
基于语音信号处理的电子病历系统探索研究
2021-02-07 08:56华东理工大学刘峻宇刘逸捷岳川梦真王宪伟刘金琳
电子世界 2021年2期
华东理工大学 刘峻宇 刘逸捷 岳川梦真 王宪伟 刘金琳
伴随着深度神经网络的的到来,机器学习与人工智能技术在人们的日常生活中逐渐得到了广泛运用,尤其是诸如人脸识别,身份认证,物体识别等图像识别以及计算机视觉相关的技术。虽然深度神经网络对于语音识别模块的推进状况不如图像识别,但是迄今为止仍然在不断涌现的技术允许语音识别变得逐渐快速,准确。为了推动语音识别技术在人们生活中的普及,本文提出了一种医疗方向上的语音识别以及与正在发展的电子病历系统结合的系统,并在其上就语音识别和说话人识别,基于语音识别工具包Kaldi进行了一系列研究和探索,针对语音识别修改thchs30的语音模型,获得了一个专门针对医疗语音识别的模型,通过对案例sre16/v2的学习获得了基于xvector的文本无关说人识别模型,最后基于对已经识别出来的语音的正则提取处理,构建了一个手机语音问诊app系统。
1 简介
1.1 语音识别
语音识别是一个十分复杂的过程,其包括语音的采集,前端处理,解码器以及最后的文字处理部分。首先,语音采集也许是所有步骤中看起来最没有技术含量的一个步骤,但这并不意味着这个步骤无足轻重,在韩纪庆等人所著的《语音信号处理》艺术中就阐述了一个良好,全面的语音素材,对于语音信号处理可以起到极大的简化作用,好的语音采集同样对于建立良好的语音模型十分有帮助。然后是前端处理,在这个部分,需要做的包括:端点检测,语音降噪,语音筛选,片段截取。这同样是个工作量十分大而且还需要一定技术支持的步骤,良好的语音降噪和端点检测对于一个用于训练语音模型的语音素材十分重要,加上对于语音内容的筛选,这有利于建立识别度高,有针对性的语音模型。而片段截取则是有利于缩短模型的训练时间,同时也一定的有利于模型适应度。接下来就是本文主要研究的两个部分,解码器和文字信息处理两个部分,解码器有两个部分组成,分别是通过语音数据和文本数据训练出的声学模型和语言模型,由于训练声学模型需要大量好的语音资源来训练,由于不具备这个条件,本论文的探索的技术主要在于修正通过其他语料寻来出来的模型使其适应医疗领域从而达到针对医疗语音识别这个目的。最后,文字信息处理部分其实主要在app框架之中,对于语音识别出来的信息,通过正则表达式将需要的关键信息提取或转化,填入预先设定好的电子病历之中。
1.2 问题与针对的解决技术
要设计针对与医疗方向的语音识别,就需要先假设拥有这样一款产品。倘若有这样一个产品,客户会需要其拥有什么样的性能呢?首先需要其拥有与一般语音识别软件一样的功能,其次,与平常语音识别不同的是,首先,需要其能够快速且准确的识别出问诊时候的专业词汇。最有,由于病人和医生在问诊时,存在一问一答的对话模式,所以需要其具有良好的说话人识别功能,以便于之后的电子病历填写。本文之后的探索与研究皆围绕此两点进行。
2 具体技术探索
2.1 语音识别(thchs30)
Tri-gram语言模型:
Tri-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为3的滑动窗口操作,形成了长度是3的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第3个词的出现只与前面2个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计3个词同时出现的次数得到。

图1 DNN-HMM声学模型
DNN-HMM声学模型:
DNN:深度神经网络,HMM:隐马尔科夫模型,DNN-HMM框架原理示意图所示,与DNN-HMM相比较,将DNN替换GMM,计算的是多个帧的特征的概率值,即每个状态的后验概率。从图中可以很明显看出,DNN的训练会产生大量的参数,使用CPU进行DNN的训练会消耗非常多的时间,因此在DNN的训练中使用GPU可以节省大量的时间,提高运算速度。具体实现如图1所示。
语音识别主要使用工具:
主要是用SRILM和Kaldi工具,其中使用SRILM训练语言模型,使用Kaldi训练声学模型。
SRILM是一个用来构建和测试语言模型的工具。SRILM包含C++类库,基于这些类库的训练以及测试语言模型的可执行的封装好的程序,以及事先准备好的任务脚本。因此可以通过SRILM非常简单地通过训练数据得到一个语言模型,这当中包括最大似然估计也可以通过相应的平滑算法使模型更加平衡。
Kaldi与构建操作隐马尔可夫模型的HTK工具相似,用于构建语音识别模型,但是在其基础之上,Kaldi的易于修改和易于扩展体现了代码的灵活性,同时Kaldi运行稳定,且支持一些目前流行的如深度神经网络等的高阶模型,极大程度上便利了语音识别方面的研究。
模型训练:
(1)数据准备
数据参考了清华大学thchs-30[23]在Kaldi平台上训练语音识别模型的语言模型的训练数据,在其基础之上对其语料进行了一定程度的扩充,从而增加语言模型在疝病问诊方面的识别效率。同时,将瑞金医院的疝病问诊的对话记录通过人工处理,得到新的训练文本,用于训练新的语言模型。
训练声学模型时,数据的准备主要分为两个部分,一个是语音数据,即与数据集相关的录音以及一些记录了录音信息的文件;另一个是语言数据,即与语言本身更相关的发音字典、音素集合等关于音素的额外的信息。
字典文件的准备上,本研究准备继续使用清华的thchs30中的“lexicon.txt”字典和“lexiconp.txt”概率字典,但是在其基础之上,增加医疗专用词汇,同时调整词汇出现的概率,以实现模型的领域化。如图2所示。

图2 数据分布
(2)训练模型
首先是训练语言模型Tri-gram,通过对瑞金医院疝病问诊的文本集合进行训练得到一个相对而言较小的3-gram语言模型,new_word_3gram.lm。将thchs30中的word.3gram.lm模型和new_word_3gram.lm通过SRILM中自带的compute-best-mix脚本,计算出合适的比例,进行合并,得到最终的基于词的语言模型final_word.3gram.lm。
其次是声学模型,利用Kaldi,结合使用SRILM训练出来的语言模型,训练出基础的隐马尔可夫模型语音识别模型,在此基础模型之上进行深度神经网络的训练,与此同时可以利用Kaldi这个平台,对比多个算法的优劣,对模型进行调整,得到最终的模型。最终模型的生成流程如图3模型生成流程图所示。对于DNNHMM的训练主要有五个步骤,包括特征提取、处理语言材料、单音素GMM-HMM训练、三音素GMM-HMM训练以及最后的DNN-HMM模型训练。具体过程如图4所示。
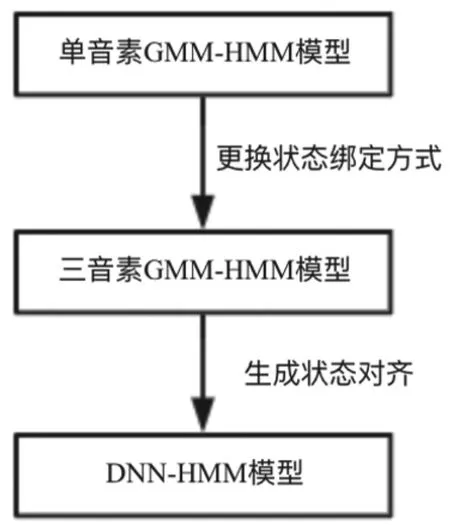
图3 模型关系
(3)调整参数
对于三音素模型的训练,使用了step/train_deltas.sh脚本进行训练。step/train_deltas.sh脚本有几个重要的参数,包括叶子节点数、总的高斯数目以及存放数据、音素对齐结果等数据的目录路径。

表1 参数调整方法
模型效果对比:
在本次研究中,主要改进集中在对语言模型的改进当中。通过对语料和词典的扩充,增强语言模型在医疗领域的识别效率。首先,本次研究在使用了添加了新的语料的语言模型的基础之上训练了单音素GMM-HMM、三音素GMM-HMM以及DNN-HMM。
其中,与单音素模型不仅仅只有上下文的区别,三音素模型在训练的过程中,还加入了LDA、MLLT等参数调整以及说话人自适应等过程。
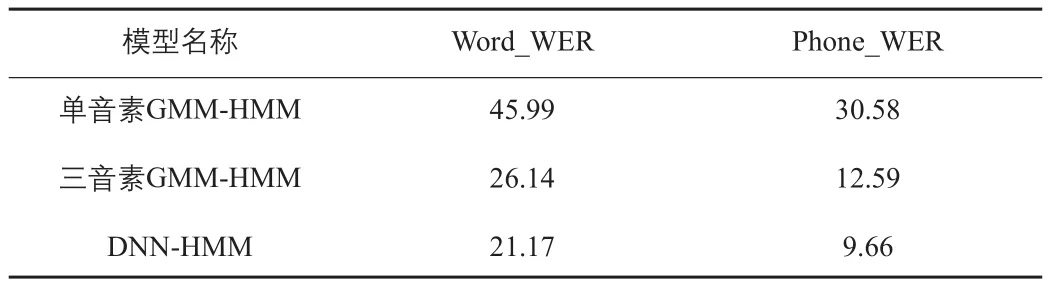
表2 模型识别率
通过得到的数据,对比了一下这三者之间的区别,在整体的识别率上,如表2模型识别率所示,和预期一样,经过了参数调整的三音素GMM-HMM的识别率极大程度优于单音素GMM-HMM,可见三音素模型确实拥有比单音素模型更佳的效果。而DNN-HMM则是小幅度优于三音素GMM-HMM。然后,本次试验通还将修改语言模型前后,三种模型在词和音素的识别率分别进行了对比。
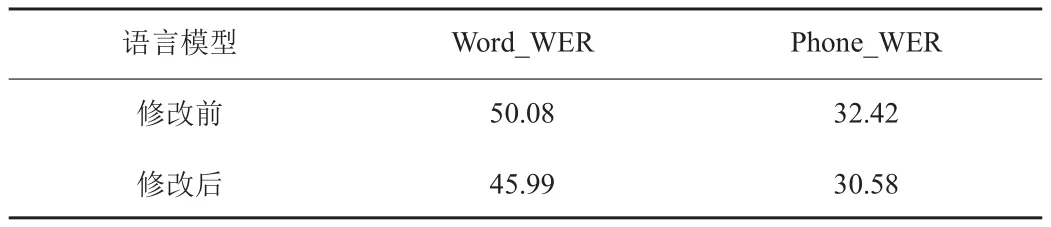
表3 因素GMM-HMM对比
首先是修改语言模型前后,单音素GMM-HMM的对比,如表格3单音素GMM-HMM对比所示,从表格中的数据可以看出,对语言模型进行修改之后,在相同的测试集中,识别率也略有提升,且词的识别率提升较因素的识别率提升更多,原因是对于单音素模型而言,虽然对语言模型的修改对于识别率的提升并没有多大的作用,但是由于更丰富的语言模型构成了更加完善解码网络,因此会对词和音素的识别都略有提升。
而修改之后的单音素模型在词的识别上起到好的作用,则是因为更加完善的词的语言模型即使使用了医疗领域的对话文本,文本中也包含了日常的用词,故而在普通领域的测试集中,识别率也会有提升。

表4 单因素GMM-HMM对比
对于三音素GMM-HMM和DNN-HMM的识别,如表4三音素GMM-HMM对比和表格5 DNN-HMM对比所示,修改语言模型的效果则不那么明显,原因是因为对于三音素模型而言,会使用单音素模型的对齐序列,而DNN-HMM模型会使用GMM-HMM进行初始化,因此效果的提升会有一定程度的削弱。

表5 DNN-HMM对比
2.2 说话人识别(Xvector)
xvector系统:
Xvector系统是一个深度神经网络系统,可以通过变长的语音片段来计算语音中嵌入的说话人这是kaldi工具栏中公共的体系结构。如下表格展示了xvector拓展网络的结构。其主要功能可以分为三块,如图4所示:第一组包括一到九层,是TDNN(一维卷积)和密集层的集合。卷积的层次结构提供了一种有效的方式来处理数量减少的230ms扩展输入上下文。给定一系列F维的T个输入特征,此块将23×F个特征的块映射到T个高维向量(1500dim)序列中。第二组,即第10层,通过计算每个维度上的均值和标准差,对该序列执行时间合并操作。这两个统计量被串联在一起,成为大小为3000的固定维向量,该向量总结了整个输入记录。第三组,即第12层至第13层,是具有瓶颈层的前馈网络,并用作分类器,为训练说话者输出后验概率。在ReLU非线性之前,先从层11中提取x向量。网络的瓶颈结构用于实现嵌入尺寸的减小(512尺寸)。实验中使用的DNN的参数总数(使用7,168名训练者)约为800万,其中仅需要400万即可提取x矢量。

图4 xvector实现
Xvector的优势:训练速度十分快;无需特定的语种设置一个embedding层进行提取特征直接进行plda打分;识别率十分可观
模型测试:
我们通过运用的数据集是AISHELL中文普通话开源数据,总共178 h,400个人讲,其中训练集340个人,测试解20个人,验证集40个人,每个人大概讲三百多句话,每个人讲的话都放在一个文件夹里面。复现了xvector说话人识别。
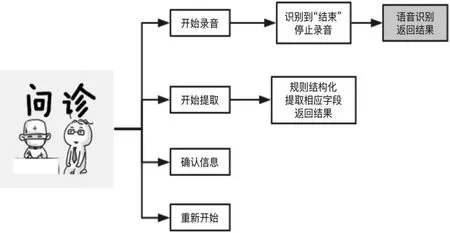
图5 逻辑流程图

图6 系统界面
3 医疗语音识别系统(简单框架)
3.1 开发环境与逻辑流程图
我们选用app inventor进行开发,它是一个非常直观的可视化编程环境,将代码功能模块化,使用积木拼图式编程,程序员通过拖拽具有所需功能的模块,通过拼接即可实现各种功能。以及系统的逻辑流程图设计图如图5所示。
3.2 使用流程
系统界面如图6所示,可以看到从左到右依次有四个按钮“开始录音”“开始提取”“确认信息”“重新开始”,其实这也是使用系统的流程。
下面我们从医生角度解释系统使用的流程。
(1)医生点击按钮“开始录音”后即可开始问诊,系统开始录音并进行语音识别,录音过程中系统界面。
(2)问诊接收后,医生只需说声“结束”,系统识别“结束”后即中断录音,并将识别好的内容显示在界面上方的文本框中,鉴于识别结果可能并不准确,医生可修改识别结果。
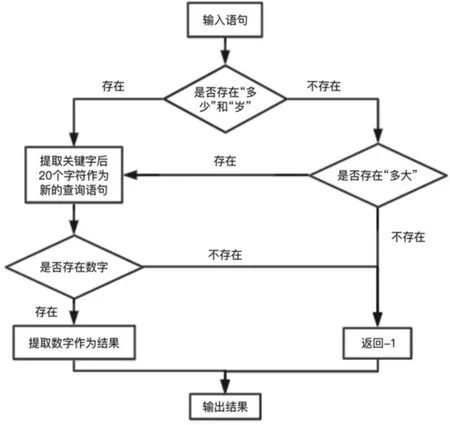
图7 年龄的结构化规则
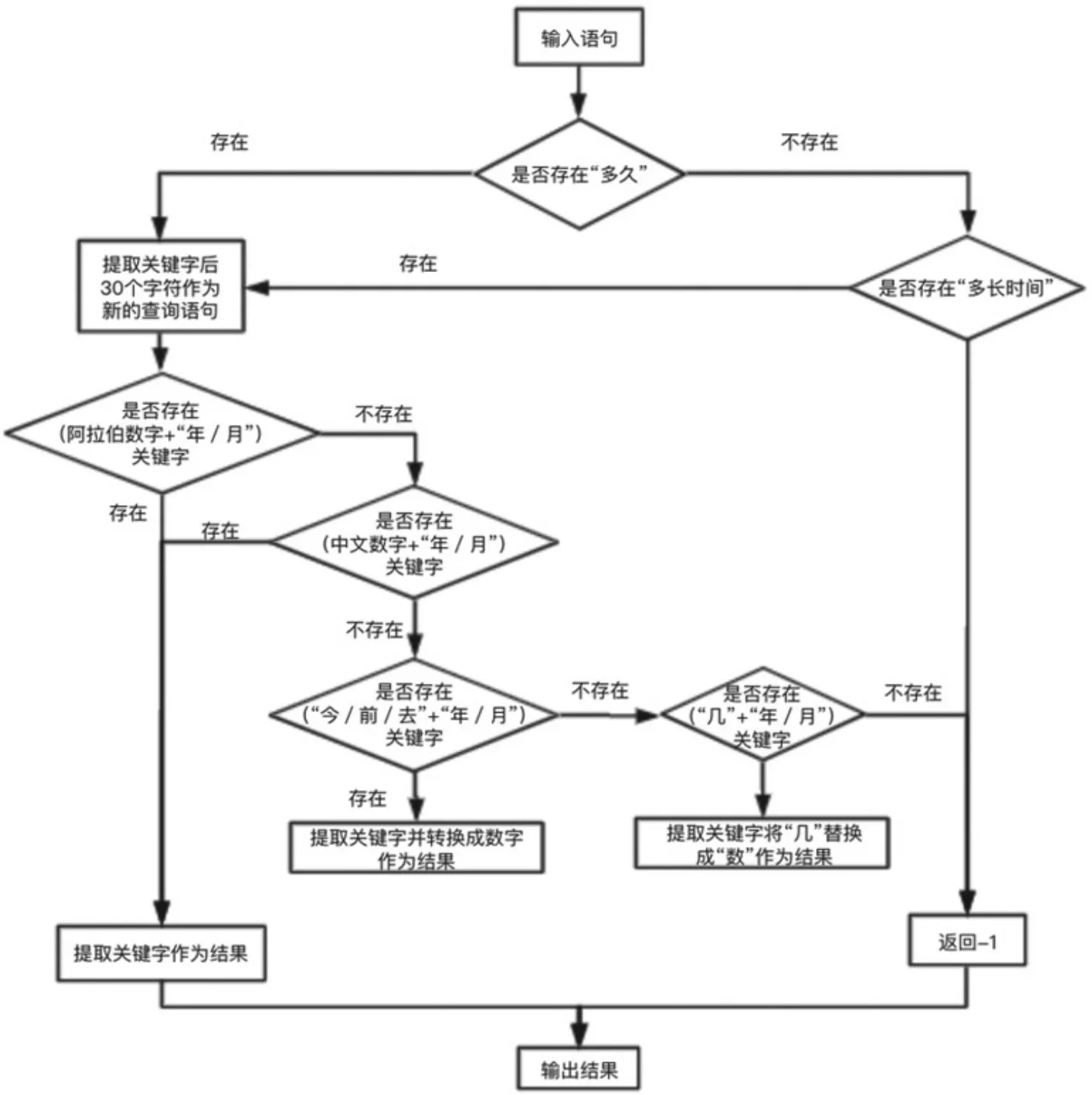
图8 疼痛时长的结构化规则
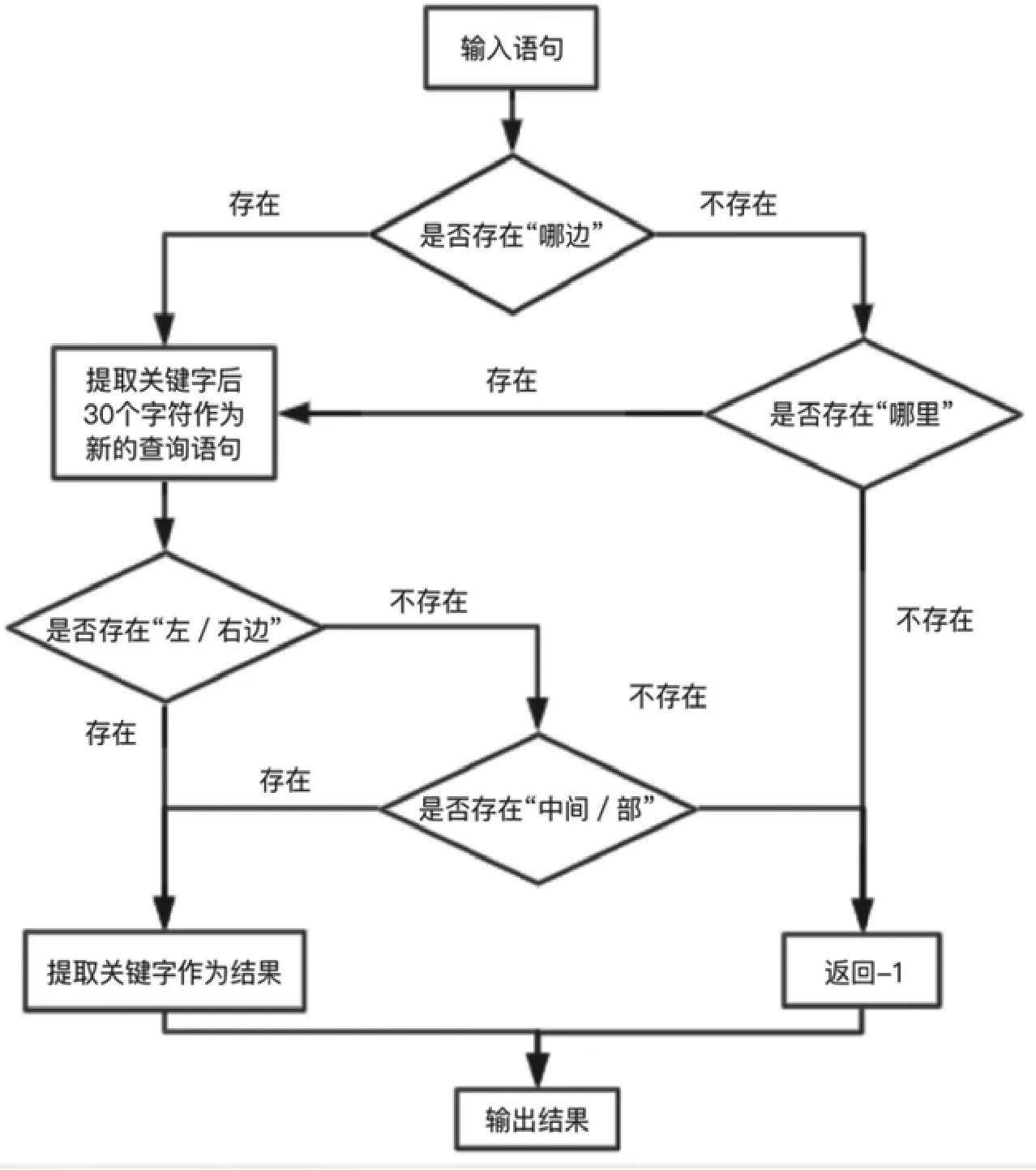
图9 肿块位置的结构化规则
(3)医生确认识别结果无误后,点击“开始提取”,系统开始从文本中提取电子病历所需信息并显示在下方表格中。
(4)提取结束并显示后,即问诊结束,医生点击“确认信息”即自动上传电子病历到数据库中,系统的本次使用结束,点击“重新开始”即可开始下一次问诊。
3.3 设计难点以及解决方法
规则结构化,提取相应字段返回结果,结构化中主要有三方面问题需要处理,分别是:
年龄的结构化规则:
对于年龄的结构化规则如图7所示,针对不同的语言习惯,考虑到了两种询问方式,主要为“多少岁”和“多大”两种,对于回答则是考虑到了语音识别的过程中,会直接将数字转换成阿拉伯数字,因此在该基础之上,不用考虑中文的数字的问题,直接使用正则中的数字表达即可对所有情况进行提取。
疼痛时长的结构化规则:
疼痛时长的结构化规则如图8疼痛时长的正则化规则所示,针对疝病的具体情况,病人的回答可能不仅仅只有数字,而是涉及到去年、前年等词,因此在正则化的过程中需要考虑到这些情况,故而对于疼痛时长的正则规则相对其他的字段的规则会复杂很多。
首先在提问方面,有两种情况,对于这两种情况都提取关键字后30个字符作为下一个正则提取的语句,这样就可以极大程度上避免“答非所问”的情况。对于新的语句,首先判断有没有阿拉伯数字,有则直接作为最后结果输出,没有则判断是否有中文数字,有则直接提取并输出,没有则判断是否存在“去”、“今”和“前”等关键字,有则提取之后转换成相应的数字,例如“去年”会被转换成“一年”,若还是没有这些关键字,则判断是否有“几”字存在,该字的存在也表明了病人对具体时间的不确定,因此可以通过将“几年”转换成“数年”的方式来表达。
肿块位置的结构化规则:
对于肿块位置的结构化规则如图9肿块位置的正则化规则所示,针对疝病的具体情况,肿块的位置主要集中在左、中、右三个部位,因此医生询问病人的时候会引导病人回答左、中、右这样的关键词,故而相对于其他几个字段的结构化规则而言,肿块位置的正则化规则看上去非常简单。
4 结果与讨论
本文在语音医疗语音识别上进行了探索,综合判断挑选了有针对性的技术解决对应的问题,并且在这些领域做了研究和探索。首先,对于问诊对话中常出现医疗词汇的情况,本文基于清华的thchs30中的“lexicon.txt”字典和“lexiconp.txt”概率字典,增加医疗专用词汇,同时调整词汇出现的概率,以达到快速,准确识别医疗词汇的效果;针对说话人识别,本文探索了目前在训练速度,识别率,适用性各方面综合下来最优的xvector系统,基于kaldi工具包训练了模型。最后,本文提出了一种语音问诊智能电子病历app系统的功能流程与框架设计,这些技术探索和研究,都将有助于今后的医疗语音系统开发。
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19
北京教育·普教版(2020年9期)2020-10-09
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
计算机工程(2020年3期)2020-03-19
校园英语·中旬(2019年11期)2019-11-26
广西教育·D版(2019年6期)2019-07-11
中国听力语言康复科学杂志(2019年3期)2019-06-24
疯狂英语·新策略(2018年7期)2018-08-29
中国交通信息化(2018年3期)2018-06-13
