
融合浅层学习和深度学习模型的语音情感识别
2020-12-14 09:13:44赵小蕾许喜斌
计算机应用与软件 2020年12期
赵小蕾 许喜斌
1(中山大学新华学院信息科学学院 广东 广州 510520)2(广东工程职业技术学院 广东 广州 510520)
0 引 言
语音情感识别(Speech Emotion Recognition,SER)是模式识别领域的研究热点,是新型人机交互系统及人工智能发展不可或缺的重要技术[1]。SER技术主要分为语音信号采集、特征提取和情感识别三个阶段[2],其中关键的模块是特征提取和情感识别模块。针对特征提取技术研究者们多年来进行了细致的分析和研究,情感特征主要包括韵律特征、频域特征和音质特征[3],这些特征在传统语音情感识别中起到关键作用,辅以一定的特征选择算法针对特定数据集可以取得优异识别性能。值得一提的是,学者们尝试将时频两域的情感特征进行结合,提出了语谱图特征提取方法,并应用于语音识别[4]和语音情感识别相关领域[5]。在识别模型研究方面,从浅层学习的支持向量机(SVM)[6]、隐马尔可夫模型(HMM)[7]、高斯混合模型(GMM)[8],到深度学习的卷积神经网络(CNN)[9]、深度置信网络(DBN)[11]和递归神经网络等(RNN)[10]。与传统的机器学习模型相比,深度学习能够提取高层的特征,近年来在计算机视觉领域具有出色的表现,其中卷积神经网络在语音识别、图像识别等领域取得了前所未有的成功[11]。许多研究者们也逐步将深度学习引入到SER任务中。黄晨晨等[11]利用深度信念网络自动提取语音情感特征,合并连续多帧语音情感特征构造一个高维的特征,最后输入到支持向量机(SVM)进行分类。Mao等[12]基于CNN网络提取显著特征,从而提升复杂场景下的SER情感识别性能,实验证明该方法具有较高的鲁棒性和稳定性。Huang等[13]训练了一个改进的CNN模型,能够提取显著语音情感特征,进而提高情感识别率。Lee等[14]提取了高层特征并使用RNN进行预测,在IEMOCAP数据库上取得62%的识别准确率。Niu等[15]提出了数据预处理算法,通过改变频谱图的大小获得更多的数据,并输入到深度神经网络模型AlexNet中,在IEMOCAP数据集上获得了48.8%平均准确率。Fayek等[16]研究了适用于SER任务的前馈神经网络和递归神经网络及其变体,并在副语言语音识别中验证了深度学习结构的有效性。文献[17]提出了一种利用卷积神经网络识别语谱图特征的语音情感识别方法,首先提取灰度语谱图特征,随后利用Gabor小波和分块PCA进行特征再提取和降维,最后送入CNNs进行识别分类,取得了不错的效果。
虽然深度学习在SER中取得了一定的成绩,但以往的传统语音情感识别(浅层学习)也并非没有任何价值,浅层学习模型训练速度快,参数少,所提取的特征具有针对性,而深度学习网络结构复杂,需要大量的训练数据,调参复杂。文献[18]指出深度学习不需要人工参与进而缺乏先验知识的引导,故提出使用浅层学习引导深度学习的方法,说明浅层学习仍有特定意义。
对于语音情感识别问题虽然是大数据的时代,但获取的有效数据却有限,而浅层学习在小样本数据集上具有优势,能否突破数据集的数量限制,充分发挥二者的优势,形成优势互补,是值得研究的课题。因此,本文提出了融合深度学习和浅层学习且适用于小样本语音的语音情感识别的模型。构建了两种识别模型:传统语音识别——浅层学习和深度学习框架——PCANET模型[19],最后通过有效决策层融合两类模型。研究目标是充分利用浅层学习和深度学习的优势以避免不足,提高识别率和鲁棒性。传统声学特征具有针对性但主观性较强,深度学习网络可以自动提取特征,但会受样本数量和参数影响,通过有效的决策融合方法,可以综合利用二者的优势,得到稳定的高识别率。
1 方法框架流程
本文方法框架流程如图1所示,主要分为三个模块:浅层学习特征提取模块、深度学习特征提取模块、分类决策融合模块。浅层学习特征提取模块,使用人工特征提取方法,并通过特征选择,选取有效的特征;深度学习特征提取模块,鉴于PCANET在图像处理上具有绝对优势,故获取具有丰富情感信息的灰度语谱图作为输入,最后经过有效的决策融合取得最终结果。

图1 本文方法框架流程
2 深度学习特征提取
PCANET网络输入为灰度语谱图,故深度学习特征提取模块涉及两部分:灰度语谱图生成算法以及PCANET网络计算过程。
2.1 语谱图生成算法
语谱图的生成流程如图2所示。

图2 语谱图获取流程
具体步骤描述如下:
步骤1对语音情感信号加窗分帧。假设第i个语音情感信号用si表示,则加窗分帧后用si(m,n)表示,m为分帧的个数,n为帧长,加窗采用汉明窗,本文实验采用的窗长为1 024。
步骤2加窗并进行傅里叶变换。计算傅里叶系数Xi(m,n):
(1)
式中:N代表序列长度;k代表序数。
步骤3采用对数能量方法生成灰度语谱图。设在点(a,b)上的灰度值为gi(a,b):
gi(a,b)=log10|Xi(m,n)|
(2)
步骤4采用最大最小归一化方法对语谱图进行归一化。得到归一化灰度语谱图Gi(a,b):
(3)
式中:gmax(a,b)、gmin(a,b)分别为语谱图Gi(a,b)灰度级中的最大值和最小值。
步骤5将语谱图量化成0~255的灰度级图像Gi′(a,b)。
2.2 PCANET特征提取过程
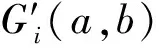
步骤2第一阶段PCA处理。假设第一阶段PCA滤波参数为L1,用来表示PCA中对特征值排序后的前L1个特征值。随后取L1个最大的特征值对应的特征向量组成L1个PCA卷积核。用PCA对样本集X进行计算:
(4)
s.t.VTV=IL1
式中:IL1为L1×L2的单位矩阵。
对应的PCA滤波器如下:
(5)
式中:matk1k2为将向量从Rk1k2空间投影到Rk1×k2空间的函数;ql(XXT)表示计算XXT的第l个主成分特征向量。
通过训练将样本变换到新的空间:
(6)

步骤3第二阶段PCA处理。在步骤2得到的卷积图像上再次进行相似的操作。此次取L2个最大的特征值对应的特征向量,得到L2个PCA卷积核。得到的特征变换为:
(7)
步骤4输出层处理。为了使特征表达能力更强,使用赫维赛德阶跃函数O(x)对特征值进行二值化[20],最终获得的二值化及加权处理后的结果如下:
(8)
将输出S分为B块,每个块分别进行直方图统计,得到的最终特征:
(9)
式中:fi表示第i个语谱图经过PCANET网络得到的特征表示;Bh表示分块直方图统计。
3 决策层融合方法
为了实现浅层学习和深度学习模型的优势互补,采用了决策层融合方法。SVM分类器在小样本语音情感识别中具有广泛的应用,PCANET模型原采用SVM,可取得较佳效果[15],投票机制是决策层融合常用有效方法,且SVM采用投票机制。综上分析本文基于投票决策提出了有效的差异性投票机制,差异性投票机制体现在两个方面:两类特征的识别精度差异性,各自分类器类别之间的差异性。综合两个SVM分类器统计总票数,判定得票最高的类别为最终决策的类别。本文设采用深度学习特征的SVM分类器为D-SVM,采用浅层学习的分类器为S-SVM。
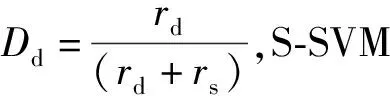
步骤2计算每个模型类别间的差异性信息。对于识别N个类别的“一对一”SVM分类,有N(N-1)/2个子分类器,各子分类器根据到各个类别的距离进行两两投票。为了保证票数的有效性,舍弃距离小于一定阈值的无效投票,描述如下:(1)计算阈值t(取样本所有子分类器的平均距离值);(2)舍去两两子分类器距离小于t的投票。
步骤3计算N个类别的最终投票分别为V1,V2,…,VN,其中Vi=Dd×vdi+Ds×vsi,vdi为深度学习第i个类别的有效投票数,vsi为浅层学习第i个类别的有效投票数。最终结果为result=max(V1,V2,…,VN)。
4 仿真实验
在两个数据库上进行验证,其具体信息如下:
数据库1:柏林数据库(EMO-DB)。由柏林工业大学录制的德语情感语音库包含535个语音数据,采样率为16 kHz,16 bit量化,由10个不同的人(5男5女)录制而成,包含7种不同的情感,分别为中性、害怕、厌恶、喜悦、厌烦、悲伤和生气。
数据库2:课题组自行录制的语音情感语音数据库SPSED[21]。包含6种情感:高兴、伤心、惊奇、生气、害怕和厌恶。由5男6女录制,每人录制每种情感的15个语料(本文选用5男5女)。
实验方案:采用5折交叉验证方法,将情感语料分成5份,4份用于训练,剩下的一份作为测试,经过5次轮换训练及测试,取平均值作为最终的识别结果。
4.1 生成语谱图部分示例
将语谱图作为PCANET网络的输入。给出语谱图示例图(部分),图像经过降采样最终大小为384×301,如图3和图4所示,可以看出不同情感的语谱图信息具有显著的差异性。

图4 EMO-DB情感语音库灰度语谱图(部分)
4.2 参数设置
针对浅层学习(人工统计)特征识别方法,为了观察特征降维后特征大小对识别率的影响,在两个数据库上进行实验,求得各情感类别识别率平均值,最初提取的特征为能量相关、基音频率相关及共振峰系数等101维特征,并采用序列浮动前向选择(SFFS)方法进行特征选择,实际降维到61维。
对PCANET网络的各参数设置,通过实验给出对比,并确定最终的参数值。为了观察PCANET网络中块大小的选取对识别率的影响,在两个数据库上,块大小分别取3×3、5×5、7×7、9×9、11×11(单位:像素,通常选用奇数),测试本文方法的平均识别率,固定其他参数L1=L2=8,重叠率为50%,直方图块大小为两阶段分别取2,其结果如图5所示。可以看出,块大小(实际为选取的窗口大小)为5×5时可以获得最佳效果。
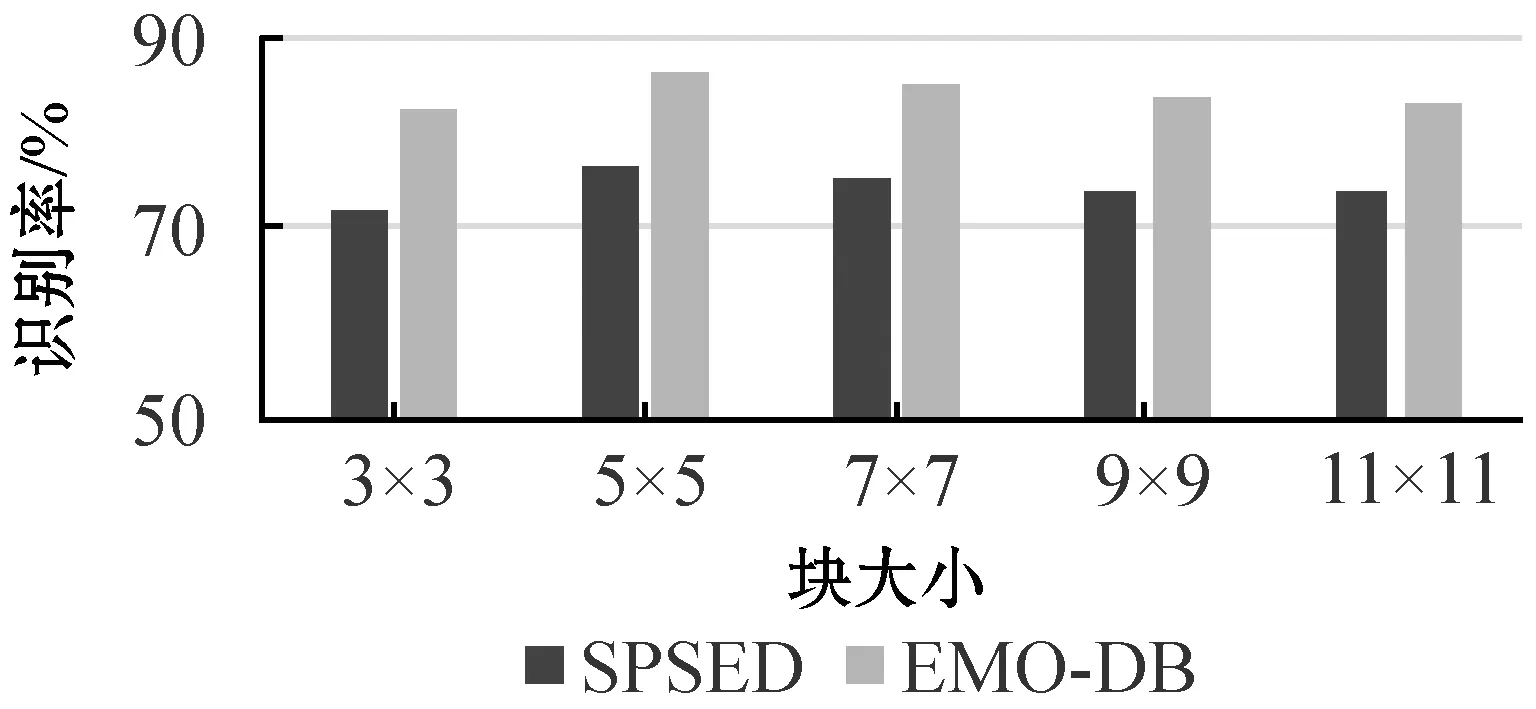
图5 块大小参数对识别率的影响
为了观察滤波器选取参数对识别率的影响,测试了不同取值下的识别率,如图6所示。固定其他参数块大小选取5×5,直方图块大小选取2,重叠率为50%。可以看出,两阶段都选择8时效果为最佳。实验也测试了直方图块大小和重叠率的影响,选择2为最佳,重叠率在30%以上已经可以取得较好效果,为了保险起见本文选择50%。
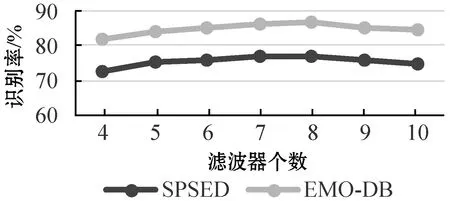
图6 滤波器个数选择对识别率的影响
4.3 对比实验与分析
为了验证融合浅层学习和深度学习的有效性,测试仅使用浅层学习识别方法(传统方法中的人工统计特征,记为方法1)、深度学习识别方法(记为方法2)、本文方法,实验结果如表1所示。可以看出,在两个数据库上方法2识别率明显高于方法1,说明采用语谱图+PCANET提取特征+SVM方法较传统人工统计特征+SVM方法更佳。而本文方法较方法2取得了更高的识别率,在SPSED上较融合之前的方法2提高了2.54个百分点,较方法1提高了6.1个百分点;在柏林数据库上,本文方法较方法2提高了2.93个百分点,较传统方法提高了3.86个百分点。实验结果表明,本文方法是有效的,这是因为其充分利用了两种识别模型的优势,丰富了情感信息的获取途径。

表1 融合方法有效性验证实验 %
为了进一步验证本文决策层融合方法的有效性,分别与下述方法进行比较实验:特征层融合方法(方法1),该方法采用特征级联,然后使用SVM分类器识别,以及常用的决策融合方法:线性加权融合方法(方法2,权重取0.5)、证据理论融合方法(方法3)、贝叶斯融合方法(方法4)。为了验证融合浅层学习和深度学习方法的有效性,与较有代表性的语音情感识别方法进行了对比,如文献[11]和文献[13]。对比实验结果如表2所示。可以看出,本文方法取得了最佳结果。方法1是特征级联融合方法,方法2-方法4的特征决策融合方法均比方法1略高些,说明采用决策融合方法更为合理。本文方法与文献[11]和文献[13]相比也取得了明显的优势,验证了本文方法在小样本数据集上可以取得较好的效果。

表2 与其他方法的对比实验 %
5 结 语
本文分析了浅层学习和深度学习模型的优缺点,为了实现两种模型的优势互补提出了浅层学习和深度学习模型决策层融合方法,并应用于小样本语音情感识别中。浅层学习采用传统的人工统计特征,提取具有针对性的有效特征,深度学习阶段获取了情感语音的语谱图信息,并将语谱图按照图像处理方式,使用PCANET提取特征,将两类特征分别输入到SVM识别模型中,随后使用提出的有效差异性投票机制的决策融合方法进行融合。在两个数据库上进行验证实验,对比了特征层、决策层常用融合策略以及具有代表性的语音情感识别方法,本文方法取得了相对较高的识别率。下一步工作是研究利用浅层学习的先验知识引导深度学习端到端的识别策略。
猜你喜欢
建材发展导向(2021年24期)2021-02-12 02:00:24
环境影响评价(2020年5期)2020-12-02 01:18:56
计算机工程(2020年3期)2020-03-19 12:24:50
小型微型计算机系统(2019年9期)2019-09-09 03:38:42
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
中国交通信息化(2018年3期)2018-06-13 03:27:58
东北师大学报(自然科学版)(2017年2期)2017-06-13 10:43:55
水利规划与设计(2016年10期)2017-01-15 14:01:14
中国交通信息化(2016年2期)2016-06-06 07:28:02
