
一种轻量级的不规则场景文本识别模型
2020-12-04 07:50产世兵刘宁钟沈家全
计算机技术与发展 2020年11期
产世兵,刘宁钟,沈家全
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
0 引 言
随着科学技术的不断发展,人们的生活方式也不断地向现代化、科技化、智能化转变。如今,人们获取信息的方式越来越多样化、智能化,特别是随着各种智能设备的普及,人们随时随地可以使用智能手机、数码相机、iPad等设备获取信息。这些移动设备给人们获取图像提供了优越的平台,人们利用这些移动设备可以获取到各种内容丰富的场景图像,增加了图像的多样性。
在自然场景图像中,包含了丰富的文本语义信息,这些语义信息是帮助人们更加深入理解场景的重要依据。近年来,场景文本识别已经在工业、商业和民用上占据了重要的地位。不同于工整的文档文本图像,场景图像文本表现得十分不同,它具有背景多样性、字体不统一、间隔不等、颜色不同和字符大小不一等特点,场景图像中的文本区域还可能会产生变形。这些特点加大了对场景文本识别的难度。使用传统的基于字符分割和单字符识别的方法[1-3],可以很好地识别文档文本,但是并不适用于多样的场景文本识别。
随着深度学习技术的快速发展以及广泛应用,和深度卷积神经网络[4-5](deep convolutional neural network,DCNN)在目标检测的优良表现,人们开始使用DCNN和常用于语音识别的循环神经网络[6-7](recurrent neural network,RNN)来建立场景文本识别模型,并在场景文本识别中取得了不错的效果,更加激励了人们对场景文本识别的研究[8-10]。
但是,目前在文本识别应用广泛的DCNN,例如VGG[11]、ResNet[12]等,这些网络的参数量很大,需要消耗大量内存和计算量,在训练时,需要巨大的样本量。RNN在场景文本识别中具有广泛的应用,但是在训练的时候,经常有梯度消失和梯度爆炸的情况。为了避免这些问题,文本识别一般采用改进的RNN模型,比如长短记忆网络[13-14](long short-term memory,LSTM)。LSTM在反向传播中避免小梯度的乘法运算,降低了梯度消失的概率,它是文本识别中最常用的模型之一。但是,LSTM在时间序列上仍然是个深度网络,训练过程中的过拟合和梯度爆炸问题并没有根本解决,网络收敛较慢,模型训练比较困难。
1 相关工作
场景文本识别技术发展迅速,早期传统的基于字符分割的技术利用二值化或者滑动窗口等方法,将单个字符从背景中分别分割出来,然后再识别分割出来的字符。例如,Novikova等人的Extremal Regions[15]和Bissacco等人的Niblack自适应二值化算法[16]来对图片进行二值化,分割字符,此算法根据字符区域的长宽比自动调整Niblack窗口的大小来进行字符的分割,然后再进行字符识别。然而,场景文本图片中的背景十分复杂多变,文本的字体、颜色、大小、形态等都不统一,人们很难从这样恶劣的环境下提取出单个字符。基于滑动窗口的方法random terns[17]和integer programming[18],直接使用多尺度滑动窗口策略从图片中定位字符。在字符识别阶段,人们利用单个字符的语义信息来对字符进行分类。其中比较常用的方法有支持向量机[19](support vector machine,SVM)、Bayesian inference[20]和条件随机场[21](conditional random field,CRF),它们需要人工提取大量的特征,代价很大,而且不同的场景需要的特征不同,导致人工特征的鲁棒性低,泛化能力差。
近年来,基于神经网络的深度学习方法发展十分迅速,相比于传统的人工提取特征的方法,它不需要人工设计特征,可以通过学习的方式自动获取对象的特征,在目标检测、语音识别等方面取得了不错的效果。受到语音识别技术的启发,人们开始使用Encoder-Decoder框架进行文本识别。首先获取一张文本图片的特征序列,然后将这些特征序列转换成字符串。在CRNN[22]中,作者利用VGG网络提取输入图片稳定的图片特征,然后以特征图的每列为单位生成特征序列,这些特征序列被传入RNN层,利用RNN结构提取每个特征序列的上下文特征,最后利用CTC(connectionist temporal classification)结构获取最终的字符串。在DTRN[23]模型中,用CNN滑动窗口来提取序列特征,并利用RNN网络来提取特征序列的上下文特征,最终获取字符串。这些基于CNN+RNN+CTC的网络模型是场景文本识别中的主流框架。
该文提出的ISTR-LW模型,通过引入轻量级网络PeleeNet[24]、Dense Block[25]以及注意力机制[26](attention mechanism,AM),不仅加快了网络训练的收敛速度,而且提高了网络预测的速度以及准确度。此外,还采用了空间变换网络[27](spatial transformer network,STN),将弯曲的文本变换成规则的文本,改善了场景文本变形的问题。
该文主要的创新点有:
(1)提出了一种新颖的对不规则文本具有鲁棒性的场景文本识别轻量级模型;
(2)在特征序列提取阶段,引入了轻量级网络PeleeNet,减小了ISTR-LW模型的大小,加快了ISTR-LW网络的识别速度;
(3)在循环网络层加入Dense Block模块,加快了ISTR-LW训练收敛速度,降低了网络的训练难度。
2 ISTR-LW模型与方法
这一节将介绍ISTR-LW模型的整体框架和4个组成部分,包括STN、特征序列提取层、循环网络层和注意力机制模型。ISTR-LW模型框架如图1所示。
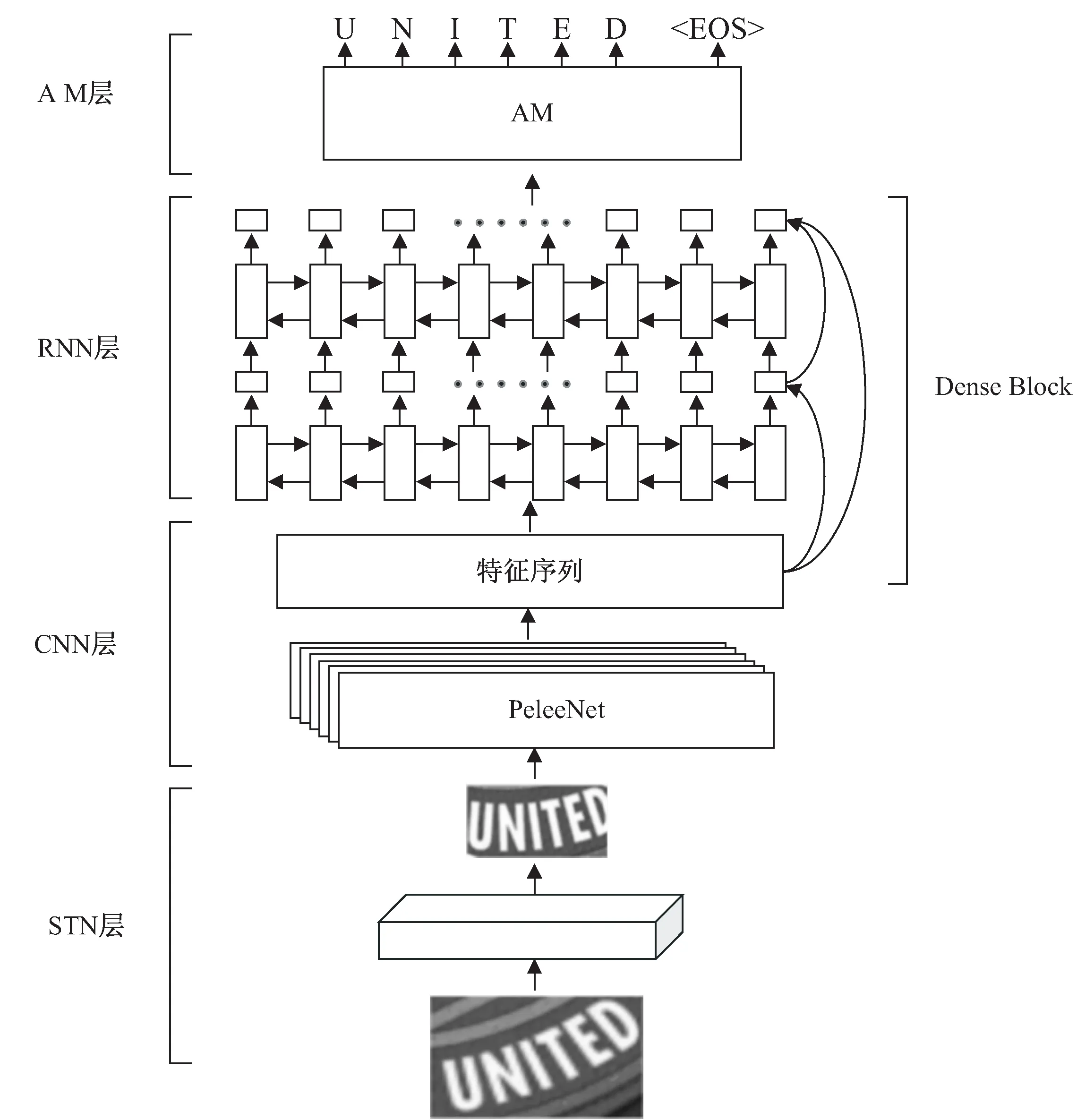
图1 ISTR-LW模型
2.1 STN
在场景文本图像中,如图2(a)所示,存在很多弯曲的文本。如果直接将弯曲的文本输入到网络中,则特征提取阶段就需要学习到形状不变的特征,会增加网络的负担。在框架的初始阶段,为了处理一些弯曲的文本图片,引入了TPS[28]变换,作为空间变换网络STN的一种变体,如图2所示,来解决弯曲文本难以识别的问题。TPS转换,首先通过定位网络在原图上预测一系列基准点,然后基于预测的基准点通过网格生成器计算转换矩阵,并生成一个关于原图的采样网格,最后采样器结合网格和输入图片,通过采样网格上的点转换得到最终的规则的图片。

图2 STN网络
2.2 特征序列提取层
在传统的场景文本识别中,为了学习到很好的特征,使用参数量巨大的VGG网络,不仅计算量巨大,而且内存消耗巨大。为了减少特征序列提取层的计算成本,引入高效的轻量级网络PeleeNet。图3为经过改变后的满足文本特征序列提取的轻量级网络。在文中的PeleeNet中,摒弃了原文中的第4阶段,将原文中的每个阶段的2×2的平均池化层改成1×2的平均池化层,并且在最后添加一个1×1的卷积层。在不考虑维度的情况下,最终获得一个L×1的特征向量,用X=x1,x2,…,xL表示提取的特征序列,每个xi代表特征序列的每一列。由于在特征序列提取时,并不会改变文字的空间结构,所以特征序列顺序与文本的顺序一致。
2.3 循环网络层
将卷积层提取出的特征序列X=x1,x2,…,xL输入到循环网络层中,每个xi对应一个hi,生成一系列序列H=h1,h2,…,hL。在循环网络层中,以双向长短记忆[22](bidirectional LSTM,Bi-LSTM)为单元,获取文本的左右两边的语义信息。但是,Bi-LSTM在时间序列上是深度网络,容易产生梯度消失和梯度爆炸的问题,网络收敛较慢,模型训练比较困难。为了缓解这一问题,如图4所示,受到Dense Block模块的思想启发,在每个输入和输出之间以级联的方式建立一条直接的关联通道。这一设计的引入,有效缓解了梯度消失和梯度爆炸的问题。
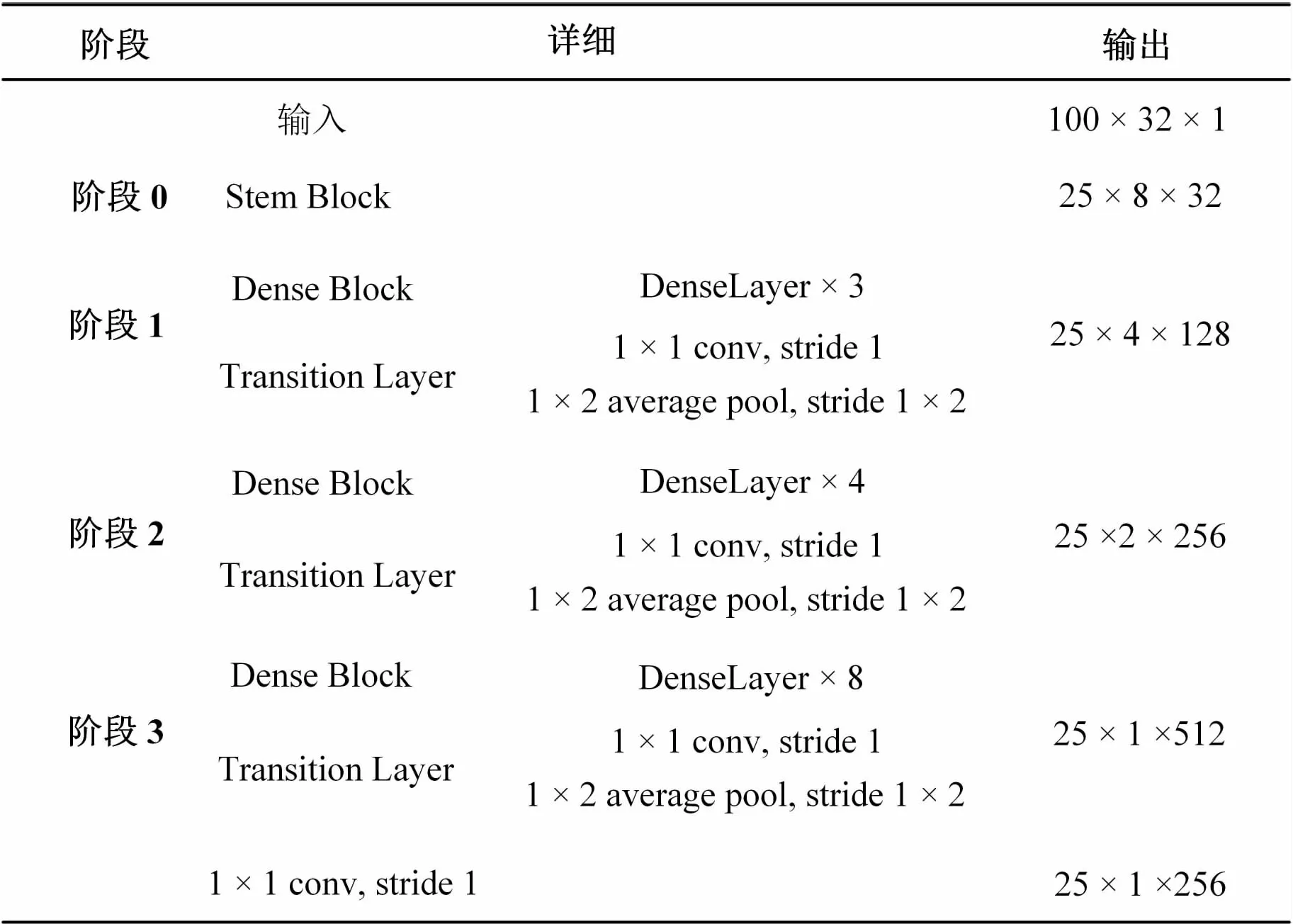
图3 特征序列提取网络

图4 循环网络层+Dense Block
2.4 注意力机制模型
ISTR-LW模型在做最终预测时,利用了RARE[29]中的注意力机制模型,如图5所示,以GRU[30]为单位建立的一个预测模型,增加了预测的准确率。在文本区域中,不同的序列对当前字符序列的重要性是不同的,为了获取更加重要的信息,注意力机制模型给不同的序列分配不同的权重,如式(1),计算不同序列的权重:
at=Attend(st-1,at-1,h)
(1)
其中,st-1为上一个GRU的输出。gt为当前GRU的输入,gt的表示如下:
(2)
2.5 训练过程
最终使用softmax函数对文本进行预测,如式(3)所示:
yt=softmax(WTst)
(3)
将训练集表示为:X={(Ii,gi)}i=1,2,…,n,其中I表示输入的文本,g表示ground truth。该文使用最大似然法计算损失函数,如式(4)所示:
(4)
其中,p(.)由softmax计算得到,θ是模型的所有参数。实验表明,优化算法采用ADADELTA收敛速度较快。模型参数初始化时,除了STN中的定位网络全连接层权值初始化为0,其他网络权值使用Kaiming[31]初始化方法。
3 实 验
3.1 实验细节
在STN中的定位网络,初始化基准点的数量为20,图6所示为定位网络的结构,最终输出为2×20=40大小的向量。在网络中除了输出层以tan为激活函数,其他层的激活函数都为ReLU。

图6 STN定位网络
ISTR-LW模型是在MJSynth数据集上训练,该数据集约为890万张图片。该文采用ADADELTA优化算法,衰退率设置为0.95。批量大小设置为192,训练次数为300 K。训练和测试时所有的输入都被缩放为100×32的大小。
实验环境是基于Pytorch深度学习框架下实现的,CPU为Intel(R) Core(TM) i9-9900 @ 3.50 GHz,显卡为RTX 2080Ti 11 GB显存,物理内存为64 GB,操作系统为Ubuntu 16.04。
3.2 数据集
训练数据集和测试数据集分别介绍如下:
MJSynth:作为唯一训练数据集。该数据集约有890万张合成图片作为训练集,9万个英文单词,约90万张合成图片作为测试集。
IC03:作为测试数据集。该数据集包含1 110张不规则的场景文本测试图片,排除少于三个字符或者非字母数字的图片,用于文中测试的图片有860张。
IC13:作为测试数据集。该数据集大部分取自IC03数据集,共有1 095张场景图片,排除少于三个字符或者非字母数字的图片,用于文中的测试图片为857张。
IIIT5K:作为测试数据集。该数据集包含3 000张不规则的测试图片,全是取自于Google图片。
SVT:作为测试数据集。该数据集取自Google Street View,共有647张不规则的场景图片用于文中测试。
3.3 实验结果
在测试时,如表1所示,分别在上文介绍的5个公开的数据集上进行了测试,并且与PhotoOcr[16]、 Jaderberg[32]等模型进行了对比,可以看出,ISTR-LW模型相比其他模型大幅减少了参数量。并且,在IC03和IC13测试数据集上识别准确度有稍微的提升,在其他数据集上,除了比参数量较大的RARE模型识别准确率稍微低一些,相比其他模型都有提升。ISTR-LW模型比CRNN模型大小减小了29%,比RARE模型大小减小了45%。以上数据说明,引入PeleeNet网络和Dense Block模块的ISTR-LW模型,不仅大幅度减少了模型的参数量,还在文本识别精确率上有很大的竞争力。

表1 多个模型识别准确率数据对比
4 结束语
提出的ISTR-LW模型,引入了PeleeNet网络和Dense Block模块,通过STN修正变形图片,通过注意力机制让模型获取需要关注的重点区域,加快了网络的收敛速度,在保证识别准确率的前提下,大大减小了模型的规模大小。并且实现了端到端的训练,可以接受任意长度的文本。在公开数据集上的对比实验表明,ISTR-LW模型的表现具有很强的竞争力。但是ISTR-LW模型仍然存在一些缺陷,例如,对一些弯曲度比较大的图片识别率低;模型的准确度上有些许下降。在以后的工作中,将把工作重心放在处理变形图片和提高准确度上。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
电脑报(2021年41期)2021-11-04
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
