
基于迁移学习的汉越神经机器翻译
2021-02-02 08:51黄继豪余正涛于志强文永华
厦门大学学报(自然科学版) 2021年1期
黄继豪,余正涛,于志强,文永华
(昆明理工大学信息工程与自动化学院,云南省人工智能重点实验室,云南昆明650500)
随着我国“一带一路”战略的提出,中越两国交流日益频繁,汉语-越南语(简称汉越)双语翻译技术需求不断增长,但是汉语-越南语神经机器翻译(neural machine translation,NMT)平行语料规模较小,翻译性能不够理想,这成为制约中越两国交流的瓶颈问题.基于编解码模型的端到端NMT[1-2]是目前机器翻译的主流研究方向,其利用编码器将源语言文本编码为固定长度的语义表示,解码器利用该表示逐词生成相应的目标翻译.目前基于编解码的NMT模型包含大量的参数,需要利用大规模平行语料实现参数优化,因此虽然NMT模型在资源丰富型语言翻译任务上已具备很好的翻译性能[3-4],但是低资源语言因为语料规模有限,模型无法得到充分的训练,导致模型性能不佳.Zoph等[5]也证明在低资源的场景下,NMT性能甚至低于传统的统计机器翻译(SMT).因此探索如何利用资源丰富型语言来提升汉越NMT性能成为了当下的研究热点.
目前枢轴语言和迁移学习是解决低资源场景下NMT效果不佳的有效方法.Wu等[6]和Utiyama等[7]提出基于枢轴语言的翻译方法,使用资源丰富型枢轴语言桥接源语言和目标语言,利用存在的源语言-枢轴语言和枢轴语言-目标语言的平行语料库,分别训练源语言到枢轴语言和枢轴语言到目标语言的翻译模型.该方法的优点在于,即使在缺乏大规模的双语平行语料库的低资源场景下,也可以利用枢轴语言实现源语言和目标语言的有效翻译;但是直接使用枢轴语言作为翻译的中间桥梁,会因为源语言到枢轴语言、枢轴语言到目标语言的二次解码而造成误差累积.相较于枢轴语言方法,迁移学习(transfer learning,TL)可以直接改进源语言-目标语言模型参数.Zoph等[5]提出使用迁移学习提升低资源NMT的方法,利用资源丰富语言上训练得到的翻译模型参数对低资源语言翻译模型参数进行初始化.Cheng等[8]提出一种基于枢轴语言的迁移学习方法,在模型训练中考虑源语言-枢轴语言和枢轴语言-目标语言之间的关联性,并通过对源语言-枢轴语言和枢轴语言-目标语言翻译模型进行联合训练,且在训练期间共享模型参数.但源语言到枢轴语言,枢轴语言到目标语言这样分步训练的过程缺少双语平行语料的指导,导致多语言输入所产生的噪声现象;而且上述方法更侧重于改进低资源场景下模型的参数,并没有对单独的编码器或者解码器进行改进.
汉越NMT是一种典型的低资源场景下的NMT,其训练语料稀缺,但是汉语-英语(简称汉英)、英语-越南语(简称英越)平行语料却大量存在,因此适用于使用迁移学习与枢轴语言的方法来解决其翻译性能不佳的问题.本文提出一种基于迁移学习的汉越NMT(TLNMT-CV)模型,将迁移学习的思想应用到汉越NMT模型的训练中,在此基础上引入枢轴语言思想,选择英语作为枢轴语言来缓解汉越语言差异大的问题.首先利用汉英、英越平行语料训练编码器与解码器的参数,然后利用此参数对汉越NMT模型的编码器与解码器参数进行初始化,最后使用汉越小规模平行语料对模型参数进行微调,从而提升汉越翻译的性能.
1 基于迁移学习的NMT
NMT是一个典型的编解码结构,其中编码器读取整个句子序列并进行编码,得到句子的向量表示,解码器利用编码器获取到的句子向量作为目标输入,逐词生成目标语言的单词序列.迁移学习可以将模型学习到的参数迁移到相近的任务上,利用高资源翻译任务得到的参数来改善低资源翻译任务的性能,从而降低翻译任务对平行数据的依赖[9].Lakew等[10]提出使用动态词表的方法,通过将初始语言对的模型参数迁移到新的语言对来提升机器翻译模型的性能与收敛速度.Hill等[11]证明了在语义相似性任务上,从NMT编码器中得到的单词向量表示优于从单语(例如语言建模)编码器中获得的单词向量表示.Mccann等[12]使用NMT模型的注意力机制将词向量语境化来改善自然语言处理任务的性能.李亚超等[13]在藏语-汉语(简称藏汉)NMT研究中采用迁移学习方法缓解藏汉平行语料数量不足的问题:首先使用大规模英汉平行语料训练得到一个英汉NMT模型;其次,在训练藏汉NMT模型时,采用英汉翻译模型整体参数初始化藏汉翻译模型参数;最后对英汉翻译模型参数初始化后的汉藏模型使用藏汉平行语料进行参数微调得到最终的模型.与Zoph等[5]提出的方法不同,李亚超等[13]提出的方法对藏汉翻译模型的所有参数均使用英汉模型来初始化,且在初始化时不要求两种翻译模型的汉语词向量一致,没有对翻译模型结构进行修改,更加适用于低资源场景下的NMT.通过以上分析可知,在富资源语言上预训练NMT模型的参数初始化低资源模型的参数,不仅可以保证富资源语言上学习的语言知识能够迁移到低资源模型中,还可以加快模型的收敛速度.
2 TLNMT-CV模型
NMT模型将源语言句子表示成一个定长向量,但是固定长度的向量不能充分表达出源语言句子的语义信息.基于注意力机制的NMT先将源语言句子编码为向量序列,然后在生成目标语言时,通过注意力机制动态寻找与生成该词相关的源语言词语信息,大大增强了NMT的表达能力.本文在Klein等[14]提出的基于注意力机制的Transformer基础上训练汉英与英越的翻译模型,训练流程如图1所示.首先采用大规模的汉英平行语料与大量的英越平行语料训练得到两个预训练模型(A和B);其次,在训练汉越NMT模型时,采用汉英模型的编码器参数初始化汉越翻译模型的编码器参数,并且采用英越模型的解码器参数初始化汉越翻译模型的解码器参数;最后,对初始化参数后的模型采用汉越平行语料进行微调训练,得到最终的TLNMT-CV模型(C).
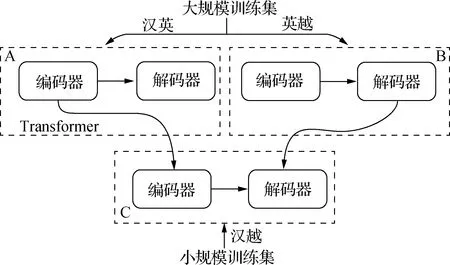
图1 TLNMT-CV训练流程图Fig.1Training flow chart of TLNMT-CV
与Zoph[5]等和李亚超等[13]方法不同的是,本文对汉越翻译模型的编码器与解码器参数,使用汉英模型的汉语端编码器与英越模型的越南语端解码器的参数来初始化,在此基础上再使用小规模汉越双语平行语料进行微调训练,得到汉越NMT模型.为了提升预训练得到的编码器与解码器之间的关联性,保证初始化的参数更有利于微调训练,本文在进行实验前对训练集进行扩充.首先在已有的汉英、英越的训练集中,对枢轴语言英语进行回译[15],使用大规模英汉平行语料训练英汉翻译模型;然后利用英汉翻译模型对英越平行语料中的英语进行回译,从而得到汉-英-越三语平行语料;再使用数据增强[16]的方法增加汉-英-越三语平行语料,提升模型参数之间的关联性,减少存在的噪声.
3 实验与结果分析
3.1 实验数据
本实验采用规模为10万句对的汉越平行语料,其中测试语料0.13万句对,验证语料0.1万句对;70万句对英越平行语料,其中测试语料0.5万句对,验证语料0.4万句对; 汉英平行语料5 000万句对,其中测试语料3万句对,验证语料1万句对.在训练之前对实验数据进行过滤乱码与分词处理,其中汉语分词工具采用结巴分词,越南语分词采用Underthesea-Vietnamese NLP工具.
为了增加实验数据,使用回译与数据增强的方法,扩充汉越训练语料.回译阶段使用汉英大规模语料训练翻译模型,对2万英越平行句对中的英语语句进行回译得到2万伪平行的汉英语料,与越南语对应并经人工筛选后得到1.5万汉越平行语料,将得到的汉越平行语料加入到初始的10万汉越平行语料中.最后使用数据增强的方法对11.5万的汉越平行语料词表(词表为3.2万个词)中出现次数少于3的稀有词进行替换,再通过人工筛选得到12万汉越平行语料.
3.2 实验设置
为了评估TLNMT-CV模型的有效性,实验选取5个基线系统(基于SMT的Moses[17]、基于OPENNMT[14]框架的Transformer、卷积神经网络(CNN)、基于注意力机制的Google NMT(GNMT)[18]和李亚超等[13]提出的迁移学习翻译(Nmt-trans)模型作为对比.
Moses、Transformer、CNN、Nmt-trans、GNMT与本文提出的TLNMT-CV模型,在汉越翻译方向上均以12万的汉越平行语料作为训练集.
Moses训练中,使用Mgiza[19]训练词对齐,利用Lmplz[20]训练三元语法的语言模型(LM).
Transformer、TLNMT-CV和Nmt-trans模型使用的词表设置为3.2万,句子的最大长度设置为50,“transformer_ff”设置为 2 048,“label_smoothing”设置为0.1,“attention head”设置为2,“dropout”设置为0.2,隐藏层数量设置为2,词嵌入维度设置为256,“batch_size”设置为128,学习率设置为0.2.优化器选择Adam[21],其参数设置为β1=0.9,β2=0.99,ε=10-8.CNN中编码器设置为10层,解码器则采用长短时记忆(LSTM)网络,批次大小为64,卷积核大小设置为3.GNMT中隐藏层数量设置为2,“num_units”设置为128,“dropout”设置为0.2.
3.3 实验结果
本文采用双语互译评估(BLEU)值作为评测指标.表1给出的是基线系统与TLNMT-CV在汉越和越汉两个翻译方向上模型的BLEU值对比结果.其中TLNMTe为参照TLNMT-CV模型只对编码器参数预训练,TLNMTd为参照TLNMT-CV模型只对解码器参数预训练.
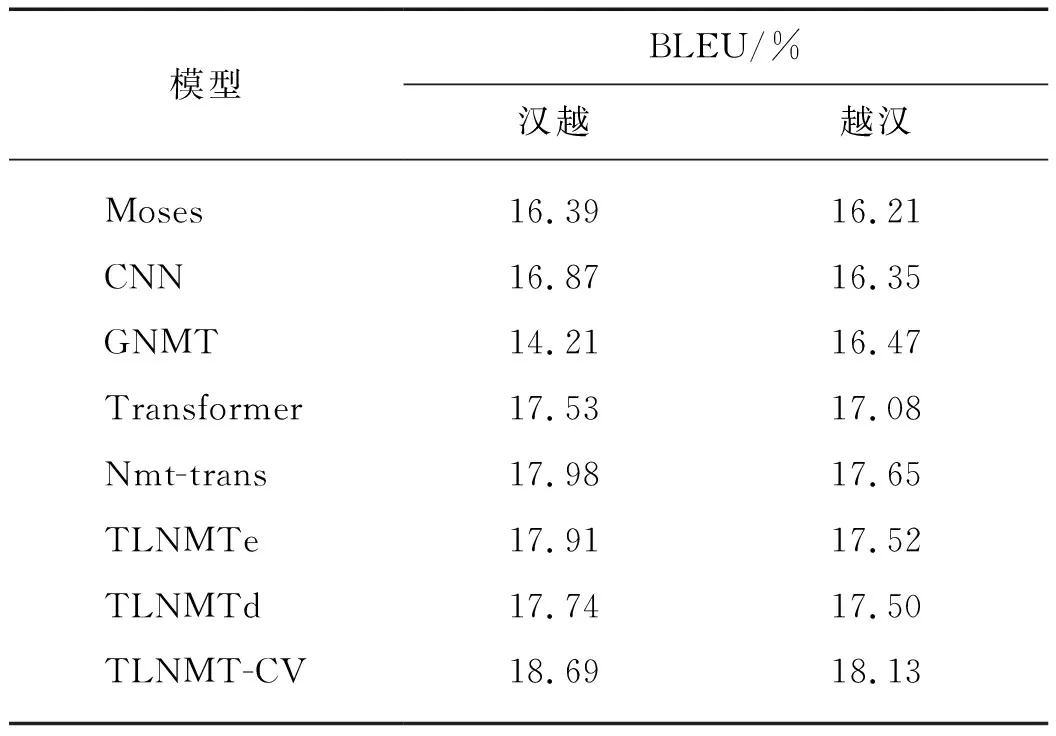
表1 不同模型的BLEU值对比Tab.1 Comparison of BLEU values of different models
从实验结果可以看出汉越双语NMT上TLNMT-CV模型效果明显均优于基线系统,其中TLNMTe模型BLEU值对比Moses模型在汉越翻译方向上提升1.52个百分点,在越汉翻译方向上提升1.31个百分点.对比Transformer模型,TLNMTe模型BLEU值在汉越翻译方向上提升0.38个百分点,越汉翻译方向上提升0.44个百分点. TLNMT-CV模型在汉越翻译方向上BLEU值对比Nmt-trans模型提升0.71个百分点,越汉翻译方向上提升0.48个百分点.TLNMT-CV模型在汉越翻译方向上BLEU值对比Transformer模型提升1.16个百分点,在越汉翻译方向上提升1.05个百分点.
表2给出的是基线系统与TLNMT-CV模型在汉越翻译方向上译文的对比示例.
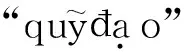
以上翻译示例说明,本文方法虽然仍存在翻译不充分的问题,但是在汉越NMT任务上,比基线系统能产生更高质量和准确度的译文.

表2 不同模型的译文示例Tab.2 Translation examples of different models
4 结 论
本文提出的TLNMT-CV方法,能够利用汉英和英越大规模语料训练汉越NMT的编码器与解码器的初始化参数,通过小规模汉越语料微调训练获得汉越NMT模型,该方法能够提升低资源场景下汉越NMT性能.对比实验也证明了本文提出方法的有效性.下一步可以继续探索利用大规模的汉越单语语料进行预训练,并将预训练得到的语言知识融合到汉越双语NMT模型构建中,提升翻译的性能.
猜你喜欢
传感器世界(2022年4期)2022-08-05
新高考·高一数学(2022年3期)2022-04-28
思维与智慧·上半月(2022年4期)2022-04-08
锻压装备与制造技术(2021年5期)2021-11-13
小哥白尼(神奇星球)(2021年4期)2021-07-22
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
新高考·高一物理(2017年7期)2018-03-06
