
基于社会立场建模的网络犯罪预警研究*
2021-02-03 04:08魏墨济赵燕清朱世伟
计算机工程与科学 2021年1期
魏墨济,赵燕清,朱世伟,李 晨
(齐鲁工业大学(山东省科学院)情报研究所,济南 山东 250014)
1 引言
以通信网、物联网、互联网及三网融合为代表的新一代信息技术,在原有社会生活空间基础上,创建了全新网络空间,映射着社会生活的方方面面。网络空间在加速各类信息传播速度和扩大传播范围方便人们通讯的同时,也使得政治方向、舆论导向和价值取向引导变得更加复杂[1]。依托网络空间所实施的新型恐怖、淫秽、贩毒、洗钱和赌博等网络犯罪,利用其隐蔽性、普及性、虚拟性和时空超越性等特点隐身于网络空间中,使得传统安全防范手段处处掣肘,特别是具有强交互性的论坛、微博、博客、私人空间和人人网等网络社交媒体,所承载的海量数据流为网络犯罪提供了活跃空间,呈现出不同于传统犯罪的特征,网络空间已演变为安全防控“第二战场”[2],网络犯罪预警成为非传统社会安全领域的一个重要课题。习近平主席提出“构建网上网下同心圆防范网络犯罪”的新要求。因此,针对社会敏感话题事件和危险观点持有者,以实时发现新型网络犯罪,在亿万个网民的亿万种声音中挖掘犯罪线索,成为当前安全工作的重要目标。
敏感话题分析最早源于网络舆情监测[3,4],依据公众情感倾向发现敏感事件,按分析粒度可分为粗粒度基于情感词表的情感倾向分析[5 - 9]、细粒度基于主题建模的话题聚类[10 - 12]和微粒度基于观点的持有者倾向分析[13 - 16]。其中基于情感词表方法给出正负面情感词,通过文本所用词汇与正负面情感词的匹配情况判别情感倾向。基于主题建模的话题聚类方法则在情感分析的基础上,利用潜在语义分析从语义层划分主题,以细粒度探寻不同主题的倾向。而观点挖掘技术则在主题和情感的基础上加入观点持有者信息,以深入发现不同观点持有者的倾向性。无论何种粒度的情感倾向分析,其核心情感分类又可分为有监督和无监督情感极性分类。有监督情感极性分析依赖于已标注极性的词表,采用已有分类算法,如支持向量机、最大熵等训练模型进行情感极性分类;无监督情感极性分类在标注词性的基础上提取特定词性组合作为文本特征值,并利用互信息方法计算特征词与“完美”和“极差”的相似度值作为情感倾向的分类标准。20世纪90年代中期国外学者即开始关注文本分析的话语分析研究,围绕政党及公共政策进行价值说明、观念传播和意识形态渲染等[17]。国内对敏感话题的研究起步较晚,且多以方法论为主,在应用方面主要体现于舆情系统负面事件研判,而主题和观点持有者分析罕有所见。目前的安全防控一线工作,犯罪敏感信息线索更多来源于线下举报,缺失了线上数据实时监测线索发现部分。
本文面向网络犯罪防控工作一线,针对网络社交媒体文本大数据,提出基于主题分类构建社会立场,监测和预警新型恐毒黄赌等网络犯罪,提高犯罪防控作战过程中线上数据处理、分析能力与自动监控、预警能力。
2 网络犯罪监测平台
针对网络犯罪防控线上线索发现及预警机制缺失,以及现有监控预警服务模式处理多源、异构社交媒体数据时存在数据利用低效、数据处理服务功能有限、过程不可智能控制、无法实现精准监控以及难以对数据进行多维度、深层次智能分析等问题,借鉴国内外大数据服务和监控预警平台建设研究成果,结合现有数据服务架构优势及问题,构建基于立场的网络犯罪监测预警平台,总体逻辑架构如图1所示。

Figure 1 Framework of cyber-crime monitoring and early warning platform图1 网络犯罪监控预警平台架构
平台自底向上分别为数据源层、数据采集清洗层、数据存储分发层、数据处理引擎层、业务逻辑模型层(网络犯罪防控模型层)、数据接口层和可视化展示层,以及为保证平台的稳定运行所必需的信息安全管理组件和系统运维管理组件。其中数据源层维护着网络犯罪防控一线工作者需监测的目标网站和社交媒体列表。虽然网络空间访问无地域性,但网络媒体影响力却有区域差异性。因此,线上线索监测和判定仍可按地域划分,除国内主流网站和通用社交媒体(如四大门户网站、百度贴吧、天涯论坛、新浪微博等)外,一线工作者可根据所属地域将区域内影响力较大的网站和社交媒体加入监测列表,如山东的齐鲁晚报、大众论坛,河南的大豫网、大河论坛等,还可根据相应权限接入本地资源库,以更好地维护区域内网络安全。数据采集清洗层根据监测列表中各数据源特征采用不同技术采集多源异构数据,并同时进行链接查重和内容查重2个方面的清洗。数据存储分发层负责存储数据、构建索引、实时热备和定时冷备,将新采集的数据实时送入上层进行检测。数据处理引擎为上层业务模型层的数据处理提供框架平台和基础工具,其中历史大数据批处理系统根据过往累积数据为网络犯罪防控建模,流态大数据实时处理系统结合网络犯罪防控模型负责实时获取数据安全性检测结果。数据接口层将监测结果转化为适宜各类协议传输的标准化数据,为可视化层提供基础数据。数据可视化层则根据用户需求和数据特点将数据以简明易懂的可视化方式传递给用户。信息安全组件负责用户权限管理以保证数据安全。系统运维管理组件监控系统运行状态并适时调整以保证平台稳定运行。
由图1可知,平台的核心是网络犯罪防控模型,其它层可通过改进现有大数据服务和监控预警平台快速实现,因此本文将着重描述此模型的构建方法。
3 网络犯罪防控模型
3.1 网络犯罪文本特征分析
网络犯罪防控与敏感话题发现相似,均以网络文本大数据为监测对象,发现对社会稳定产生威胁的言论。在敏感话题发现中无论是粗粒度、细粒度还是微粒度的分析,所采用的技术核心均为情感分类,通过标记情感词汇构建特征词,利用分类算法将特征词分到不同情感类别,最后通过特征词情感倾向计算,发现负面舆情聚类敏感话题。
然而与舆情敏感话题监测不同,网络犯罪敏感言论监测关注的重点并非负面观点或消极情感,而是与社会立场相悖的言论。如在恐怖袭击事件中,正常言论的社会立场均为否定,只有持肯定观点的言论才是监测重点,故在此情形下需对正面情感做出预警。此外,还存在诸多仅依靠情感分析无法判别的情形,如对人权或民主观点的阐述,不同言论可以支持、论述或反对,因此所含感情色彩既可能是积极的、中性的,也可能是消极的。而观点评判应立足于国情和特色,从大众利益和国家稳定发展角度客观判别,而非通过情感的对立与否进行判别。
为测试情感分类方法对网络犯罪言论监测的效果,本文分别测试有监督和无监督情感分类方法。在有监督分类方法中采用SentiWordNet作为情感词典语料库,并从文档、句子和特征3个层面分别对言论进行情感分类。由结果亦可看出,网络犯罪言论没有固定的情感倾向,采用情感分析方法并不能有效判定敏感言论。
3.2 基于立场的网络犯罪监测与预警建模
对网络犯罪文本特征分析可知,其核心并不在于言论情感是否为负面,而在于其观点是否有悖于社会立场。因此,建模核心在于构建社会公众立场,并计算社交媒体言论与社会立场的相悖度。

Figure 2 Framework of viewpoint-based social event model图2 基于立场的社会事件模型框架
面向社会立场所构建的网络犯罪监测模型框架如图2所示,首先以各类网络犯罪为对象构建犯罪本体库,采用面向主题的定向采集方法获取权威媒体言论,聚焦具有代表性的观点建立社会立场;其次,采用分布式爬虫采集社交媒体数据,构建发布者理念,并基于本体个体推理获取与发布者理念相关的社会立场;最后,计算理念与社会立场相悖度,在预设阈值的基础上进行预警。
3.2.1 犯罪本体库构建
犯罪本体库由知识工程领域专家依据不同警种实际破案工作经验,提取知识分层构建而成,其顶层本体中的类及其属性如图3所示。

Figure 3 Top-level ontology图3 顶层本体
图3中网情类(NetInfo)由来源(Source)、内容(Content)、发布者(Publisher)和跟随源(Follower)4个类组成,内容类由主题(Subject)、用语(Term)、时间(Time)、地点(Space)、组织(Organization)5个类组成,来源类有网站(Website)、论坛(Forum)、博客(Blog)、微博(MicroBlog)和社区(Community)5个不相交的子类,发布者类有官方媒体(Authority)、机构媒体(Group)和个人(Individual)3个不相交的子类。参考我国司法警察分类,结合网络犯罪打击目标,本文将警种类(PolType)划分成缉毒警(DrugPol)、经侦警(EconPol)、治安警(CrimPol)、防暴警(TerrPol)、科技警(SciePol)、交通警(TrafPol)等18个不相交的子类。不同的警种关注的网情主题不同,使用属性监测(supervise)描述,其定义域为警种类,值域为主题类。使用本体描述语言OWL形式化表示的顶层本体片段如代码1所示。
代码1
⋮
〈owl:Class rdf:ID="NetInfo"〉
〈owl:unionOf rdf:parseType="Collection"〉
〈owl:Class rdf:resource="#Content"/〉
〈owl:Class rdf:resource="#Source"/〉
〈owl:Class rdf:resource="#Publisher"/〉
〈owl:Class rdf:resource="#Follower"/〉
〈/owl:unionOf〉
〈/owl:Class〉
⋮
〈owl:Class rdf:ID="Source"/〉
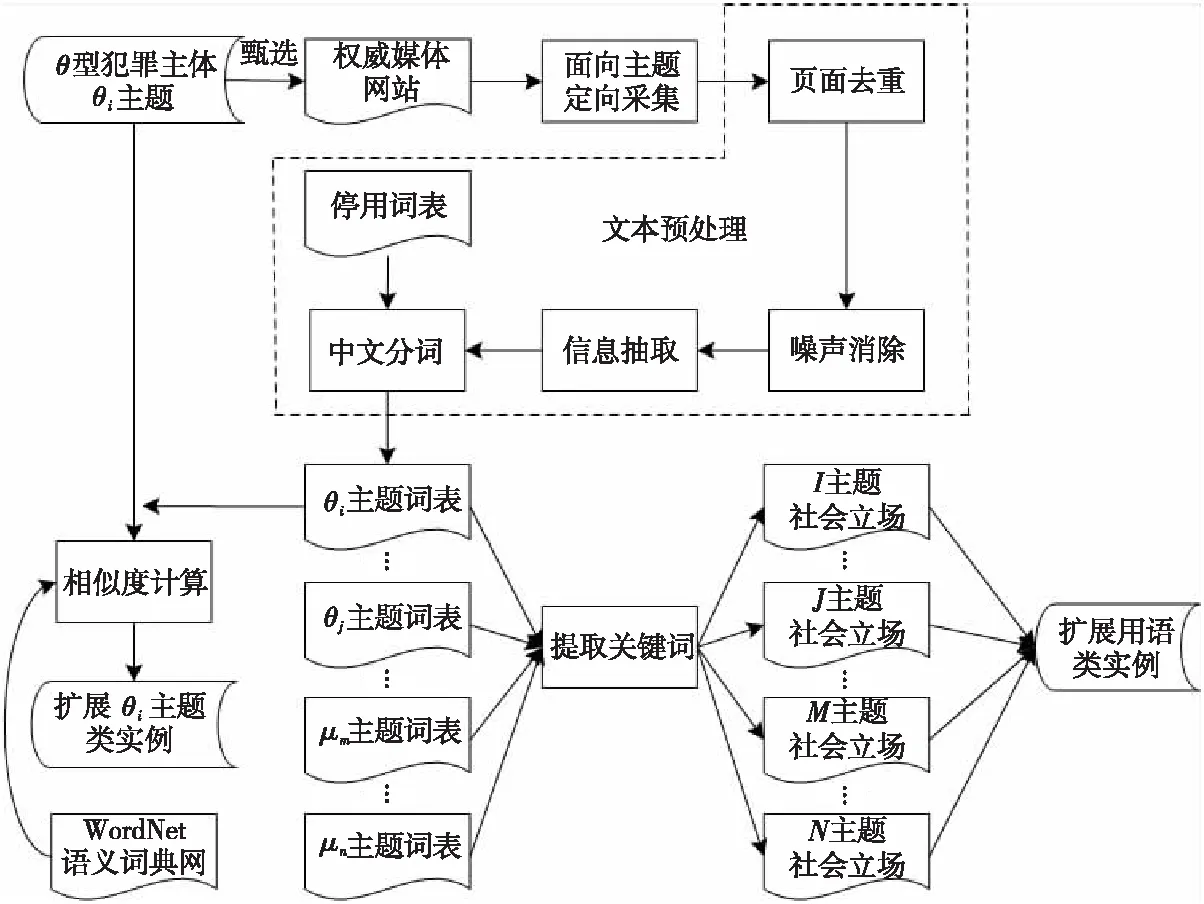
Figure 4 Flowchart of social viewpoint construction图4 社会立场构建流程图
〈owl:Class rdf:ID="Website"〉
〈rdfs:subClassOf rdf:resource="#Source"/〉
〈owl:disjointWith rdf:resource="#Forum"/〉
〈owl:disjointWith rdf:resource="#Blog"/〉
〈owl:disjointWith rdf:resource="#MicroBlog"/〉
〈owl:disjointWith rdf:resource="#Community"/〉
〈/owl:Class〉
⋮
〈owl:Class rdf:ID="PolType"/〉
〈owl:Class rdf:ID="DrupPol"〉
〈rdfs:subClassOf rdf:resource="#PolType"/〉
〈owl:disjointWith rdf:resource="#EconPol"/〉
〈owl:disjointWith rdf:resource="#CrimPol"/〉
〈owl:disjointWith rdf:resource="#TerrPol"/〉
〈owl:disjointWith rdf:resource="#SciePol"/〉
〈owl:disjointWith rdf:resource="#TrafPol"/〉
⋮
〈/owl:Class〉
〈owl:ObjectProperty rdf:ID="supervise"〉
〈rdfs:domain rdf:resource="#PolType"/〉
〈rdfs:range rdf:resource="#Subject"/〉
〈/owl:ObjectProperty〉
⋮
犯罪本体库中的各型犯罪本体(CrimOnto)均继承自顶层本体,并按照18个警种类的子类划分为Ⅰ型、Ⅱ型、…、ⅩⅤⅢ型等18个领域本体,在每型犯罪本体中根据警种涵盖的业务类型细分监测主题类。如治安警所对应的Ⅲ型犯罪本体中,主题类按照业务又可细分为涉黄(ProsSub)、涉毒(GambSub)和违禁(ConbSub)等子类。各型犯罪本体依据主题类分层构建分类管理不同领域知识。
3.2.2 社会立场库构建
新华网、人民网、光明网等官方媒体,天生是社会正义的维护者和代言人[18],代表着社会立场和公众利益。因此,本文依据各型犯罪本体中不同主题类,采用面向主题的定向采集方法获取权威媒体发布的信息构建社会立场,其流程如图4所示。
社会立场库构建的具体步骤如下所示:
(1)依次为犯罪本体库中θ型犯罪本体CrimOntoθ(其中θ∈[Ⅰ,ⅩⅤⅢ])的各主题类Subjectθi(其中i∈[1,θ型犯罪本体中子主题类个数])甄选合适的权威媒体网站。
(2)采用主题爬虫定向采集权威媒体网站。
(3)文本预处理,针对采集结果进行页面去重,去除页面内噪声数据,抽取页面正文信息并进行中文分词,使用停用词表过滤分词获取主题相关词集,构建Subjectθi词表WordListθi。
(4)引入WordNet语义词典网络,基于路径计算WordListθi中各词语与Subjectθi概念的语义相似度,如式(1)所示。
sim(subθi,wk)=
(1)
其中,subθi表示Subjectθi,wk是WordListθi中的词语,los(subθi,wk)表示两者的公共父节点,depth(los(subθi,wk))表示两者公共父节点的深度,shortlen(subθi,wk)表示两者间的最短路径长度。
(5)将相似度sim(subθi,wk)大于阈值的词语wk声明为Subjectθi概念的实例,如涉赌主题类中,媒体发布信息中所用词语“赌钱”“博彩”等与主题概念“赌博”的语义相似度大于设定阈值,可将这些词语声明为主题概念的实例。其OWL形式化表述如代码2所示。
代码2
⋮
〈owl:Class rdf:ID="Gamble"〉
〈rdfs:subClassOf rdf:resource="#Subject"/〉
〈rdfs:label xml:lang="ch"〉赌博〈/rdfs:label〉
〈/owl〉
〈owl:ObjectProperty rdf:ID="CrimSupervise"〉
〈rdfs:subPropertyOf rdf:resource="#Supervise"/〉
〈rdfs:domain rdf:resource="#CrimPol"/〉
〈rdfs:range rdf:resource="#Gamble"/〉
〈/owl:ObjectProperty〉
〈Gamble rdf:ID="赌钱"/〉
〈Gamble rdf:ID="博彩"/〉
⋮
(6)将各WordListθi作为一个文档组建文档集,采用TF-IDF算法计算词汇权重,如式(2)所示:
(2)
其中,count(wk)为词汇wk出现次数;WLi表示WordListθi;|WLi|表示WordListθi中所有词汇数量;N为WordListθi总数量;I(wk,WLi)表示WLi是否包含词汇wk,若包含则值为1,否则值为0。
(7)使用WordListθi中权重TF-IDFwk大于阈值的词汇wk作为关键词构建相应主题Subjectθi的社会立场,并将其声明为犯罪本体术语类CrimOntoθ.Termθi的实例。如涉赌主题类中,媒体发布信息中所用 “色子”“牌九”“麻将”“赌注”“筹码”等词语的TF-IDF权重大于设定阈值,可将这些词语声明为主题术语的实例。其OWL形式化表述如代码3所示。
代码3
⋮
〈owl:Class rdf:ID="GambleTerm"〉
〈rdfs:subClassOf rdf:resource="#Term"/〉
〈rdfs:label xml:lang="ch"〉赌博用语〈/rdfs:label〉
〈/owl〉
〈GambleTerm rdf:ID="色子"/〉
〈GambleTerm rdf:ID="牌九"/〉
〈GambleTerm rdf:ID="麻将"/〉
〈GambleTerm rdf:ID="赌注"/〉
〈GambleTerm rdf:ID="筹码"/〉
⋮
3.2.3 基于立场的社交媒体监测
社交媒体高度开放的特性,在方便人们正常沟通交流的同时,也为危及社会安全的网络犯罪提供了庇护。本文构建的网络犯罪防控平台通过监测社交媒体言论,计算其与社会立场相似度,预警敏感信息,其流程如图5所示。

Figure 5 Flowchart of social media monitoring and early warning图5 社交媒体监测预警流程图
基于立场的社交媒体监测的具体步骤如下所示:
(1)面向日信息更新量过亿的社交媒体平台,采用分布式爬虫[19,20]采集多源媒体中个体言论,并去除噪声数据抽取正文信息。
(2)对所获取的信息进行词性和句法分析,提取各类元素生成发布者理念(ViewPoint)。本文将理念定义为一个7元组。
定义1
ViewPoint=[Publisher,Subject,Opinion,Time,Space,Organzation,Wgtvp]
其中,发布者(Publisher)定义理念的持有者,主题(Subject)定义该言论所针对的主题,观点(Opinion)是发布者言论中所使用的用语,时间(Time)、地点(Space)和组织(Organization)分别是发布者言论中所提及的时间、地点和组织,理念权重(Wgtvp)记录言论中观点与社会立场的相似度。利用词性和句法分析,提取社交媒体言论中各元素,填充7元组中前6项生成发布者理念。
(3)依据理念中的主题项检索犯罪本体库,结合形式化语言OWL的描述逻辑推理能力,构建SWRL(Semantic Web Rule Language)规则(如规则1所示),通过本体语言个体ABox推理,检索犯罪本体主题类实例,获取与发布者言论主题相关的社会立场。
规则1
SameAs(?x,?y)∧Subject(?y)∧isPartOf(?y,?c)∧?isPartOf(?z,?c)→Term(?z)
其中,x是理念中主题项词汇,即x∈ViewPoint.Subject,y、c、z分别是犯罪本体主题类、内容类和术语类实例,即y∈CrimOnto.Subject,c∈CrimOnto.Content,z∈CrimOnto.Term。
(4)计算理念中观点ViewPoint.Opinion项词集与社会立场CrimOnto.Term类实例集合的相似度。文本相似度比较通常采用文本向量夹角余弦,使用文本词集的词频构成一个向量,然后计算2个文本对应向量的夹角余弦。但是,由于文本特征向量维度极高,实时监测万亿级社交媒体数据,其计算代价是难以接受的。因此,本文采用Google提出的SimHash算法[21],通过生成2个词集的SimHash签名进行降维,计算2个词集间的海明距离作为理念权重(Wgtvp)的值。
(5)对理念权重小于阈值的社交媒体言论发出一级预警。
(6)更进一步,以预警言论为基础,汇总该言论发布者的所有言论,计算其平均权重。由于言论所用词汇数量及与社会立场的背离度均会对影响力产生作用,因此本文将词汇量作为相似度的权重,采用式(3)加权平均计算相似度:
(3)
其中,wgtpublisher是发布者权重,描述发布者所有言论的加权平均与社会观点的相似度,wni是第i条言论的词汇数量,wgtvpi是第i条言论的理念权重。
(7)若发布者权重小于阈值则进行二级预警。
4 实验与结果分析
4.1 实验设计
本文以党中央相关精神为评判标准,围绕恐怖主义、赌博、色情、毒品、人权和民主5个领域的网络犯罪敏感信息监测预警进行实验。首先针对每个领域人工从新华网、人民网和光明网等新闻网站选取2 000篇文本作为训练所用的正面语料库,并从国外网站、博客或声明等中选取2 000篇文本作为训练所用的负面语料库。然后针对每个领域从Twitter、Facebook和Huffpost等社交媒体中分别选取正负面言论各5 000条组成测试集。最后利用5个领域正面语料库构建5类主题社会立场。
为对比基于立场的监测与基于情感分析的监测的效果,本文同时测试了现有有监督和无监督情感分类方法对敏感言论的预警效果,其中,有监督分类方法从文档、句子和特征3个层面构建情感分类模型,引入SentiWordNet作为情感词典语料库。在基于立场分析的敏感言论监测中,本文同时使用正、负面语料库构建分类模型。
实验采用精确率P、召回率R和F1值3个指标评测效果。其中,P用于度量被预警信息中实际为负面信息的言论所占比例,采用式(4)计算;R用于度量负面测试集言论中有多少被正确预警,采用式(5)计算;F1值是准确率和召回率的加权调和平均,该值越大效果越好,采用式(6)计算。
(4)
(5)
(6)
其中,TP表示负面言论测试集中被正确预警的言论数量,FP表示负面言论测试集中被认为是正面言论的数量,FN表示正面言论测试集中被错误预警的言论数量。
4.2 结果分析
表1所示为文档层面、句子层面和特征层面有监督情感分类方法、无监督情感分类方法和基于立场的言论监测方法的结果。

Table 1 Evaluation of early warning effect 表1a 预警效果评价 %
从表1可以看出,言论立场与情感并无正相关性,通过情感分类模型不能很好地预警网络犯罪敏感言论。而通过社会立场建模,监测言论用语与社会立场的相似度可更好地甄别敏感信息,实现网络危险事件一级预警。

Figure 6 Top 10 users list sorted by publisher weight图6 发布者权重Top10用户列表

Figure 7 List of accompanying users图7 伴随用户列表
然而言论用语层面的一级预警仍存在误报和漏报情况。而误报言论中所使用的反语、讽刺等和漏报言论中所使用的比喻、双关等修辞手法,又很难直接通过用词分析出正确的情感倾向。因此,本文方法在分析单条言论的基础上,按照发布者汇总言论,将其作为一个言论集合采用式(3)计算发布者言论平均权重。
图6是恐怖主义主题中按照发布者权重降序排序的发布者Top10,可通过详情项观测发布者的言论。更进一步,通过言论发布者的伴随用户分析,可发现深层隐藏的危险用户,如图7所示。
汇总计算每个用户所发表言论的平均权重,当权重小于阈值时进行二次预警,可进一步判断言论与社会立场的关系,在一次预警的基础上准确率和召回率提升了约7%(如表2所示),可更好地监测网络犯罪敏感信息。

Table 2 Evaluation of secondary early warning effect 表2 二次预警效果评价 %
5 结束语
互联网的隐蔽性、普及性、虚拟性和时空超越性等特点,为网络犯罪提供了沃土,给社会安全和国家稳定带来巨大挑战。如何在亿万个网民亿万种声音中预警敏感信息,已经成为非传统社会安全领域的一个重要课题。本文首先分析了社会安全事件特征;然后为各类型网络犯罪构建犯罪本体库,并依照主题利用官方媒体资讯构建社会立场扩展犯罪本体库实例;最后计算社交媒体言论与社会立场的相似度,进行言论层面一级预警和相同发布者言论加权平均的二级预警。
网络社交媒体中数据传播载体不仅有文本,还包括图像、音频和视频等,这些在本研究中未曾涉及。下一步拟针对文本、图像、语音和视频等多源异质内容的一致性知识表达机理,进一步丰富网络犯罪反恐平台。
猜你喜欢
湘潮(上半月)(2021年4期)2021-07-20
湘潮(上半月)(2021年3期)2021-07-20
河北画报(2020年10期)2020-11-26
疯狂英语·新阅版(2020年3期)2020-09-22
武术研究(2020年3期)2020-04-21
中外文摘(2019年20期)2019-11-13
智族GQ(2019年12期)2019-01-07
重庆邮电大学学报(自然科学版)(2018年1期)2018-03-03
知识产权(2016年4期)2016-12-01
计算机应用与软件(2016年4期)2016-05-09
