同词的出现频率不同,对于一些高特征词出现频率较高,同时也存在边缘流特征信息.这将使得到词向量的权值存在较大的偏差,分布不均衡.
为了解决上述问题,本文实验中采用Word2Vec 模型训练以字为单位的词向量的前提下,并对词向量进行标准化处理,达到降噪效果.首先,遍历词汇表,统计每个单词出现的次数,计算其频次;其次,计算所有词的权重误差;最后,采用标准化处理,得到均值表示的词向量.再把处理后的词向量作为训练模型的输入,具体计算公式如下:
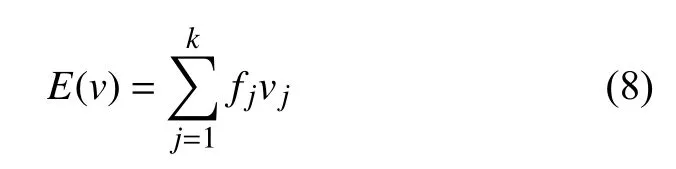
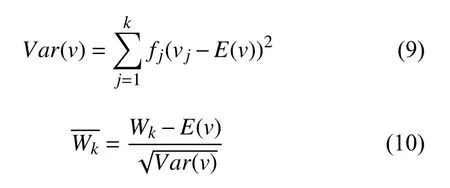
其中,fj表示单词出现的次数,k表示词的个数,vj表示对应词的权重.经标准化后的词向量,其范围固定在一个固定值之间,弱化某些词向量的权重值过大对模型的影响.加快网络的收敛速度,提高模型的分类精度.
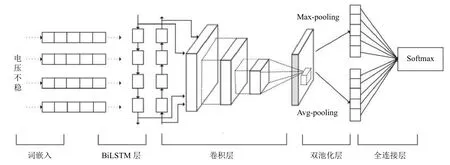
图3 基于BiLSTM_DPCNN 混合神经网络模型
2.2 BiLSTM_DPCNN 分类模型
实验中所采用的BiLSTM_DPCNN 组合模型的思想,充分利用了各个模块的优点.首先,待分类文本经过数据预处理后通过Embedding Layer 层把单词表示成模型可以识别的文本向量.再利用BiLSTM 网络提取句子特征语义信息,由于文本在处理时,调用Keras库提供的pad_sequence 方法将文本pad为固定长度,因此在BiLSTM 输出时乘以MASK 矩阵来减小pad带来的影响.最后,将BiLSTM的输出作为改进CNN网络的输入,进行二次特征提取,最后实现分类.
BiLSTM_DPCNN 模型由输入层、BiLSTM 层、卷积层、双池化层、分类输出层五部分组成.以下详细介绍每一层的实现过程.
首先,采用BiLSTM 网络学习每个字的向量语义,BiLSTM 因其双向计算的特点,可以获取目标序列的“左序列”和“右序列”的文本信息.具体计算公式如下.
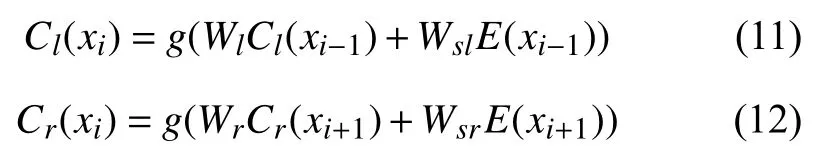
其中,Cl(xi)表示左边的文本向量,Wl是一个从当前隐藏层到下一隐藏层转换的Wsl矩阵表示连接当词的左文本的语义信息.Cl(xi−1)表示前一个词的左边文本信息,E(xi−1)表示前一个词的字向量.同理,可计算xi的右文本Cr(xi).
根据式(11)、式(12),得到当前字xi的向量表示.计算公式如下:
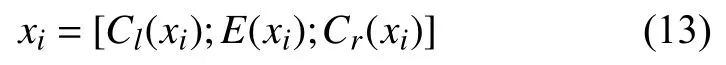
其次,把BiLSTM 网络层输出的句子特征矩阵输入到卷积层中进行卷积操作,提取深层语义信息.经卷积操作后,使用双通道池化进行特征筛选,进而提取句子特征矩阵中相邻文字的关联特征,其中池化部分的具体计算公式如下:

其中,cmax表示最大池化的输出,cavg表示平均池化的输出,⊕表示拼接运算,h表示滑动窗口大小.该方法弥补了由于每次最大池化操作只能取一次最大值,从而丢失强特征词信息的缺点.将两个池化操作的结果进行特征融合,保证了文本特征信息的完整性,得到的更全面的、深层次的句子特征.
最后,由双池化层提取到句子的特征表示作为Softmax 层的输入,分类过程的具体计算公式所示:
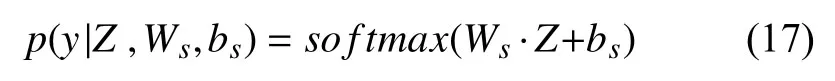
其中,y∈{0,1},Ws∈R|Z|,bs代偏置项,Z表示句子特征矩阵.
2.3 模型算法流程
BiLSTM_DPCNN 组合模型的算法过程如算法1.

算法1.BiLSTM_DPCNN 模型训练过程1)初始化模型参数配置,设置每批训练量batch_size和总迭代次数epochs;2)将由标准化后的字向量表示的句子信息输入到BiLSTM 网络层中,提取全局句子语义信息;3)将第2)步的输出句子矩阵输入到DPCNN 网络中,通过卷积操作,进一步捕获局部语义信息;4)将第3)步中卷积后的结果分别输入到双通道池化层进行降维操作,并将特征融合;5)将第4)步融合后文本向量经过矩阵的concat和reshape 之后送入Softmax 分类器,输出类别标签;6)模型训练过程中,采用mini-batch的梯度下降法进行训练,训练过程中保存最优的模型,减少再训练过程中的开销;7)重复2)~6)步,设置epochs=50,若训练集的精度不在上升,则提前结束训练.
实验中batch的大小设置为30,能够获得较好的效果,则所有参数θ的计算公式如下所示.

其中,λ表示学习率.
3 实验设计及分析
3.1 实验环境
本实验基于Python 编程语言和Tensorflow 1.8.0深度学习框架展开,主要参数配置CPU:Intel Core i9-9900 K;内存:32 GB;操作系统:Windows 10.
3.2 数据来源和预处理
在本次实验中采用来自电网公司客服工单记录的真实数据,数据主要记录客户对电力公司的用电反馈信息.其中每条工单数据以短文本的形式记录着工单类别及相应的信息反馈,共分为停电、安全隐患、停电未送电、电压不稳、缺相、供电故障、用户资产故障7 个工单类别,下述分别用C1~C7命名.所有数据都经过数据清洗和停用词过滤,实验中将数据集划分为训练集、验证集和测试集,其比例为3:1:1.
3.3 模型超参数设置
模型中主要参数包括字向量的维度d,滤波器的个数m等,另外BiLSTM 层中隐藏层层数为2 层,神经元个数256 个.模型最优参数设置如表1所示.
3.4 评估指标
由于工单数据是多分类问题,工单类别分为7 类,采用查准率(P),召回率(R),F1 值(F1)和宏平均(Macro_F1)等4 个指标,对分类的准确度进行评估,其计算公式如下:

其中,V表示工单类别个数,TP表示正确的标记为正,FP错误的标记为正,FN错误的标记为负,TN正确的标记为负.

表1 模型参数配置
3.5 对比实验设置
实验中设置以下几个分类模型来评估本文模型,通过对比模型验证BiLSTM_DPCNN 模型的分类性能:
(1)TextCNN 模型.CNN 模型采用文献[23]中的网络结构,以字符粒度建模,使用卷积提取文本特征图后,输入到最大池化层,提取矩阵实现对文本的分类.
(2)BiLSTM 模型.BiLSTM 模型是由两个不同方向的LSTM 组合,它可以同时捕获上下文语义信息,解决了分类过程中长距离依赖问题.
(3)RCNN 模型.RCNN 模型采用文献[24]中的结构,使用循环网络学习单词的上下文信息,得到当前词的向量表示,再通过一维卷积,提取句子特征,经池化后输入到Softmax 分类器中获得分类结果,可以简单看成LSTM和CNN的混合网络.
为了更好地评估模型,以上对比模型输入的词向量均是随机生成,不做标准化处理.
3.6 实验结果及分析
如表2所示,给出各个模型在电力客服工单数据集上的测试结果,其中Dev-Macro_F和Test-Macro_F分别表示在验证集和测试集上的宏平均分数.
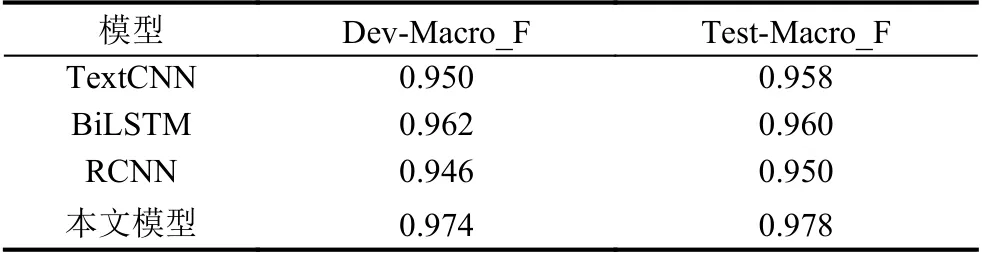
表2 实验中各个模型分类精度
通过表2中的实验结果可看出,BiLSTM 网络在分类结果上与TextCNN 网络相比而言,其在测试级上的精度,达到96%,明显高于TextCNN 分类模型.这是因为BiLSTM 网络具有记忆单元,选择性记忆和遗忘信息,具有递归学习信息的优势,此外,又能捕获前后两个方向上的时序信息,在电力短文本数据集中表现突出.但是在一般的文本分类任务中,较多采用TextCNN结构,因为训练速度较快,模型易收敛.RCNN 网络模型由于其结构较为简单,其分类指标低于其他模型.而本文提出的将BiLSTM和DPCNN 网络组合的模型,无论是在测试级和验证集,模型的分类准确率都表现最优.其在测试集上的Macro_F1 值较TextCNN 模型提高了2.0%.主要原因是因为在文本实验中,不仅在网络模型上进行组合优化,还在词向量上做进一步处理.具体而言,首先以字符级嵌入词向量,从细粒度层次分析字与字之间的语义关系,并对词向量进行归一化处理,减少数据噪音;其次,将 BiLSTM_DPCNN 模型应用到客服工单数据的任务中.该模型首先,利用BiLSTM网络具有“门控”结构,对句子特征信息选择性保留,又可以同时捕获上下文信息,在文本分类任务中具有较高的准确率;其次,考虑到对TextCNN 网络而言,不仅对相邻语义信息的捕获能力较强,又能通过设置不同滑窗大小来提取不同位置的局部信息,最后融合多层卷积特征,得到较好的分类效果.但模型存在一个最大的弊端,即采用最大池化操作,只能取一次最大值,从而丢失强特征词信息.因此,本文实验中的在原有网络的基础上进行改进,添加平均池化层,把卷积层提取的句子特征,分别输入到最大池化和平均池化层,最终把池化输出的特征进行融合,通过全连接的方式和Softmax分类器,实现分类输出.因此,在分类性能上要高于单一网络结构.
由于本文以字为单位作为模型的输入,所以在这里研究了字向量的特征维度对模型分类效果的影响.图4表示字向量的特征维度从50 维变换到400 维的过程中,宏平均值(Macro_F1)的变化情况.由图4可知,随着字向量维度的逐渐增加,整体的分类性能不断上升,但当维度为超过300 时,分类性能趋于下降状态,原因是字符级别过大导致计算成本增大.本次实验选300 作为字向量的表示维度,此时模型的分类效果最佳.
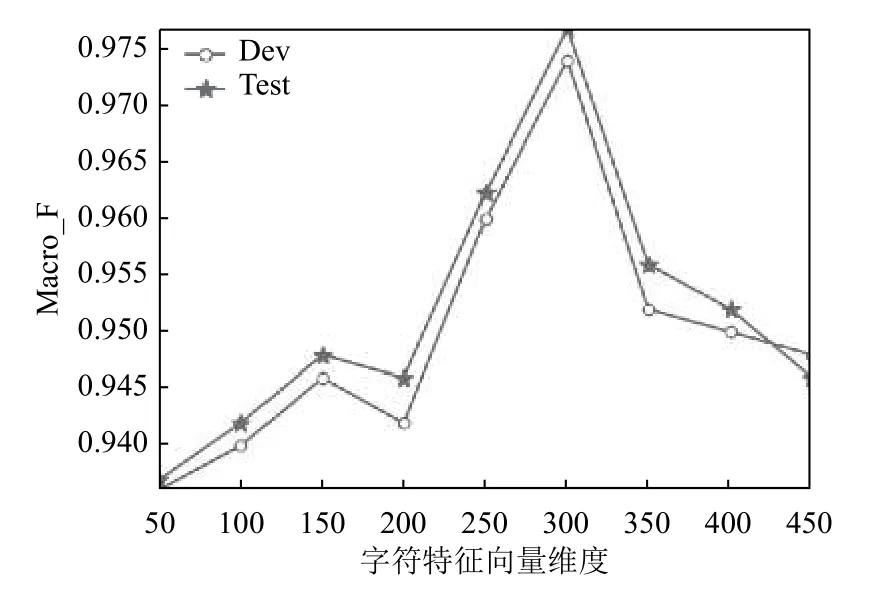
图4 分类性能与字向量特征维度的关系
表3给出不同模型在各个分类中的P、R、F1 值,通过表3可以看出BiLSTM 模型在C1、C3、C6类别上的F1 值高于TextCNN 模型.RCNN 模型分别在C2、C5、C7类别上的F1 值高于BiLSTM 模型,尤其是在C5类别中F1 值相比BiLSTM 模型,提高了5%.但从整体分类效果看,本文模型表现优于其他模型,其中最好的区分类别是C1和C5,F1 值达到99%和97%,在其他类别中的F1 值也均有提升.
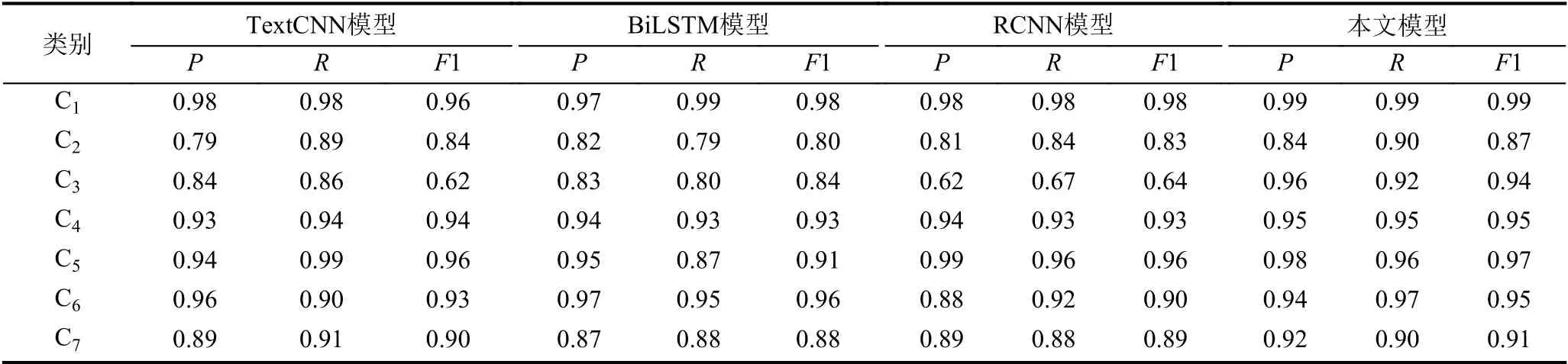
表3 不同神经网络模型的实验对比
表4给出不同模型的训练和测试时间对比,从表中数据可以看出,就训练时间而言,TextCNN 模型的训练速度快比BiLSTM 快很多,主要是因为该模型适合并行计算;本文实验中的BiLSTM_DPCNN 混合模型,时间复杂度要高些.

表4 各模型时间复杂度对比(单位:s)
4 结论与展望
本文通过分析电力客服工单数据特征,基于字符级嵌入的BiLSTM_DPCNN 分类算法对工单文本进行分类.在模型训练过程中,首先对词向量进行优化表示;其次,使用BiLSTM 循环结构学习上下文信息,获取全局语义信息;最后,采用卷积双池化方法提取全局最优的语义特征值.通过与其他分类算法对比,验证了该模型分类效果的优越性.但在大量客服工单数据中仍存在可用样本较少,不足以构成训练集类别的问题.因此,下一步需对模型进行完善使其同样适用于样本不均衡分布的客服工单数据,这对促进电网智能化发展有着重要意义.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
科学与财富(2021年33期)2021-05-10
上海师范大学学报·自然科学版(2019年5期)2019-12-13
科技视界(2019年3期)2019-04-20
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国信息化周报(2018年8期)2018-03-28
高中生学习·高三版(2016年9期)2016-05-14
