
混合云环境中调度执行多工作流费用优化算法
2020-11-20 06:07卢莉李亮亮黎红友
现代计算机 2020年29期
卢莉,李亮亮,黎红友
(1.四川大学计算机学院,成都610065;2.四川大学网络空间安全学院,成都610065)
0 引言
随着计算技术的发展与变革,不断有新的划时代意义的技术涌现出来,例如网格计算、并行计算、效用计算等,近年来兴起的云计算又是一次新的变革,但它也不完全是一种全新的技术,而是从之前的那些计算方式不断演化而来的。美国国家标准与技术研究院(NIST)[1]定义云计算是一种使用便捷,通过网络按需获取的可配置的资源共享池,用户根据使用量进行付费,并可以在上面快速部署应用。
工作流技术已经发展了数十年,关于它的定义也多种多样,工作流管理联盟认为工作流就是要实现科学工作任务的自动化执行,Buyya 等人则认为科学工作流就是根据各个任务之间的相互依赖关系或者它们之间的控制逻辑,自动化的完成科学任务[2],而Bertrem Ludasher 等人认为科学工作流是一个由任务和任务之间的数据依赖所构成的复杂的流程[3],综合上述可以看出工作流有两个要点,其一是任务和任务之间的依赖关系,其二是自动化执行。工作流一般分为传统的业务工作流和需要大量计算的科学工作流,它们都具有工作流的一些基本特征,但又各具特点。例如两种类型的工作流所面对的用户不相同,传统的业务工作流主要面向企业,他们会将自身的业务用业务工作流模型来构建,而科学工作流主要面向科研人员;另外两者所侧重的内容也不相同,传统的业务工作流更关注控制结构,即比较注重任务实际执行时的顺序,而科学工作流则偏重于数据的处理和传输。本文中的任务类型偏向科学工作流,包括需要大量计算的大数据和金融领域的工作流,下文简称为工作流或者任务。
由于执行工作流对计算资源和存储资源都有较大的需求,所以在传统的分布式计算环境中都是将工作流部署到集群或者网格中去执行[4],而云计算的出现给工作流的执行带来了新的机遇,对工作流在云环境下进行高效的资源配置和制定恰当的调度策略,不仅可以使工作流更加高效的执行,也能降低用户的成本,提高执行的可靠性和安全性,同时云服务商也能提高云基础设施的利用效率,减少能源浪费。
针对云环境中单个工作流的调度,Bittencourt 等人[5]使用混合云代价优化(Hybrid Cloud Optimized Cost,HCOC)算法,在满足工作流的期限和预算的前提下降低单个工作流的执行费用;文献[6]将混合云环境下单个工作流调度问题转换为整数线性规划问题,提高私有云的资源使用率并降低公有资源使用费用。
针对多工作流的调度,Kumar 等人[7]提出混合云时间费用优化(Time and Cost Optimization for Hybrid Clouds,TCHC)算法,它能降低多个异构工作流的执行花费。Sharif 等人[8]考虑工作流的截止时间和数据安全性,提出基于部分关键路径(Partial Critical Path,PCP)排序的混合云在线安全多端切割(Online Multi-terminal Cut for Privacy in Hybrid Clouds using PCP Ranking,OMPHC-PCPR)算法和基于任务排序的混合云数据安全在线调度(Online scheduling for Privacy in Hybrid Clouds using Task Ranking,OPHC-TR)算法来降低执行花费;Lin 等人[9]针对连续提交的多个同构大型工作流调度算法,提出分层迭代程序划分(Hierarchical Iterative Application Partition,HIAP)算法来切割工作流成多个子任务,考虑带宽限制、数据传输和计算代价,结合最小负载最长应用优先(Minimum Load Longest App First,MLF)队列排序算法和非直接至公有云(InDirectly to Public)策略,降低执行花费,由于该算法所针对的场景与本文类似,因此该算法将作为本文的对比算法之一。
本文研究的场景是在混合云环境中调度执行由不同的用户动态提交的多个工作流,这些工作流具有不同的QoS 需求,而本文主要关注工作流的截止时间和安全需求,因此如何在保证工作流上述QoS 需求的同时优化整个混合云系统的总费用支出是本文要解决的问题,本文针对该问题以及现有算法的不足,做了如下工作:
(1)对混合云中多工作流调度问题,提出了混合云环境中动态多工作流调度算法,优先将工作流任务调度到私有云中执行;采用多约束工作流分割机制,对无法在私有云中完成的任务进行分割形成子工作流。
(2)针对在私有云中调度执行的工作流,提出了一种基于表启发式算法改进而来的多工作流调度算法,提高私有云资源的利用率,减少公有云资源的使用量,从而优化混合云系统的费用支出。
1 混合云中多工作流调度模型
1.1 任务模型
本文中的任务类型是工作流(Job),它由一系列子任务(Task)和任务与任务间的数据依赖关系构成,由于子任务之间有数据依赖关系,所以它们的执行具有先后顺序,一个子任务执行完成之后,依赖它的输出数据的下一个子任务才有可能开始执行,因为一个子任务可能同时依赖其他多个子任务的数据,因此需要具备所有数据才能开始执行。使用有向无环图(Directed Acyclic Graph,DAG)来描述工作流,图中的结点(vertice)代表工作流的子任务,边(edge)代表子任务之间的数据依赖关系。图1 使用DAG 表示的一个简单工作流示例。工作流中的每个子任务是一个独立的执行单元,即不能再被分割成更小的执行单元,具有原子性,且本文规定一个子任务在执行的过程中不能被剥夺资源打断执行。
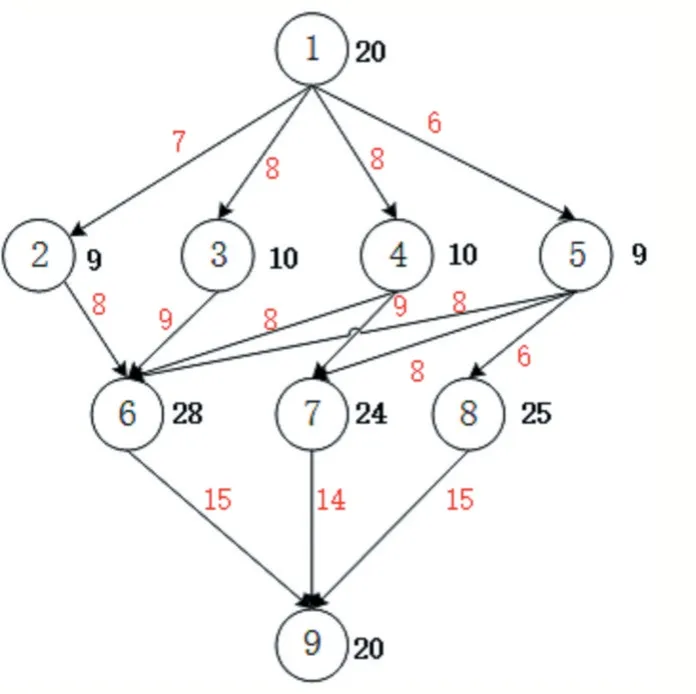
图1 工作流实例
在本文的场景中,用户会持续不断的向系统提交工作流执行请求,这些工作流使用集合Job={job1,job2,…,jobi,…,jobI}表示,对每个工作流使用一个五维结构来描述WF(T,D,WST,WDT,SN) ,其中T={t1,t2,…,ti,…,tN}表示该工作流的子任务集合,ti表示一个子任务,D={dti,tj|ti,tj∈T,i≠j}表示任务之间的数据依赖关系,WST(Workflow Submission Time)表示该工作流的提交时间,WDT(Workflow Deadline Time)表示工作流的截止完成时间约束,SN(Security Needs)表示工作流的安全需求。
1.2 资源模型
本文的混合云环境由私有云和M个公有云服务商(cloud provider)提供的公有云共同组成,用Cp表示所有公有云服务商,每个Cp对外提供Sm种处理能力不同的虚拟机实例,使用者根据自己的需求租用相应的虚拟机实例即可。为了保证服务更多用户,公有云服务商规定企业可以租用的虚拟机实例数量是有限的,用ToNumm表示每个云服务商可提供的虚拟机总数,Nvmn表示每类虚拟机的数量,每一种虚拟机实例Vmn能提供的处理能力也各不相同,因为不同的虚拟机具有不同的处理器核心数Nvcpun,每种vcpu的处理能力也不尽相同,使用SPvcpun表示。
企业中的私有云使用CR表示,建立该私有云以及后期的运转维护会产生一定的费用,但是本文不考虑这些成本开销。私有云提供的虚拟机使用Vmq表示。
与私有云中的资源免费使用不同,公有云服务一般是按照一定的周期Tc计费的,本文中将采用不同服务商自定的计费周期时长Tc=h计算相应虚拟机的租赁费用,所以为了降低系统费用支出,需要充分利用好已租用的资源。
除了租用虚拟机带来的费用开销,私有云和公有云之间的数据传输开销是系统费用支出中的另一大组成部分。本文根据现在一般商用公有云的实际情况,假设在各个云内部传输数据是免费的,只有在云之间传输数据才会收取费用,并且该费用Cdata是按照传输的数据量大小进行计算的。
1.3 问题描述
本文中的工作流任务是由用户随机向系统提交的,因此工作流的到来具有不确定性,在工作流执行的过程中随时可能有其他新的工作流请求到达系统,那么调度器需要根据当前实际的资源使用状况为新到来的任务分配资源,同时还需要考虑对已经在资源上执行的工作流的影响,避免新的资源分配方式导致已经在执行的任务不能按时完成。
本文使用DAG 表示工作流,假设工作流的任意一

假设私有云中各虚拟机之间的带宽都是已知且固定的,引入一个Q 维的矩阵BW,其中的元素BWi,j表示私有云中的虚拟机Vmi和Vmj之间的通信带宽,BWi,j=0 表示在虚拟机内部传输数据不产生通信消耗,两个有数据依赖关系的子任务ti和tj被分配到虚拟机Vmm和Vmn上执行,则在这两个结点之间所产生的数据传输时间开销为:

其中Lm表示虚拟机在处理数据传输之前的准备开销,dtitj/BWm,n表示传输数据的真正耗时。如果上述两个任务被分配到同一个虚拟机上执行,则本文忽略该时间开销,因此两个有数据依赖的子任务之间的平均数据通信开销为:

Lˉm表示所有虚拟机在数据传输之前的准备耗时的均值,表示私有云内部平均传输带宽,即:个子任务ti在任何一个虚拟机中的运行时间都是可以估计得到的,使用wi,q表示每一个子任务ti在私有云中的虚拟机Vmq上的执行时间,则子任务ti在私有云中执行的平均时间表示为:
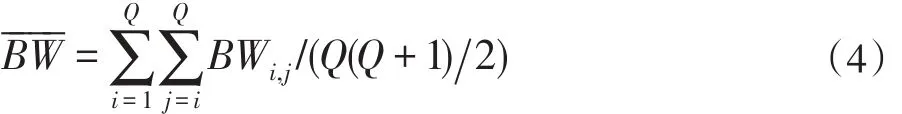
当把工作流调度到公有云中执行时,由于工作流具有一定的安全等级需求,因此需要使用到公有云中的相应安全服务,本文使用文献[10]中的安全模型,产生的额外时间开销如下所示:
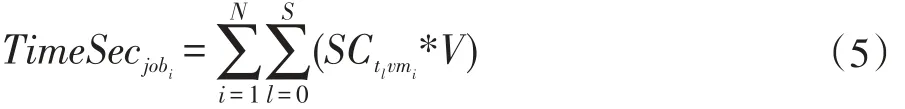
其中SCtlvmi表示子任务tl在虚拟机vmi上执行时产生的安全服务时间开销,当子任务tl在虚拟机vmi上执行时,V为1,否则为0。
系统产生的总费用开销包括虚拟机租赁费用和通信费用。引入向量KVmn表示某个服务商的虚拟机Vmn是否处于使用状态,如果被租赁使用则其值为1,否则为0。从时刻timemin到timemax,使用公有云产生的租赁费用为:
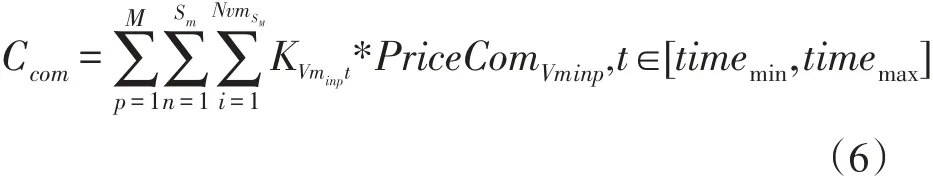
数据通信产生的费用为:
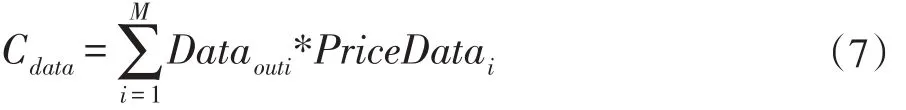
其中Dataouti表示这段时间内公有云Cpi传输到私有云中的数据量,PriceDatai表示数据通信单价。
因此这段时间内总的费用开销可表示为:

综上,在混合云环境下调度执行动态多工作流可用如下目标函数和限制条件表示:
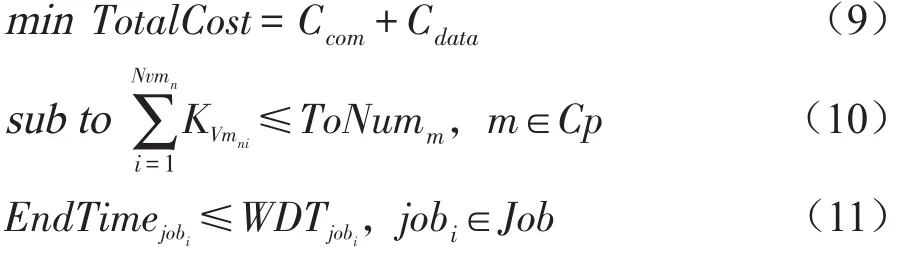
2 混合云下多工作流调度策略
为了优化整个系统的费用支出,优先调度工作流到私有云中执行,因此本节将首先提出一个私有云中的调度算法用于工作流在私有云中的调度执行,提高私有云资源利用效率。
2.1 改进的表启发式多工作流调度算法
由于系统中工作流请求和执行都是动态进行着,所以调度系统具有一定的实时性需求,本文根据异构最早完成时间(Heterogeneous Earliest Finish Time,HEFT)算法[11]提出一种适合本文场景的启发式调度算法。
本文使用经典的时间估算模型来计算一个工作流中各子任务的开始时间和完成时间。假设子任务ti在私有云虚拟机Vmq上执行的最早开始时间(Earliest Start Time)表示为EST( )ti,Vmq,最早结束时间(Earliest Finish Time)为EFT( )ti,Vmq,实际结束时间(Actual Finish Time)为AFT( )ti,Vmq,则子任务ti的EST计算方式如下:
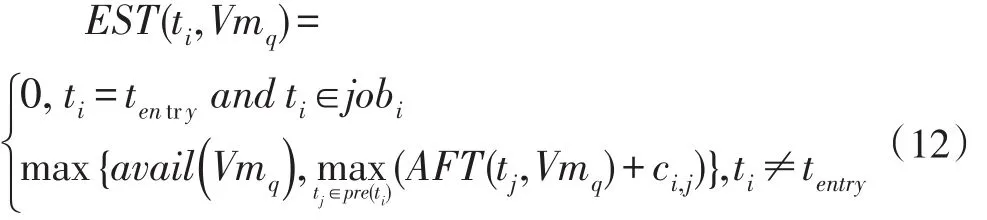
其中pre(ti)表示子任务ti的直接前驱任务集合,avail(Vmq)表示虚拟机Vmq完成上一个任务后可以开始执行任务ti的时间,内层max 表示任务ti所有的前驱任务全部运行完后依赖数据送达Vmq的时刻。任务ti的EST 通过递归定义,因此任务ti的最早开始执行时间是其所有前驱节点已经把依赖数据送达虚拟机Vmq的时刻和该虚拟机资源可用时刻中的较大者,即外层max 的含义。EST(tentry,Vmq)=0,则Makespan(job1)为job1中所有的出口子任务中AFT(texit)的最大者。对其他时刻提交的任务请求,Makespan(jobi)则是出口子任务中AFT(texit)最大者与任务最早开始调度执行的时间之差。
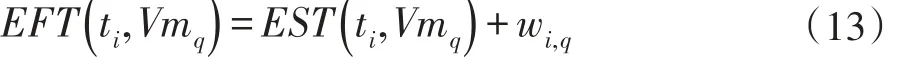
由于工作流中的子任务执行具有先后顺序,因此需要为它们制定合理的调度顺序。首先对一个工作流中的子任务进行排序,优先级高的任务先分配资源调度执行。算法HEFT 中给出了任务优先级的计算方式,该优先级顺序是从出口子任务texit递归向上定义,直到该工作流的入口子任务tentry为止,计算方式如(14)所示:
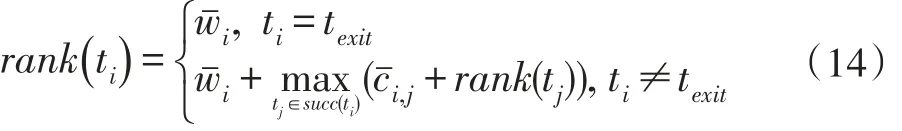
子任务ti在虚拟机Vmq上的最早结束时间则是最早开始时间与该任务在虚拟机上的实际执行时间之和,如(13)所示。
如果一个工作流中有多个入口任务或者多个出口任务,则为其添加一个虚拟的入口任务或者一个虚拟的出口任务,它们的计算量和数据传输量全为0。对于一个工作流,从该工作流的第一个子任务被调度执行到最后一个子任务执行完毕,中间的历时长度称为一个工作流的调度长度,用Makespan 表示。假设提交到系统中的第一个工作流job1的入口任务tentry的tj∈succ(ti)表示tj是ti的直接后继任务之一,对于texit,其rank(texit)定义为它的平均执行时间wexit,而其他子任务的rank(ti)为ti的平均执行时间加上它的直接后继任务中rank 值与平均数据传输时延之和最大者,通过这种递归向上的方式计算出一个工作流中每个子任务的rank 值,然后进行内部的优先级排序,所以这种方式称为向上排序方式(upward rank)。
从上述优先级计算方式可知,子任务的rank 值表明该任务在整个工作流中的优先级,值越大则优先级越高,说明该任务在整个工作流中的位置越靠前,应该被尽早调度执行。
但是,HEFT 中的rank(ti) 计算方式比较简单,对于复杂的工作流,不能完全反映出各子任务在整个工作流中的重要程度。如图1 中的工作流实例,该工作流由9 个子任务构成,圆圈旁边的粗字体数字代表任务的平均执行时长,箭头旁的数字表示子任务之间数据传输耗时。
假设使用rank(ti) 方法计算得到各子任务的排序值,结果如表1 所示。

表1 rank 排序结果
根据HEFT 调度算法,图1 中的工作流子任务调度 顺 序为t1→t3→t4→t2→t5→t6→t8→t7→t9。 从DAG 图中可以看出,t5的直接后继任务有3 个(t6,t7,t8),且t8只和t5有数据依赖,所以为了使t8更早被调度执行,t5应该比同一层次中的其他任务(t2,t3,t4)更早的被调度,但是根据rank(ti)方法所得的优先级顺序,t5需要在t2,t3,t4调度之后才可能被分配资源执行,所以这种优先级计算方式需要加以改进更好的提高工作流执行,从而更好的刻画出工作流内部的结构特性,尤其对于子任务众多、结构复杂的工作流,合理的安排子任务的调度顺序可以的并行度,降低工作流的Makespan。因此本文将对原来的rank(ti) 计算方式做出改进,以更好的反映出一个工作流内部子任务之间的优先顺序。
从图1 可以看出,子任务t5较同一层次中的其他子任务更加重要,因为它的直接后继子任务(t6,t7,t8)都与它有数据依赖关系,而t2,t3,t4都只有一个或者两个直接后继子任务,因此如果t5没有执行完毕,即使t2,t3,t4已经执行完毕,后继子任务也无法开始执行,这将很大程度降低整个工作流的并行执行效率,延长Makespan,所以t5相对于其他几个同层的子任务应该需要更高的优先级以尽早被调度执行。
从上述分析可知,t5的重要性表现在它有更多的直接后继子任务,DAG 图中则表示节点t5的出度相较于同层中其他节点更多,所以在调度前期计算各子任务的rank(ti)时我们将其直接后继子任务的数量纳入考虑,得到如下新的衡量子任务调度顺序的指标Nrank(ti),其计算方式如下:
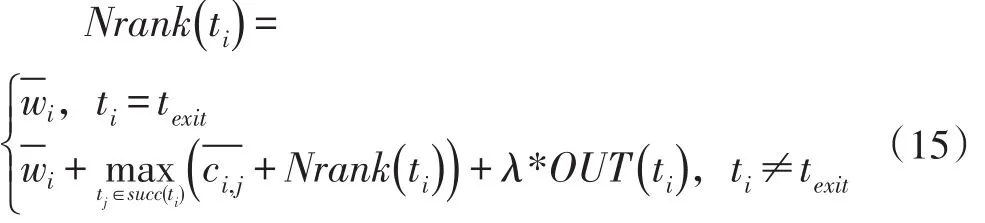
OUT(ti)表示ti的直接后继子任务的个数,λ是一个参数因子,它与具体的应用类型有关系,后文将对其进行实验讨论。
由于工作流执行请求是由不同用户动态随机提交至系统的,因此任务调度器会周期性的对系统中还未调度的任务进行资源分配并调度执行,所以在一个调度周期Cycle内,可能有很多新的工作流请求进入系统,当系统中资源不充足时,如何决定在该时间段内到达的所有工作流的调度顺序就显得很重要。一些算法按照工作流的截止时间(WDT)安排调度顺序,选择截止时间靠前的工作流优先分配资源,该方式称为EDF(Earliest Deadline First),这种简单的方式很容易导致一些工作流不能在其WDT之前执行完成。于是其他人又提出了一种衡量任务紧急程度的指标,叫任务宽松度,该指标定义为某时刻一个工作流执行结束到它的WDT之间的时间区间,Ljobi=Djobi-Ejobi,其中Djobi表示工作流的截止时间,Ejobi表示工作流执行结束时间,Ljobi越小表示工作流jobi越急迫,越应该尽早调度,当工作流类型差异很大时,这种度量方式就不能很好的工作,可能存在某个工作流的执行时长为lenjoba,它远大于另一个的执行时长lenjobb,但是它们距离各自的截止时间Ljoba>Ljobb,如果按照上述方式则认为jobb更加紧急,从而在资源不充足时优先调度了jobb,这很可能导致joba不能在它的截止时间之前完成,因为它的执行时间较长导致不确定性更多。因此本文提出一种相对紧急程度来度量各工作流之间的调度顺序,
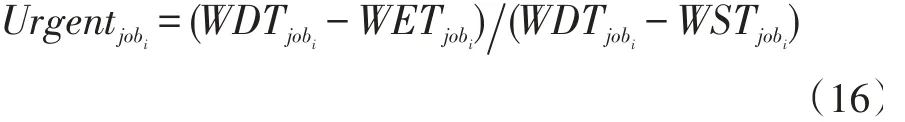
其中WETjobi是根据当前时刻的实际资源状态估计得到的,Urgentjobi是(0,1) 之间的一个小数,它通过工作流最早结束时间到指定截止时间的这段空余时间段,除以工作流提交的时间到截止时间的这段时间长度(即工作流的最长容忍时间)所得的,数值越小表示距离工作流的截止时间越近,说明该任务越急迫。
本文借鉴HEFT 算法中的核心思想提出了调度动态多工作流的MIHEFT(Move and Insert based Heterogeneous Earliest Finish Time)算法,对不同时刻动态到达的任务请求,根据它们的相对紧急程度Urgentjobi制定工作流之间的调度顺序,对工作流内部的子任务,则采用改进的Nrank(ti)计算他们的优先级,然后制定相应调度策略。
MIHEFT 算法的伪代码如下:

Algorithm 1 分别计算出每个工作流子任务的EST和EFT,然后再估计出整个工作流的WET,接着计算出待调度工作流的Urgent。然后对各工作流分别进行资源预分配和调度执行,如伪代码11~20 所示。该过程需要先对工作流中的所有子任务计算Nrank 值,然后在内部做出优先级排序。然后将排序后的子任务预分配到合适的计算资源上,当资源可用时任务将获得资源执行,通过调用Algorithm 2 为每个子任务寻找合适的资源。

对每个需要分配资源的子任务,首先需要计算该任务在每类虚拟机上的计算时间,然后从最快的虚拟机开始检查。对于空闲出来的虚拟机,首先检查该空闲时间槽的长度(Free Time Slot length),如果该空闲时间槽长度大于等于该任务在此虚拟机上的执行时长leni,则可以直接将该任务“插入”到此虚拟机任务队列相应的位置上,如果当前的空闲时间槽长度有限,不足以执行完此任务,则需要检查是否能够“移动”后续的子任务加长时间槽。如12~18 行所示,首先对虚拟机任务队列中该空闲时间槽后面的任务所属的工作流进行检查,因为在工作流中,一个子任务延迟length 时长执行,也会影响到该子任务的所有后续子任务,使它们也延后length 执行,进而可能使整个工作流的执行时长延后length,所以需要检查延后length 时长后是否会影响到其他工作流在deadline 之前完成,如果对后续所有子任务所属的工作流都没有影响,则可将该任务插入任务队列的相应位置上,如果检查后发现“移动”后续的子任务会使其他工作流超出截止时间,则该虚拟机空闲时间槽不能满足此任务的执行,继续换其他虚拟机执行上述相同的操作,直到为此子任务寻找到合适的资源,或者是搜索了整个系统资源后没有找到合适的资源能够使该工作流在截止时间内完成。
2.2 混合云下多工作流调度
为了减小系统费用支出,任务调度器优先为工作流在私有云中寻找空闲资源,私有云中使用2.1 小节中的MIHEFT 算法为工作流分配虚拟机资源。MIHEFT算法首先需要使用Nrank 计算一个工作流中各子任务的优先级,计算该优先级时需要为子任务在虚拟机上的执行时间进行估计。
假设ti在虚拟机Vmn上执行,则执行时间可以使用式(17)计算:
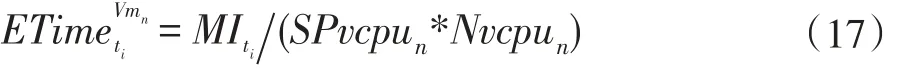
MIti表示ti的计算量,一般为指令数,SPvcpun和Nvcpun分别代表所在虚拟机Vmn的虚拟CPU 的计算能力和核心数。工作流之间如果存在数据依赖,即如果tj的执行依赖ti给它传递数据,用dtitj表示两个任务之间需要传递的数据量,则数据传输耗时可以通过(18)计算得到:
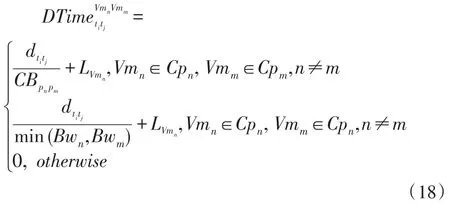
ti和tj两个任务分别在虚拟机Vmn和Vmm上执行,虚拟机Vmn和Vmm分别属于云系统Cpn和Cpm。可以看出两个子任务之间的数据传输时间分为3 种情况:当两个虚拟机分别属于不同的云环境中时,数据传输需要跨越不同的云,因为本文假设云数据中心之间的链路带宽相比云内部的带宽要小,所以在云之间传输数据时瓶颈在云之间的链路带宽,因此大概传输时间由需要传输的数据量大小与云间可用链路带宽以及虚拟机Vmn在处理数据传输之前的准备时间开销LVmn确定;当Vmn和Vmm属于同一个云环境下时,此时数据链路带宽由虚拟机本身的带宽所决定,因此数据传输时间由数据量大小和两个虚拟机带宽中的较小者决定;当两个虚拟机处于同一个物理机中时,数据可直接在物理机内共享,此情况下本文忽略数据传输时延。
混合云中动态多工作流调度算法HCDMW(Hybrid Cloud Dynamic Multiple Workflows Scheduling)伪代码如下:

调度器使用Algorithm 3 不断检查系统中的任务池,如果任务池中还有工作流未得到调度,则将未调度的工作流取出进行调度,使用Algorithm 1 为这些任务在私有云中预分配资源,如果成功为任务找到合适的资源,则继续等待新任务的到来,如果工作流在私有云中不能在截至时间内完成,则把该工作流分割为多个子工作流,然后调度部分子工作流到公有云中执行。
一个子任务如果它的直接前驱任务和直接后继任务都少于一个,定义这种子任务为简单子任务(simple task),非简单子任务则定义为复杂子任务(complex task)。在对工作流分割的时候,从入口子任务开始,采用一种类似深度优先搜索的方式,将更多简单子任务分割开,并调度至公有云中并行执行。
2.3 公有云中调度
分割后的部分子工作流需要调度到公有云中执行,本文的优化目标是费用开销,任务在公有云中执行的费用开销主要包括计算资源的成本和数据传输产生的费用,总费用表示如下:

其中,Tc表示该虚拟机计费周期时长,priceVmn表示周期单价,k 表示该虚拟机在之前所产生的计费周期数量,如果该任务能在已租用过的计费周期内完成,则不会产生新的费用,否则需要计算新产生的费用。
在公有云中为子任务分配资源时,为了提高公有云资源利用率,首先在已经租用了的虚拟机集合中为任务寻找合适的资源,因为本文公有云计费方式都是按照时间段计费,所以可能存在很多租用了的虚拟机处于空闲状态而浪费掉,因此当任务调度至公有云中时,先在已租用的虚拟机集合中寻找能使子任务在截止时间内完成的资源,当无法找到时再租用使该任务能够按时完成且费用最小的新虚拟机,这样能减少虚拟机的租用数量并提高已租用资源的利用率,降低整体成本开销。
3 实验与分析
为了验证HCDMW 算法在混合云环境下对动态提交的多工作流调度执行的有效性以及对系统整体费用开销优化的效率,使用WorkflowSim 模拟器[12],它是基于CloudSim[13]开发而来的云工作流模拟器,它弥补了CloudSim 不支持工作流调度的特点,并提供容错调度的特性,提供工作流级别的任务聚簇、资源配置和任务调度等功能。将该算法与Greedy、MLF_ID[9]和HCOC[5]三个算法进行对比。
本实验将构建一个混合云环境,它由一个小型的私有云和3 个公有云服务构成,私有云提供的虚拟机配置如表2 所示,包括三种类型,每一种虚拟机实例提供10 个,由于这些资源是私有的,所以安全级别最高并且可免费使用。
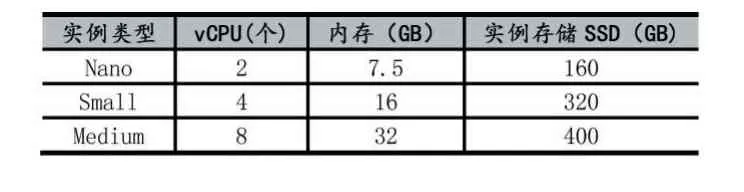
表2 私有云实例类型
3 个公有云中的虚拟机实例类型分别按照Amazon EC2- Asia Pacific(Tokyo)、Amazon EC2-Asia Pacific(Singapore)[14]和Microsoft Azure[15]中的部分实例进行配置。Amazon EC2 在东京(Tokyo)和新加坡(Singapore)区域以及Microsoft Azure 在上海的实例配置和价格如表3 所示。由于公有云服务商对每个用户所能使用的虚拟机实例数量有限制,因此本节实验假设两个使用Amazon EC2 配置的公有云能够提供的虚拟机实例数量均为20 个,使用Microsoft Azure 配置的能提供30 个实例。
如表3,Amazon EC2 中的实例,本实验只选取了计算优化型(C3.)实例和存储优化型(i2.)实例,Microsoft Azure 中的实例只选择了优化计算实例类型。按照Amazon EC2 中实例类型配置的虚拟机设置为按小时收费,不足一小时的部分也按一小时计费,Microsoft Azure 实例类型的计费方式则精确到分钟数[16],不足一小时的部分四舍五入到最接近的分钟数,实验环境中的几个公有云计费方式本文都按照这些真实的情况设置。
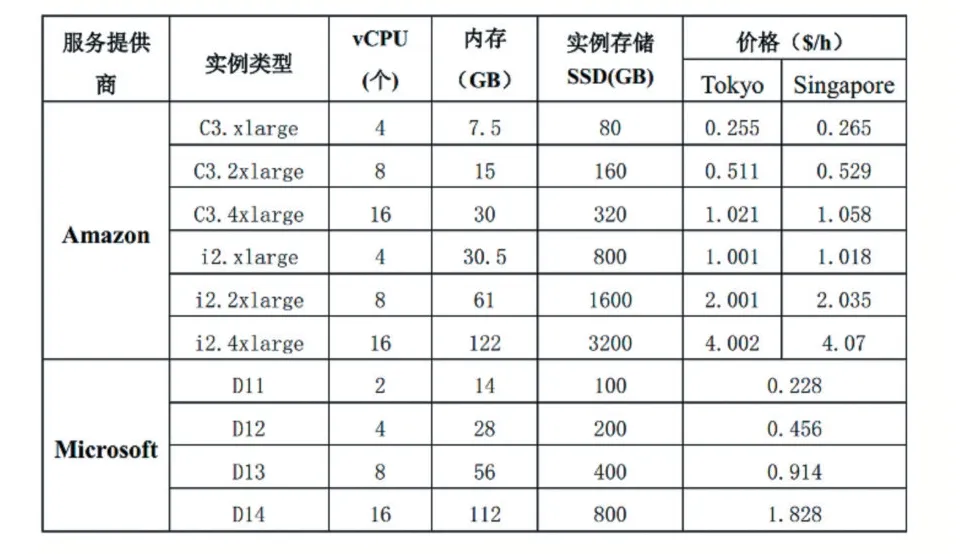
表3 公有云实例类型
假设各公有云和私有云内部的实例之间的网络拓扑结构均是全连接的,即同一个云内部的任意两个虚拟机实例之间都可以直接连通而不用经过外部网络。为了实验环境的网络设置与真实情况相近,现假设将私有云部署在四川大学校园内,使用网络测速工具SpeedTest 测量校内与上述各公有云服务商之间的网络带宽,为了获得稳定可靠的数据,本测量实验在校内多个地点进行且分不同时间段,测量多天后取平均值,测量结果如表4 所示。然后使用这些真实数据设置实验平台中私有云和3 个公有云之间的链路带宽。
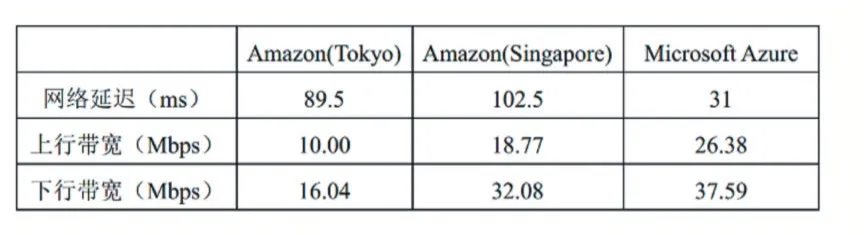
表4 私有云和公有云之间的链路带宽
除了租用虚拟机实例需要收费,使用公有云另一项大的费用支出是数据传输产生的开销。Amazon EC2规定数据传入和在同一个数据中心内部的数据传输是免费的,但是数据传出至互联网以及在不同区域(region)之间的数据传输是需要付费的,其付费方式如表5 所示。
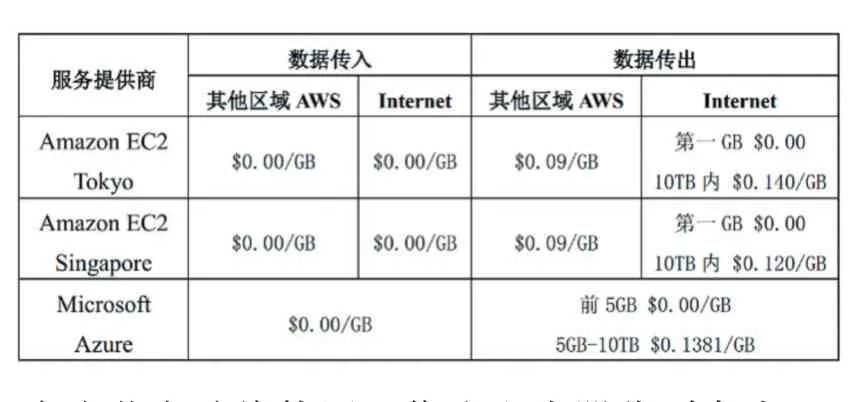
表5 数据传输费用
本小节实验将使用工作流生成器分别合成100 和200 个工作流,估计各工作流在上述各种虚拟机实例下的执行时长,然后取平均值作为对应工作流的标准执行时长。设置每个工作流的截止时间时,取其标准执行时长与截止时间因子θ的乘积,其中θ服从一个方差为0.2 的高斯分布,该分布的均值μ将作为实验的变量参数。对每一个生成的工作流,根据文献[10]为其所有子任务分别设置安全需求等级,该安全等级是满足条件的随机值,同时也需要为实验模拟器中的所有虚拟机实例赋予安全级别。最后将生成的工作流动态提交到实验模拟器中,这些工作流的提交过程也符合泊松分布。
实验分别对比4 个算法执行所有工作流需要的总时长,执行完毕后系统总费用开销以及私有云资源的利用效率。
3.1 执行时间
图2 和3 分别描述了提交100 和200 个工作流后,使用4 种不同的调度算法最终的执行总时长。从两图中可以看出,随着参数μ变大,使用不同调度算法的执行总时长均呈现变大的趋势,因为参数μ变大意味着工作流整体截止时间变长,因此有更多工作流能够在本地私有云中执行,但私有云中的资源相对有限且性能没有公有云实例强大,所以任务的总体执行时长会增加。使用Greedy 算法和HCOC 算法时,工作流执行时间比其他两者长,因为它们没有充分利用私有云中的资源,相比其他两种算法,它们将更多工作流调度到公有云中执行。
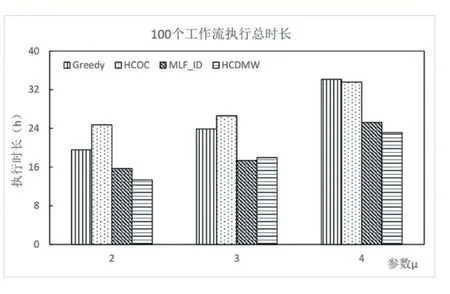
图2 100个工作流调度执行总时长
由于在公有云中执行前需要将大量基础数据传输到公有云,所以会使整体时长增加不少。
使用本文的HCDMW 算法执行时长较短,因为它能够充分利用私有云资源,减少了私有云中虚拟机等待的空闲时间槽,提高了资源利用效率。当有工作流在私有云中不能在截止时间内完成时,HCDMW 算法也并非将整个工作流完全调度到公有云中执行,而是采用工作流分割的方式,在满足工作流需求时将尽可能少的子工作流调度到公有云中并行执行,从而缩短了整体执行时间。
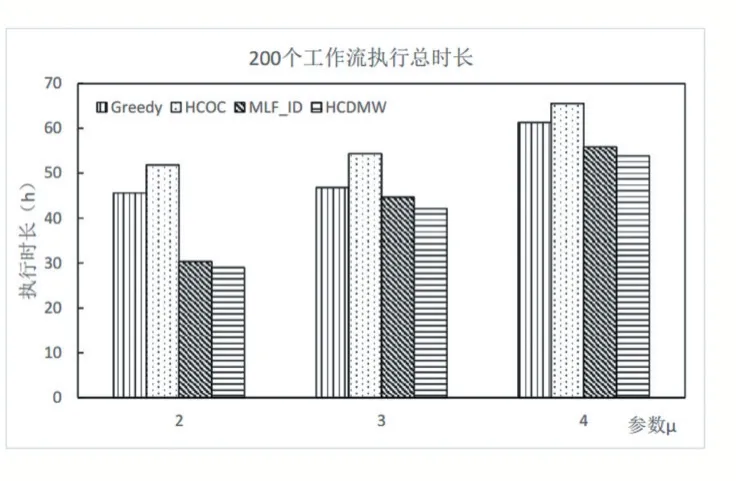
图3 200个工作流调度执行总时长
3.2 执行费用
图4 和图5 分别描述了使用4 种算法调度时,执行完100 个工作流和200 个工作流后系统产生的总费用开销。可以看到随着μ变大,系统总费用支出均在减小,因为随着μ变大工作流整体的可容忍时长(提交时间到截止时间)增加,更少的工作流被调度到公有云执行,因此系统费用都会变小。其中Greedy 算法始终高于其他算法,因为Greedy 算法优先为工作流选择性能最高的虚拟机实例,这些虚拟机的价格也相对较高,因而执行费用最高。本文的HCDMW 算法相比其他3 个算法要少很多,因为当工作流需要调度到公有云中执行时,HCDMW 算法会考虑多个成本因素,将工作流合理分割为多个子工作流,然后将部分子工作流调度到公有云中执行,且在公有云中执行时,也是优先使用已租赁过的虚拟机实例,其次选择满足要求且便宜的实例,这些措施都进一步提高了已租用公有云资源的利用效率,从而使系统总费用开销大大降低。
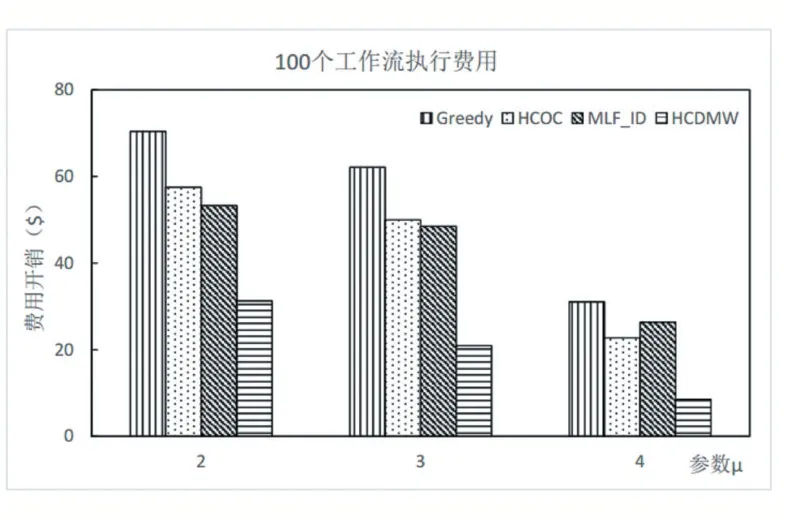
图4 100 个工作流调度执行费用开销
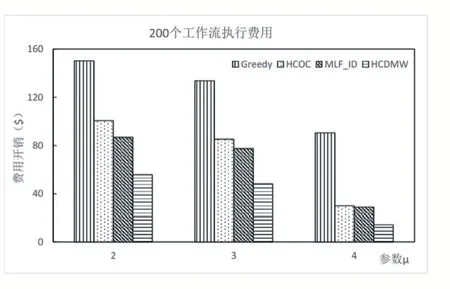
图5 200个工作流调度执行费用开销
3.3 资源利用率
图6 和图7 分别描述了使用4 种不同算法调度执行100 和200 个工作流时,混合云系统中私有云资源的利用率。当μ变大后,即工作流整体的截止时长变大,意味着工作流提交到系统后预留了更长的执行时间,容忍时长增加,更多的工作流可以在本地私有云中执行而无需调度到公有云中,所以从图中可以看出,随μ变大私有云资源利用率总体呈现变大趋势。
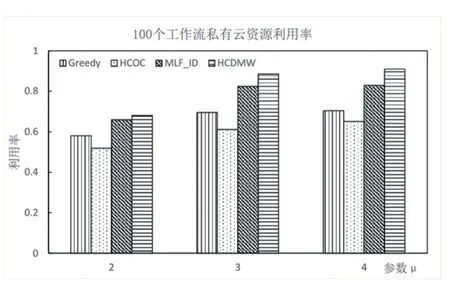
图6 100个工作流私有云资源利用率
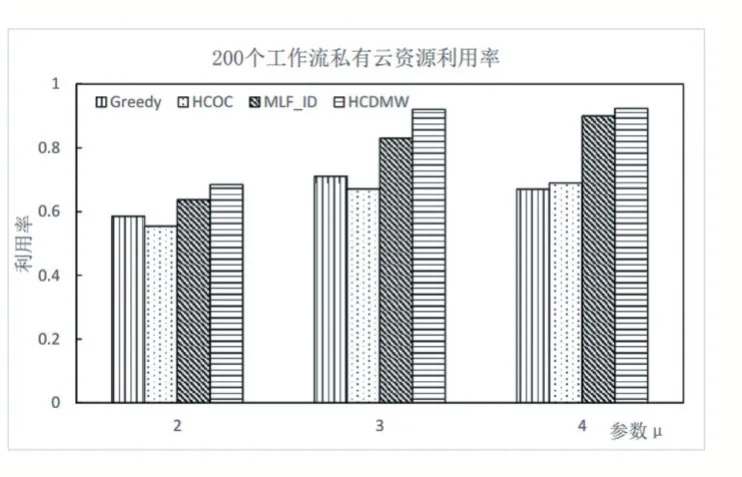
图7 200个工作流私有云资源利用率
从图6-图7 可以看出,当参数μ取2 时,使用4 种不同算法的私有云资源利用率都不高,因为任务的截止时间都比较紧迫,因此需要调度很多任务到公有云中执行,导致私有云资源利用率较低。使用HCOC 算法时,大部分时间的利用率都比其他算法低,因为该算法会将整个工作流调度到公有云中并且寻找最经济的资源,导致任务的执行时间变得很长,从而让私有云资源被浪费更多。本文的HCDMW 算法相比MLF_ID 算法在资源利用率上要好一些,因为HCDMW 算法将不能在截止时间内完成的工作流进行分割,然后只调度部分任务到公有云中,保证私有云不会因此而闲置等待,并且私有云中的MIHEFT 调度算法能够充分利用资源的空闲时间槽,进一步减少了私有云资源的浪费,提高了利用率。该实验结果也印证了执行费用的实验结果,因为HCDMW 算法能够充分利用免费的私有云资源,所以才使系统整体费用开销得到优化。
4 结语
本文以混合云环境下动态多工作流调度执行问题为研究背景,为了既减小系统整体费用支出,又能满足工作流的截止时间约束、安全隐私需求等,提出了针对混合云中动态多工作流调度执行的HCDMW 算法,有效减少了系统的费用开销。但本文算法还存在一些问题需要进行更深入的研究和改进,在后续工作中从以下几个方面进行:
(1)虑资源失效的可能性,当资源失效后能够调度任务到其他资源上执行避免整个工作流执行失败,增强调度系统的鲁棒性,使其能够更加贴近真实的云环境;
(2)公有云中还具有一类资源具有竞价模型,即价格是动态变化的,本文后续工作将考虑加入该类资源模型,以更有效地优化系统的费用。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
南方农业·下旬(2022年4期)2022-05-24
阿来研究(2021年2期)2022-01-18
北京航空航天大学学报(2021年6期)2021-07-20
北京航空航天大学学报(2019年9期)2019-10-26
当代陕西(2019年11期)2019-06-24
读友·少年文学(清雅版)(2018年8期)2018-12-06
恋恋中国风(2017年5期)2017-09-11
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
