
学习因子随权重调整的混合粒子群算法
2020-12-04 08:01:00曹晓月张旭秀
计算机技术与发展 2020年11期
曹晓月,张旭秀
(大连交通大学 电气信息工程学院,辽宁 大连 116021)
0 引 言
粒子群算法(particle swarm optimization,PSO)是Kennedy和Eberhart教授于1995年联合提出的一种基于群体智能的随机进化优化算法[1]。PSO算法因其需要调整的参数较少、收敛速度快、精度高等优点被快速接受并运用在电磁优化[2-3]、参数优化[4-5]和电力系统[6]等领域。对粒子群算法的改进也层出不穷。其中对惯性权重和学习因子的改进最为简单快捷。Shi等人引入随进化次数而线性递减的惯性权重w[7],这使得PSO算法的运行速度和搜索能力得到了大幅度提升。文献[8]中通过随机分布的方式获取惯性权重,文献[9-10]将sigmoid函数引入到惯性权重中构造动态调整因子,这些都提高了算法的全局和局部的搜索能力。有的学者将学习因子进行改进[11-13]。
但是惯性权重和学习因子等参数的独立调整削弱了算法的智能性。该文结合对上述文献中对粒子群算法改进的分析,使学习因子随惯性权重非线性变化,并且加入差分进化算法中的交叉算子来增加种群多样性,并对算法进行复杂性分析。最后同相关算法进行对比,证明算法的有效性。
1 基本粒子群算法
PSO算法首先初始化一群粒子Xi=(xi1,xi2,…,xin),在每一次迭代过程中,粒子通过个体极值pbest和全局极值gbest更新自身的速度和位置,更新公式如下:
(2)
其中,w为惯性权重,表示粒子继承了当前速度的程度,w越大,全局的搜索能力越强,w越小,局部的搜索能力越强;c1,c2为速度因子,其中c1是“自我认知”,表示粒子向自我的学习能力强弱,其中c2是“社会认知”,表示粒子向社会的学习能力强弱;rand1和rand2是分布在[0,1]之间的随机数;t为当前迭代次数;vid为粒子的运行速度。粒子群算法存在的主要问题是随着迭代次数的增加,搜索速度变慢和易陷入局部寻优。而w则是控制速度和全局搜索的重要因素,学习因子反映了微粒之间的交流情况,平衡了算法的全局探测和局部开采的能力。因此,对惯性权重和学习因子的改进使具有重要意义。
2 改进的粒子群算法
2.1 状态因子的提出
粒子在每次迭代都是将当前值与最优值比较,更新出全局最优值。但并不是所有粒子都具有这种趋向最优的特性。在搜索过程中,总会有一些粒子会离最优值较远或者集中于一个“自认为”最优的区域进行搜索。这时,就需要统筹兼顾所有粒子,用类似数学上的方差来表示粒子的当前质量。则提出粒子状态因子如下:
(3)
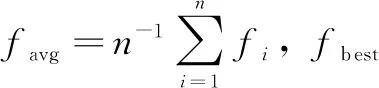
全局最优值的取值决定于个体极值的变化,全局和个体的关系也反映了粒子的当前状态。在求极小值问题时,个体极值要小于全局最优值,当然也小于平均值。平均值反映了所有粒子的平均质量。
2.2 惯性权重的改进
Shi等人[7]提出线性递减w的方法,实验表明虽然LDW在函数优化速度和精度方面有了提升,但是随迭代次数改变的惯性权重的方法对于最优解附近才有效。如果搜索初期没有找到最优解,随着搜索次数的增加,惯性权重逐渐减小,局部的搜索能力增强,粒子就会跳过最优解而陷入局部最优。该文提出了一种新的惯性权重更新公式,使惯性权重随粒子的迭代次数和搜索状态进行更新。公式如下:
(4)
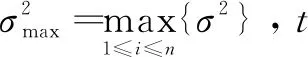


2.3 学习因子的改进
粒子在搜索过程中通过跟踪个体最优值和全局最优值进行更新,所以加强粒子个体之间和全局之间的交流对提高算法速度有着重要意义。通过借鉴对学习因子已有的研究发现,w和c1,c2的关系变化如图1和图2所示。
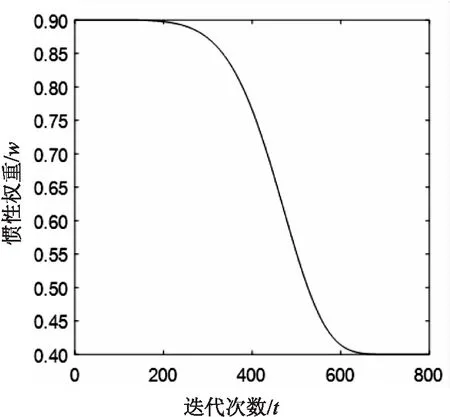
图1 w-t变化曲线
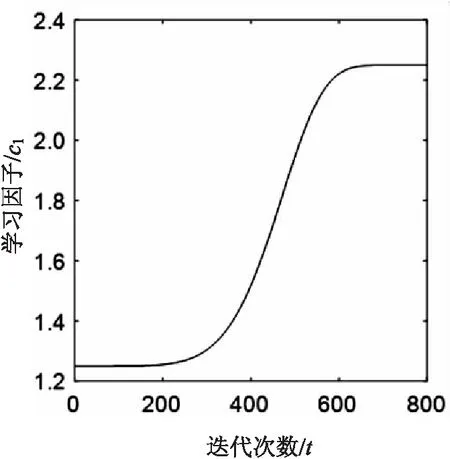
图2 c1-t变化曲线
由图分析可知,c1与w的关系类似于logistic回归分析,图形是一个s型变化曲线,二者呈正相关变化。并且满足:
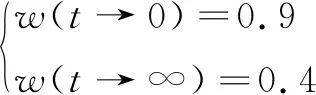
综上,将w表示为c1的函数,并且满足c1+c2=2.5。c1和c2的更新规则如下:
(5)
其中,c1采用logistic回归曲线方程,这个函数满足了中期随w快速变化,加快算法的速度;后期缓慢变化,配合w进行精细搜索,平衡算法的全局和局部的搜索能力。c1+c2=2.5,是此消彼长设置。前期c1较大而c2较小,此时粒子的自我学习能力较强而社会学习能力较弱,有利于加强算法的全局搜索;后期c1较小而c2较大,此时粒子的社会学习能力较强而自我学习能力较弱,有利于算法局部的精细搜索。
3 种群多样性的保持
粒子群算法的缺陷之一是随着搜索的进行多样性会降低,并且随着上述提出的非线性因子的加入,粒子多样性缺失会更加严重,导致陷入局部寻优。为了解决这一现象,加入差分进化算法中的交叉算子来提高算法的全局探索能力,保持种群多样性,利用DE算法的变异策略产生候选解来更新位置公式。
3.1 变异策略的加入
差分进化算法是基于种群的随机优化算法[14-15],此算法在同一种群中将父代个体和其他个体之间通过交叉得到差异信息,从而获得候选解。
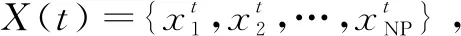
变异操作的主要目的是生成变异个体。该文采用策略一来产生变异个体。变异策略如下:
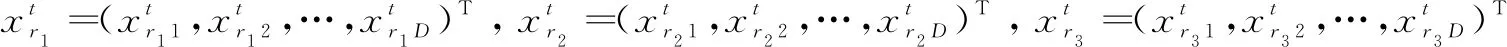
3.2 交叉算子的加入
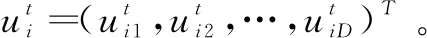

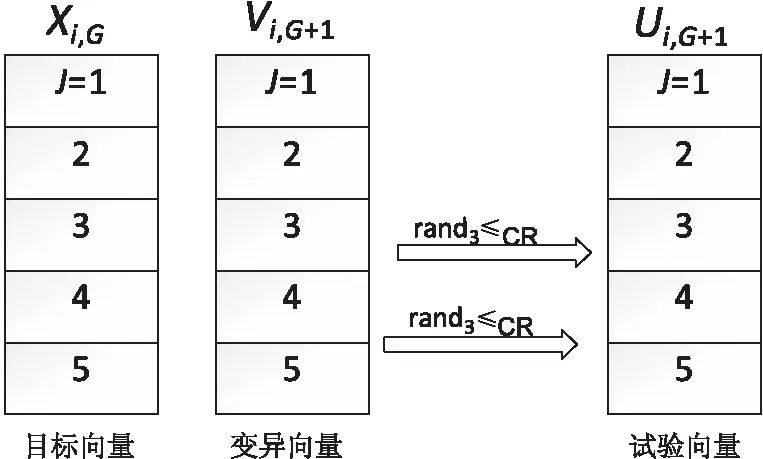
图3 5维向量交叉原理示意图
综上提出新的位置更新公式:
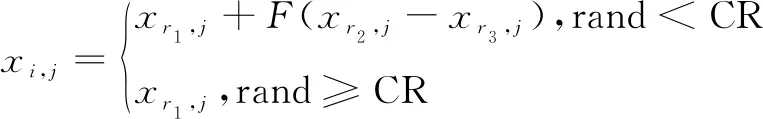
(6)
r1,r2,r3∈{1,2,…,N}是随机的三个个体且互不相同。这里缩放因子F取0.5。CR为交叉算子,这里取0.1。当rand产生的随机数小于CR时,采用差分交叉算子来更新位置公式;当rand产生的随机数大于CR时,采用经典粒子群算法的更新位置公式。
3.3 算法流程
学习因子随权重调整的混合粒子群算法的流程如下:
Step1:初始化粒子,令其值约束在规定的范围内,并令每个粒子都具有位置向量Xi,速度向量Vi;
Step2:计算粒子的适应度值,将fi设置为粒子当前位置的适应度,计算出favg为平均适应度值;
Step3:将粒子的适应度值与自身经过的粒子的所有位置进行比较,将较好的一个作为当前的最好位置,记为pbest;将粒子的适应度值与所有粒子经过的位置进行比较,将较好的一个作为全局的最好位置,记为gbest;
Step4:如果rand<变异率,采用差分交叉算子更新粒子位置,否则根据标准粒子群算法来调整微粒速度和位置;
Step5:对所有粒子相继按式(6)更新位置公式;按式(4)、式(5)计算惯性权重w,c;计算适应度值;
Step6:如果算法达到最大迭代次数,执行步骤8,否则执行步骤3;
Step7:将迭代次数加一,执行步骤3;
Step8:达到最大迭代次数,输出gbest。
4 收敛性分析
4.1 收敛准则
在分析DSPSO算法时,需要用到一些假设和定理,下面简要给出它们的内容。
定义:给出一个函数f,其解空间为Dn~D,S为Dn的一个子集;在S中存在一个点z,它能够使函数f的值最小或能够使函数f的值在S上能够有较小的下确值。
假设1:f(H(z,δ))≤f(z),若δ∈s,则f(H(z,δ))≤f(δ)。H是在待求解空间产生的一个解的函数,并且应保证H所产生的所有新个体优于当前个体。
4.2 DSPSO算法的全局收敛证明
引理1:DSPSO算法满足假设1。
证明 由式(1)、式(6)可知,DSPSO算法的可描述为:
所以假设1很容易证明。
引理2:收敛性证明。
证明:不考虑式(1)中的随机分量rand(i=1,2),并假设pd为一常量且定义如下:
将上式带入到式(1)中
vt+1=w*vt+c(pd-xt)
其中,c=c1+c2。
设yt=pd-xt,则速度和位置更新公式可简写为:
vt+1=ω*vt+c*yt
yt+1=-ω*vt+(1-c)*yt
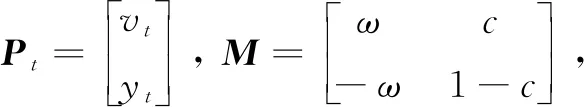
当(ω+1-c)2≠4ω时,可以定义矩阵N满足下式:
其中,
假设Qt=NPt,则Qt=LtQ0。对于L为对角矩阵,可得下式:
(7)
由动力系统的稳定性理论,可得如下定理:
定理:要使DSPSO算法模型稳定,即收敛于pd,当且仅当max{|λ1|,|λ2|}<1。
推论1:当(ω+1-c)2≠4ω且0<ω<1时要使DSPSO算法模型稳定,即收敛于pg,当且仅当0 推论2:当(ω+1-c)2=4ω,且0<ω<1时要使DSPSO算法模型稳定,即收敛于pg,当且仅当ω-1 推论3:当0<ω<1时要使IDWPSO算法模型稳定,即收敛于pg,当且仅当0 综上,学习因子和惯性权重之间的收敛关系如图4所示。 图4 c与w的收敛关系 DSPSO算法中学习因子表示为惯性权重的函数,既学习因子随惯性权重而决定。在实际算法中,学习因子往往乘以[0,1]随机数randi(i=1,2),所以只需要确定算法收敛模型学习因子的上限值,而乘以随机数后必然收敛于此条件,在此算法中惯性权重取值在[0.4,0.9],满足上述条件。 为了验证改进算法的有效性,用SPSO和LPSO与提出的DSPSO进行对比。用四个测试函数进行测试。在收敛精度、收敛速度和维度方面进行对比。 在实验中,种群规模为30,迭代次数为1 000,LPSO惯性权重从0.9线性递减到0.4;DSPSO的参数设置:惯性权重wmax=0.9,wmin=0.4。 实验将从以下三方面进行测试分析: (1)对四个函数在三种算法下的3维、10维和30维运行50次求平均值,对其各维度收敛精度进行分析; (2)通过多次实验的平均适应度进化曲线来比较四种算法的收敛速度; (3)固定收敛精度,规定迭代次数,比较四个函数在三种算法下的成功率。 测试函数如表1所示。 表1 测试函数信息 5.2.1 算法收敛精度比较 对四个函数分别在3维、10维和30维进行50次运行取平均值,最优值和平均值如表2所示。 表2 函数测试结果 续表2 由表2可知,宏观来看,对于函数f1,f3,f4,DSPSO不管在3维、10维或是30维,平均值都优与SPSO和LPSO。对于函数f2,三种算法的最优值都一样,但平均值却不同,SPSO和LPSO在3维和30维的精度在10-6左右,而DSPSO不管在3维、10维还是30维,其最优值和平均值都是8.881 8E-16,这也就说明了DSPSO对处理f2这种用于许多局部最优值并且自变量之间相互独立的函数具有很好的稳定性。 随着4个函数的维数增加,函数变得逐渐复杂。SPSO和LPSO的搜索精度渐渐变低,说明SPSO和LPSO对于处理高维度的函数的搜索能力逐渐减弱;而对于DSPSO,虽然随着四个函数的维度增加,精度在逐渐减低,但对于f1,DSPSO的精度逐渐由10-29到10-26最后到10-6;在函数f2中,DSPSO的值一直是8.881 8e-16,体现了DSPSO的稳定性;在函数f3中,DSPSO的算法平均值由0到0.085 173再到0.019 103,由此表明,虽然在3维时搜索结果最优,但随着维数增加,30维的结果优于10维,但二者精度是一样的;在函数f4中,DSPSO的精度由10-46到10-32再到10-6,但都是远远优于同维度的其他两种算法。综上表明DSPSO算法对于搜索精度和解决高维度的函数问题有很好的效果。 5.2.2 算法进化速度比较 四个函数的适应度进化曲线如图5和图6所示。 在图5左中,由于DSPSO算法在700次左右完成迭代,而SPSO和LPSO没有完成迭代,所以附上程序运行后的迭代最优值,如图7所示。 图5 函数f1、f2适应度进化曲线 图6 函数f3、f4适应度进化曲线 图7 函数f1的最优值 由图5左和图7可知,DSPSO在600完成迭代,而且精度是10-100,远远高于SPSO和LPSO的精度;SPSO和LPSO在1 000次内并没有完成迭代,说明DSPSO的搜索速度远高于其他两种算法;在图5右中,虽然三种算法最后搜索精度和迭代次数相近,但可以发现,DSPSO还是比较优中取精的,不管是速度还是精度都要优于其他两种算法;在图6左中,SPSO和LPSO早早陷入局部寻优,DSPSO在300次时陷入局部最优,但是随后跳出局部最优,在600次左右完成迭代,增加了搜索的精度;在图6右中,LPSO早早陷入局部寻优,DSPSO的最后收敛精度优于LPSO10-3个精度,并且DSPSO的搜索速度快于SPSO,并且DSPSO在700次迭代完成,而SPSO要900次迭代完成。 5.2.3 算法成功率比较 对每个函数进行50次仿真,其中对f1、f2、f3、f4设置1 000次迭代次数。当每个函数达到设定迭代次数时仍未收敛的则认定收敛失败。收敛成功率分析如表3所示。 表3 函数成功率 其中f1是单峰函数,f2、f3、f4为双峰函数。 由表3可知,在处理f1之类的单峰函数问题时,DSPSO算法并不比SPSO和LPSO具有很大优势;但在f2、f3、f4多峰问题上,DSPSO算法成功率明显高于其他两种算法。这表明,DSPSO算法的改进对处理多峰复杂函数问题有明显优势。 经过实验分析,提出了学习因子随权重调整的混合粒子群算法。首先对惯性权重进行改进,使其随迭代次数和粒子状态改变;将学习因子表示为惯性权重的函数,加强了粒子的统一性和智能性;引入差分进化算法保持种群多样性,利于算法跳出局部收敛;最后对算法的收敛性进行分析,证明算法可行性。仿真结果表明该算法的寻优性能明显提升。在今后的算法研究中,应加强群算法的实际工程应用,可以将其应用到电机控制参数调整中,减小超调。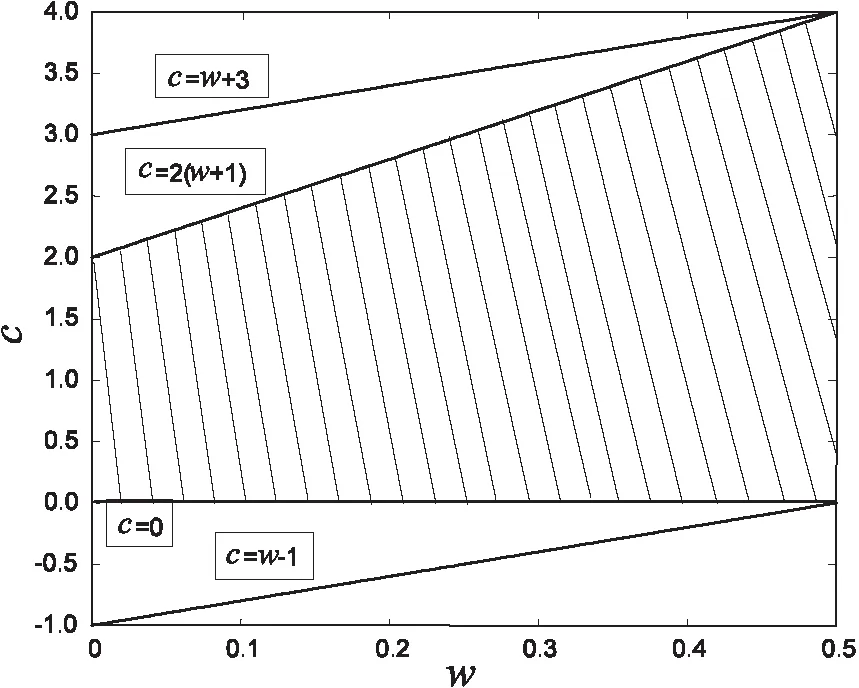
5 仿真测试与分析
5.1 实验设计

5.2 测试结果分析


6 结束语
猜你喜欢
中学生数理化·八年级物理人教版(2023年3期)2023-03-21 00:40:16计算机仿真(2022年8期)2022-09-28 09:53:02数学物理学报(2022年4期)2022-08-22 04:07:12数学物理学报(2022年2期)2022-04-26 14:08:04中学生数理化·八年级物理人教版(2022年3期)2022-03-16 05:55:06金桥(2018年4期)2018-09-26 02:24:54中学生数理化·八年级物理人教版(2017年3期)2017-11-09 03:05:23小学科学(学生版)(2016年1期)2016-10-09 01:53:02中国塑料(2016年11期)2016-04-16 05:26:02中国卫生(2014年5期)2014-11-10 02:11:26
