
基于灰狼优化聚类算法的读者行为分析*
2020-12-11 06:10蒋一锄
吉首大学学报(自然科学版) 2020年4期
蒋一锄
(湖南环境生物职业技术学院图书馆,湖南 衡阳 421001)
随着物联网、大数据、人工智能等技术的推广应用,以数据为核心驱动的图书馆服务模式将成为未来发展趋势[1].为了能从读者行为数据中及时、准确地发现读者的真实需求,图书馆需要引入特定的信息处理技术,从海量数据中找出其中隐藏的有效信息并进行处理,利用大数据结论快速、准确、便捷地为读者提供所需信息资源,满足读者的个性化需要[2].数据挖掘技术就是实现该任务的关键技术之一.
传统的读者行为分析一般采用数据挖掘技术中的聚类算法,对图书馆信息系统中大量数据进行聚类,得到隐藏在信息中的内在规律及关联,以提升图书馆服务质量和资源有效利用率[3].但对于传统的聚类算法,其最明显的缺点是难以寻找到最佳的初始值,而初始值的确定对最终聚类分析的结果影响较大.针对这个问题,笔者以线下图书馆图书借阅数据为例,采用灰狼优化算法(Gray Wolf Optimization Algorithm, GWO)来优化模糊C均值(FuzzyC-Mean, FCM)的聚类初始值,然后再对读者借阅行为数据进行聚类分析.实验证明,此方法行之有效,能显著提升聚类结果的准确度.
1 相关研究
国外学者对读者行为分析的研究起步较早.2001年,Michael利用数据挖掘技术对加州大学数字图书馆进行分析,发现了不同类型用户在图书馆的时间规律,并采用时间序列和聚类分析法对该规律进行分析,最终成功地预测了该图书馆未来的访客情况[4].2010年,Kovacevic等利用数据挖掘技术对读者的资料和搜索记录进行分析,提出了数字化图书馆的推荐服务模式,将兴趣爱好相同的读者归类在一起,为他们提供专门化的服务[5].
相对而言,国内图书馆领域对数据挖掘技术的研究就起步较晚.2015年,李文林等结合文本挖掘工具和医药类专业文献构建了数据挖掘平台,从而提高了读者的文献检索准确度和效率[6].2016年,吴越采用数据挖掘技术对图书馆的借阅数据进行聚类,将不同用户对文献的利用情况进行了对比,结合读者的需求分析,为图书馆管理者提供了决策依据[7].同年,陈金菊也通过对读者借阅数据的挖掘,构建了读者个性化服务模型,实现了读者个性化推荐服务[8].
总的来说,国内图书馆界对读者行为分析算法的研究尚处于起步阶段,与国外同类研究存在较大差距.
2 基于灰狼优化的聚类算法
2.1 灰狼优化算法
GWO聚类算法是澳大利亚格里菲斯大学Mirjalili等于2014年提出来的一种群智能优化算法,具有收敛性能较强、参数少、实现容易等特点[9].GWO是基于对自然界中灰狼的狩猎与社会机制的研究而提出来的.在自然界中,灰狼可分为头狼(alpha)、决策狼(beta)、执行狼(delta)以及最底层的狼(omega).GWO将狼群中的狩猎机制分为寻找、包围、攻击3个步骤.狼群中alhpa的主要职责是负责制定狩猎流程,决定狩猎对象,决定狼群是休息还是继续搜索猎物;beta帮助alpha制定狩猎流程和决策;delta执行aplha和beta所做出的决定,以及命令、领导omega;omega处于狼群社会中的最底层,只能服从于alpha,beta以及delta.灰狼的社会等级分层如图1所示.

图1 灰狼的社会等级分层Fig.1 Gray Wolf Grading Distributions and Functions
在灰狼优化算法中,一般取最终的alpha作为优化算法的最优解,beta和delta作为次优解.在灰狼优化算法的迭代过程中,通过omega不断地搜索、包围、攻击猎物,来更新alpha,beta以及delta的位置,最终得到的aplha位置,即是优化算法所得到的最优解.具体迭代公式为

式中:Pt+1表示的是狼群在t+1次迭代时候的位置;Dα,Dβ,Dδ分别表示在第t次迭代过程中alpha,beta,delta与omega之间的距离.
在迭代过程中,alpha,beta,delta指挥最底层的omega进行狩猎来锁定猎物的位置,然后再去对猎物进行捕杀.由于A=2a×r1-a,A会随着a的减小而减小,因此当A的值少于1的时候,就是狼群对猎物发起进攻的时候.
2.2 FCM聚类算法
FCM聚类算法是一种基于目标函数划分的聚类算法,具体来说是使被划分到同一簇对象之间的相似度最大,而不同簇对象之间的相似度最小.FCM聚类算法是普通C均值算法的改进.普通C均值算法对数据的划分是硬性的,而FCM聚类算法则是一种柔性的模糊划分.假设X={x1,x2,…,xn}是需要进行聚类的数据集,标准的FCM会将每个对象xi(1≤i≤N)分配给具有隶属度的矩阵U=(uij).uij表示第i个类别的第j个数据的隶属度.FCM的具体定义为
U∈RC×Nuij∈(0,1),
FCM聚类算法的主要目的是得到每个数据对应每个类别的隶属度和每个类别的聚类中心点C={c1,c2,…,cc}.在标准的FCM聚类算法中,首先随机地初始化隶属度矩阵,然后通过目标函数来更新参数.具体的目标函数为

式中:m为模糊因子,这里取值为2;dik表示xk和第i个聚类中心点vi之间的距离,通常表示的是欧式距离,dik=‖xk-vi‖2.
FCM算法的基本步骤如下:
Step 1 初始化参数,给定聚类的类别数和所能接受的最大迭代次数;
Step 2 初始化隶属度矩阵U=(uij);
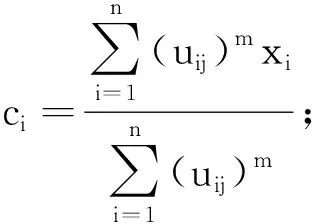
Step 5 判断是否达到结束迭代的条件,如达到便输出,如未达到就返回Step 3.
2.3 基于灰狼优化的模糊C均值局内算法流程
在标准的FCM聚类算法中,不断迭代的目的是为了使目标函数值最小.但在迭代过程中,由于标准FCM聚类算法在初始化参数时采用的是随机初始化方法,而随机的聚类中心会极大影响最终聚类效果.针对这个问题,笔者拟用GWO优化FCM聚类算法的办法来解决,首先采用GWO优化算法找到FCM的最佳聚类中心,然后再采用FCM聚类迭代达到较好的聚类效果.
GWO-FCM算法流程如图2所示.为了找到最优的初始化聚类中心点,选取的狼群适应度函数
式中Jm表示FCM聚类算法中的目标函数.
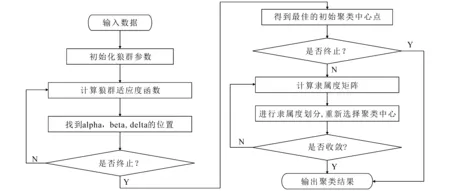
图2 GWO-FCM算法流程Fig. 2 GWO-FCM Algorithm Flow Chart
3 仿真实验
3.1 实验环境
笔者采用Matlab软件对读者借阅行为数据进行分析,在实验过程中所用到的软件、硬件及其参数为:CPU Inter Core i7-9750H,GPU NVIDIA RTX 2060 6G,RAM 16 GB,ROM 500 G,Matlab-R2016a,OS Windows 10.
3.2 实验数据选取与读者分类
读者与图书馆间产生的读者行为信息数据,既有基于传统形式的读者、资源属性信息和行为信息,也有基于互联网产生的读者行为信息,包括读者性别、年龄、阅读辅导、电子资源浏览与检索、访问内容、下载、收藏、到馆时间、到馆次数、图书借阅记录、RFID数据等多种不同类型数据.分析这些行为数据,可帮助图书馆提升服务质量与管理水平.采用传统的聚类算法分析这些读者行为数据,难以寻找到最佳的初始值,对聚类结果影响较大.笔者采用GWO来优化模糊C均值的聚类初始值,是一种改进后的初始值优化方法,能提升最终聚类分析结果的准确度.为了方便验证算法的有效性,笔者选取线下到馆读者借阅图书行为数据进行仿真分析.首先,读者借阅信息是重要的读者行为数据之一,能较直观地反映出读者阅读行为事实.其次,基本上每个图书馆都具备图书借阅管理系统,能轻松、真实地获取读者借阅信息.第三,图书借阅管理系统中线下读者借阅信息是一段时期内相对准确、稳定和连续的读者行为记录数据,符合数据分析要求,通过分析这些数据能客观反映出相应的行为意义.第四,选择何种类型行为数据进行实验,对所采用的聚类算法并没有影响,通过读者借阅信息对算法进行验证,能直接反映出算法在读者行为数据分析中的有效性.第五,选择线下到馆读者借阅数据,能方便同行再现实验过程和结果,激发对数据挖掘算法服务图书馆管理的研究兴趣,促进图书馆事业的发展.
笔者所在单位Interlib图书馆管理系统中,2019年的图书借阅行为数据由5 174条线下到馆读者图书借阅行为数据(不包括还书)组成,每条数据代表读者一年内借阅图书的总数量.
在进行实验前,将线下到馆借阅图书的读者分为“十分活跃型”读者、“活跃型”读者、“一般活跃型”读者和“不活跃型”读者4类,然后根据数据特征将5 174条数据按上述读者类型分类,最后根据聚类实验结果,验证算法的准确性.
3.3 实验算法与参数设置
因传统聚类算法的随机初始化值会影响聚类分析最终结果,因此笔者采用GWO算法优化聚类的初始值,然后分别选取GWO-FCM聚类算法、FCM聚类算法、基于粒子群优化(Particle Swarm Optimization, PSO)的FCM聚类算法(PSO-FCM)[9]及K最近邻算法[10](K-Nearest Neighbor, KNN)进行聚类仿真实验,并对比实验结果.在实验参数的确定中,根据控制变量的原则,参考文献[10-11],将实验参数设置如下:选区的粒子群种群规模大小为20,FCM聚类算法的模糊因子m为2,算法最大迭代次数为100,灰狼种群大小为20.
3.4 实验结果
笔者将5 174条数据输入到GWO-FCM算法中,数据聚类成4类.统计各个类别的读者数目、占比以及图书借阅情况,结果表明:第1类读者393人,占比7.6%,图书借阅25~69次;第2类读者642人,占比12.4%,图书借阅12~24次;第3类读者3 063人,占比59.2%,图书借阅2~11次;第4类读者1 076人,占比20.8%,图书借阅0~1次.
第1类属于“十分活跃型”读者,虽然占比只有7.6%,但他们的借阅量最高.对这类读者,应尽最大努力满足他们的借阅需求,保持他们的阅读热情.第2类属于“活跃型”读者,占比12.4%,他们的借阅量较高.对这类读者,应尽力去发现他们的潜在需求,进一步激发他们的阅读热情.第3类属于“一般活跃型”读者,占比59.2%.这类读者个人借阅量较低,但总体人数最多,总借阅量高.对这类读者,应尽最大努力去唤醒他们的阅读内驱力,提升读者的阅读“黏度”,挖掘他们的阅读潜力.第4类属于“不活跃型”读者,占比20.8%.通常这类读者的学习成绩较差,缺乏阅读兴趣.对这类读者,应通过“帮”“带”等各种导读活动方式,多措并举,慢慢培养他们的阅读爱好.
为了验证GWO-FCM聚类算法的有效性,笔者对KNN,FCM,PSO-FCM和GWO-FCM算法的聚类结果进行分析,分别统计聚类结果中的正确与错误的样本数量,计算聚类分析结果的正确率(表2).
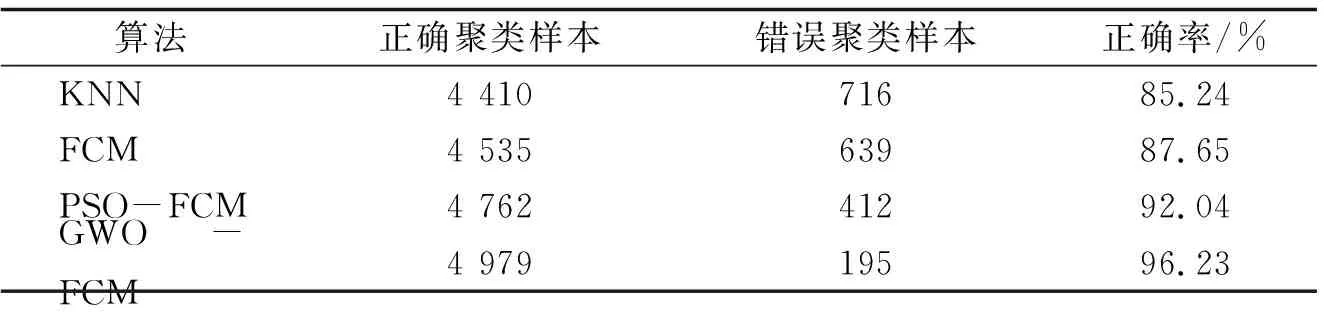
表2 聚类正确率
从表2可以看出,笔者改进的GWO-FCM聚类算法优于其他三种算法.对比PSO-FCM聚类算法和GWO-FCM聚类算法可以发现,对于FCM聚类算法,GWO的优化效果要比PSO的优化效果更好,仿真实验证明了GWO-FCM聚类算法的有效性,GWO-FCM聚类算法能较好地完成读者行为分析任务,提升聚类分析结果的准确度.
4 结语
在对比现有的读者行为分析技术的基础上,笔者提出了一种基于灰狼优化聚类的读者行为分析算法,该算法能显著提升聚类结果的准确度,提高图书馆个性化、精准化服务质量,能帮助图书馆构建科学、合理、高效的服务管理体系.当然,由于设备设施等条件的限制,笔者仅对读者行为数据中的线下到馆读者借阅行为数据进行了分析,尚存在一定的局限性.基于大数据的智慧服务是图书馆未来的发展趋势,对网络环境中读者复合行为的信息数据进行聚类分析,将是未来研究关注的重点.
猜你喜欢
小学阅读指南·低年级版(2021年3期)2021-03-19
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
铁道通信信号(2019年6期)2019-10-08
小太阳画报(2019年1期)2019-06-11
数学大王·低年级(2018年5期)2018-11-01
雷达学报(2017年6期)2017-03-26
快乐作文·低年级(2017年3期)2017-03-25
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
