
基于地质图像大数据的岩性识别研究*
2021-01-15 02:31胡启成叶为民陈永贵
工程地质学报 2020年6期
胡启成 叶为民② 王 琼 陈永贵
(①同济大学岩土及地下工程教育部重点实验室,上海 200092,中国)(②教育部城市环境与可持续发展联合研究中心,上海 200092,中国)
0 引 言
2008年,Google推出了GFT(Google Flu Trends),利用Google搜索引擎,根据人们键入的搜索关键词的频数预测流感,经与美国疾病控制和预防中心监控报告相关书籍的多次比对,证实了预测结果与实测值之间存在很大的相关性(Laser et al.,2014)。这意味着,利用大量数据的相关性解决部分问题成为可能。与此同时,根据搜集到的用户信息,大数据推荐系统可向用户推送专属、感兴趣的片段信息(朱扬勇等, 2015),如购物软件的商品推荐系统,音乐软件的歌曲推荐系统,导航软件的交通流量预测等等,大数据已经渗透进人们生活的方方面面。
长期以来,地质学科积累有大量的文本、图像和序列数据,借助大数据手段开展地质数据在科研和商业上的应用研究,具有极其重要的理论与社会意义。2017年11月,“地质云1.0”上线运行,实现了地质调查数据共享; 2018年10月18日,“地质云2.0”在2018中国国际矿产大会上正式上线,我国的地质数据共享工作正在有序推进。
地质大数据一般包括序列数据、文本数据及图像数据。其开发利用过程一般包括数据采集、数据预处理、模型构建、模型训练和结果评价等5个步骤。其中,模型构建是地质大数据挖掘的关键。
地质数据挖掘的发展主要取决于大数据挖掘技术的进步。初期主要依赖于传统的机器学习、模式识别等方法,如Bhattacharya et al.(2006)利用决策树、人工神经网络及支持向量机算法,将静力触探试验测得的锥尖阻力和侧壁摩阻力生成图像,再利用CONCC算法进行分割,并针对分割块进行土性分类。Marjanoviet al.(2011)通过GIS系统提供的关于滑坡的地理、地质数据,分别使用决策树、logistic回归模型和SVM模型进行滑坡稳定性分析,并且通过对比展现出SVM模型的泛性。当深度学习展露出强大功能后,Patel et al.(2016)使用Probabilistic Neural Network对石灰石种类进行分类; 程国建等(2016)借助深度学习将多隐含层(Hidden Layer)与大量训练数据联系起来,构建“深网络模型”实现自动学习并最终提升岩性分类的准确性。刘丽婷(2017)将深度信念网络应用于岩石薄片的图像处理中,借用光学显微镜进行图像采集,经无缝拼接出整张图片的光学图,并传入深度信念网络分类模型。张野等(2018)采用基于Inception-v3的深度卷积神经网络模型,建立了岩石图像分类的深度学习的迁移模型,实现基于图像特征的岩性分类。
实际上,开展基于地质图像大数据的岩性识别研究,对于遥感卫星等岩石图像及处于较危险地带岩性图像等的识别,减轻传统人工识别工作强度,提升工作效率与识别准确率等均具有重要的学术与经济社会价值。
本文针对地质大数据中的图像数据,基于深度学习,通过基于网络搜索的数据采集、数据预处理、搭建网络、训练网络以及评价与结果等步骤,开展图像识别岩性研究。结果表明,图像识别岩性的测试准确率可达90%。
1 图像数据(Image Data)
图像是人类世界中数量最大的数据类型之一,可以传递大量的直观信息。基于图像数据可以开展复杂的分析,如识别图中物体、描述图像,甚至对图像进行联想。随着近几年计算机视觉技术的发展,机器在处理诸如图像识别(Image Recognition)、图像描述(Image Caption)、图像风格转移(Style Transfer)等方面均取得了长足进步。
图像识别:简单来说,就是输入图像数据,通过模型输出图像名称。该模型可以是人的大脑,也可以是其他数学模型。实际上,日常地质图像处理工作中,存在诸多识别问题,如岩性识别、矿物识别、结构识别等等。需要指出的是,图像识别不仅只局限于普通光学照片的识别,红外、X光、高光谱等技术同样可以用于地质图像识别。
图像描述:即输入图像数据,借助模型分析,机器输出图像信息对应的文字描述。例如,输入某个地质体的图像,机器会对地质体图像进行分析,从而生成对该地质体相关信息的文字描述。
图像生成:即输入图像数据和图像风格信息,借助模型分析输出带有目标风格的图像。目前常用的生成模型为对抗模型(GAns)和变分自编码器(VAes),两者都拥有较强的图像生成能力。在此基础上,可通过文本数据的加入,构建需求描述和图形设计数据集,从而通过网络模型实现自动生成设计图的功能。
2 基于图像数据的岩性识别
开展基于图像数据的岩性识别,就是要利用输入的图片数据来预测、判断该图片所示的岩性类别,实质上是要寻找一个从高维图片空间到低维图片类别空间的映射。为此,本文开展了数据采集、数据预处理、网络搭建、网络训练和结果评价研究,以实现基于图像数据的岩性识别。本次训练环境为Win10,CPU为i5-8100h,所用的图形加速硬件为RTX2060。
2.1 图像数据采集
数据采集是该类型任务中最重要的部分,数据的数量、质量直接影响到基于图像的岩性识别结果。原则上,采集的数据应该包含目标关键词,图像分辨率不宜过小,图像非拼接,数据分布均匀和图像内只存在同一种类岩石等。
本次岩性图像数据主要是借助百度、谷歌等搜索引擎从网络采集,输入岩石或矿物关键词搜索图片,再利用Python编写爬虫脚本解析网页内容,寻找图片内容的范式,以模拟人类完成下载。最终获取了约1200张、共8个分类的图片数据集。
网络本身是一个超级大的数据库,通过搜索引擎获取的图片同样遵循大数据特性。但需要说明的是,在图片的爬取过程中,由于价值密度的不断降低,后半过程爬取的图片常发生内容与关键词偏离,甚至可能出现广告图片及不完整图片等问题。即图像的质量和数量呈反比关系,爬取的图片越多,质量越差(混入错误的图片越多)。为此,本文最终爬取了约1200张图片。

图1 网络爬取的图像数据Fig.1 Images crawled from Web source
2.2 数据预处理
针对所采集的图片数据存在重复、不完整及与关键词无关等问题(图2),需要进行必要的预处理。对于重复图片(图片编号不同,但内容相同)只能人工删除,或者不处理; 对于数据不完整图片,可以编写脚本检查图片完整性,对不完整图像重新下载即可; 而对于图片数据与关键词不符(即出现不符合标签的错误图片数据),目前未找到较好的解决方法,也只能通过人工检查后删除。可见,图像数据的预处理目前大多通过人工审查来完成,若要使用机器进行预处理,就要先训练机器,而训练机器又需要图片数据这就形成了悖论。

图2 网络采集的问题图像数据Fig.2 Diagrams of problem data编号28和编号33为重复图片; 编号42为无效信息; 编号40和编号41为错误图像
同时,数据预处理的另一项任务是规范图片的存储地址、大小等属性,从而构造数据集并提高数据集的质量。
本次处理中首先规范图片的存储地址为:
——Dataset Folder
——Train Data
——Data
——Test Data
——Data
即一级目录为Dataset Folder,二级目录为Train Data和Test Data,三级目录为Data的各个分类文件夹。其目的是为了使用Pytorch(Python中的深度学习框架)中的ImageFolder函数,以构造训练和测试数据集。训练数据集是网络训练所依赖的数据集,即网络会查看到图片的正确分类,以修正自己的错误,使得下一次预测更准确; 而测试数据集不会获得图片的正确分类,它是对网络性能的一次测试。为了使测试集充分反应模型的能力,极为重要的一点是,网络不能查看到测试集的正确分类。
构造完毕后,使用transforms函数将图像数据集大小重新调整为448×448(根据机器性能决定,一般为2的倍数),再将图片数据转化为tensor(张量)数据,以方便读取和训练,并对张量数据进行归一化处理,加快模型的收敛速度。对于训练数据集,在转化为张量数据之前,可以利用数据集增大(Dataset Aggregation)操作,如对图像翻转、随机裁剪等等,增加训练数据集的多样性。
图3是处理完成后, 36张训练数据集的可视化效果。

图3 可视化的训练样本Fig.3 Visualized training data
2.3 网络搭建
为使网络模型拥有不错的性能,同时又不消耗过多的训练时间,选择了预训练的Resnet50模型进行迁移训练。
Resnet模型是广大神经网络模型家族中的一员,拥有神经网络模型的普遍特性,即模型是由模块(Block)所堆叠组成的,每个模块通常由不同功能的神经层(Layer)所连接而成(图4、图5)。其中输入层(Input Layer)负责数据的输入,输出层(Output Layer)负责数据的输出,卷积层(Convolution Layer)负责数据的卷积运算以获得图像的特征信息,非线性层(Non-linearity Layer)负责对特征信息进行非线性拟合,池化层(Pooling Layer)负责对数据降维、压缩参数数量等。
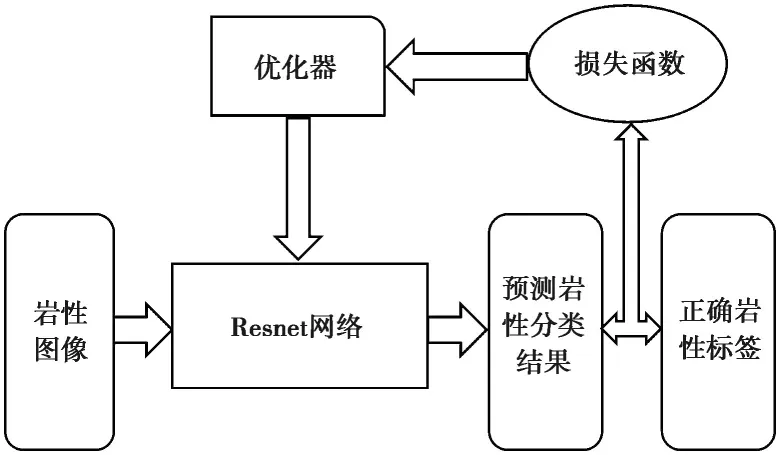
图4 网络训练流程图Fig.4 Flow path for network training
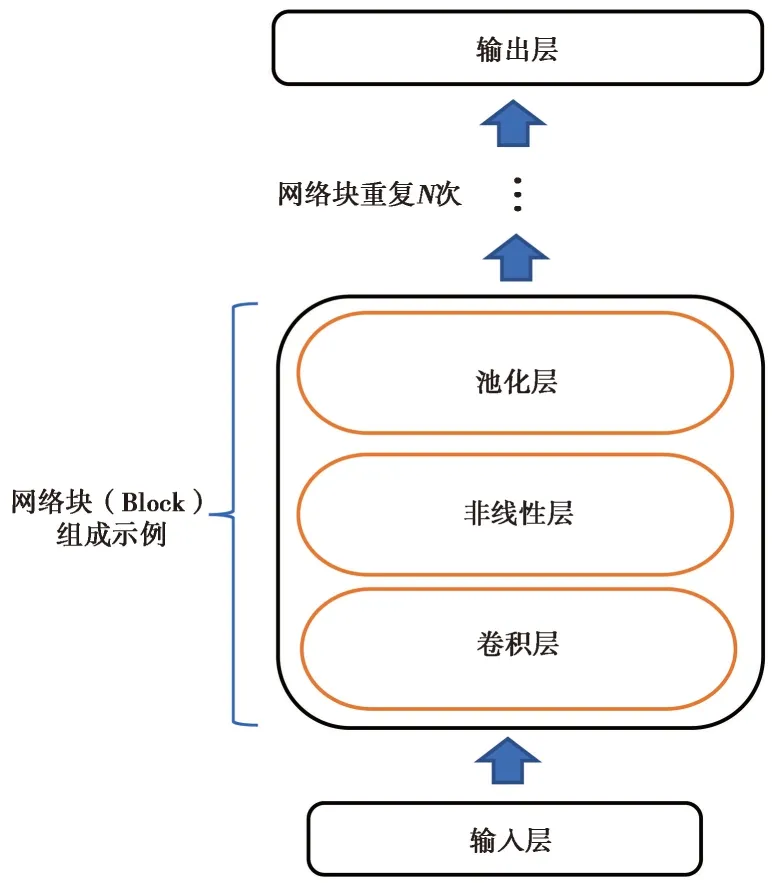
图5 网络模型示意图Fig.5 General view of a network model
经过上述一系列功能层的组合与堆叠,模型能够学习图像中物体的特征信息。特征信息获取的多少与网络模型的深度有关。以任意一张岩石图像为例,图6是输入图像经不同模块处理后的特征可视化图,其中图6a是输入的原始图片; 图6b是经第1个模块(block)的处理结果。从蓝到红,提取特征的相关程度依次上升,每一张小图表示该神经层对图像特征学习/提取的激活程度,可以看到浅层的神经层更多地关注岩石物体自身的特征(特别是左侧萤石的特征),同时对于背景图像(右侧光亮区)也赋予了较多的关注; 图6c是经第3个模块处理后的结果。到此深度时,机器所提取特征的激活程度变低,同时所提取的特征变得抽象(人类难以理解),多数情况下,特征呈离散的点状分布,当然依然有特征与岩石和背景相关。利用这些在模型训练过程中所学习到的特征,模型可以很好地对目标物体进行分类。总之,该网络已经被证明拥有良好的图片分类能力(He et al., 2016)。

图6 网络模型学习/提取中的图像特征结果Fig.6 Visualization of part of feature maps of network model a.输入图像; b.第1个模块的可视化结果; c.第3个模块的可视化结果
理论上借助该网络模型,输入岩性图片,便可输出预测的岩性名称。但实际操作过程中,预测的岩性名称难免与实际岩性名称之间会存在一定的误差。为此,本文选择了损失函数(Cost Function)来衡量网络预测值和实际值之间的误差。考虑到图片识别属于分类问题,故这里选择常用于分类问题的交叉信息熵(Cross Entropy Loss)作为衡量误差的函数。
同时,为使网络预测值最接近真实值,需要选用一个优化器,以使衡量误差的损失函数最小化。为此,本文选择常用的随机梯度下降法(Stochastic Gradient Descent)作为优化器。
2.4 网络训练
完成搭建的网络需要进行必要的训练,以保证模型的有效性。实际网络训练过程中,需要手动选择两个参数,即训练批次大小(Batch size)和学习率(lr, Learning rate)。前者主要受硬件设备制约,一般选取2的次方,如32、64等,这里选取了8,即一次同时训练8张图像。学习率对于最后的训练结果影响较大,因而本文依次尝试了10-2,10-3,10-4,10-5情况下的学习率,结果如图7所示。图7结果表明,当学习率为10-2时,训练误差下降太快, 20个轮次后,就已经开始收敛,再进行训练将会过拟合,从而导致模型的实际预测能力不足; 当学习率为10-5时,训练误差下降过慢(图中红色曲线几乎为一直线),模型学习能力不足,故舍弃; 当学习率为10-3,10-4时,训练误差下降正常(绿色与橙色曲线性能良好),准确率稳步上升,再出于训练时间考量,本文选择了前者。

图7 学习率试验曲线Fig.7 Learning rate curvesa.训练误差与训练轮次关系曲线; b.测试误差与训练轮次关系曲线
至此,网络训练参数设置如下:训练批次为8,学习率为0.001,同时利用stepLR函数(Pytorch深度学习框架下的函数)来控制学习率大小变化,使得学习率随着训练过程逐渐减小,直至训练误差或训练准确率收敛。
根据设定的参数,对整个模型经过50轮次(Epoch)的训练,获得训练准确率及测试准确率等参数随训练次数变化关系如图8所示。

图8 模型网络训练过程Fig.8 Network training processes该图为训练准确率与测试准确率随训练轮次变化关系
从图8可以看到,随着训练次数的增加,训练准确率稳定增加,且经约40 Epochs以后逐渐收敛,训练准确率在约94%波动,表明训练基本稳定,网络模型已经学习到了图片的分类特征; 同时,对应的测试准确率尽管伴有数值上的波动,但总体趋势变化与训练准确率曲线相同,网络整体训练完毕。
2.5 结果与评价
图8网络训练表明,测试准确率在75%左右波动,且在第46个轮次达到最高值0.895 833 3,即约90%。选取最高准确率下的网络参数权重值,输入经最优配置的网络模型,开展基于图像的岩性识别,并部分岩样图像及其识别结果见图9。

图9 岩样图像及其岩性识别结果Fig.9 Rock images and lithological recognition results
图9中,左图为图像数据及其对应的岩样正确名称,右图为模型识别获取的岩性数值图(按数值降序排列),其中最值对应的岩性类别即为预测的岩性名称。图9a中,输入的为方解石图像,按识别值降序依次为:方解石、萤石与片麻岩等,说明对于待识别图像,这些岩性具有相似的特征,根据最大值对应的岩性,方解石应为待识别图像的岩性名称; 输出数值为负值时,表明对应的岩性相关性更低; 图9b和9c识别的岩性与图像数据对应的岩性同样一致。
然而,图9d识别结果表明,模型将“砾岩”识别成了“方铅矿”。产生识别错误的原因,可能是由于用于模型学习与识别训练的图像数据数有限,未能达到“大数据”的程度。同时,岩石图像的背景也会对最后的识别结果产生一定的影响,这点理论上可以通过增加数据集数量、使用更高分辨率的图像以及剥离物体和背景来弥补。因此,此类模型要想在实际应用中具有良好表现,就必须收集大量的岩性图片、构建合理的数据集供模型进行训练。此外,岩性分类识别过程中,岩石图片的一些非常相近的特征,譬如宏观的形状、颜色等,都会误导机器给出正相关评分,导致网络产生错误判断。
因此,只有输入足够数量、足够高清的岩性图像数据,机器才能识别出微小的特征差异,完成正确识别。但高清原图数据不易获取、对硬件显存要求高,以及需要的计算资源成倍增长等又成了必须面对的问题。理论上采用BCNN(Bilinear Convolutional Neural Network)等能够捕捉更精细细节的网络模型,对于这类在计算机视觉中被称为细粒度识别问题的解决,应该是今后的一个研究方向。
3 结论与展望
本文基于深度学习理论,通过网络搜索的数据采集、数据预处理、网络搭建、网络训练及结果/评价等,探讨了基于深度学习的地质图像岩性识别问题。
借助深度学习技术,分别从数据采集、数据预处理、网络搭建、训练网络、评价和结果等方面阐述了岩性图像数据的识别过程,构建了识别率约90%的图像识别模型,完成了不同图像的岩性识别,分析了结果误差及其产生的原因。
构建数量多、质量好、数据分布均匀的数据集,是提高识别准确率的有效保证,但由此可能会带来计算资源成倍增长等问题。开发使用能够捕捉更精细细节的网络模型,应该是解决相似特征区分难(细粒度识别问题)的一个研究方向。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
云南化工(2020年11期)2021-01-14
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
建材发展导向(2019年5期)2019-09-09
中国交通信息化(2018年5期)2018-08-21
录井工程(2017年3期)2018-01-22
中国海上油气(2015年3期)2015-07-01
