
基于文件分时索引的大规模流量实时IoT终端识别算法①
2021-02-23 06:30徐彭娜彭行雄
计算机系统应用 2021年2期
徐彭娜,彭行雄
1(福州职业技术学院 阿里巴巴大数据学院,福州 350108)
2(福建师范大学 网络与数据中心,福州 350117)
近年来,随着智能手机以及摄像头、打印机等IoT终端的快速发展,人们逐渐倾向于连接或使用IoT 终端进行工作和学习,个人的身份信息和行为信息都作为物联网服务中重要的数据,园区网络管理机构对各个IoT 终端进行管理和认证.而伴随着5G 时代的来临,IoT 终端的数据流量呈现出爆炸式增长,伪装成IoT 终端访问园区数据以及窃取个人隐私数据使得园区网络安全面临巨大挑战[1].为了加强网络安全,对网络空间中的IoT 终端的研究是当前的热点[2].
利用异常检测算法的IoT 终端识别技术保证大数据平台安全性是一种有效的解决方式,但仍然存在许多困难.第一,在服务器端汇聚的IoT 终端的网络流量主要是以TCP、UDP 等为主的报文数据,其海量性以及时效性可能导致现有IoT 终端识别技术无法在短时间内迅速检测出异常;第二,由于每个终端设备在出厂后都有指纹信息以及通信行为数据,在应用层进行的基于Web 流量中用户行为的IoT 终端识别,主要通过用户行为数据来反映访问习惯,根据攻击者与正常访问者的行为逻辑不同来进行识别.但对于摄像头、打印机等哑终端发送报文数据方面的研究不多.IoT 终端中存在大量的哑终端,主要通过TCP 或UDP 报文和服务器进行通信[3],难以直接从Web 流量角度来识别[2].第三,5G 时代使得IoT 终端不得不面临大数据挑战,需要依托于大数据平台完成IoT 终端识别算法处理,给服务器带来性能和成本等多方面压力.因此,如何高效快速的利用报文数据在少量内存中识别IoT 终端具有重要意义.
针对以上问题,本文提出基于文件分时索引的IoT 终端识别算法(a real-time IoT terminal recognition algorithm for huge data based on File Time-Sharing Index,IoTFTSI)大幅度降低实时IoT 终端识别中的内存消耗.具体方法是:首先,利用哈希桶多进程按批次分发数据,提高数据吞吐量,并建立内存分时索引元数据;其次,使用文件的分时索引来存储构建会话的中间数据;最后,控制内存分时索引元数据触发从少量文件中提取特征并进行IoT终端识别,而达到在少量磁盘消耗的代价下,将内存消耗降低92%后并保证IoT 终端识别算法精度.
1 相关工作
随着物联网在智慧城市、智慧园区等各个领域的广泛应用,物联网的安全问题也层出不穷.当前,物联网安全问题主要通过IoT 终端识别技术[2,4]来解决.IoT 终端识别的核心是通过指纹生成技术,将探测到的IoT 终端数据经过特征提取并转换为相应的指纹,从而根据分类模型识别IoT 终端.
一般情况下IoT 终端的数据是成对出现的,例如请求和响应包.数据可来自传输层、网络层和应用层协议,特别是传输层的TCP/UDP的数据报文头部包含了大量可用信息,例如分段时长、延时、请求字节数等丰富的可用于特征提取的数据[4].Beverly[5]使用半链接TCP 探测及交互时间延迟,完成全网拓扑结构识别.但仅支持IPV4 协议的网段.Liu 等[6]通过发送四组报文到防火墙后而得到的报文时间差异作为特征,然后通过统计学习方式识别IoT 终端类型.但报文特征有限,识别率不高.Shamsi 等[7]提出的Heshel 方法利用TCP 数据包发送时间与重传时间的差异性作为特征,并使用EM 算法降低网络抖动、丢包等因素的影响.但是主要数据是设备操作系统信息,有效的设备行为数据包不多.
随着5G 技术的兴起,例如智能终端与服务器存在大量的交互,势必其TCP/UDP 等数据流量大幅度增加.Bezawada 等[8]通过从网络流量中提取设备行为的近似特征,用于训练设备类型的机器学习模型.Yang等[9]利用神经网络对监控设备的海量数据报文进行解析,提高了IoT 终端的识别率.贾煜璇[2]通过建立一个IoT 终端识别系统对海量的TCP 数据进行提取和分类,具有较高的精确率.宋金珂[3]实现了大规模实时在线监控设备的隐私检测,但每次检测的资源成本较大.使用大规模流量来描绘行为轮廓是当前的研究热点[2,10],引入机器学习或者深度学习的方法对网络流量进行分析,虽然能够提高IoT 终端识别准确率并提高系统的自动化能力,但使得承载IoT 终端识别技术的系统尤其是对于实时性要求高的系统或服务器带来了资源成本的大幅度提升.尹方鸣等[11]提出一种基于内存受限的RFID 复杂事件处理优化算法,使用文件分时索引方法进行海量数据中的复杂事件处理,降低了资源消耗成本.因此,降低大规模流量下IoT 终端识别的资源消耗是IoT 终端识别技术中的关键问题.
基于以上工作,受到文献[11]的启发,本文建立一个新的IoT 终端识别算法模型,该模型并不针对IoT终端识别准确率的提升,而是借助于文件分时索引技术,以极小的磁盘消耗代价达到大幅度降低实时IoT终端识别中的内存消耗的目标.
2 理论基础
2.1 会话约束条件
生成会话的目标是为IoT 终端识别提供数据支持,本文使用数据特征较为丰富的TCP/UDP 数据[12],并使用FlowBroker[13]抓取报文数据Packet,最后利用机器学习算法对报文组成会话后的特征向量进行分析.在构建流的特征向量前,对报文生成会话的过程约束如下:
(1)构建会话序列S:根据四元组k收集在时间Ts内的报文数据组成会话,Ts指从第一次收集到某k的报文的时间开始计算.使用非自然时间的超时机制,对各k维护Ts时间内的缓存并能触发生成会话,而k相同的报文在Ts内将构成会话序列S.对于哑终端而言,其报文数据中的k会维持长时间不变.对于非哑终端而言,其报文数据最终符合用户的习惯,文献[14]表明网络流量的访问概率服从齐普夫分布,即非哑终端访问服务器时,其访问次数和访问概率成反比.因此可以使用较少的报文数量np来控制报文数量,以防止在Ts内出现了热点问题.
(2)提取会话流特征向量SF:收集ns条k相同的会话后,统计并提取会话特征SF.其中ns需要根据不同的场景调整.
2.2 文件分时索引
基于内存的会话生成算法在接收到报文时,根据k存放到集合KP中,如果该k是第一次出现,则记录该k的时间作为初始时间;否则,则将当前时间和初始时间对比,超过设定的Ts则形成会话,并从KP移出,否则加入KP.由于每个k都有一个需要维护的Ts,其难点包括以下两个方面:一方面,当该时间段内数据量巨大时,内存占用量极大,需要设计良好的反压机制.另一方面,KP到达Ts时需要快速老化,否则会影响后续进入系统的数据.该问题属于复杂事件处理范畴,文献[11]表明,在内存受限的情况下,使用B±树分时优化索引(BIOT)的复杂事件处理算法将数据流按时序进行分割且用B±树进行区间分块索引.受此启发,本文使用文件的分时索引来存储构建会话的中间数据,达到减少内存消耗的目标.图1是使用文件的分时索引存储会话中间数据的描述.
相似地,横坐标为时间线,表示在Ti到Ti+1时间内的文件索引情况.竖直方向上,A表示哈希桶的集合,共有b个Bucket,通过对数据包p的字符串进行哈希运算分配到Bucket 中,其中b的值影响算法的并行性能.B表示Bucket 中IP(终端)的集合,共有n个IP,表示通过哈希运算分配到该Bucket 中的IP 对应的数据包p.C表示IP 对应的KP,共有m个k.D表示k对应的数据包p的集合P,共有z个p.在文件分时索引算法的文件存储阶段中,A和B都表示为索引的集合,C表示文件的集合,D则是文件中内容的集合.在内存索引阶段中,使用TR集合来存储以上A和B构成的二级索引元数据,TR在内存中用于加速文件的索引过程,TR在算法启动时从数据库中加载状态.

图1 使用文件的分时索引存储会话中间数据
3 IoT-FTSI 算法框架
3.1 算法描述
ks表示Bucketi中的四元组集合.IP 表示ks集合中某个k解析后的源IP 地址.TRIP表示TR中IP的集合,TRKey表示TR中k的集合.fl表示IP和k索引到的会话文件的最后更新时间和文件长度.activeIP表示IP的激活状态,当值为true 时表示处于激活状态,允许和IP 相关的新的报文进入,否则不允许进入.activek表示某会话的激活状态,当值为true 时表示处于激活状态,允许与k相关的报文进入,否则不允许进入.lk表示从消息队列消费的当前批次中k对应的报文数量,m表示IP 对应的会话数量.δt表示当前时间和的ft差值.np表示每个会话中的报文数量上限,δl表示np和当前会话文件中报文数量的差值.ns表示每个IP 允许的会话数量上限.IoT-FTSI 算法实现如算法1 所示.

算法1.IoT-FTSI 1)for k in ks:2)if ip in TRIP &&activeIP:3)if key in TRk &&activek:4)if δt<Ts>&&fl< np:

5)wf()6)else:even(RF_FE)7)else:8)if m <ns:9)if lk<np:even(RF_FE)10)else:even(AW)11)else:even(RF_FE)12)else:even(AW)?
IoT-FTSI 算法的步骤描述如下:步骤1)遍历ks.步骤2)判断源自k中的IP是否存在于内存的二级索引TR的第一级索引中,并且当前ip处于激活状态,如果是则进入步骤3),否则进入步骤12).步骤3)判断k是否存在于内存的二级索引TR的第二级索引中,并且当前Key 处于激活状态,如果是则进入步骤4),否则进入步骤7).步骤4)判断δt是否超过了Ts,并且当前会话文件的文件长度fl是否超过了报文最大数量np,如果是则进入步骤5),否则进入步骤6).步骤5)中的wf()函数功能为写入文件,wf函数的算法描述如算法2 所示.

算法2.wf 1)del wf():2)if δl>=lk: even(MW)3)else:even(AW)4)update(ft,fl)
算法wf主要功能是判断待写入的报文是否超过了会话文件允许的最大报文数量上限,如果超过(包含等于)则触发事件even(MV),即将待写入的报文数据切割出δl长度,再将会话文件中的报文全部提取出来,进行合并后进行特征提取;如果未超过,则触发事件even(AW),即将所有待写入报文数据全部写入文件中.这种写入方式主要是减少和磁盘的读写交互.而且wf()函数采用文件的顺序读写,对磁盘的开销也比较小.最后在以读写文件为主的事件结束后,需要对会话文件的信息进行更新,即更新ft和fl.
IoT-FTSI 算法的步骤6)触发事件even(RF_FE),其算法描述如算法3 所示.

算法3.even(RF_FE)1)fe(ip)2)k.clean 3)remove_file(k)4)m+=15)if m>=ns:activeIP=activek=False
事件even(RF_FE)的功能前置条件是会话已经达到了Ts并且会话文件长度已经达到了np,那么此时不需要再将报文数据写入会话文件,并且直接读取IP 下的ns个会话文件,使用fe()函数对二级索引TR中IP索引下的所有k的会话文件进行特征提取,并将activeIP设置为冻结状态.同时清空内存中的k以及删除该IP的所有会话文件.
3.2 算法分析
在磁盘占用方面,IP 体现为文件夹名,k体现为csv文件,文件中的每行是报文,并删除了四元组信息,可将原有处于内存中的JSON 格式的600 Byte的报文对象压缩为50 Byte 以内的字符串.实际内存最大使用量=b×n×报文CSV 字符串字节数,默认情况下我们使用4 进程,即b=4,每个IP 桶最大允许存放报文数量n=20 000个,并且默认设置反压阈值(back pressure threshold,bpt)为0.8,即当报文数量达到最大允许报文数的反压阈值时则会进行休眠操作.默认值=4×20 000×50 Byte≈4 MB.另外,与磁盘的交互主要表现为文件追加和删除文件的顺序批量操作.经过测试,实验用机械硬盘的每秒进行读写操作的次数(input/output operations per second,iops)为138 MB/s,IoT-FTSI 算法最差情况为将全部数据顺序写入磁盘,iops为4 MB/s,因此对磁盘影响不大.
在时间消耗方面,IoT-FTSI 算法从消息队列每次拉取的报文数量为batch=b×n×bpt,每个报文数据通过不同的进程分配到不同桶中,在桶的内部,报文数据按照k进行分组.IoT-FTSI 算法遍历ks中的k,最后将k拉取到的所有数据写入磁盘.最差情况下,将np数量的报文从磁盘中读取出来进行特征提取.因此IoT-FTSI算法的时间消耗主要为磁盘的读写耗时.
4 实验分析
4.1 实验数据集
本实验目标在于验证IoT-FTSI 算法的内存消耗,数据来源于通过位于高校服务器上FlowBroker 两次采集到的IoT 报文数据,分别为Da和Db 两个数据集,包含了337 个终端.采集时间为工作日的流量高峰时段,每次采集为1.5 小时,数据量分别为21 305 332、22 700 220 条.Da 数据集采集时间为9:00~10:30,Db 数据集采集时间为14:00~15:30.考虑到IoT-FTSI 算法可能存在的计算延迟,需要将FlowBroker的数据缓存到消息队列中,其结构包含了除了四元组外的包大小、时间延迟等特征数据[2].
4.2 结果分析
根据文献[10] 中提到使用特征加权聚类算法(Feature Selection algorithm based on Feature Weighted Clustering,FS-FWC)作为IoT 识别算法基础.实验采用在预测问题中常用的准确率作为评测标准.将FSFWC 算法和使用IoT-FTSI 算法进行对比,在相同的准确率下,比较内存消耗量(memery used,mu)和数据处理完的时间消耗量(time used,tu).为了减少实验中因系统环境导致的不一致性以及模拟真实运行环境.将实验部署在相同docker 虚拟出的Ubuntu 系统环境中,在7200 r/min的机械硬盘上限制虚拟环境最大使用4 核CPU和4GB 内存的硬件资源.实验结果为在数据集Da和Db 上运行10 次并取平均值.
首先,在Da和Db 上使用FS-FWC 算法进行预测,为了分析准确率和np的关系,观察不断增大np后准确率的变化情况.实验结果如图2所示.

图2 增大np 后算法准确率变化情况
图2中横坐标代表np值,最小为1000,最大为20 000.纵坐标代表使用系统FS-FWC 算法时在Da和Db的准确率的平均值.每个报文占用内存大小约为600 字节.那么对于337 个终端而言,内存使用量理论值已经达到了3.77 GB,因此试验中将np最大值设定为20 000.从图2中可以看出当np达到10 000 时,准确率已经达到0.93,随着np的增加,准确率增加非常缓慢.当np达到18 000 时,准确率达到0.96,继续增加np导致的准确率极小,因此将np设定为18 000.那么内存使用量理论值为3.38 GB.
其次,在docker 虚拟出的Ubuntu 系统中使用free命令观察FS-FWC 算法和IoT-FTSI 算法在处理数据集时的内存总体消耗情况与时间的关系,实验结果如图3所示.在图3和图4中前3 分钟为空载时间,可以看出IoT-FTSI 使用的内存是超过FS-FWC的,这是因为IoT-FTSI 算法的元数据消耗了部分内存.
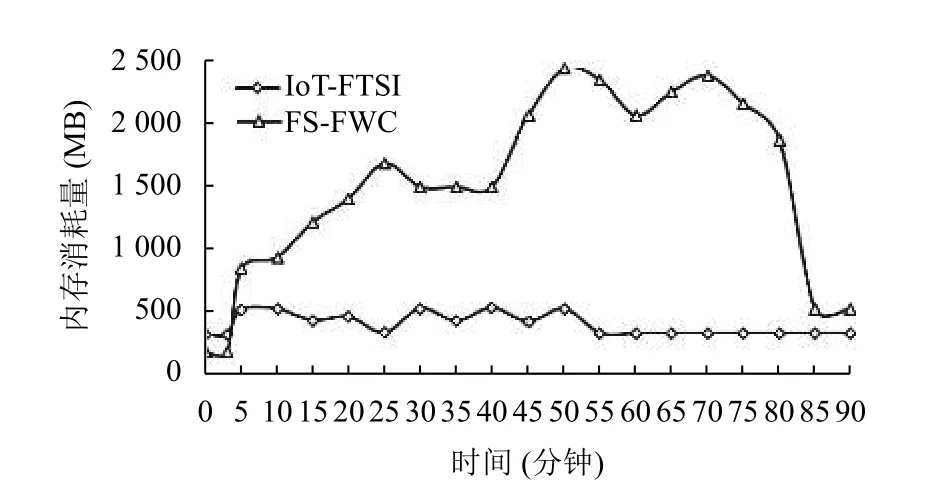
图3 Da 数据集中算法内存使用量随时间变化情况
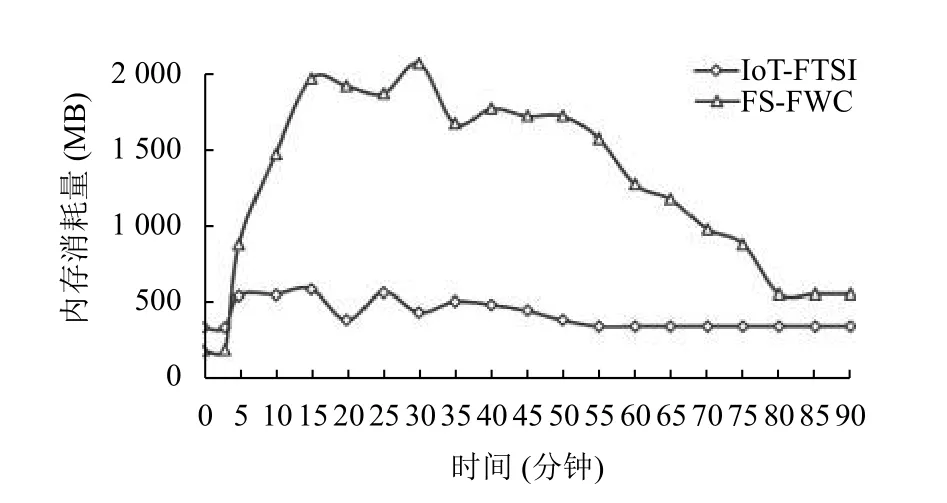
图4 Db 数据集中算法内存使用量随时间变化情况
从第3 分钟开始,IoT-FTSI和FS-FWC 系统都从消息队列中拉取同样的数据,两者的mu都突发性的增长,但对比发现FS-FWC的mu持续递增.另外,FSFWC的mu对突发的热点更加敏感,反映了IoT-FTSI更加稳定,面临更小的内存耗尽风险.在图3中,IoTFTSI的mu在前55 分钟有明显的波动现象,因为每个会话在Ts间隔就会触发特征提取与预测,使得mu突然增加;而且mu较小,原因是其最大理论mu更小.IoTFTSI在55 分钟后的mu趋于平缓且接近空载时的mu,原因是前期已处理的报文被过滤掉.反观FS-FWC,虽然mu在25 分钟后出现下降,但是由于其报文都是存放在内存中,使得mu居高不下并且在55 分钟时达到最高点.在图4中,IoT-FTSI的mu在前25 分钟有明显波动现象,但是其波动的mu仍然较小,虽然在前25 分钟时数据量突发增长,但是由于最大报文数量np的限定和达到反压阈值bpt时的反压功能使得其具有更好的稳定性.
最后,通过磁盘读写性能来对比A和B 系统对磁盘的影响.实验结果如表1所示.

表1 算法在不同数据集上的磁盘性能对比情况
在表1中可以明显发现IoT-FTSI 对磁盘的影响更大,这主要是其将用于产生会话的临时报文数据按批次写,同时伴随着到期删除文件、特征提取时全量读取文件内容等读过程.而FS-FWC 则对磁盘影响较小,原因是其产生会话、特征提取等都在内存中完成,最后只有少量的预测结果写入磁盘.故IoT-FTSI 对磁盘的影响更大,但对于顺序读写性能达到138 MB/s的磁盘而言,其影响程度不大.
5 结论与展望
本文针对实时IoT 终端识别算法对服务器资源需求高的问题,结合文件分时索引的方法将原存储于内存中的用于产生会话的大量临时报文数据使用文件分时索引存储在磁盘中,提出了IoT-FTSI 算法,使用少量的磁盘读写代价替换了大量内存的资源耗用,同时降低了热点问题导致的内存高占用风险.实验结果表明,该算法利用文件分时索引方法生成会话,能够更合理的使用服务器资源,降低成本,可以有效地应用于IoT 终端识别.然而,文中提到依赖于哈希算法将报文数据负载到桶中,哈希算法的性能影响了算法的负载均衡能力.因此,如果更好地提高IoT-FTSI 算法负载均衡性能是下一步要做的工作.
猜你喜欢
汽车电器(2022年9期)2022-11-07
电子技术与软件工程(2022年11期)2022-09-09
软件导刊(2022年3期)2022-03-25
科学家(2021年24期)2021-04-25
长江丛刊(2020年17期)2020-11-19
电脑爱好者(2020年18期)2020-09-26
电脑爱好者(2019年2期)2019-10-30
电脑知识与技术(2017年14期)2017-07-10
考试周刊(2016年82期)2016-11-01
电脑爱好者(2015年6期)2015-04-03
