
集成DS证据理论和模糊集的建筑物检测方法
2020-12-05 01:52张仕山孙振海汪小钦储国中黄书海
遥感信息 2020年5期
张仕山,孙振海,汪小钦,储国中,黄书海
(1.福州大学 空间数据挖掘和信息共享教育部重点实验室,福州 350116;2.卫星空间信息技术综合应用国家地方联合工程研究中心,福州 350116;3.数字中国研究院(福建),福州 350116;4.军事医学研究院,北京 100071)
0 引言
随着人类社会的快速发展,城市人口急剧增长,城市化进程加快,导致建设用地占用其他用地的矛盾日益突出。因此,快速、准确地提取建筑物信息,对于及时掌握城市发展状况,科学合理地进行城市规划和保护土地资源等都具有十分重要的意义。近年来,诸多亚米级分辨率对地观测卫星(如高分二号、高景一号、WorldView系列、Pleiades等)陆续升空,同时自从实施高分辨率对地观测系统重大专项以来,我国的卫星遥感技术也迈入了亚米级时代,实现了满足一定数据体量需求的高空间分辨率数据对地表的全覆盖监测。由于高空间分辨率影像包含地物丰富的光谱、纹理、形状、结构、空间格局等特征,在准确建筑物检测方面具有更大的应用潜力。
在高分辨率遥感影像分析领域,基于像元的影像分析方法往往难以获得理想的结果,因为独立的像元无法完整地表达地物以及地物间的关系,同时提取结果存在明显的“椒盐”现象[1]。面向对象的分析方法[2]在高空间分辨率影像处理中取得良好的结果,是该领域的一种主流分析方法。
建筑物信息提取是遥感信息处理的关键内容,监督分类方法一直在其中发挥着重要作用。Inglada[3]和Huang等[4]将建筑物相关特征输入到支持向量机(support vector machine,SVM)分类器提取建筑物区域。当前最为热门的深度学习也被广泛应用到建筑物提取研究,如Alshehhi等[5]提出一种基于块的卷积神经网络架构用于在高分影像中提取建筑物和道路;范荣双等[6]通过将遥感影像纹理特征输入softmax分类器中获得精度更高的建筑物区域。这些学习方法在建筑物提取方面都表现出十分出色的效果,但是这些方法都要求大量的训练样本,在构建样本方面相当费时费力,而且自动化水平方面还有待提高。
为了避免费时的训练样本构建和提高建筑物提取的自动化程度,非监督的提取方法成为重要的选择。Pesaresi等[7-8]基于灰度共生矩阵(gray-level co-occurrence matrix,GLCM)的对比度纹理特征构建建筑物存在指数PanTex(texture-derived built-up presence index),并将其应用到全球的建成区提取,该特征对于高分影像中独立建筑物的表现能力较弱;Huang等[9]在建筑物的光谱结构特征和一系列形态学操作的基础上提出形态学建筑物指数(morphological building index,MBI),具有很好的提取精度,被很多学者广泛地应用和改进[10-15];Ali[16]和Li等[17]根据建筑物和阴影之间的方向空间关系构建建筑物指数,用以提取建筑物区域;Qi等[18]在MBI指数构建体系启发下通过多尺度均值滤波代替形态学线性操作,构建多尺度滤波建筑物指数(multi-scale filtering building index,MFBI)。
以上方法多是基于单特征的建筑物检测方法,虽然在表达建筑物方面效果良好,但都存在一定的局限性。PanTex和MBI指数是基于建筑物及其阴影在光谱的强对比度特征构建的,在复杂的城市场景中,对于暗表面的建筑物表达能力较弱,同时容易受到与非建筑物的阴影和水体等相邻的亮地物的干扰。而且MBI在非建成区容易受到大量无关对象(如明亮裸地和贫瘠土地、农田、不透水面、道路等)的干扰,使得其在非城市地区(山区、农业区、农村地区等)建筑物检测性能较差[19]。
本文采用的方向特征(direction relation,DR)是Li等[17]基于建筑物和其阴影的方向关系构建的建筑物指数。其基本假设是:建筑物沿着太阳照射方向总是存在阴影,但是这一假设并不总是成立。该特征建筑检测精度不依赖于建筑物本身,所以对于不同材质屋顶的建筑物具有统一的表达能力,但建筑物的检测效果直接依赖于建筑物阴影的提取精度,所以对于密集建筑物区检测能力较弱,且无法检测不存在阴影的建筑物。
MFBI通过滤波函数构建,可以有效抑制高分影像的噪声,减弱对象内的噪声,保证同质区域的完整性,弥补由于 MBI对象内部存在异质性因素干扰导致的提取结果的不完整性。但是由于其不能利用空间信息,又因为建筑物和部分道路具有相似的光谱特征,使得建筑物容易和道路混淆。而MBI特征是通过构建多方向的形态学开运算,从而能够有效地去除道路的干扰,因为道路总是沿1个或者2个方向延伸,而建筑物一般具有多个方向。
基于以上不足,本文采用DS证据理论[20]融合以上3个建筑物特征(MBI、MFBI、DR),综合利用建筑物及其阴影的强对比度特征、光谱特征,以及建筑物和其阴影的空间关系特征,使其能够有效地结合和平衡反映不同特征的多个证据,利用冗余数据进行目标提取可以降低特征检测中的不精确性,同时互补数据可以提供更完整的对于目标的描述。而DS证据理论中最为关键的是需要去定义每个命题的初始概率分配函数(basic probability assignment function,BPAF)。概率分配函数为每个命题分配初始概率mass,在本文中即为每个分割对象属于建筑物的概率。对于如何初始化每个命题的概率分配函数一直是DS证据融合理论的难点。前人的实验多是以分割对象为基元,在基于像元的提取结果的基础上,去初始化对象的mass,同时还需要考虑证据间的关系,往往难以确定[21-24]。模糊集理论[25]通过对事件不确定性信息的分析,用隶属度来描述命题属于某个事件的程度,降低数据间的离散度和不一致性,十分符合BPAF的定义。通过使用隶属度来代替初始的概率值,可以避免证据源间的相关性分析,极大简化BPAF的定义,同时保证提取的精度。
因此,本文集成DS证据理论和模糊集方法,融合不同建筑物特征。对于不同类型建筑物的表达能力,以适应复杂场景下的建筑物检测工作。
1 实验区与数据
本文建筑物提取实验采用2015年获取的厦门市高分二号遥感数据作为源数据,实验区域位于福建省厦门市岛内中部的感兴趣区(图1(a)),其尺寸大小为1 239像素×1 095像素。实验区内建筑物类型丰富,影像分辨率较高,包含不同屋顶材质、不同形状、不同尺寸的建筑物,适用于建筑物提取的实验,以验证本文方法的鲁棒性,并通过人机交互的方式,获得研究区的建筑物分布(图1(b))作为精度验证。
同时为了进一步验证本文方法的泛化能力,以厦门软件园一带为研究区,开展不同分辨率数据下本文方法的适应性分析。多源高分数据(高分一号(GF-1)、高分二号(GF-2)、WorldView-3(WV-3))的分辨率分别为2 m、1 m、0.5 m。同样通过人机交互的方式,获得多源数据厦门软件园的建筑物分布作为精度验证。实验区具体情况如图2所示。

图1 数据情况

图2 多源数据
2 研究方法
本文提出一种基于模糊集的DS证据融合方法,用以检测建筑物区域,以充分发挥多特征在检测建筑物方面的优势。该方法使用3个显著的建筑物特征作为待融合的多源证据,分别是:MBI、MFBI、DR。具体流程如图3所示,包括数据预处理与特征提取、基于模糊集的BPAF初始化、DS证据融合、建筑物提取及数据后处理、精度评价5个过程。

图3 建筑物提取方法流程
2.1 数据预处理
本文在对源数据进行相对配准的基础上,采用GS(Gram-Schmidt)算法对全色和多光谱影像进行融合,该融合方法可以较好地改善原始影像的空间细节特征,且对影像的光谱特征具有较好的保真性[26]。接着采用PIE-SIAS国产软件的多尺度分割方法,获得较优的分割结果。该方法是一种自底向上的分割算法,在初始分割的基础上,通过层次区域融合方法合并相邻对象,构建双层尺度集模型[27-28],并基于局部方差和MI(Moran’s I)的逐步演化分析,确定最优的分割尺度[29-30]。PIE提供多种方式定义对象间的相似性,本文采用eCognition中使用的异质性准则Battz&Schape[31],wshape设置为0.3,wcompt设置为0.5。通过这种方法可以快速获得相对最优的分割结果。图1数据的分割结果如图4所示。

图4 影像分割结果
通过该方法不仅可以快速获得相对最优的分割结果,而且支持便捷的手动调优操作,即通过滑动条手动选择尺度,从而完整地解决分割尺度参数的问题。在计算效率和解决最优尺度问题效率方面都优于其他软件。
2.2 特征提取
以对象为基本单元,提取3个显著的建筑物特征(MBI、MFBI、DR)。同时为了使得特征间具有可对比性,本文进一步将提取的建筑物特征归一化到0和1之间。
MBI建立在建筑物的光谱结构特征和形态学操作基础上,该指数充分考虑建筑物在遥感影像上的不同特征(材质、形状、亮度、对比度等)[9]。根据MBI指数的大小,通过阈值分割的方法,提取建筑物区域。MFBI通过滤波函数构建,可以有效抑制高分影像的噪声。为了充分发挥多光谱信息,将对源数据进行主成分分析(principal components analysis,PCA)获得的第一主成分作为亮度特征影像[18]。DR[17]是给定一个建筑物阴影的参考对象和太阳方位角,根据几何关系构建的。
本文的建筑物阴影是通过假彩色波段组合(近红外、红光、绿光)的IHS颜色空间变换获得的饱和度S(saturation)和强度I(intensity)分量构建的阴影特征提取的[32],并通过建筑物阴影后处理操作进一步提高建筑物阴影的提取精度。
2.3 集成DS证据理论和模糊集方法融合多特征
多个特征产生的建筑物检测结果可能相互吻合,也可能相互矛盾,由此将产生较多检测结果的不确定性。DS证据融合理论采用区间估计的方法描述命题,它提供了对不同来源信息的不精确性和不确定性的估计。
假设n个命题组成的假设空间为Θ,2Θ表示命题空间的幂集,根据不同的数据源信息,可以为2Θ中的任意命题分配一个概率值m(A),A表示任意命题。其满足式(1)。
(1)
式中:m表示命题空间上的概率分配函数BPAF;m(A)表示命题A的基本概率质量mass,反映对命题A本身的信度大小。通过模糊集方法实现对BPAF函数的定义。
在相对论域U上的一个集合A,对于任意x∈U,通过HA(x)∈[0,1]来表示x属于A的程度,由HA(x)所确定的集合A成为U上的一个模糊集,HA(x)称为A的隶属度函数(membership function),对于某一x∈U,HA(x)称为x对于A的隶属度,即为DS证据理论中的m(A)。
常见的S型隶属度函数参数易于调节,可以较好地反映出地物的特征,同时在模糊分割方面具有较好的鲁棒性和准确性。因此,采用S型隶属度函数进行DS证据融合理论中基本命题的BPAF定义。
根据阈值分别计算第k个建筑物特征中对象属于建筑物的隶属度Hkb,则属于非建筑物的隶属度为:1-Hkb。计算过程如公式(2)所示。
(2)
式中:bk=(ak+ck)/2;ak参数的意义是尽量避免非建筑物被误检成建筑物,即保证最大的提准率;ck参数的意义是尽量使得建筑物区域都被检测出来,即保证最大的提全率;xi表示第i个对象的k特征的均值。
DS证据理论通过合并多重证据作出决策。令m1,m2,…,mk表示k个建筑物特征的基本概率质量,则融合后的命题最终概率质量定义如式(3)所示。
(3)
式中:m(B)即为Hkb;Bi表示基本事件,即对象类型,对象是否属于建筑物;Ab表示对象类型为建筑物的事件。根据以上公式计算获得融合后的概率值。本文采用以下决策方式判断对象是否属于建筑物区域。Ri=1表示对象i属于建筑物。
(4)
2.4 建筑物后处理
在以上方法提取建筑物区域的基础上,对建筑物区域进行后处理。本文采用的后处理框架主要包括光谱约束、阴影约束和形状约束[33]。
1)光谱约束。光谱约束主要通过归一化植被指数(normalized vegetation index,NDVI)和色调分量H(hue)实现的。高亮的植被和土壤是建筑物检测主要的误差来源。由于蓝色屋顶材质的建筑物呈现较大的NDVI值,容易同时被植被掩模去除。通过联合NDVI和H的方式,可以剔除这部分建筑物的提取误差。约束规则如式(5)所示。
if NDVI(x)>TNDVIandH(x)>Ththen
Build(x)=0
(5)
式中:TNDVI和Th表示NDVI和H特征的阈值,分别通过OSTU和直方图法确定。
2)阴影约束。阴影约束是基于大部分建筑物在太阳照射方向总是存在阴影这一基本原理实现的。阴影约束的精度直接依赖于建筑物阴影的提取精度。建筑物阴影采用计算方向特征时所用到的建筑物阴影结果。在城市区域建筑物阴影的干扰主要来自水体、非建筑物阴影(植被、高架桥、道路等)、暗地物等,建筑物阴影后处理环节主要也是围绕这些干扰项展开的。水体区域的方差一般要小于阴影区域的方差,通过该方式可以消除部分水体的干扰。在城市区域,非建筑物阴影主要由植被阴影和高架桥阴影所组成,可以通过面积约束和形状约束(长宽比)的方式,以及通过NDVI提取的植被区域基于太阳方位角反向提取植被阴影,以消除这些地物阴影的干扰。
3)形状约束。形状约束主要通过面积阈值(像元数量)和最小外接矩形长宽比实现,进而剔除小面积、减少狭长的误提现象,例如狭长道路、小面积裸地等的干扰。约束规则如式(6)所示。
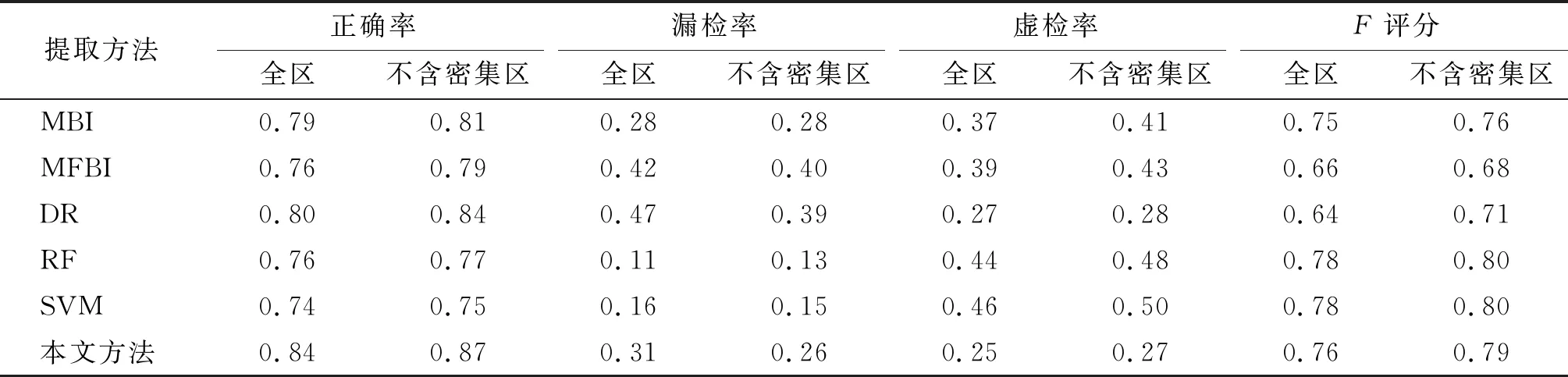
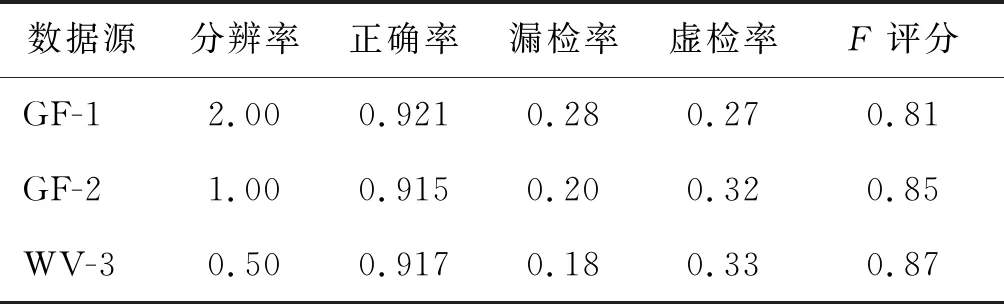
if ratio(x)>Tratioor area(x)>Tamaxor (6) 式中:ratio(x)和area(x)表示对象x的最小外接矩形的长宽比和面积;Tratio为长宽比的阈值;Tamax和Tamin为建筑物的最大面积和最小面积。这些阈值参数主要通过经验设置。 为了定量评价采用本文方法检测建筑物的精度,本文采用4个广泛使用的指标用于定量评价提取的精度,分别是正确率、漏检率、虚检率3个指标[34],以及1个综合指标:F评分。正确率代表能检测到真正建筑物的精度;漏检率表示在提取的过程中真实建筑物误判为非建筑物的概率;虚检率表示在提取的过程中非建筑物误判为建筑物的概率;而F评分是对提取结果精度的综合评价。 基于以上特征分析时设置的参数,提取建筑物相关特征(图5)。从图上可以看出,MBI和DR是正向指标特征,而MFBI是负向指标特征。对比3个建筑物特征可以发现:MBI特征中潜在的建筑物区域呈现高值,在图上表示高亮的区域;而MFBI特征与之相反,潜在的建筑物呈现低值(甚至是负值)。从总体而言,MBI特征在表现建筑物方面要优于其他的特征。MBI、MFBI特征都可以很好地把建筑物和背景区域区分开来。DR特征值范围是0~1,值为1的部分表示为阴影区域,沿着太阳照射的反方向投射建筑物区域,越靠近阴影区域和越符合太阳照射方向的像元值越大,即为潜在的建筑物区域。 图5 建筑物特征 基于以上提取的建筑物特征,通过面向对象分析的方法提取建筑物区域(图6(a)~图6(c)),并在eCognition软件平台下基于MBI、MFBI、光谱、形状特征(PSI(pixel shape index)、长宽比),采用随机森林分类器(random forest,RF)和支持向量机提取建筑物区域(图6(d)、图6(e));最后基于真实的研究区建筑物分布图,获得每个特征建筑物提取结果的误差空间分布图(图6(a)~图6(e))。从图上可以看出,MBI和MFBI特征在表现建筑物方面的全局性能上要优于方向特征,但是MBI和MFBI特征在误差分布图中红色区域(虚检)要明显比方向特征占比大,主要是因为DR特征的提取精度直接受到建筑物阴影提取精度和分割效果的制约,其受到的干扰因素更少。同时在建筑物提取结果的完整性方面,DR特征也要明显优于其他2种特征的提取结果。DR特征的虚检主要是由高架桥以及一些其他中高层非建筑地物的阴影导致的,同时建筑物间的道路也会导致虚检情况发生;MBI特征的虚检主要来源于道路;MFBI特征的虚检部分主要由道路和高亮植被组成。在建筑物和道路混淆方面,主要是因为建筑物和道路具有相似的光谱特征,同时这一点也将影响对象分割的结果。DR特征在区分建筑物和道路方面效果最好。MBI在建筑物和道路混淆情况相对于MFBI特征有一定的改善,因为MBI特征是通过多方向、多尺度的形态学操作构建的,建筑物一般是沿多个方向的延伸,而道路多是沿着1到2个方向,所以在区别建筑物和道路方面要优于MFBI特征。 在图上低矮密集的建筑物区域,MBI和MFBI特征呈现黄绿(正确检测和漏检)混合的情况,且MBI误差分析中正确检测部分面积最大,而DR特征中密集建筑物物区域基本都呈现绿色(漏检)。这说明,MBI特征在表达低矮密集建筑物区的能力方面要明显优于其他2种特征;DR特征对于此类建筑物提取效果最差,主要是因为低矮密集建筑物的阴影较少,甚至在影像上都不存在阴影,这就导致基于建筑物与其阴影方向关系构建的方向特征在检测该类建筑物时直接失效。但是方向特征也具有其他特征所不具备的优势,即其他特征对于建筑物屋顶的材质较为敏感,对于暗屋顶建筑物的检测结果不佳,但是对于方向特征来说,只要暗屋顶建筑物阴影被提取出来,该特征就能很好地检测出建筑物。在实验区的其他区域,3种特征均存在大小不一的漏检现象,在影像上表示为绿色区域。从图6(d)、图6(e)可以看出,2种机器学习方法提取的结果较为相似,图中漏检的部分较少,要明显少于其他单特征的提取结果。基本建筑物都被成功检测,但是同时也导致了大量的虚检情况,虚检主要位于城市内的道路和裸地,而且建筑物检测结果在建筑物完整性方面要明显弱于其他方法,普遍存在建筑物连接成片的情况。 采用集成模糊集的DS证据理论方法结合以上3个建筑物特征在表现不同类型建筑物方面的能力,用以检测建筑物区域。检测结果和误差分布如图7所示。 图7 本文方法提取结果和误差分布 从图7可以看出,本文方法正确提取的建筑物在完整性上要优于MBI和MFBI特征提取的结果,与DR特征提取结果较为相似。漏检部分主要集中在低矮密集建筑区和低矮暗屋顶建筑物,对于低矮密集建筑区的检测能力和MFBI特征较为接近,介于MBI和DR特征检测能力之间。MBI特征的检测结果要比本文方法检测结果更完整,这可能是因为方向特征在检测密集建筑区方面效果较差,从而导致融合的结果对于这一类建筑物表达效果不佳。其他部分的漏检主要是由于分割效果导致的。而对于低矮暗屋顶建筑物类型,3种特征和本文方法均无法表达。虚检部分主要集中在高亮的裸地和道路区域,相对于其他3个特征有明显的改善,虚检面积更小。 根据上面的评价指标对建筑物检测结果作出定量评价。为了进一步分析本文方法在非密集建筑区的检测精度,对去除密集建筑区的建筑物检测结果作二次精度评价。建筑物检测结果的评价指标如表1所示。 从表1可以看出,本文建筑物提取方法在正确率指标上都要高于其他单特征和机器学习的提取结果。本文提取方法正确率达到了0.84,而其他方法的检测结果正确率都要低于本文方法,分别是0.79、0.76、0.80、0.76、0.74。在F评分评价指标方面,机器学习方法最高都达到了0.78,本文方法次之,达到了0.76,接着是MBI特征提取方法的0.75,MFBI和DR特征的F评分指标最低,只有0.66和0.64。本文方法在虚检率指标方面只有0.25,要显著小于其他方法(MBI和MFBI这2种方法的0.37和0.39,以及机器学习方法的0.44和0.46),在虚检方面有了明显的减少,对最终的检测精度影响较大。但是在漏检率方面,本文方法为0.31,要略高于MBI特征提取方法的0.28,但是这2种方法都要显著小于MFBI和DR特征提取结果的0.42和0.47。其中,最低的当属机器学习方法,分别是0.11和0.16。这主要是因为本文方法在检测低矮密集建筑区时,受DR特征的影响导致最终的检测效果不佳,检测能力介于MBI和DR特征之间。而实验区中存在2个较大的低矮建筑区,这就导致本文方法在漏检率方面要高于MBI特征的检测方法。综合考虑所有指标情况,本文方法的提取结果要明显优于其他提取方法,本文提出的建筑物检测方法可以较好地区别建筑物和背景区域,较高精度地提取建筑物区域,并保证建筑物的完整性。 表1 建筑物提取结果精度评价 去除密集建筑区后的精度评价指标在正确率和F评分上都有一定程度的提高,提高程度保持一致,其中机器学习方法的相关指标变化不大,只是在虚检方面有了较大的增加。MBI方法在正确率提高了0.02,达到了0.81,MFBI和本文方法提高0.03,分别达到0.79和0.87,机器学习方法提高不大,只有0.01,其中,DR方法提高程度最大,为0.04,达到了0.84。DR方法在F评分方面提高程度最高,达到0.71,其他方法提升程度基本一致。本文方法在漏检率方面改善效果最好,降低了0.05,其他单特征方法降低程度均小于等于0.02。但是在虚检率方面,除了机器学习方法其他方法都有不同程度的增加,MBI和MFBI方法增加幅度最大,为0.04,DR和本文方法相对幅度要小于以上方法,分别为0.01和0.02。综上所述,本文方法在去除密集建筑区后的精度提高程度要大于其他方法。 以上提取的建筑物结果均没有经过统一的建筑物后处理操作。为验证建筑物后处理流程对建筑物检测结果的影响,本文对6种方法提取的结果进行统一的后处理操作,后处理结果如图8所示。 图8 建筑物后处理结果与精度分析 图8(a)~图8(f)的精度分析图中,正确部分表示被正确去除的非建筑物,错误部分表示之前被正确检测,经过后处理流程后被错误去除的建筑物。由于密集建筑区的影响,本次后处理中除了机器学习方法,其他方法未添加阴影约束。从图上可以看出,6种方法提取的建筑物结果经过后处理流程后精度均获得一定的提高,但同时也会将之前正确检测的部分区域去除(图8(a)~图8(f)中红色区域)。之前虚检部分经过后处理流程被正确去除的部分(图8(a)~图8(f)中黄色区域)在图中占据大部分区域,主要集中在实验区中间的2条主干道区域,以及高亮的植被区域;而错误去除的部分主要集中在建筑物轮廓区域,以及部分屋顶材质光谱特征和植被相似的建筑物区域。MFBI特征提取结果经过建筑物后处理流程后效益最佳,从图8(b)中可以看出大部分的黄色误提部分都被去除;其次是MBI特征提取方法和本文方法;后处理收益最小的是机器学习方法,只有中间交叉的主干道存在部分被正确去除的非建筑。从全局上分析,在牺牲一定程度的建筑物完整性的基础上,获得更大程度的精度提高是利大于弊的。同时,也对建筑物后处理结果作出定量评价,并与未经过后处理的结果作对比分析,评价指标如表2所示。 表2 建筑物提取结果精度评价 从表2可以看出,经过后处理流程后,6种方法在正确率方面都有一定的提高,MFBI方法正确率提高程度最大,达到了0.80,提升了0.04,其他5种方法提升程度相差不大,分别是0.02、0.01。本文方法和机器学习方法在F评分指标方面表现出略有增长的趋势,而其他方法则呈现降低趋势。在漏检率方面,基于特征方法均有一定程度的提高,提高程度基本相同,DR特征提高程度为0.03,其他特征都是0.04,RF方法提高0.02,而SVM方法降低了0.01。4种特征方法在虚检率方面均有不同程度的降低,降低幅度较大的是MFBI和DR特征,分别是0.11和0.09,MBI和本文方法降低幅度基本相同,分别为0.05和0.06,而机器学习方法变化幅度较小,其中RF降低了0.03,SVM降低了0.02。经过后处理流程后,本文方法的正确率指标相对于其他方法最高,达到了0.85,其他方法在正确率方面差异不大。而在F评分方面,机器学习方法要高于本文方法,高出了0.02,达到了0.79。在虚检率方面,本文方法和DR特征方法要显著低于其他方法,分别是0.19和0.18,机器学习方法最高,分别为0.47和0.48。这4种基于特征的方法在漏检率方面表现出较高的值,都大于0.30,DR方法甚至达到了0.50,主要是由于对低矮密集建筑物区域检测能力不足导致的,而机器学习方法在密集建筑区表现出较高的检测能力,使得机器学习方法的漏检率最低,只有0.13和0.15。 以厦门软件园一带为研究区,开展不同分辨率情况下本文方法的适应性分析。以相同的方法分别对多源高分数据(GF-1、GF-2、WV-3)进行建筑物检测,检测结果如图9所示。 从整体上分析,基于GF-1、GF-2、WV-3数据的建筑物检测结果精度较高,从图上黄色正确检测部分可以得出大部分建筑物都被成功检测,满足进一步分析的需求。3种数据源提取结果都有不同程度的虚检,相对来说,WV-3检测结果的虚检率要大于其他2种数据。虚检部分主要集中在城市道路、高亮裸地、高层非建筑物等,尤其是和水体等暗地物相邻的地物极易被误提成建筑物。主要是因为建筑物和这些地物具有相似的光谱特征、对比度特征等,同时对象分割的精度也可能影响虚检率。从漏检方面来看,3种数据的漏检部分都相对较少,主要集中在建筑物轮廓部分和具有暗屋顶的建筑物部分,其中建筑物轮廓漏检主要是由于对象分割的精度导致的,而对于暗屋顶的建筑物检测能力都普遍偏弱。 图9 多源数据建筑检测结果和误差空间分布 对以上多源数据建筑物结果进行精度评价,评价结果如表3所示。从表3可以看出,3种数据的建筑物检测结果的正确率相差不大,都大于0.91,其中GF-1正确率最高,达到了0.921,而GF-2相对最低,为0.915。在F评分评价指标方面,GF-2和WV-3之间相差不大,分别为0.85和0.87,但是都要高于GF-1,GF-1的F评分只有0.81。从分辨率上来看,越高分辨率数据检测结果的F评分也越高。3种数据的虚检率相差不大,GF-1相对最低只有0.27,而GF-2和WV-3要比GF-1要高,分别达到了0.32和0.33,从图3、图7(c)~图7(f)也可以得到相似的结论,在图中表现为具有相似的红色虚检的面积占比。分辨率的增加也会导致虚检率的增加,主要是因为随着分辨率的提高,“异物同谱”的现象更加严重,从而导致虚检率提高。在漏检率指标方面,GF-2和WV-3相对最低,分别为0.20和0.18,GF-1要显著大于其他2种数据,达到了0.28。漏检率和分辨率呈现负相关,随着分辨率的提高,漏检率越来越低。主要是因为随着分辨率的提高,影像上地物对象的异质性加剧,“同物异谱”现象加剧。 表3 多源数据建筑物提取结果精度评价 本文提出一种集成模糊集的DS证据融合方法,用于检测高空间分辨率影像中复杂场景下的建筑物区域。该方法通过模糊集理论定义DS证据理论中关键的BPAF函数,极大简化了DS证据理论的实现,从而实现3个建筑物特征(MBI、MFBI、DR)的融合,最后根据融合后的证据提取最终的建筑物区域。该方法能够有效地结合和平衡不同特征的多个证据,较大地提高检测精度。本文方法的建筑物检测精度要优于其他单特征和机器学习的提取方法,提取的建筑物正确率达到0.85,F评分指标达到了0.77。在非密集建筑区域正确率可以达到0.87,F评分为0.79。本文建筑物检测方法适应于不同分辨率的多源数据,均能获得较高的检测精度。以厦门软件园一带为研究区,以GF-1、GF-2、WV-3为测试数据,检测结果的正确率均大于0.91。但是受到输入的建筑物特征的影响,本文方法在检测低矮密集建筑区方面效果不佳,同时由于分割效果和建筑物阴影提取精度的制约,本文方法在建筑物完整性方面和后处理效果方面还有待提高。 在本文方法的框架下,理论上可以实现任意数量和任意组合的建筑物特征的融合,实现多源数据的互补,充分发挥和整合多源数据对建筑物不同的表达能力,以进一步提高建筑物检测的精度。本文方法对于建筑物特征分析方面还停留在定性层面上,后续工作可以在增加建筑物特征的基础上,引入定量分析,以进一步完成对建筑物特征的筛选工作,选择最具有代表性的建筑物特征参与后续的融合操作,期望能够获得最佳的提取精度。
area(x)2.5 建筑物提取精度评价指标
3 结果与讨论
3.1 基于单特征和机器学习的建筑物提取结果分析

3.2 基于融合特征的建筑物提取结果

3.3 建筑物后处理精度分析


3.4 多源数据适应性分析

4 结束语
猜你喜欢
今日农业(2020年20期)2020-12-15
文苑(2020年11期)2020-11-19
中华养生保健(2020年7期)2020-11-16
中国诗歌(2019年6期)2019-11-15
能源(2018年10期)2018-12-08
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
数学大王·中高年级(2016年4期)2016-05-14
