
基于持久性内存和SSD的后端存储MixStore
2021-02-06 09:27屠要峰陈正华韩银俊关东海
计算机研究与发展 2021年2期
屠要峰 陈正华 韩银俊 陈 兵 关东海
1(南京航空航天大学计算机科学与技术学院 南京 211106)2(中兴通讯股份有限公司 南京 210012)(tu.yaofeng@zte.com.cn)
近年来,随着移动通信和物联网技术的快速发展,数据的规模呈爆发式增长,传统的存储系统已经无法满足不断增长的海量数据存储的需要.为解决数据存储规模、数据备份、数据安全、服务质量、软件定义等问题,分布式存储系统应运而生.分布式存储是通过软件的方法把若干节点的存储资源,如磁盘、内存等组织起来,对外提供虚拟的统一的块、文件或对象接口的按需存储服务.
本地文件系统如XFS(extents file system),EXT4(fourth extended file system),btrfs(B-tree file system)等,具有成熟、稳定的优势,成为分布式存储系统访问本地存储资源的主要方法.应用广泛的分布式存储系统Ceph的后端存储FileStore也是基于XFS进行存储访问.这样做的优势是利用了文件和对象天然的映射关系,利用操作系统页缓存机制缓存数据,利用索引节点(inode)缓存机制缓存元数据,同时从操作系统层面保证了磁盘的隔离性.但是这种架构也有明显的缺陷[1],主要是事务一致性难以保证,元数据管理低效,以及缺乏对新型硬件的支持.鉴于此,Ceph在Jewel版本引入了BlueStore作为后端存储.BlueStore将对象数据的存放方式改为直接对裸设备进行指定地址和长度的读写操作,不再依赖本地文件系统提供的POSIX(portable oper-ating system interface of Unix)接口.同时,BlueStore引入了RocksDB数据库保存元数据和属性信息,包括对象的集合、对象、存储池的omap信息和磁盘空间分配记录等,BlueStore有效避免了数据的双写,提升了元数据的操作效率,同时借助RocksDB解决了事务一致性问题.
BlueStore虽然改善了元数据效率和事务一致性,但在实际使用中存在一些明显的问题[1],主要包括:
1) RocksDB使用预写式日志(write ahead logging, WAL)技术保证一致性,存在写放大.RocksDB本身的LSM-Tree(log-structured merge tree)[2]机制也会带来写放大.LSM-Tree的数据压紧(compaction)机制还会带来业务的性能抖动.
2) BlueStore的元数据信息、属性信息和小数据被存储到RocksDB中,并在其中多次复制和序列化,带来较大的CPU开销.
3) 为了保证事务一致性,对小数据的更新需要先从磁盘读取更新后保存到RocksDB中,同时RocksDB有自己的WAL日志,导致Journal of Journal的写放大问题.
上述3个问题和对应的系统开销,在固态硬盘(solid state disk, SSD)和机械盘场景下,相对系统整体性能提升带来的收益来说是值得的,但在持久性内存场景下则成为了不必要的负担.
PMEM(persistent memory)[3]也称为非易失内存(non-volatile memory, NVM)或存储级内存(storage class memory, SCM),在本文统称为PMEM.PMEM因其非易失、字节寻址和原地更新等特性,成为工业界和学术界研究的热点.
BlueStore没有很好利用PMEM内存式高速处理和外存式持久化的双重能力.PMEM具有非易失、字节寻址特性[4],可以通过简化日志的方式保证事务一致性,减少日志结构引起的数据整理和写放大,以及由此带来的额外系统开销和性能瓶颈.与传统基于块的存储设备相比,PMEM提供了更高的吞吐和更低的延迟.但是,PMEM比SSD容量小且单位存储成本更高,而且目前商用的PMEM读写具有不对称性,例如通过Intel MLC[5]测得的Intel Optane DC Persistent Memory读带宽最高约为6 GBps,而写带宽则约为2 GBps.因此,PMEM更适合用来存储元数据和小数据,而SSD更适合存储大块的数据对象.充分发挥PMEM和SSD存储介质的优势特性,设计高性能的后端存储,将为解决传统存储的不足带来了新的机遇.
本文提出了一种基于PMEM和SSD的分布式后端存储MixStore,通过针对PMEM和SSD特性的组合优化设计,构建性能更优的本地存储系统,解决了Ceph现有后端存储BlueStore的写放大以及compaction等问题.
1 相关工作
Ceph现有的BlueStore被设计为一个面向SSD和HDD(hard disk drive)的存储引擎,致力于提供快速的元数据操作、避免对象(Object)写入时的一致性开销,同时解决日志双写问题.BlueStore通过将元数据保存到RocksDB来实现快速的元数据操作.通过Space Allocator进行磁盘空间管理,将Object直接写入块设备,去除对文件系统的依赖.同时,BlueStore实现了写时复制机制(copy-on-write, CoW)方式的Object更新,从而避免在日志中包含完整的Object数据,解决双写问题.但是基于RocksDB管理元数据存在写放大问题,RocksDB的compaction操作也会导致性能抖动,影响系统吞吐率.另一方面,在数据规模较大以及EC(erasure code)等应用场景中,基于RocksDB的元数据管理仍然难以满足性能要求.即使更换持久性内存等更高性能的硬件,所获得的提升也有限.
以LevelDB[6]和RocksDB[7]为代表的LSM-Tree存储引擎凭借其优异的写性能成为众多分布式组件的存储基石.在大型生产环境中,例如BigTable[8],Cassandra[9],HBase[10]等广泛部署了各种基于LSM-Tree的本地存储.LSM-Tree把小的随机写通过合并操作变成连续的顺序写,因此对HDD硬盘的写入性能有很好的优化.相比HDD来说,SSD的顺序写入和随机写入性能差别较小,所以LSM-Tree对SSD的写入性能提升有限.为此,WiscKey[11]提出一种基于SSD优化的键值(key-value, KV)存储,核心思想是把key和value分离,只有key被保存在LSM-Tree中,而value单独存储在日志中.这样就显著减小了LSM-Tree的大小,使得查找期间数据读取量减少,并减轻了索引树合并时不必要的数据移动而引起的写放大.WiscKey保留了LSM-Tree的优势,减少了写放大,但数据访问时需要进行多次MAP映射,且依然存在LSM-Tree固有的compaction过程.SLM-DB[12]基于PMEM和磁盘对LSM-Tree进行改进,将磁盘上的数据从多级树减少到1级,在PMEM上构建B树加速对磁盘数据的访问,具有低写入放大和近乎最优的读取放大特性.但在磁盘上数据依然需要做compaction操作,同时因为数据存放在磁盘,小数据的访问性能较差.NoveLSM[13]是一款基于PMEM的LSM-Tree存储结构的KV系统,旨在利用PMEM为应用提供高吞吐、低延迟的KV存储,在WAL日志满的时候,或在compaction受阻时,引入PMEM进行加速,是一种改良的LSM-Tree,但没有完全解决写放大和compaction的问题.
针对PMEM,NOVA[14]把DRAM和PMEM相结合,索引存放在DRAM中,日志放在PMEM中,每个inode都有自己的日志,日志通过链表进行组织,这样的设计充分发挥了PMEM的字节寻址特性,但因为单位存储成本较高不适合作为大容量后端存储.Ziggurat[15]提供了一个分层文件系统,将PMEM和慢速磁盘结合在一起,通过在线预测应用的访问模型,把同步的、小的数据写入PMEM,把异步的、大的数据写入磁盘,这种分层放置的策略对有多样性的访问模型有效,但对于单一数据类型的应用将不能充分发挥PMEM和磁盘的各自的特性.NV-Booster[16]提出了一种基于PMEM的文件系统来加速存储节点的对象访问,通过PMEM中的高效命名空间管理,实现了快速的对象搜索以及对象ID和磁盘位置之间的映射,其优化是针对Ceph的FileStore,未解决BlueStore所面临的问题.此外,以上这些工作都提供基于内核态的本地文件系统,由于系统调用、内存拷贝和中断而导致较大的性能开销,并不适合作为分布式存储的后端.Octopus[17]提出了一种基于PMEM和RDMA(remote direct memory access)的分布式持久存储文件系统,利用了RDMA可以直接读写PMEM的特性,将文件数据设置为全局可见,直接执行远程读写,提高性能;而文件元数据则设置为私有,对应的操作由服务端来执行,从而保证安全性和系统数据一致性.但该系统缺少对大容量SSD的集成,不适合作为分布式存储的后端.
KVell[18]是基于NVMe SSD设计的高效KV存储,核心设计思想是简化CPU的使用,数据在SSD上不排序,每个分区的索引在内存中是有序的.这种设计在每次启动时需要进行索引的重构,无法满足快速重启动的工程需求.KVell使用页缓存和LRU(least recently used)算法负责磁盘上的空闲空间申请和释放,省去了磁盘上空闲空间回收和整理的过程.但是当磁盘容量快被用完,特别是被覆盖写时,大概率触发SSD的擦除→拷贝→修改→写入过程,实际IO性能会大幅下降.Pmemkv[19]是针对持久性内存优化的本地键值数据存储,其底层包含了cmap、csmap、tree3、stree等多种存储引擎,其中csmap引擎基于SkipList实现,put、get、count等操作的性能随线程数扩展,但其remove操作使用了全局锁,限制了并发性.
在并发访问控制和事务一致性方面,Harris等人[20]利用指针标记的方法解决了DRAM上CAS(compare-and-swap)算法在并发执行节点插入和删除操作时,删除前置节点会导致插入节点丢失的问题.David等人[21]基于此研究提出一种无锁数据结构,实现了适用于PMEM的CAS算法,当使用CAS指令更新前置节点的next指针时,同步为该指针添加未持久化标记,并在完成持久化后去除此标记.其他并发的更新操作在检测到未持久化标记时,则首先执行持久化,以保证更新的线性执行.但上述方法中,保存在PMEM中的指针包含了未持久化标记,后续的标记移除操作则可能因故障而未被持久化,导致故障恢复后新的插入操作重复执行指针持久化,产生不必要的性能开销.PMwCAS[22]通过无锁持久高效的多字段CAS技术,解决了多字段更新的原子性问题,大大降低了构建无锁索引的复杂性,但未提供节点删除时资源回收的解决方案.TLPTM[23]通过分配感知和基于压缩算法的日志优化策略设计了一种基于微日志的持久性事务内存系统,虽然减少了日志的写入量,但本质上还是一种基于日志的事务系统,没有解决前述的数据双写问题.
肖仁智等人[24]从持久索引层面、文件系统层面和持久性事务等方面对面向PMEM的数据一致性相关工作进行了综述和总结,并指出在开发新的一致性的持久内存索引方面,未来更多的工作将集中在LSM-Tree和SkipList上.
综上,现有后端存储BlueStore固有的写放大和compaction问题在PMEM上更加突出,业界针对SSD和PMEM下的LSM-Tree提出了许多改进,但仍然避免不了compaction带来的性能抖动.在构建基于持久性内存的存储系统方面业界提供了一些解决方案,但大多是内核态的实现,存在较多的上下文切换和数据拷贝的开销,并且基于本地文件系统的后端存储在事务一致性保证和高效元数据访问方面并不友好,同时PMEM本身由于容量和成本原因并不适合单独构建大规模分布式存储系统,因此基于PMEM和SSD的特性联合设计后端存储存在切实的需求.
2 MixStore架构设计
针对PMEM和SSD的硬件场景,本文设计了MixStore替换原有的BlueStore,作为Ceph的后端本地存储.其最大的挑战是事务一致性处理和充分发挥新型硬件的性能,事务一致性要求一次IO更新操作要么全部成功,要么什么也没做,确保系统异常崩溃时数据的正确性.通常基于本地文件系统实现后端存储时,需要先写WAL日志,再更新数据,但这样存在严重的写放大而影响到系统的性能.与此同时,由于本地文件系统在管理文件时使用了多层级inode来管理文件数据和元数据的存放,但后端存储也有自己的元数据,会导致后端存储元数据到本地文件系统多级元数据和数据的映射的开销,所以直接基于裸盘设计后端存储更具有性能优势.
MixStore利用PMEM的字节寻址和持久性特性,把元数据和小块数据存放在PMEM中,基于SSD裸盘,把对齐的大块数据对象存储在SSD上.PMDK(persistent memory development kit)[25]是Intel提供的适用于持久性内存的开源库,专门针对PMEM进行了优化.基于PMDK事务机制可以确保在节点故障后,所有内存操作都回滚到最后提交的状态,PMDK实现了线程内的原子性,但没有提供隔离性.MixStore提出了一种基于PMEM的Concurrent SkipList索引管理机制,基于PMDK事务、区段标志位以及待删除列表的方式保证节点修改的事务一致性、原子性和并发性.同时提出了一种高效的数据对象更新管理方法.针对PMEM和SSD各自的特性,优化数据对象的访问性能.
MixStore的系统架构如图1所示.作为用户态后端存储,MixStore对外提供ObjectStore接口,内部分为元数据管理和数据对象的管理.MixStore的核心创新是在PMEM上实现了基于Concurrent SkipList的索引替换原有RocksDB所实现的元数据管理功能,去除了对RocksDB的依赖;通过直接管理Object元数据,避免了WAL和LSM-Tree机制带来的写放大和compaction时的性能抖动;同时避免了序列化和反序列化带来的CPU开销;小块的数据存放于PMEM中,并优化了小IO的事务一致性处理方法,避免了BlueStore的Journal of Journal的问题,对于大块的数据对象,首尾非最小可分配大小(minimal allocate size, MAS)对齐的部分存放在PMEM中,中间MAS对齐部分使用CoW机制存储到SSD中.得益于PMEM的字节寻址特性,对于非对齐写和小IO有更好的优化.
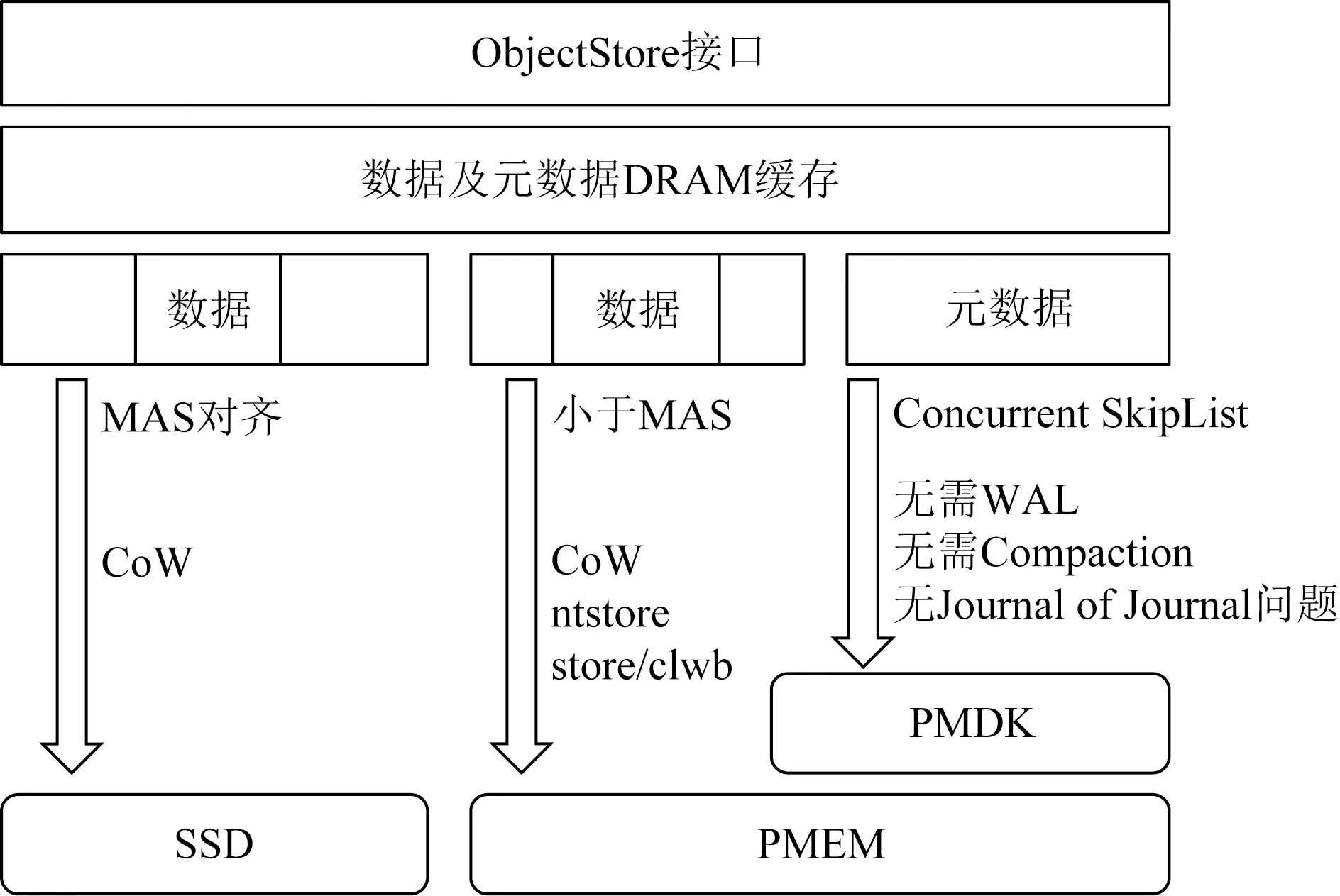
Fig. 1 System architecture of MixStore图1 MixStore系统架构图
在索引结构的选择上,现有的LSM-Tree在WAL日志更新,多层级查找及序列化方面开销巨大[13],且无法利用PMEM的字节寻址和低延迟特性,显然不适用于PMEM.有序链表因为O(N)的较高时间复杂度消耗亦不适合用作索引结构.对于树形结构,数据量的变化通常需要对树结构重新平衡,重新平衡操作可能会影响树结构的较大范围,这将需要在较多树节点上使用互斥锁.相比树结构,SkipList具有更好的局部性,更适合并发访问修改[26-27].对SkipList的操作只会影响到节点本身以及前后插入的节点,在更改SkipList结构时不需要锁住和同步整个SkipList数据,具有更好的并发性.MixStore选择SkipList作为索引结构,同时基于PMEM实现了事务一致性和并发性.
在写放大方面,PebblesDB[28]显示,插入5亿个键值对时,平均键值大小100 B,共写入45 GB数据,RocksDB实际写入了1 868 GB数据,写放大率达42倍.对于SkipList来说,只需要额外一个指针,加上中间层次节点,平均一个键值对额外增加16 B,写放大为0.16倍,远远少于RocksDB的写放大.对于每个100 B键值加上SkipList管理开销16 B,可以管理NVMe SSD上的4 KB的数据块,实际元数据最多消耗仅为数据量的2.8%.
在时间效率方面,SkipList通过维护一个多层次的链表,且与下面一层链表元素的数量相比,每一层链表中的元素的数量更少.算法首先在最稀疏的层次进行搜索,直至需要查找的元素在该层2个相邻的元素中间.这时,算法将跳转到下一个层次,重复刚才的搜索,直到找到需要查找的元素为止[29].SkipList与平衡二叉树一样可提供时间复杂度为O(logN)查找、插入和删除操作[30],而无需像B树、红黑树或AVL树所要求的那样,进行复杂的树平衡或页面拆分,并且实现起来更加简单和简洁.
在数据布局方面,根据DRAM,PMEM,SSD各自特性和优势,合理搭配使用以充分挖掘系统的性能.SSD容量最大,用于存储具体的数据内容,PMEM随机读写性能好,且具有持久性,用于存储元数据信息、磁盘空间分配信息、属性信息等,同时还存储非MAS对齐的临时的数据内容.而对于DRAM,性能相比PMEM更好,用作热点数据和元数据的缓存.对于MAS对齐的数据首先写入DRAM,然后持久化到SSD中,但在DRAM中仍然保留,直至后续被LRU淘汰.
在事务一致性方面,PMDK libpmemobj库实现了事务机制,提供更新原子性,以及崩溃一致性保证.通过Concurrent SkipList设计,基于PMDK实现了强一致的元数据管理,而不必额外使用日志机制,从而避免了Journal of Journal问题.但是PMDK未提供足够的隔离性,当多个线程并发执行事务操作时,对共享资源的访问仍然需要额外的隔离机制.MixStore通过区段标志位方式进行并发控制访问,解决了多线程隔离性问题.对于PMEM中非MAS对齐的小数据更新使用ntstore或clwb指令通过CoW方式直接写入.因为大块数据使用ntstore指令具有更好的性能表现[31],所以MixStore对于大于等于256 B的数据采用ntstore的方式进行存储,而对于小于256 B的数据采用clwb的方式进行存储.
3 关键技术
本节详细描述MixStore在元数据管理和数据对象管理方面的关键技术.
3.1 基于Concurrent SkipList的元数据管理
MixStore的元数据通过基于PMEM的SkipList进行管理,内存结构的SkipList可以基于CAS指令实现数据的并发更新机制,但在PMEM上应用CAS算法面临新的挑战.
现有的Cache Coherency模型是针对DRAM的,当CAS操作完成时,数据在CPU Cache间保持一致,但对于PMEM,仍然需要额外的clflush操作,才能完成持久化.因此,操作原子性被破坏,如果在断电时仅完成了指针的更新,而没有持久化到PMEM,则在多线程并发更新访问时,会导致数据结构的损坏,产生内存泄漏和一致性问题.
3.1.1 元数据插入机制
与David等人[21]提出的无锁数据结构不同,MixStore使用一种易失区段标记来解决并发操作一致性问题,即将SkipList分为多个区段,并在DRAM中保存每个区段的更新标记.更新操作在完成前置节点查找后,通过CAS指令将对应区段设置为更新中,以与同区段的其他更新操作互斥.更新标记保存在DRAM而不是PMEM中,以提升访问效率,并简化故障恢复处理.区段级而不是节点级的更新标记则可以缩减内存使用量,并有助于解决插入和删除并发时的节点丢失问题.为了解决跨区段更新的问题,在SkipList中引入dummy节点作为区段边界,以保证前置节点和待插入节点总是在一个区段中.此时,仅同区段的更新操作需要互斥,不同区段的更新操作可以并发执行,而查找操作不需要互斥,完全是并发执行的.
以一个2区段的SkipList为例,新元素的插入操作如图2所示,首先根据待插入元素d所属区段设置对应的更新标记,并开启PMDK事务,然后将待插入元素d的next指针指向x(x为区段中第1个元素时,则指向该区段的起始dummy节点),通过CAS操作将元素c的指针指向元素d.此时,CPU cache中的插入操作完成,元素d对查找操作可见.接下来,提交PMDK事务将更新操作持久化到PMEM中,并复位SkipList的区段更新标记.此时,CPU cache和PM中的数据视图达成一致,整个插入操作完成.对于待插入元素的高度超过1的情况,由于上层list在故障恢复时可以通过底层的数据进行重建,因此可以仅通过CAS操作进行更新,无需主动执行持久化操作.
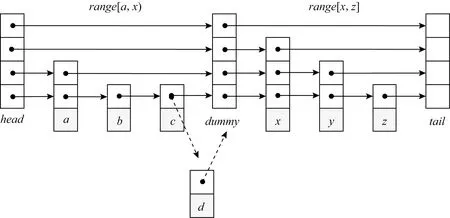
Fig. 2 Metadata insertion mechanism图2 元数据插入机制
为了进一步减少同区段的并发冲突,插入时的查找操作可以使用二次确认(double check)的方式,即首先遍历SkipList确定新元素的插入位置,然后设置区段更新标记,并再次检查前置节点的next指针,确定是否需要重新执行查找操作.完整的节点插入流程描述如算法1.
在节点插入时需要同时更新本节点的next指针和前一节点的next指针,把这2个指针更新放在同一PMDK事务中执行,确保系统的崩溃一致性,避免断电导致的各类异常,例如数据部分持久化导致的内存区域泄漏、SkipList链表断裂等情况.
算法1.插入节点Insert(node).
①pre←SearchPrevious(node.key);
②MarkRange(node.key);
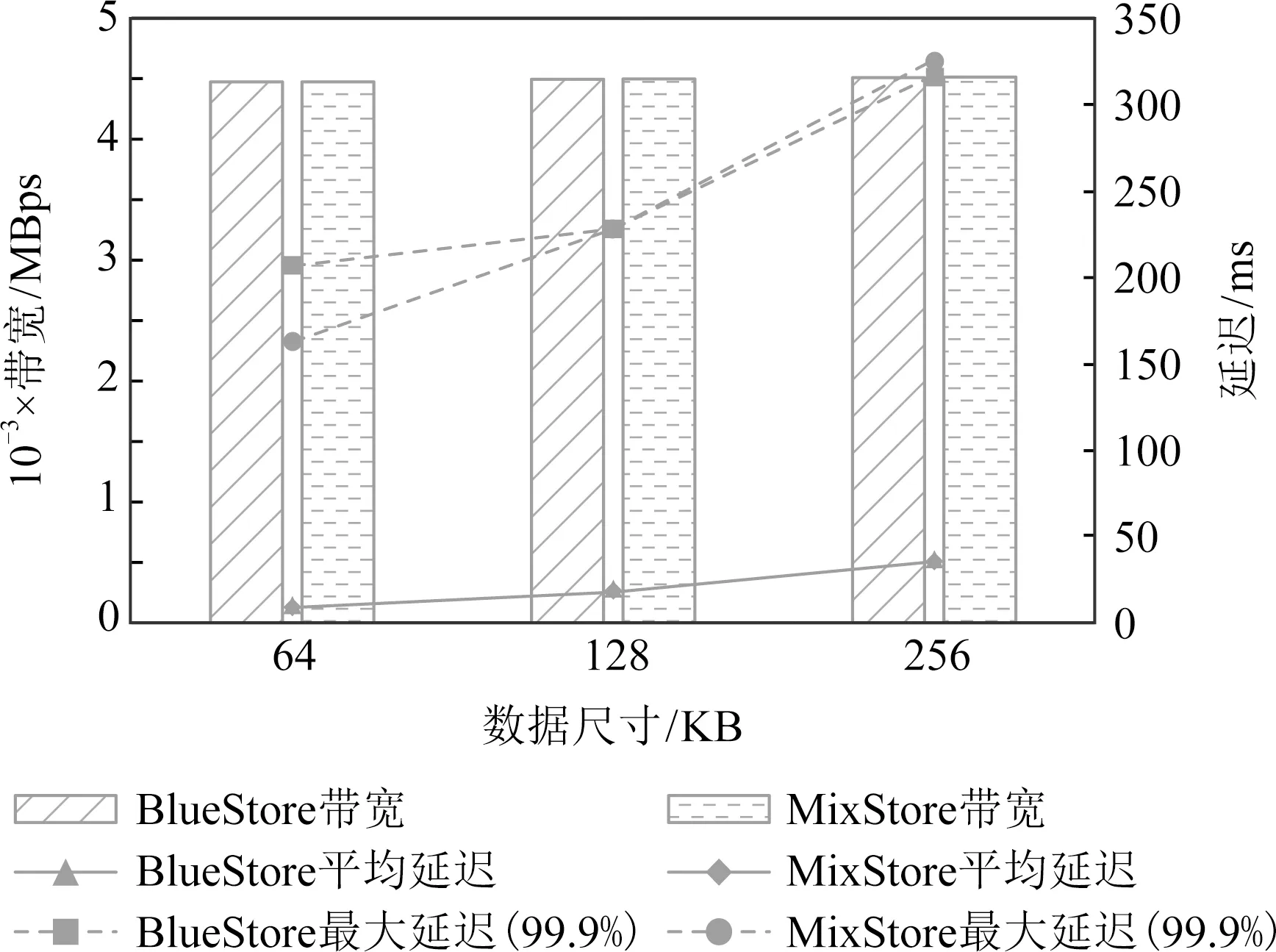
③ ifpre.next.key ④pre←SearchPrevious(node.key); ⑤ end if ⑦node.next←pre.next; ⑧pre.next←node; ⑩UnmarkRange(node.key). 3.1.2 元数据删除及查询机制 元素删除操作与插入操作类似,需要通过区段更新标记进行互斥.与插入操作不同的是,元素从SkipList移除后,由于可能有其他线程正在执行查找操作,其内存区域不能立即释放.同时,在等待释放期间,为了避免异常断电导致持久内存泄漏,待删除的元素需要进行妥善的跟踪管理. MixStore使用待删除列表解决上述问题.如图3所示,首先为每个线程维护一个SkipList访问事件时戳,线程每次完成SkipList的访问后,时戳加1.同时,每个线程有一个保持在持久内存中的待删除元素列表,该列表实际由2个数组和对应的2个时戳向量组成,在当前数组满时互相交换,并在符合特定条件时清空备用数组.时戳向量中记录了特定时刻所有线程的时戳值,线程时戳和时戳向量均无需持久化,在启动时初始化为0即可.元素从SkipList中删除时,会被暂存到待删除列表,同时更新此刻的时戳向量. Fig. 3 Metadata deletion mechanism图3 元数据删除机制 以删除元素c为例,首先设置区段更新标记,并开启PMDK事务,然后使用CAS操作将元素b的next指针指向元素x.此时,元素c对后续的查找操作不可见,但仍然可能有查找过程正在访问元素c.然后,元素c被加入待删除列表,提交PMDK事务完成持久化,同时复位区段更新标记.接下来,更新时戳向量,记录当前时刻所有线程的时戳值.显然,删除操作发生在此时戳向量之前,当后续某一时刻的时戳向量严格大于该值时,即每个线程的时戳都大于旧值时,元素c的内存可以被释放.具体而言,在更新当前时戳向量后,将当前时戳向量与备用数组的时戳向量进行比较,并确定是否清空备用数组.完整的节点删除流程描述如算法2所示. 算法2.删除节点Remove(key). ①pre←SearchPrevious(key); ②MarkRange(key); ③ ifpre.next.key≠keythen ④pre←SearchPrevious(key); ⑤ end if ⑥curr←pre.next; ⑧pre.next←curr.next; ⑨AddToSwaplist(curr); 在进程重启后的故障恢复阶段,由于待删除列表中的元素仍然可能会被其他线程的恢复过程访问,故保留待删除列表中的元素,并将2个时戳向量重置为0.此时,待删除列表中的元素被延迟到后续删除操作中进行清理. 与插入和删除不同,查询操作不需要关注区段标记.节点插入时,链表指针的更新通过原子操作完成,从链表中删除的节点则首先保存在额外的待删除列表中,直到查询操作完成后相关内存才被释放.因此,查询操作是完全并发的,不存在等待时间,故而具备较高的性能和延迟一致性表现. MixStore充分利用PMEM的字节寻址特性,来优化Object的写入性能.一方面,Object的元数据使用存储在PMEM中的SkipList进行管理,另一方面,对于非对齐IO和随机小IO,也利用PMEM,通过不同的写入策略进行优化. 虽然SSD有较好的随机读写性能,但相比于顺序读写仍有所降低.为此,设定SSD的最小分配大小MAS,对于普通的SATA SSD来说,MAS=16 KB.对于NVMe SSD来说,因为有更好的随机读写性能,我们设定MAS=4 KB.通过数据写入策略的设定,有效减少了SSD的随机读写,进一步优化系统的性能. Object更新时,小于MAS的数据被直接写入PMEM,后续小IO写入也直接在PMEM中进行追加更新和合并,从而有效减少了SSD的磨损和闪存转换层(flash translation layer, FTL)频繁垃圾回收(garbage collection, GC)导致的性能抖动.对于此类数据,如图4左侧部分所示,BlueStore采用DeferredWrite策略,即首先从SSD读取旧数据与新数据进行合并,获得block对齐的待更新数据块,然后将待更新数据块和元数据作为WAL写入RocksDB.最后,异步执行数据的In-Place更新,并在完成数据写入后删除WAL.这种方式导致在构建WAL时即需要执行SSD数据读取,且增加了PMEM的写入数据量.与BlueStore不同,MixStore对异步写入的数据不使用In-Place更新策略,如图4右侧部分所示,MixStore将非对齐小IO直接写入PMEM,然后异步执行SSD读取操作并进行CoW异地更新.MixStore面向更高性能的PMEM和SSD设计,由于数据的不连续分布对SSD设备的读性能影响要远小于HDD,因此选择CoW异地更新而不是In-Place更新,从而避免了构建WAL,降低了PMEM写入数据量;此外,PMEM的高性能也可以更好的支撑不连续的读取操作,使得MixStore可以使用更惰性的数据回写策略,从而提升非对齐小IO的合并概率,减少最终的SSD写入次数和数据的碎片化. Fig. 4 Comparison of unaligned IO processing图4 小IO数据更新流程对比 对于大于MAS的更新操作,则首先进行MAS对齐,将其切分为3个部分,即首尾非MAS对齐的部分和中间MAS对齐的部分.对于首尾非对齐部分使用与小IO相似的方式处理,对齐部分则使用CoW策略,在写入SSD后更新元数据信息.具体而言,整个更新操作分为2个阶段,即首先将中间MAS对齐部分异地写入SSD,首尾非对齐部分写入PMEM,然后将所有的元数据修改在一个PMDK事务中完成. Object读取时,通过访问SkipList获取数据存放位置信息,首选从SSD中读取本次IO涉及的数据区域,然后从PMEM中读取非对齐的小IO增量,并进行必要的合并即可.得益于PMEM的随机访问性能,对数据的碎片化有更高的容忍度,读性能仍然可以保持较高的水平. MixStore根据PMEM的可用容量和数据的碎片化情况决定是否执行合并操作,PMEM读取4 KB数据的延迟通常不超过5 μs,而NVMe SSD的4 KB读延迟通常在100 μs左右.MixStore在读操作中检查数据的碎片化情况,当碎片数量超过阈值以后,触发合并操作,合并后的数据使用CoW的形式进行更新,以避免In-Place更新可能的一致性问题.碎片阈值是动态的,在PMEM容量充足时,碎片阈值较高,并随着可用容量的减少而逐步降低. 本实验采用的硬件配置信息如表1所示,实验在一个由40 GbE以太网交换机连接的4节点集群上完成,测试使用的持久内存为Intel最新推出的Optane DC持久性内存,单条容量为256 GB,NVMe SSD为Intel的P4610,单盘容量为1.6 TB.PMEM可以配置为App-Direct或Memory这2种工作模式,由于本实验都是把PMEM作为持久存储来使用,所以采用App-Direct模式.本实验对比BlueStore和MixStore测试时所采用的硬件环境相同. Table 1 Experiment Configuration表1 实验环境配置 所有主机均安装Fedora release 29,内核版本升级到4.18.16-300,以提供对PMEM的支持.测试基于Ceph Luminous 12.2.12或其修改版本完成,使用FIO 3.10进行负载模拟. Ceph集群部署在其中3台安装了PMEM和NVMe的主机上,PMEM配置为fsdax模式.另一台主机作为客户端运行FIO程序,该主机上实际未安装PMEM和NVMe设备. 测试BlueStore时,PMEM作为块设备使用,用于存储WAL和DB数据,SSD用于保存对象数据.测试MixStore时,PMEM格式化为ext4-dax,然后通过MMAP转换为持久内存使用,PMEM用于存储索引和小块数据,大块对象数据保存在SSD上. 本次测试使用FIO工具的rbd ioengine访问Ceph RBD接口,后端为2副本存储池.为了更接近真实负载,FIO的队列深度被设置为32,而不是更大的值.每次测试使用20个FIO客户端分别对20个大小为50 GB的RBD Image进行读写,测试过程持续5 min. 4.2.1 写性能 本次测试覆盖了小IO随机写入和大IO顺序写入2类场景.对于随机写入,为了进一步确认BlueStore和MixStore针对不同数据大小的写入策略差异,分别测试了2 KB,4 KB,16 KB的数据写入.对于顺序写入,分别测试了64 KB,128 KB,256 KB的数据写入. 每组数据测试完成后,重启全部OSD(object storage daemon)节点,以排除缓存等因素的干扰. 小IO随机写入的性能如图5所示,可以看到,对于所有随机写入场景MixStore均有优于BlueStore的表现,其中4 KB写入高出约59%,这显然得益于MixStore的高效原数据管理和事务日志的消除.对于2 KB随机写,BlueStore和MixStore均使用PMEM进行数据暂存,不同的是,BlueStore需要执行read-merge-write操作,因此最终写入PMEM的为包含4 KB数据块的事务日志,而MixStore则直接将2 KB的数据以及相关元数据写入PMEM.测试过程中,通过iostat或pcm-memory.x可以观察到MixStore消除了NVMe读操作,PMEM写带宽约为BlueStore的一半.但由于NVMe磁盘实际负载较小,最终MixStore测试结果仅表现出与4 KB类似的优势,领先BlueStore约56%.对于16 KB的随机IO,MixStore领先约34%,一方面,MixStore更高效的元数据操作释放了NVMe的性能,另一方面,对于16 KB的数据,NVMe写操作在整个请求处理开销中的占比上升,导致最终的性能优势不如4 KB数据明显.MixStore的平均延迟和尾延迟也呈现出和IOPS相同的优势,平均延迟约为BlueStore的63%~75%,尾延迟约为BlueStore的72%~84%. Fig. 5 Comparison of random write图5 随机写测试对比 如图6所示,对于大IO顺序写入,MixStore和BlueStore基本表现出相同的性能,平均延迟也基本相同.这是因为对于64 KB以上的写请求,2个系统的处理策略基本相同.较大的数据尺寸也导致请求处理的主要开销来自于SSD写入操作,软件栈的差异被进一步削弱.即便如此,由于具备更好的元数据操作并发性,MixStore仍然表现出了更好的尾延迟,约为BlueStore的54%~91%. Fig. 6 Comparison of sequential write图6 顺序写测试对比 4.2.2 读性能 对于读操作,本次测试选择了与写操作相同的数据特征,即针对2 KB,4 KB,16 KB的随机读取,以及64 KB,128 KB,256 K的顺序读取场景进行测试.同样,每组测试完成后重启所有OSD,以消除缓存的干扰. 对于小IO随机读,如图7所示,MixStore和BlueStore有基本相同的IOPS和平均延迟,这是因为在排除缓存干扰后,读操作的开销主要来自于磁盘数据读取.而较大的写入总量也导致读操作更多的是从SSD而不是PMEM读取数据,因此不同数据大小的测试之间并未体现出差异.但得益于MixStore元数据访问的高并发性,在16 KB读取测试中,MixStore的尾延迟表现出了23%的降低. Fig. 7 Comparison of random read图7 随机读测试对比 对于大IO顺序读,如图8所示,受限于本次测试的网络环境,BlueStore和MixStore未能体现出差别,仅64 KB顺序读MixStore体现出约21%的尾延迟降低.128 KB及256 KB的性能制约则更多来自于网络传输. Fig. 8 Comparison of sequential read图8 顺序读测试对比 现有的分布式存储的后端存储存在着明显的写放大和compaction消耗.持久内存具备字节寻址,接近DRAM性能,掉电不丢数据等特性.但持久内存容量较小,更适合存放数据的元数据或小的数据的缓存,相反SSD容量较大,顺序读写性能更优,更适合存放大块的数据.MixStore充分利用持久内存和磁盘各自的特性,把两者结合起来,通过构建Concurrent SkipList进行精细的索引元数据组织,以及通过惰性的CoW的数据存放机制,提供了高性能的后端存储,有效减少了写放大和避免了compaction带来的消耗.实验显示,相比BlueStore,MixStore的写吞吐提升59%,写时延降低了37%,有效地提升了系统的性能,并且具有更好的读写尾时延表现.展望未来,随着新型器件的发展和持久内存产业化水平的提升,计算、存储和网络能力都将显著提升,可能会出现基于持久内存等新型器件构筑的全新存储环境.我们需要重新审视现有的设计和优化机制,并设计新的算法来适配新的硬件环境.
3.2 数据对象管理

4 实验及分析
4.1 实验环境

4.2 性能对比

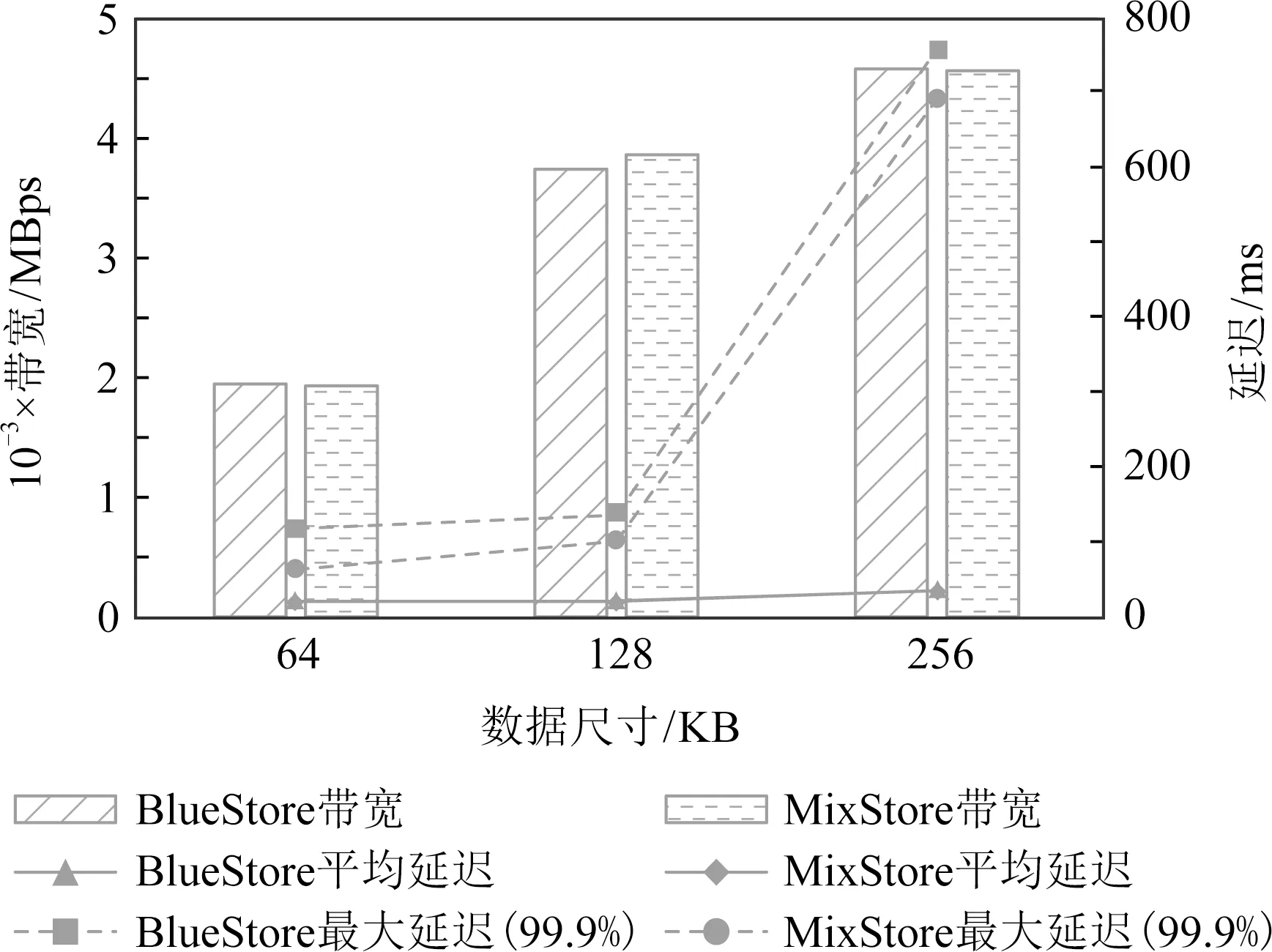
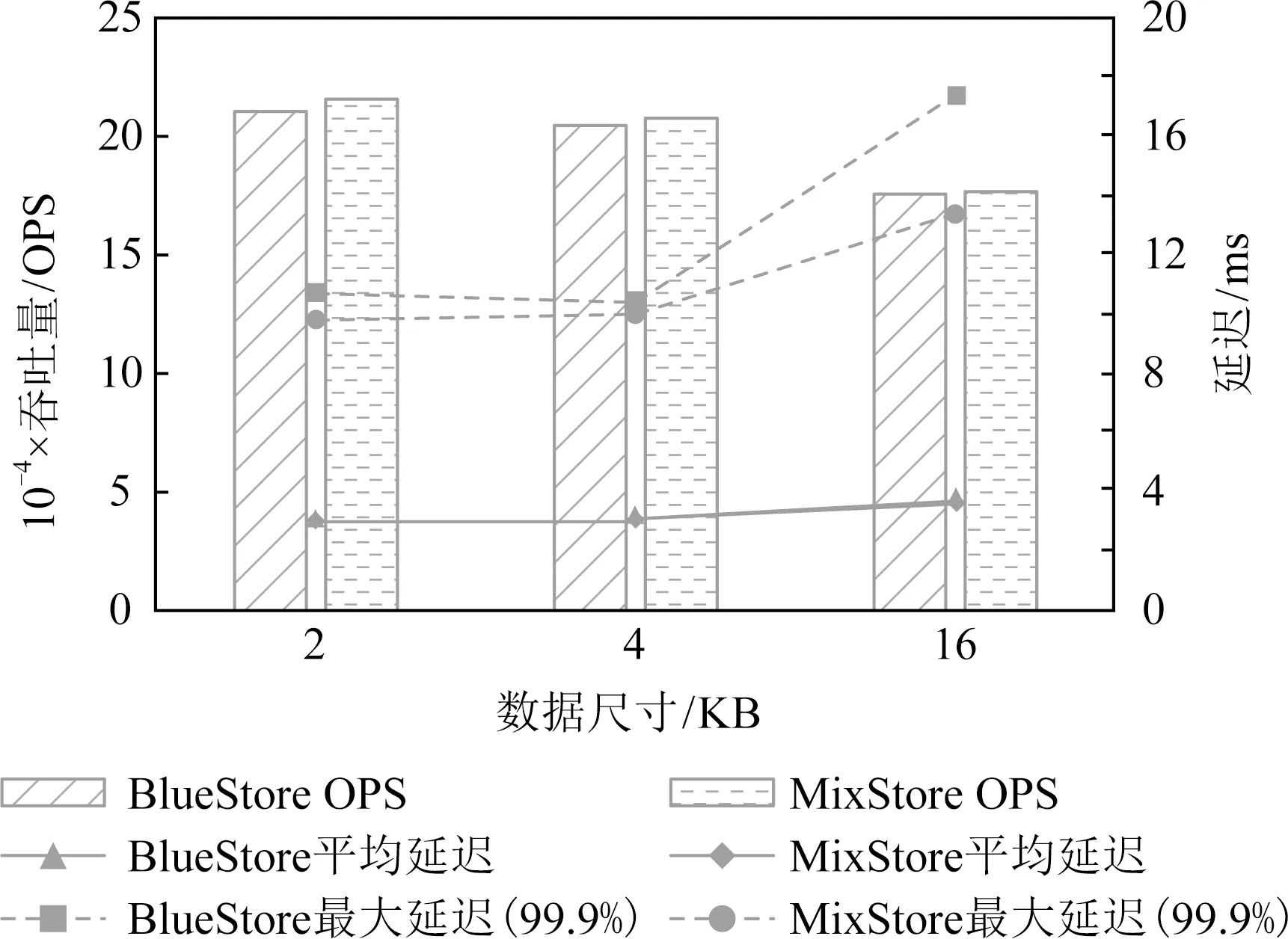
5 结 论
猜你喜欢
云南画报(2021年11期)2022-01-18
华人时刊(2021年13期)2021-11-27
诗选刊(2020年12期)2020-12-03
电脑爱好者(2020年18期)2020-09-26
装备维修技术(2020年33期)2020-08-10
科技视界(2020年8期)2020-05-18
电脑爱好者(2019年2期)2019-10-30
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
电脑知识与技术(2017年14期)2017-07-10
