
基于Senti-PMU 模型的文本情感分析
2020-11-20 06:07余亮蒋玉明
现代计算机 2020年29期
余亮,蒋玉明
(四川大学计算机学院,成都 610065)
0 引言
情感分析,也被称为观点挖掘,即程序对文本中隐藏的信息进行挖掘和分析,根据分析结果判断出文本包含的情感是正向还是负向的。正向情感代表积极,例如:赞美、高兴、兴奋等;负向的情感代表消极,例如:斥责、忧愁、悲哀[1-2]。
目前,互联网上的信息极速增长,囊括了在各个领域的海量信息。思科公司此前公布了一项统计数据,截止2018 年6 月,全世界的信息总量已达到4ZB,增长速度为每年100PB[3];根据IBM 研究,到2020 年全人类历史上产生的数据总量将高达220EB[4]。这些数字化信息中文本数据占很大比重,它驱动着自然语言处理技术快速地发展。提取数字文本中的语义情感信息成为自然语言处理技术的重点研究方向。
情感分析技术分为三种:情感词典方法、有监督的机器学习方法、弱监督的机器学习。
情感词典技术基于特定领域的情感词典信息,将整个文本匹配成为情感权值列表,将文本中的否定词取出,对整体权值乘以-1,将权值列表相加,结果大于0表示文本为正向的,结果小于0 表示文本为负向的。由于不同领域中有不同的关键词,因此构建合适的情感词典成为提升极性预测结果的瓶颈。Whissell[5-6]最先创建并修订了情感词典。后来李寿山等人[7]在英文种子词典的基础上,对英文词语进行翻译,构建出中文情感极性词典。现在,主流英文词典HowNet 或者WordNet;主流中文词典为HowNet 中英文情感词典、NTUSD 等。
为了克服情感词典技术手工扩充词典的复杂情况,机器学习方法应运而生。机器学习方法通过优化的算法与特定文本特征,可以匹配到特定词语的情感极性,从而减少重复的工作。Thomas Bayes[8]最先提出一种基于概率的机器学习算法:朴素贝叶斯算法、贝叶斯算法通过训练样本,计算所有结果的概率,找出概率最大的结果,可以用来计算情感极性。Vladimir[9]根据结果的类别数量,提出了适用于二分类的线性分类器,这种通用的分类起简化了对文本极性的分类工作。Sharma 等人[10]基于 Boosting 技术将多种“弱”支持向量机分类器整理到一起,以SVM 作为基础,利用了Boosting 技术的优秀的分类性能,结果显示该技术准确率非常高。Abbasi 等人[11]基于文本的语义规则,提出一种多元文本特征选择方法,同时考虑了语义信息和语法特性,其性能十分优秀。
弱监督的机器学习方法用于解决由于词向量导致整体文本的情感被忽略的情形。Ferndndez Gavilanes M 等人[12]提出了一种基于依存句法的无监督的情感分析算法,该算法在判断情感的极性方面表现优秀。梁斌等人[13]基于注意力机制,通过结合词性注意力机制,位置注意力机制,词向量注意力机制,提出了多注意力卷积神经网络MATT-CNN,从而帮助网络处理在文本中出现大量不一致的情感词的复杂情况。
本文首先提出研究背景和研究意义,并介绍了情感分析的相关原理和方法,后介绍Senti-PMU 记忆增强型循环神经网络模型,通过Amazon Review 数据集训练该模型,最后得出研究结果。
1 相关技术
1.1 Word2Vec
2003 年Bengio 首先提出了神经网络语言模型(Neural Network Language Model,NNLM)[14],该模型通过训练最大化似然函数从而计算n 元条件概率。2013年,谷歌发布了Word2Vec[15-16]的NLP 模型训练工具,Word2Vec 基于NNLM 模型,将输入的文本序列转换成为词向量。Word2Vec 训练得到的词向量是分布式表示(Distributed Representation)的低维实数向量,这种向量的优点在于,语义相近的词语,其欧氏距离更近,因此可以通过欧氏距离判断词语的相关度;由于分布式表示的词向量维度较低,因此不会造成“维度灾难”。
如图1 所示,通过PCA 降维的方法可以将词向量的分布和词向量的语义关系联系起来。如图1 所示可知,语义接近的词语在距离上更近。
1.2 SentiWordNet
2013 年,意大利信息科学研究所(ISTI)基于Word-Net 研发了一套情感词典SentiWordNet[17]。SentiWord-Net 词典记录了不同词语、词组在不同的词性下的情感值,它包含了10W+条记录,每条记录由POS、ID、Pos-Socre、NegScore、SynsetTerms、Gloss 的 6 个字段组成,其中文意思分别是词性、词条编号、正向情感值、负向情感值、同义词词条名和注释。SentiWordNet 词典中记录了4 类词性,分别是名词、形容词、动词和副词。
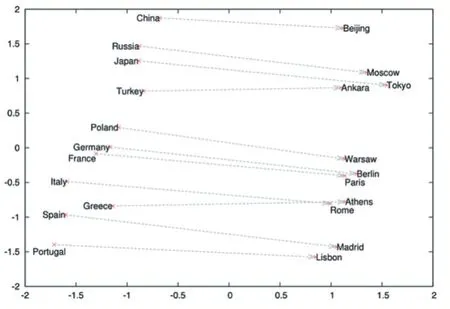
图1 词向量的二维表示
1.3 PMU
Ronald J.Williams 提出 Recurrent Neural Network(RNN)[18],RNN 在训练时容易产生梯度消失和梯度爆炸的情况。后来,S.Hochreiter 等人提出了Long Short-Term Memory(LSTM)[19],LSTM 包通过提出输入门、遗忘门、输出门,解决了梯度消失问题。后来,K.Cho 等人提出了 Gated Recurrent Unit(GRU)[20],GRU 剔除了输出门,训练精度更优秀。后来,Mohamed Morchid 提出了Parsimonious Memory Unit(PMU)[21],PMU 是基于节制记忆单元(Parsimonious Memory Unit,PMU)的神经网络,相对于LSTM 和GRU,PMU 只有一个更新门,精简的结构使其训练精度要优于GRU 等神经网络。PMU 前向传播函数为:
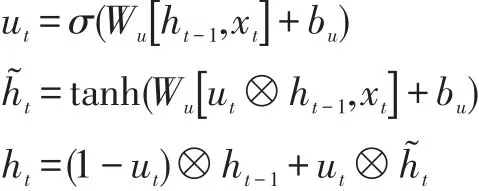
PMU 网络内部结构图2 表示。
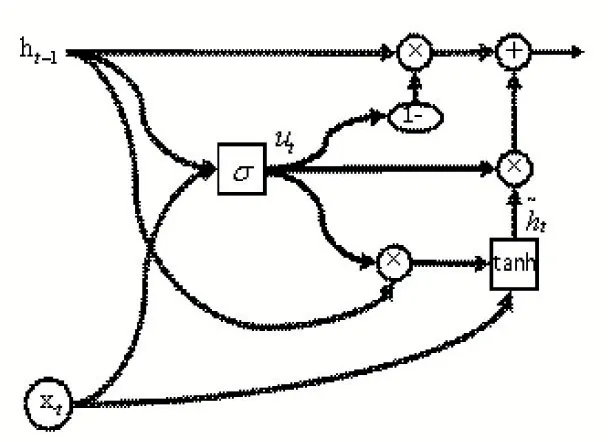
图2 PMU网络内部结构图
1.4 MLSM
潜在语义增强模型(Memory-Enhanced Latent Semantic Model,MLSM)[23]认为一个句子中关键词对整个句子的情感倾向起决定性作用,该模型基于关键词的情感值对网络的信息流动进行辅助地调控。例如,“I like watching movie a lot”,该文本是正向的,其中“like”是关键词,对整句话语义极性的贡献最大。
MLSM 模型根据上述思想,将关键词汇及其情感值制作成词库,根据输入的词语,在词库中查询该词的情感极性,情感极性的匹配函数如下所示:
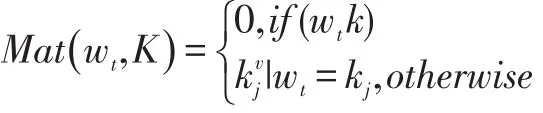
上述公式中,wt表示t 时刻输入的词汇,表示该词汇对应的情感值。若单词在字典中,则返回该单词对应于中的情绪值;若单词不在字典中,则情感值为0。Mat(wt,K)表示输入词汇为k 时的情感极性值。
MLSM 获取到每个情感值后,在前向传播的时候控制信息的流动,在LSTM 神经网络中MLSM 网络的信息流动公式如下所示:
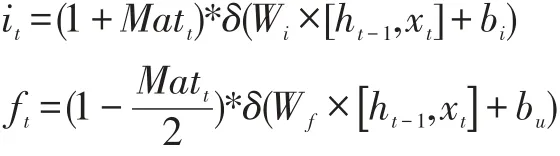
该公式中δ(Wi×[ht-1,xt]+bi)表示LSTM 的输入门,用来控制输入信息的记忆量表示LSTM 的遗忘门,用来控制舍弃的信息量。MLSM 通过匹配函数的结果值Matt,控制输入门和遗忘门内的参数数值,这种基于已有的输入的情感值从而辅助网络进行训练的思路可以提高整体网络的精度。
2 Senti-PMU模型
本文提出了Senti-PMU 模型,该模型在原有的PMU 模型基础上增加了MLSM 优化算法。在Senti-PMU 模型中,MLSM 分为匹配模块和控制模块。匹配模块用于根据SentiWordNet 词典取出每个输入实体对应的实时情感值。控制模块用于每个实体的情感值动态地修改每个Gate 控制的记忆量。
Senti-PMU 前向传播函数为:
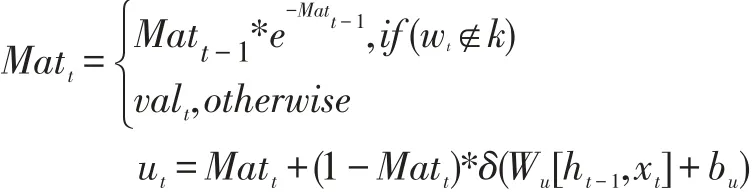
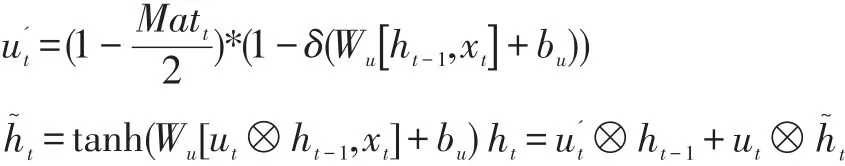
Senti-PMU 网络内部结构如图3 表示。
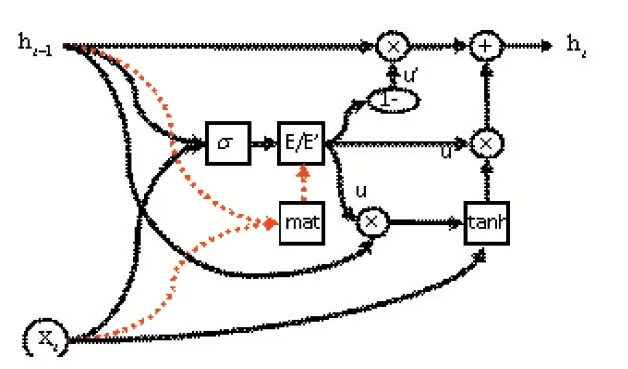
图3 Senti-PMU网络内部结构图
由图3 可知Senti-PMU 网络Cell 内部结构的具体逻辑。在上一阶段处理得到的状态ht-1,与当前输入xt共同作用。通过学习到的权重得到σ,也就是初期的记忆门和遗忘门。再通过匹配模块,判断当前词汇的情感值,通过控制模块,使其有规律性的修改u 和u'。得到了u',用来与ht-1产生作用,记忆之前的状态;得到u,与当前xt产生作用,记忆当前的内容。最后将之前的状态和当前的内容进行整合,得到当前的状态ht。整个过程中,只使用了一个门u,通过u 衍生出u'。极大地减少了计算模块数,使得当前网络训练时间更短。加入了MLSM 思想,使得网络精度得到了大大增加。
2.1 匹配模块
匹配模块根据SentiWordNet3.0 情感词典中的单词-情感值对应表获取输入单词的情感值。MLSM 认为,若单词不在字典中,则取出上一个时刻的匹配到的情感值,对其进行指数衰减,其结果要比实时的非衰减的情感值要好。
本文将两种MLSM 模型都结合到PMU 模型上。
若单词在字典中,则返回该单词对应于中的情绪值;若单词不在字典中,则情感值为0。应用于这种非衰减型匹配函数的PMU 模型在本文中统称为Senti-PMU。匹配函数表达式为:
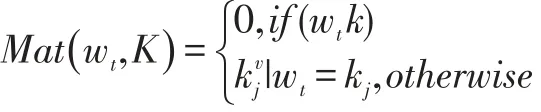
若单词不在字典中,则取出上一个时刻的匹配函数对应的情感值对其进行指数衰减。应用于这种衰减型匹配函数的PMU 模型在本文中统称为En-Senti-PMU。匹配函数表达式为:
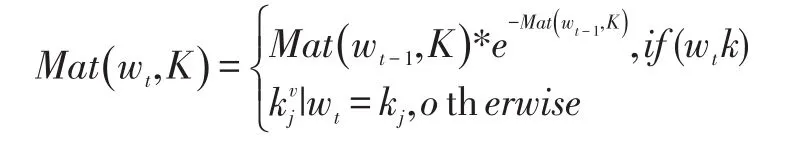
2.2 控制模块
控制模块用于控制信息的记忆量。分为E 和E'两个部分。E 表示对词语进行增强,它是优化后的更新;E'表示对词语进行弱化。控制模块的E/E'的表达式如下:
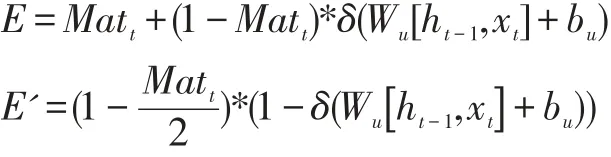
通过匹配模块找到匹配的情感值后,将其作用到控制模块上。控制模块主要起增强当前/过去记忆和减弱过去/当前记忆的作用。
模块中E 部分对当前输入起作用。具体地,当输入的词为带有强烈情感的词汇时,即匹配函数返回值较大,网络结构会对这个词进行深层次记忆。因此,这个网络结构对这个词记忆的权重匹配值增大,即最终的Gate 中的元素增大;相应的,增加当前词汇的记忆,就意味着减弱之前词汇的记忆。因此,这个网络结构对之前的状态记忆的权重减小,即最终的Gate 中的元素减小。
2.3 Senti-PMU网络结构
根据上述Senti-PMU,本文构建深度神经网络模型以实现文本情感分类,如图4 所示。
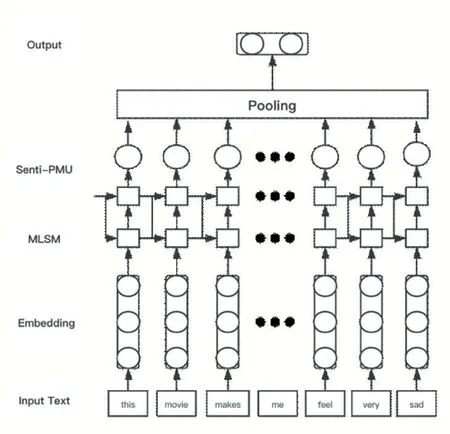
图4 Senti-PMU网络图结构
该网络结构主要包括输入层、词嵌人表示层、MLSM 层、Senti-PMU 层与Pooling 层。其基本流程为:首先将经过文本预处理的词序列作为网络输入,利用Word2Vec 词嵌人工具将词表达成向量然后逐步输入到MLSM 层,MLSM 层通过将隐藏层与输入的状态通过情感词典进行增强或者削弱,将结果输出到Senti-PMU 层进行运算,并通过Pooling 操作将Senti-PMU 层的输出进行聚合运算,最后利用Softmax 函数来计算输入的文本序列所属情感类别的概率。
3 实验
3.1 数据集
本文基于亚马逊商品评论的情绪数据进行分类。该数据集中,有150,000 条训练数据,其中:积极的评论数目为75,000,消极的评论数目为75,000;有30,000 条测试数据:积极的评论数目为15,000,消极的评论数目为15,000。
3.2 数据预处理
数据预处理包括数据清洗、替代处理、词型还原、数据集去重、命名实体处理、词性标注、词组匹配。
数据清洗的工作是要删除文本中的噪声数据,例如URLS 地址、HTML 标签,这些数据对结果毫无影响。替代处理是对表情符号、俚语和缩写词用标准表达的单词替代,如用“I am”替代“I’m”,用“January”来替代“Jan”、用“Very Important Person”替代“VIP”。词形还原是指将英文单词中的多种形态、含有重复字母的单词还原成单词原形,因为SentiWordNet 中单词都是以词根的形式保存的。提取词根的攻击有很多,NLTK模块中的 Snowball Stemmer、Porter Stemmer、Lancaster Stemmer、Regexp Stemmer 等工具都可以提取词根,本文中里使用的是NLTK 中基于WordNet 的词性还原工具WordNet Lemmatizer。数据集去重是去除训练数据集的相似影评文本,通过将相似度最高的影评文本进行合并,从而去掉训练集和测试集的重复数据。命名实体处理是指将文本数据中的一个命名实体的多个连续单词的首字母大写,NLTK 模块提供了一种基于CONLL-2000 Chunk 语料库的ne_chunk()方法用来识别不同命名实体。词性标注是指在进行词性匹配之前,将训练文本中的每个数据进行词性标注,后续可以在SentiWordNet 词典中的单词或词组对应到不同的情感值。词组匹配是指将输入文本中的词组转换成SentiWordNet 词典中对应的词组,这样可以避免词组无法识别。通过将输入文本中的词组的每个词语连接,再转成成SentiWordNet 中的多字词,可以避免将词组分割成单个词语去匹配,大大提高了输入文本的质量。
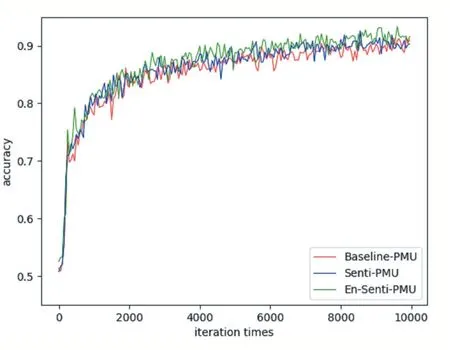
图5 PMU精度曲线
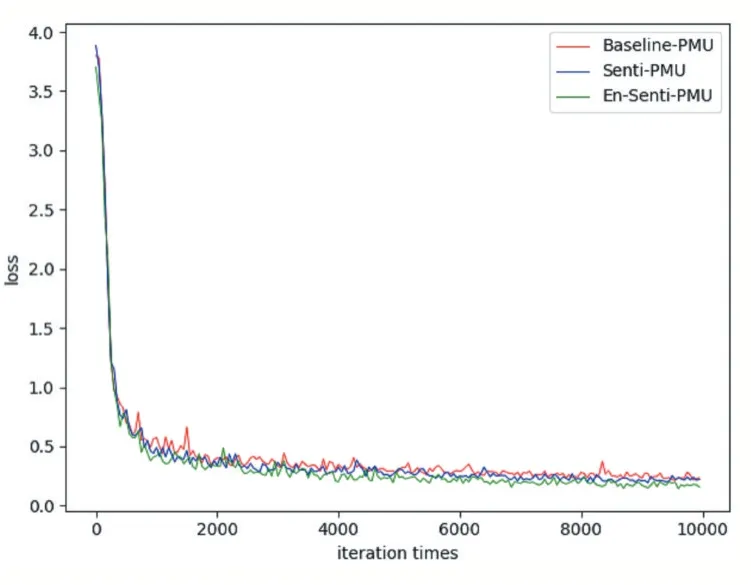
图6 PMU 损失曲线
3.3 实验分析
为了评价模型Senti-PMU,本文中选择深度神经网络器学习方法PMU,基于非衰减匹配函数的Senti-PMU 模型与基于衰减匹配函数的Senti-PMU 模型进行实验比较,以情感分类准确率为评估标准。
PMU 各模型的精度曲线如图5 所示,损失曲线如图6 所示。
由上述实验结果,可以总结成图表1。
通过表格中的数据可以发现,Senti-PMU 模型对比PMU 模型精度提高了0.7%,表明关键字有助于基本循环网络模型更好地理解文本。En-Senti-PMU的精度较于Senti-PMU 提高0.9%,这表明衰减型匹配函数在精度对网络的优化效果更好。
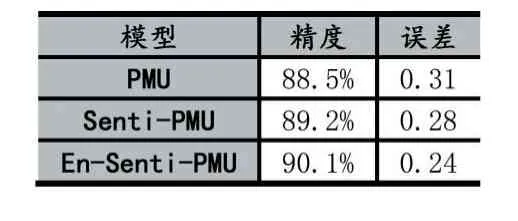
表1 精度误差表
结果表明,Senti-PMU 有效并且强大,特别是在处理文本上。因此综合水平上,Senti-PMU 在性能上较PMU 神经网络而言更优秀。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小天使·一年级语数英综合(2020年4期)2020-12-16
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
传奇故事(破茧成蝶)(2015年7期)2015-02-28
