
基于联合特征和XGBoost的活动语义识别方法
2020-11-30 05:47郭茂祖赵玲玲
计算机应用 2020年11期
郭茂祖,张 彬,赵玲玲,张 昱,4
(1.北京建筑大学电气与信息工程学院,北京 100044;2.建筑大数据智能处理方法研究北京市重点实验室(北京建筑大学),北京 100044;3.哈尔滨工业大学计算机科学与技术学院,哈尔滨 150001;4.深部岩土力学与地下工程国家重点实验室(中国矿业大学),北京 100083)
(∗通信作者zhaoll@hit.edu.cn)
0 引言
移动互联网的迅速发展促进了基于位置的社交网络的形成[1]。社交网络融合了社交关系和位置信息,用户能随时随地分享包括位置信息、活动信息、个体情感信息、空间环境信息等动态内容,这些由活动所产生的移动性时空数据对基于位置的服务研究提供了数据基础,可用于挖掘用户的移动特征、活动偏好和生活模式。
对人类移动性时空数据的建模可以从时间和空间两个维度进行考虑。在时间维度上,人类的活动表现出一定的序列性[2-3]和周期性[4],而在空间维度上人类的活动则表现出一定的区域聚集性[5-6]。在建模个体移动的序列相关性中基于马尔可夫链的研究取得很好的成果,Cheng等[7]在原始马尔可夫链的基础上进行改进引入了一种因式分解个性化马尔可夫链;Zhang 等[8]则提出了位置转移概率图;Cho 等[1]建立了一个基于社会网络结构的人的移动模型,用于解释人类移动的周期性行为;Wang 等[4]建模了一种高斯混合模型将人类移动的规律性和一致性进行整合。上述研究都是对时间维度上的序列特征以及周期特征进行探讨,缺乏对空间信息的挖掘。而人类在活动选择上偏好于访问人数多的地方以及熟悉的地方,各种活动地点也有不同的属性。显然,这些特性的表达将对活动语义的识别提供更丰富的信息支持,但目前仍然缺少针对这些属性的研究。
针对上述问题,本文提出了一种结合时间特征和空间特征的人类活动语义识别方法。空间特征中的空间热点区域特征用于表示人类的热点访问区域,经纬度特征表示访问位置,时间特征则是基础特征,记录人类活动的时间信息。本文通过具有噪声的基于密度的聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)得到空间热度特征;时间特征表达人的周期和序列活动模式。相比较于K均值聚类算法(K-means clustering algorithm,K-means),DBSCAN 不需要指定簇类的数量,能够发现任意形状的簇,对噪声点也可以很好地识别。空间中的热点区域的数量不定,分布不均匀,受地理与地形的影响。因此采用K-means 聚类算法不能有效挖掘出空间热点区域。最后,利用极限梯度提升(eXtreme Gradient Boosting,XGBoost)算法来进行编码,建立结合空间经纬度特征、区域热度特征、时间周期特征的人类活动语义识别模型。XGBoost 是一种基于梯度提升理论的集成学习算法,有着良好的拓展性和高效性。与随机森林、AdaBoost 集成学习算法相比,XGBoost 算法针对损失函数、正则化和并行运算等方面做了改进,同样支持列抽样,当训练数据为稀疏值时还可以为缺失值或指定值设置分支的默认分裂方向,因此本文选择XGBoost 对活动语义进行分类,提高算法的效率和识别精度。
1 相关研究
时空特征的周期性是人类活动建模中显著的特征,工作、休息、饮食等活动具有很强的周期性。在许多对人类移动性建模的模型里都使用到了时空特征的周期性,如:Zarezade等[9]针对社交网络中用户的签到行为的周期性以及其社交关系提出了一个基于周期衰减核的双随机点过程的概率模型;Li等[10]则提出了一种时空数据周期性检验和度量方法以挖掘活动行为的周期性;Rizwan 等[11-12]使用核密度估计的方法来观察用户的活动时空趋势,并对空间进行回归分析,发现相对于男性,女性更倾向使用社交媒体数据,而且在工作日与周末的活动上二者也表现出差异性。
序列特征是隐藏在人类行为当中的特征,人类的行为活动往往具有先后顺序,而序列模式就是指这种从语义时空轨迹中挖掘出来的有规律的序列。Ying等[13]将活动内容标签进行了连接,把各个活动语义串联起来(家-工作-吃饭),然后使用频繁模式语义挖掘来得到序列特征;Chen 等[14]将序列符号化之后,采用了一种基于序列的模式挖掘算法:STS-TPs(standing for Spatial-Temporal Semantic Trajectory Patterns)。
对于时空数据建模的无监督方法主要是通过聚类的方法。例如对轨迹点进行聚类,各个聚类簇中的轨迹可看作具有相同的行为或进行着相同的活动。聚类的方法主要有两种:基于距离的聚类和基于密度的聚类。为了得到用户的行为规律,基于距离的聚类方法往往需要首先衡量轨迹的相似性,包 括CPD(Closet-Pair Distance)、SPD(Sum-of-Pairs Distanc)、DTW(Dynamic Time Warping)、LCSS(Longest Common SubSequence)、EDR(Edit Distance on Real sequence)等,其中LCSS 和EDR 对噪声具有更好的鲁棒性,而CPD 和SPD 计算开销比较小。Redondo 等[15]将熵分析与聚类技术结合起来证实社交媒体活动中的意外行为是该城市活动意外变化所导致;Cao 等[16]提出了一种社交学习模型,根据用户偏好和社会关系来评估兴趣点,之后还将用户地理信息整合到模型框架中,使用聚类的方法形成个性化的兴趣点(Point of Interest,POI)推荐列表;Zhong 等[17]提出了一种多中心聚类算法来捕获用户的移动模式并开发一种用户相似性度量的方法;Sakkari 等[18]通过使用无监督竞争学习算法自组织图和基于密度的聚类方法来识别和检测人群,然后建立熵模型用于检测城市中的异常事件;Coelho Da 等[19]提出了一种在线轨迹挖掘的框架,用于得到用户的行为规律,其中采用了基于距离聚类的方式对轨迹段进行聚类。
在预测算法方面,近年来机器学习发展迅速,作为统计学和计算机科学的交叉领域、人工智能以及数据科学的核心方法,广泛地应用于许多领域,解决了各种各样的问题,在轨迹模式识别、活动预测等相关领域中也有着很好的效果。Liao等[20]采用了两个基学习器和一个元学习器将时间特征和序列特征整合起来用于预测用户的活动目的和活动位置;Lv 等[21]通过将原始的全球定位系统(Global Positioning System,GPS)轨迹分割从中提取出活动点,进而得出活动场所,并结合时间特征、空间特征和序列特征提出了一种增强型位置分类器用于活动预测;邓尧等[22]则使用用户签到内容的短文本来进行地理定位,从短文本中提取实体,之后建立实体与位置间的概率模型,然后对候选区域进行排序选择排名最高的位置作为结果;Fu 等[23]应用自然语言处理的方法从用户发布Twitter 帖子中的文本内容挖掘用户的活动类型,并根据时间和空间分布来评估得到的活动类型。
2 联合特征和XGBoost理论
针对基于社交网络签到数据的人类活动语义识别问题,本文提出了基于联合特征和XGBoost 的活动语义识别方法,该方法包括两个主要模块:联合特征提取模块和XGBoost 分类模型构建模块。联合特征指用户在进行某活动时的空间特征和时间特征,空间特征指经纬度特征、区域热度特征,其中区域热度特征使用DBSCAN 提取出用户活动的聚集区域(不同的簇),然后计算各个簇中包含元素的数量,将空间中的区域的热度量化作为该空间区域的热度特征;时间特征指时间信息中的季节、月份、星期、工作日、时间点;将以上特征组成特征向量用于XGBoost 的输入通过训练学习构建分类模型。图1概述了本文方法的模型架构。
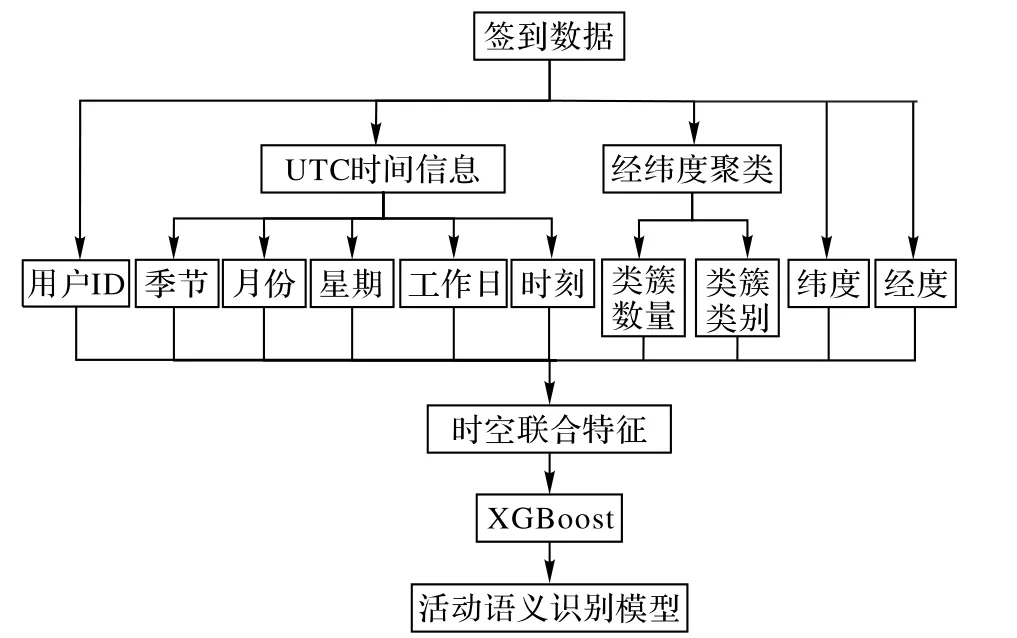
图1 基于联合特征和XGBoost的活动语义识别方法框架Fig.1 Framework of activity semantic recognition method based on joint features and XGBoost
2.1 特征提取
签到数据信息中一般包含4 个主要信息(U,L,T,A),U 表示User 用户,L 表示Location 具体地点,T 表示Time,A 表示Activity 即进行的活动或者一些用户在当前时间位置所记录的文本、图片、视频等信息。
本文从空间、时间两个维度进行特征提取,其中空间特征除了经纬度特征之外还针对人群的行为特点来提取,即个体进行特定活动时具有较大概率选择访问热度高、访问人数多的区域,因此采用基于密度的聚类方法DBSCAN 得到这些高热度的访问区域,并将其结果量化,从而得到空间特征。
时间序列特征是指人类不同活动行为之间的序列相关性,在移动轨迹问题中主要是从时间序列中获得,但是对于签到数据来说存在时间间隔不固定、签到次数不固定等问题,不能够有效地从时间序列中得到序列特征。时间周期特征主要指人类相同活动之间的周期相关性,包含时间数据中提取的季节、月份、工作日、小时等特征,对于时间特征是指在不同天、月、季节在同一时间进行活动的周期性。
2.1.1 基于DBSCAN聚类的空间特征提取
DBSCAN 是一种典型的基于密度的聚类算法,相比较于K-means这种只适用于凸样本集的聚类,DBSCAN 还适用于非凸样本集。DBSCAN 的显著优点就是聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类,该算法利用基于密度的聚类概念,要求聚类空间内所包含的对象数目不小于给定阈值,过滤低密度区域发现稠密样本点,同一类别的样本之间紧密连接。在空间上人类活动表现出一定的区域聚集性,而实际的地理位置上确实存在一些热点区域,例如繁华的市中心、商业步行街、网红餐厅、著名景点等。本文研究使用的数据集是FourSquare 的公共签到数据集,其实际签到位置图如图2 所示,其签到位置热力图如图3 所示,K-means、DBSCN聚类结果分别如图4、图5所示。
结合签到位置以及热力图可以发现有一些地点,人们对于其的访问次数要比其他地方多很多,本文基于这一空间中的热点区域访问量大的特点,考虑在识别人类的活动语义时人们对于此类地区的访问可能性应大于其他地方。因此在识别的时候采取DBSCAN 聚类方法将这一空间特征提取量化,作为表达活动语义的特征之一。算法步骤如下。
算法1 DBSCAN聚类算法。
输入 n 个样本的数据集D,半径参数ε,邻域密度阈值MinPts;
输出 样本集合的聚类C。
1)标记所有对象为unvisitied;
2)Do
3) 随机选择一个unvisitied对象p;
4) 标记p为visited
5) If p的ε邻域至少由Minpts个对象:
创建一个新簇C,并把p添加到C;
令N为p的ε邻域中的对象集合
For N中的每个点p:
If p是unvisited:
标记p为visited;
If p 的ε 邻域至少有MinPts 个对象,把这些对象添加到N;
If p还不是任何簇的成员,把p添加到C;
End For
输出C
6) Else 标记p为噪声
7)Until没有标记为unvisited的对象
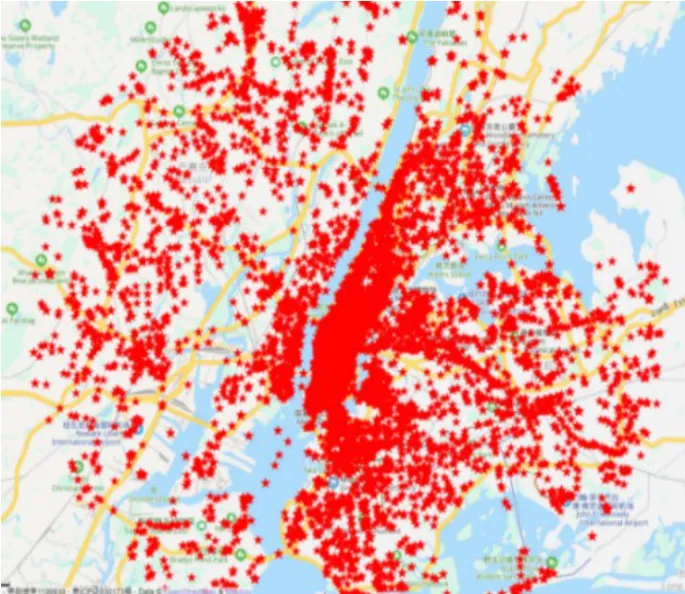
图2 纽约市签到数据地理投影Fig.2 Geographic projection of New York city check-in data
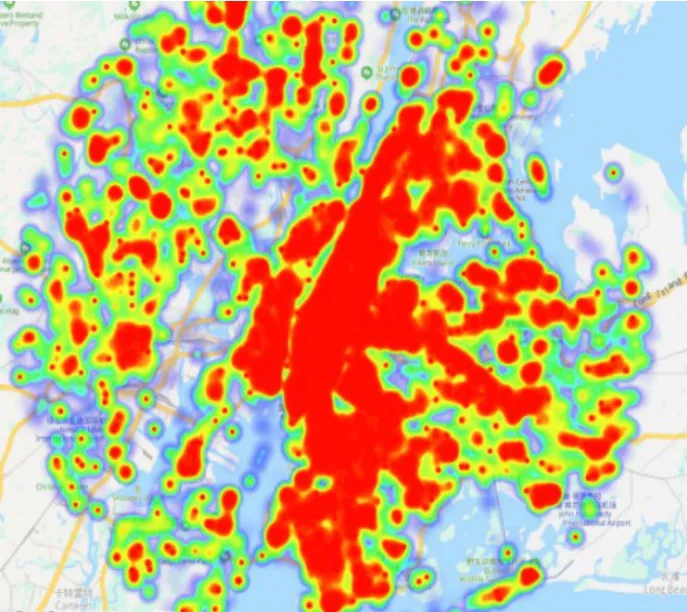
图3 纽约市签到位置热力图Fig.3 Heat map of New York city check-in locations
从K-means 和DBSCAN 聚类结果可以看出,K-means 聚类结果中各类别以区域划分,而DBSCAN 则是以区域内访问量即签到点的密度划分,因此可以更好地挖掘空间区域热度特征。所以本文选取DBSCAN 聚类方法,并从聚类结果中提取了两个特征:聚类的类别标签、各个聚类结果簇中包含元素的数量。两个特征均反映空间区域的热度特征,对于那些访问量大的热点区域,其簇中的点多占比就大,人们再访问其地点时的可能性就高。从空间中得到的区域热度特征是基于对区域的访问偏好所提取的。
2.1.2 时间特征提取
对于签到数据来说,存在用户签到时间的不规律性、签到间隔的不确定性,整个签到行为具有很大的随意性,这就导致了签到数据集本身稀疏的问题。本文提取了季节特征season、月份特征month、日特征day、星期特征week、工作日特征workday、时刻特征hour1、时刻特征hour2,其中month、day、week、hour1 从协调世界时(Universal Time Coordinated,UTC)时间信息中获得,hour1的精度为小时向上取整。
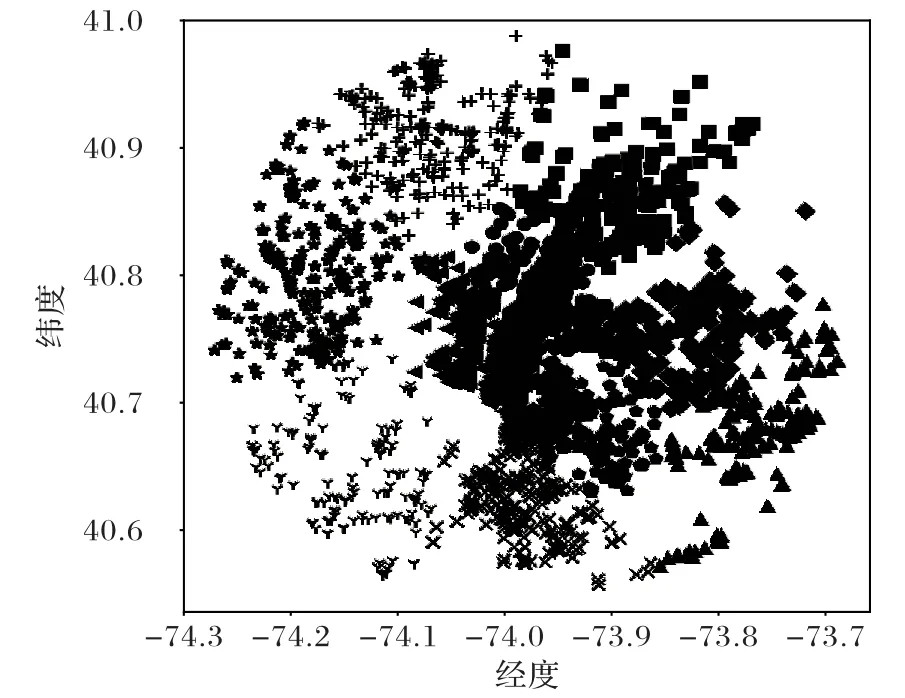
图4 基于K-means聚类的热度分类结果Fig.4 Heat classification results based on K-means clustering
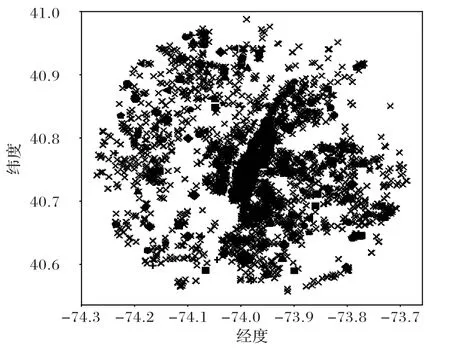
图5 基于DBSCAN聚类的热度分类结果Fig.5 Heat classification results based on DBSCAN clustering
季节特征season 按纽约气候特征,划分3~5 月为春季、6~8月为夏季、9~11月秋季、12~2月为冬季。
工作日特征workday 周六日为休息时间,其余为工作时间。时刻特征精度为小时分为两种特征hour1 和hour2,hour1为一天当中所属小时24 小时制,hour2 为一周当中所属小时7*24 小时制。其余的月份month、日day、星期week 直接从数据中提取。各特征计算方法见式(1)~(3):

2.2 基于XGBoost的用户活动语义识别
XGBoost是传统Boosting方法的一种,Chen等[24]首次提出此算法。对于包含n 个样本m 个特征的训练集Data={(xi,yi)},i=1,2,…,N。XGBoost 预测值由多个分类回归树(Classification And Regression Tree,CART)构成的集成模型所得,表示为:

式中:K为决策树数量;fk(xi)为第k棵CART对数据集中第i个样本计算分值;F为所有CART函数所构成的函数空间。
XGBoost 算法中模型学习的目标函数考虑损失函数和正则项两部分,正则项用于控制模型复杂度,避免过拟合,表达式见式(5):

式中:T 是叶子节点总数,r 代表控制叶子数量权重的参数,wj为第j个叶子的权重,ft是树的模型函数。
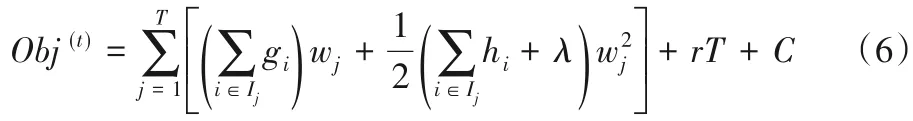
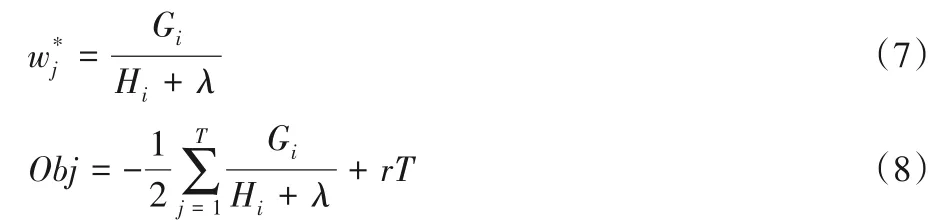
XGBoost 对损失函数采用了二阶泰勒展开,同时用到了一阶和二阶导数,在代价函数中加入了正则项,用于控制模型的复杂度。缩减(Shrinkage)技术削弱了每棵树的影响,列特征二次采样,可以减少计算同时降低过拟合。对于高维稀疏性数据XGBoost 采用了一种稀疏感知的分割搜寻算法,对于样本在某特征缺失无法划分时,将样本分别划分到左节点和右节点,然后计算其增益最终划分到增益大的那边。XGBoost还具有高效性,在训练开始时会进行一遍预处理来提高之后每次迭代的效率,多线程的并行计算也会减少计算时间的开销。XGBoost算法步骤如下:
算法2 XGBoost算法。
输入 训练集样本Data={(x1,y1),(x2,y2),…,(xm,ym)},最大迭代次数k,损失函数L;
输出 XGBoost模型。
1)循环增加一棵CART ft(xi)
2)采用贪婪算法建树,对迭代轮数t=1,2,…,k有:
①对样本i=1,2,…,m,计算损失函数的一阶和二阶导数(取负值):
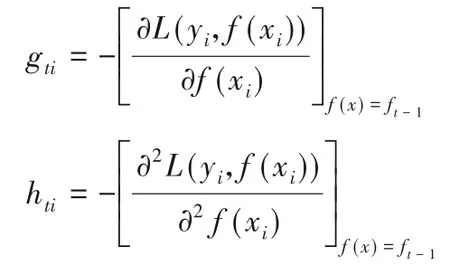
②利用(xi,gti),(xi,hti),拟合CATR,得到第t 课树,其对应的叶子节点区域为Rij(j=1,2,…,J),其中J 为新添加树的叶子节点数。
③对叶子区域j=1,2,…,J,计算最佳拟合值:
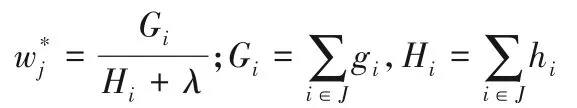
④计算节点分裂的最优增益:
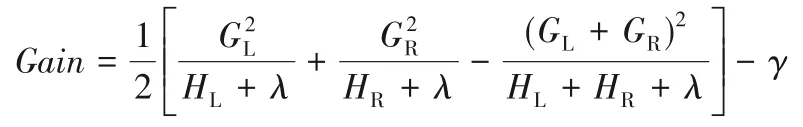
3)用构建好的树迭代优化函数空间:
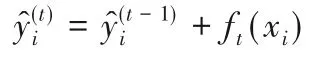
4)重复1)直到生成第k棵树。
3 实验设计与结果展示
3.1 数据集描述
本文实验采用的数据集[25]是从2012 年4 月12 日到2013年2 月16 日从Foursquare 上收集的公共签到数据,数据集总共包含8列,分别是:1)用户ID(user_id);2)场地ID(Foursquare 编码);3)场地类别ID(Foursquare 编码);4)场地类别名称(Foursquare 编码);5)纬度;6)经度;7)时区偏移量(分钟);8)UTC 时间。涉及227 428 条签到信息、1 000 多位用户的记录。签到数据示例如表1 所示,此示例数据未包含场地ID、场地类别ID、时区偏移量。
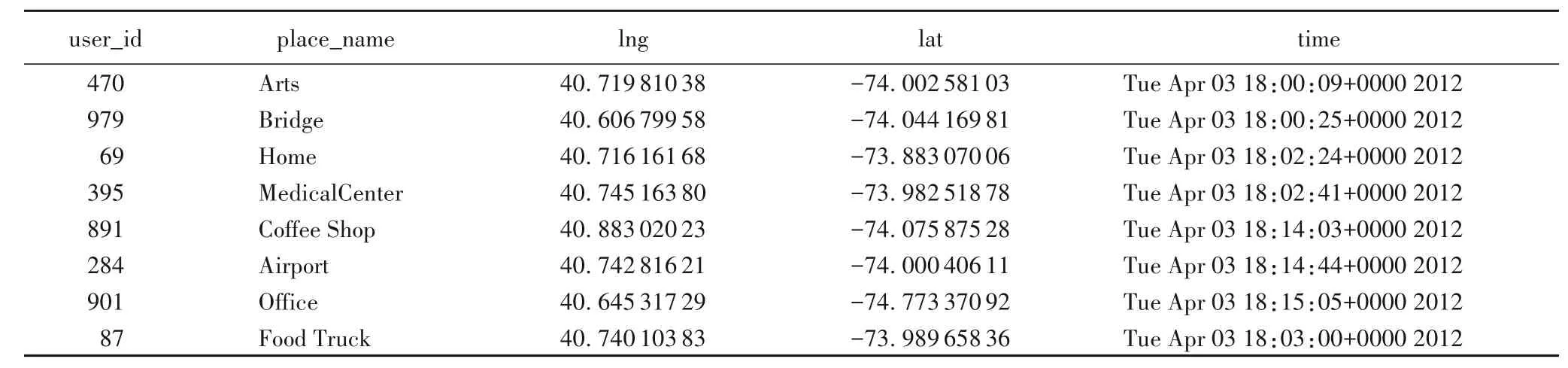
表1 用户签到数据示例Tab.1 Examples of user check-in data
3.2 实验设置
在相同实验条件下,从联合特征的有效性和识别算法的性能两个方面对本文方法的有效性进行了验证。在联合特征有效性方面,采用不同的特征组合进行实验结果的比较和分析;在方法性能评估方面,将本文基于联合特征和XGBoost 方法(Joint Feature and XGBoost algorithm,JF-XGBoost)与CAH(Context-Aware Hybrid)方 法[20]、STAP(Spatio Temporal Activity Preference)方法[25],在相同数据集下,以前k 个分类准确率Acc@top-k来进行比较。
XGBoost 参数主要分为三大类:通用参数、Booster 参数和学习目标参数。调参调整的是Booster 参数,通过穷举搜索所有候选参数,循环遍历得到最优的参数,利用的是GridsearchCV 网格搜索算法,参数优劣的评价标准是测试集准确率的高低。候选参数主要考虑:生成最大树的数目n_estimator,决定最大的迭代次数;学习率learning_rate,控制运行速度和准确率;树的最大深度max_depth,用于控制模型对样本的拟合程度。本文XGBoost 模型实验参数设置为:
n_estimators=1 200,learning_rate=0.1,max_depth=7,objective='multi:softprob'。
3.3 实验结果
时间特征和联合特征的对比实验结果如图6 所示。实验结果表明,基于联合特征模型在进行活动语义识别时效果更好,在具体数值上基于时间特征的模型识别准确率为0.300 46,基于联合特征的模型准确率为0.586 7,模型的识别准确率提高了28个百分点。
图7是XGBoost识别模型的混淆矩阵,由于本文以签到位置的签到点名称为标签,类别众多共247 类,其混淆矩阵太密集,因此本文对签到点的名称进行了归类总结,将247 类归为12 类用于展示说明。从混淆矩阵中发现Restaurant 活动的识别中出现了较多问题,许多错例被识别为Restaurant 项,出现这一问题从数据上分析是因为各项活动数目不均衡,Restaurant 项在所有数据中最多。签到数据在时间上,Restaurant项几乎包含所有时间点,并且签到数据集中只有签到时间,没有活动开始时间、持续时间和结束时间;空间上实际生活中存在一楼消费、二楼餐饮的设置,这样不同活动会在空间位置上重叠,因此导致其在时间特征与空间特征上具有很大相似性,所以在识别中会出现较多的问题。人们在进行签到时也偏向于签到那些新奇的地方,对于日常的活动行为记录相对较少,这也不利于活动行为的识别。
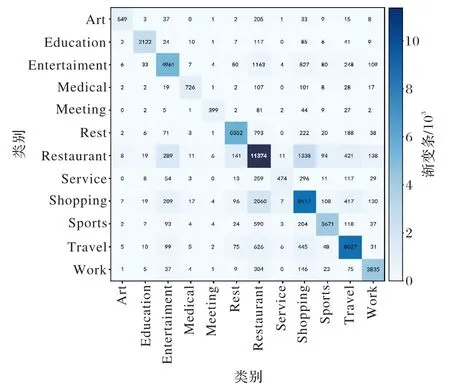
图7 识别结果混淆矩阵Fig.7 Confusion matrix of recognition results
本文对比了CAH方法[20]、STAP方法[25],结果见表2。
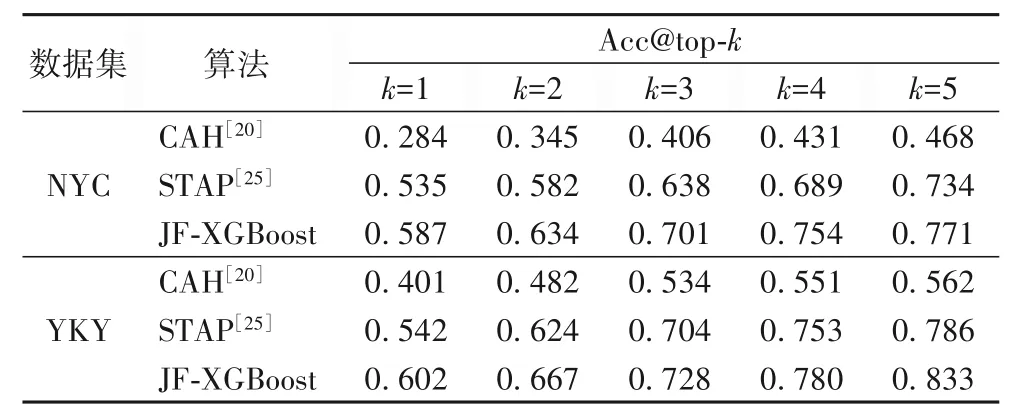
表2 识别算法对比结果Tab.2 Comparison results of recognition algorithms
通过算法对比和特征对比实验,本文JF-XGBoost 方法在活动语义的识别方面具有更好的效果,而且时空联合特征也在活动语义识别中也有重要作用。在空间地理位置访问上形成热点的空间区域,这是人类在现实社交生活中经过长时间的积累自然形成的聚集区域,具有十分客观的现实意义,在时间上一些日常的饮食、运动、工作等行为也有着明显的周期性特点,对于这些特征的深入挖掘将有利于活动行为语义的识别。
4 结语
本文主要研究了人类的活动语义识别,考虑了空间经纬度特征、区域热点特征,并结合时间特征,利用联合特征和XGBoost 集成学习方法从稀疏的社交媒体签到数据中识别用户的活动语义。相对于以往研究,增加了对空间热点特征的挖掘,通过无监督学习的DBSCAN 聚类方法从原始数据中获得空间热度特征并结合时间特征组成特征向量,采用XGBoost 算法学习数据中的信息,从而得到活动语义识别模型。在个人的活动建模方面,本文主要关注了空间特征和时间特征,以及地理空间、活动类型的整合等,但对于个体本身的偏好、属性等个人特点未加考虑,个人的社交关系网络也会对此有所影响,因此,将上述等问题考虑进活动语义建模中是今后提高识别效果的研究方向所在。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
互联网天地(2016年1期)2016-05-04
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
