
融合卷积神经网络与VLAD的闭环检测方法
2021-01-15 08:29阮晓钢朱晓庆
计算机应用与软件 2021年1期
李 昂 阮晓钢,2 黄 静,2* 朱晓庆,2
1(北京工业大学信息学部 北京 100124) 2(计算智能与智能系统北京市重点实验室 北京 100124)
0 引 言
目前,闭环检测已经成为了移动机器人导航领域的关键问题和研究热点,是视觉同时定位与地图构建(SLAM)的重要环节。视觉SLAM主要由视觉里程计、后端图优化、闭环检测和建图四个部分组成[1]。其中闭环检测也称为位置识别,指机器人在导航过程中使用视觉传感器提供的图像来识别是否经过了先前到达的位置[2]。假设在当前时刻和较早时刻相机捕获了两幅图像,那么闭合检测的任务就是根据这两幅图像的相似性来判断这两个时刻的位置是否相同。正确的闭环检测可以为后端优化的姿态图中增加边缘约束,进一步优化机器人的运动估计,消除视觉里程计产生的累计位姿误差,而错误的闭环检测会导致地图绘制失败。因此,一个好的闭环检测算法对于构建全局一致性地图乃至整个SLAM系统都至关重要。
近年来,学者们在闭环检测方面做了大量的研究。经典的闭环检测算法大致可以分为两类:词袋模型(BoW)算法[2]和全局描述子算法。BoW从图像中提取局部特征,然后聚类形成不同的单词,最终用单词向量的形式来描述图像,将闭环检测转化成了图像单词向量的相似性度量问题。词袋模型算法的关键在于如何选择最优的局部特征,目前多采用传统的SIFT[3]、SURF[4]和ORB[5]等特征作为图像的表达。而全局描述子算法的主要思想是直接计算整幅图像的描述子,从而表达图像的整体属性。GIST是一种非常有效的常规图像描述子,它能够以紧凑的方式去捕捉不同类型场景的基本结构。在此基础上,Liu等[6]使用GIST提取图像的全局特征,并采用PCA对描述子进行降维,提高了闭环检测的计算效率和图像描述子的识别能力。但以上两种方法各有优缺点。Furgale等[7]证明了BoW相较于全局描述子能更好地应对相机视角变化,而Milfold等[8]和Naseer等[9]提出全局描述子方法在光照变化的情况下更鲁棒。McManus等[10]将这两种方法结合起来,提出了一种使用场景标签的无监督系统,该系统可以为不同的视觉元素产生广域检测器,提高了闭环检测的准确性。然而,这些方法所使用的都是低层特征,是人为设计的,它们对光照、天气等因素的影响很敏感,缺乏必要的鲁棒性。
随着大规模数据集的公开(如Imagenet)以及各种硬件的升级(如GPU),深度学习[11-12]得到了迅速发展。深度学习能够通过多层神经网络对输入的图像提取抽象的高层特征,从而更好地应对环境的变化[13],这种优势使其在图像分类和图像检索中得到了广泛应用。考虑到闭环检测问题与图像检索十分相似,学者们开始尝试将深度学习应用于闭环检测。Gao等[14]利用自编码器提取图像特征并采用相似性度量矩阵对闭环进行检测,但忽略了图像的空间特性。何元烈等[15]设计了一种快速、精简的卷积神经网络(FLCNN),在保证闭环检测准确率的情况下提高了算法的计算效率。Xia等[16]利用PCANet对图像进行特征提取,证明了该网络提取的特征优于传统的手工设计特征,但限制了输入图像的尺寸。Hou等[17]利用PlaceCNN进行闭环检测,该方法即使在光照变化时也具有较高的检测精度,但算法运算时间较长。
为了进一步提高闭环检测算法的准确率和鲁棒性,本文采用了融合VGG16与VLAD的网络结构VGG-NetVLAD。该网络采用了基于VLAD[18]思想的NetVLAD池化层,充分考虑了图像的局部空间特性,以提高闭环检测的准确性和鲁棒性。不同于典型的CNN,VGG-NetVLAD训练数据的标签仅为各自的地理位置,能够进行弱监督学习。
1 融合VGG16与VLAD的网络模型
1.1 传统VLAD的编码方法
局部聚合描述符向量(VLAD)是一种常用于实例检索和图像分类的描述子池化方法,可以捕获局部特征在图像中聚合的统计信息。词袋模型保存了图像中不同种类单词的数量信息,而VLAD储存的是每个单词与对应聚类中心的残差和。
假设VLAD算法的输入为单幅图像的N个D维特征向量xi,参数为K个聚类中心ck,则VLAD会输出一个K×D维的图像特征向量,将其写成矩阵的形式,并记作V,计算公式如下:
(1)
式中:xi(j)和ck(j)分别代表第i个特征向量和第k个聚类中心的第j个元素;ak(xi)表示第i个特征向量对应第k个聚类中心的权重,当该特征属于这个聚类中心时,权重为1,否则为0。由此看出,矩阵V的第k个D维列向量代表所有特征向量对应第k个聚类中心的残差和(xi-ck)。因此,VLAD方法提取的图像特征表达了聚类中心周围的特征分布,包含了一定的语义信息。
1.2 可训练的VLAD编码模型NetVLAD
在VLAD中权重ak(xi)只有两种取值,并且特征向量在不同聚类中心的权重之和为1,是一个离散函数,所以无法通过反向传播进行训练。为了将VLAD的思想引入到CNN,本文采用了Arandjelovic等[19]提出的NetVLAD池化层。它采用了一种近似的方式,将ak(xi)软分配到多个聚类中心,使其可微:
(2)
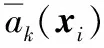
将式(2)中的平方项展开,分子分母同时约掉e-α‖xi‖2,得到如下的软分配(soft-assignment)形式:
(3)
式中:wk′=2αck;bk=-α‖ck‖2,将式(3)代入式(1)最终得到NetVLAD层输出的特征向量:
(4)
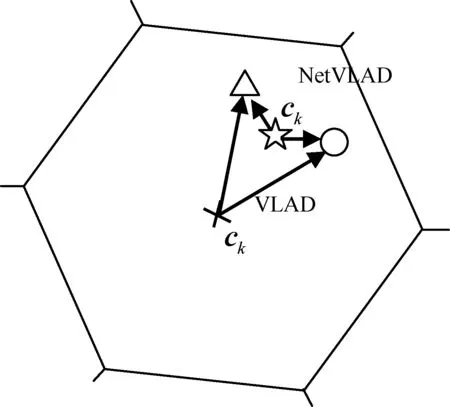
图1 NetVLAD相对于VLAD的自适应性
图1中圆圈和三角形分别代表两个不同图像的特征描述符,被分配到同一个集群,聚类中心为ck。当采用余弦距离计算图像相似度时,在VLAD编码下,由于VLAD的特征向量进行了L2归一化,所以相似性得分等价于两幅图像残差向量(xi-ck)的点积,聚类中心ck位于“×”处是为了均匀分布所有的残差。而在NetVLAD编码下,如果两幅图像并不相似,它会学习到一个更优的聚类中心“☆”,使得残差向量间的点积更小,从而得到更加准确的相似度。
1.3 融合NetVLAD层的卷积神经网络设计
为了使卷积神经网络提取到的图像特征更适用于闭环检测,本文对VGG16网络进行了裁剪,去掉了最后一个卷积层(conv5_3)之后的池化层和全连接层,包括ReLU激活函数,并将NetVLAD层连接到卷积层conv5_3之后,作为新的池化层。将图像输入到VGG-NetVLAD网络中,提取Layer_5层的特征作为池化层NetVLAD的输入。网络结构如图2所示。
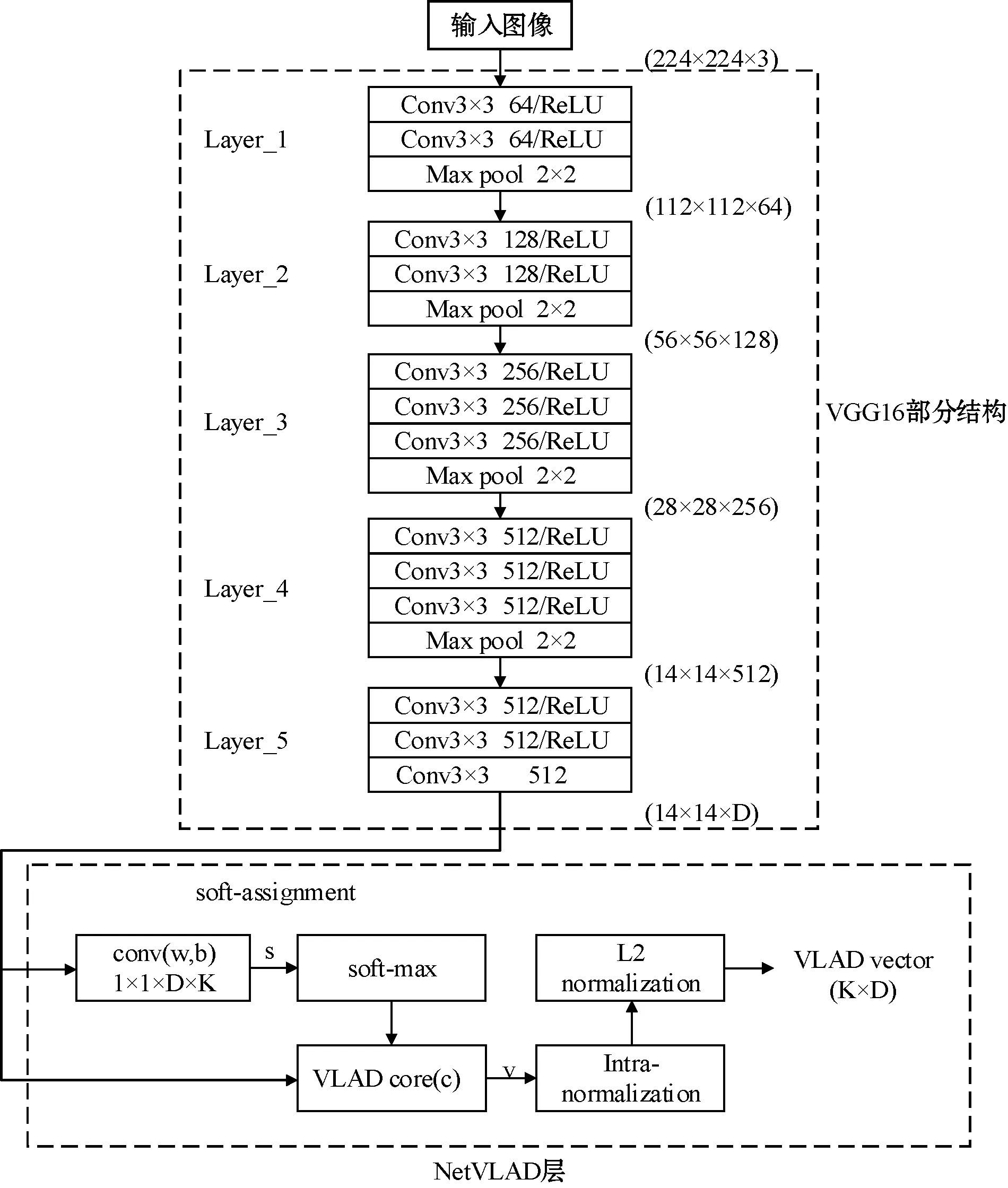
图2 融合VGG16与VLAD的网络模型
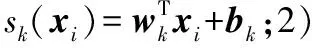
1.4 VGG-NetVLAD的训练
为了获得VGG-NetVLAD的最优参数,便于进行闭环检测,使用Pittsburgh(Pitts250k)数据集[19]进行训练。它包含了250 000幅从Google街景下载的数据库图像和24 000幅与数据库拍摄时间不同(间隔为几年)的测试图像,可用于地点识别。将Pitts250k平均分为三部分用于训练、验证和测试,每部分包含83 000幅数据库图像和8 000幅查询图像。通过对拍摄于不同季节但地点相同的图像进行描述,能够使算法学习到更优的特征表达,以准确地识别图像所处的位置。
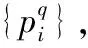
(5)
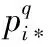
(6)
在三元组的基础上,定义弱监督排序损失函数的形式为:
(7)
式中:l为hinge loss函数,l(x)=max(x,0);m为一个附加常数;Lθ代表了所有负样本图像的损失之和,对于每一个负样本图像,当其与查询图像的距离大于查询与最佳匹配图像的距离与m之和,则损失为0,否则其损失值与m成正比。
VGG-NetVLAD在反向传播过程中,使用随机梯度下降法对参数进行优化,设置每个训练批次的样本数量为4个三元组,K值设为64,初始学习速率设为0.000 1,m设为0.1,冲量系数设为0.9,每迭代5次学习速率减半,共迭代30次。用训练好的VGG-NetVLAD模型在Pitts250k数据集上进行实验,结果显示:当准确率为100%时,该算法可以达到85%的召回率。
2 基于VGG-NetVLAD的闭环检测算法
闭环检测的任务是识别当前时刻位置是否曾经到达过,算法流程可分为图像特征提取与相似性度量两个步骤,具体流程如图3所示。本文将在Pittsburgh数据集上训练好的VGG-NetVLAD模型作为图像的特征提取器,将提取到的特征用于闭环检测。
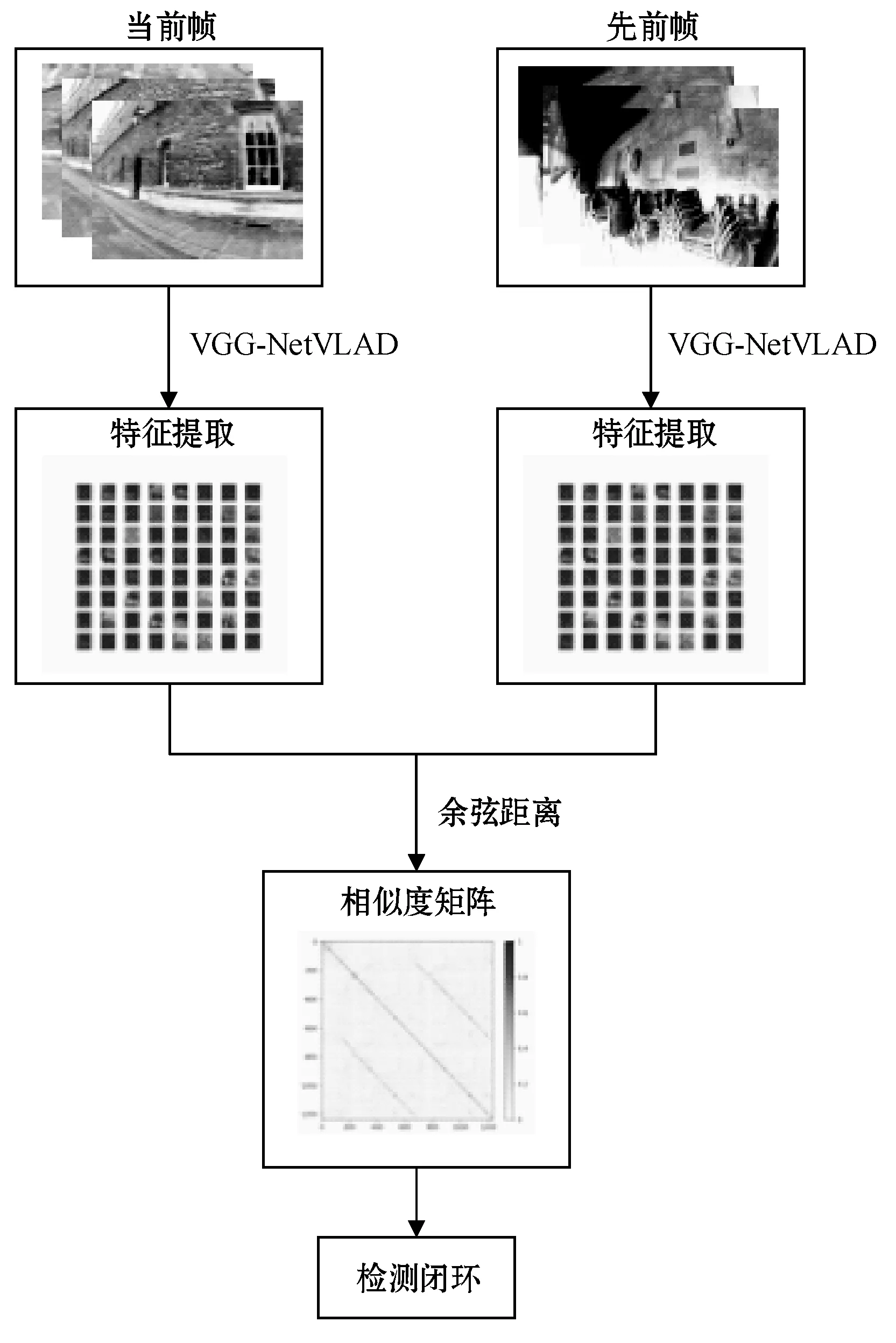
图3 闭环检测算法流程
2.1 图像特征提取
图像的原始尺寸为640×480,为了减小算法的计算复杂度,将图像大小缩小为224×224,并进行减均值处理后输入到网络中。从图4所示的特征图可以看出,VGG-NetVLD中池化层NetVLAD输出的特征图更加关注静态的建筑物,而不是汽车这种有利于图像分类的物体,因此更适合应用于闭环检测。因此,将NetVLAD层提取的特征作为图像的最终表述,每个图像的特征向量的维度为4 096。

图4 两种算法生成的特征图
2.2 相似性度量
假设当前图像为In,之前某一时刻图像为IP,分别输入到VGG-NetVLAD模型中得到特征向量vn和vp。为了计算两图像的相似程度,采用向量间的余弦距离作为度量标准,余弦相似度计算公式如下:
(8)
式中:S为图像In与IP的相似性得分,也是特征向量vn和vp夹角的余弦值。在闭环检测时,对数据中所有图像两两分别进行相似性比较,最终得到一个相似性矩阵,矩阵中第i行第j列的值代表图像Ii与图像Ij的相似性得分。设定相似性阈值,当图像间的相似性得分超过阈值时,认为两图像为同一地点,产生了闭环,否则就判定不是闭环。
2.3 时间约束
在进行闭环检测时,输入的图像是由相机在连续时间内拍摄的,因此相邻图像的内容重复性很高,容易被检测成同一位置,但实际的运动轨迹并未形成闭环。为了避免产生大量的错误结果,需考虑图像相似度对比的时间阈值,对于当前图像,不考虑与其拍摄的间隔时间小于阈值的图像进行比较。由于难以获取每个图像具体的拍摄时间,所以采取设定图像比较范围的方式,假设当前检测的图像为It,在时间阈值内与It相邻的图像数量为d,则图像It的相似性比较范围为第1帧至第t-d帧。
3 实 验
为了验证基于VGG-NetVLAD的闭环检测算法的性能,与其他闭环检测算法进行对比,其中包括经典的BoW方法(在训练词典时提取ORB特征),以及三种基于深度学习的方法:自编码器(Autoencoder)、Inception和VGG16[22],均通过ImageNet数据集进行训练。评价算法的性能指标为准确性和计算时间。实验采用的环境为:Ubuntu16.04,Tensorflow。计算机配置为:内存32 GB,一块GTX1080显卡,处理器为Intel Xeon E5-2603 V3。
3.1 实验数据集
闭环检测实验在NewCollege和City Center两个数据集上进行,它们是由牛津大学发布,应用最广泛的闭环检测验证数据集。NewCollege数据集主要为自然物体的图像序列,如公园里的花草树木,而CityCenter数据集则主要为城市环境的图像序列,如在街道上行走的人和车。这两个数据集的共同点是在同一个地点存在左右两个不同视角的图像,其获取方式为:在移动机器人的云台上放置左右两个相机,当机器人每移动1.5 m时采集一次图像。表1为两个数据集的详细信息,图5为数据集的部分示例图。
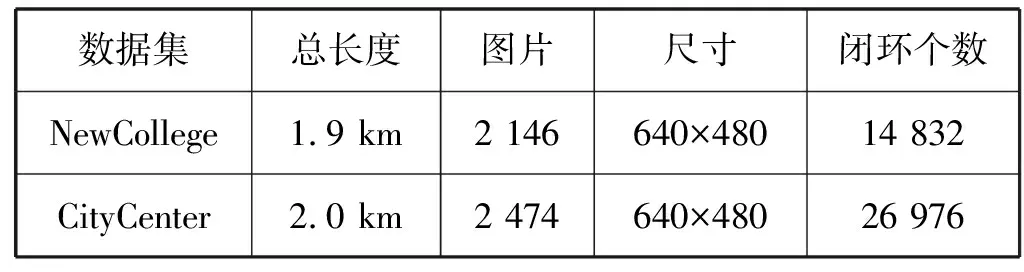
表1 数据集详细信息

(a) New College left (b) New College right

(c) City Center left (d) City Centerright图5 数据集部分示例图
数据集没有将左右两个相机拍摄的图片进行划分,而是分别以奇偶序号命名。两个数据集都提供了图像对是否形成闭环的真实标注,分别储存为2 146×2 146、2 474×2 474的二维矩阵形式。当图像i和图像j为同一地点时(形成闭环区域),矩阵中(i,j)处的数值为1,否则为0。由图5可以看出,左右两个相机在同一地点拍摄的两幅图像完全不同,而真实的标注数据将很多同一地点拍摄但场景完全不同的图像对(i,j)也归类为闭环区域,这种情况下仅仅通过比较图像间的相似性很难获得与真实标注数据一样的结果。为了解决上述问题,首先对两个数据集各自进行归类,将数据集中左相机采集的图像和右相机采集的图像分为两部分,对标注数据也采取相同的操作,然后再分别进行4组闭环检测实验。参照文献[23]中d值的设置方式,将分类后New College两个数据集的d值设为50,City Center两个数据集的d值设为400。
3.2 相似性矩阵
在四组实验中,分别按照3.1节和3.2节的方法提取输入图像的特征向量,以余弦距离作为度量标准计算每对图像间的相似性得分,最终生成整个数据集的相似度矩阵。图6对四组实验的相似度矩阵进行了可视化,左侧为真实标注数据的热力图,右侧为基于VGG-NetVLAD方法生成的热力图。图中颜色越亮的地方代表图像的相似度越高,颜色越暗的地方图像相似度越低,其中对角线的值为图像对(i,i)的相似性得分,因此对角线的颜色最亮。可以看出,基于VGG-NetVLAD的闭环检测方法可以检测出大部分的真实闭环区域,并且与非闭环区域有一定的区分度。

(a) New College left
3.3 准确性比较
为了验证算法的准确性,将算法的预测值与真实值进行比较,分为4种结果,如表2所示。

表2 闭环检测的结果分类
准确性指标主要为准确率(pression)和召回率(recall),准确率代表算法预测出的所有闭环中正确闭环所占的比例;而召回率则代表算法预测出的正确闭环占所有真实闭环的比例。分别统计表2中TP、FP、FN的预测个数,根据式(9)-式(10)可以计算准确率P和召回率R。通过不断改变阈值大小,获得不同的预测结果,最终绘制准确率-召回率曲线。
(9)
(10)
实验的准确率-召回率比较结果如图7所示。当召回率接近0时,五种算法的准确率都等于1。随着阈值的减小,算法能够检测到更多的闭环数量,因此召回率不断上升,但同时算法的准确率随之下降。从图7(a)、图7(c)和图7(d)可以看出,当召回率分别小于0.43、0.24和0.17时,VGG16(fc6层的输出)的准确率均低于传统的BoW,而VGG-NetVLAD要优于其他四种算法。在图7中,当准确率为100%时,VGG-NetVLAD的召回率依次达到0.284、0.247、0.258和0.274,在保证高准确率的情况下提高了召回率,有效地增加了检测出真实闭环的数量。
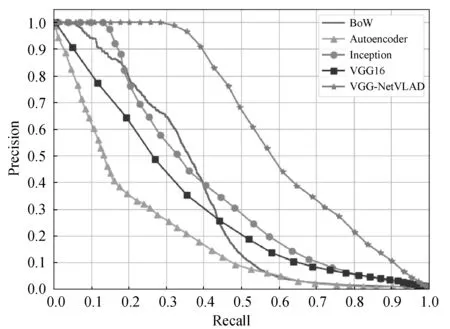
(a) New College left
另一个衡量算法准确性的指标为平均准确率:
(11)
式中:N代表数据集中图像的总个数;P(k)表示检测到K个闭环区域时的准确率;Δr(k)表示当调整阈值时,检测到的闭环区域从K个增加到K+1时召回率的变化值。不同闭环检测算法在四组实验下的平均准确率如表3所示,结果显示无论是在New College left、New College right数据集还是City Center left、City Center right数据集进行实验,VGG-NetVLAD的平均准确率均高于BoW、VGG16和其他两种深度学习方法。由于VGG-NetVLAD使用的训练数据集为Pitts250k,其获取的场景中人、汽车和道路出现的次数更多,所以算法在CityCenter数据集下的平均准确率相对更高。
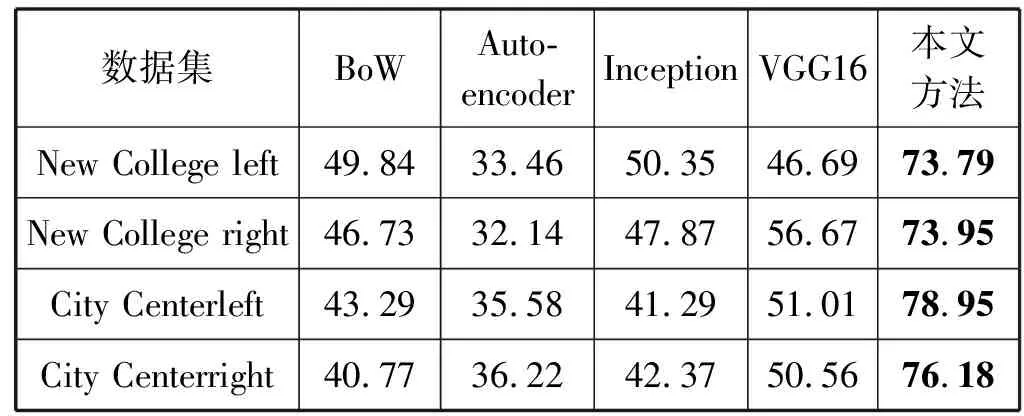
表3 不同数据集上算法的平均准确率 %
3.4 时间性能比较
除了对算法的准确性进行比较,还通过计算不同算法的特征提取时间来衡量算法的实时性。实验在New College数据集上计算提取单幅图像特征的平均时间,基于深度学习算法的提取过程均在GPU下实现。从表4的时间性能比较可以看出,本文模型在特征提取时间上要远小于传统的BoW,但由于VGG-NetVLAD需要对特征进行降维,略高于VGG16,但大体上满足了闭环检测的实时性的需求。
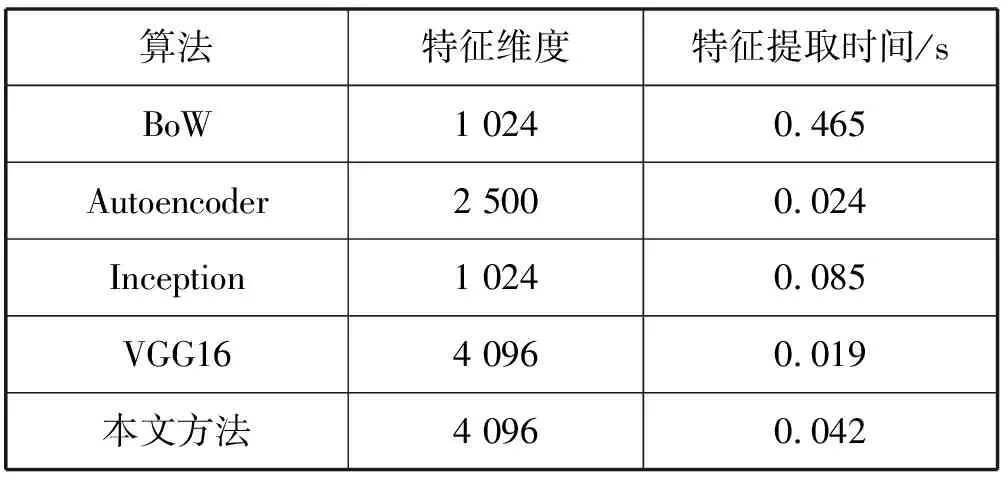
表4 时间性能比较
4 结 语
本文提出了一种融合VGG16与NetVLAD池化层的闭环检测方法。NetVLAD层将VLAD的思想引入到了卷积神经网络,其参数可以通过端到端的学习获得。本文使用Pittsburgh数据集作为网络的训练集,并采用弱监督排序损失函数训练网络,将训练好的网络作为图像的特征提取器,在New College和City Center数据集上进行闭环检测实验。实验结果表明,本文的闭环检测算法与传统的BoW以及其他三种深度学习方法相比,在保证高召回率的情况下提升了准确率,同时基本满足了闭环检测的实时性。下一步研究会着重考虑机器人在移动过程中视角变化、光照变化对闭环检测的影响,对算法进行改进以达到更好的鲁棒性。
猜你喜欢
当代水产(2022年7期)2022-09-20
军民两用技术与产品(2022年3期)2022-06-05
纺织服装周刊(2022年16期)2022-05-11
物流科技(2022年2期)2022-05-07
保定学院学报(2022年2期)2022-04-07
中学生理科应试(2021年11期)2021-12-09
现代英语(2021年18期)2021-11-22
数学学习与研究(2018年15期)2018-11-12
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
