
基于区块链的数据透明化:问题与挑战
2021-02-06 09:27孟小峰刘立新
计算机研究与发展 2021年2期
孟小峰 刘立新,2
1(中国人民大学信息学院 北京 100872)2(内蒙古科技大学信息工程学院 内蒙古包头 014010)(xfmeng@ruc.edu.cn)
随着大数据技术和人类生产生活的交汇融合,丰富的数据通过多种方式源源不断地被多方数据收集者收集,进而依据这些数据进行数据决策和提供服务.这种先予后取的数据收集模式已成为越来越多应用的必要条件.固然大规模数据收集为个人、企业和国家带来巨大的数据价值,但也带来隐私泄露和决策不可信等问题,表现为大规模数据收集(mass collection)、大规模数据监视(mass surveillance)和大规模数据操纵(mass manipulation)三个方面.
1) 大规模数据收集.大规模数据通过被动、主动和自动方式被收集,如医疗就医、购物、网站搜索、个人移动通信、出行和位置轨迹等数据.然而,作为数据生产者,我们不知道哪些数据被收集、被谁收集、数据被收集后会流向何处以及作何使用,导致隐私泄露追踪问责困难.
2) 大规模数据监视.大规模数据收集导致大规模数据监视,例如医疗就医和个人移动通信等数据被政府部门收集,购物、社交和出行等数据被各大公司掌握.个人在享受服务的同时也时刻处于被监视状态,个人隐私在深度和广度受到巨大冲击.
3) 大规模数据操纵.由于现有政策、技术和制度的不完善,数据战略合作和数据交易等过程中存在大量用户隐私与安全问题.在数据决策过程中,数据非真实产生、数据被篡改、数据质量管理过程中的单点失败等问题导致决策数据不可靠,由此导致数据决策结果不可信[1-2].然而,我们深受数据操纵影响却对此束手无策.
“Facebook-剑桥分析事件”是大规模数据收集、大规模数据监视和大规模数据操纵的典型案例.匿名和差分等传统隐私保护技术主要解决数据发布时的隐私泄露问题,致使其并不能很好地解决当下数据自主汇聚产生的隐私泄露问题.同时,数据决策应用于人类生产生活的方方面面,决策数据不可靠导致的决策不可信是影响大数据进一步发展和应用的重要因素[3].
进一步,数据自主汇聚还导致数据垄断现象出现.数据本身的易聚集特性、大公司覆盖各数字化领域的商业模式和庞大的用户规模等因素加剧数据聚集现象,各公司数据持有量出现差异[4].我们在2019年《中国隐私风险指数分析报告》中对3000万移动用户的权限数据(权限数据是指在移动场景下,某用户安装并使用一系列App,数据收集者通过App的权限体系获取该用户的个人隐私数据)收集情况进行分析,数据收集者获取权限数据的分布如图1所示[5].可以看出前10%的数据收集者获取大于99%的数据,数据垄断现象已悄然形成.数据垄断可能会阻碍市场竞争、使消费者福利受损、阻碍行业技术创新和带来更严重的个人隐私泄露风险等.现实世界财富获取的“二八定律”指20%的人占有80%的社会财富,这依赖于法律、税收等方式的调节.而在虚拟世界,如果将数据比作财富,还是一个没有得到有效调节和分配的领地.因此,急需建立相关技术手段和法律法规.

Fig. 1 Data acquisition distribution of the collectors图1 数据收集者权限数据获取分布
如何使这些问题得到有效治理,使数据得到正确、合理和规范地使用是大数据发展面临的主要挑战.导致这些问题的主要原因是大数据价值实现过程中存在不透明性,数据获取和数据等共享流通过程的不透明性使隐私泄露问题问责困难和数据垄断问题缺乏解决依据,数据决策的不可审计性导致大数据驱动的决策不可信.工业界对大数据价值实现过程的透明性提出迫切需求.苹果CEO库克在2019年《时代周刊》发表评论建议设立新框架增强企业处理用户数据的透明性,并建议建立数据清算和要求所有数据中介在清算所注册,从而使用户能够跟踪被捆绑并被销售的数据.Gartner发布的2020年战略性技术研究趋势报告中也将“透明性与可追溯性”作为十大战略性技术趋势之一[6].
增加大数据价值实现的透明性,是促进大数据正确使用的重要举措和必经之路.据此,本文提出数据透明性的概念,指在大数据价值实现过程中,各个参与方都能获取与自身相关的全部数据信息.并将数据透明性分为数据获取透明性、数据共享透明性、数据云存储服务透明性、数据决策透明性和法律法规透明性5个部分,通过这5个部分实现数据透明化.数据透明化需要公开透明地记录数据的获取和共享流通等信息,以及去中心化地管理数据和执行数据质量管理.这些需求与区块链的特性天然契合,而且区块链的去中心和不可篡改特性使数据透明化具有更强的问责能力.
1 数据透明化概述
数据透明化旨在增加大数据价值实现过程的透明性.其研究内容涉及数据生命周期内各阶段,其实现途径主要包括法律法规和技术方法等方面.
1.1 定义与研究框架
文献[7]在2017年提出数据透明化概念,并建议从数据透明性策略、日志系统和算法透明性3个方面进行实现.但是对数据透明化的研究维度划分没有涵盖大数据生态中的主要透明性需求,也没有深入分析数据透明化与当前大数据生态中的隐私保护、决策可解释和数据垄断关系.
本文提出的数据透明化研究与文献[7]一脉相承,都是保证大数据在其生命周期内各个阶段的透明性.但本文对数据透明化研究的划分更为清晰和具象,进一步将数据透明化研究放在大数据生态范围进行考虑,并阐述数据透明化研究与数据隐私保护、决策可解释和数据垄断的内在关系.
实现数据透明化涉及到大数据生命周期内多方参与主体,各个参与主体有不同的数据透明性需求.目前,参与主体主要包括数据生产者(data contri-butors)、数据收集者(data collectors)、数据使用者(data consumers)、数据处理者(data processors)和数据监管者(data supervises) 5个角色.其中,数据生产者是指产生数据的个人或机构;数据收集者是指收集数据的个人或机构,如服务提供者和科研工作者;数据使用者是指任何形式使用数据的个人或机构;数据处理者是指在授权的情况下代替数据使用者处理数据的个人或机构;数据监管者是指对数据生命周期各阶段的数据共享流通等情况进行监管的机构,主要包括政府部门、可信第三方组织等.各参与主体之间可能存在重合,例如当数据收集者自己使用数据并且具有处理能力时,数据收集者也充当数据处理者和数据使用者.
定义1.数据透明性.在大数据价值实现过程中,使所有参与主体均能有效获取与自身相关的全部数据信息.其中,数据信息包括原始数据、间接数据和决策数据.
数据透明化研究围绕各方参与主体的数据透明性需求展开,根据大数据生命周期和各方参与主体的透明性需求,将数据透明性分为数据获取透明性、数据共享透明性、数据云存储服务透明性、数据决策透明性和法律法规透明性5个部分.通过实现数据获取透明性和数据共享透明性来记录数据获取和共享流通等信息,在隐私泄露和数据滥用等事件发生后进行追踪溯源,并对违反规范的参与方进行问责;通过实现云储存服务透明性增加云存储服务的可信性;通过实现数据决策透明性对决策数据进行审计,从而促进大数据驱动的决策的可信性.数据透明化研究框架和各部分信息如图2所示.
1) 数据获取透明性.数据获取透明性指对数据收集内容、形式和使用目的等信息进行记录,数据生产者、数据收集者和数据监管者等能获知相关信息.目前,通过透明增强工具(transparency enhanced tools)、数据使用协议和可审计的访问控制等方式实现获取透明.
2) 数据共享透明性.依据数据共享方式,数据共享透明性可以分为支持溯源问责的数据共享、可验证分布式数据集共享和可验证的分布式机器学习.当发生数据访问和流通时,需要实现支持溯源问责的数据共享,对数据流向进行记录,数据生产者和数据监管者能够据此对数据共享情况和隐私泄露进行追踪问责,数据处理者和数据使用者能据此说明是合法使用数据.当由于传输代价和法律法规等因素限制,需要在不泄露原始数据情况下通过分布式数据集共享技术和分布式机器学习等方式进行数据共享,这时需要对数据提供者(包括数据生产者和数据收集者)提供的加密数据和参数等进行记录,数据使用者可对共享过程进行验证.

Fig. 2 Dimensions of data transparency图2 数据透明化研究框架
3) 数据云存储服务透明性.越来越多的企业和个人将数据存储到云服务器,享受云存储服务带来的便利.然而传统的数据完整性验证、可验证可搜索加密、确定性数据删除等云数据安全和隐私保护技术通常依赖于可信的第三方且实现过程存在不透明性,实现数据云存储服务透明性旨在增加其透明性.
4) 数据决策透明性.数据是决策的基础,所以数据使用者需要对决策数据进行审计和追踪溯源.除此之外,数据决策透明性的实现还需要算法可解释和算法透明的支持(1)目前,关于算法透明和算法可解释有2种理解.一类认为两者是不同的,透明是指算法源代码或者实现原理等内容的公开(public),而可解释则是指向用户解释算法是如何做决策,侧重解释(interpretation)和理解(understanding);另一类认为两者相同,指解释和理解..算法可解释性主要是指机器学习算法的可解释性,即合理解释特定机器学习算法做决策原理以及判断算法是否存在不公平现象.算法透明是指选择合适方式公开决策算法.
5) 法律法规透明性.法律法规是技术之外重要的数据透明化实现手段.世界各国家和组织出台法律法规将知情同意作为个人隐私数据获取、共享、使用和存储等过程的基本要求.知情同意是指数据收集者在收集个人数据之时,应当充分告知有关个人数据被收集、处理和利用的情况,并征得主体明确的同意.例如,欧盟实施的《一般数据保护条例》将透明性作为数据主体的基本权利.
通过上述5个部分的数据透明性实现可以将各方参与主体所需要的数据信息作为溯源数据记录下来.之后,可以依据这些溯源数据实施追踪问责和对数据决策进行验证.通常情况下,在问责过程中,需要策略承诺(policy compliance)、违反检测(violation detection)和隐私审计(privacy audit)等支持;在决策过程中,对数据决策验证后,还需要综合考虑数据自动决策和人工决策去获取更加全面的决策结果.
1.2 实现途径
数据透明化需要从法律法规和技术2种主要途径进行考虑.法律法规具有威慑和事后惩罚的作用,技术上实现数据透明性能够事先预防和为事后提供依据.
法律法规中数据透明性要求的实现建立在法律法规约束、第三方信用背书和道德自律的基础上.然而,第三方信用背书仅从形式上告知用户数据获取内容、数据共享情况和如何使用用户数据等情况[8].而由于数据获取、数据共享和数据使用等过程对外不可见,其契约履行情况也无从考证.
技术上实现数据透明性为各个参与主体获取与自身相关的数据信息提供技术支持.数据获取透明性和数据共享透明性的实现需要可信的“账本”记录数据获取和共享流通等信息;数据云存储服务透明性和数据决策透明性需要去中心方式执行验证、管理数据和执行质量管理等.数据透明化的这些需求与区块链[9-10]的不可篡改、可追踪、去中心和公开透明的特性相契合.
总体而言,法律法规和技术2种途径之间既存在互相支持关系也存在互补关系.本文主要探讨技术途径实现数据透明性.
2 数据获取透明性和数据共享透明性
大数据获取形式多样且共享流通错综复杂,对于直接发生数据流通的场景,需要实现支持溯源问责的数据获取和共享,当发生隐私泄露时,数据生产者和数据监管者能够进行溯源问责;对于需要在分布式数据集上实现数据共享和机器学习的场景,除了需要考虑安全和隐私,还需要考虑透明性和可验证性,数据使用者能对其过程进行验证.
2.1 支持溯源问责的数据获取和数据共享
现有关于支持溯源问责的数据获取研究还相对有限,数据未知收集、数据过度收集和用户缺乏控制权等问题有待解决.皮尤研究中心一份关于美国隐私状况的报告指出:91%的受访者认为他们对个人数据被收集和使用已经失去控制,61%的受访者对不了解数据收集者如何使用个人数据感到沮丧[11].文献[12]提出基于区块链管理移动应用程序的权限,通过权限透明管理实现数据的获取透明和支持溯源问责.当用户安装App时,将权限列表存入区块链,数据经加密后存储在分布式散列表(distributed Hash table, DHT),用户发送交易实现权限授予、更新与回收.
现有研究大多基于区块链实现支持溯源问责的数据共享.数据被收集后,由数据收集者存储并通过访问控制等方式与其他第三方进行数据共享.然而大多数访问控制遵循OAuth开放网络标准实现访问授权,由数据收集者作为处理访问控制逻辑的授权引擎,这导致数据共享不支持审计溯源问责.通过访问控制与区块链结合实现数据共享透明可以支持溯源问责,已经应用在物联网[13-15]、医疗[16-17]、社交网络[18]和边缘计算等场景[19-20].
基于区块链实现的访问控制可以概括为“数据获取层—存储层—区块链层—共享层”4层.在数据获取层,数据收集者获取数据生产者产生的数据,需要实现数据获取透明.在存储层,采用传统数据库管理系统、云存储和分布式存储系统等方式存储数据[21],同时为保证数据安全通常需要将数据加密后存储.在区块链层,与传统访问控制模型自主访问控制(discretionary access control, DAC)、强制访问控制(mandatory access control, MAC)、基于属性的访问控制(attribute based access control, ABAC)和基于角色的访问控制(role-based access control, RBAC)等相结合,由区块链执行访问控制,使任何数据访问情况都通过交易被记录在区块链.在共享层,实现数据共享并对共享关系进行保护.
图3为基于区块链实现社交网络数据共享.①~③为服务提供者向用户申请获取数据,④⑤为访问请求与授权,⑥~⑨为区块链执行访问控制.
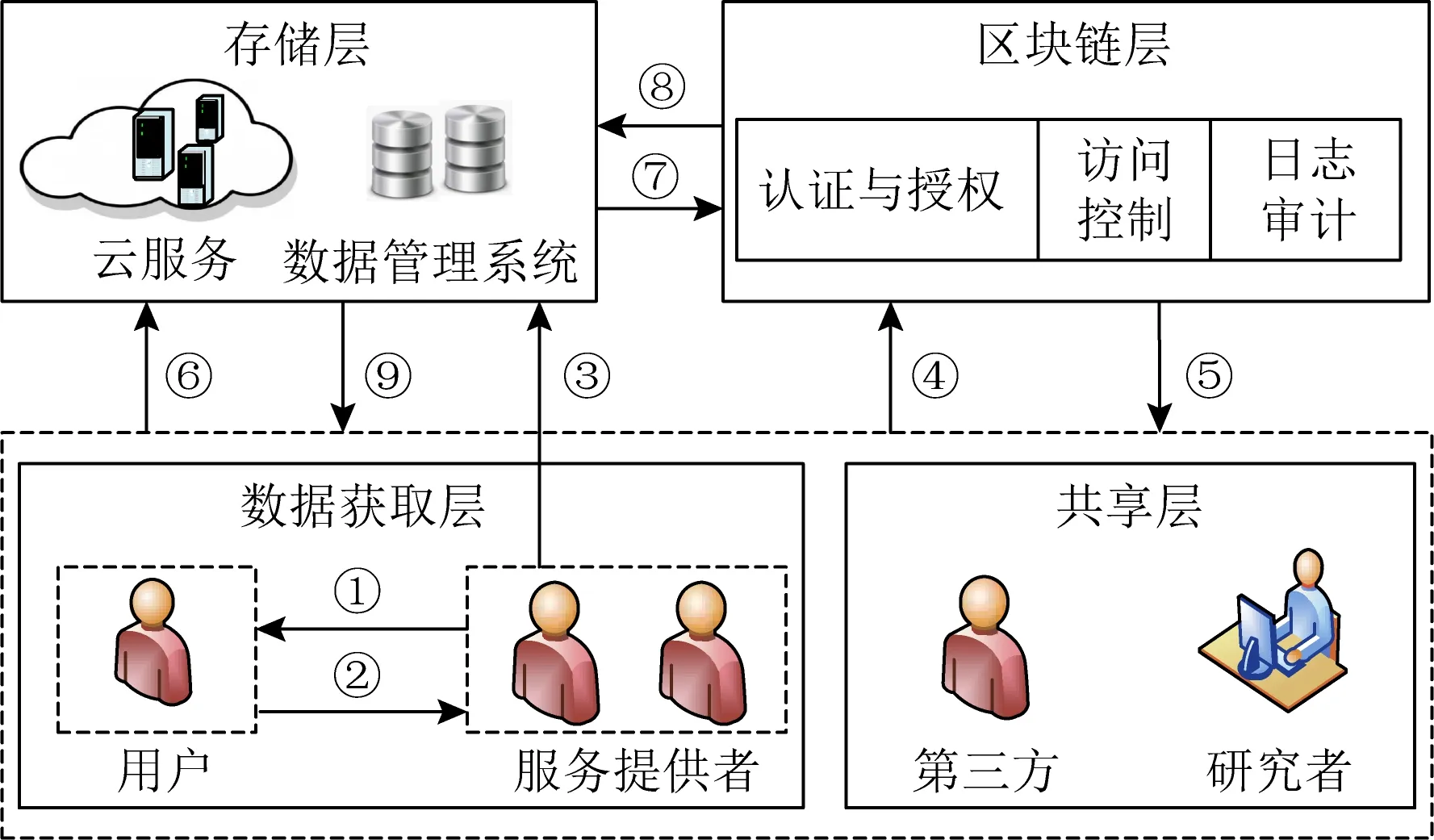
Fig. 3 Data sharing based on blockchain for access control图3 基于区块链实现社交网络数据共享透明性
基于区块链实现访问控制可分为基于交易和基于智能合约2种方式.基于交易方式是使用区块链的交易对访问控制的策略权限进行管理.大多方法基于比特币的安全性,应用OP_RETURN指令在比特币上存储策略权限.由于比特币脚本不适合实现复杂的业务逻辑,所以常结合DAC模型实现访问控制[12].在物联网数据共享场景中,考虑到底层区块链的可扩展性,区块链层之上增加虚链层来提高系统可扩展性[14,22].针对物联网设备计算和存储能力受限,目前有2种解决方法:一种方法是采用RBAC模型的扩展模型OrBAC,引入比特币钱包执行访问控制代理,并通过授权令牌形式管理权限[13];另一种方法是在区块链之下添加边缘设备层,由边缘设备管理设备的身份验证、创建交易、收集和发送数据至存储层[15].
基于智能合约方式是将访问控制策略编写为智能合约,由智能合约自动执行,当前研究尝试与DAC或ABAC等访问控制模型相结合.DAC模型基于身份进行授权,与智能合约结合实现不同身份的用户权限判断透明.文献[16]将策略存储在以太坊智能合约实现分布式医疗数据库共享.但是随着策略规模增加,以太坊智能合约运行成本会增大,且其权限管理不够灵活;考虑到分布式数据库可能存在的安全问题,文献[17]基于Fabric并采用对称密码加密医疗数据并将其存储在符合法律法规要求的云存储;文献[18]依据Fabric实现社交网络数据共享透明;文献[19]实现不同利益相关者边缘设备上数据共享透明,并提出符合边缘设备应用的共识机制、交易类型和区块来适应边缘设备计算和存储能力.DAC模型与区块链相结合能支持问责,但区块链公开透明性也会泄露共享关系和身份隐私,一定程度上仅依据假名并不能保护用户隐私.ABAC模型通过属性对实体及约束进行描述,按照访问者权限条件设置属性和权限的关系,将区块链与ABAC模型相结合能实现细粒度的、支持身份隐私保护和透明的共享.文献[23]基于区块链解决属性签名时密钥管理问题实现医疗数据共享;文献[24]基于EbCoin区块链实现ABAC访问控制;文献[25]基于属性签名和密文策略属性加密实现物联网数据共享;文献[26]设计密文策略属性加密实现数据共享.采用ABAC模型,策略不会随用户数量呈指数增长,但需权衡问责与隐私保护.
上述方法依据区块链实现访问控制直接进行数据共享流通,可能会带来隐私泄露和数据滥用等问题,例如数据收集者承诺使用数据用于科研,而实际却是用于广告推荐.由区块链执行访问控制,与同态加密、安全多方计算相结合[27-28]实现可控的间接数据共享,可避免上述因数据共享流通带来的问题.此外,数据共享过程中,还可借助区块链实现无需第三方的公平支付,激励数据共享[29-32].
表1为基于区块链的数据获取和共享透明方法对比.在区块链层,基于交易的方式多采用比特币;在共享层,大部分方法都不支持共享关系保护[33-37].同时,大部分方法都是实现访问控制,只有文献[32]提出通用的数据共享协议,具有普适性和更广泛应用场景.此外,这些方法都基于现有区块链实现,没有考虑现有区块链可扩展性对实现数据获取与共享透明的影响[38-40].
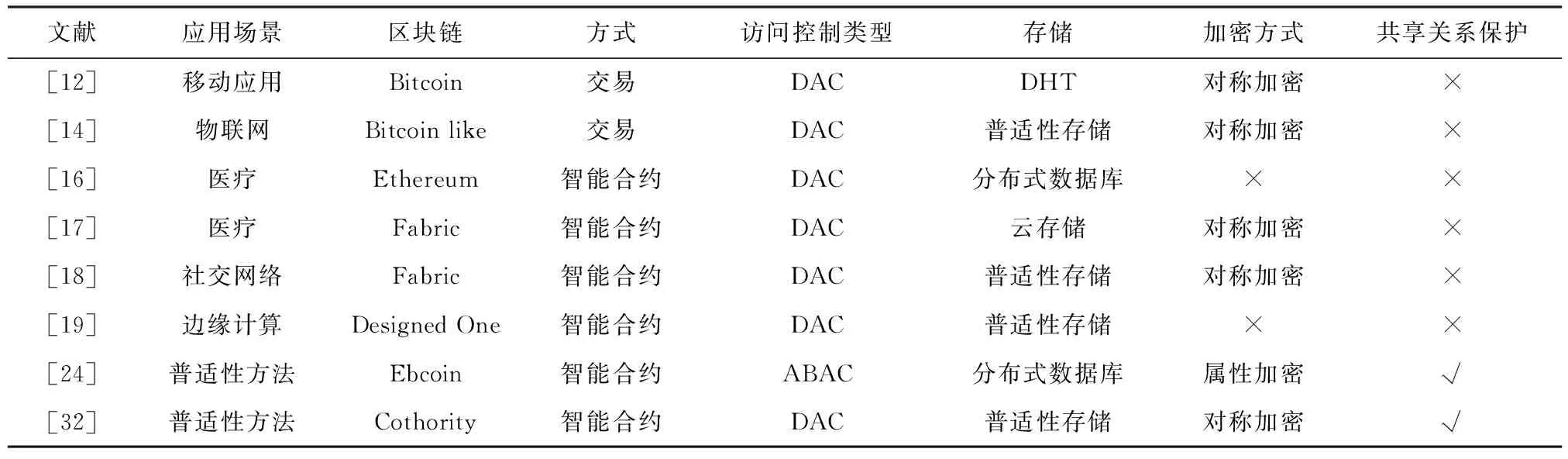
Table 1 Access Control Methods Based on Blockchain
综上所述,区块链和传统访问控制模式结合从技术上实现数据获取性和数据共享透明性,使数据生产者能控制自己的数据.但是还存在5个待解决问题:1)数据获取透明性相关研究仍然有限;2)大量访问控制请求带来区块链存储和可扩展性需求,区块链系统的效率成为亟待解决的重要问题;3)将策略和权限存储在区块链,很容易被攻击者找到漏洞,同时会泄漏共享关系,因此需要有效的方法对其进行保护;4)区块链交易确认时间会影响权限更新的及时性;5)大部分研究只给出理念和系统设计,并未提供具体技术实现方法.
2.2 可验证的分布式数据集共享
在医学研究、公共安全和商业合作等很多领域,限于一些安全和隐私因素并不能直接传输原始数据,需要在分布式数据集上执行统计分析实现数据共享.分布式数据集共享方法如图4所示.早期的PeerDB[41]和混合P2P系统[42]等传统分布式数据管理和共享系统并没有考虑隐私和安全.考虑安全和隐私的方法可以分为中心化和去中心化2类.中心化方法基于可信的第三方、诚实且好奇的第三方、可信的硬件实现,该类方法的通信代价较低但可能存在单点失败[43-48].去中心化方法主要有秘密共享、安全多方计算和多计算节点等方式.基于秘密共享方式是数据提供者将隐私数据存储在多个服务端并通过秘密共享方式解密数据[49-50],致使数据提供者失去数据控制权.安全多方计算在不泄露数据情况下执行计算,但目前一些安全多方计算的编译库并不支持多于三方参与[51-55].多计算节点方式采用多个计算节点解决单点失败问题,同时保证数据提供者仍然能控制自己的数据且适用于大规模数据提供者场景.但在实际应用中,数据提供者可能是不可信的,计算节点也可能被攻击或恶意违背执行协议从而导致结果错误,因此需要对数据提供者和计算节点进行验证,增强分布式数据集共享的可验证性.

Fig. 4 Ways of distributed data sharing图4 分布式数据集共享方法
为实现分布式数据集共享的可验证性,采用区块链或公告牌(bulletin board)公共存储验证信息,并通过零知识证明对数据提供者的输入数据和计算节点计算过程进行验证[56-58].此外,多计算节点共享方式还需考虑数据机密性、数据提供者和数据之间不可连接性、查询结果机密性和计算结果的鲁棒性等安全和隐私问题.文献[57]假设数据提供者是诚实且好奇的,且至少存在一个计算节点是诚实的,但没有将验证信息公开.文献[58]假设数据提供者和计算节点都是恶意的,将区块链作为验证层,实现分布式数据共享.文献[59]假设数据提供者是恶意的,基于公告牌实现去中心的、可验证的在线信誉评价系统.

Fig. 5 Verified distributed data sharing system图5 可验证分布式数据集共享
图5将区块链作为验证层,实现多计算节点的分布式数据集共享.数据提供者和计算节点基于零知识证明和密码学承诺(commitment)把证明存入区块链.区块链作为验证层,执行验证并记录共享过程.
综上所述,通过区块链或公告牌作为验证层可增加分布式数据共享的透明性和支持可验证.但是还存在2个待解决问题:1)现有方法采用零知识证明和密码学承诺的方法对数据提供者和计算节点进行验证,然而零知识证明生成证明和验证过程都存在较大计算开销;2)现有方法大都依据范围承诺对数据提供者的输入进行验证,适用范围有限.
2.3 可验证的分布式机器学习
分布式机器学习通过数据并行(data parallelism)或模型并行(model parallelism)实现,能间接实现数据共享.目前,分布式机器学习常采用中心化方式,即1个主节点(master)和多个参与节点(parties)共同完成机器学习任务.主节点单点失败[60-63]和参与节点投毒攻击(poisoning attack)[64-66]等原因会影响机器学习结果.所以,存储分布式机器学习过程中重要参数信息是必要的,识别哪些节点贡献了哪些参数以及该参数对整个模型的影响[67-70].
基于区块链可以实现可验证的分布式机器学习,由区块链记录和传递重要参数,同时参数传递过程中采用差分隐私、秘密共享和同态加密等技术对参数进行保护.实现方式也分为中心化和去中心化2种:中心化方式是指保持固定的主节点和参与节点,由区块链存储机器学习过程中产生的参数[71-72],但仍然存在单点失败;去中心化方式依据区块链共识算法产生主节点,通过区块链交易交换并存储参数信息[73-75].

Fig. 6 Machine learning based on blockchain图6 基于区块链的机器学习
图6为去中心化的分布式机器学习模型.其中,①为各个数据提供者依据本地数据获得本地梯度信息(gradient descent, GD),并通过区块链交易上传至区块链.②为区块链网络中各个矿工交叉验证.③为矿工通过共识算法生成并更新全局梯度信息.④为区块链网络再将更新后的全局梯度信息发送给各个数据提供者.重复迭代执行①~④,直至满足要求.
表2为基于区块链实现可验证分布式机器学习方法.大多数方法都采用去中心化方式实现,采用差分隐私对数据提供者的本地梯度信息进行保护.而且,文献[58]同时支持分布式数据集统计分析和分布式机器学习.

Table 2 Comparison of Distributed Machine Learning Methods
综上所述,依据区块链实现分布式机器学习,可以增加透明性和支持可验证.但是还存在3个待解决问题:1)零知识证明生成证明和验证过程都存在较大计算开销;2)区块链延迟性对分布式机器学习产生影响[76];3)虽然可以通过经济激励和区块链实现公平,如何合理激励数据提供者并解决激励带来的新问题.目前分布式机器学习方法大多假设数据提供者有足够的数据且愿意参加,事实上对数据提供者奖励应该与其数据量多少和数据质量等因素成正比,但这也会促使数据提供者为获得奖励而虚报数据量等问题.
3 数据云存储服务透明性
越来越多的数据拥有者 (data owner, DO)将数据存储至云端,享受云服务提供商(cloud service provider, CSP)提供的云存储服务.由于DO和CSP之间不存在完全信任,数据完整性验证、可搜索加密和确定性数据删除等是保障云存储数据安全和隐私的重要技术.现有方法大多基于CSP是不完全可信、DO是诚实可信的假设条件,进而引入可信的第三方审计(third party audit, TPA)并支持DO实施验证.然而,这些假设条件在实际部署和实施时是有限制的,而且大多数方法实现仍然缺乏透明性.事实上,TPA也可能会发生错误或合谋,DO也可能进行欺诈[77],所以需要增加CSP,TPA,DO之间交互的透明性和可信性.应用区块链可以在不依赖可信第三方的情况下实现服务透明.此外,依据区块链还可以实现不依赖可信第三方的数据云存储服务公平.
1) 数据完整性验证.数据完整性验证方法有数据持有证明(provable data possession, PDP)和数据可恢复证明(proof of retrievability, POR).PDP可以快速验证数据是否被云端正确地持有.POR不仅能够识别数据是否已丢失或损坏,还能对丢失或损坏的数据进行修复.对数据完整性进行验证时,通常依赖TPA执行验证,由于验证过程缺乏透明性,DO只能相信TPA返回的验证结果.虽然已有研究通过支持DO复审[78-79]、多TPA验证[80]、可信硬件[81]解决验证过中TPA的不可信和验证过程不透明问题,但是这些方法需要引入其他可信方.区块链与传统完整性验证方法相结合能够增加透明性和可信性,有去中心化验证和中心化验证2种方式.去中心化验证是指区块链网络代替TPA执行验证.文献[82]结合PDP和以太坊实现数据完整性验证,但是并没有考虑如何减少GAS开销,文献[83]也采用PDP和以太坊实现完整性验证,并实现不依赖第三方的服务公平;文献[84]采用联盟链验证,并设计符合应用场景的共识机制.中心化验证指仍由TPA执行数据完整性验证,但将完整性验证挑战信息存入区块链用于日后复审.文献[85]利用区块中nonce字段构建完整性验证时的挑战信息,由DO对TPA验证结果进行复审.这种方式能支持批量处理,提高验证效率,但要求DO具有一定的计算能力执行复审.
2) 可搜索加密.可搜索加密技术,根据实现功能不同可以分为单关键词搜索、连接关键词搜索和复杂逻辑结构搜索;根据构造算法不同可以分为对称可搜索加密(symmetric searchable encryption, SSE)和非对称可搜索加密(asymmetric searchable encryption, ASE)[86].可搜索加密结果完整性验证方法大多都假设可信的TPA执行公共验证,缺乏透明性.区块链与传统可搜索加密方法相结合能够增加透明性和可信性,可分为去中心化搜索和中心化搜索2种方式.去中心化搜索时,由区块链网络中各节点通过执行智能合约代替CSP执行搜索,共识过程保证搜索结果是正确的,不需要数据拥有者对搜索结果进行验证[87].中心化搜索指仍然由CSP执行搜索,在给DO返回搜索结果的同时将验证信息存入区块链[88].此外,除了传统中心云存储,结合区块链还可以实现Storj和Filecoin等去中心云存储关键字搜索结果完整性验证[89-90].
3) 确定性数据删除.确定性数据删除方法有覆盖写删除(deletion by overwriting)和密码学删除(deletion by cryptography).当进行确定性数据删除时,DO发出删除请求之后,CSP执行删除操作并返回1位的“成功”或“失败”作为响应.DO无法根据此响应来确定云端数据是否已经被删除,删除过程亦缺乏透明性.已有研究依赖于用户能访问存储介质[91]、沙漏模型[92]等假设条件,或者基于可信硬件[93]和可信第三方[94]实现可验证确定性数据删除,但仍缺乏透明性.由区块链记录删除证明可以增加数据确定性删除的透明性.在执行数据删除时仍由CSP执行删除, 基于信任但可验证原则(trust-but-verify),将DO的删除请求和CSP的删除证明存入区块链.任何人都可以依据区块链执行验证操作,增加删除透明性,防止DO和CSP双方都可能存在的恶意行为.文献[95]采用覆盖写方法,假设DO和CSP之间已通过身份验证实现问责,并引入时间服务器为删除证明提供时间戳服务.文献[96]在此之上使用基于属性签名代替比特币中采用椭圆曲线数字签名增加隐私性和安全性,并将交易内容加密防止窃听攻击.
表3为基于区块链增加云存储服务透明性和公平性研究总结.数据完整性验证多采用去中化方法,仅支持DO验证.可搜索加密技术都考虑了公平性.确定性数据删除都采用去中心化方式和公有链实现,支持DO和CSP双方验证.

Table 3 Comparison of Cloud Storage Services Transparency
综上所述,应用区块链可增加数据云存储服务的透明性和公平性.但是还存在3个待解决问题:1)数据完整性验证,采用中心化验证方式仍然需要DO执行复审,增加DO的计算负担;采用去中心化方式,由于以太坊智能合约的执行需要消耗燃料(gas),燃料需要通过以太币进行购买,所以需要尽力优化实现代码等方式减少代价消耗.2)可搜索加密技术,一般来说密文和索引都有可能造成不同程度的信息泄露,需要设计更安全的模型使陷门和索引都不泄露关键词信息;采用中心化搜索方式需要实现可验证的多关键词和复杂逻辑结构搜索.此外,可搜索加密技术也存在以太坊计算燃料消耗问题.3)确定性数据删除,现有方法均基于覆盖写删除方法,依赖于DO事后发现数据仍然存在的假设,需要设计可验证的即时数据删除方法.此外,如果数据拥有者和云服务提供者要求将区块链上信息也同时删除,此时应该考虑链上数据删除技术[97-99].
4 数据决策透明性
在基于“数据—信息—知识—智慧”模型的数据决策过程中[100],首先需要收集数据,并对其加工处理之后形成对决策有价值的信息,进一步对信息使用归纳、演绎方法得到知识,最后利用这些知识并经由探讨得出最终决策.然而,在大数据环境下,此模型的有效性受到冲击.数据被篡改、数据质量管理过程中的单点失败等问题会导致决策数据不可靠;训练数据偏见、算法设计偏见和算法错误都可能导致决策算法不可靠.为此,数据决策透明性需要实现决策数据可审计、算法可解释[101-105]和算法透明.
区块链作为去中心化的分布式数据库,为决策数据可审计提供支持.通过获取透明、共享透明和服务透明,在对数据进行追踪溯源的同时也为数据使用者对决策数据进行审计有促进作用.此外,基于区块链的去中心化存储模式,数据使用者可以验证数据是否被篡改和对数据进行追踪,在金融保险[106]、医疗[107-110]和供应链[111-114]等数据完整性要求较高领域有重要意义.区块链作为分布式数据库,区块链的可扩展性[115]、安全[116]]和隐私[117]等问题是影响其应用的重要因素.此外,考虑到区块链存储限制,通常采用“链上”存储元数据与“链下”存储数据相结合的方式,并进一步在这些可信数据上执行查询分析.大部分区块链查询系统仅提供区块、交易和账户等信息的简单查询,并未提供复杂查询功能.实际应用中还需要实现范围查询和Top-k查询等复杂查询[118]、数据查询完整性验证[119]、密文查询[120]和细粒度在线查询溯源[121]等.
多源数据的格式、标准不统一等问题也会影响数据质量,进而影响数据决策.然而传统数据质量管理和质量控制方法通常依赖可信第三方执行,存在缺乏透明性、单点失败和时间资源消耗较大的问题.依靠智能合约自动执行可以制定统一数据格式、规则来提高数据质量管控的透明度[122-123].
综上所述,基于区块链可以促进决策数据可审计,进而有助于决策可解释.但是还存在3个待解决问题:1)大数据来源广泛,虽然采用区块链存储和管理数据可以实现数据追踪问责,但是如何保证数据在存入区块链之前的真实可信是挑战问题;2)支持区块链上复杂数据查询、查询隐私保护和密文数据查询等;3)如何保证 “链下”存储数据的安全性.
5 挑战问题
基于区块链的数据透明化旨在增加大数据价值实现过程的透明性,记录数据获取、数据共享和数据使用等信息.进而依据这些信息实现具有不可篡改性质的溯源问责和数据在其生命周期内的可审计,为隐私保护和数据决策可审计提供支持.数据透明性、溯源问责和数据可审计的实现主要面临5个挑战问题:
1) 符合数据透明化需求的区块链架构问题.基于区块链的数据透明化具有更强的问责能力,但现有区块链的技术和系统无法被直接应用于数据透明化.例如,实现数据获取透明性和数据共享透明性对区块链的可扩展性提出较高要求;实施溯源需要涉及多区块链之间的互操作性;实施问责与现有公有链的监管困难相冲突.为此,需要设计符合数据透明化需求的高可扩展性、隐私与监管并重、轻量级的区块链,而非完全依赖于现有的、开源的区块链平台.
2) 具有用户控制权的数据获取透明性问题.目前的数据获取过程缺乏透明性和用户控制权,导致隐私泄露问题严峻.然而,目前关于数据获取透明性的研究仍然相对有限,亟需一种全新的数据获取架构以及政策和法律法规的支持,实现数据获取透明性.此外,用户(即数据生产者)在数据获取过程中缺少控制权,用户或者同意数据收集者制定的数据协议而付出所有数据收集者要求的数据,或者不同意但会导致不能享受服务.在数据获取透明性实现过程中,如何将控制权还给用户,由用户决定数据内容、目的和形式,并根据用户同意的数据提供服务是挑战问题.由此,用户所获得的服务与自身数据隐私损失之间的平衡也至关重要.
3) 保证数据使用协议的数据共享透明性问题.服务提供者(service provider)作为数据收集者收集用户数据并为用户提供服务,但服务提供者是否依据数据使用协议执行数据共享是不透明的.为此如何实现强制执行数据使用协议进行共享并对数据共享情况进行透明记录是一个挑战问题.此外,数据开放共享平台是重要的数据共享流通方式,可以促进不同领域资源相融合,使数据发挥更大价值.例如,政府公共部门数据共享开放可以促进更智能高效的服务和据此为公共问题提出有效的方案.但是数据开放共享平台的数据可能会涉及众多个人隐私,原则上数据开放共享需要征求个人同意,但实现难度较大且可能会导致数据出现偏差.为此,在数据提供者和数据使用者能够保护数据义务的前提下,可以考虑个人同意让位于集体公共利益,在不经过个人同意情况下实现共享.那么,针对这种 “捆绑”数据共享流通情况,如何在隐私保护前提下实现数据共享透明性,并使用户能追踪与他们数据有关的共享流通信息也是一个挑战问题.
4) 具有不可篡改性质的溯源问责问题.通过获取透明和共享透明可以获得溯源数据,依据这些溯源数据可以实现溯源问责.溯源问责的前提是溯源数据的完备性,然而如何使所有的数据获取和共享事件都被记录是一个挑战问题.除技术手段,还需要政策、法律法规等多方面的支持.例如,可采用激励等非技术手段,将记录数据获取和共享信息与企业信誉相关联,主动记录数据获取和共享信息的企业获得较高的信誉,增加用户的信任,利于其业务发展.进一步,在大规模数据收集和数据共享流通错综复杂背景下,如何实现跨平台和跨领域的溯源问责是仍未解决的挑战问题.同时,由于溯源数据描述数据获取和共享流通整个脉络,在数据溯源过程中也可能会泄露其他隐私信息,所以溯源过程的隐私保护也至关重要.进一步,如何根据策略承诺和溯源数据自动进行违反检测也是一个挑战问题.
5) 保证数据在其数据周期内的可审计问题.在数据生命周期内,数据是否真实产生和处理、数据在共享流通过程中是否被篡改等问题都会影响数据决策结果.虽然基于区块链进行去中心化存储和管理数据会使数据使用者能够对数据完整性进行验证和追溯,但并不能防止数据在存入区块链之前数据被伪造和篡改等问题.此外,为保证决策结果可解释性,应该保证数据的准确性.然而数据隐私保护技术会在某种程度上扰动数据,必然会造成数据准确性降低,并影响决策数据的可解释性.如何平衡数据隐私保护和决策数据可审计是一个挑战问题.
6 总 结
如何保证数据得到正确、合理和规范的使用已经成为大数据生态中亟待解决的根本问题,建立数据透明化的治理体系是有效途径和重要举措.本文提出数据透明化研究框架,并总结和分析该框架下的基于区块链的数据透明化研究现状,最后提出主要面临的挑战问题.此外,作为一个跨学科问题,数据透明化将数据获取和共享流通置于新的范式之下,如何确保用户具备足够的法律法规素养来理解和应对这种变化,也是需要学界和全社会共同去探索的课题.于此同时,我们更要遵从“管理数据、理解数据、敬畏数据”的理念,从而促进大数据生态良性发展.
猜你喜欢
法制博览(2020年2期)2020-04-29
中文信息(2018年6期)2018-08-29
法制与社会(2017年15期)2017-06-06
法制与社会(2017年9期)2017-04-18
法制与社会(2017年5期)2017-03-14
中国新通信(2017年3期)2017-03-11
商(2016年20期)2016-07-04
人民论坛(2016年2期)2016-02-24
电子技术与软件工程(2015年6期)2015-04-20
新媒体研究(2009年23期)2009-07-01
