
基于Hadoop的高校学生行为预警决策系统研究
2021-01-15 08:21葛苏慧白成杰
计算机应用与软件 2021年1期
葛苏慧 万 泉 白成杰
1(青岛工学院信息工程学院 山东 青岛 266300) 2(山东师范大学信息科学与工程学院 山东 济南 250358)
0 引 言
大数据带来的信息风暴正在改变着人们的日常生活、工作模式和思维方式,但目前很多高校教育管理手段存在诸多弊端,管理方式大多停留在宣传教育、定期检查阶段,管理模式多数是事后分析,管理手段既落后又被动,很难适应大数据时代智慧校园智能管控的要求。学业危机、安全危机、心理危机、就业危机、舆情危机等成为高校学生管理亟须解决的问题。因此,大数据背景下,要求高校管理者转变思维,运用大数据分析技术,开展多维、动态、全面、智能的教育管理新模式,建立动态的预警决策机制,主动掌握学生生活、学习、行为规律,对不良思想行为做到事先警示教育、事后跟踪管理,从而实现个性化的管理新模式,探索实效性的管理新路径。
本文主要利用Hadoop大数据框架及HDFS、Map-Reduce、Spark、Kafka、Flume大数据技术研发智慧校园预警决策系统,使用Kafka、Flume进行日志采集,HDFS为海量学生校内轨迹数据提供存储,MapReduce提供并行运算,从而提供动态的学生校内行为轨迹地图和查询功能。利用基于距离的聚类方法,对经过降维后的学生特征数据进行分类,分离出偏离中心点的状态异常的学生;使用Echart、D3.js可视化呈现,采用SaaS形式交付,生成“学生画像”对学生行为进行监控、预警、根源分析的闭环管理,并通过网页版和手机版html5技术以微信、短信的方式主动推送预警,实现异常事件的闭环管理,为智慧校园的学生行为管理提供智能的手段,实现一种全新的智能管控新思路。
1 Hadoop大数据技术
Hadoop是一个开源的海量数据处理框架,最核心的设计是HDFS和MapReduce,HDFS为海量数据提供存储和管理功能,处理非结构化的数据,MapReduce自动实现分布式并行计算,二者的巧妙结合使Hadoop拥有了高效的存储和计算能力[1]。Hadoop可利用集群实现对海量数据的高效专业化处理,是一个对大规模数据存储、计算、分析、挖掘的软件平台,具有低成本、高效率等优点,能可靠地存储和处理PB级的数据[2-3]。
本文利用Hadoop框架的分布式文件系统HDFS和MapReduce对智慧校园多维学生轨迹数据进行数据清洗、建模、计算、分析与可视化呈现,HDFS负责学生多维校内行为轨迹的存储和管理[4],MapReduce负责对大规模数据集的并行处理。Hadoop能将一台机器的计算能力无限次、高速地复制到集群机上,使集群具有超强的计算能力,不断扩充处理速度与运算能力[5-7]。
2 预警决策系统整体结构
基于Hadoop的高校学生行为预警决策系统分为权限管理、安全认证、技术支撑四层模型、预警决策可视化呈现[8-9]四大部分。其中技术支撑四层模型分为数据采集层、运行数据层、核心能力层、场景应用层。数据采集层对学生的历史数据、点击流、实时日志等数据市场的数据进行采集;运行数据层利用Hadoop集群、云存储、云数据库等对多维数据进行计算;核心能力层是对计算之后的数据进行清洗、建模、分析,实现即时查询;场景应用层对数据进行可视化呈现[10-11]。权限管理分用户管理、角色管理、用户组管理、文件管理。安全认证可以分为iPaas、Ldap和Kerberos三类。预警决策系统可实现校园足迹、行为轨迹实时监测、预警反馈、预警信息主动推送,并利用Echart、D3.js可视化呈现,采用SaaS形式交付。该预警决策系统整体结构如图1所示。
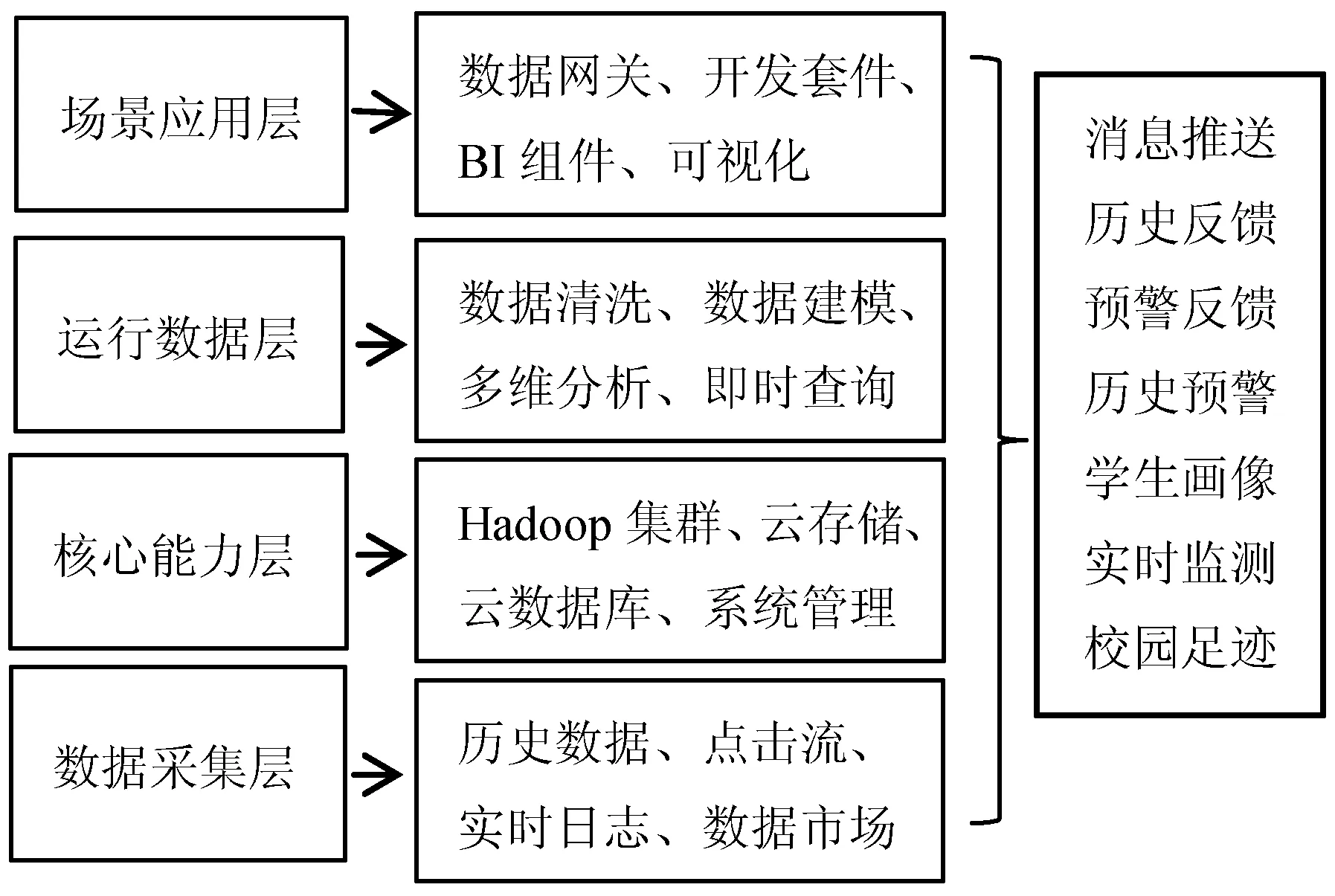
图1 预警决策系统整体结构图
2.1 数据采集清洗
通过高校智慧校园中的校园信息化基础设施以及物联网、智能感知、云计算等技术,利用Kafka、Flume大数据采集工具,收集学生的静态和动态特征属性,静态属性包括姓名、性别、专业、年级、宿舍、年龄、籍贯、爱好等特征;动态属性包括课堂考勤信息、线上线下学习情况、图书馆借阅情况、宿舍回归率、门禁系统、校园一卡通、餐厅就餐情况、校内上网情况、洗澡频率等数据。通过大数据采集工具实现海量学生校内轨迹数据的抓取与存储,将多维的学生活动状态数据进行集成分类存储,生成学生在校画像属性值。把轨迹数据的属性值进行分类,将当前时刻数据属性值的样本,合并上一个周期采集到的并且已经处理完毕的数据属性值的样本进行清洗,采用曼哈顿函数计算目标区域为半径之外的数据距离本域中心点的偏离距离。然后计算某个属性的异常度,通过排序设定一定的阈值,将所有离群点的偏离程度进行比对,判断该点与本域中心点之间的偏离距离,计算每个属性值的异常情况[12-15]。步骤如下:
依据n个数据的属性值,设每个属性值的数据为m维,S(t0)为这次数据属性值的样本,不同时刻tk(tk∈[T,t0])采集到的数据属性值的样本为S(tk),因为校内轨迹数据的时序性,需要把当前时刻属性值的样本用式(1)合并上一周期已处理完的“干净”数据进行清洗。
(1)
式中:Sc(t-1)表示t-1时刻清洗完毕的轨迹数据;r(Sc(t-1))表示对t-1时刻数据采集的结果;S+(t0)表示当前时刻与上一周期合并之后待处理的数据集,为了防止较高密度簇影响异常数据的分离需要将冗余删除。
设s为轨迹数据属性值集合S+(t0)中的点,区域半径RAD(s)表示分析目标距离中心点为第k远的对象的曼哈顿长度:
d(i,j)=∑|Xik-Xjk|
(2)
式中:Xik和Xjk表示第k远对象的坐标值。
把点s作为本域的中心,该区域包含k个对象,这些对象的集合为Nk(s)。由此可以得出结论,分布不均匀的、密度较大的区域RAD(s)较小,反之密度较小的区域RAD(s)则较大。
定义点s与点p之间的距离:
REA(s,p)=max{RAD(Pp),d(s,p)}
(3)
利用式(3)可以求出轨迹数据集合S+(t0)内的第i个属性值的异常度LOF(si),对其排序,然后设置最大的阈值,从而分离出偏离中心点的异常数据。
(4)
式中:Lnr(p)和Lnr(s)分别为点p和点s的阈值长度。
(5)
式中:Lrdk(s)为Nk(p)轨迹数据集合中平均可达距离密度的倒数。
由式(3)、式(4)、式(5)可知,如果点s偏离中心点的距离较小,那么对于同一属性的轨迹数据的可达距离RAD(s)则较大,并且分布较为均匀;反之如果点s是偏离中心距离较远的异常点,那么可达密度的方差就较大,证明该点距离所有簇都相对较远,通过设置阈值计算偏离中心点的异常数据。
2.2 聚类分析
利用Hadoop框架的HDFS、MapReduce技术,采用分布式文件系统和并行计算,将学生的静态和动态特征属性贴上标签,生成协方差特征矩阵的特征值及特征向量,使用主成分分析法进行降维处理,提取关键特征值,利用基于距离的方法进行聚类分析,将多维数据进行归一化处理。把严重偏离中心点的学生特征异常信息提取出来,从而分离出学生的异常状态,对异常行为作出科学的预测和研判。
主成分分析法利用降维的思想,使用线性变换的方法,将给定的一组相关变量转换成另一组不相关的变量,转换之后的新的变量按照方差依次递减的顺序排列,在数学变换中保持变量的总方差不变[16-18]。利用主成分分析法,首先计算学生样本属性的协方差矩阵,再求出协方差矩阵的特征向量,根据这些特征向量生成变换矩阵的行向量,最后依据数据协方差矩阵的特征向量构成新的坐标系的基矢量。根据学生不同属性向量的特征可以得到如下结论。样本集在较大特征值对应的特征向量上的投影方差较大,所以该分量对于区分样本的贡献就较大[19-20]。由此可见,通过主成分分析法可以清晰地找出区分性大的维和区分性不大的维。主成分分析法的具体实现步骤如下:
(1) 将n个学生,每个学生的m个特性属性数据,构成n行m列的在校画像矩阵S:
(6)
如果用j来表示学生画像的某一项属性,那么所有学生的这一项属性xj可表示为:
(7)
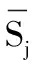
(8)
(3) 将学生画像属性矩阵S进行计算,得出协方差矩阵R:
(9)
为了使统计分析的结果达到更好的处理效果,需要对学生特征属性的多维数据进行归一化处理,把经过数据清洗、处理之后的特征矩阵代替原来的矩阵S,式(10)可以计算特征矩阵S的有关系数。
(10)
(4) 特征值表示为λ,协方差矩阵R的特征值λi=(λi1,λi2,…,λim),特征向量ɑi=(ɑi1,ɑi2,…,ɑim),贡献率w由式(11)计算,特征值λi的贡献率为w。
(11)
(5) 从标准化处理之后的学生的特征属性数据中选择主成分,按照贡献率w将学生的特征属性值由高到低降序排列,根据统计的实际需要提取属性的前若干行,从而形成降维后的学生特征矩阵S。
(6) 采用KHM(K-HarmonicMeans)算法对特征矩阵S进行聚类分析,如图2所示,该算法根据式(12)最终计算出每个学生的特征属性数据到各聚类中心的调和平均值的和。
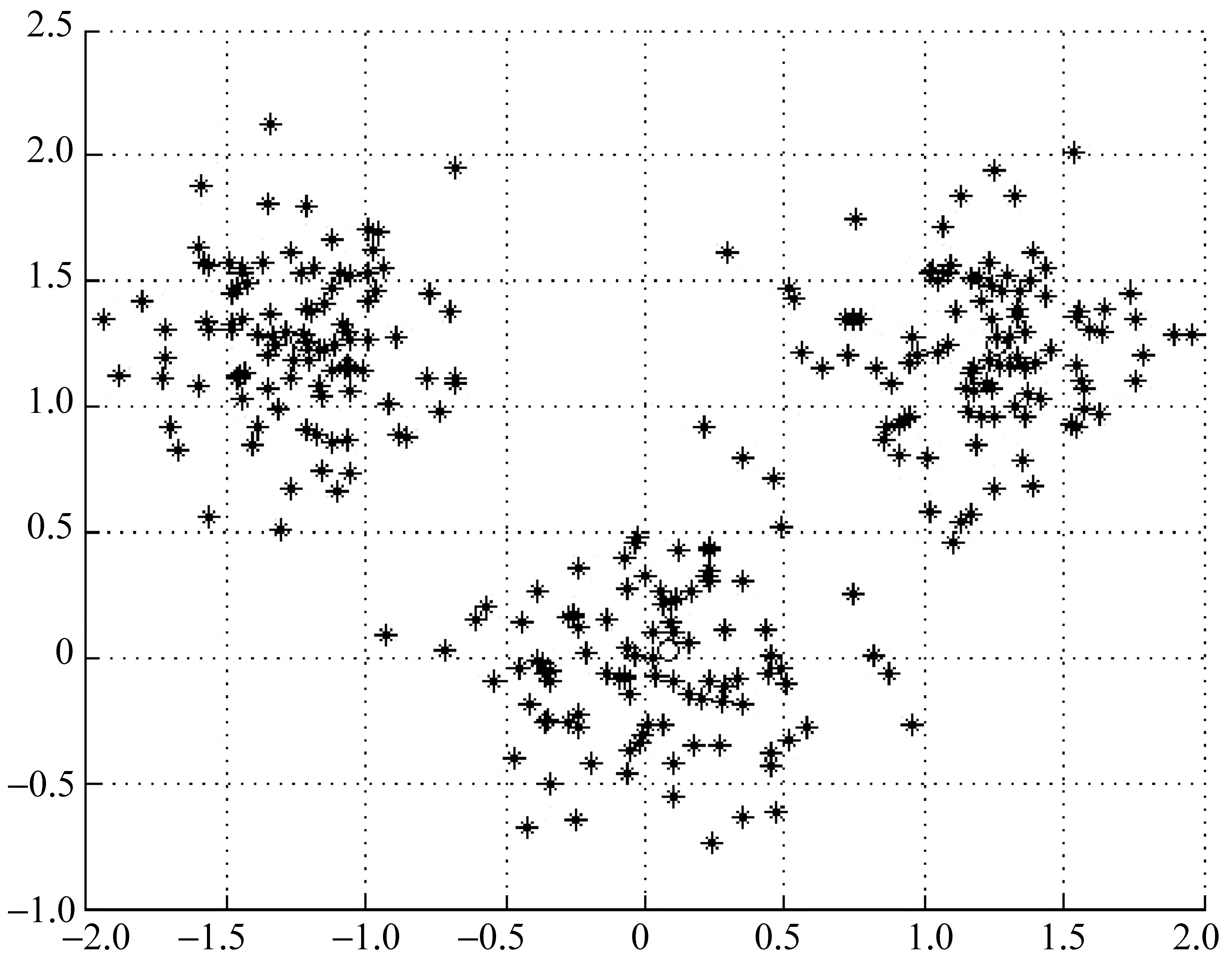
图2 学业成绩分析
(12)
式中:第i个学生的m个特征表示为Si={Si1,Si2,…,Sim},第l个聚类中心表示为Cl=[Cl1,Cl2,…,Clm],第i个学生到中心点l的距离为d(Si,Cl)。利用初始值通过公式不断迭代,最终使得各类趋于稳定,从而分离出状态异常的学生[21]。
2.3 预警决策
最终该预警决策系统使用Echart、D3.js可视化输出,采用SaaS形式交付,生成学生在校画像,并提供学生校内行为轨迹和查询功能。学校管理人员可以实时感知学生生活、学习及活动状态,从而动态监测学生异常,对于可能会发生的异常问题或已经出现危机前兆的问题,通过网页版和手机版html5技术以微信、短信的方式主动推送预警,实现学生异常事件的闭环管理,对异常事件真正做到可查、可管、可追溯。
3 算例分析
实验在真实环境下进行,采用基于Hadoop框架搭建的HDFS、MapReduce技术,HDFS提供存储和管理,MapReduce实现分布式计算。集群相关配置情况如表1所示。
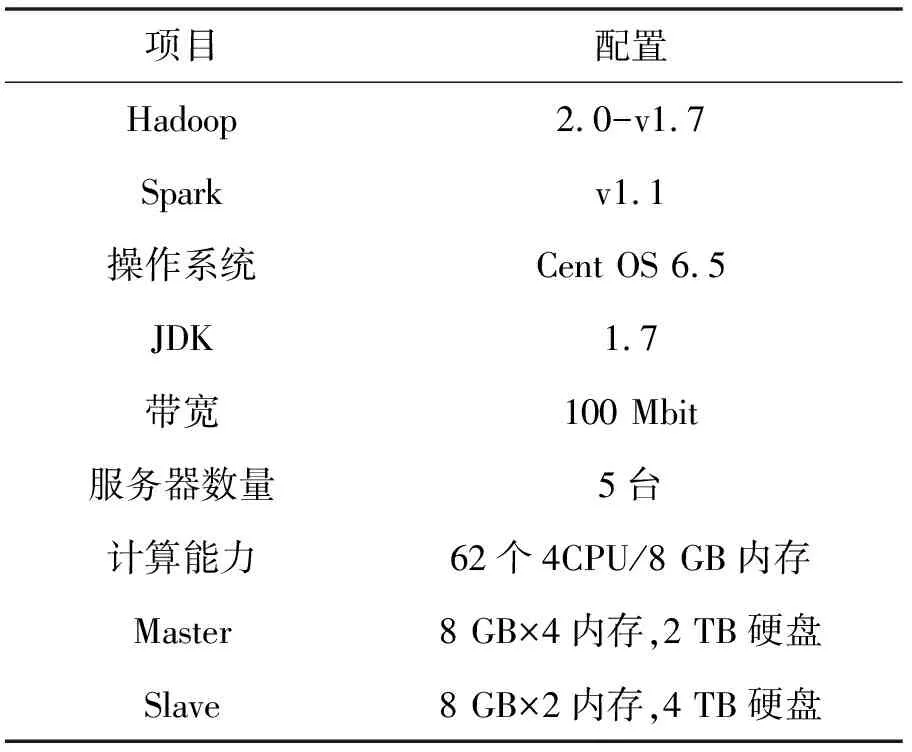
表1 集群配置参数
3.1 轨迹数据分析
为验证Hadoop架构和MapReduce算法的性能,实验样本集为某高校数据采集系统10个月的学生校内轨迹数据,学生轨迹数据每天采集量为120个点,将原数据集横向表示为10个不同大小的样本集[22]。前 5 个轨迹数据样本的差异性较小,在处理少量文件时Hadoop无法体现它的优势,但当样本集数据量日志增大时,Hadoop便能对大规模的学生轨迹数据集进行分布式并行处理,清洗速度与清洗量近似正相关[23]。算例中采集了学生10个月的校内轨迹数据,最大样本集中有5万个监测点,100万条数据,数据清洗时间大约为10 s,其速度和处理能力完全满足目前乃至今后一段时间内的校内轨迹数据采集量的要求。
图3所示是某天15 870个轨迹数据采集点的日清洗情况,其中折线为平均斜率,表示平均变化趋势。因为校内轨迹数据采集所需的时间与学生异常数据的规模无关,且Hadoop能够处理大规模的非结构化数据,并将原数据分类进行差异化处理、添加时间戳,所以数据的质量不会影响轨迹数据的清洗效率。为验证算法的高效性,在样本数据的24个时间段中随机生成大规模异常数据。通过实验验证得出,Hadoop具有强大的快速处理能力,10万条数据的清洗时间大约是5 636~6 340 ms,而且不同规模的异常数据量的清洗时间变化较为稳定。
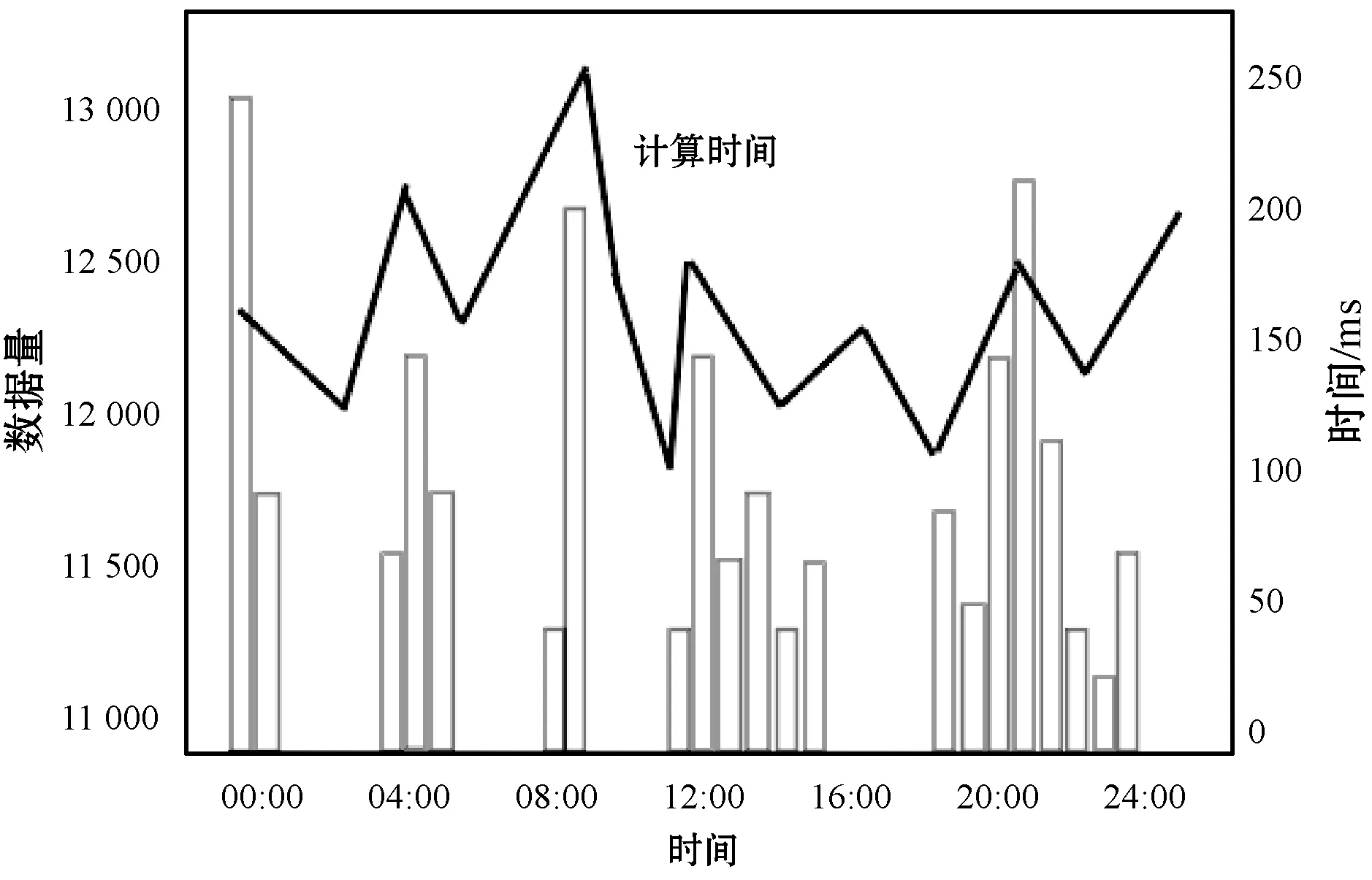
图3 轨迹数据日清洗状况
通过此预警决策系统对全校30多个专业,10 000多名学生进行了校内活动轨迹数据的采集、清洗、处理和聚类分析,读取历史数据,形成时间节点的数据集合,并合并上一次采集周期的数据进行清洗,设置目标区域半径。通过曼哈顿长度计算异常数据距离中心点的离群程度,利用主成分分析法进行降维处理,生成学生静态和动态属性的特征矩阵,使用基于距离的方法进行聚类分析,并通过此预警决策系统最终可视化呈现,将严重偏离中心点的学生异常提取出来。图4为学生校内轨迹数据聚类图,通过采集10个月期间的大规模学生校内轨迹数据,进行清洗以及聚类分析,然后将此预警决策系统测试的结果与学生的实际状态进行比对,得出的结论如表2所示。可以看出此预警决策系统分析的结果与这些学生在校内的实际状态基本一致,数据预测成功率接近95%,误差率可以控制在6.5%之内。

图4 校内轨迹数据聚类图
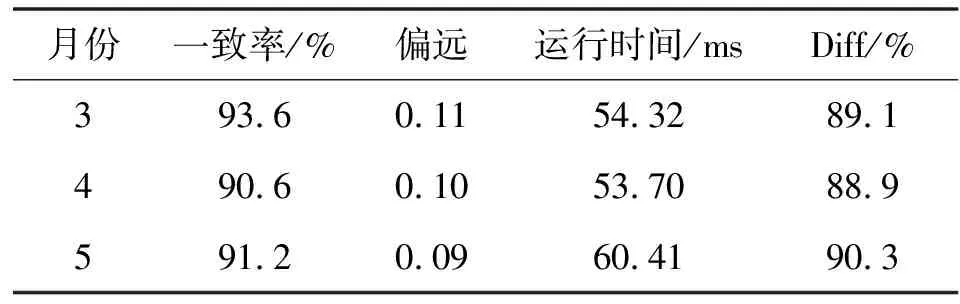
表2 系统预警与实际状态结果比对

续表2
3.2 学生画像规则
学生画像标签分为内容和权重。标签是可变的,权重也是实时变化的,随时间延长而衰减。以学生成绩记录为例:张三,数学成绩90,为学生打上某一学科成绩的标签。通过编写学生画像规则,来计算标签权重,基本权重=90/100=0.9。时间衰减因子为R,随着时间D(天数)的延长,R会线性减少,R=1-0.05×D。标签权重=基本权重×衰减因子。 由此计算出张三的数学成绩标签权重为0.9,标签内容为科目名称“数学”,因此该学生的一个标签为:数学,0.9。一周之后如果衰减因子变为0.7,标签权重变为0.63,那么该生的标签为:数学,0.63。当标签权重不断减小到某个值,如0.5时,就要为该生“撕下”数学的标签,从而更好地体现标签的实时性,因此将0.5记为阈值。再使用Hive规则生成学生标签,存入标签库,表3为学生画像表(User_Profile)。

表3 学生画像表
HiveQL标签生成语句:
insert into table User_Profile select g. School_ID ,g.Student_ID,g.Student_Name,001,“数学”,0.9,2016-12-01 from Grade g where Subject=“数学”。
不是异常学生的概率为:
P(A2|B1)=1-P(A2|B1)=1-0.15=0.85
(13)
如果所具有的一项信息不是B1,而是B2、B3、B4,则是否是异常的概率分别为:
P(A1|B2)=0.13P(A2|B2)=0.87P(A1|B3)=0.11P(A2|B3)=0.89P(A1|B4)=0.16P(A2|B4)=0.84
(14)
再计算同时有2、3、4项特征的学生是异常状态的概率,如表4所示。例如,同时有B1、B2两项与B1、B2、B3三项的学生是异常的概率分别为:
P(A1|B1B2)=
(15)
P(A1|B1B2B3)=
(16)

表4 具有各种异常特征的概率
4 结 语
本文提出了基于Hadoop的智慧校园预警决策系统。通过智慧校园中各种智能终端、可感知设备,动态获取学生海量活动轨迹与状态数据,利用Hadoop大数据技术对多维数据进行关联、分类、降维及聚类分析,生成“学生画像”,实时监测学生状态,科学研判异常行为,实现对异常事件监控、预警、根源分析的闭环管理,预警信息主动推送,开创智慧校园管理决策的新途径。该系统为高校智慧校园学生管理的决策科学化、监督过程化提供智能参考的依据,开创高校教育管理的新模式。同时该系统可在其他高校中逐步推广,让高校的智慧校园建设迈上一个崭新的台阶,对高校的教学管理和人才培养具有重要的实际应用价值。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
电脑报(2020年12期)2020-06-30
电脑报(2019年4期)2019-09-10
新课程·小学(2019年1期)2019-03-18
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
