
基于新词发现和Lattice-LSTM的中文医疗命名实体识别
2021-01-15 08:22赵耀全
计算机应用与软件 2021年1期
赵耀全 车 超 张 强
(大连大学计算机辅助设计国家地方联合工程实验室 辽宁 大连 116622)
0 引 言
作为自然语言处理领域的基础任务,命名实体识别得到了持续的关注。在中文命名实体识别中,目前的主流方法是基于字符的LSTM-CRF模型[1]。然而词语为命名实体识别提供了重要的边界信息,越来越多的研究利用单词信息提高识别的准确率。例如:Rei[2]通过构建一个单词语言的模型去提高命名实体识别的准确率;Peters等[3]通过预先训练一个字符的语言模型来增强单词表示进而提高识别的准确率。
然而,在特定领域的命名实体识别中,由于专业术语的特殊性,未登录词常常会因为歧义造成识别错误。这在医疗领域中尤其严重,如“支气管哮喘”中的“气管”因为在生活领域是一种工具而被错误识别。为了在利用词语信息的同时减少未登录词造成的错误,本文在Lattice-LSTM模型[4]基础上引入新词发现进行医疗命名实体的识别。Lattice-LSTM能够将输入的字符以及所有能在词典匹配的单词一起编码输入到模型中,选择出最相关的字符和单词,降低歧义发生的概率,从而提升识别的准确率。为此,本文构建了一个医疗相关的词典。在构建医疗词典的过程中,使用N-grams算法从大量的医疗对话语料中获取新词,帮助分词算法进行分词。然后根据分词后的结果使用Word2Vec构建一个医疗的词典。本文模型将潜在的多种的单词信息作为特征,构建Lattice-LSTM模型来对这些单词进行建模。如图1所示,利用构建的词表来构建网格结构。图示的句子包含多种粒度的单词信息,如果使用门结构,可以动态地控制不同路径的信息流,从而为模型提供更多的引导,选择最相关的字和单词。与基于字符的方法相比,本文模型加入潜在的多种粒度的单词信息作为特征,更好地提高了识别的性能。
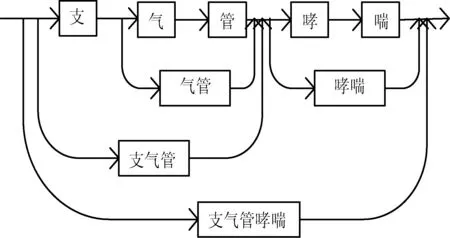
图1 词表的网格结构
1 相关工作
目前,常用中文分词方法主要分为基于词典的方法[5]、基于传统机器学习的方法[6]、基于深度学习的方法[7]。由于基于词典的方法简单高效,在一些实际应用中常常使用,主要以词典为主,结合少量的词法、语法规则和语义解析。随着时代的进步,一些新词不断涌现,词典的规模也相应扩大,还会面临存在未登录词的问题。所以,越来越多的学者研究如何发现新词去扩充词典。
在新词发现上,现在常用的方法大致有三种思路。第一种是基于构词法[8],它需要理解特定语言语法规则;第二种是基于统计模型的方法[9-10],它是基于对字符排列的统计分析和基于词排列的统计分析;第三种是将语言规则和统计模型的方法结合起来的方法[11]。传统命名实体识别的方法大致分为三种。(1) 基于规则的命名实体识别的方法,大多需要专家手工构造的规则模板或词典,例如:Hanisch等[12]提出了ProMiner,它利用预处理的同义词字典来识别文本中的蛋白质和潜在基因;Quimbaya等[13]提出一种基于字典的电子健康命名实体识别方法。(2) 无监督学习的典型方法是聚类[14],这是一种基于上下文相似性的方法,例如:Nadeau等[15]提出了一种用于地名词典建立和命名实体消歧的无监督系统;Zhang等[16]提出了一种从生物医学文本中提取命名实体的无监督方法。(3) 在有监督的学习方法中,命名实体识别被转换为多分类或者序列标记任务,最大熵[17]和条件随机场[18]等模型被用来解决序列标注任务。
当前,基于深度学习的命名实体识别模型成为主流。例如:Hammerton[19]第一次尝试使用单向的LSTM去解决这个问题;Collobert等[20]使用CNN-CRF结构在通用命名识别领域取得了比较好的效果;Huang等[21]构造了采用手工拼写特征的BiLSTM-CRF模型,大大提高了识别的效率;Chiu等[22]使用BiLSTM-CNN的模型,使用双向LSTM和CNN混合结构自动获取字符和单词的特征,进一步提高命名实体识别的性能。
2 实体识别模型
本文研究提出的命名实体识别方法分为两步。首先,使用N-grams算法从医疗对话语料中寻找新词后构建一个医疗的外部词典。然后,在基于字的LSTM-CRF的基础上结合词典中潜在的多种单词信息作为特征,构建Lattice-LSTM模型。
2.1 基于N-grams模型的新词发现法
N-grams新词发现法主要利用词语频数和凝固度两个指标。其中:频数指词语在数据中出现的次数;凝固度指词语片段间的紧密程度,常常用互信息来衡量。提取的新词就是满足词语频数和凝固度阈值要求的单词。
本文考虑到文本中多个字的内部凝固度,即使用N-grams对句子进行切分,然后计算其内部凝固度。其中,三个字的凝固度为:
(1)
式中:a、b、c是相邻的三个字;p(a)、p(b)、p(c)代表各自出现的频率;p(ab)、p(bc)、p(abc)代表组合成词语后出现的频率。取组合中凝固度最小的那个为整个字组合的凝固度。
算法步骤如下:
步骤1本文中设n为4字即4grams对句子进行切分。统计2grams、3grams、4grams,计算它们的内部凝固度,并设置不同的阈值,在本文中阈值设置为5的倍数。当n为2时,阈值设置为5;当n为3时,阈值设置为25;当n为4时,阈值设置为125。保留高于阈值的片段,构成一个集合M。
步骤2用上面的grams对语料进行粗切分,并统计频率。切分的规则是,只要有一个片段在集合M中,该片段就不再切分。以片段“各项目”为例,只要“各项”和“项目”都在集合M中,即使“各项目”不在集合M中,片段“各项目”依然不会被切分。
步骤3在类似于片段“各项目”的单词被切分出来之后,再判断其是否在对应的grams中。如果存在则保留,否则予以删除。N-grams的优点是在互信息较大的情况下,不会切错词,同时排除比较模糊的词。
使用上面的方法进行实验,将提取的新词与结巴内置词典进行对比筛选。然后,将筛选之后剩下的新词进行人工筛选,进而最终确定发现的新词。
2.2 Lattice-LSTM
基本的循环神经网络(RNN)由于梯度消失的原因不能很好地学习到长距离依赖关系。为此,长短期网络(LSTM)在RNN的基础上引入记忆单元来记录状态信息,通过输入门、遗忘门和输出门这三个门结构去更新隐藏状态和记忆单元。
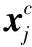
(2)
式中:ec表示字向量映射表。LSTM模型中计算式包括:
(3)
(4)
(5)
(6)
(7)
(8)
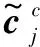
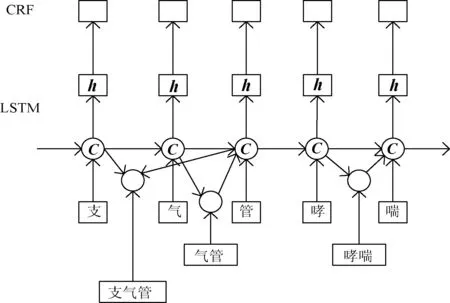
图2 Lattice-LSTM模型
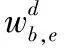
(9)
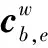
(10)
(11)
(12)
(13)
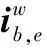
(14)
(15)
(16)
(17)
2.3 CRF层
在h1,h2,…,hn上使用CFR层,最后得到标签序列的概率为:
(18)
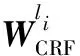
3 实 验
3.1 数据集
在中文医疗命名实体识别的任务中,实验所用的数据来自医疗网站上的医生和患者的对话数据。数据由具有临床经验的医生进行标注,语料整体标注质量较高,其中数据中的实体采用BIO的标注方式。对话数据中一共标注了5种实体类型,包括疾病名称、药品名称、临床表现、治疗方法和检测方法,不同类型的具体数目如表1所示。其中训练数据1 201 KB,验证数据325 KB,测试数据322 KB。

表1 实体的类型及其数目 KB
3.2 评测指标
本文中文命名实体识别任务采用F1值来进行评测。输出的结果集合为S={s1,s2,…,sm},人工标注的结果集合为G={g1,g2,…,gn}。定义si∈S与gi∈G等价,当且仅当:
max(si·posb,gi·posb)≤min(sipose,gj·pose)
(19)
si·c=gic
(20)
式中:posb和pose分别代表实体在句子中开始位置和结束位置;c代表实体类型。式(19)表示预测集和输出集的某个实体在位置上有交集。
基于以上等价关系,定义集合S和G的松弛交集∩,因此得到评价指标F1:
(21)
(22)
(23)
式中:P表示准确率,是预测正确的结果占所有预测结果的比例;R表示召回率,是预测正确的结果占所有数据的比例。
3.3 超参数设置
在神经网络模型中超参数的选择对模型有着很大的影响。本文模型的超参数设置如表2所示。LSTM是模型层数为1、隐藏层维度为200的网络结构。在字向量和单词向量使用Dropout,并且Dropout比率设置为50%。使用SGD(随机梯度下降法)对模型进行优化:
lr=init_lr×((1-decay_rate)×epoch)
(24)
式中:epoch代表使用训练集的全部数据对模型进行的训练次数;init_lr为初始学习率,设置为0.015;decay_rate为衰减率,设置为0.05。
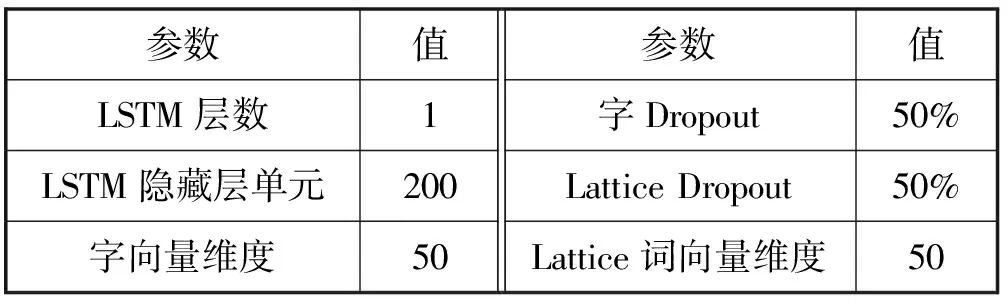
表2 超参数设置
3.4 实验结果及分析
经过N-grams新词发现算法提取到部分新词包括:布地奈德、舒利迭、小细胞肺癌、未见、保守治疗、倍他乐克、二甲双胍、肺动脉高压、希望医生、可能是。
在新词发现的结果中,出现了一些像“未见”“希望医生”“可能是”不是医疗实体的错误词语,这些词语由于凝固度较高从而产生了较高的互信息被抽取出来。很多专业的术语都被正确地提取出来,如“布地奈德”“二甲双胍”“小细胞肺癌”等医疗专业名称。但是,一些出现次数比较少的专业单词不能做到很好的发现,如“孟鲁司特钠片”“硫酸沙丁胺醇口腔崩解片”“脾氨肽口服液”等。因此,通过扩大语料规模或者采集更多相对应症状的医疗对话来提高新词发现的数量。
表3给出了本文基于N-grams新词发现的Lattice-LSTM的多粒度命名实体识别模型在医疗对话数据集上的实验结果,并且同中文命名实体识别常用的基于字符的CRF、LSTM-CRF和BILSTM-CRF模型的实验结果进行了对比。与传统方法相比,本文基于N-grams新词发现的Lattice-LSTM算法的F1值得到很大的提升,相对于没有进行过新词发现的Lattice-LSTM算法F1值也从89.73%提高到90.95%。
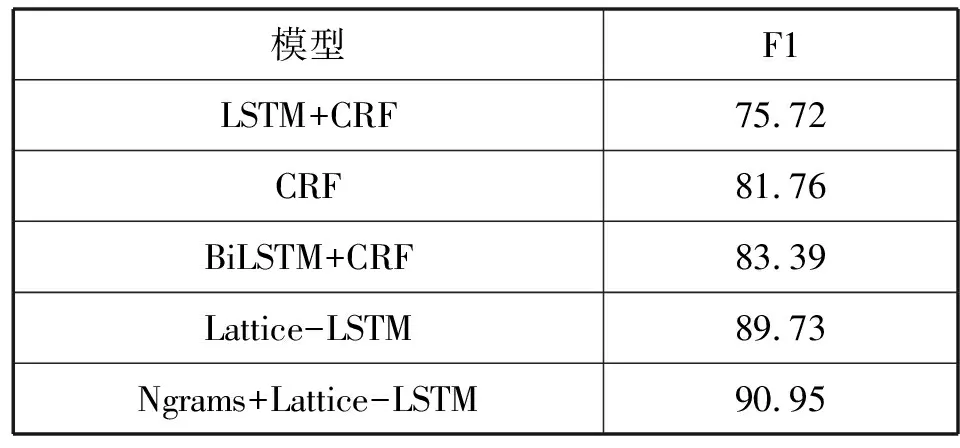
表3 实验结果对比 %
通过对实验结果的对比分析,本文基于N-grams新词发现的Lattice-LSTM的命名实体识别模型在医疗命名实体上有很好的效果。由于实验所用医疗对话语料针对的疾病类型主要是高血压、肺病,涉及疾病类型不全面,所以提取到的新词数量不多,但相对于没有经过新词发现的Lattice-LSTM算法有了一定的提升。由于评测指标中采用交集的计算方式,在CRF模型上出现了较多的一个目标标签对应多个正确的标签,从而F1值相对于LSTM+CRF有一定的提高。本文提出的命名实体识别模型充分利用了经过新词发现法构建的词典里的多种粒度的单词信息,对命名实体识别任务效果的提高起到了一定的帮助作用。
4 结 语
本文针对医疗的命名实体识别任务,提出一种基于新词发现和Lattice-LSTM的多粒度的命名实体识别模型。通过N-grams算法去发现新词,从而构建一个有针对性的词典,然后使用Lattice-LSTM模型选择了词典中最优的字符和单词,从而取得了更好的结果。但是在新词发现的过程中,一些不是医疗实体的错误单词由于凝固度较高也被识别出来,给后期新词筛选工作增加了负担。接下来我们会探索更有效的新词发现方法,应用在基于Lattice-LSTM命名实体模型中。
猜你喜欢
中学生天地(B版)(2022年4期)2022-05-17
现代计算机(2021年33期)2022-01-21
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
周末·校园文学(2017年35期)2018-02-06
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
中关村(2014年5期)2014-05-15
疯狂英语·原声版(2013年6期)2013-07-16
