
长短时记忆网络的自由体操视频自动描述方法
2020-12-09 02:31贺凤张洪博杜吉祥汪冠鸿
华侨大学学报(自然科学版) 2020年6期
贺凤,张洪博,杜吉祥,汪冠鸿
(1. 华侨大学 计算机科学与技术学院,福建 厦门 361021; 2. 华侨大学 福建省大数据智能与安全重点实验室,福建 厦门 361021; 3. 华侨大学 厦门市计算机视觉与模式识别重点实验室,福建 厦门 361021)
在现代人日益注重健康、推崇体育运动的大背景下,体育视频的内容分析与识别成为研究热点.然而,现有的体育视频研究多集中于体育运动的语义分析及识别方面,在体育运动的分类细项研究中,除足球、篮球、高尔夫球、羽毛球等球类运动外,其他运动项目少有涉及[1-8].体育视频自动描述是对体育视频中人体动作的自动描述,是计算机视觉研究中的难点和热点之一.通过计算机视觉和模式识别等技术手段对视频中的人体运动进行分析,可以对视频序列中存在的特定人体运动进行智能化表示和标记.自由体操是竞技体操的典型代表,其自由度最大,动作变化较多,需在规定时间内按照规则表演多个动作组合的成套动作[9].自由体操视频的自动描述研究具有极强的现实意义.对非专业人士而言,自动描述不仅能够提升观赛感受,也能增进观众对自由体操运动的了解;对专业人士而言,可以通过自动描述进行动作数据分析,挖掘自由体操技术创新发展的规律性特征,从而辅助训练.
为了实现对自由体操动作的自动描述,可使用卷积神经网络对自由体操视频特征进行分析[10-19];基于分析得出的特征,通过长短时记忆(LSTM)网络[20-22]实现特征到自然语言的映射,自动生成自由体操分解动作的描述.在数据标注的基础上,自由体操视频的自动描述问题可看成是视频字幕的自动生成问题.视频字幕自动生成的任务是自动生成视频内容的自然语言描述.S2VT[23]是第一个序列到序列的视频描述模型,可实现视频帧序列的输入及文本序列的输出,且输入的视频帧和输出的文本长度可变.然而,对自由体操视频而言,分解动作的关键在于翻转方向、旋转度数、身体姿态,故将包含这些关键动作的视频帧定义为关键帧,通过提取视频中判别力较高的关键帧,提高视频自动描述的精度.本文基于S2VT模型,提出一种长短时记忆网络的自由体操视频自动描述方法.
1 自由体操视频自动描述方法
自由体操视频自动描述的基本框架,如图1所示.
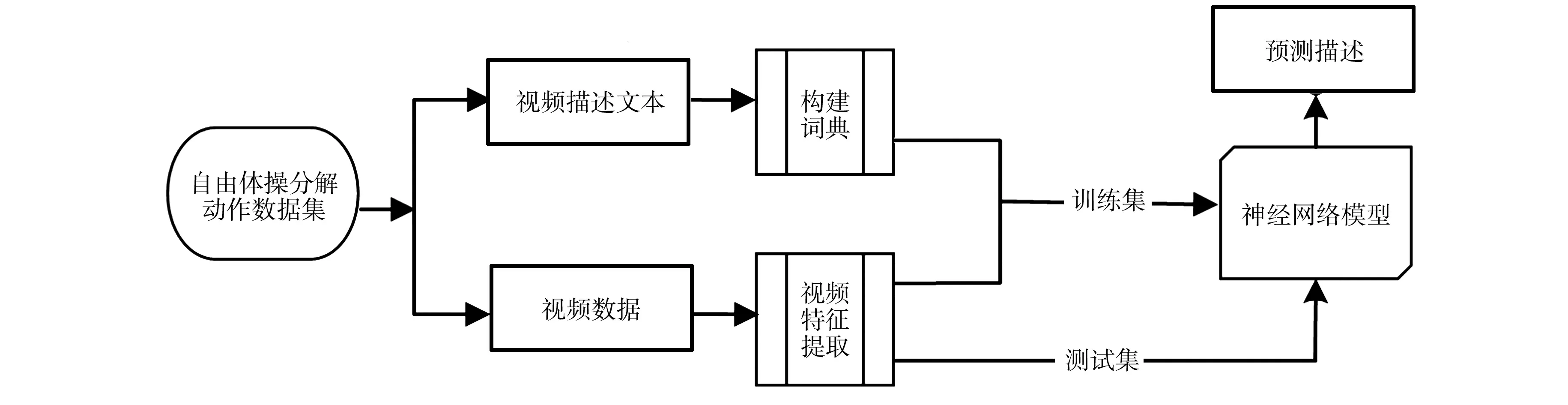
图1 自由体操视频自动描述的基本框架Fig.1 Basic framework of automatic description of floor exercise video
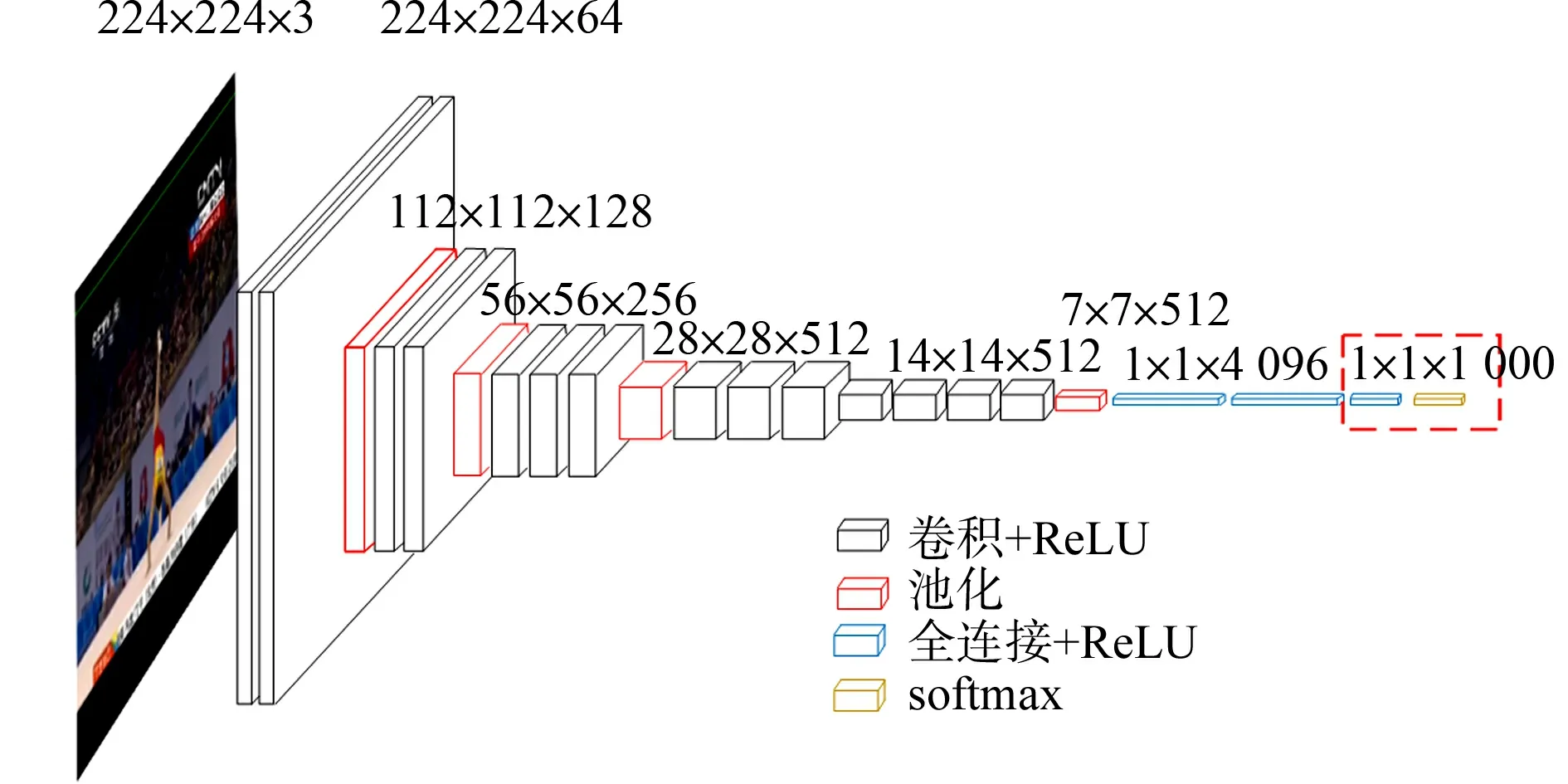
图2 VGG16网络结构图Fig.2 VGG16 network structure diagram
1.1 特征提取
自由体操视频自动描述网络的输入数据包括视频序列和文本序列.通过卷积神经网络提取视频特征,并利用自然语言文本处理方式提取文本特征.
1.1.1 视频特征提取 卷积神经网络对几何变换、形变、光照具有一定程度的不变性,可用较小的计算代价扫描整幅图像[24].因此,卷积神经网络被广泛地应用于图像特征提取.文中使用VGG16[25]卷积神经网络提取自由体操视频的特征.VGG16网络结构图,如图2所示.图2中:ReLU为线性整流函数;softmax为激励函数.
与state-of-the-art网络相比,VGG16的错误率较低,拓展性较强,迁移到其他图片数据上的泛化性非常好.VGG16的结构简洁,整个网络都使用相同大小的卷积核尺寸(3 px×3 px)和最大池化尺寸(2 px×2 px).VGG16模型的输入为227 px×227 px固定尺寸的RGB图片,输出为视频特征序列X=(x1,…,xn).
1.1.2 描述文本处理 通过one-hot向量编码的方式将自由体操视频的描述符转化为特征,统计自由体操标注文本中的词语,构建字典.因为在自由体操分解动作描述中使用的字词种类数量不一,所以在预处理时未对字词进行筛选.
one-hot向量编码的输入是一句话,输出是一个特征.one-hot向量编码的计算方法:先计算自由体操数据集中所有描述的单词总数N;然后,将每个单词表示为一个长1×N的向量,该向量中只有 0 和 1 两种取值,且该向量中只有一个值为 1,其所在位置即当下单词在词表中的位置,其余值为0.
1.2 自由体操自动描述系统
通过长短时记忆网络实现视频特征到文本特征的学习.循环神经网络(RNN)在反向传播过程中易产生梯度消失现象,导致网络参数难以持续优化[26],而LSTM网络作为一种特殊的循环神经网络,可以有效地解决该问题.
LSTM在每个序列索引位置t时刻除了向前传播与RNN相同的隐藏状态ht外,还多了另一个隐藏状态,即细胞状态Ct.此外,LSTM网络通过增加门控单元控制即时信息对历史信息的影响程度,使神经网络模型能够较长时间地保存并传递信息.
因此,LSTM单元可以看作一个尝试将信息存储较久的记忆单元,记忆单元被遗忘门(forget gate)、输入门(input gate)和输出门(output gate)保护,并以此为基础,实现有效信息的更新和利用.
LSTM单元的更新方式为
ft=σ(Wf1ht-1+Wf2Xt+bf)
,
(1)
it=σ(Wi1ht-1+Wi2Xt+bi)
,
(2)
at=tanh(Wa1ht-1+Wa2Xt+ba)
,
(3)
Ct=ft⊙Ct-1+it⊙at
,
(4)
ot=σ(Wo1ht-1+Wo2Xt+bo)
,
(5)
ht=ot⊙tanhCt
.
(6)
式(1)~(6)中:ft,it,at,Ct,ot,ht分别为t时刻各状态的输出值;σ为Sigmoid激活函数;Wf1,Wi1,Wa1,Wo1,Wf2,Wi2,Wa2,Wo2均为权重向量;ht-1,Ct-1分别为t-1时刻的隐藏状态和细胞状态;Xt为t时刻输入的视频序列;bf,bi,ba,bo均为偏移量;tanh为双曲正切激活函数;⊙为向量元素的Hadamard积.
长短时记忆网络结构,如图3所示.图3中:hN,ht+1,hn分别为不同时刻的隐藏状态;XN,Xt-1,Xt,Xt+1,Xn分别为不同时刻的视频输入序列.

图3 长短时记忆网络结构Fig.3 Long short-term memory network structure
将固定维度的自由体操分解动作特征向量X=(x1,…,xn)编码成特征序列,由此得到对应隐藏层的输出H=(h1,…,hn).已知LSTM网络的输出取决于前一个输入序列,将特征向量按顺序输入LSTM网络,可得到一个序列向量的编码映射输出.
当最后一帧图片的特征向量输入后,LSTM网络的输出即为帧序列编码.解码阶段的LSTM送入起始符,促使其将收到的隐藏状态解码成单词序列,输出的单词序列Y=(y1,…,ym),概率为p(y1,…,ym|x1,…,xn),即
.
(7)
解码阶段进行训练时,在已知帧序列的隐藏状态及之前输出单词的条件下,求预测句子的对数似然性.训练目标是使待估参数值θ达到最大值θ*,即
.
(8)
采用随机梯度下降算法对整个训练数据集进行优化,使LSTM网络学习更合适的隐藏状态.第二层LSTM网络的输出z在Y中寻找最大可能性的目标单词y,其概率p(y|zt)为
.
(9)
式(9)中:zt为t时刻的输出;Wy,Wy′均为权重向量.
视频描述的编解码结构图,如图4所示.
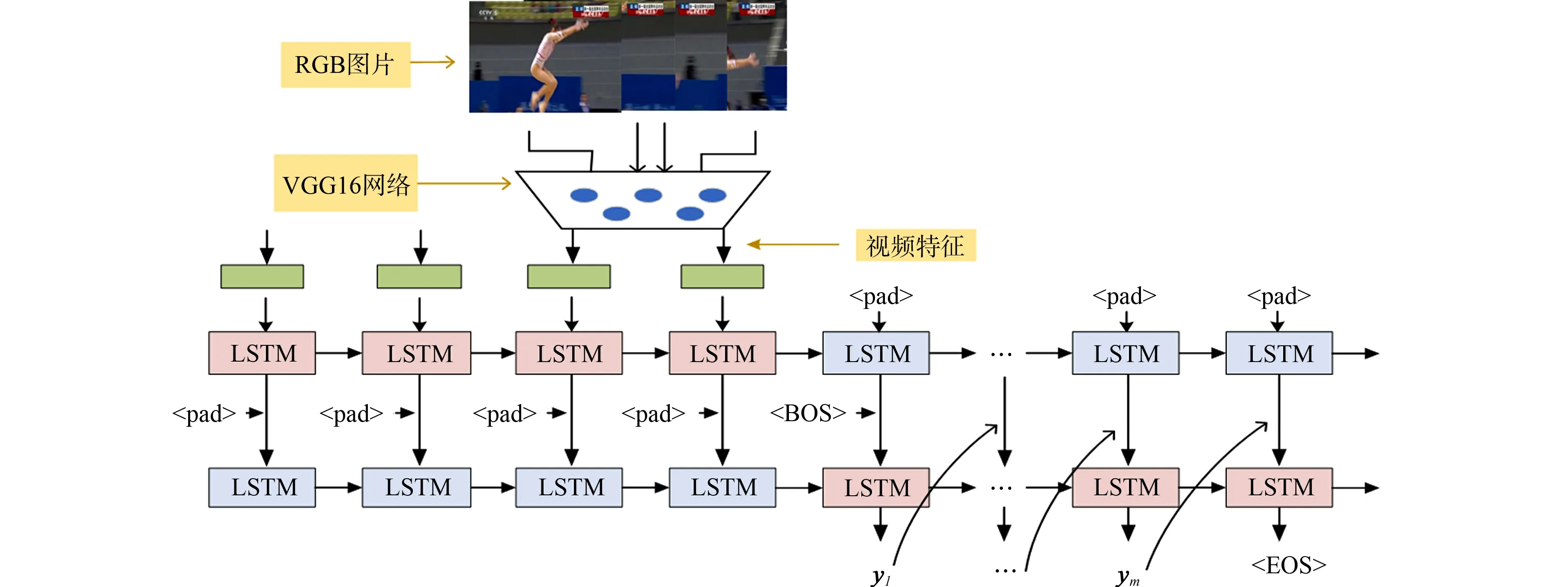
图4 视频描述的编解码结构图Fig.4 Encoding and decoding structure diagram of video description
1.3 注意力机制
人脑对不同部分的注意力是不同的.注意力机制是人类视觉特有的大脑信号处理机制.人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,即注意力焦点,并对这一区域投入更多的注意力资源,以获取更多需要关注目标的细节信息,抑制其他无用信息.
对自由体操分解动作自动描述具有决定性作用的是关键帧,故关键帧的权重应该更大.在网络结构中引入注意力机制[27],可允许解码器对自由体操视频的每个时间特征向量进行加权.采用时间特征向量的动态加权和公式为
.
(10)
.
(11)
式(11)中:score(xi,hj)为第i个隐藏层的输出hj在视频特征向量xi中所占的分值;score(xi,hi)为第i个隐藏层的输出hi在视频特征向量xi中所占的分值,分值越大,说明这个时刻的输入在该视频中的注意力越大.
score(xi,hi)的计算公式为
score(xi,hi)=wTtanh(Wxi+Uhi+b)
.
(12)
式(12)中:w,W,U均为权重向量;b为偏移量.
引入注意力机制后的网络结构图,如图5所示.图5中:α1~αn为不同时刻的隐藏层输出与整个视频表示向量的匹配得分占总体得分的比值;δ为α1~αn在对应隐藏层输出中的比值.
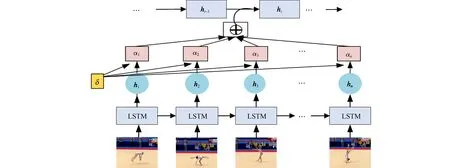
图5 引入注意力机制后的网络结构图Fig.5 Network structure diagram after adding attention mechanism
2 实验结果与分析
2.1 自由体操分解动作数据集的构建
自由体操分解动作数据集的构建是自由体操视频自动描述的基础工作.为此收集了大量高规格赛事的视频,包括奥运会、世界锦标赛、全运会等多个男女重量级赛事视频.
首先,对这些赛事视频进行预处理.一场完整的赛事视频是由多名运动员共同参与完成的,期间会穿插精彩瞬间的回放、慢动作解说、评委打分排名等.在海量的视频里,以运动员为单位进行裁剪,仅保留运动员自由体操的成套动作.构建的自由体操分解动作数据集OURS包括训练集(298个视频)与测试集(45个视频),测试集中的自由体操分解动作均在训练集中出现.由于体育赛事的解说没有字幕,解说员对分解动作名称进行语音解说时,常常会伴随着一些评判,干扰因素很多,无法通过语音识别等技术进行识别.因此,自由体操分解动作数据集只能根据实时体育解说词进行手动标注.
对测试集的298个视频对应的298条描述进行分词和词频统计.单词及频数的统计结果,如表1所示.由表1可知:45.83%的单词出现的频数低于10;仅有4.20%的单词频数为150次以上.
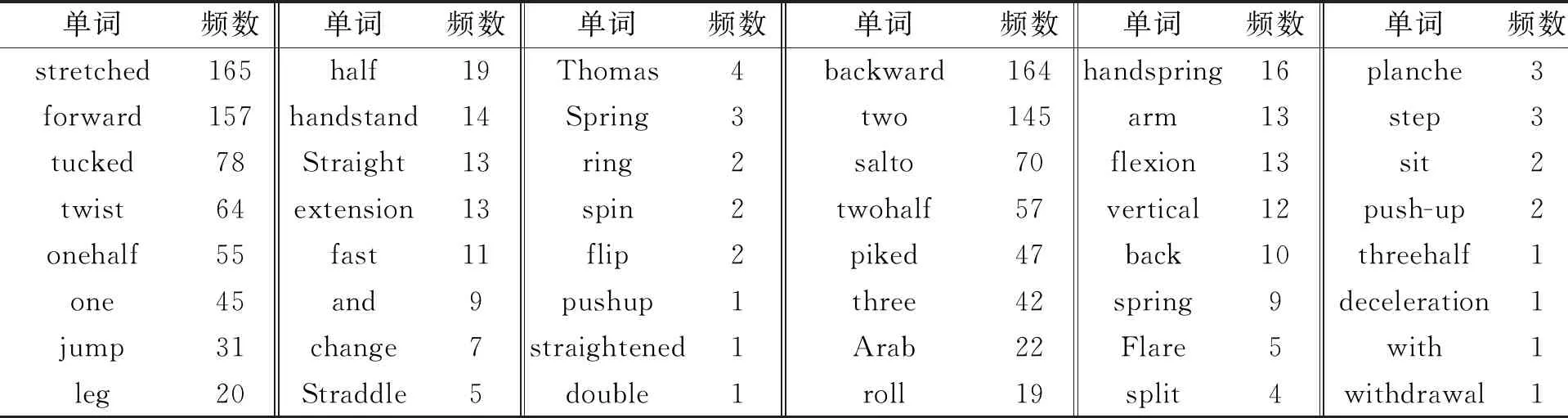
表1 单词及频数的统计结果Tab.1 Statistical results of words and frequencies
2.2 计划采样
训练解码器是将目标样本作为下一个预测值的输入;而预测解码器是将上一个预测结果作为下一个预测值的输入.这个差异导致训练和预测的情景不同.因此,在预测阶段,如果上一个词语预测错误,其后的数据都会出现错误,而训练阶段则不会.
为消除训练解码器与预测解码器之间的差异,需对训练解码器模型进行修改,故引入计划采样方法.训练解码器的基础模型是以真实标注数据作为输入,加入计划采样的训练解码器是以采样率P选择模型自身的输出作为下一个预测的输入,以1-P选择真实标注数据作为下一个预测的输入,即采样率P在训练的过程中是变化的.一开始训练不充分,P可以小一些,尽量使用真实标注数据作为下一个预测的输入;随着训练的进行,P逐渐增大,可以多采用自身的输出作为输入;随着P越来越大,训练解码器最终趋于预测解码器.通过计划采样方法,可缩小训练解码器和预测解码器之间的差异.
2.3 损失函数
使用TensorFlow开源软件库中的TensorBoard可视化工具,读取TensorFlow训练后保存的事件文件,可展示各个参数的变化.S2VT模型(原始模型)和文中模型(经文中方法改进的模型)训练完成后,通过损失函数了解2种模型的损失值随迭代次数的变化情况,结果如图 6所示.图6中:d为迭代次数;L为模型训练损失值.由图6可知:随着迭代次数的增加,S2VT模型与文中模型的函数损失值均逐渐下降,最终趋于稳定收敛状态;相较于S2VT模型,文中模型因复杂度增加,起始的损失值较大,但其收敛速度有所提高.因此,文中模型具有可训练性及有效性.

(a) S2VT模型 (b) 文中模型 图6 损失值随迭代次数的变化情况Fig.6 Change of loss value with number of iterations
2.4 评价指标及性能对比
自由体操视频自动描述的结果是自由体操分解动作的描述语句,是一种自然语言,因此,评价自由体操视频自动描述结果可参考自然语言领域中机器翻译质量的评价指标,即双语评估候补(BLEU).BLEU[28]是目前最接近人类评分的评价指标,BLEU重点关注相同文本下,机器译文和参考译文的相似度,其值越大,则翻译质量越好.
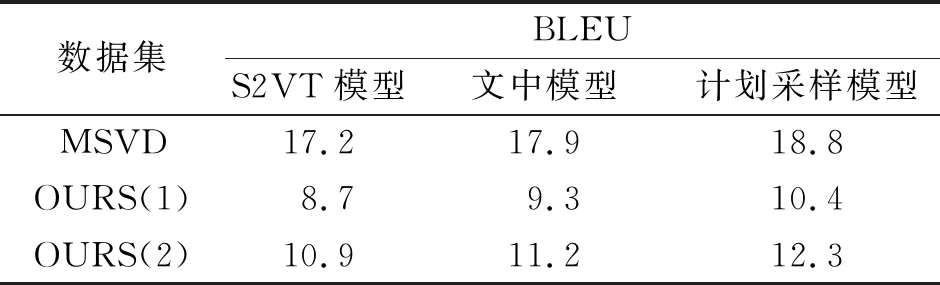
表2 不同模型的BLEU对比 Tab.2 BLEU comparison of different models
在数据集MSVD[29]和自建数据集的两个语料库OURS(1),OURS(2)中,对S2VT模型、文中模型和计划采样模型(引入计划采样方法的文中模型)的性能进行对比.OURS(1)采用最直接的自然语言;OURS(2)则根据专业术语对描述语句进行调整.不同模型的BLEU对比,如表2所示.由表2可知:相较于S2VT模型,文中模型和计划采样模型的性能更优.
由于篇幅所限,仅给出一个实例作为参考.自建数据集OURS上,自由体操视频自动描述实例,如图7所示.图7中:正确描述为forward stretched twist three forward stretched twist one;S2VT模型为twohalf forward onehalf forward;文中模型为onehalf forward one stretched forward;计划采样模型为two stretched 〈PAD〉 stretched 〈PAD〉.由图7可知:文中模型在翻转方向方面的测试结果与正确描述相近,如“forward”;计划采样模型在身体姿势方面的测试结果与正确描述相近,如“stretched”.

图7 自由体操视频自动描述实例Fig.7 Example of floor exercise video description
3 结束语
提出一种长短时记忆网络的自由体操视频自动描述方法,但该研究仍需进一步优化.在数据层面,应进一步丰富自由体操自动描述数据集的建设,均匀不同分解动作的数据量及描述量.在视频特征的提取层面,可以使用目前较为流行的三维卷积操作对自由体操视频进行时域和空域的特征提取[30].此外,可以借助知识迁移更有效地识别、定位体育视频中运动员的动作,并将自由体操视频自动描述方法运用于其他体育项目中,扩大研究成果的使用范围.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小学生必读(低年级版)(2021年10期)2022-01-18
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
阅读(快乐英语高年级)(2020年8期)2020-01-08
家庭影院技术(2019年8期)2019-12-04
智慧少年·故事叮当(2018年11期)2018-05-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
