
基于集成学习的烟草异常数据挖掘研究与应用
2020-12-04 08:02李天举谢志峰张侃弘陶亦筠
计算机技术与发展 2020年11期
李天举,谢志峰,张侃弘,陶亦筠,范 杰,汤 臻
(1.上海大学,上海 200072; 2.上海烟草集团有限责任公司,上海 200082; 3.上海市烟草专卖局,上海 200120)
0 引 言
随着数字化信息时代的到来,烟草行业数据量正在以惊人的速度快速增长,这种数字化趋势为机器学习与数据挖掘技术在其生产、物流、监管等各方面的应用创造了新机遇[1-3]。数据挖掘技术已经逐渐地应用于各行各业,对异常数据的挖掘也开始得到人们更多的重视,所谓异常指的是在海量数据中存在着与一般数据形式相差较大或者与正常行为相左的数据对象,一般的数据挖掘过程常常将这些数据当作噪声进行清除处理,但大多时候它们可能包含了解决现实问题中极其重要的信息。异常数据挖掘技术已在模式识别、信用欺诈、企业监管等领域得到广泛应用。比如在金融行业的征信系统中,异常数据往往代表了用户存在违约、造假等不良行为;在电网系统中,异常数据通常警示设备故障问题或者用户的异常用电的行为;在城市轨道安防系统中,异常数据意味着行人或车辆存在违章行为。在这样的背景下,面向烟草行业的异常数据挖掘技术有望从海量的烟草数据中,提取挖掘出零售户在卷烟经营中是否存在涉烟违法的行为。数据挖掘技术的应用将有效推进整个烟草行业向信息化、智能化方向发展。
基于数据挖掘的市场异常预警预测研究,能够进一步加强烟草零售市场监管力度,有效限制零售户的涉烟违法行为,合理分配稽查工作中的人员调度,有效净化卷烟市场经营环境。在烟草专卖市场监管方面,异常数据挖掘的任务就是在专卖监管数据中发现那些有违规经营迹象的数据对象,并找到隐藏在这些对象背后的各类违规经营情况。通过深入挖掘分析现有的烟草专卖信息数据,能够有效结合现有市场监管模式,加快烟草专卖管理方式的信息化转变,加强对重点涉烟违法行为的治理,提升市场监管的精准性。
目前将前沿的机器学习与数据挖掘技术应用于烟草专卖市场监管方面的研究稍显不足,但在其他领域的相关研究为笔者提供了宝贵的经验。文献[4]将机器学习技术运用于发布虚假财务报表(FFS)公司的异常行为检测中,通过使用优化的Stacking多模型融合方法将典型的机器学习算法组合在一起,取得了比任何单一算法和经过检验的简单集成方法更好的检测性能。文献[5]利用XGBoost机器学习算法,能够对云计算中SDN控制器易受到分布式拒绝服务(DDoS)的异常攻击行为进行快速的检测。文献[6]通过使用基于功能树分类器和三种当前比较先进的机器学习集成框架Bagging、AdaBoost和MultiBoost,提出并验证了一种能够提高滑坡异常和敏感性模型预测性能的集成方法。文献[7]将前沿的机器学习LightGBM算法应用于广告转化率预估中,通过LightGBM模型提取广告日志中的高阶组合特征,并结合了区域因子分解机FFM模型对稀疏数据进行相应处理,有效提高了广告转化率预估模型的有效性和泛化能力。文献[8]提出的深度网络xDeepFM算法,能够有效地自动学习数据的特征交互。
该文基于上海市卷烟经营零售户从2016年1月到2019年4月的烟草专卖相关数据,提出了基于多模型Stacking集成学习的烟草异常数据挖掘模型,旨在利用前沿的机器学习算法XGBoost、LightGBM等,以及深度学习网络xDeepFM算法对该数据进行建模预测和分析,最终推动烟草专卖市场监管方式的转型,进而促进全市烟草市场监管水平的大幅提升。
1 数据预处理
1.1 数据来源
选取了上海市4万多家零售户从2016年1月-2019年4月的烟草专卖相关数据,基础数据主要包括:经营户静态数据、客户历史数据、订货数据、卷烟主数据、市场检查数据、投诉举报数据、案件数据等。
1.2 数据预处理(构建数据指标)
影响数据分析与挖掘的第一要素是数据的预处理工作,而数据挖掘技术的合理运用是异常数据检测能否正确运行的核心环节。在对数据进行预处理之后,必须结合有效的分析手段,才能找出数据的规律,从而挖掘出异常经营行为。通过对烟草市场监管数据的深入分析,发现大部分的数据属于结构化数据,其中主要包含了连续和离散两种形式的变量类型,这两种类型数据相对应的处理方式明显不同,因此,如何快速有效地实现复杂条件下结构化数据的分析与挖掘尤为重要。针对烟草行业中的海量、多维、动态数据,分析烟草结构化数据的特点,从营销、物流、市场监管、案件等多个维度进行分析,梳理形成静态特征指标与动态特征指标。部分特征分类如表1所示。
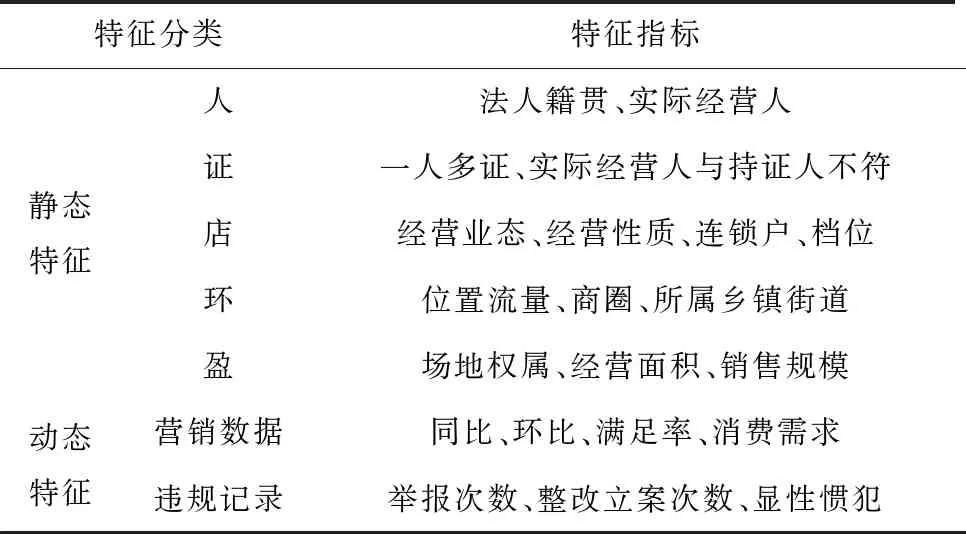
表1 部分特征分类
在数据预处理阶段,需要对类别数据进行编码,比如:订货方式包括POS订货、电话订货、电子商务、手工订货、网上配货等,需要将其转为数值型数据进行处理。对数据的编码往往会影响到模型训练的速度和预测的结果,所以如何合理选择数据的编码方式十分重要。常见的编码方式有独热编码(one-hot encoding)、标签编码(label encoding)和实体嵌入(embedding)。
(1)one-hot编码,其基本思想是使用位寄存器对类别数据的N种类别状态分别编码,每个类别状态占用其中的一位,且每种状态只有一个位置是1,其他状态位置都为0。例如,“POS订货”编码后的形式为[0 0 0 0 1],“电话订货”编码后的形式为[0 0 0 1 0],“电子商务”编码后的形式为[0 0 1 0 0],“手工订货”编码后的形式为[0 1 0 0 0],“网上配货”编码后的形式为[1 0 0 0 0]。
(2)标签编码:给每种类别分配整数,例如“POS订货”为1,“电话订货”为2,“电子商务”为3,“手工订货”为4、“网上配货”为5。由于连续的数字代表着数字之间的先后顺序,要尽量避免将其使用在线性模型中,而基于树的算法模型则不受这种数值顺序的限制。
(3)采用实体嵌入方式可以将类别数据用向量来表示,生成高维数据在高维空间体现它们的相互关联。一般多用于深度神经网络算法模型中。
通过观察样本发现,大多数类别数据在5个类别以下,所以选择使用one-hot编码对类别数据进行编码,一方面防止标签编码带来的赋值顺序问题,另一方面又可以同时适用于机器学习算法和深度神经网络算法。最后,由于原始数据中还存在一些比较脏、乱、差的数据,还需要对其进行大量清洗,比如经营面积数据存在大量不合理数值,而经营面积代码则是以类别A、B、C、D来表示,则提取特征时就去掉经营面积数值型数据,转而用类别型数据代替。大户类别数据中只包含空值和其他大户类别,那么这一特征数据全是无用信息,则无需进入模型。零售户的档位信息存在缺失值,处理方式是按当前时间点往前最近的一次档位进行填补。通过数据预处理和特征工程提取之后,最终进入模型的一共有244个特征(指标)。
2 相关算法
2.1 XGBoost算法
XGBoost(extreme gradient boosting,极端梯度提升算法[9]),是一种基于CART树的boosting算法,高效地实现了GBDT算法,并进行了算法和工程上的许多改进。
XGBoost模型的目标函数主要包含两个部分:
(1)
XGBoost模型每次训练一棵新的树都要拟合上一次结果的残差,每次增加的函数的增量要使新一轮的残差尽可能减小,在进行到第t次时,模型的目标函数可以写为:
(2)
模型训练的最终目标是要找到一个能够最小化目标函数的ft(xi),对式(2)采用其在x=0处的泰勒二阶展开式来近似,近似的目标函数为:

Ω(ft)
(3)
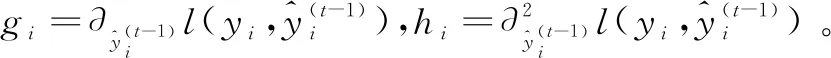
去掉不影响目标函数最终优化的项,可简化为:
(4)
2.2 LightGBM算法
LightGBM算法主要使用了基于梯度的单边采样和互斥特征捆绑这两种方法来弥补传统Boosting在处理大数据样本时的计算损耗问题[10]。
模型在训练时首先采用基于梯度的单边采样(简称GOSS),计算梯度时不再是扫描全部的样本点,而是保留梯度比较大的一小部分样本数据,对梯度小的大多数样本进行随机采样;而互斥特征捆绑(简称EFB)主要依据高维数据的稀疏性,主要特点是存在很多特征不会同时取值为非零值,称具有这样的性质的特征为互斥特征,将这些特征组合在一起可以达到降低特征维度的目的,使得确定切分点的计算损耗减少,同时对互斥特征的处理也在一定程度上降低了模型过拟合的风险。
2.3 xDeepFM算法
对于预测性的模型来说,如何让模型自动地去学习特征之间的交叉特性对数据挖掘系统是特别必要的。所谓特征之间的交叉特性也称之为交叉特征[11],是指两个及两个以上的特征进行组合形成一个新的特征。深度神经学习网络为解决这一问题提供了突破口,比如基于因子分解机的FNN、PNN和DeepFM等深度神经网络算法[12-14],对特征之间的高阶交互特性的学习使用了多层的全连接网络,但是这些网络的缺点是模型学习出的是隐式的交叉特征,使得其具体形式是未知的和不可控的。为了挖掘不同交叉特征之间的潜在联系,该文引入xDeepFM(极深因子分解机)深度神经网络模型[8],来让模型自动地去学习特征之间的交叉特性。其基本结构如图1所示。
xDeepFM算法首先把数据集的原始特征中每个one-hot编码后的特征组成一个field,用来克服数据的稀疏性;然后进行embedding转换使特征表现为向量级;接着将数据送入压缩交互网络CIN模型中,使得模型以显示的方式自动学习高阶的交互特征,CIN每层的神经元都是由原始特征向量和它前面的隐层计算而来,即:
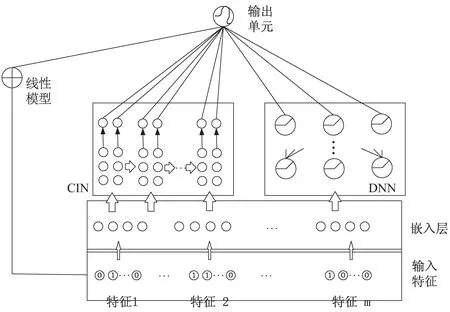
图1 xDeepFM神经网络结构
(5)
其中,Xo为数据的原始特征,Xk为CIN神经网络中的隐层,点乘的计算为:
(6)
同时xDeepFM模型中还分别包含了集成的线性模型和DNN神经网络模型,前者使得模型具有泛化的记忆能力,后者使得模型能够隐式地学习特征的交互特性。
3 烟草异常数据挖掘建模分析流程
3.1 整体流程分析
基于Stacking的集成学习[15]是按照一定的方式将多种不同的算法集成组合来提升模型的训练效果,相比于单一的模型,使用该方法通常可以产生更好的预测性能。与Bagging[16]和Boosting[17]采用单一的机器学习算法训练单个模型不一样的地方在于,Stacking是一种每一层都可以使用多个模型来进行训练的集成学习方式,每一层的多个模型都有各自输出值,将该层每一个模型的输出值作为新的特征组合成新的数据集作为下一层的输入进行学习。
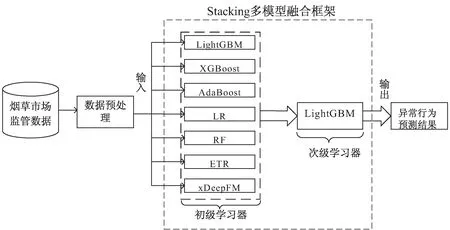
图2 整体流程
模型构建流程如图2所示。首先对烟草市场监管数据进行预处理,在训练集上对单个算法进行训练调参,使单个模型性能达到最优状态;然后确定Stacking集成学习模型的第一层模型组合方式,利用划分后的数据集来训练,将第一层的各个初级学习器模型的输出组合形成新的数据集;Stacking第二层次级学习器模型用新生成的数据集来训练,并输出最终的预测概率值。
3.2 烟草异常数据挖掘建模分析
烟草异常数据挖掘模型最终要实现的目标是,预测出零售户“销假,销私,乱渠道进货”等异常经营行为的可能性。基于模型的预测性能,Stacking集成学习方式一般要求组合中的单个基学习器不仅要有较强的学习预测能力,还要在算法原理上具有较大的差别。因此Stacking模型中的第一层除了选用学习性能比较强的XGBoost算法、LightGBM算法和xDeepFM算法,还使用了AdaBoost算法、随机森林算法(random forest,RF)、极端随机树算法(extratrees,ETR)和Logistic Regression算法(LR)。其中RF和AdaBoost分别使用了基于Bagging与Boosting的集成学习方式,具有较强的学习能力和严谨的数学理论作为支撑[18]。ETR算法是在RF的基础上多了一层随机性,即在对连续变量特征选取最优分裂值时,不会计算所有分裂值的效果来选择分裂特征,而是在每一个特征的取值范围内,随机产生一个分裂值,从中计算出一个较优值来进行分裂。其次与RF使用Bagging集成学习方式对样本数据进行有放回抽样不同,ETR使用所有的样本,只是特征是随机选取的。LR算法相对来说是弱一点的基学习器,使用该算法的原因是为了防止过拟合,让Stacking模型具有更强的鲁棒性。Stacking模型中的第二层的元学习器用了学习预测能力比较出色的LightGBM算法。基于多模型Stacking的烟草异常数据挖掘模型如图3所示。
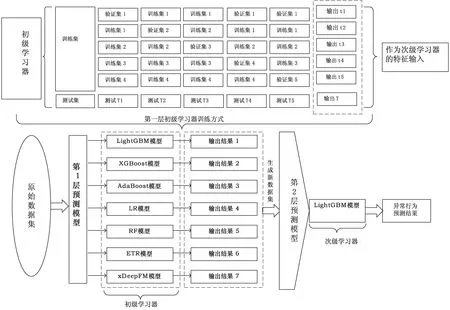
图3 基于多模型Stacking的预测模型
Stacking模型训练具体步骤如下:
(1)划分原始数据集,其中划分的方式为随机采样选取90%的数据作为训练集,10%的数据作为测试集,在训练集上使用五折交叉验证的方式对单个算法模型进行训练,确定每一个模型的最优参数,使单个模型性能达到最优状态;
(2)确定Stacking第一层模型组合方式,利用划分后的数据集来训练,将第一层的各个模型的输出组合形成新的数据集,具体过程如图3中上半部分,其中每个模型最终的输出结果为五次交叉验证结果的平均值,将每个模型的输出结果作为新的特征组成一个新的数据集;
(3)Stacking第二层模型用新生成的数据集来训练,并输出最终的预测概率值。
3.3 模型训练与结果分析
实验数据使用经过整理好的2016年1月到2019年4月上海市烟草专卖市场监管数据中的检查数据以及对应的静态和动态指标数据作为模型的数据集。总共166 563个样本,244个特征,其中30个静态特征和214个动态特征。
由于该模型预测属于二分类预测问题,且最终的输出值为概率值,为了直接分析模型输出的概率值,预测评价指标采用Log_loss和AUC来评价模型的预测效果,避免了将其转换成类别数值带来的可能误差。公式如下所示:
(7)
其中,N为样本的总数;M为预测的类别数,比如文中实验为二分类预测,M就为2;样本i属于分类j时yi,j为1,否则为0;pi,j为样本i被预测为第j类的概率。
(8)
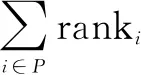
要想使融合模型Stacking性能达到最好,首先要确保其第一层的各个基学习器达到最佳的学习能力,因此将各个基学习器在原始数据集上单独训练,从而确定每一个模型的训练参数,具体参数如表2所示。

表2 模型参数
在相同的数据集上对每个单一模型和Stacking模型分别进行训练并预测,最佳模型通常具有较小的Log_loss值以及较大的AUC值,各个模型的预测结果对比如表3所示,对应ROC曲线如图4所示。
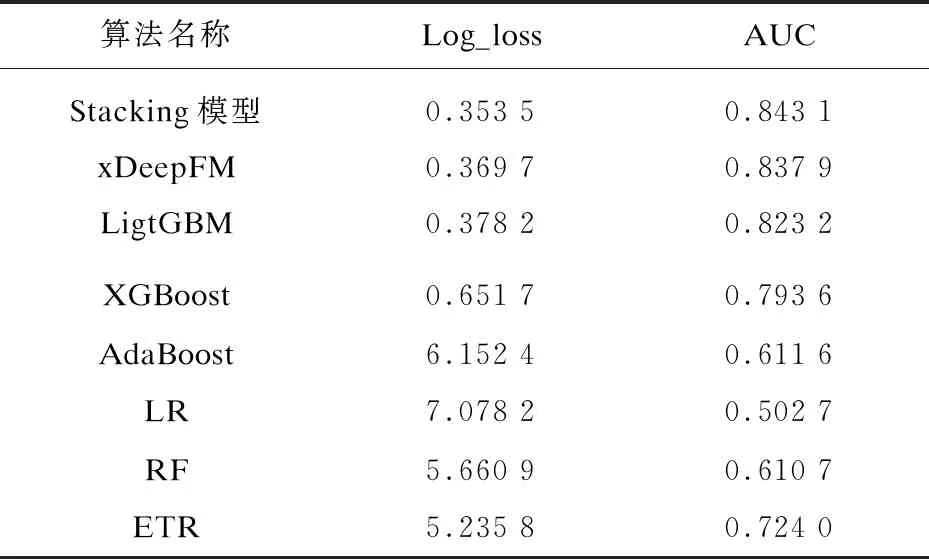
表3 模型预测结果
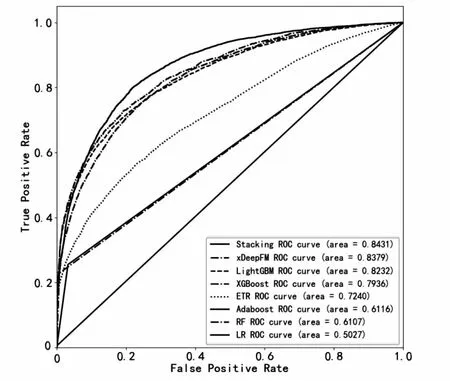
图4 ROC曲线对比
通过预测结果可知,单个模型中表现最好的是xDeepFM神经网络算法,说明该算法可以很好地学习不同特征之间的交叉特性,加上模型兼具记忆和泛化的学习能力,使得其在最终的预测精度上表现更好。其次是LightGBM算法,两项指标也都达到了不错的效果,对比其他几个机器学习基学习器,可以确定LightGBM算法比较适合处理这种大样本,高维度,特征稀疏的数据集。虽然其他几个基学习器的表现稍差,但是通过Stacking方式集成以后,效果上更加出色。一方面是由于Stacking模型可以很好地保持学习能力优异的单个学习器的性能,提升自身的预测能力;另一方面基学习器之间算法原理的明显不同使得Stacking集成后的模型具有更加稳健的预测性能。
4 烟草异常数据挖掘模型的应用
经过前期阶段充分测试、验证模型的有效性后,该文提出的基于多模型Stacking集成学习的烟草异常数据挖掘模型,在上海市烟草专卖市场监管工作中进行了实际应用,对模型的推荐名单进行了稽查实证。
本次实证数据分别选取截止2019年06月30日和2019年07月31日这两天的上海市烟草专卖数据,将数据处理成相应的特征指标作为模型的测试集,来对7月份和8月份的稽查名单进行预测,其中7月份推荐的烟草零售户为1 322户,8月份推荐的烟草零售户为1 344户,最后对稽查结果计算最终的查实率。具体数据如表4所示。
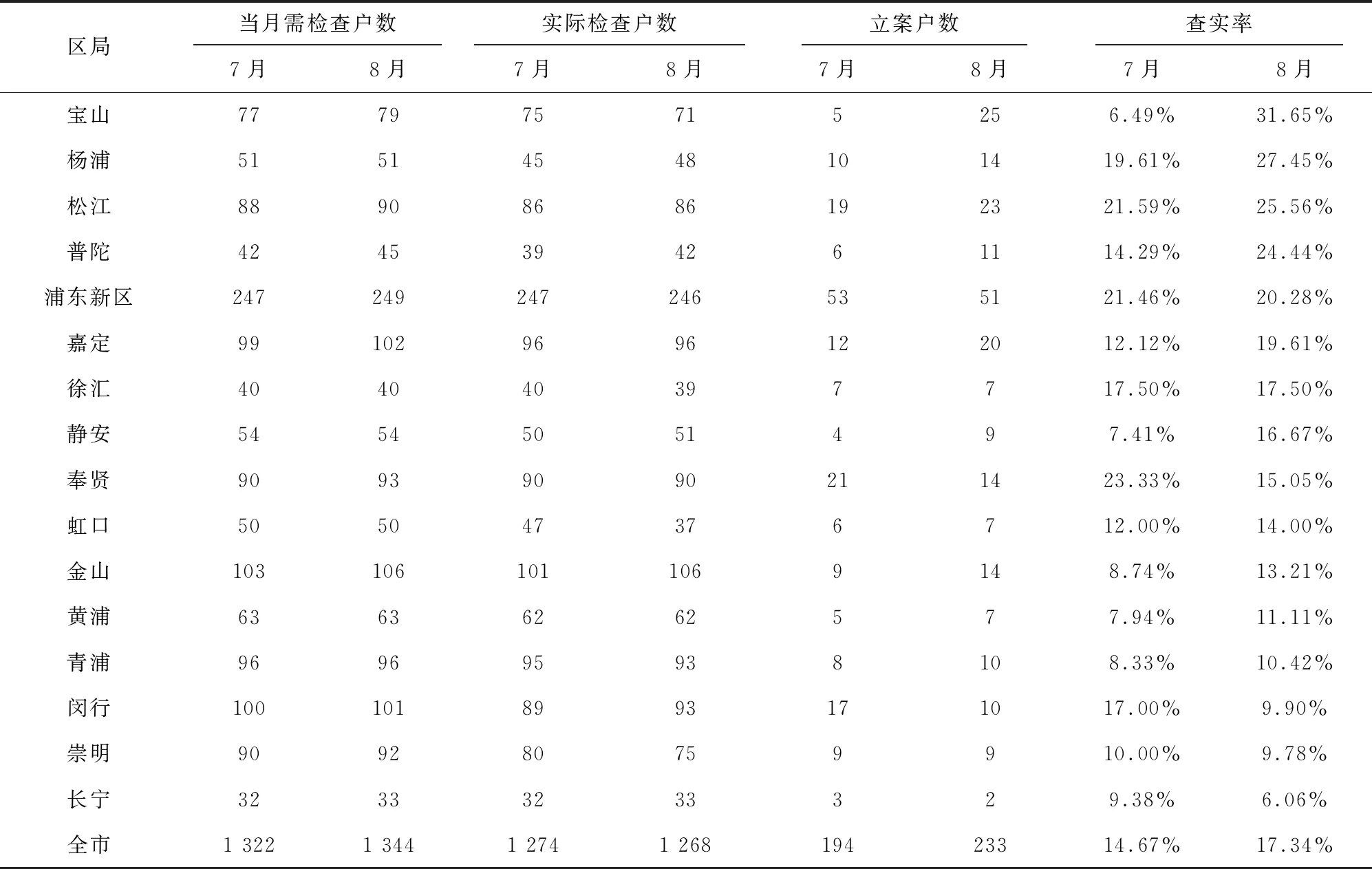
表4 实证结果
表中涉及到的计算公式如下:

(9)
其中,立案标准主要分为三类:(1)真烟流入,即零售户从其他渠道低价购买香烟再高价卖出的情况,稽查时若零售户真烟流入条数大于等于5条则进行立案处理;(2)假烟,即零售户有贩卖假烟的情况;(3)走私烟,即零售户有销售走私烟的情况。
此外表中部分地区存在实际检查户数低于当月需检查户数的情况,这是因为存在个别零售户当月暂不经营的情况,实际检查中做另外的处理。
上海市烟草专卖市场监管体系现有稽查方法主要依据违规加分制,即对零售户的卷烟经营数据进行分析,对零售户的违规行为按照一定的规则对其赋分,最终得分越高的零售户,其违规风险越高。结合2016年1月到2019年4月的检查数据及检查结果分析得知,原有检查方式在实际稽查中,每个月检查的零售户中有涉烟违法行为的查实率在5%左右。而由表4可以看出,在7月份和8月份Stacking模型预测名单的查实率分别达到了14.67%和17.34%,相比原有的传统方式有比较大的提升,稽查实证结果进一步证明了Stacking模型的有效性。
5 结束语
基于深度神经网络xDeepFM算法,机器学习LightGBM、XGBoost等算法,利用集成学习Stacking方式将多个算法学习器进行集成组合,构建了基于多模型Stacking集成学习的烟草异常数据挖掘预测模型。对2016年1月到2019年4月的上海市烟草专卖数据进行训练及验证分析,在2019年7月和8月对模型推荐名单进行实地稽查验证,两个月的查实率均达到了预期,使得上海市卷烟市场监管稽查工作中的人员调拨分配更加合理,对零售户涉烟违法行为的监管更加精准,有效净化了卷烟市场的经营环境。
同时,从稽查结果的查实率可以看到存在各区局查实率结果不平衡的问题,因此,在后续的研究中会在以下几个方面继续优化完善:
(1)可以引入权重因子,使各区局预测精度更加准确;
(2)除了机器学习算法外,着重研究目前较为流行的深度学习算法,挖掘特征之间更高阶的有效信息;
(3)将异常行为综合预测分析与现有市场监管处理流程进行充分结合,形成从数据预处理到模型构建再到评估应用的全流程处理模式,建立智能化的全流程市场监管处理流程,全面提升市场监管水平。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
九江学院学报(自然科学版)(2022年2期)2022-07-02
中国典型病例大全(2022年7期)2022-04-22
小学生学习指导(中年级)(2021年12期)2021-12-30
家庭影院技术(2021年6期)2021-07-28
大众投资指南(2021年35期)2021-02-16
海峡姐妹(2019年1期)2019-03-23
中国化妆品(2018年11期)2018-12-26
中国化妆品(2018年3期)2018-06-28
电子技术与软件工程(2016年24期)2017-02-23
