
基于BERT 模型的中文短文本分类算法
2021-01-15 07:17段丹丹唐加山袁克海
计算机工程 2021年1期
段丹丹,唐加山,温 勇,袁克海,2
(1.南京邮电大学 理学院,南京 210023;2.圣母大学 心理学系,美国 南本德46556)
0 概述
根据中国互联网络信息中心于2019 年2 月28 日发布的第43 次《中国互联网络发展状况统计报告》[1],截至2018 年12 月我国网民规模达8.29 亿,互联网普及率达到59.6%,其中网民通过手机接入互联网的比例高达98.6%,即时通信、搜索引擎和网络新闻是手机网民使用率最高的应用,这3 类手机应用包含聊天记录、搜索日志、新闻标题、手机短信等大量短文本[2],携带了丰富的数据信息,其已成为人类社会的重要信息资源,如何高效管理这些海量的短文本并从中快速获取有效信息受到越来越多学者的关注,并且对于短文本分类技术的需求日益突显。
国内学者针对中文短文本的分类研究主要包括中文短文本的特征表示与分类算法的选择与改进。文献[3]提出一种基于word2vec 的中文短文本分类算法,使用word2vec 词嵌入技术对短文本的分词结果进行词向量表示,并使用TF-IDF 对每个词向量进行加权,最终使用LIBSVM 分类算法进行文本分类。实验结果表明,该算法可以有效提高短文本的分类效果。文献[4]提出一种全新的文本表示方法(N-of-DOC),即通过运用基尼不纯度、信息增益和卡方检验从短语特征中提取整个训练集的高质量特征。每篇文档提取的短语特征必须由这些高质量特征线性表示,再经word2vec 词向量表示后,使用卷积神经网络(Convolutional Neural Network,CNN)的卷积层和池化层提取高层特征,最终利用Softmax 分类器进行分类。实验结果表明,该方法在分类精度上相比传统方法提高了4.23%。文献[5]以微博为例,设置词和字两种特征粒度,选择信息增益率、信息增益、word2vec 和特征频度来降低特征维度,重点探讨两种特征粒度在口语化短文本分类中的特点和作用,并得出在口语化短文本分类中选择字特征效果更好。文献[6]提出一种基于混合神经网络的中文短文本分类方法,先使用自定义特征词筛选机制将文档基于短语和字符两个层面进行特征词筛选,运用CNN 结合循环神经网络(Recurrent Neural Network,RNN)提取文档的高阶向量特征,并引入注意力机制优化高阶向量特征。实验结果表明,在二分类及多分类数据集上,该方法能够在分类精度上比单模型取得更好的效果。文献[7]提出一种融合词频-逆文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)和隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)的中文FastText 短文本分类方法。该方法在模型输入阶段对经过n元语法模型处理后的词典进行TF-IDF筛选,之后使用LDA 模型对语料库进行主题分析以补充特征词典,使得模型在计算输入词序列向量均值时会偏向高区分度的词条。实验结果表明,该方法在中文短文本分类方面具有更高的精确率。
文献[8]采用正则化权值的方式对K 近邻(KNearest Neighbor,KNN)算法进行改进,并结合粒子群优化(Particle Swarm Optimization,PSO)算法提高文本分类效果。文献[9]采用组合模型的方式,提出一种基于集成神经网络的短文本分类模型C-RNN。该方法使用CNN 构造扩展词向量,再利用RNN 捕获短文本内部结构的依赖关系,然后使用正则化项选取出模型复杂度和经验风险均最小的模型。实验结果表明,该方法对短文本分类具有较好的分类效果和鲁棒性。
上述针对短文本的特征表示算法均是将短文本进行分词或者分字,处理对象为字符或者词语层面的特征,而由于短文本具有特征稀疏的特性,字符或者词语不能表示短文本的完整语义,因此导致短文本的特征表示向量不能较好地代表短文本语义。文献[8-9]虽然对分类算法进行了改进,但是分类算法的输入仍是短文本的特征表示向量,特征表示向量的误差会向下传至分类器,因此,短文本的特征表示是提高短文本分类性能的关键步骤。基于以上研究,本文将对短文本的特征表示进行改进,提出一种基于Transformer 的双向编码器表示(Bidirectional Encoder Representation from Transformer,BERT)[10]的中文短文本分类算法。
1 基于BERT 的中文短文本分类
本文基于BERT 的中文短文本分类算法主要由短文本预处理、短文本向量化以及短文本分类三部分构成,短文本预处理的目的是将输入的短文本整理成分类所需的文本,降低其他符号对分类效果的影响,然后对预处理后的短文本进行向量化表示并形成特征向量,最终将特征向量输入搭建好的分类器以实现短文本分类。
1.1 短文本预处理
中文短文本有多种预处理方式,而本文对于短文本的预处理过程具体如下[11]:
1)文本清洗。文本清洗主要包括去除特殊符号、去除多余空白及文本繁体转简体3 个步骤。去除特殊符号以及多余空白是使短文本的特征表示尽可能地只关注短文本自身词汇的特征和语义本身,降低其他符号对分类准确率的影响。文本繁体转简体是为了方便后续的文本向量化表示,因为本文使用的文本向量化表示方法是调用外部的词向量模型,如果文本中使用的词汇不在词汇表中,则会使当前词汇使用初始化的向量表示方法,改变词汇本身的语义,而多数繁体文本较为复杂,通常都会超出词汇表的范围,而将其转为简体既不会改变其本身的语义,又方便向量化表示,所以文本繁体转简体的步骤十分必要。
2)去除停用词。因为中文短文本中通常存在“的”“吧”“啊”“呃”等高频且无实际意义的词,所以本文将这类词语加入停用词库进行过滤,这样可在一定程度上降低输入文本的特征维度,提高文本分类处理的效率和效果。
3)类别匹配。将原始文本与其对应类别一一匹配,因为本文使用有监督的文本分类算法,所以需要知道每一个样本的特定类别。
4)文本过滤。文本过滤主要包括文本过滤和类别过滤。文本长度过滤是因为本文研究对象为短文本,而短文本通常为不超过200 个字符的文本形式,若文本过长,则会超出本文研究范围,所以将此类文本进行过滤。类别过滤是因为有的类别所包含的文本样本过少,不具有研究参考价值,所以将此类别的文本进行整体过滤。
1.2 BERT 模型
预处理后的短文本只有再经过一次向量化表示,才能作为分类模型的输入。通常地,短文本向量化表示是将短文本进行分词,之后针对分词后的短文本进行特征词提取,选取最能代表短文本语义的特征词进行词向量表示,一般使用word2vec 模型[12]作为词向量模型,能够将每个特征词都转化为相同形状的多个1×k维的向量,其中k为词向量维数,最后经过拼接的方式将特征词的词向量整合成一个n×k维的向量,其中n为短文本特征词个数。由于word2vec 模型进行词向量表示时不能通过上下文语义进行特征词区分,例如“苹果”这个词存在多种语义,如果是“院子里的苹果熟了”,则此时“苹果”表示水果,如果是“苹果公司发布新产品”,则此时“苹果”表示公司名,因此word2vec 词向量模型会将这两个短文本中的“苹果”都表示成相同的向量,然而对于分类器而言,这两个词表示相同含义。为解决该问题,本文使用BERT 模型替代word2vec 模型进行文本语义表示。
1.2.1 BERT 模型结构
BERT 模型结构[10]如图1 所示,其中E1,E2,…,EN表示字的文本输入,其经过双向Transformer 编码器(Trm 模块)得到文本的向量化表示,即文本的向量化表示主要通过Transformer 编码器实现。

图1 BERT 模型结构Fig.1 Structure of BERT model
Transformer[13]是一个基于Self-attention 的Seq2seq模型。Seq2seq 是一个Encoder-Deocder 结构的模型,即输入和输出均是一个序列,其中,Encoder 将一个可变长度的输入序列变为固定长度的向量,Decoder 将该固定长度的向量解码为可变长度的输出序列,Seq2seq 模型结构如图2 所示。

图2 Seq2seq 模型结构Fig.2 Structure of Seq2seq model
通常解决序列问题的Encoder-Decoder 结构的核心模块基于RNN 实现,但是RNN 不能进行并行实现且运行速度慢。为此,Transformer 使用Self-attention替代RNN。BERT 模型中主要使用Transformer 的Encoder 部分,具体结构如图3 所示。

图3 Transformer Encoder 结构Fig.3 Structure of Transformer Encoder
从图3 可以看出,Encoder 的输入是一句句子的字嵌入表示,然后加上该句子中每个字的位置信息,之后经过Self-attention 层,使得Encoder 在对每个字进行编码时可以查看该字的前后信息。Encoder 的输出会再经过一层Add &Norm 层,Add 表示将Selfattention 层的输入和输出进行相加,Norm 表示将相加过的输出进行归一化处理,使得Self-attention 层的输出有固定的均值和标准差,其中,均值为0,标准差为1,归一化后的向量列表会再传入一层全连接的前馈神经网络。同样地,Feed Forward 层也会经过相应的Add &Norm 层处理,之后输出归一化后的词向量列表。Encoder 部分中最主要的模块为Self-attention,其核心思想是计算一句句子中每个词与该句子中所有词的相互关系,再利用这些相互关系来调整每个词的权重以获得每个词新的表达方式,该表达方式不但蕴含词本身的语义,还蕴含其与其他词的关系,因此通过该方法获得的向量相比传统词向量具有更加全局的表达方式[14]。
1.2.2 Self-attention 计算
假设输入句子X,将其按照字粒度进行分字后表示为X=(x1,x2,…,xN)T,N表示输入句子中字的个数,将每个字采用One-hot 向量[15]表示,设维数为k,则X对应的字嵌入矩阵为A=(a1,a2,…,aN)T,其中ai是对应xi的向量表示,是一个k维向量,A是一个N×k维的矩阵,每一行对应该输入句子中一个字的向量表示。Self-attention 计算步骤具体如下:
1)计算Query、Key、Value 矩阵[13],通过模型训练得到:
Q=AWQ,K=AWK,V=AWV
其中:Q、K、V分别为N×dk、N×dk、N×dv维的矩阵,它们的每一行分别对应输入句子中一个字的Query、Key、Value 向量,且每个Query 和Key 向量的维度均为dk,Value 向量的维度为dv;权重矩阵WQ和WK的维度均为k×dk,权重矩阵WV的维度为k×dv。
2)计算Attention[13]:

其中,Softmax(·)为归一化指数函数,当其作用于矩阵时,表示对矩阵中的每一个行向量都进行以下运算[16]:
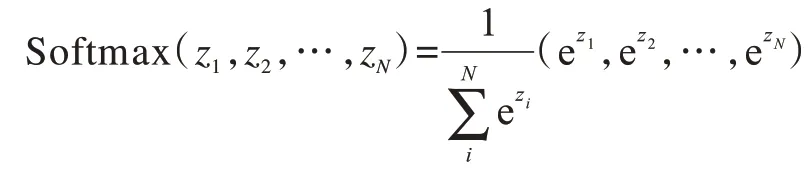
其中,(z1,z2,…,zN)为一个N维行向量,经Softmax(·)函数作用后的行向量元素被等比例压缩至[0,1],并且压缩后的向量元素和为1。最终得到的Attention 值是一个N×dv维的矩阵,每一行代表输入句子中相应字的Attention 向量,该向量已融合其他位置字的信息,是一个全新的向量表示。
由上文计算公式可以看出,整个Self-attention 计算过程是一系列矩阵乘法,且可以实现并行运算,运行速度优于RNN。在实际应用过程中,Transformer 使用Multi-head Self-attention,即多头Self-attention,多头模式可以增强模型关注能力,head 个数即超参数个数[13],在实际训练模型中可以人为设置。假如本文设置head=2,那么其中一个Self-attention 可以更多地关注每个字相邻单词的信息,另一个Self-attention 可以更多地关注每个字更远位置的单词信息,然后将这两个Self-attention 矩阵进行横向拼接,最后使用一个附加的权重矩阵与该矩阵相乘使其压缩成一个矩阵,计算公式[13]如下:

在上文Self-attention 计算过程中没有考虑输入序列中各个单词的顺序,但在自然语言处理中文本的单词顺序是非常重要的信息,例如,“他打了我”和“我打了他”,对应单词完全一样,但是由于单词顺序不同,却表达出完全相反的语义,因此在实际应用中,Transformer 将输入字的位置信息加在输入层的字嵌入表示上,即在进入Self-attention 层之前,字嵌入表示矩阵已经融合了位置信息。综上所述,BERT模型使用双向Transformer 的Encoder 可以学习每个单词的前后信息,获得更好的词向量表示。
1.2.3 预训练任务
为增强语义表示能力,BERT 模型创新性地提出MLM(Masked LM)和NSP(Next Sentence Prediction)两个预训练任务。
1)MLM 任务。给定一句句子,随机掩盖其中的一个或者几个词,用剩余的词去预测掩盖的词。该任务是为了使BERT 模型能够实现深度的双向表示,具体做法为:针对训练样本中的每个句子随机掩盖其中15%的词用于预测,例如,“大都好物不坚牢”,被掩盖的词是“坚”,对于被掩盖的词,进一步采取以下策略:
(1)80%的概率真的用[MASK]替代被掩盖的词:“大都好物不坚牢”→“大都好物不[MASK]牢”。
(2)10%的概率用一个随机词去替代它:“大都好物不坚牢”→“大都好物不好牢”。
(3)10%的概率保持不变:“大都好物不坚牢”→“大都好物不坚牢”。
经过上述操作,在后续微调任务的语句中不会出现[MASK]标记,若总使用[MASK]替代被掩盖的词,则会导致模型预训练与后续微调过程不一致。另外,由于当预测一个词汇时,模型并不知道输入的词汇是否为正确的词汇,这使得模型更多地依赖上下文信息预测词汇,因此上述操作赋予模型一定的纠错能力。本文只随机替换1.5%的词为其他词,整体上不会影响模型的语言理解能力。
2)NSP 任务。给定一篇文章中的两句句子,判断第二句句子在文章中是否紧跟在第一句句子之后。问答(Question Answering,QA)和自然语言推理(Natural Language Inference,NLI)等重要的自然语言处理下游任务多数是基于理解两个句子之间的关系,因此该任务是为了使BERT 模型学习到两个句子之间的关系。具体做法为:从文本语料库中随机选择50%正确语句对和50%错误语句对,若选择A和B 作为训练样本时,则B 有50%的概率是A 的下一个句子,也有50%的概率来自语料库中随机选择的句子,本质上是在训练一个二分类模型,判断句子之间的正确关系。在实际训练过程中,结合NSP 任务与MLM 任务能够使模型更准确地刻画语句甚至篇章层面的语义信息。
1.3 短文本表示
本文使用BERT 模型进行短文本的向量表示,一般的短文本表示流程如图4 所示。

图4 一般短文本表示流程Fig.4 Procedure of general short text representation
BERT 模型的输出有两种形式:一种是字符级别的向量,即输入短文本的每个字符对应的向量表示;另一种是句子级别的向量,即BERT 模型输出最左边[CLS]特殊符号的向量,BERT 模型认为该向量可以代表整个句子的语义,如图5 所示。

图5 BERT 模型输出Fig.5 Output of BERT model
在图5 中,最底端的[CLS]和[SEP]是BERT 模型自动添加的句子开头和结尾的表示符号,可以看出输入字符串中每个字符经过BERT 模型处理后都有相应的向量表示。当需要得到一个句子的向量表示时,BERT 模型输出最左边[CLS]特殊符号的向量,由于本文使用BERT 模型的输出,因此相比一般短文本表示流程,无需进行特征提取、特征向量表示及特征向量拼接,具体流程如图6 所示。

图6 本文短文本表示流程Fig.6 Procedure of the proposed short text representation
1.4 Softmax 回归模型
本文引入Softmax 回归模型进行短文本分类。Softmax 回归模型是Logistic 回归模型在多分类问题中的扩展,属于广义线性模型。假设有训练样本集{(x1,y1),(x2,y2),…,(xm,ym)},其中:xi∈ℝn表示第i个训练样本对应的短文本向量,维度为n,共m个训练样本;yi∈{1,2,…,k}表示第i个训练样本对应的类别,k为类别个数,由于本文研究短文本多分类问题,因此k≥2。给定测试输入样本x,Softmax 回归模型的分布函数为条件概率p(y=j|x),即计算给定样本x属于第j个类别的概率,其中出现概率最大的类别即为当前样本x所属的类别,因此最终分布函数会输出一个k维向量,每一维表示当前样本属于当前类别的概率,并且模型将k维向量的和做归一化操作,即向量元素的和为1。因此,Softmax 回归模型的判别函数hθ(xi)为[17]:

其中:hθ(xi)中任一元素p(yi=k|xi;θ)是当前输入样本xi属于当前类别k的概率,并且向量中各个元素之和等于1;θ为模型的总参数,θ1,θ2,…,θk∈ℝn为各个类别对应的分类器参数,具体关系为
Softmax 回归模型的参数估计可用极大似然法进行求解,似然函数和对数似然函数分别为:

在一般情况下,Softmax 回归模型通过最小化损失函数求得θ,从而预测一个新样本的类别。定义Softmax 回归模型的损失函数[18]为:

其中,m为样本个数,k为类别个数,i表示某个样本,xi是第i个样本x的向量表示,j表示某个类别。
本文使用随机梯度下降法优化上述损失函数,由于在Softmax 回归模型中,样本x属于类别j的概率为因此损失函数的梯度为
1.5 短文本分类算法
本文提出基于BERT 的中文短文本分类算法,具体步骤如下:
算法1基于BERT 的中文短文本分类算法
输入初始中文短文本训练集T={(x1,y1),(x2,y2),…,(xN,yN)},i=1,2,…,N,其中,xi为第i个训练样本对应的中文短文本向量,yi为第i个训练样本对应的类别
输出中文短文本分类模型M
步骤1对训练集T进行预处理得到训练集T′={(x1',y1'),(x2',y2'),…,(xN',yN')},i=1,2,…,N′,其中,xi'为预处理后的第i′个训练样本对应的中文短文本向量,yi'为预处理后第i′个训练样本对应的类别。
步骤2使用BERT 预处理语言模型在训练集T′上进行微调,采用BERT 模型输出得到训练集T′对应的特征表示V=(v1,v2,…,vN'),i=1,2,…,N′,其中,vi是每条短文本xi'对应句子级别的特征向量。
步骤3将步骤2中得到的特征表示V输入Softmax回归模型进行训练,输出中文短文本分类模型M。
2 实验结果与分析
2.1 实验数据
本文实验使用的语料库来自搜狗实验室提供的2012年6月—2012年7月国内、社会、体育、娱乐等18个频道的搜狐新闻数据[19],选取其中体育、财经、娱乐、IT、汽车和教育6 个类别。根据6 000、18 000 和30 000 的文本数据量设计A、B、C 3 组实验,按照8∶1∶1 的比例划分训练集、验证集及测试集,并且每次从各类别中随机选择等量的文本数据,如表1 所示。

表1 实验数据设置Table 1 Setting of experimental data
2.2 评价指标
本文研究问题属于分类问题,分类问题常用的评价指标为精确率(P)、召回率(R)以及F1 值,分类结果的混淆矩阵[20]如表2 所示。

表2 分类结果的混淆矩阵Table 2 Confusion matrix of classification results
1)P是指分类器预测为正且预测正确的样本占所有预测为正的样本的比例,计算公式如下:

2)R是指分类器预测为正且预测正确的样本占所有真实为正的样本的比例,计算公式如下:

3)F1 值是P和R的综合指标,一般计算公式[21]如下:

其中,Fβ是基于P和R的加权调和平均,β>0 时表示R对P的相对重要性[21],通常取β=1,此时Fβ为标准F1 值,计算公式如下:

其中,0≤F1≤1,当P=R=1 时,F1 值达到最大值1,此时P和R均达到100%的理想情况,而由文献[21]可知该情况在实际应用中很难实现,当P高时R通常会偏低,当R高时P通常会偏低,因此在使用F1 值评估分类器性能时,其值越接近1,说明分类器性能越好。可见,F1 值可以更加全面地反映分类性能,因此本文将其作为衡量分类效果的主要评价指标。
2.3 实验过程
本文选择TextCNN 模型[22]作为对照模型进行实验,其利用卷积神经网络对文本进行分类,执行效率高且分类效果较好。TextCNN 模型在短文本分类训练过程中使用的分词工具为jieba 分词,词嵌入技术为word2vec,训练参数设置如表3 所示。

表3 TextCNN 模型训练参数设置Table 3 Training parameter setting of TextCNN model
本文使用Google 提供的BERT-Base 预训练模型。该模型具有12 层网络结构,其中隐藏层有768 维,采用Multi-head Self-attention(head=12),并且共有1.1×108个参数,训练参数设置如表4 所示。

表4 BERT 模型训练参数设置Table 4 Training parameter setting of BERT model
2.4 实验结果
本文做了A、B 和C 3 组实验,数据量逐渐增加,每组实验均使用TextCNN 模型作为对比,测试集保持不变,验证集与训练集中的模型参数保持一致,评价指标主要采用F1 值,对比结果如图7 所示。可以看出,在3 组实验中BERT 模型与TextCNN 模型在6 个类别上的F1 值均有所差异,说明两个模型在6 个类别上的分类性能不同,而且两个模型均在体育、娱乐、汽车和教育类别上表现出优于财经和IT 类别的分类性能,主要原因为这4 类新闻数据具有更多的类别区分词,有利于模型学习到更优的类别特征,提高预测能力,这也从侧面反映出文本分类模型的分类性能与文本数据质量具有一定的关系。另外,BERT 模型在6 个类别上的分类性能均比TextCNN模型效果好,其中BERT 模型在A 组实验财经类别上的F1 值相比TextCNN 模型最高提升14 个百分点,在教育类别上最低提升3 个百分点,而且BERT模型在C 组实验的体育类别上的F1 值最高可达97%,在B 组实验财经类别上的F1 值最低为85%,但也高出TextCNN 模型5 个百分点,验证了本文基于BERT 模型的中文短文分类算法的可行性。

图7 BERT 模型与TextCNN 模型的分类结果对比Fig.7 Comparison of classification results between BERT model and TextCNN model
从3 组实验整体分类结果可以看出,随着实验数据量的增加,两个模型F1 值均有所提高,但总体而言,BERT 模型的F1 值一直优于TextCNN 模型,最高F1 值达到93%,相比TextCNN 模型提升6 个百分点,即使在数据量较少的情况下,BERT 模型的F1 值也达到90%,说明其相比TextCNN 模型能更好地表示短文本层面的语义信息,具有更好的中文短文本分类效果。
3 结束语
本文在解决中文短文本分类的问题时,使用BERT 模型替代常用的word2vec 模型进行短文本的向量表示,提出一种基于BERT 模型的中文短文本分类算法。实验结果表明,该算法在搜狐新闻数据的多个类别上具有较好的分类效果,在体育类别上的F1 值最高达到97%,并且随着数据量的增加,在测试集上的整体F1 值最高达到93%,相比基于TextCNN 模型的中文短文本分类算法提升6 个百分点,说明BERT 模型具有更好的中文短文本分类效果,对其他处理对象为句子级别的自然语言处理下游任务具有一定的参考价值。后续将在本文算法的句子表征上融入表情、标点符号等位置信息来丰富短文本的句子向量特征表示,进一步提高中文短文本的分类效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
高中生学习·高三版(2016年9期)2016-05-14
新校长(2016年8期)2016-01-10
新高考·高二数学(2015年11期)2015-12-23
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
阅读与作文(英语高中版)(2013年12期)2013-12-11
