
基于证据权重及信息价值筛选的信用卡透支风险检测模型的建构
2020-12-01 00:32:48徐公伟
宿州学院学报 2020年10期
谢 军,徐公伟
宿州学院商学院,安徽宿州,234000
透支是信用卡的常见形式,也是人们选择使用信用卡的重要原因,可促进信用卡市场发展。近年来人们对生活质量要求的提高,加上信用卡发行机构之间市场份额的竞争,信用卡透支现象较为普遍,但透支逾期不还现象也频发。在司法实践中,信用卡借款过期无法归还扰乱了市场金融秩序[1],由此产生的纠纷虽不应认定为诈骗罪,但应通过民事诉讼途径解决或贷款诈骗类犯罪追究刑事责任[2]。由于信用卡借款存在一定透支风险,有必要运用信贷管理中的技术手段预先评估持卡人的信用状况。
针对网络借贷客户的相关信息,刘志惠等[3]使用XGBoost机器学习模型,陈战勇[4]筛选出特征信息后使用逻辑回归模型,预测个人信用风险准确率分别为77.16%和82.10%。机器学习模型的预测准确率显著高于传统回归模型,尤其随机森林、决策树算法相较于传统逻辑回归模型准确率高,但模型的可解释性不强而且存在过拟合的问题。
利用证据权重方法测度信用风险,甘信军等[5]定量刻画了商业银行客户的违约概率,违约客户辨识率为88%。肖龙阶等[6]结合证据权重和逻辑回归针对个人网贷评估了其信用风险,预测准确率为86.45%,但仅研究1 382笔贷款数据,难以说明其方法的有效性。
从借款人信息角度考虑,Herzenstein等[7]认为,借款人信用状况、个人背景对能否如期还款有显著影响。廖理等[8]使用Probit模型研究认为借贷个人学历水平越高,客户违约风险越低。
个人财务状况直接影响着借款人的还款能力,财务状况越差,意味着借款人无法按时还款的可能性越大,本文利用持卡人特征、信用历史记录、交易记录等信息进行系统分析,挖掘数据蕴含的行为模式、信用特征,构建透支风险的检测模型。如果检测持卡人的透支风险在发行机构所设定的界限以内,则借贷申请处于可接受的风险水平并将被批准;否则将拒绝或给予标示以便进一步审查。本文将在完成证据权重理论推导后,量化评估信用卡的透支风险,为个人信贷提供可靠的风险检测方法。
1 数据来源及相关指标
信用卡透支检测相关的案例较少,考虑商业数据的敏感性,数据来源于美国数据挖掘与预测的“kaggle”竞赛,该竞赛在线提供了Give Me Some Credit训练数据共计约15万条,测试数据43 607条。该原始数据属于个人消费类贷款,从可实施信用测评的角度考查,具体指标如表1所示。
将透支数据与交易数据相匹配,透支账户在透支期间(第一次透支日到被发现之日)之间的所有记录即为透支使用;对非透支账户,其所有使用即为非透支性使用[9]。透支账户在第一次透支日之前的正常使用只为透支账户建立档案,信用卡这些正常使用作为非透支性使用也进入建模样本[10]。通过跟踪信用卡账户的历史数据,可以提炼账户的使用行为模式[11]。如果当前的使用与历史行为模式差别较大,则透支的可能性较大;判断当前的这笔是否可能透支,需要将当前的信息与建立的评分模型对比,相差越大则透支的可能越大[12-13]。
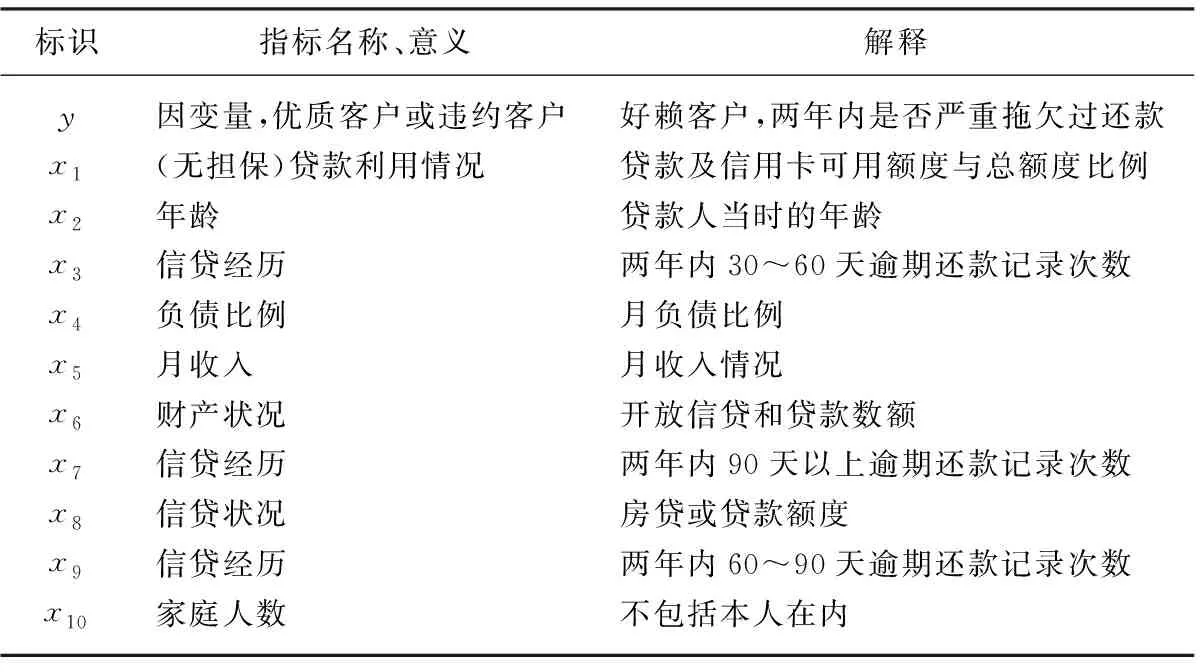
表1 数据的指标
2 数据预处理
x5、x10分别表示月收入和家庭人数指标的有效数据量,经过缺失值处理发现,月收入共缺失29 731个值,家庭人数缺失3 924个值。这种情况在现实中很普遍,为使后续的分析方法得以正常应用,需要进行缺失值处理。其中,月收入指标缺失率较大,采用随机森林法(Random Forest),根据指标之间的相关关系填补缺失值。采用python的pearson相关系数计算各变量间的相关性,各变量间相关性较小,共线性可能性小(表2)。
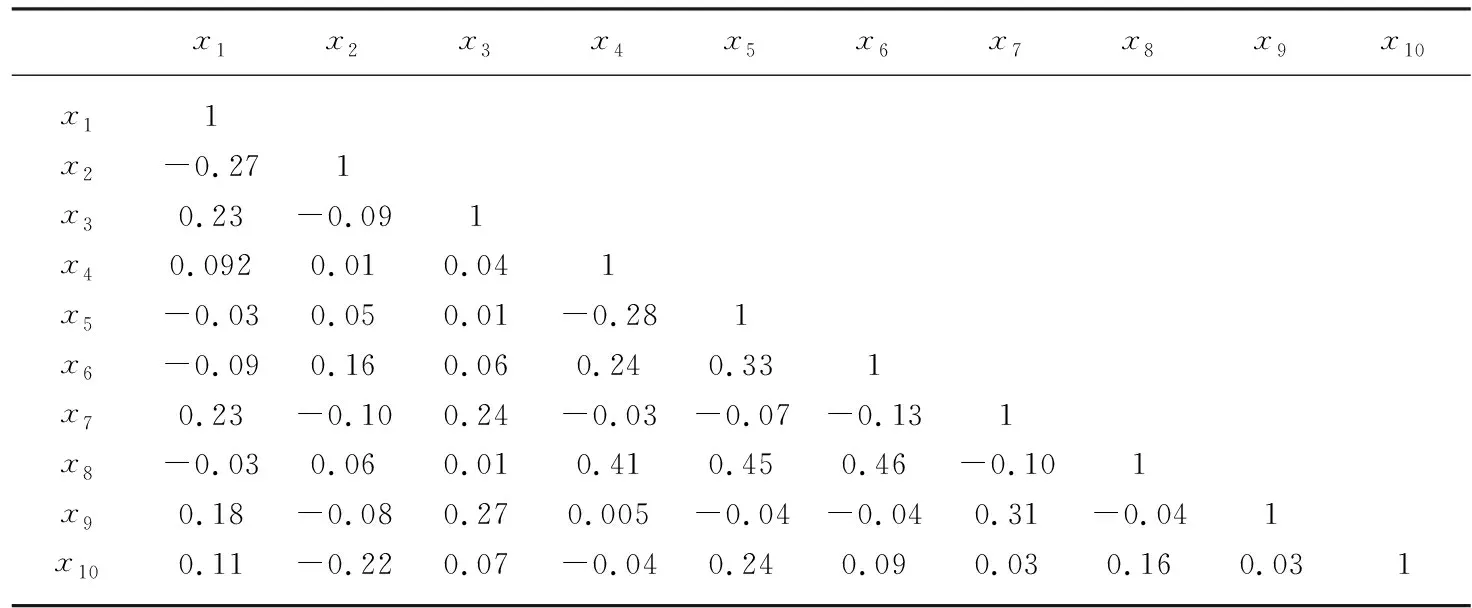
表2 多变量的相关性
3 相关假设与证据权重的理论推导
为将上述数据转化为证据权重,假设x是类别变量或分箱处理过的连续变量,含R个类别或分段,取值于样本集{C1,…,Cr,…,CR};y是目标变量,取值为0(Good)或1(Bad)。定义变量x第r类的证据权重WOE为:
因此WOE有监督的方法,可以将计算变量x的WOE看作是x拟合y的优化过程,则证据权重WOE关于x的函数写作:
WOE(x)=δ1WOE1+δ2WOE2+…+δrWOEr+…+δRWOER
其中,δ1,…,δR是二元虚拟变量,如果变量x取第r类,则δr=1或0。
通过以上定义和假设可知,证据权重WOE是变量x第r类中Bad与Good的比率与整个样本中Bad与Good的比率之比的对数值,其是衡量第r类对Bad和Good的比率的影响程度。当WOE等于0时,表示该类别中Bad与Good的比率与整体样本中Bad与Good的比率相等,说明该类别完全没有区分度;当WOE大于0时,表示该类别中Bad与Good的比率大于整体样本中Bad与Good的比率,说明第r类Bad和Good的比率的影响程度大;当WOE小于0时,表示该类别中Bad与Good的比率小于整体样本中Bad与Good的比率,说明第r类Bad和Good的比率的影响程度小。
下面根据证据权重WOE的定义建立信用卡透支风险检测的模型函数:
其对数损失函数可定义为:
l(y,p)=-ylnp-(1-y)ln(1-p)
=yln(1+e-f(x))-(1-y)(-f(x)-ln(1+e-f(x)))
=(1-y)f(x)+ln(1+e-f(x))
=(1-y)(WOE(x)+b)+ln(1+e-WOE(x)+b)
则整体样本的损失函数L记为:
ln(1+e-(WOE(xi)+b))]
ln(1+e-(WOE(xi)+b))]
ln(1+e-(WOEr+b))]
其中,Ir={i|xi=cr}为x的样本集,i=1,2,…,10。因此,WOE是使损失最小化的编码方式,计算WOE就是一次单变量建模过程,得到的WOE值使损失最小,即信息损失最小。常数b的不同取值会产生不同的WOE编码值,但不影响WOE编码的效果。由前述的推导可知,经过WOE编码后的单变量拟合逻辑回归模型将得到变量系数为1,截距项为b。
下面令损失函数L(y,p)的计算损失最小,即令整体样本的损失函数L关于WOEr的偏导数为0。
=0
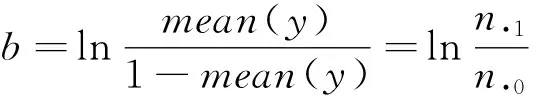
4 透支风险的检测模型
信用卡评分模型的分组操作常用等距分段、等深分段和最优分段三种,本文采用最优分段。定义信息价值函数(IV,Information Value)
IVi=(pyi-pni)*WOEi
是衡量第i个自变量xi的预测能力,则整个检测系统的信息价值函数IV=sum(IVi),i=1,…,10。从经验上看,过高的信息价值(IV)可能有潜在的风险,而且自变量分组越细,信息价值IV越高。
信息价值IV的预测能力:<0.05,无预测能力;0.05~0.09,低;0.10~0.39,中等;>0.40,高。通过以上各变量的样本值分组后计算得到各分组的WOE值,其中贷款利用情况x1与年龄x2的WOE如表3所示。
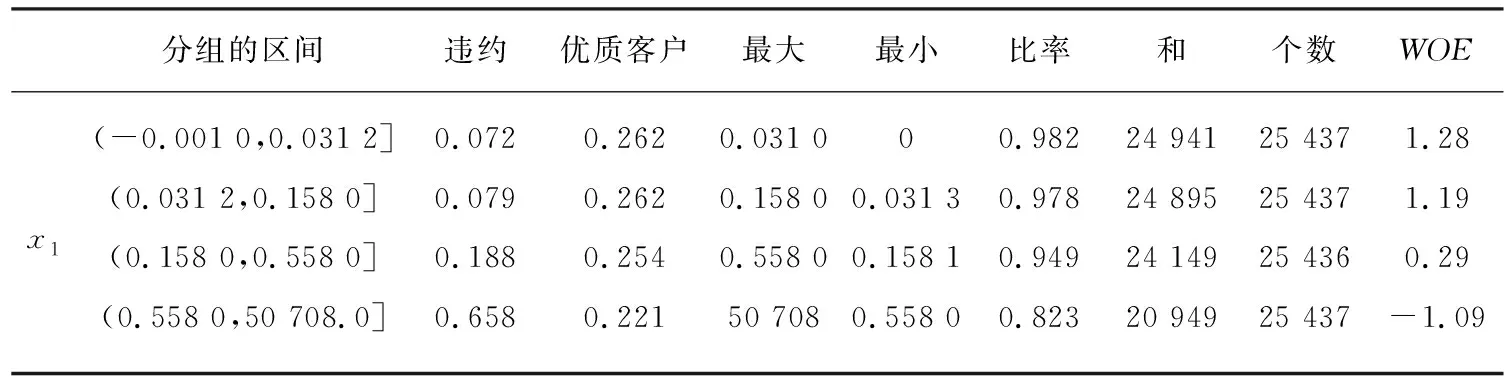
表3 贷款利用情况x1与年龄x2的证据权重
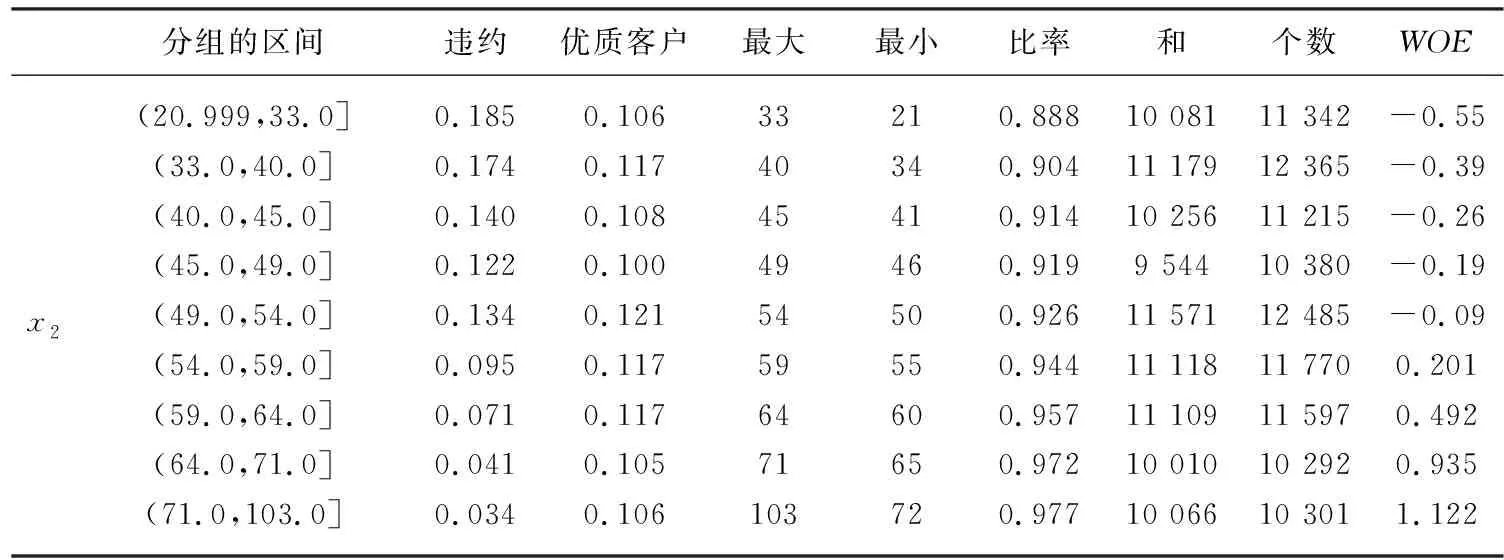
(续表)
由各变量WOE值进一步计算每个变量的信息价值(IV),确定各自变量的预测能力(表4)。

表4 各自变量的信息价值
由于构建评分检测模型需要参照多种变量,有些变量预测能力强,有些能力弱,如果不筛选会影响检测效率。而且,变量的子集(分组)之间很可能高度相关,造成“过拟合”,将影响模型的准确性、可靠性,在测试样本检测效果佳但由于训练过度,造成推广至新样本效果反而不佳[14]。因此有必要对以上自变量进行删选,这里的相关性分析只是初步检测,进一步检测的信息价值IV作为筛选变量的依据。
本文选取逻辑回归模型对因变量预测分析,属于广义线性回归模型,表达简单、预测能力有限。将单变量分组之后,每个变量具有单独的权重,这相当于为模型引入了非线性的变量,提升了模型的表达能力、预测精度,同时也降低了模型过拟合风险。
当IV值<0.1时,预测能力较弱,不带入模型进行拟合,故剔除负债比例、月收入、财产状况、贷款额度和家庭人数这5个变量,留下贷款利用情况、年龄、30天未还、90天未还、60天未还这5个变量。
在逻辑回归模型中,用优质客户与违约客户发生比率的对数表示为各变量的线性关系。信用卡评分模型用来评估信用卡持卡人是否会在未来出现90天逾期未还的现象,评分根据各变量的分配分数是WOE乘该变量的回归系数,加上回归截距offset再乘比例因子factor,即各变量的分配分数相加就得到了信用评分。
逻辑回归模型:Logit=log(优质客户数/违约客户数)
信用评分:Score=offset+factor(WOE×b)
计算得到逻辑回归模型的模型及其系数:
y=9.738 849 + 0.638 002x1+ 0.505 995x2+ 1.032 246x3+ 1.790 041x7+1.131 956x9。
计算结果显示观测数据量101 747条,伪R2=0.239 7,其余如表5所示。
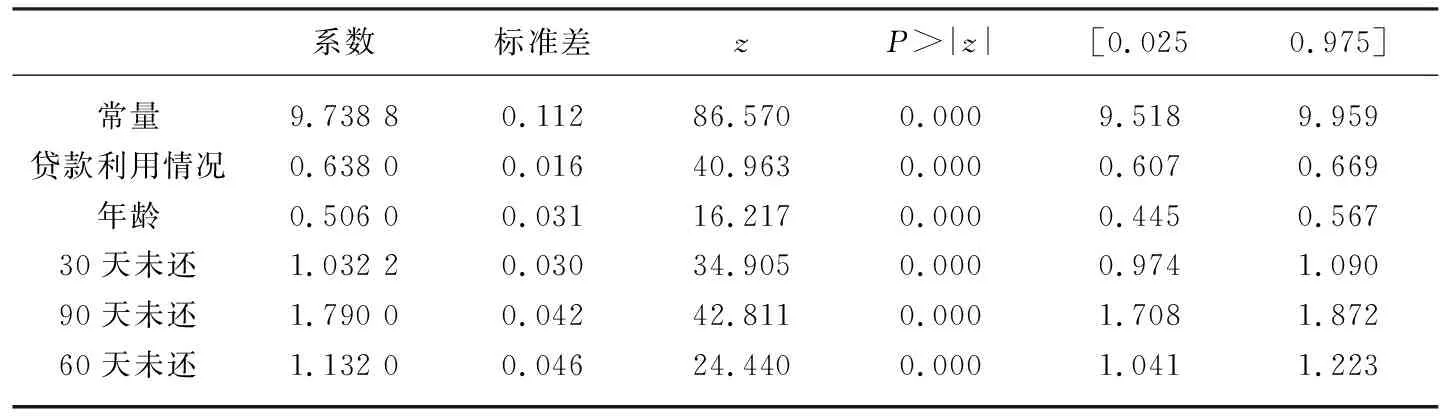
表5 逻辑回归的结果
逻辑回归的拟合结果显示误差较小,有泛化性能,各变量系数通过显著性检验,各变量与是否违约之间有显著关系,满足要求。最后使用计算信用评分AUC值为0.85,说明检测方法真实性较高,正确率较高,信用卡评分模型的预测效果较佳。
5 结 语
本文按数据的预处理、选择变量、建模分析的步骤建立了信用评分机制。根据该信用评分机制,银行可以从持卡人的信贷经历,即贷款利用情况、两年内逾期还款次数考查持卡人透支信用卡的风险。这样构建的评分检测模型可帮助银行及时发现异常账户,及时发现透支风险,避免金融损失,对恶意透支的用户发出预警信息,促使用户适度消费,同时这种机制也可以用来帮助持卡人做出最佳财务决策。
猜你喜欢
数学物理学报(2022年1期)2022-03-16 06:15:20
当代陕西(2020年17期)2020-10-28 08:18:18
人大建设(2018年5期)2018-08-16 07:09:00
瞭望东方周刊(2017年35期)2017-09-22 21:18:36
电信科学(2017年6期)2017-07-01 15:44:57
中国防伪报道(2016年10期)2016-11-21 06:39:00
公民与法治(2016年6期)2016-05-17 04:10:39
中国惯性技术学报(2015年1期)2015-12-19 13:12:07
中国检察官(2015年14期)2015-02-27 15:39:37
河南科技(2014年15期)2014-02-27 14:12:51
