
基于特征重建的知识蒸馏方法
2020-11-20 06:07郭俊伦彭书华李俊杰
现代计算机 2020年29期
郭俊伦,彭书华,李俊杰
(北京信息科技大学自动化学院,北京 100192)
0 引言
随着深度神经网络技术的不断发展,深度神经网络的表现越来越优异并且优异性是传统算法远远所不能及的。这些都是因为神经网络的深度不断增加,从而使得结构越来越复杂,对更高层更抽象的特征提取能力也变的越来越强。例如:宽度相同的8 层和16 层的神经网络模型用于同样的图片识别任务中,16 层神经网络的性能要远高于8 层神经网络。但是随着网络的加深,所需存储的网络节点以及所需要的浮点运算次数也会成倍的增加。而这些深度神经网络有这百万级别的网络节点以及需要上亿次的浮点运算,这样会消耗很大的储存空间并且需要强大的计算能力。但是,GPU 的出现使得模型训练周期大大的缩短,计算效率大大提升。
而在生活生产中往往使用的使基于CPU 的嵌入式设备,CPU 设备内存小,计算能力弱的特点,使得在嵌入式设备中应用神经网络技术成为一大难点,这严重限制了神经网络技术在资源有限的嵌入式设备中应用。现在已经有将深度神经网络压缩技术应用在嵌入式设备[1]中。并且在许多领域取得了一定的研究成果,例如无人驾驶技术[2]、医学图像处理[3]、人脸识别[4]等。
目前主流的网络压缩与加速方法[5]主要有以下五种:①轻量化模型的设计;②参数剪枝;③参数量化;④低秩分解;⑤知识蒸馏。
其中知识蒸馏这一方法相比于其他压缩方法有这优异的压缩效果,它可以在准确率损失较小的前提下将大模型压缩为原模型的一半以上。但是到底以何种方式“蒸馏”依然是个很大的问题。2014 年,Hinton 等人[6]第一次提出了知识蒸馏的概念,就是将复杂模型的知识迁移到另一个轻量级模型上,使轻量模型的结果近似逼近复杂模型。2015 年,Romero 等人[7]提出Fitnets 模型,选取学生网络和教师网络的中间层,利用教师网络中间层信息训练学生模型前半部分参数,再利用真实标签训练学生模型整体。2017 年,Zagoruyko 等人[8]将注意力机制[9]引入模型压缩中,通过选取教师网络与学生网络的中间卷积层生成的注意力图作为“知识”传递到学生网络的中,指导小模型进行训练。并且将注意力机制与传统知识蒸馏方法结合后学生网络的精度会有所提高。2018 年,Zhou 等人[10]提出了一种新的知识蒸馏方式,就是学生网络与教师网络共用基层,这种方法不仅学生网络精度有了提升,而且教师网络的精度也有了一定程度的提升,这种方法的缺点就是共用基层网络限制了小网络的灵活性。2019 年,Mirzadeh 等人[11]提出了教师助理传递模式,这种研究方法发现大模型与小模型进行传递时如果加一个规模适中的中间模型,小模型会取得更好的效果。而这个中间模型就被称为教师助理。
综上,传统的知识蒸馏忽略了教师模型的互相交互,而一些新模型Zhou[10]、Mirzadeh[11]等人提出的模型虽然有了交互过程,但是网络交互方式大大限制了学生网络的灵活性。由此本文结合图片风格迁移实验中的特征重建方法提出了一种新的知识蒸馏方法。
1 理论方法
1.1 残差网络
研究发现神经网络的层次越深,网络就会有越强的特征提取能力,从而就能有更好的使用效果。但是人们发现随着网络的不断加深会出现梯度弥散、梯度消失甚至神经网络退化等问题,这些问题使得深度神经网络的发展变得困难,在2015 年ImageNet 比赛中,He 等人[12]提出残差网络(Residual Network),网络的深度达到了152 层,为加深神经网络提供了新的思路。残差网络解决了层数加深后出现的一系列问题。残差网络的残差块结构如图1 所示。
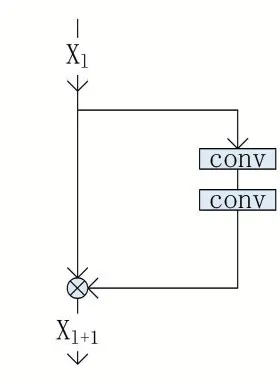
图1 残差网络的残差块结构
残差网络在普通卷积网络中引入了残差块,由公式(1)可见引入残差块后会对原先网络的训练结果进行微调,从而抑制原网络在训练中产生的错误,修正深度神经网络的训练结果。

其中,Xl、Xl+1为残差网络第l 层和第l+1 层的卷积层运算结果;W 为残差块结构的网络参数;F(·)为残差块中的卷积运算函数。
因为网络压缩实验中需要使用深度神经网络,并且为了方便与其他方法的实验结果进行对比,选用了宽度残差网络结构(Wide Residual Net,WRN)即以模型的宽度作为基准的残差网络,进行相关实验。
1.2 知识蒸馏
用于分类任务的深度神经网络往往使用Softmax层来计算出类概率。模型的训练往往采用的是人工标注的标签,又叫硬标签。知识蒸馏则是采用教师网络Softmax 层的输出作为小模型训练的标签,又叫软标签,并且在Softmax 中引入温度参数T,此时基于知识蒸馏的Softmax 公式变为:

zi为进入Softmax 输出层前的标签;qi为知识蒸馏后计算出的每一类的概率;T 为知识蒸馏温度参数,当T 为1 时,公式便是神经网络分类任务中最常用的Softmax 公式,由公式(2)可见温度T 越高神经网络计算出的软标签分布越均匀,这也是“蒸馏”名字的由来。典型的知识蒸馏架构如图2 所示。
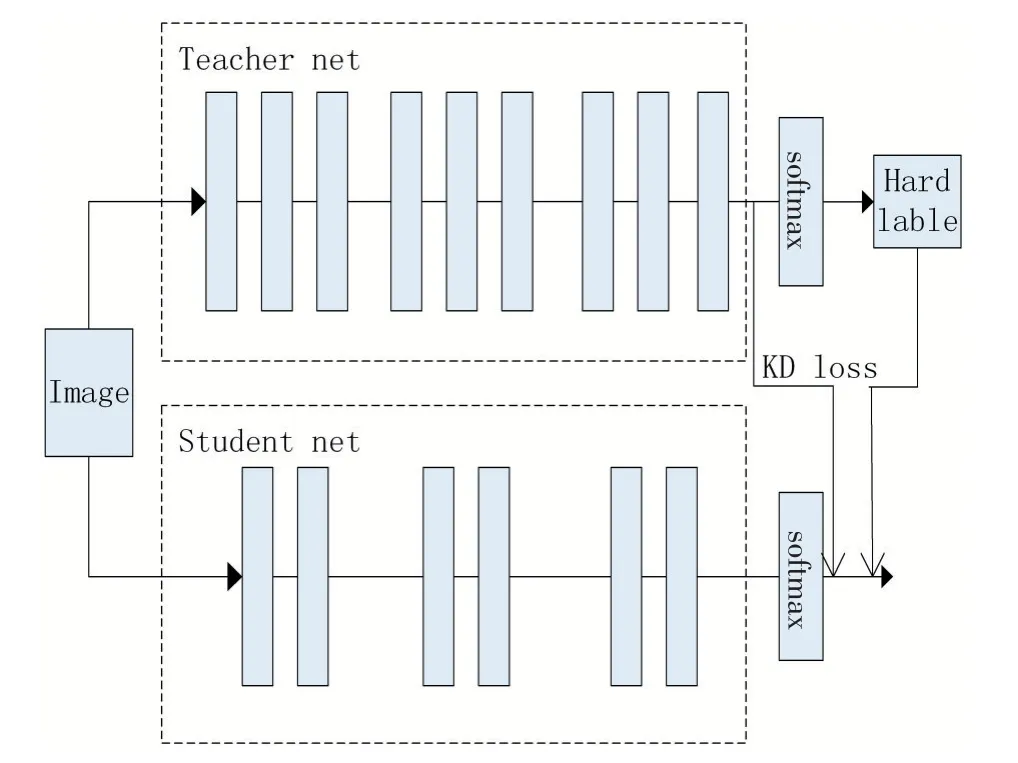
图2 知识蒸馏架构
由图2 可知,引入参数T 后的学生模型损失函数变为:
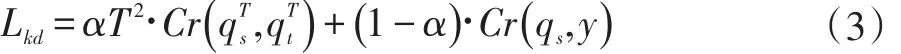
其中,α为软标签在学生模型训练中所占的比例;T为温度参数,与公式(2)中T 相同;、分别为学生网络和教师网络含参数T 的Softmax 公式;qs为学生网络中的 Softmax 公式;Cr(·)为交叉熵函数;y 为模型训练的真实标签。
1.3 特征重建算法
Johnson 等人[13]在图片风格迁移实验中发现,两张图片输入同一个网络时,图片的内容越相似则网络的深度特征越相似。于是在图片风格迁移实验中提出了特征重建损失函数。此损失函数是由已经训练好的VGGNet[14]计算得到的,将VGGNet 作为损失函数产生网络,用来训练图片风格迁移网络。风格迁移实验内容迁移(即特征重方法)的训练架构如图3 所示。
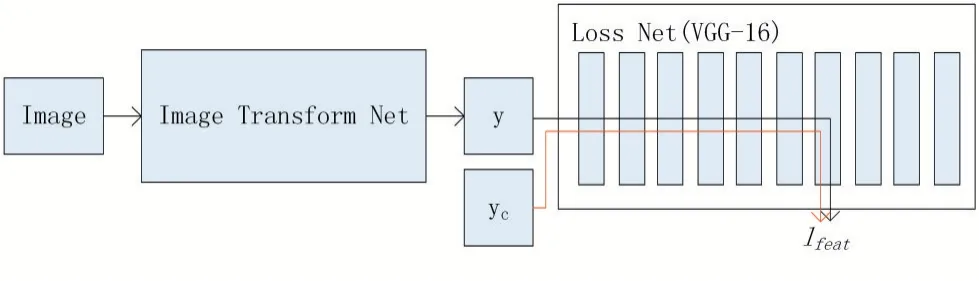
图3 图片风格迁移之内容迁移训练架构
其中y 为图片生成网络生成的新图片,yc为图片生成网络生成新图片的目标图片。实验中VGGNet 的深度特征欧氏距离越小,则图片生成网络生成的图片内容越接近目标图片。由此也可以得出特征重建损失函数。此损失函数如下:

Cj×Hj×Wj为学生网络第 j 层特征图的尺寸;、为图片y 和yc分别输入VGGNet 后第j 层的特征向量。
2 使用特征重建算法设计知识蒸馏新架构
传统知识蒸馏架构都是利用教师网络与学生网络中间层特征向量作为知识传递介质进行知识蒸馏。这种做法的缺点就是教师网络和学生网络相对独立,没有充分发掘出模型间的内在联系。目前,已经存在多种知识蒸馏框架,这些框架大都还是保持教师网络与学生网络相对独立的结构,只是寻求不同的知识传播形式。所以到底以何种架构的知识传播形式更加高效需要进行不断的实验。
在图片风格迁移实验中,是使用已经训练好的网络作为损失函数生成网络,去训练图片风格迁移网络。而在知识蒸馏中,也是已知一个训练好的教师网络,去训练一个规模更小的学生网络,由此,参照风格迁移实验,使用教师网络作为损失函数生成网络,并且使用风格迁移实验中的特征重建损失函数对学生网络进行训练。蒸馏框架总设计如图4 所示。
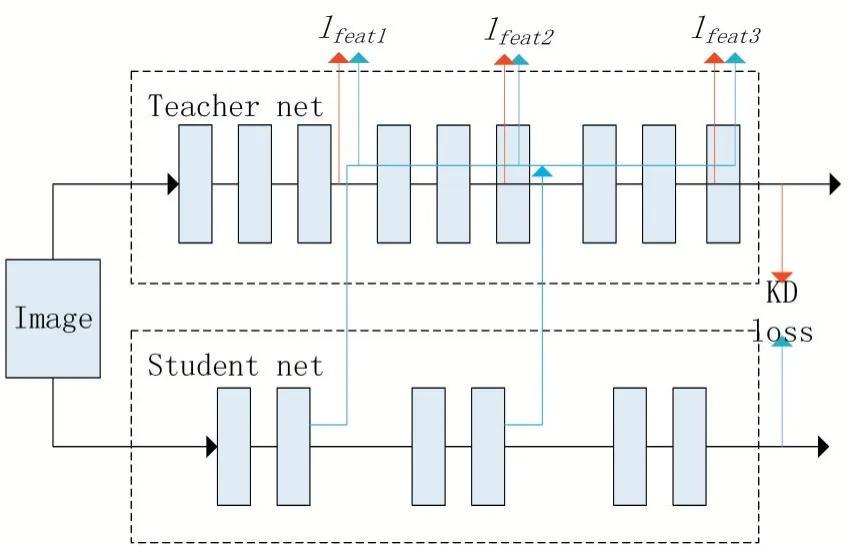
图4 基于学生网络特征重建的知识蒸馏架构设计
由图4 可见,该架构主要分成两部分,一部分为利用特征重建算法的损失函数生成网络;另一部分是传统的知识蒸馏算法。损失函数生成网络是将学生网络的中间层特征分组嵌入到教师网络中,使用教师网络的深度特征对学生网络插入教师网络之后生成的新特征进行特征重建。
那么其中的利用特征重建生成损失函数的网络框架的结构如图5 所示。
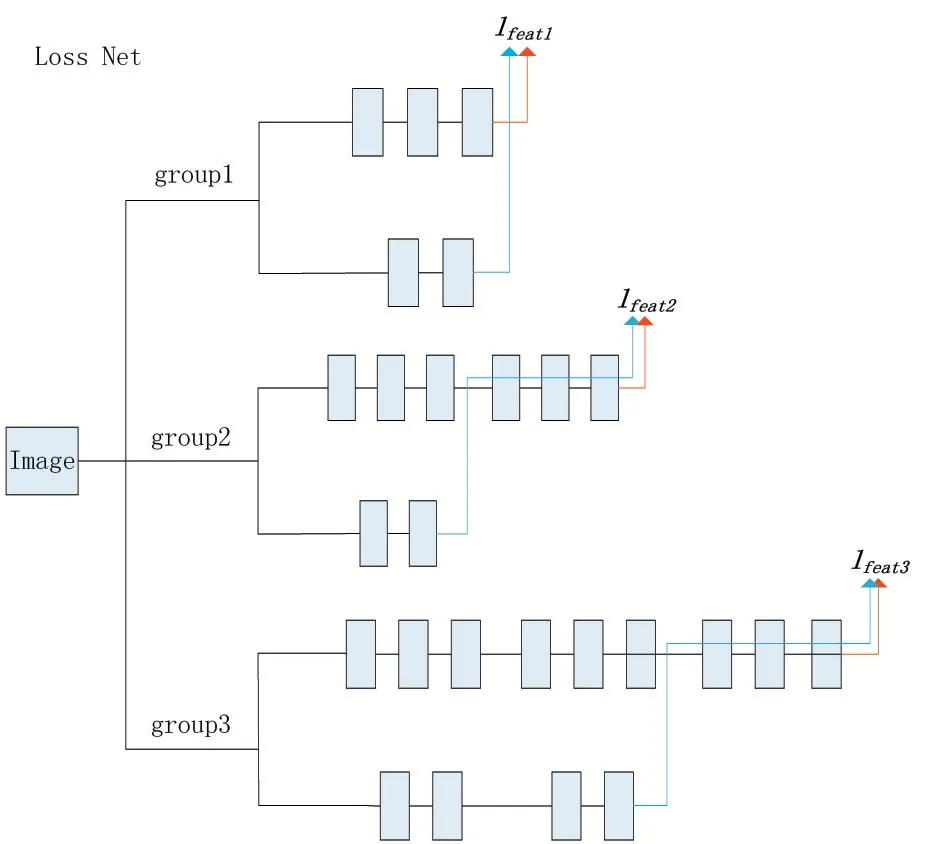
图5 利用特征重建生成损失函数的框架
使用此损失函数生成网络生成损失函数对学生网络进行训练。此时结合传统知识蒸馏训练学生网络的损失函数为:
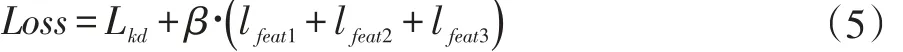
其中j 为重建特征层的分组数;β为特征重建损失函数组在训练中所占的比重;Lkd和lfeat分别为上文所提到的传统知识蒸馏损失函数以及特征重建损失函数。
3 实验结果及分析
3.1 在Cifar10上的实验结果及分析
(1)利用知识蒸馏新架构进行知识蒸馏的可行性分析
在使用数据集Cifar10 的实验中,分别选用学生网络为 16 层(WRN-16-1 和 WRN-16-2),教师网络为40 层(WRN-40-1 和 WRN-40-2)的宽度残差网络结构,其中1 和2 表示网络宽度为基准宽度的倍数。
第一组实验学生网络选用WRN-16-1,教师网络选用WRN-40-1,特征重建算法(Feature Reconstruction,FR)公式(5)中选用β为 0.01;若结合传统知识蒸馏(Knowledge Distillation,KD)算法(即 FR+KD 算法),则选用β为 0.1,公式(3)中选用参数α为 0.9,T 为 4。
第二组实验学生网络选用WRN-16-2,教师网络选用WRN-40-2,特征重建算法中选用β为0.01;结合传统知识蒸馏算法后选用β为0.2,其中公式(3)中仍然选用参数α为 0.9,T 为 4。
表1 为对比实验的实验结果。(其中base 和teacher 分别问为不使用任何蒸馏算法的浅层神经网络和深层神经网络的错误率)。
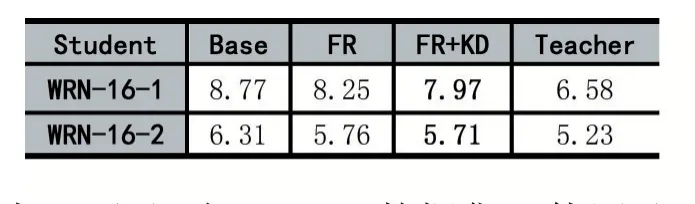
表1 知识蒸馏新架构的错误率(单位:%)
由表1 可见,在Cifar10 数据集上使用基于特征重建算法的新蒸馏框架将学生网络的准确率提升了将近0.5%,而结合传统知识蒸馏算法后,新架构的准确率更是提高到1%。
而其中WRN-16-1 的参数量为0.2M,WRN-40-1的参数量为 0.6M;WRN-16-2 的参数量为 0.7M,WRN-40-2 的参数量为2.2M。由此可见蒸馏后在保证准确率的前提下,学生网络的参数量降低到了教师网络参数量的1/3,甚至更低。并且网络的深度还降低到了原教师网络的一半多。
(2)不同知识蒸馏算法间的对比实验
为了验证上述知识蒸馏架构的有效性性,针对基于注意力转移机制[8](Attention Transfer,AT)的知识蒸馏方法以及传统知识蒸馏算法做对比实验。实验结果如表2 所示。在实验中使用了控制变量法,保证了不同算法间使用相同的神经网络以及相同的训练方法(随机梯度下降法),等等。
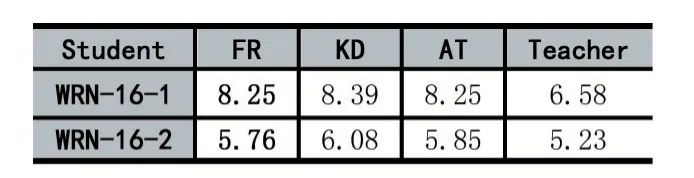
表2 各种知识蒸馏算法的错误率(单位:%)
3.2 在Cifar100上的实验结果及分析
Cifar100 相比于Cifar10 就是同样的数据集细分为了100 类,增加了分类任务的难度。由此,可以实验出在其它的复杂分类任务中此框架是否还可适用。在Cifar100 上同样选用学生网络为 16 层(WRN-16-1),教师网络为40 层(WRN-40-1)的宽度残差网络结构。这两个网络的深度以及参数量都是与上述在Cifar10 中使用的网络是相同的。
其中,特征重建算法中选用β为0.01;结合传统知识蒸馏算法后,则选用为0.1,公式(3)中选用参数α为0.9,T 为4。其中公式(3)中参数的选择仍参照经典知识蒸馏方法中的实验结果。表3 为各种算法的实验结果。

表3 在Cifar100 中各种算法的错误率(单位:%)
由表3 可得,在复杂分类任务中,此框架的表现效果优异,不仅将学生网络的准确率提高到了10%以上,而且基于此框架训练出的学生网络的准确率要高于目前较常用的传统知识蒸馏框架。相比与未压缩的原网络而言,模型大小仅为原模型的1/3,而准确率仅仅损失了3%。相比与未使用蒸馏模型训练出的小模型准确率有了极大的提升。
4 结语
本文所提出的新知识蒸馏框架更进一步发挥了教师网络强大的特征提取能力,对学生网络的特征进行重建,从而使学生网络的准确率方面超越了大部分传统知识蒸馏架构。该构架在学生网络的准确率方面,与原教师网络的准确率相比损失了1%-3%;在压缩效率方面,学生网络的参数量以及网络深度都降低为了原教师网络的一半以上。由此,新的蒸馏框架在准确率以及压缩效率上都有了一定的提高。
虽然新框架取得了一定的实验成果,但是由于学生网络的特征是通过人工分组嵌入教师网络中进行特征重建,这在一定程度上限制了学生网络的结构,学生网络只能采用与教师网络宽度相同的网络结构,这也是此架构存在的缺点。
尽管新架构存在一定的缺点,但是本实验为知识蒸馏的研究提供了一种新思路,并且往后将对此架构进行进一步的完善。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
成都信息工程大学学报(2022年2期)2022-06-14
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
煤气与热力(2022年2期)2022-03-09
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
