
基于嵌入式平台的交通标识检测
2020-11-20 06:07俞辰卿粼波滕奇志胡亮
现代计算机 2020年29期
俞辰,卿粼波,滕奇志,胡亮
(四川大学电子信息学院,成都 610065)
0 引言
随着城市的现代化,交通环境越来越复杂,智能交通系统也成为了大众的研究热点。作为智能交通系统的一部分,交通标识检测是实现智能交通的必需条件。交通标识检测可以使驾驶员避免交通违章,对于驾驶人员和行人的出行都增加了安全性,很有研究意义,所以交通标识检测得到了学术界的广泛研究[1]。传统检测方式主要采用机器视觉算法来检测交通标识,例如基于形状和颜色来进行检测,等等[2],但是该方法一般通过人为的选取或设计特征,然后结合分类器提取检测目标,存在一定的主观性[3]。与上述方法相比,基于深度学习的交通标识检测算法在消除主观性的同时,其性能更具优越性。近些年来,基于深度学习的交通标识检测算法研究取得了一定的进展。其中,Muller J 等人使用 SSD(Single Shot MultiBox Detector)实现了交通标识的识别,达到了95%的召回率[4],Linxiu Wu等人基于Faster R-CNN(Faster Region-based Convolutional Neural Network)在不同天气情况下实现了对交通标识的检测,准确率约为90%[5]。Cen han 等人基于Faster R-CNN 实现了交通标识检测并对其进行了改进,提高了12.1%的准确率[6]。但是上述算法复杂度和空间复杂度都较大,因此不便于部署在低容量的嵌入式平台上实现实时的交通标识检测。
因为大部分嵌入式平台与通用计算平台相比,存储容量是极其有限的,所以要在嵌入式平台上实现,网络需要具有模型小,实时性较高的特性[7]。在所有检测算法中,Tiny-YOLO 系列网络由于实时性高、参数量较小的优点[8],所以本文采用Tiny-YOLOv3 作为交通标识的检测网络,而Tiny-YOLOv3 精度不是特别高[9],针对上述问题,本文在原有的Tiny-YOLOv3 网络基础上,提出了如下优化方法:
(1)对数据和网络候选框进行预处理,使网络更适用于交通标识的检测。
(2)对网络尺度和深度进行了增加,提高网络对交通标识的准确率。
(3)对网络的卷积层和目标检测层都进行了密集连接,减少网络的参数量。
1 Tiny-YOLOv3网络
1.1 网络结构介绍
Tiny-YOLOv3 模型是 YOLOv3 的轻量级网络[10],与 Faster R-CNN 算法相比,YOLO(You Only Look Once)系列算法是将检测问题转化为回归问题[11],这种检测方式提升了检测速度。并且Tiny-YOLOv3 保持了YOLOv3 的部分网络结构,融合了最新的特征金字塔网络和全卷积网络[12],并且使用多尺度预测最终目标,在检测小目标方面更有效。其网络结构如图1所示。
1.2 网络存在的不足
Tiny-YOLOv3 对输入图片进行了5 次池化操作,并使用最后2 次池化得到的降采样结果对目标进行预测。最后2 次降采样包含了19×19 与38×38 的目标检测特征图。Tiny-YOLOv3 网络只有上述两个目标检测层,这意味着当目标小于一定像素时,网络对目标的预测就会出现困难[13],检测小目标时会出现漏检,误检等问题。因为经过16 倍降采样的目标检测层对于目标位置信息的检测能力是有限的。YOLO 算法是通过划分的网格数来输出预测结果的,由于原Tiny-YOLOv3网络只有 19×19 和 38×38 的特征图层,如图 2 和 3 所示,只凭借这两个尺度上的预测难以精确检测所有的交通标识。
同时由图1 可见,Tiny-YOLOv3 网络有部分卷积层卷积核数较多,该网络卷积层的参数经计算有8668080 个,不满足一些较小存储容量的嵌入式平台的需求。

图2 19×19卷积尺度图

图3 38×38卷积尺度图
2 Tiny-YOLOv3的改进模型
2.1 数据及网络模型预处理
由于图像是从不同的设备上获取的,所以图像的大小并不统一,例如 1000×300、1024×768 和 1280×720。因为YOLO 算法所需输入图片的尺寸需要为固定大小,所以将不同大小的图像调整为608×608 的标准格式[14]。
YOLOv2 后的YOLO 网络都使用锚点框(anchor boxes)来检测目标[15],所以同样的 Tiny-YOLOv3 也需要设置anchor boxes 的值。anchor boxes 是一组初始候选框,可以自行设定它们的宽和高。对初始anchor boxes 不同的设定会影响到网络对交通标识的检测精度和速度。
本文主要研究的是交通标识检测问题,所以面对的检测对象是交通标识,原网络是为了检测VOC 和COCO 数据集设置的anchor boxes,对于本文的研究对象不太适用。因此,利用K 均值聚类算法(K-means Clustering Algorithm)对数据重新聚类分析,本文采用预测的box 与标注的box 的交并比(Intersect Over Union,IOU)作为目标聚类分析的量度,对数据集进行聚类分析。IOU 的计算公式如式1 所示:

在上述公式中,IOU 表示预测框和真实检测框的交并比。A 表示预测框,B 表示检测框。由于网络增加了目标检测层,anchor boxes 的数量由原来的6 个增添成了9 个,此时对应的anchor boxes 的宽和高分别为(15,15),(19,19),(24,24),(16,41.6),(32,31),(46,44),(28.5,74.1),(70,73),(126,144)。
2.2 网络尺度及深度增加
由于Tiny-YOLOv3 中网络对输入图像进行了多次池化操作,而池化是对图像进行下采样,即缩小了卷积层输出的特征图从而来加快网络的计算速度。但池化操作会使得上一层的卷积特征图的语义信息损失掉一部分。而且浅层的卷积特征感受野包含的背景噪声小,对小目标具有更好的表征能力[10]。另外,当目标被遮挡住部分时,这时只能得到目标的局部特征,对于浅层的卷积层来说,它们通常对目标的局部特征更为敏感,因此需要增加包含浅层信息的目标检测层,从而加强对遮挡的交通标识和较小交通标识的识别能力。
所以添加浅层目标检测层,以提高检测的准确率,为保证网络结构的平衡性,首先在Tiny-YOLOv3 的网络结构第二个卷积层后面添加了两个卷积层,在此基础上利用输出的8 倍降采样特征图与经过2 倍上采样的16 倍降采样特征图进行融合,增加了输出为8 倍降采样融合目标检测层,即增添了76×76 的特征图层,如图4 所示。增添了目标检测层后,可以获取到更多的目标位置信息[16]。

图4 增添76×76卷积尺度图
2.3 网络压缩
为了压缩网络,本文将密集连接网络应用到了Tiny-YOLOv3 网络中。对卷积层和目标检测层都进行了密集连接。密集连接模块中,如图5 所示,它的每一层的输入都是由前面各层的输出相加而得,将跳层连接用到了极致。如果设定每一层l 的非线性操作是如下表达式:Hl(.)。这个非线性操作可以是卷积、批标准化(Batch Normalization,BN)、线性整流函数(Rectified Linear Unit,ReLU)、池化,等等。而每一层的输出是:Xl,对于残差网络(Residual Networks,ResNet)来说,每一层的输出只是当前输出叠加上一层输出的结果[17],计算如式(2)所示:

而在密集连接模块中,是每一层都叠加了前面所有层的输出结果,即:

密集连接网络主要有以下两个优点:①可以减轻在训练过程中梯度消散的问题。该网络反向传播时每一层都会接受它后面所有层的梯度信号,所以不会出现网络越深,接近输入层的梯度会越来越小的情况。②密集连接中会有大量的特征被复用,所以只要使用少量的卷积核就可以生成大量的特征,因此卷积核数目不会太多,最终网络模型也会比较小[18]。所以在较浅的网络结构中,在相同精度下,使用了密集连接后,参数量和计算量都会大量减少。
图5 密集连接网络结构
为了降低参数量的同时保证准确率,采用密集连接网络,将增加尺度后的Tiny-YOLOv3 网络中的部分卷积层的网络结构修改为密集连接结构,使得其中的部分卷积层的输入为它前面的多层卷积特征图。同时对目标检测层(即YOLO 层)也进行了密集连接,使每个目标检测层都接受它前面所有目标检测层的特征作为输入,同时由于部分网络层连接了多层的输入,所以在进行目标检测前需要进行多次上采样。经过尺度及深度增加和密集连接后的网络结构图如图6 所示。
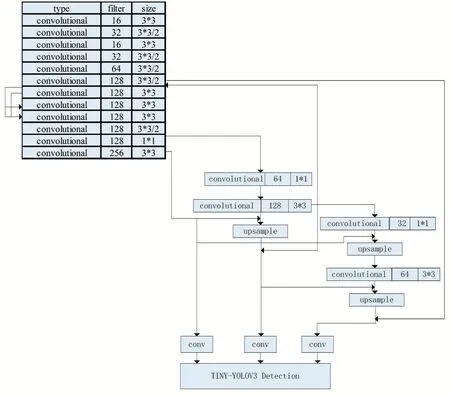
图6 改进后Tiny-YOLOv3网络模型
由图6 可知,Improved Tiny-YOLOv3 网络的卷积层卷积核个数都较少,卷积层的参数经计算有1597360个,减少了嵌入式平台运行该网络的存储需求。
3 实验及实验结果
3.1 实验环境及评价指标
目前国内在交通标识检测方面的公开交通标识别数据集有CCTSDB(长沙交通标识数据集)等。CCTSDB 数据集包含各种场景下摄像头采集的交通标识图像,其中训练集为上述数据集中随机的3500 张,测试集为上述数据集中的随机的1000 张,验证集为上述数据集中的随机500 张。数据集共分3 个类别:warning、prohibitory、mandatory。其中 warning 是警告标识,prohibitory 是禁止标识,mandatory 是指示标识。因此,本文基于公开数据集CCTSDB 对我们提出的模型进行训练和测试。
本文的实验环境配置如下:
训练环境及参数配置如下:Intel Core i7-6700 3.4GHz 处理器;显卡为显存12GB 的NVIDIA Titan X;Ubuntu 16.04 64 位操作系统;深度学习框架为Dark-Net。 Tiny-YOLOv3、Improved Tiny-YOLOv3 及 YOLOv3 的网络参数配置如下:训练框架为DarkNet,动量为0.9,权重衰减为0.0005,迭代次数为10000,学习率设置为 0.001,Tiny-YOLOv3、Improved Tiny-YOLOv3的预训练模型为Tiny-YOLOv3.conv15,YOLOv3 的预训练模型为darknet53.conv.74。Faster R-CNN 的网络参数配置如下:训练框架为Caffe,动量为0.9,权重衰减为0.0005,迭代次数为10000,学习率设置为0.001,训练方式为end to end(端到端)方式。
测试环境及参数配置如下:NVIDIA Jetson TX2,Quad ARM A57/2MB L2 处理器,8GB RAM。
针对准确率以及考虑将网络在硬件上实现等问题,选择了平均精确度均值MAP(Mean Average Precision)、召回率 Recall、参数量大小(Parameters)及运行时间(Time)作为硬件平台下运动目标检测模型的评价指标。
3.2 实验结果
将本文提出的网络以测试集结果的召回率(Recall)为横坐标,精确率(Precision)为纵坐标,最终绘制出P-R 曲线。计算P 和R 的公式分别为:

上式中,TP 表示正确检测到的交通标识,FN 表示没有被检测到的交通标识,FP 表示被错误检测到的交通标识。上述PR 曲线下的面积即为AP(该类的平均准确率),图7 为各标识的PR 曲线图。而对于每一个类别均求得其AP 最终取均值即为MAP。将改进前网络的各类AP 值与改进后网络的AP 值进行对比,显然改进后各类的AP 要略大一点。
表1 为同等硬件环境和同一个数据集,不同网络对交通标识检测的测试结果。其中Improved Tiny-YOLOv3 相比于原Tiny-YOLOv3,降低了参数量的同时,准确率和召回率都得到了提高。改进后的运行时间相较于原网络,虽然略慢了一些,但平均检测时间也只有0.01s,充分满足实时检测的要求。同时,本文提出的网络在准确率只略低于YOLOv3 的情况下,参数量得到了大大降低,更加利于将模型应用到嵌入式平台。
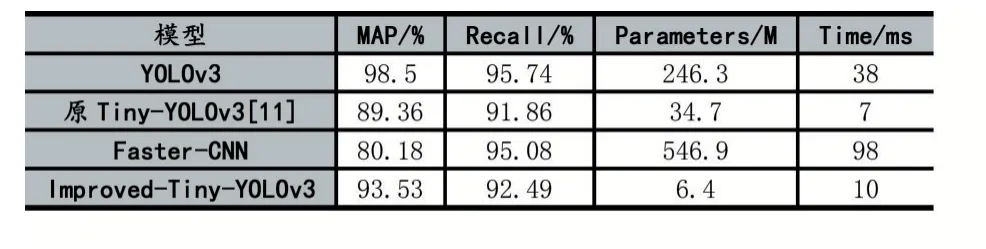
表1 不同模型实验结果
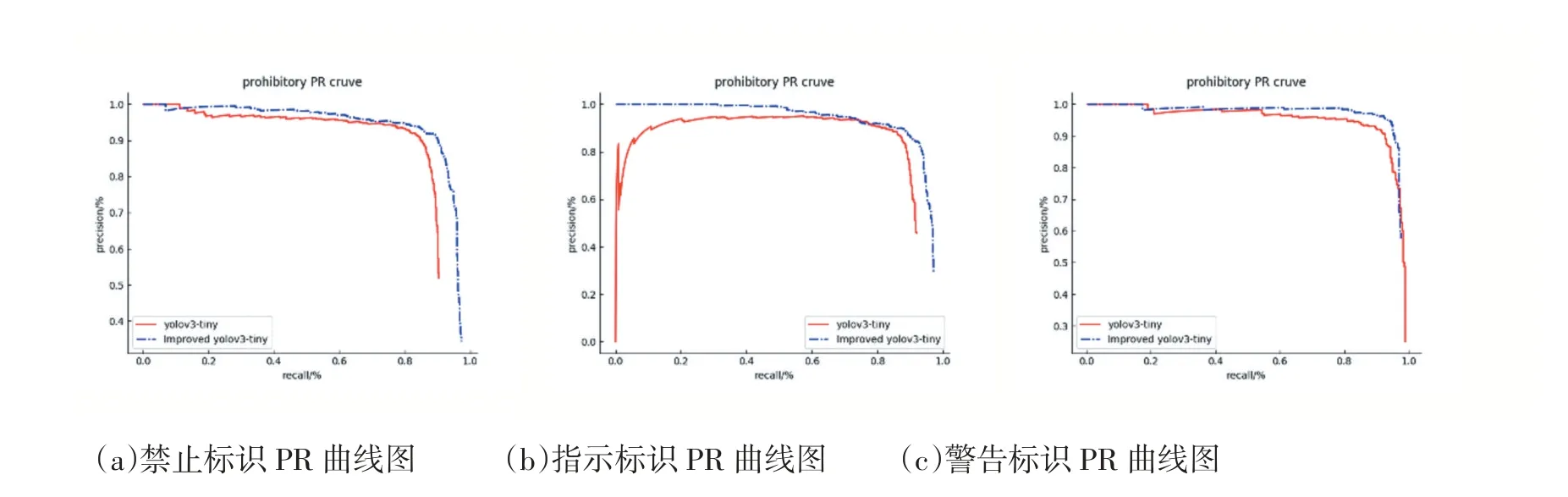
图7 不同标识PR曲线图
表2 为本文实验结果与其他论文中对交通标识检测的实验结果对比。可以看出本文提出的模型相较于它们来说无论在准确率上还是召回率和执行时间上都具有更好的性能。
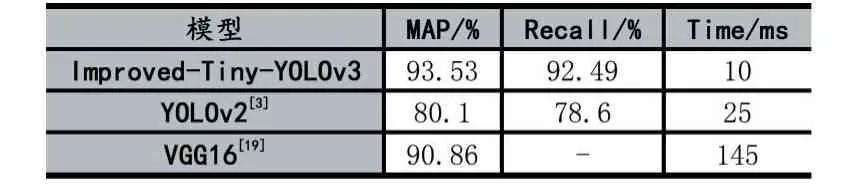
表2 Improved Tiny-YOLOv3 与其他论文模型对比
为了更好地观察本文方法的准确率提升效果,我们给出了原Tiny-YOLOv3 和Improved Tiny-YOLOv3网络测试图片的结果示例(左边为原Tiny-YOLOv3 结果,右边为Improved Tiny-YOLOv3 结果)。如图8 所示,原Tiny-YOLOv3 遗漏的交通标识,Improved Tiny-YOLOv3 都成功检测。
4 结语
本文基于嵌入式平台提出了一种基于改进的Tiny-YOLOV3 的交通标识检测方法,对候选框以及数据进行预处理使网络更适用于交通标识的检测、通过增加卷积层及建立输出为8 倍降采样的目标检测层减少漏检错检的概率,最后为了减少参数压缩网络,将密集连接的概念应用到了整个网络中,对卷积层和目标检测层都进行了密集连接。改进后的算法不仅在准确率及召回率上有所提升,并且还降低了网络在嵌入式平台上存储空间的需求。为了进一步降低网络运行功耗以便实际应用在智能交通系统中,本文的进一步目标是在FPGA 嵌入式平台上实现该网络。

图8 改进前后测试结果对比
猜你喜欢
汽车实用技术(2022年13期)2022-07-19
今日农业(2021年9期)2021-11-26
家庭影院技术(2021年7期)2021-08-14
英语文摘(2021年2期)2021-07-22
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
汉语世界(The World of Chinese)(2018年6期)2018-01-22
BOSS臻品(2015年1期)2015-09-10
