
基于SVD与核极限学习机的多标记学习算法
2020-12-01 00:32李闪闪田文泉潘正高
宿州学院学报 2020年10期
李闪闪,田文泉,潘正高
宿州学院信息工程学院,安徽宿州,234000
在标记学习中,研究对象往往具有多重语义,即一个对象包含多个属性[1]。例如在自然风景图像标注中,可以同时存在“蓝天”“白云”“大海”“沙滩”等多个元素,通过对标注信息的分析可以完成图像分类的工作。随着数据采集技术的发展,各种类型的数据资源正在迅速增长,以数据为基础的多标记研究面临着维数灾难的问题。数据的增长会增加计算时间、空间的消耗,同时无关数据的加入会降低分类算法的性能,因此,如何保证精度的同时有效去除多余特征是大家研究的重点。
在多标记学习中存在多种算法,如经典的ML-KNN(Multi-Label K Nearest Neighbors)算法[2],考虑近邻样本的类别信息,根据最大化后验概率完成对多标记的分类预测,使分类器性能得到有效地提高。为了将标记间的相关性考虑进来,Elisseeff等提出Rank-SVM(Ranking Support Vector Machine)算法[3],利用最大间隔策略构建多标记分类器。以上算法能够取得良好的实验效果,但伴随数据维数的增长,算法所消耗的时间也会增加。因此在多标记学习中引入数据降维,通过对数据进行处理,减少特征数目同时提高系统性能的方法。现有降维算法可以分为两种[4]:一是基于特征选择的属性约简方法,考虑特征之间的相关性,生成特征间冗余性较小的特征子集。二是基于特征提取的属性约简方法,根据对特征进行变换,把原始高维空间数据映射至新的低维空间,改变数据原有结构,保留数据信息。在多标记学习中,通过特征降维方法可以剔除冗余、重复的特征,减少数据的计算量,并提高算法整体的准确度。
数据降维可以有效提高数据的实用价值,因此采用奇异值分解[5](Singular Value Decomposition,SVD)对多标记特征进行维度约简处理,提出基于SVD与核极限学习机的多标记维度约简算法(Multi-label dimension reduction learning algorithm based on singular value decomposition and kernel extreme learning machine,MLDR-SK)。首先,采用SVD对原始数据进行奇异值计算,选择前k个奇异值,实现特征降维。然后,将降维之后的数据作为输入,通过特征和标记信息训练核极限学习机模型。最后,根据模型推测给定数据,在6个公开基准数据集上进行对比,记录4种算法基于5种不同评价指标的实验情况。实验结果表明,算法在多标记分类中能够发挥较好的效果。
1 SVD算法
假设有包含m个样本,n个特征的训练矩阵A∈Rm×n,则存在一个分解满足:
(1)
从而将原始矩阵A分解为U、Σ、VT三个矩阵的乘积,将此定义为奇异值分解[6]。式(1)中U和V视作酉矩阵,即满足UTU=I,VTV=I,Σ则视作m×n的非负实数对角矩阵,除对角线元素之外,其余元素均为0,具体可以描述如下:
U=[u1,u2,…um]∈Rm×m
V=[v1,v2,…vn]∈Rn×n
Σ=diag[σ1,σ2,…,σk],k=min(m,n)
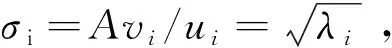
根据主成分思想,奇异值越大,其包含的信息就越多。实际上,在某个奇异值(第k个)之后,剩余的奇异值均很小。 也就是说,在此数据集中,只有前k个特征较为重要,其余特征都是次要特征。因此,奇异值分解,可以用于数据的降维或是去噪处理,实现数据中重要特征的提取。
2 多标记学习
2.1 多标记学习相关定义
在多标记学习框架下,假设样本空间X=Rp中,存在一个输入输出对D={(xi,Yi)|1≤i≤n},其中每一个xi=[xi1,xi2,…,xip]表示第i个样本中的p维的特征向量,而Yi=[yi1,yi2,…,yiq]表示与xi相对应的一组标记向量,yij表示第i个样本的第j个标记,yij=1表示输入样本中存在对应标记,yij=0表示输入样本中不存在对应标记。例如,一个问题中存在的类别标记有天空、草地、风筝、儿童,则此时yi表示一个四维的行向量(yi1,yi2,yi3,yi4),如果输入样本图片中仅包含天空和草地,那么Yi=(1, 1, 0, 0)。
多标记学习的根本任务即在已知多标记数据集D时,构建多标记分类器[1]f:X→2Y,令输入的待分类样本属性xi∈X,该分类器f能够推出属于该样本的类别标记集合f(x)⊆Y。
2.2 多标记学习评价指标
多标记学习框架中,广为使用的评价指标主要包括平均查准率(Average Precision,AP)、排位损失(Ranking Loss,RL)、覆盖率(Coverage,CV)、一错误率(One-Error,OE)、汉明损失(Hamming Loss,HL)等,其具体描述如下:
平均查准率(Average Precision,AP)用于评估在所有样本预测标记的排位序列中,排在相关标记之前的标记仍是相关标记的情形。该指标取值越大,分类性能越好,其定义如下[1]:
(2)
覆盖率(Coverage,CV)用于评测在样本预测标记的排位序列中,平均需要移动多少步才能覆盖样本的所有相关标记。该指标取值越小,分类性能越好,其定义如下[1]:
(3)
汉明损失(Hamming Loss,HL)用于评定样本的预测标记中分类错误的情况。该指标取值越小,分类性能越好,其定义如下[1]:
(4)
排位损失(Ranking Loss,RL)用于评定在所有样本的类别标记排位序列中排序不正确的情形,即对不相关标记的排位在相关标记之前的统计。该指标的取值越小,分类性能越好,其定义如下[1]:
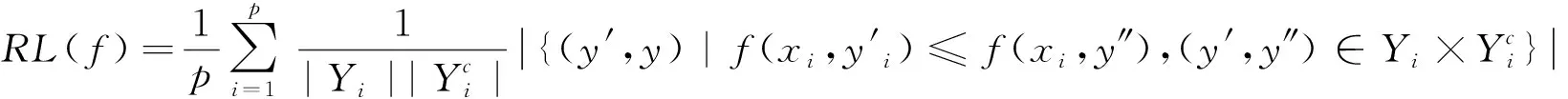
(5)
一错误率(One-Error,OE)用于评定在一系列样本的预测标记排位中,排在最前面的标记不属于该样本的相关标记集合的次数统计。该指标取值越小,分类性能越好,其定义如下[1]:
3 基于SVD与核极限学习机的多标记算法
3.1 基于SVD的数据降维处理
已知矩阵R,R是m×n阶矩阵,采用SVD分解方法将矩阵R分解成3个矩阵的乘积,如公式(7)所示:
Rm×n=Um×r·Sr×r·Vr×n
(7)
其中,U视作m×r的正交矩阵,V视作r×n的正交矩阵,S视作对角矩阵,而对角线上的元素则是奇异值。第一个奇异值最大,代表包含信息最多的方向,随着奇异值大小的改变,数据中包含有用信息的含量也在发生变化。因此,使用前k个奇异值可以有效描述样本数据集,实现数据集的降维。
在SVD数据特征降维中,矩阵奇异值特征能够实现对高维特征的局部特征提取及维数约简[6]。同时奇异值分解具有全局最优下的数据处理能力,因为特征值最大的前20%到30%可以有效保留数据集的大部分信息,所以本文针对多标记数据集采用SVD实现对数据的降维处理,计算多标记特征数据的特征值,保留特征值最大的前20%,实现SVD对多标记数据的降维。
原始数据集R是m×n阶矩阵,进行特征降维之后变成RD,RD是m×k阶矩阵,其中k≪n。
3.2 核极限学习机多标记分类算法
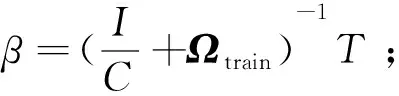
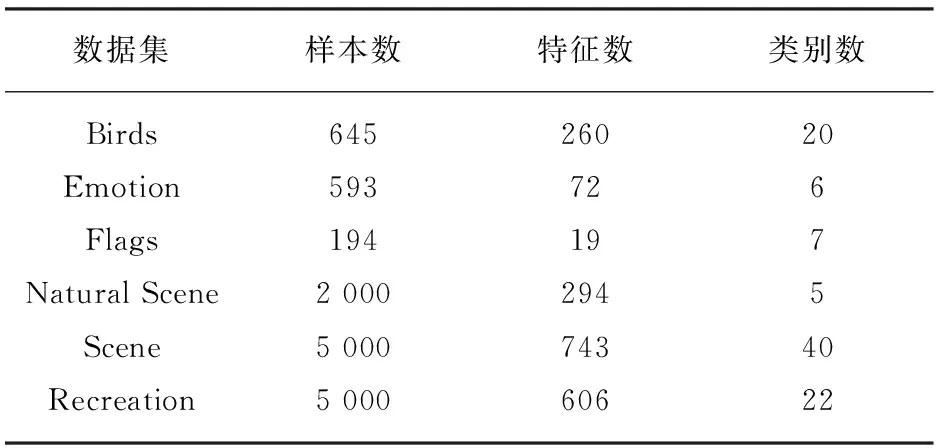
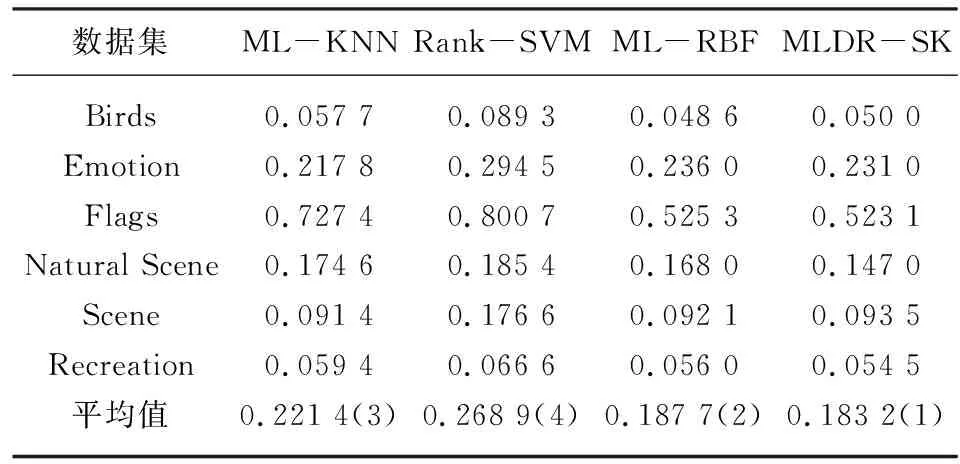
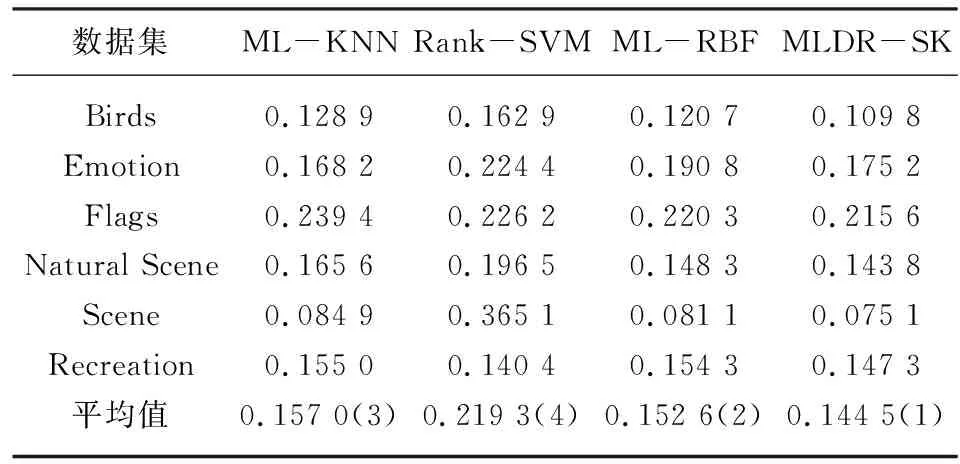
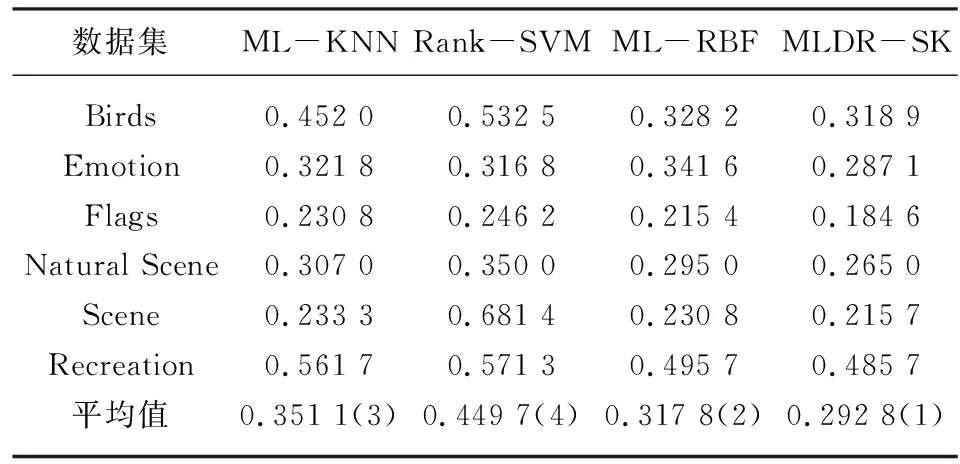
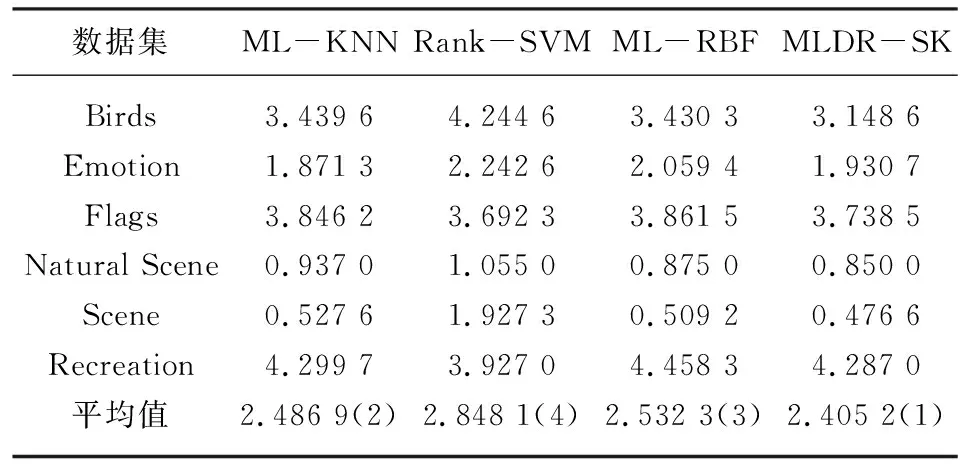
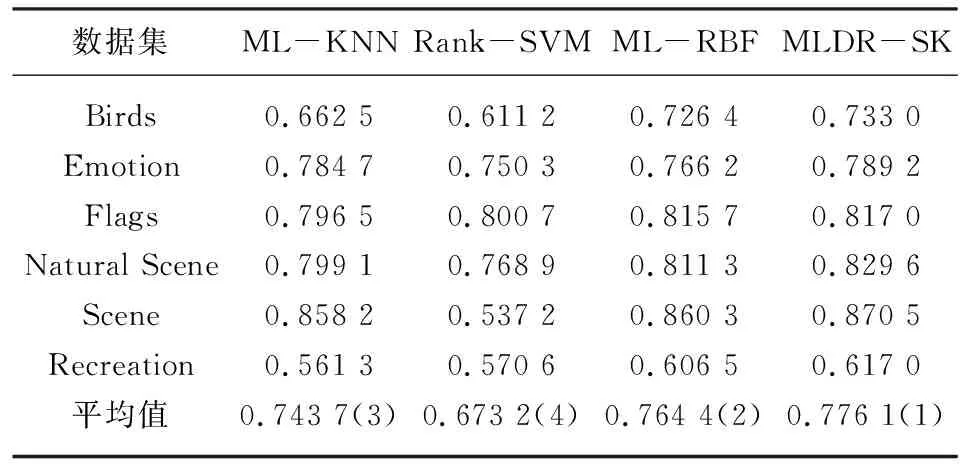
在多标记学习中,多标记数据集D={(xi,Yi)|1≤i≤n},n是每个数据集中的样本数量,对于每一个样本xi=[xi1,xi2,…,xip]都是P维的特征向量,利用SVD进行特征降维,降维后的样本为Xi′=[Xi1,Xi2,…,Xiq] ,q代表降维后的维度数(q 在极限学习机中,矩阵可以表示为: H·β=T (8) 其中,H是隐含层节点的输出,β是输出权重,T为输出期望。 β=H-1·T (9) 极限学习机的输出模型可以描述为: (10) β为权值向量,h(xi)则是将原始数据xi从输入空间映射至L维特征空间的向量。 按照Karush-Kuhn-Tucker (KKT)条件,能够计算出输出权值β,描述如下: (11) 其中,C是正则参数,标记分布输出函数可表示为: (12) 通过把核函数思想引入至极限学习机(ELM)[7],以核矩阵Ω代替ELM中随机矩阵H,能够在ELM的基础上增强模型的稳定性。利用mercer条件可定义核矩阵: ΩELM=h(xi)·h(xj)=K(xi,xj) (13) K(xi,xj)是核函数,核极限学习机的逼近函数可表示为: (14) 算法结合公式(8)和(14),首先,通过训练数据集已知标签,获得输出权值β,然后,将测试集特征映射到ΩELM中,估测输出标记。 输入:多标记训练集D={(xi,Yi)|1≤i≤n}; 输出:预测标记ypred。运算经过如下10个步骤: ⅰ:使用SVD对多标记数据集D作降维预处理,得出数据集D′; ⅱ:初始化正则参数C,核参数σ; ⅲ:for 训练集 ⅴ:end ⅶ:计算核矩阵Ωtest; ⅷ:end ⅸ:测试集预测标记输出f(xtest)=Ωtestβ; ⅹ:ypred=f(xtest); 为了分析算法的实验性能,共计选取6个公开基准多标记数据集,数据集信息如表1所示。所选数据集均是取自http://mulan.sourceforge.net/datasets.html。 表1 多标记数据集 实验代码均在Windows 10 、Matlab2016a 中运行,硬件环境Inter i5-4200 CPU 8G 内存。为了分析算法的实验性能,选择5种典型评价指标,分别是:平均查准率(AP)、汉明损失(HL)、覆盖率(CV)、一错误率(OE)、排位损失(RL)作为算法的性能评价指标。通过这5种评价指标来共同评价ML-KNN[2]、Rank-SVM[3]、ML-RBF[8]、MLDR-SK四种算法的性能,最终得出各算法的整体效能评估结果。如表2—6所示,用黑体突出标识,作为此实验结果的最优数值,采用统计分析的方法对各种算法进行排序。 表2—6分别给出在Birds、Emotion、Flags、Natural Scene、Scene和Recreation数据集上的算法实验结果。各评价指标之后的向上“↑”代表该指标的数值越大,实验性能越优;向下“↓”则代表该指标的数值越小,实验性能越优。 表2 汉明损失测试结果↓ 表3 排位损失测试结果↓ 表4 一错误率测试结果↓ 表5 覆盖率测试结果↓ 表6 平均查准率测试结果↑ 基于表2—6的实验结果进行分析,实验结论如下: (1)本文算法MLDR-SK在5种评价指标上均能取得较好的实验结果,在不同评价指标的平均值上排名均最优。 (2)算法在OE和AP评价指标上数值优于各对比算法,同时在其他几个数据集上也能取得较好的效果,说明算法能有效提高多标记学习精度。 (3)在Emotion数据集,本文算法在HL、RL以及CV等指标上性能略低于ML-KNN算法,仍优于其他对比算法,综合排名仍为第一。 (4)算法在多种不同的数据集上,均有较好的实验结果。在特征数目较大的数据集上通过特征降维,对降维之后的数据进行分类,能取得较理想的效果。 MLDR-SK算法对比现有多个算法,均能取得较好的效果,说明本文算法MLDR-SK是有效的,可以用于多标记学习,提高分类算法的精度。 稳定性分析:为了验证实验不同学习算法的稳定性,利用蜘蛛网图对不同评价指标进行稳定指数表示。图1显示了6个数据集上4个算法的稳定性。 从图1可知,图1(a)显示的是在Hamming Loss评价指标中,MLDR-SK在3个数据集上的平均精度的稳定指数值是4,在其他三个数据集上效果低于ML-RBF和ML-KNN。图1(b)显示的是在One-Error评价指标中,MLDR-SK在6个数据集上性能较优,稳定指数值在均为4,算法稳定性指标均优于其他算法。图1(c)显示的是在Ranking Loss评价指标中,MLDR-SK在4个数据集上的平均精度的稳定指数值在均为4,其中两个数据集上算法稳定性低于ML-KNN、Rank-SVM,但是稳定性数值仍高于其他对比算法。图1(d)显示的是在Coverage评价指标中,MLDR-SK在3个数据集上的稳定指数值在均为4。图1(e)显示的是在Average Precision评价指标中,算法在各数据集上表现比较稳定,稳定性指标均较优。 图1 具有不同评估指标的6个基准数据集测试获得的稳定性指数值 图1所示的结果表明,MLDR-SK相比于现有多种算法具有较好的稳定性,虽然在个别数据集上略低于对比算法,但是稳定指数值波动不大且整体较优,说明算法MLDR-SK可以有效提高精确度,适合多标记学习。 多标记学习是一种能够解决标记多义性的机器学习范式,本文提出基于SVD的多标记降维MLDR-SK算法。通过SVD计算多标记特征数据的奇异值,保留奇异值最大的前20%进行计算,实现特征数据降维。将降维之后的特征数据作为输入,帮助训练核极限学习机模型,完成对未知标记数据的预测。通过6个常见的多标记数据集,使用3种主流多标记分类算法进行对比实验,采用5种多标记分类评价指标对实验结果进行评价,结果表明MLDR-SK算法在多标记分类中可以有效提高精确度。3.3 基于SVD与核极限学习机的多标记学习算法
4 实验及结果分析
4.1 实验数据
4.2 实验环境与实验对比方案
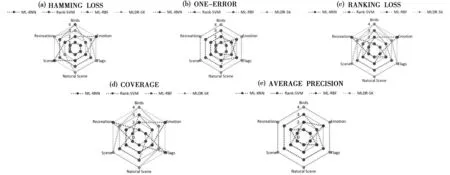
4.3 实验结果与稳定性分析
5 结 语
猜你喜欢
车主之友(2022年4期)2022-08-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
海峡姐妹(2019年12期)2020-01-14
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
火控雷达技术(2016年1期)2016-02-06
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
