
基于HBase/Spark的教学大数据存储及索引模型研究
2020-12-18 03:17李亚平曲金帅
云南民族大学学报(自然科学版) 2020年5期
唐 立,李亚平,曲金帅
(1.安徽经济管理学院 信息工程系,安徽 合肥 230031;2.安徽经济管理学院 教务处,安徽 合肥 230031;3.合肥工业大学 管理学院,安徽 合肥 230009;4. 云南民族大学 云南省高校信息与通信安全灾备重点实验室,云南 昆明 650500)
随着教育领域对大数据诉求的增强,教学过程与结果数据的持续采集,动态汇集成了新数据形式的教学大数据.教学大数据更能精准刻画全维度的“学生画像”,服务于师生教学和学校管理[1].而传统的关系型数据库系统用来储存爆炸式增长的教学大数据将力不从心,非关系型数据库系统具有强大的扩张性和高并发性,可以弥补关系型数据库的不足[2].
非关系数据库中的apache HBase是开源分布式的列式存储系统,因为它有高扩展性和并发性而被广泛使用,成为当前的热门存储技术之一[3].目前针对HBase存储和查询的相关研究比较多,如李正武[4]利用Hadoop集群的HBase对区域化桥梁健康监测数据进行分布式存储;李攀宇[5]利用HBase分布式存储交通数据,运用HBase的行键设计结合二级索引,解决时空维度分布不均引起的热点问题;董萌萍[6]设计与实现了一种基于HBase的农作物病虫害数据存储系统,弥补传统关系数据库的不足.以上研究针对不同的应用场景,设计出不同模式的HBase存储以解决数据在存储与查询过程中面临的效率问题.但是数据存储时的负载均衡和写热点问题,索引时针对属性过滤的效率问题都没有得到很好的解决.
本文根据教学大数据存储结构的特点和常用查询概率出发,设计了基于组合行键的HBase系统,进行Region预分区和构建cost评分函数,解决写热点和负载均衡的问题.然后利用组合行键和Spark分布式的属性过滤,到达快速查询的目的.
1 教学大数据存储与索引系统框架
教学大数据是指教学活动产生的,根据教学需求采集到的,用来促进教学模式创新以及教学质量提升的数据集合[1].教学大数据来源比较广泛,数据大量而分散,结构复杂而异构.为了实现此类大数据的检测统计、管理、预测和分析等智能应用,就要建立一套完整的教学大数据存储与索引系统,实现海量教学数据的存储和查询,为智能化教学应用提供高效的数据支撑.
本文设计基于Spark/HBase的教学大数据系统框架如图1所示.框架主要分为2大块:1)通过数据元数据或教学数据的采集,构建HBase表.主要经过行键设计,行键表达式和算法实现,负载均衡问题解决,然后入库.2)根据用户查询请求,进行语义分析,逻辑优化,基于行键过滤出模糊结果集,然后基于SparkRDD分布式处理进行属性过滤,得到精确查询结果.
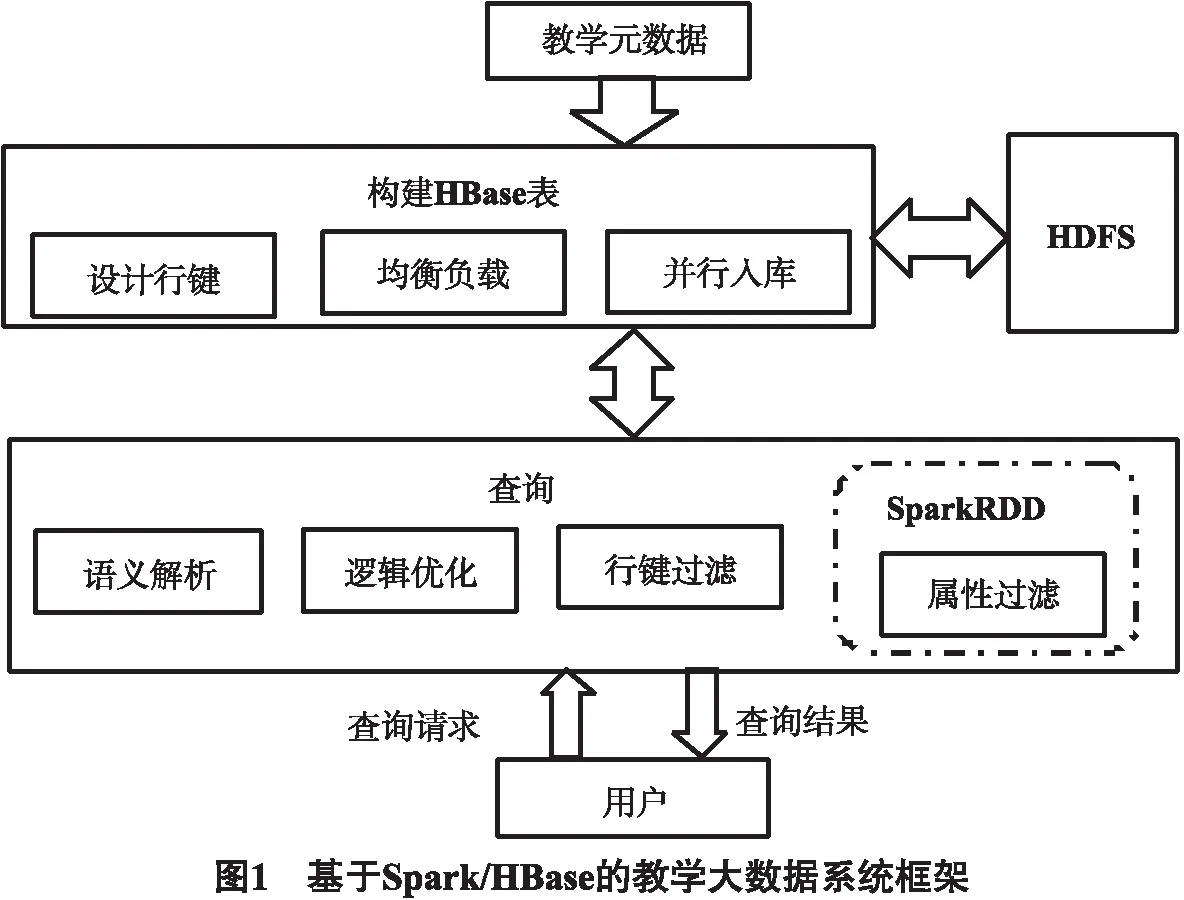
系统要解决的问题:1)基于HBase的存储设计,如何既能满足索引需求,又能解决均衡负载和写热点问题,达到高效存储目的.2)快速索引,对于用户提出的多特征值的复杂查询问题,如何利用行键和SparkRDD快速进行收索,满足用户查询的需求.
2 基于HBase的教学大数据存储设计
根据HBase表的逻辑结构特点,将教学大数据的模型设置为由行键RowKey、列族ColumnFamily和时间戳TimeStamp组成,如图2所示.根据查询需求把行键设计为组合行键,用于对教学数据的唯一索引.列族映射存放着教学数据的其他属性,同时也可以按需求动态扩展属性列.时间戳主要是标记数据的记录时间,便于区分数据的不同版本.

2.1 教学大数据的组合行键的设计
在HBase中构造存储数据表,行键的设计是最为关键的.行键就是要反映数据重要特征字段的,并且具有唯一性.为了提高数据查询性能,利用教学数据中查询频率最高的若干个字段组合成行键,与普通列值数据冗余存放在多张HBase数据表中.
通过教学大数据的日常查询记录和管理日志来看,关于CourseID、StudentID、TeacherID的特征值查询符合大多数用户的查询习惯,基于CourseID、StudentID、TeacherID的特征值的查询频率较多.同时由于CourseID在教学大数据中的占有比例相对于StudentID、TeacherID要小,如果把CourseID作为单独的行键索引会增大查询开销.因此本文设计2张表,分别以
CourseID+ StudentID:
Row-Key:CourseID{
Column Family: StudentID{
Column:( Attribute)
}
}
CourseID+ TeacherID:
Row-Key:CourseID{
Column Family: TeacherID {
Column:( Attribute)
}
}
2.2 RowKey表达式及行键生成算法
RowKey表达式是一般都是特征值的编码与解码规则.RowKey通过对字段来源的抽象和约定,按一定的规则定义好RowKey,然后执行数据转换时解析RowKey表达式,并从指定位置提取多个特征值[7].本文组合RowKey表达式是从HBase中的数据行键将字段名、字段名称值或固定字符按一定的形式转换运算后生成的.组合RowKey的生成算法如下.
定义1转义字符表达式为[ ],解码时对括号里的内容进行转义计算.
定义2字段名表达式C(index),获取索引为index的字段名称.
定义3字段值表达式V(name|index),按字段名称或索引号来获取字段值.
定义4字符串断取表达式Sub(string,start,num),从字符串string的start位置断取num数量的字符.
定义5字符串的格式化表达式T(format),将字符串转换为format对应的格式.
定义6文件名表达式为F,表示获取的数据文件名称.
步骤1 读取行键表达式字符串如“CDE”,并将字符串分解成字符集合EXP.
步骤2 初始化变量:遍历行键字符集合EXP,循环变量n=0;临时缓存字符串TMP;转义控制符TC初始为false;字符串控制SC初始为false;返回结果字符串SR初始为空;状态变量S初始为空.
步骤3.1 初始转义控制符TC=false;表示处于非转义的状态.
对于画面上2/3区域,我们使用了去朦胧+46、饱和度-16的渐变滤镜进行处理。去雾工具在提高反差的同时也会增强画面饱和度,所以我们使用了负向的饱和度设置平衡这个问题。远景的山脉受到的雾气影响更加明显,所以我们再使用去雾设置为+18的画笔工具对这个部分进行一些额外的手动处理。现在,画面整体看上去有些偏蓝。一般情况下我会重新调整白平衡设置来解决这个问题,对于这张照片来说,我觉得使用色温7400、色调+4的参数,效果恰好给绿色带来了更丰富的变化。
步骤3.2 对字符串EXP[n]进行判断:‘[’表示转义开始,并设置TC=true,否则将EXP[n]添加到SR,跳转步骤3.6;‘]’表示转义结束,TC= false,把TMP添加到SR,接着跳转到步骤3.6,否则继续进行一下步.
步骤3.3 对字符串控制SC的判断:当SC= true处于字符状态,若EXP[n]为空表示字符状态结束,与此同时设置SC= false,若EXP[n]不为空,则将EXP[n]添加到TMP中,再跳转步骤3.6;当SC= false,则进一步判断,运行步骤3.5.
步骤3.4 判断 EXP[n]是否为空,如果是空则表示开启字符状态,SC设置为 true,跳转步骤3.6;如果EXP[n]是非空,字符是文件名,则取文件名放入TMP,字符是C、T、V、Sub中的任意一个,则S设置为相应的字符,再跳转步骤3.6.如果都不是则继续下一步.
步骤3.5 如果EXP[n]为‘)’,是指一个带参数的符号结束,根据S中的符号类型,C取列名,V取列值放入TMP,T按String.Tostring(format)的方法将TMP进行格式化,Sub断取TMP的字符串.
步骤3.6n+=1,如果n小于或等于集合中的最大行数,则回到步骤3.1,否则进行下一步.
步骤4 返回SR.
按照以上算法步骤举例,现有教学大数据中一系列命名为CourseID_A_01012.DAT的课程数据文件,使它以组合RowKey的算法存入HBase数据库中,则RowKey表达式为Sub(F,10,1)Sub(F,14,3)"S"V(StudentID).T("000").式中的F是指CourseID_A_01012.DAT文件名字符串、Sub(F,10,1)断取文件名称为F中的第10个字符、Sub(F,14,3)断取文件名称F中的第14,15,163个字符、"S"取固定字符S、V(StudentID).T("000")取StudentID列的值并转换格式为"000",最后将这些字符顺序的组合起来.教学大数据的存储转换过程如图3所示.
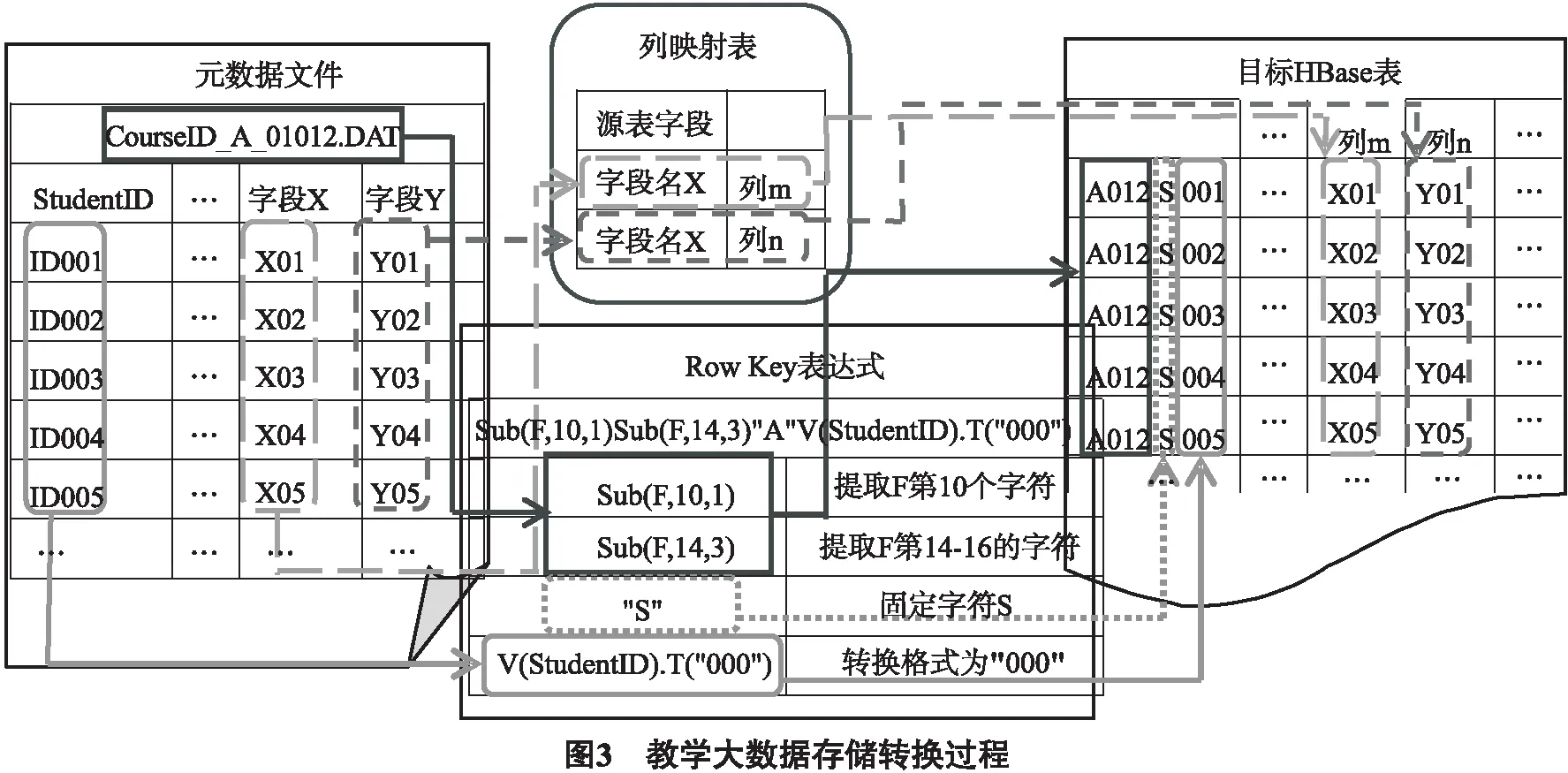
2.3 数据入库及均衡负载优化处理
整个教学大数据入库流程如图4所示.1)根据教学元数据文件特点以及查询习惯设计组合行键;2)根据设计好的RowKey,归类相应的教学数据列族;3)提取教学大数据属性数据的名称和值,作为HBase列族的列限定符和列值;4)按组合行键的记录,根据规则匹配入库到指定的Region预分区.
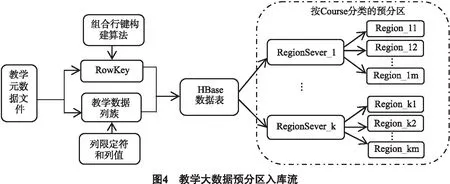
本文的RowKey设计是一种组合RowKey,因为这种组合RowKey的前缀本是取元数据文件名的第10个字符,如2.2节所述,该字符表示的是教学中Course的学科类别,本身不是有序的,所以这样组合RowKey设计本身就解决了写热点问题[9].
根据教学大数据的特点,以Course的类别来预设分区以缓解负载均衡问题.首先是按一级学科进行分类成若干个Region Server;然后对每个Region Server再分出若干个二级或三级学科Course集的Region,由于本文设计的组合RowKey是与Course有密切关系,很容易根据RowKey将Course存放在对应的Region中;最后把选取负载因子作为请求数目预测值,构建cost评分函数,以此来检测并迁移负载,达到负载均衡的目的.其算法过程如下:
收集每分钟每一个Region的写入请求数目,得到长度为n的序列R=(r1,r2…,rn),使用二阶差分指数平滑法对未来写请求数进行预测[10].
(1)
(2)
(3)
最终预测结果如下:
(4)
数据热度值θi是按秒为单位,就是对预测值除以60,如公式(5).
(5)
对HBase集群中的每个Region Server的负载总和计算如公式(6),其中m为当前Region Server下的Region总数.
(6)
平均负载的计算如公式(7),其中k是Region Server的数目.
(7)
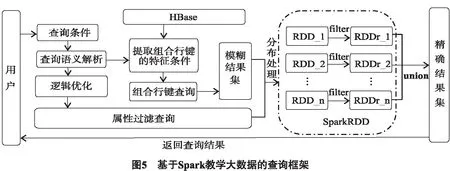
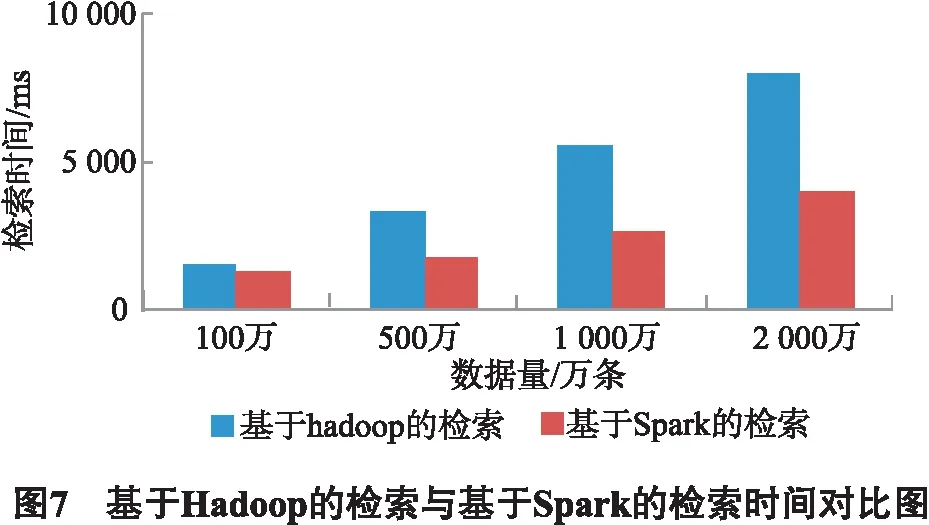
我们设定最大负载loadmax=1.05×loadavg,最小负载为loadmin=0.95×loadavg.当1个Region Serverj的负载满足loadmin cost = write_cost + msize_cost +sf_cost + locality_cost. (8) 公式(8)中:write_cost为写请求,msize_cost为memstore容量评分,sf_cost为StoreFile评分,locality_cost本地性评分. 个Region Server超载的情况下,需要根据公式(8)cost测评函数[11-12]遍历计算出负载不足的Region Server中最小的Region,并执行迁移操作,以此来实现负载均衡. 对于教学大数据在智慧教学和教学研究中的应用,在进行数据查询时,查询语句是多样化的,根据各种角色查询习惯分析,常被用到的查询条件包含CourseID、StudentID、TeacherID和其他属性.因此对查询语义进行解析,提取CourseID、StudentID、TeacherID的常用信息,利用组合行键实现模糊结果集的提取.再将模糊结果集以弹性分布式数据集(resilientdistributed dataset,RDD) RDD的形式存储在Spark的内存环境中,并行完成属性过滤,得到精确结果集,最终将结果返回给用户. 基于Spark的教学大数据框架如图5所示,其过程为:1)用户根据需求提交查询条件;2)对查询语义进行解析,提取与组合行键相关的特征条件,同时对查询语义进行逻辑优化;3)运用组合行键的算法从HBase表中筛选出符合特征条件的模糊结果集;4)将模糊结果集以SparkRDD形式分布存储在内存环境中[13],根据逻辑优化后的查询条件,对其他数据属性进行分布式过滤查询;5)每个RDD并行过滤查询,得到相应的结果RDDr;6)排序合并所有的RDDr,把查询结果返回给用户. 本文是依据用户查询习惯,提出基于组合行键的查询,根据查询条件CourseID+ StudentID和CourseID+TeacherID两种不同的组合行键,可以快速度得到模糊结果集,具体算法如下: 输入查询条件θ 输出组合行健集合查询的模糊结果集FR 利用SparkRDD对模糊结果集进行分布式属性filter,最终精确结果集合. 本文的实验数据采集于安徽经济管理学院教务处2008年以来所有的学生数据,其中除了包含关系型元数据,还有非关系型非结构化数据如:视频、图像、声音等,数据量约为110万条.为了比对大数据量处理能力,在此数据基础上,通过代码生成技术生成约 2 000 万条. 本实验所用的Spark与HBase部署在以1个Master节点和3个Slave节点的集群框架上.所有节点机器配有CUP i3 2.75GHZ 、内存4G配置,使用linux操作系统.服务平台配置为ThinkServer RD650,处理器类型E5-2609v4,内存 16 GB,硬盘1T.所使用的HBase版本为1.3.1,Spark为2.1.0,Hadoop为2.7.3.其中HBase的实验平台中的Master和Region Servers分布如图5所示. 原生系统是未设置预分区,本文采用的是组合rowkey设计,对表使用预分区后,采用负载均衡优化后的系统.进行插入操作,进行批量的数据写入操作,如图6所示. 通过图6可以看出优化后的HBase系统相对于优化前提高了写入性能.没有优化的原生态系统,没有预分区,会不断自我分裂造成运算时间的消耗,同时连续性增长的rowkey,会造成写热点问题不断频发,从而耗费大量的写入响应时间. 把实验数据按不同数量分类,在相同检索条件下,以文献[4]基于Hadoop下的检索和本文提出的基于Spark下的检索进行对比实验,如图7所示. 可以从图7看出,基于Spark的检索比文献[4]基于Hadoop的检索时间要小,而且随着数量级别越大,它们的检索时间差距越大.这是因为Spark是基于内存的并行计算框架,它具有弹性分布式数据集RDD和分布式运行架构,可以精确读取存储的数据,几乎没有磁盘访问的时间开销,所以基于Spark的分布式属性过滤可以大大提高教学大数据的查询速度. 为了满足教学大数据的存储和索引的需求,实现对海量教学数据进行准确高效的处理和管理.本文设计了基于Spark/HBase的教学大数据存储和索引模型,它基于HBase设计组合行键,并根据Course的类别进行预分区后,通过负载因子预测请求数,构建cost评分函数,来检测并迁移负载,达到解决写热点和负载均衡的问题.然后利用组合行键对查询数据进行模糊集筛选,通过Spark分布式的属性过滤,实现高效查询目的.实验证明该模型设计的有效性,通过与原生系统和文献[4]进行对比,本文设计的模型在存储写入和查询响应时间上具有明显优势. 在研究的实验过程中也发现了问题,研究适合大部分常规查询用户范畴,但是如果遇到非典型的非行键的列查询,则需要对全表进行扫描了,这样的查询效率并不高.后续将对此继续展开研究.3 基于Spark教学大数据索引
3.1 基于Spark查询框架
3.2 组合行键的算法

4 实验与分析
4.1 实验数据与运行环境
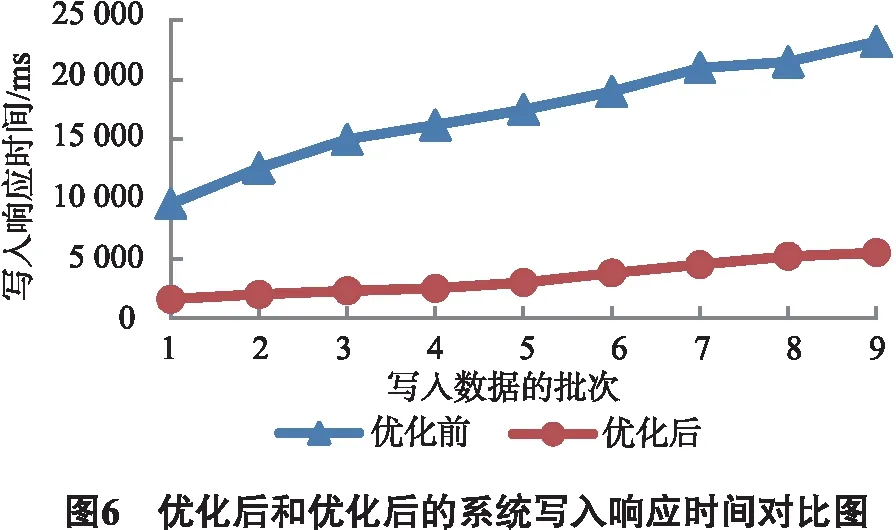
4.2 写入对比实验结果与分析
4.3 检索对比实验和分析
5 结语
猜你喜欢
初中生世界(2020年47期)2021-01-07
无线互联科技(2020年11期)2020-12-01
安顺学院学报(2020年1期)2020-04-05
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
数字通信世界(2019年3期)2019-04-19
现代计算机(2019年6期)2019-04-08
科教导刊·电子版(2016年30期)2016-12-26
中国信息技术教育(2015年21期)2015-09-10
