
基于Tree LSTM+CRF的属性级观点挖掘
2020-11-12 01:35
山东科技大学学报(自然科学版) 2020年6期
(山东科技大学 计算机科学与工程学院,山东 青岛 266590)
随着互联网的发展,互联网上的评论信息越来越多,属性级观点挖掘因能够挖掘出评论中包含的各个评价对象及观点内容、提取评论句中有价值的信息、快速准确地得出用户的关注点而备受关注。观点由属性(aspect)、观点内容(opinion)、持有者(holder)及情感(sentiment)组成,评价对象(aspect terms)是出现在评论句中涉及属性的单词或词组。例如:在评论句“The service of the restaurant is good,but the food tastes general.”中,service和food是具体的评价对象,good和tastes general是其对应的观点内容。本研究的目的是抽取评论中包含的评价对象和观点内容。
属性级观点挖掘最早由Hu等[1-2]提出,而后引起了诸多研究者的关注。目前,常用的属性级观点挖掘方法可以分为无监督学习方法和有监督学习方法。无监督学习方法中,Hu等[1]对数据词性标注后以Apriori算法进行关联规则挖掘找到频繁名词及名词短语,然后对错误词语进行剪枝后得到要抽取的评价对象。Popescu等[3]在文献[1]的基础上,将PMI(point-wise mutual information)加入剪枝策略中,计算频繁项与预定义的判别短语的PMI值,确定是否为要抽取的评价对象。刘鸿宇等[4]根据依存句法模板和规则抽取频繁项,通过剪枝处理得到要抽取的评价对象。江腾蛟等[5]提出了基于浅层语义与语法分析相结合的评价搭配抽取方法。廖祥文等[6]利用词对齐模型抽取候选评价对象与评价搭配组合,建立多层情感关系图,利用随机游走方法计算置信度,最后选取置信度高的候选评价对象与观点内容作为输出。这些无监督方法相对来说可操作性强,无需大量标注数据,但人工干预过多,需要提前建立模板,适用于目标领域较小的数据集。有监督学习方法中,常采用PLSA(probabilistic latent semantic analysis)和LDA(latent dirichlet allocation)等主题模型;而另外一些研究者将该任务看作是文本序列标注问题,采用隐马尔可夫模型(hidden Markov model,HMM)和条件随机场(conditional random fields,CRF)等方法。Wei等[7]先建立词集对评论文本进行标注,再使用HMM进行训练,抽取评价对象和观点内容并判断极性。刘全超等[8]利用CRF,选择句法特征、语法特征、语义特征及相对位置特证,抽取评价对象与观点内容的搭配。丁晟春等[9]采用CRF选取词、词性、情感词以及本体四个特征抽取评价对象。这类有监督的方法准确率较高,但由于需要大量人为设计特征,所以领域局限性强。
最近的研究中,研究者们开始尝试基于深度学习方法的属性级观点抽取方法。Irsoy等[10]使用深层双向循环神经网络抽取观点内容。Liu等[11]提出使用循环神经网络(recurrent neural network,RNN)结合词向量的方式抽取评价对象和观点内容。Yin等[12]提出一种无监督的方法,利用循环神经网络学习融合依存路径信息的词向量,然后用词向量作为CRF的特征来抽取评价对象。Wang等[13]提出基于注意力的LSTM模型进行属性级的情感分类。Giannkopoulos等[14]提出B-LSTM(bidirectional long short-term memory),结合CRF的分类器从有监督和无监督两类研究方向抽取评价对象信息。Wang等[15]提出一种名为RNCRF(recursive neural conditional random fields)的联合模型抽取评价对象和观点内容,首先根据句子的依存句法关系构建依存树递归神经网络,将评价对象与观点内容的信息编码到递归神经网络(recursive neural network,RNN)中学习更高级的隐层表示,然后将结果输入CRF进行序列标注。
本研究提出一个树结构长短期记忆网络(tree-structured long short-term memory networks,Tree LSTM),结合条件随机场的联合模型来抽取评价对象和观点内容,在很好地表征词语之间的层次关系的同时,有效避免传统CRF需要大量人工定义特征并且编写特征模板的弊端。
1 Tree LSTM+CRF
以评论“iPhone is pretty good.”为例,本研究提出的联合模型如图1所示。模型共分为三层,底层是各词的词向量,中间层是Tree LSTM模块,顶层是CRF模块。

图1 Tree LSTM+CRF联合模型结构Fig.1 Tree LSTM+CRF joint model structure
1.1 Tree LSTM
为了更好地理解本文模型,首先给出Tree LSTM中包含的各个参数含义(表1)。其中v为词典大小,包含所有在评论语句中出现的词,d为词向量维度。

表1 Tree LSTM各参数代表内容 Tab.1 Tree LSTM parameters representing content
构建Tree LSTM的过程:
1) 对所有评论语句进行依存句法分析,得到每个句子的依存分析树。
2) 按依存分析树的结构,以LSTM单元为节点为每个句子生成Tree LSTM模块。
图2为根据依存句法分析得到的例句的依存分析树和Tree LSTM。下面将基于依存句法关系,由叶子节点到内部节点逐个计算各节点的隐向量。以图2(b)为例,首先计算叶子节点单词“iPhone”的隐向量值:

图2 例句的依存分析树及其生成的Tree LSTMFig.2 Dependent analysis tree for example sentences and its generated Tree LSTM
iiPhone=sigmoid(Wi·xiPhone+bi),
(1)
uiPhone=tanh (Wu·xiPhone+bu),
(2)
ciPhone=iiPhone⊙uiPhone,
(3)
oiPhone=sigmoid(Wo·xiPhone+bo),
(4)
hiPhone=oiPhone⊙tanh (ciPhone)。
(5)
其中,⊙代表逐元素乘积,参数含义如表1所示,在经过LSTM多个门计算之后即可得出单词“iPhone”的隐向量值hiPhone。其他叶子节点的隐向量值同样方法计算得到。例如单词“is”的隐向量值计算如下:
iis=sigmoid(Wi·xis+bi),
(6)
uis=tanh (Wu·xis+bu),
(7)
cis=iis⊙uis,
(8)
ois=sigmoid(Wo·xis+bo),
(9)
his=ois⊙tanh (cis)。
(10)
当所有叶子节点计算完毕后根据依存关系计算内部节点的值,单词“good”的隐向量值计算如下:
igood=sigmoid(Wi·xgood+Ui·WnsubjhiPhone+Ui·Wcop·his+
Ui·Wadvmod·hpretty+bi) ,
(11)
fgood-iPhone=sigmoid(Wf·xgood+Uf·Wnsubj·hiPhone+bf) ,
(12)
fgood-is=sigmoid(Wf·xgood+Uf·Wcop·his+bf) ,
(13)
fgood-pretty=sigmoid(Wf·xgood+Uf·Wadvmod·hpretty+bf) ,
(14)
ugood=tanh (Wu·xgood+Uu·Wnsubj·hiPhone+Uu·Wcop·his+Uu·Wadvmod·hpretty+bu) ,
(15)
cgood=igood⊙ugood+fgood-iPhone⊙ciPhone+fgood-is⊙cis+
fgood-pretty⊙cpretty,
(16)
ogood=sigmoid(Wo·xgood+Uo·Wnsubj·hiPhone+Uo·Wcop·his+
Uo·Wadvmod·hpretty+bo) ,
(17)
hgood=ogood⊙tanh(cgood) 。
(18)
在计算内部节点隐向量值时,输入该节点的除了该词词向量外,还有该词与其多个子节点的依存关系信息。每个子节点都会有一个遗忘门去处理该子节点传来的信息,经过LSTM多个门单元计算后即得出此内部节点的隐向量值,内部节点的一般计算公式总结如下:
(19)
fjk=sigmoid(Wf·xj+Uf·Wr(jk)·hk+bf) ,
(20)
(21)
(22)
(23)
hj=oj⊙tanh (cj) 。
(24)
其中,C(j)代表当前节点j的所有子节点的集合,Wr(jk)代表单词j、k之间的依存关系矩阵。当该句所有词的隐向量值计算完毕后,即将结果输入到条件随机场中进行序列标注。
1.2 CRF
条件随机场是序列标注任务中的主流方法之一,是一种判别式概率模型。本研究使用线性链条件随机场,输入是Tree LSTM各个节点求出的值,输出是标签,联合模型如图1所示。
对每个句子,将经过Tree LSTM计算并输入到CRF中的隐向量序列表示为H={h1,h2,…,hn},模型输出的标签序列表示为Y={y1,y2,…,yn},单词的标注标签本文选用标准的BIO标注方式,即yi∈{BA,IA,BO,IO,O},其中BA代表评价对象的开始部分,IA代表评价对象的内部,BO代表观点内容的开始部分,IO代表观点内容的内部,O代表其他词。例如评论句“The service of the restaurant is good,but the food tastes general.”,CRF的输入为H={hThe,hservice,hof,hthe,hrestaurant,his,hgood,hbut,hthe,hfood,htastes,hgeneral},模型的输出结果为Y={O,BA,O,O,O,O,BO,O,O,BA,BO,IO}。
在给定输入H的条件下,Y的条件概率分布计算:
(25)
其中:Z(H)为规范化因子,用于归一化;ψc(Yc|H)为势函数;P(Y|H)是所有最大团C上势函数的乘积。此处最大团包含两类,一是Tree LSTM输入到CRF的代表状态特征的团,二是输出序列中代表转移特征的团。在计算状态特征势函数时,额外融合上下文窗口大小为3的信息,则词“is”处的状态特征势函数计算示例如图3所示:
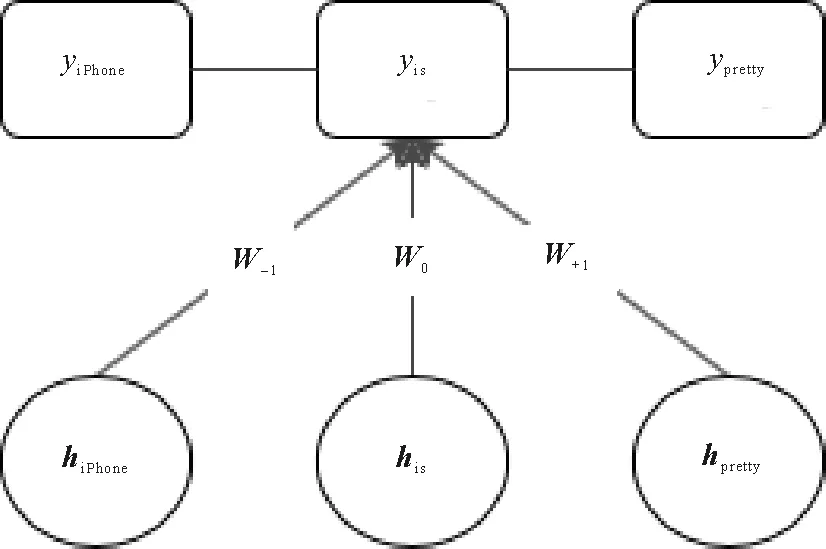
图3 词“is”处窗口大小为3的状态特征势函数计算示例Fig.3 Example of state feature potential function calculation with window size 3 at word “is”
在上下文窗口为3时,节点k处的状态特征势函数计算公式:
(26)
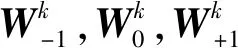
(27)
式中计算势函数时前三项代表计算窗口为3的状态特征势函数,第四项代表计算转移特征势函数。
1.3 模型训练
在对整个模型训练时,应用链式法则利用反向传播的方法学习各个参数。误差首先从条件随机场开始反向传播,沿模型结构传到Tree LSTM中,ROOT指向的节点只接收到从CRF传来的误差,其他节点将接收到来自CRF的误差和来自依存关系父节点传来的误差,LSTM单元中各门的参数也将根据链式法则学习更新。
2 实验及分析
2.1 数据集及实验设置
本节使用SemEval Challenge 2014 任务4的数据集对模型进行训练与测试,该数据集包含笔记本和餐馆两个领域的评论数据,详细信息如表2所示,该数据仅仅包含对评价对象的标注,实验使用了Wang等[15]对观点内容手工标注的数据。

表2 SemEval Challenge 2014 任务4 数据集Tab.2 Dataset of SemEval Challenge 2014 Task 4
在训练词向量时,使用gensim word2vec方法进行训练,餐馆领域的训练语料数据选择Yelp cha-llenge dataset的评论数据,笔记本领域训练语料数据选择Amazon的电子产品评论数据,词向量的维数在比对后选择350维,对比实验在2.2节中叙述。评论语句的依存句法分析树使用Stanford Parser生成,模型中的线性链CRF使用CRFSuite实现。
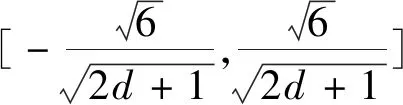
由于SemEval Challenge 2014 任务4的评测模型仅对评价对象进行了抽取,为了方便比较,将本模型去除观点内容标签后重新训练学习,得到只抽取评价对象的联合模型并命名为Tree LSTM+CRF-O。
2.2 实验与结果分析
为了验证提出模型的有效性,本研究还实现了以下几个模型:
1) SemEval-1,SemEval-2:SemEval Challenge 2014任务4评测时性能最好的两个模型。
2) CRF-1:包含基础语言特征(词、文体、词性、上下文、上下文词性)的CRF模型。
3) CRF-2:包含上述基础语言特征和依存关系特征(中心词和词之间的依存关系)的CRF模型。
4) W+L+D+B:Yin等[12]提出的CRF模型包含无监督学习得到的词嵌入特征、依存关系特征,线性上下文嵌入特征以及基础特征模板。
5) LSTM,LSTM-CRF,Bi-LSTM-CRF:分别指LSTM为基础的长短期记忆网络,LSTM-CRF为长短期记忆网络结合CRF的模型,Bi-LSTM-CRF为双向长短期记忆网络结合CRF的模型。LSTM网络中的权重通过区间[-0.2,0.2]的随机均匀分布初始化,隐层的大小设置为50,学习率设置为0.01。
6) RNCRF,RNCRF-O:Wang等[15]提出的递归神经网络和CRF的联合模型,RNCRF-O是为方便比较而忽略掉观点内容标注的模型。
选用F1值作为模型性能的评价指标,计算方法如公式(28)~(30)所示。其中,TP是模型正确标注的数量,TP+FP是模型标注的总数,TP+FN是测试集中存在的标注总数。
(28)
(29)
(30)
实验结果如表3所示。
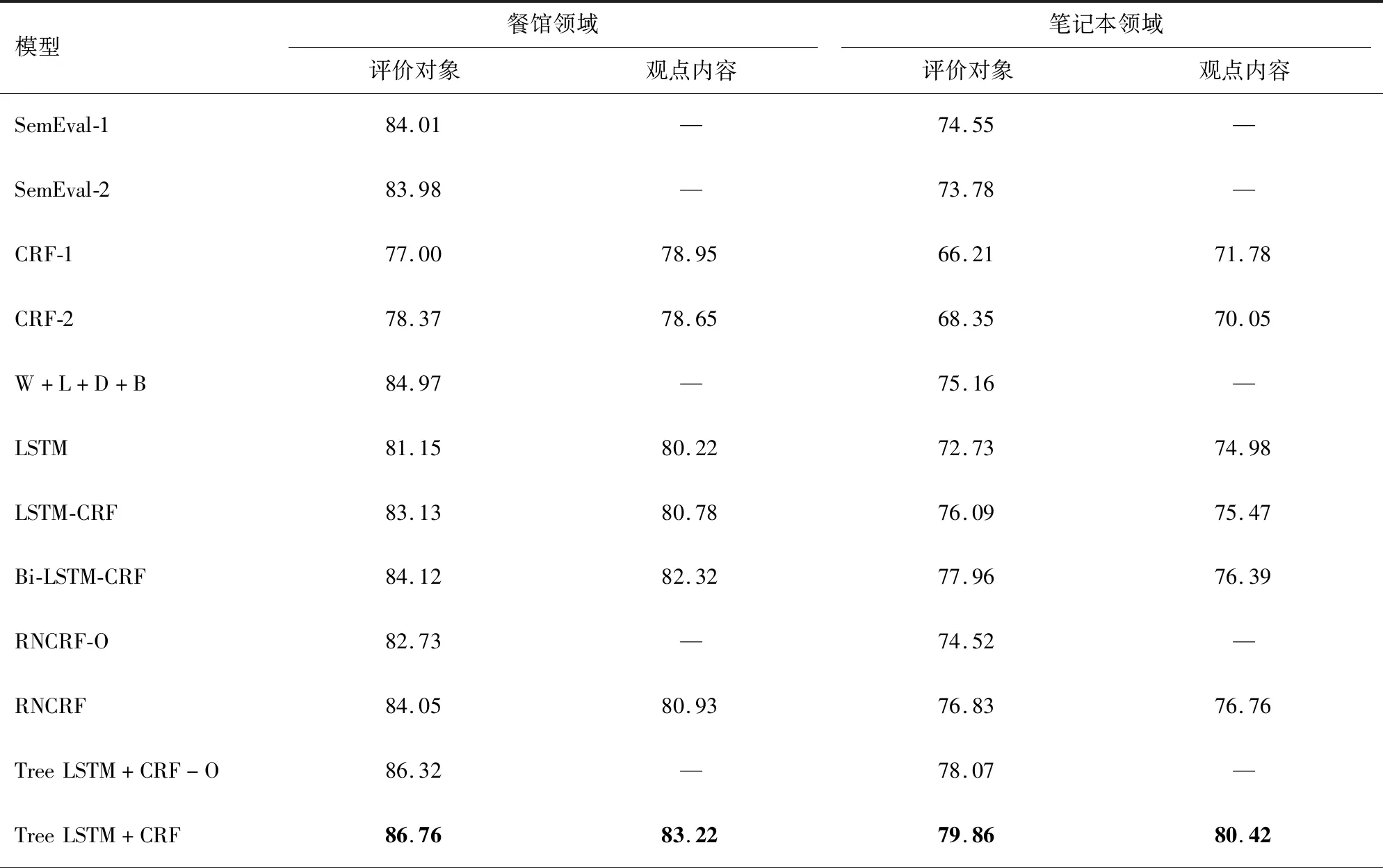
表3 各模型实验结果的F1-Score值Tab.3 F1-Score of experimental results of each model
由表3可知,本模型比SemEval Challenge的最优模型SemEval-1与SemEval-2效果好,在餐馆与笔记本领域分别比SemEval-1高出2.75%和5.31%。在与普通条件随机场的对比中,在加入依存关系特征后,CRF-2在评价对象抽取上比CRF-1在餐馆和笔记本领域分别高出1.37%和2.14%,说明依存关系特征确实有助于评价对象的抽取,同时CRF模型的结果低于其他模型,说明深度学习方法比条件随机场学习信息更加有效。LSTM模型的结果要差于LSTM-CRF模型,这是由于条件随机场能够纠正类似IA、BA这样的标注顺序错误,所以大部分模型都会在神经网络之后连接条件随机场进行标注。双向LSTM因为能够捕获2个方向的信息而比普通LSTM模型效果要好。本模型比RNCRF模型效果略好,说明将普通递归神经网络单元替换为LSTM单元和设计树结构下LSTM单元门结构的计算方法是有效的;比时间序列的Bi-LSTM-CRF模型的结果好,说明树结构在依存关系信息的处理中优于时间序列结构。由于依存关系是由子单词指向父单词,类似于树结构,所以在依存关系特征上树结构效果更好。Tree LSTM+CRF-O是去除观点内容标注的模型,从实验结果可以看出,该模型性能损失不大,表明本模型鲁棒性好。
图4给出了RNCRF和Tree LSTM+CRF两个模型实际标注的结果示例。从图4中的例子中可看出,本模型比普通递归神经网络能更好地处理依存关系特征和词本身特征,对低频出现的评价对象和依存关系相对复杂的句子标注结果更好。
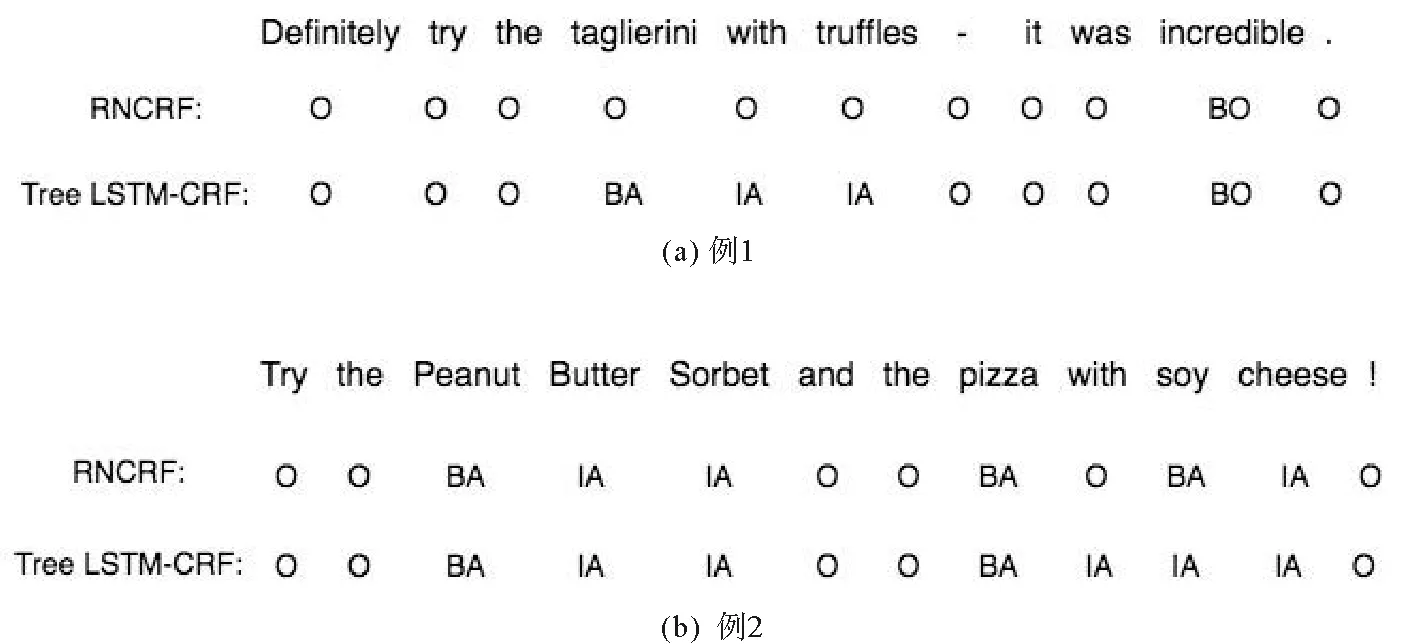
图4 RNCRF与Tree LSTM+CRF标注结果对比Fig.4 Comparison of RNCRF and Tree LSTM+CRF labeling results
进一步还对不同词向量维度对模型的影响进行了实验。实验选取维度范围为50~500维,维度间隔为50,实验结果如图5所示。
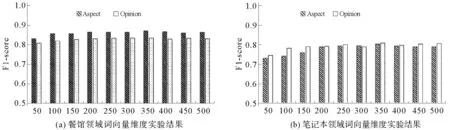
图5 词向量维度对比实验结果Fig.5 Word vector dimension comparison experiment results
由图5可以看出,在餐馆领域,评价对象的抽取结果普遍优于观点内容的抽取结果;而在笔记本领域,观点内容的抽取结果普遍优于对评价对象的抽取结果。而且模型在两个领域下都在350维处效果最好,模型性能随维度变化有波动但波动幅度不超过3%,模型性能相对稳定。
3 总结与展望
评价对象和观点内容的抽取是观点挖掘中的重要研究内容。本研究提出一个基于Tree LSTM结合CRF的联合模型来抽取评论语句中的显式评价对象与观点内容。该模型包含两部分,第一部分是根据评论语句的依存结构树构建的Tree LSTM,用于融合词向量和依存句法关系向量从而学习每个词的高层特征;第二部分是条件随机场,将从Tree LSTM得到的每个词的隐向量输入其中进行序列标注工作,将隐向量映射到代表评价对象、观点内容和其他词的标签上,实现了评价对象与观点内容的抽取。在SemEval Cha-llenge 2014 任务4的数据集上的实验结果表明本Tree LSTM能很好地表征词语之间的层次关系,同时联合模型有效避免了传统CRF需要构建特征工程的弊端。
目前本模型只是实现了简单的抽取工作,下一步将对评论句进行情感分析,深入分析用户所表达的观点;并尝试对评论中的隐式评价对象进行抽取,以全面分析用户的观点。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
廉政瞭望·下半月(2021年5期)2021-07-20
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
学生天地(2020年8期)2020-08-25
中等数学(2018年8期)2018-11-10
意林(2018年3期)2018-03-02
汽车生活(2018年1期)2018-02-02
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
好家长·青春期教育(2014年7期)2014-07-05
