
基于教育大数据环境的拟人机器学习问题研究*
2020-11-30 09:06李小平张琳孙清亮姜丽萍陈建珍
中国教育信息化·高教职教 2020年11期
李小平 张琳 孙清亮 姜丽萍 陈建珍


摘 要:教育大数据的出现无疑对教育人工智能机器学习是一个极大的推动,但是推动的核心在哪里、智能的条件和数据挖掘的条件是什么、智能有哪些步骤、如何完成机器学习下的教育智能化,一系列问题摆在智能教育推动者的面前。文章针对以上问题进行了实证分析研究,对教育数据进行了系列分析,找出了教育数据变化的规律和数据性质,给出了摸索数据与事件之间关系的方法——机器学习,并对主流机器学习进行了系统性分析,找出了一种适合于人类、适合于教育类型、在陌生环境下可学习、结果透明、可解释的拟人机器学习系统。
关键词:教育大数据;拟人学习;机器学习
中图分类号:G434 文献标志码:A 文章编号:1673-8454(2020)21-0001-06
一、引言
教育教学的智能化是相对而言的,智能只能辅助教育发现问题、找出教学规律、辅助发现教学应力问题,有相当行业的数据问题呈现出的是非准确的、非感知的、非捕捉的、非规律的、非人类遇到的问题,这种无规律的现象只能通过拟人的方法解决,并通过人的干预和认识,找出潜在的事物规律。
而当今技术的发展彻底改变了我们寻找教育教学潜在规律的方法和概念,这些进步主要是基于数据的量、复杂度和来源的指数级别的增长。由于这些技术极大地影响了我们应对具有丰富数量环境的能力,输入的数据是非线性的、非固定的、多模态/异构流的,混合了各种物理变量和信号以及图像、视频和文字,多源异构的大数据出现了。[1]教育大数据是大数据在教育领域的具体表现形式,它为新时代的教育教学创新提供了新的思路和方法,站在人的教育角度上相关研究如何从海量的教育大数据中提炼少量教学本质的信息、如何掌握其从大变小的过程、如何使人类教育带上人的特征或具有人的思维,那就必须从分析教育大数据问题下手。
要让教育具有人的思维和人的智力,先要完成对各种教育教学形态的辨识,只有在辨识的前提下才能够对问题进行决策。如何认识事物和分清事物类型,就要对海量的教育数据进行机器训练,形成模型方可实现智能控制和决策,教育智能化概要如图1所示。
二、教学大数据特性研究
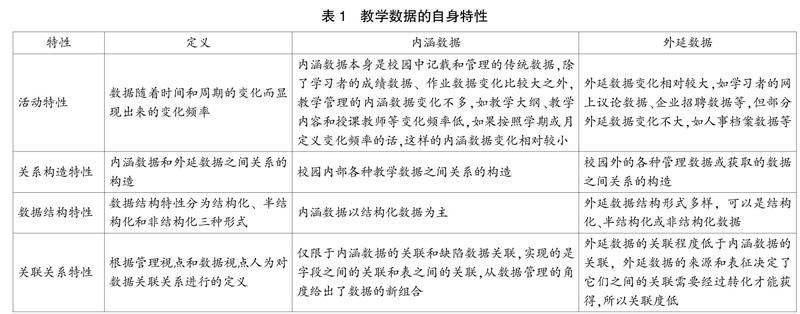
要研究人工智能,就要对数据来源和数据性质进行研究,找出数据事件的性质和类型,为下一步机器学习提取模型做准备。IT技术不断发展,随着教学办公自动化的推进、教育技术的兴起、教育技術地区差异化的普及应用,也产生了教学管理意志的不统一、数据化标准化建设程度不健全、教学政策变化过快导致政策不连续等情况,致使教育数据呈现出内涵和外延两大特性,如表1所示。
1.教学大数据时间轴问题研究
教学大数据时间轴描述的是多个事件发生的过程中所产生事件之间的顺序以及关系,它反映的是事件的特性。我们拟通过数据机器学习可以找出对应的教学策略和教学结果,还可以完成对事件的预测。[2]在时间轴上寻找事件之间的规律和关系是数据挖掘重要的研究方向,时间轴反映了事件的密度和数据的密度。
(1)事件密度:事件密度包括事件的惯性、事件的强弱、事件的稀疏、事件的叠加、事件影响力的持续、几个数据源对一个事件反映的错位以及突发事件的出现等。
(2)数据密度:数据密度与学习的惯性有关,例如学习者在业余时间上网集中等,这些都是教学惯性所反映的密度,属于正常密度。而那些不是预期范围的、突发的问题则是非正常密度,例如校园出现的突发冲突等。
2.教学大数据对象问题研究
教学大数据研究的对象是指那些在教学研究过程中起关键作用的、能被激活的数据。站在不同的教学者角度所关心的数据各不相同,因此需要在进行数据挖掘研究之前先确定所要研究的数据对象,其确定流程如图2所示。这个过程是在经验的基础上实现的,依据教学经验可以确定不同角色所关心的问题,由于关心的问题不同,需要获取的数据就会不同,在此基础之上展开大数据的处理。
3.教学大数据变化规律问题研究
教学过程是一个动态的过程,教学记录数据会随着教学过程的推进而不断发生变化,并且呈现出明显的特性,其中包括:
(1)惯性特性:教育一直延续着它的政策和惯性向前推进,这种推进是要符合教学规律的。教学数据同样常年存在着稳定性,在没有政策跳变的情况下,这些数据将维持着自己的变化规律,保持着一定的惯性特性。
(2)突发特性:教学过程中突发事件的产生将会导致教学数据的突变,这将对教学规律的挖掘产生一定的影响,但同时它也会从另一个角度反映出教学中存在的问题,对全面了解教学情况提供一定的依据。
(3)无规律特性:教学数据的变化虽然长期呈现一种变化的态势,但针对某些具体类型的数据,尤其是一些主观教学活动产生的数据,它的变化却是无规律的,这就需要进一步对其分析来获取这些数据变化的原因。
(4)叠加特性:影响教学过程数据的因素很多,这些因素有时候会单一地作用于教学数据,但绝大多数情况下会出现多因素共同作用于同一教学数据的情形,于是就会产生叠加效应。叠加效应的出现会加剧问题的复杂化,为数据的分析带来很多困难,例如一个政策产生影响的过程中又出现另一个新的政策,就会产生相互叠加和相互影响的问题,往往会打破教学规律。
(5)因果规律特性:数据的因果关系反映了数据之间的联系,通过对数据联系的分析,就可以挖掘出教学现象的原因。数据的因果规律可以根据影响因素的多少分为单因素因果关系和多因素因果关系,根据影响的结果还可以分为线性因果关系和非线性因果关系两种。
4.教学大数据衍生问题研究
教学中除了常规的内涵数据和外延数据之外,还存在很多衍生数据。通过衍生形成的新数据其本身的特性和作用点都将发生变化,衍生改变了数据的性质,对数据挖掘起到了辅助作用,它可以作为参考源,但不是挖掘的主流数据源。例如,在对学习者进行困难补助评选中,学习者在食堂的消费数据可以作为参考数据,但不能作为主要依据,它本身具有片面性,不能准确反映事实。[3]
5.教育大数据的分析结论研究
通过以上对教育数据的分析找出了教育数据的运行规律,找出了事件之间的、数据的对应规律,找出了事件和事件干扰所带来的影响因子。由于历史原因和管理因素的不系统性,造成主体数据和相关数据都不系统,整体数据结构混乱,虽然出现了多源异构,但是,逻辑规律非常不清晰,无法界定某一个事件集的数据是相对独立或完整的。如果按照抽样比对分析的方法,数据抽样明显,不具备有规律采集的条件。如果按照所有大数据进行训练并进行相应的聚类分析等,明显出现了数据的缺陷现象。如果按照单一事件去寻求教学教育的规律,明显不符合当今教学形式。怎样才能够对教学教育的事件進行有针对性的捕捉,如何在庞杂无章的教育大数据中识别事物的真相,如何进行区分和判别分类,并通过规则完成对事件的定位分类、形成人工智能模型,这是当今研究的重大课题。
三、神经网络机器学习方法的应用分析
在实施国家自然科学基金项目“考试作弊行为分析与研究”中,BP神经网络学习对考场动作行为影响方面,笔者进行了研究:对作弊行为进行训练,采集无限个样本场景,对作弊图像进行学习,试图找到中间结果,试图解释出决策的原因,我们采用了神经网络机器学习的BP神经网络进行训练分析。
本文共使用了135幅图像195个人脸进行实验,其中包括正脸80个、侧脸65个、俯视姿态50个,实验结果统计如表2所示。
在考试实际应用过程中,获得的二维考试现场往往是不确定的,试卷图像的大小、光线、角度、干扰、遮盖程度都直接影响其学习效果,必须完成严格的图像预处理,才可进行图像对象定位、特征学习训练。仅从训练字母数字相似度问题分析,我们为了减少机器学习次数,采用了基于级联分组网络将每次分类任务简单化的思想,将神经网络的任务简单化以提高其辨别能力。整个系统分成两级,第一级进行粗分类,即将相似的字符分为同一类别;第二级再对每个类别进行细分类,即将相似的字符区分开来。这样,每个子网络分类的数目就会减少很多,特别是第二级子网,就是区分几个类似的字符。整个框架如图3所示。
在机器学习训练输入层、隐含层和输出层节点数上,通常隐含层节点数越多越慢,但可达到更小的误差值,特别是训练样本误差,但超过一定的数目后,再增加则对降低误差几乎没有帮助,却陡然增加执行时间。[4]这主要是网络变得更加复杂、收敛更慢。因此,隐含层节点数目应当通过试验选取,是与其应用相吻合的个数。确定隐含层节点数的经验公式是:
s=■+0.51
公式(1)
式(1)中,s为隐含层节点数,m为输入层节点数,n为输出层节点数,计算值需经四舍五入取整。经多个实例验证,用公式(1)确定隐含层节点数比较可靠,一般能满足训练要求,有时也需略微调整。通常隐含层的层数为一层到两层时有最好的收敛性质,太多层或太少层的收敛效果均比较差。为此,我们在算法上进行了改造,有效限定了中间层级,在BP算法性能上取得了一些进展。
但是,整体训练量非常大,需要采集无限个样本场景,对作弊图像进行学习,几乎对中间结果无可解释,内部结构不清晰,无法清楚地解释做出某些决策的原因,自身也不理解正在处理的问题;BP神经网络能从图像中提取高级抽象内容,但无法以人类可理解的分析方式与所处理的问题相关联,没有明确的内部模型、语义结构,其隐藏层数量和许多其它参数都是临时确定的,无法在不确定的情境中工作。用结果对作弊进行实时捕捉,经常出现误判、漏判等致命性错误。
四、拟人机器学习问题的研究
让教育具有人的思维和人的智力,就要完成对各种教育教学形态的辨识,只有在辨识的前提下才能够提出问题的决策。对于如何认识事物和分清事物类型,要对海量的教育数据进行机器训练,而训练是一个非常庞大的工作,训练生成和处理的数据越多,计算就越复杂,耗时就越巨大,安全隐患就越大,风险就越高。由于教育大数据具有如此之多的不确定因素,如训练样本有限、数据不连续、数据呈现简短特征、数据有变化趋势、事件个性化特征明显、事件作用相互叠加、干扰度过高等,如果采用传统的深度学习,无法构成训练环境及条件,训练出来的决策如果缺乏透明度,其结果也无法进行解释,呈现出中间运算“黑箱”状态,人们很难断定训练结果是不是百分之百的可靠准确,如果按照传统深度学习方法去训练,并将其训练结果直接用于汽车自动无人驾驶的项目,很难保证在驾驶中不出事故。[5]
1.拟人机器学习问题的研究
究竟什么样的训练方法能够让教育决策者知道训练的中间结果的方向,所训练出的结果是否可靠、科学合理,教育数据能否通过机器学习训练完成智力思维的提升,且不带来致命的灾难,不会给人类带来负面的决策、判断性危险,这是未来教育人工智能解决问题的关键;针对传统机器学习训练种种不足的原因,各国都展开了这方面的基础研究。美国国防部高级研究计划局(DARPA)推出了拟人机器学习方法,即机器可以像人类那样进行学习的方法。
拟人的机器学习训练环境更加具有人的因素,需要训练的结果更加接近人的意志,不给人带来复杂的过多的工作量,在拟人的情感、拟人的视点、立体构造空间上进行自由思维;拟人可以找出问题,拟人可以对问题进行操控,拟人可以进行自我建构。拟人机器学习方法是最近引入的、基于深度规则系统进行的,从极小训练数据开始逐步建立起模型,通过原型来描述或注释学到的观察结果,解释系统为何做出决定以及学习一件事。我们将通过拟人的解决方法去处理数据教育问题,用拟人思维考虑人的智能参与度和教育自身的智能化。
拟人机器学习的方法非常适合训练样本有限、数据不连续、数据呈现简短特征、数据有变化趋势的行业,这种研究思路对非精准的、趋势性的、允许有一定延迟的、允许有一定干扰的、允许一定影响因子出现的、与目标出现偏差的数据训练更加有效,非常符合教育数据特性,人类学习与拟人学习比较问题如表3所示。
拟人化学习会使未来的教育智能机器和机器智能更好地为人类服务,也更与人类相像,同时大幅提高其处理量和自动化水平,更加准确透明,适应性强,自学习和计算效率高,更加增强了教育智能化的能力;拟人机器学习比起传统的神经网络学习更进一步地识别出未知情境,不仅可以识别此前已知的模式,还可以识别意外模式,能够意识到自身局限,能在面对未知和不可预测的情况时,启动安全程序,并从中自主学习,可高度自治,对人类友好、透明、符合人性。[6]拟人的机器学习方法非常适合教育智能研究方向,教育的数据特点与拟人的分类研究非常拟合。
2.主流机器学习和拟人学习的内容比较
目前计算机界推出了三种实现可解释人工智能(XAI)的方法和模糊逻辑方法,试图通过近似而非精确或量化的连续过程模仿人类思维,并在模糊规则系統(FRBS)上取得了进步,能够生成更短也更少的条件(if then)规则(与数量无关),保持系统获得高清晰度和可解释性的答案,与传统FRBS形成鲜明的对比;这是本文重点要推出的方法——拟人机器学习方法,即机器可以像人类那样进行学习。下面给出几个主流机器学习和拟人学习的内容比较,如表4所示。
3.拟人机器学习在未来教育当中的应用研究
能识别未知情境,并从中学习、自主学习,最关键的是基于深度规则(DRB)系统的;DRB是一个自组织、自适应、高透明、收敛性好、并行化基于规则的架构和学习算法,一种通用的新的机器学习方法,可以进行简单的修改。[7]用于图像分类的DRB系统的结构示意图,如图4所示。
从图4中可以看到,该分类器由以下组件组成。
(1)预处理块。它涉及在计算机视觉领域中广泛使用的预处理技术,包括归一化、缩放、旋转和分割。
(2)特征描述符。它将原始图像投影到一个特征空间。使不同类别的图像分离。I=>X。
(3)大规模并行模糊规则库。它是一种复杂的非线性预测模型,充当系统的“学习引擎”。每个大规模并行模糊规则由从训练集内特定类型的样本中识别的大量原型组成。因此,对于包含c个不同类型的数据样本,例如图像的训练集,if…or…or…then…识别出三个并行模糊规则(既一个类别一个规则)。
(4)决策器。一个类别带有一个局部/子决策器,给出一个局部建议。根据这些大量并行的局部建议的置信度,来决定胜出的类别标签。
基于识别出的原型RDB,从数据中自组织和自我演化一个完全透明且可由人类解释的条件逻辑(if…then…),大规模并行FRB系统。每个大规模并行的模糊规则是围绕大量原型确定的。这些原型从特定类型的训练数据样本中识别出来。RDB方法不是黑盒,它基于原型的特质提供内部结构的透明度和解释性。大多数现有机器学习方法都需要大量训练数据,而RDB系统甚至可以从单个例子中学习,也就是从零开始。即使是在完成训练/部署之后,非迭代在线自主学习算法也能进一步使RDB系统终身不断地学习新观察到的样本。因此它是不断演化的,对普通的问题场景与特殊场景相结合的补充性学习非常有用。[8]
例如,使用拟人学习的训练方法识别教育数据冲突事件时,发生于事件叠加的图形如图5 所示。
使用拟人的思想,不是识别一个二维图形,而是以人的立体化思维学习和认识事物,如果识别的原型有错误,可以随时替换正确的图形,每一个问题都非常透明,每一步骤都有解释;没见过的场景可以随时随地添加,这对于面对问题出发的教育事件识别可操控性非常强,能有目标、无风险地进行智能判断,为教学教育进一步智能化提供了有利的先决条件。
拟人的机器学习,可以边实践边学习,如果给出的规则有错误,可以修改,如果碰见没有见过的场景和问题,可以加到规则中,仅需要一两个案例学习就可以进行人机互通的交互式学习。不像神经网络对弈,物体要多角度、不同光线、不同场合进行采样,况且对其训练的结果还没有把握。
五、结束语
教育人工智能是一个庞大的系统工程,能否对事件事物数据进行正确的定位、找出数据的特性将是教育智能的基础,能否找到辨识事件和事物的关系和类型,及其学习的方法是提取有效模型的技术关键,能否进行透明的、可解释的、可调控的、陌生场景的机器学习,是第五代移动通信下教育人工智能的技术标志。盲目的数据挖掘将会带来劳命伤财的效果,科学的机器学习,按人的意志去提取教育所需要的东西,才是教育智能化的本质。脱离人的意志的人工智能是盲目的、无前途的。
参考文献:
[1]P.P.Angelov,X.GU,and J.Principe.“A Generalized Methodology for Data Analysis”IEEE Trans,Cybernetics,2017;doi:10 1109 TCYB.2017.2753880.
[2]C.M.Bishop.Pattern Recognition and Machine Learning,Springer,2006.
[3]A.Nguyen,J.Yosinski and J.Clune.“Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,”2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),Boston,MA,2015:427-436.
[4]Y.LeCun,Y.Bengio,and G.Hinton.“Deep Learning”Nature Methods, 2015,13(1):35.
[5]Plamen Angelov.Autonomous Learning Systems:From Data Streams to Knowledge in Real-time[J].2012.
[6]P.P.Angelov and X.Gu.“Deep Rule Base Classifier with Human-Level Performance and Characteristics,”Information Sciences,vol.263-464,208,pp.196-213.
[7]Angelov,Plamen & Gu,Xiaowei.Deep Rule-Based Classifier with Human-level Performance and Characteristics. Information Sciences,2018:463-464.10.1016/j.ins.2018.06.048.
[8]Gu,Xiaowei & Angelov,Plamen.Semi-supervised Deep Rule-based Approach for Image Classification. Applied Soft Computing,2018:68. 10.1016/j.asoc.2018.03.032.
(编辑:王天鹏)
猜你喜欢
现代交际(2016年24期)2017-04-14
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
