
信息传递增强的神经机器翻译*
2021-02-03 07:24史小静宁秋怡季佰军段湘煜
计算机工程与科学 2021年1期
史小静,宁秋怡,季佰军,段湘煜
(苏州大学自然语言处理实验室,江苏 苏州 215006)
1 引言
神经机器翻译NMT(Neural Machine Translation)[1 - 3]是完全采用神经网络完成源语言到目标语言的端到端的翻译系统,吸引了众多学者的关注。最初,神经机器翻译模型是基于循环神经网络RNN(Recurrent Neural Network)[4]实现端到端的翻译。注意力机制[5]是对神经机器翻译编码器-解码器(Encoder-Decoder)框架的完善,使得模型能够在解码时只关注源语言句子中的一部分区域,动态地生成源语言信息,极大地提高了翻译译文的质量。为了提高神经机器翻译的表达能力,研究人员采纳多层神经网络结构,实现了基于卷积神经网络CNN(Convolutional Neural Network)[6]和自注意力机制(Self-Attention)[7]的多层神经网络,使得神经机器翻译在多项翻译任务中达到了最先进的水平。
编码器-解码器[8,9]框架是神经机器翻译模型的经典框架,可以由不同的神经网络实现,如循环神经网络RNN[4]、门限循环单元GRU(Gated Recurrent Unit)[5,9]、长短期记忆神经网络LSTM(Long Short-Term Memory)[10]、卷积神经网络CNN[6]和Transformer[7]等。一般地,编码端对源端的输入句子由低层到高层逐层生成语义向量,解码端根据编码端最后一层的输出和已经解码生成的词的隐藏层表示作为输入,通过一系列计算得到对应的目标端的译文。多层神经网络中逐层传递的过程往往存在梯度消失或者梯度爆炸的问题,残差网络(Residual Network)[11]的引入有效地缓解了梯度消失和梯度爆炸的问题,但多层神经网络的逐层信息传递过程中的信息退化问题仍然不能得到妥善解决。
本文提出各层间信息融合传递增强和子层间信息融合传递增强的方法,在残差网络的基础上能够进一步补充多层神经网络逐层传递过程中的退化信息,保留之前所有层或子层的输出信息,再经过一个“保留门”机制来控制之前所有层的输出融合后的信息保留的权重比例。该“保留门”是通过网络自主学习得到的,与当前层的输出进行连接,共同作为下一层网络的输入,使得多层网络中层与层之间的信息传递更加充分,优化和增强了层与层之间信息传递的能力。本文提出的子层间信息融合传递增强方法在中英和德英翻译任务上BLEU得分[12]分别提升了0.66 和0.42,实验结果表明,本文方法有效地提升了神经机器翻译的性能。
2 相关工作
近年来,在大规模平行语料上训练的神经机器翻译模型获得了较好的翻译性能,超越了传统的统计机器翻译SMT(Statistical Machine Translation)[13 - 15]。神经机器翻译采用神经网络来实现翻译过程[2,3,16],仅需要句子级的平行语料,便于训练大规模的翻译模型,具有很高的实用价值,吸引了众多研究者的关注。
注意力机制[5]是对神经机器翻译编码器-解码器框架的完善,它允许在不考虑输入和输出序列中词之间距离的情况下对依赖关系进行建模,使得模型能够利用平行语料学习到词与词之间的对齐信息。Vaswani等[7]首次将自注意力机制引入神经机器翻译模型,该模型仅依赖于注意力机制就能完成源语言到目标语言的翻译,不仅在机器翻译方面达到了最先进的效果,而且在多个自然语言处理任务[16 - 18]上也达到了最好的效果。自Transformer被提出以来,为了充分利用该模型各层之间的信息,众多研究者进一步提出了许多不同的方法。Wang等[19]提出通过添加另外一层网络来将其他层的层间信息进行融合,以此来捕获丢失的信息,He等[20]提出了逐层协调的概念,显式地协调编码器和解码器隐藏层向量的学习,在生成目标端句子的时候可以参考编码端不同层的输出信息,更充分地利用编码端每一层的输出信息,Wang等[21]改进了层正则化,并提出对不同层的输出信息通过线性变换进行动态连接,以训练更深层次的Transformer模型,从而得到更好的效果。
基于编码器-解码器框架的神经机器翻译模型多是依赖于多层神经网络,然而多层神经网络结构在层与层之间信息传递的过程中往往存在信息退化的问题,残差网络[11]的引入有效地缓解了此问题。但是,残差网络只是添加了最邻近的前面一层的输出信息,未能利用其他层的输出信息,多层网络中固有的信息捕获不充分的问题并没有得到很好的解决。
与本文工作较相似的工作是Yang等[22]的工作。为了使得自注意力机制获得更好的词间的关联性,作者利用不同的策略来捕获多层神经网络的上下文信息,经过一个门控权重将上下文信息引入到注意力模型的输入中,以使得自注意力机制能够捕获到更好的词间关联信息。
3 系统结构
3.1 Transformer
Transformer模型架构首先是由Vaswani等[7]提出的,属于编码器-解码器结构,编码器与解码器之间通过注意力机制实现连接。Transformer的编码器端和解码器端分别是由N层相同的网络层组成,编码器端的每一层都包含2个子层、多头自注意力机制和全连接的前馈网络层,对每一个子层的输出都进行了残差连接和层归一化处理。与编码器端相似,解码器端的每一层中除了包含自注意力机制层和全连接的网络层之外,还包含了一个编码器-解码器注意力子层,同样地,对解码器端的每一个子层的输出进行了残差连接和层归一化处理。
Transformer中使用了多头注意力机制,多头注意力机制使得模型可以在不同位置联合处理来自不同表示空间的信息,将矩阵Q,K,V中每个向量的维度切分成更小的向量,希望通过不同视角获取多样的注意力信息。通常是将矩阵Q,K,V中每个向量的维度设置为512维,分为8个头,即每个向量被分为8份,每一份维度为64维。然后计算每个头的注意力信息,最终将各个头的注意力信息进行拼接再次映射成512维。多头注意力机制的核心是缩放点乘注意力,如式(1)~式(3)所示:
MultiHead=Concat(head1,…,headh)Wo
(1)
(2)
(3)

Transformer模型完全基于注意力机制,为了充分利用位置信息,添加了位置编码操作。位置编码采用正余弦位置编码方式,如式(4)和式(5)所示:
(4)
(5)
其中,pos表示当前词在该序列中的位置编号,i指向量的某一维度。
3.2 损失函数
Transformer中使用交叉熵作为损失函数,具体地,给定一对平行语料,其中源端X={x1,x2,…,xn},xi表示源端第i个词对应源端词表的索引,目标端为Y={y1,y2,…,ym},yi表示目标端第i个词对应目标端词表的索引。在训练过程中通过最大化似然估计来生成目标端候选词的最大化概率P(yi|y[1:(i-1)],X)。训练过程中的损失函数如式(6)所示:
(6)
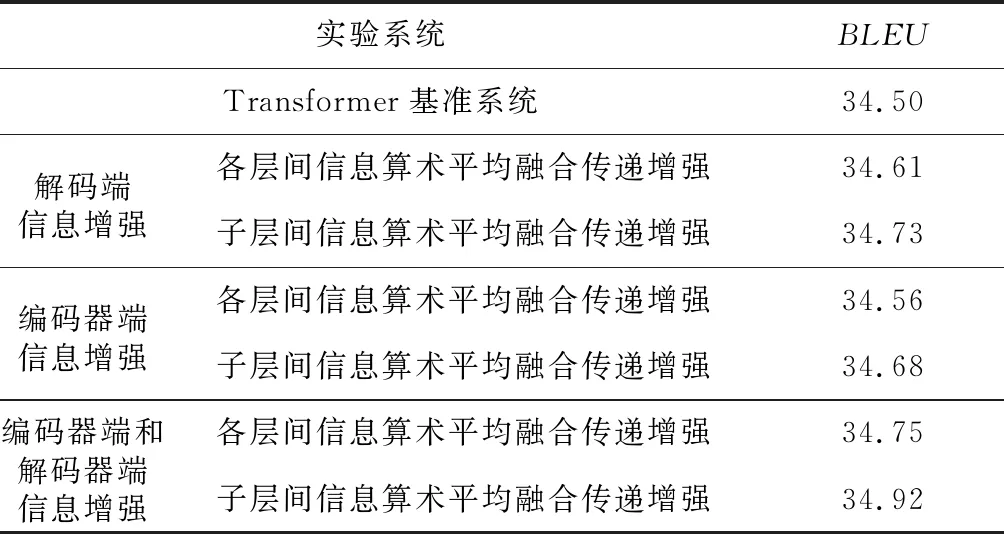
其中,m表示目标端句子的长度,P(yi|y Transformer是多层神经网络结构,在信息传递过程中存在信息退化问题。本文利用Transformer中每一层的层间输出信息和每一个子层的输出信息融合来增强不同层和子层之间的信息传递,使得模型能够捕获更丰富的语义信息,弥补逐层之间信息传递过程中丢失的信息,进一步减缓多层神经网络中的信息退化问题。 基准系统Transformer中编码器和解码器通常都是6个相同层的堆叠,当前层的输入仅基于最邻近的上一层的输出信息,而忽略了更低层的输出信息,这样很容易导致信息传递过程中的信息退化问题。针对这一问题,本文提出各层间信息融合传递增强的方法。 各层间信息融合传递增强的模型结构如图1所示。图1中每一个完整层计算之后都有一个流动箭头表示对当前第i层的输出信息layeri进行保留并流入未来每一层的输入中。在进行下一层的计算之前,将保留的低层输出语义信息[layer1,layer2,…,layeri-1]进行融合,与当前层的输出通过保留门机制进行连接,共同作为下一层的输入信息。利用补充的低层信息,能够增强神经网络表示特征的捕获能力,使得神经网络能够捕获更丰富的语义信息。其中保留门控制低层融合后的信息流入下一层计算的保留权重。本文使用的信息融合的方法包括线性变换融合和算术平均融合。具体如式(7)~式(9)所示: fusioni-1=f(layer1,layer2,…,layeri-1) (7) g=σ(W[fusioni-1;layeri]+b) (8) layeri+1=LN((1-g)*layeri+g*fusioni-1) (9) 其中,layeri表示第i层的输出;式(7)表示对保留的信息进行融合;f()表示信息融合函数,比如算术平均或线性变换等;fusioni-1表示网络前i-1层输出融合后的信息。式(8)表示将融合后的信息与当前层的输出信息进行连接,为了更好地控制融合信息的保留权重,通过Sigmoid函数使其值为0~1;W∈Rdmodel*2为执行线性变换的参数矩阵;b表示偏差。式(9)表示当前层信息和融合后的信息以不同的概率连接;LN()表示层正则化函数;*表示对应元素乘积。保留门通过网络自主学习之前每一层的保留信息权重,模型在训练过程中会自动学习所需比例的之前每一层的输出信息,控制每一层的信息保留程度。 Figure 1 Structure of layers information transfer enhancement图1 层间信息传递增强结构 本文提出的子层间信息传递增强方法如图2所示。图2中的虚线部分表示基准系统Transformer原有的残差网络,实线部分表示增加的子层信息传递增强方法流程。图2中每一个子层的输出均有一个实线流动箭头表示对第i层的第j个子层信息sublayeri,j进行保留并流入未来每一子层的输入中,在进行下一个子层的计算之前,将前面保留的所有子层的输出信息[sublayer1,1,sublayer1,2,…,sublayeri,j-1]进行融合;然后通过门机制与当前子层的输出sublayeri,j进行连接,共同作为下一子层的输入信息,具体如式(10)~式(12)所示: fusioni,j-1= f(sublayer1,1,sublayer1,2,…,sublayeri,j-1) (10) g=σ(W[fusioni,j-1,sublayeri,j]+b) (11) sublayeri,j+1=LN((1-g)* sublayeri,j+g*sublayeri,j-1) (12) Figure 2 Structure of sublayers information fusion transfer enhancement图2 子层间信息融合传递增强 其中,sublayeri,j表示第i层的第j个子层的输出;式(10)表示对保留的信息进行融合,f()表示融合函数,fusioni,j-1表示第i层第j-1个子层之前所有子层的输出融合后的信息。式(11)表示将融合后的信息与当前子层的输出信息进行连接,为了控制融合后的信息保留权重,使用Sigmoid函数将其数值限制于0~1;W∈Rdmodel*2是可训练权重矩阵,通过网络自动学习融合信息的保留权重。式(12)表示将融合后的信息和当前的输出信息以一定的概率进行连接。 此外,为了验证模型低层的输出在层与层之间信息流动中的重要性,基于基准系统,对所有保留的子层信息 [sublayer1,1,…,sublayeri,j-1]进行下一层运算时没有及时添加,而是仅在最后一层的输出上进行权重连接的实验,本文称之为子层信息连接,以验证逐层信息增强的重要性,其计算方法如式(13)~式(16)所示: sublayers= [sublayer1,1,sublayer1,2,…,sublayeri,j-1] (13) fusion=f(sublayers) (14) g=σ(W[fusion,sublayert-1,3]+b) (15) layert=LN((1-g)*layert-1,3+g*fusion) (16) 其中,t为解码器的堆叠层数,sublayers为保留的解码器端所有子层的输出信息,f()为融合函数,layert为解码器端最后一层的输出。 本文用中英和德英翻译任务实验来验证所提方法的有效性。 中英翻译任务中使用的训练数据集是从LDC(Linguistic Data Consortium)里抽取的125万句中英平行语句对,测试集采用的是美国国家标准与技术研究院2002年的数据集NIST02、NIST03、 NIST04、 NIST05 和 NIST08,验证集采用的是NIST06,分别对中英语料进行字节对BPE(Byte Pair Encoder)编码处理[23],中文和英文分别使用BPE表,表的大小均为32 000,中文设置词表大小为4万,英文设置词表大小为3万,不在词表中的低频词使用特殊符号“〈UNK〉”替换。 德英翻译任务中使用的数据是IWSLT2016平行语料,训练集包含18.5万个口语语料平行句对,验证集包含8 415个平行语句对,测试集包括7 883个平行语句对,分别对德英进行BPE编码处理[23],表的大小均为32 000,德文和英文词表大小均设置为3万,不在词表中的低频词使用特殊符号“〈UNK〉”替换。 本文所有实验的实现都是基于开源代码fairseq[24],将训练模型设置为Transformer。所有模型的训练和测试均是基于NVIDIA GeForce GTX 1080 GPU,设置一个批次中最多包含5 000个词,在所有的实验中均使用相同的超参数,采用Adam[25]优化器和逆平方根学习率计划,初始化学习率为0.000 5,β1=0.9,β2=0.99,ε=10-9,在训练期间,本文中所有相关实验均设置丢弃概率为0.3,并且设置标签平滑[26]的值为0.1。在解码的时候,采用束搜索(Beam Search)的解码方式,搜索宽度设置为5,其他实验设置与文献[7]的相同。 5.3.1 中英翻译实验结果分析 中英翻译任务的实验结果如表1所示。从表1中可以看出,基准系统在5个测试集上的平均BLEU得分为44.47。 仅在解码器端添加层间信息和子层间信息增强的平均得分分别为44.81和44.98,相比于基准系统分别提升了0.34和0.51,这说明子层信息增强方法优于层间信息增强方法。此外,对比层间信息增强和子层间信息增强的不同的信息融合方法,可以看出,算术平均融合的效果更优。 仅在编码器端添加层间信息和子层间信息增强的平均得分分别为44.65和44.73,该实验结果相比于基准系统略微有所提升。但是,对比实验结果仍可说明,子层信息增强方法更优于层间信息增强方法,并且,算术平均融合的效果更优,这与仅在解码器端添加信息增强得到的结果一致。 在编码器和解码器端分别添加层间信息和子层间信息增强的平均得分分别为45.10和45.13,相比于基准系统分别提升了0.63和0.66,再次表明子层信息增强方法优于层间信息增强方法,算术平均融合的效果更好。 为了对比信息传递增强和残差网络在多层神经网络中的影响,本文实验移除了残差网络仅使用子层间信息传递增强方法,实验结果如表1中第2行所示。从表1中可以看出,子层间信息传递增强和残差网络的平均分相差0.02,结果几乎持平,这说明了子层信息传递增强方法的有效性。 Table 1 BLEU scores of Chinese-English translation tasks表1 中英翻译任务的BLEU得分 5.3.2 德英翻译实验结果分析 德英翻译任务的实验结果如表2所示。从表2中可以看出,基准系统在测试集上的BLEU得分为34.50。仅在解码器端添加层间信息和子层间信息增强的得分为34.61和34.73,相比于基准系统分别提升了0.11和0.23。仅在编码器端添加层间信息和子层间信息增强的得分为34.56和34.68,实验结果略微高于基准系统的。在编码器端和解码器端分别添加层间信息和子层间信息增强平均得分分别为34.75和34.92,较基准系统分别提升了0.25和0.42。 Table 2 BLEU socres of German-English translation tasks表2 德英翻译任务的BLEU得分 通过对中英翻译和德英翻译的实验结果的对比和分析,发现子层间的输出信息对模型的语义信息补充得更加充分,这与本文的直观猜想一致,同样也说明了残差网络的重要性。此外,通过实验观察不同的信息融合方法可以得出,利用算术平均方法进行信息融合的效果更好。 为了进一步分析不同的方法对于不同句长输入的翻译质量,本文将所有的测试集根据句子长度分为6个不同的部分,分别测试了不同系统对不同长度句子的翻译效果。实验结果如表3所示,其中句长为21~30的句子共有1 683句,句长为10~20和30~40的分别有1 635句和1 222句。从表3中可以看出,子层间信息融合传递增强在所有句长上的测试水平均高于基准系统的,其中句长大于50的句子中BLEU得分提升了0.74,可见子层间信息融合传递增强处理较长的句子更具优势。 表4所示为从测试集中随机抽取的句子和不同的方法得到的相应的译文,对句子进行分析,基准系统中丢失了原文中“从中受益”的翻译,与之相比,加入了本文提出的各层间信息融合传递增强和各子层间信息融合传递增强的系统分别翻译为“benefited from it”和“benefited”,翻译准确无误并和参考译文相符。对于较长的句子,基准系统漏翻了“凌晨”一词,而加入本文方法的系统,分别将其翻译为”daybreak”和”early in the morning”,与参考译文相符,并且翻译无误。 本文提出层间信息融合传递增强和子层间信息融合传递增强的方法,在残差网络的基础上能够进一步补充多层神经网络逐层传递过程中的退化信息。通过保留之前所有层或子层的输出信息并将保留的信息使用不同的方法进行融合,再经过一个“保留门”机制来控制之前所有层或子层的输出融合后的信息保留的权重比例,将融合后的信息与当前层或子层的输出连接,共同作为下一层或下一子层网络的输入,使得多层网络中层与层之间的信息传递更加充分,优化了神经网络的信息捕获能力,增强了逐层信息的传递。 未来的工作中,将探索更加复杂的连接方式,使得本文方法的效果能够得到进一步提升。最后,感谢“江苏高校优势学科建设工程资助项目”对本文的支持。 Table 3 BLEU scores of different sentence lengths in Chinese-English translation systems表3 中英翻译系统不同句子长度的BLEU得分 Table 4 Translation comparison of different systems表4 不同系统的译文对比4 层间信息传递增强的方法
4.1 各层间信息传递增强

4.2 子层间信息传递增强

5 实验与结果分析
5.1 数据集
5.2 实验设置
5.3 结果及分析

5.4 层间信息融合传递增强对不同句长的翻译影响
5.5 译文质量分析
6 结束语


猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
测控技术(2021年10期)2021-12-21
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
机械制造与自动化(2018年4期)2018-08-21
上海公路(2018年3期)2018-03-21
光学精密工程(2016年5期)2016-11-07
西南石油大学学报(自然科学版)(2015年4期)2015-08-20
电子设计工程(2015年22期)2015-08-10
