
基于深度强化学习的股市操盘手模型研究
2020-11-10 07:10韩道岐张钧垚周玉航
计算机工程与应用 2020年21期
韩道岐,张钧垚,周玉航,刘 青
中国人民大学 信息学院,北京 100872
1 引言
深度学习技术已广泛应用于各领域,实现了类似人脑的分类、推理、预测功能。深度强化学习模型进一步解决了过程决策问题,在生物仿真、机器翻译、工业制造、自动驾驶控制、优化和调度、视频游戏和围棋等领域取得了显著成果[1],对股票交易领域也将起重要作用。在金融市场中,已有股票预测和操作策略方面的研究[2-4],在估值、风险评估方面文献不多,与经典量化投资理论相结合的强化学习模型并可实战的成果更少。
在金融市场量化操作时,研究人员是针对产品价值、众多指标和周边环境影响因素进行综合评估,形成当前的操作策略。但是往往受限于以下三个方面:
(1)产品信息量不足,不能准确估值。
(2)片面地依据一个指标,效果很差。
(3)依据已总结的指标和固定操作策略不能动态适应环境变化,抗风险能力弱,策略易失效。
采用基于深度强化学习技术的机器人自动进行股票交易操作,也必然面临以上问题,因此扩展DQN算法[5-6],实现智能股票操盘手模型ISTG(Intelligent Stock Trader and Gym),它能更高频和准确地发现投资机会;可端到端学习和优化操作策略,自动适应环境变化。模型在完成高收益、低风险关键目标的同时,还能辅助判断市场形势、投资决策、预测股市未来发展状况。
2 相关工作
人工智能发展经过了几次重大突破[7],形成了较完备的理论体系,并在2006 年进入深度学习阶段[8],学术界把大规模训练数据和大规模可迭代的网络结构作为人工智能的发展方向。LeCun等[9]提出了类似与人类观察世界结构方式的自学习,是未来研究重点。强化学习可无监督的观察环境,主动探索和试错,能自我总结出优秀经验。目前深度学习和强化学习相结合的主动学习系统虽然处于初级阶段,但在学习各种视频游戏方面已经取得出色的成果。
2016 年 3 月 9 日,AlphaGo 战胜李世石[10],之后深度强化学习DRL(Deep Reinforcement Learning)[11-12]技术发展迅速。DRL实现了类生物智能体,不受体力和情绪限制,能通过网络获得几乎无限的存储和计算能力,并结合了深度学习的高维数据感知能力、数据统计分析的预测能力、强化学习的搜索最优操作策略能力,使得智能体[13]能快速成为某个领域的强手。在DRL基础上,树搜索、层次化、多任务迁移学习、多agent合作和竞争学习[14]等方法均有很好的应用前景。周文吉等[15]提出端到端的、自动总结抽象的分层强化学习,能够适应复杂环境。李晨溪等[16]提出应用知识图谱和自然语言处理、迁移学习、模仿学习等方法,利用知识更好地指导深度强化学习。
金融市场由于大量复杂因素的相互影响,其数据具有不确定性和时序特征,数据分析是复杂的非线性和非稳态问题,传统的统计学模型和海量数据挖掘模型在金融预测和序列决策中效果欠佳。量化投资[17]强调建立严谨的分析模型、高效捕获机会并自动执行,如果自动决策不能针对当前实际情况自适应调整,则风险巨大,因此研究适合的智能决策模型有着迫切的需求。
DeepMind[5]的DQN(深度Q网络)首次将CNN深度学习模型和Q-learning 相结合,解决了传统Q-learning难以处理高维数据的问题。Double DQN[18]提出使用两个Q网络,一个负责选择动作,另一个负责计算,定期更新计算网络,克服了Q-learning 过优化现象。针对随机抽取经验导致忽略了经验之间的不同重要程度这个缺陷,文献[19]采取按优先级抽取经验池中过往经验样本。Dueling DQN[20]提出了一种新的网络架构,在评估Q(S,A)的时候,同时评估了动作无关的状态的价值函数V(S)和在状态下各个动作的相对价值函数A(S,A)的值,Dueling DQN是一个端到端的训练网络。多步合并收益[21-22]可更快地将新观察到的奖励传播到之前观察到的状态,减少了学习样本。价值分布网络[23]学习获得的随机回报的多个分类分布而非状态值函数,损失函数变成两个概率分布的距离,在有相同均值情况下,可以选择方差(风险)最小的动作。噪声网络[24]在参数上增加噪声和学习噪声参数,并可取消随机探索,能控制不同场景下的探索随机性。彩虹网络[25]实现上述机制的同时有更快的训练速度和更高的得分。针对需要连续动作的场景,策略梯度类算法(Policy Gradient)[26]可以直接学习动作,解决无法直接学习值函数的问题。A3C(Asynchronous Advantage Actor Critic)[22]和 OpenAI 的同步式变体A2C是actor-critic方法上的最优实现,actorcritic 方法将策略梯度方法与价值函数结合,拆分两个网络学习两个不同的函数:策略和价值。策略函数基于采取该动作的当前估计优势来调整动作概率,而价值函数则基于经历和后续策略收集到的奖励来更新该优势。分层式强化学习(HRL)则尝试使用更高层面的抽象策略,形成组合逻辑,Nachum等[27]设计了通过上级控制器自动学习和提出目标来监控下级控制器,可用更少样本和更快速度的交互,学习模拟机器人的复杂行为。总的来看,深度强化学习发展历程如图1所示。

图1 深度强化学习发展历程
深度强化学习目前已应用于金融配对交易、高频交易和投资组合等领域。Moody等[28]提出的递归强化学习(Recurrent Reinforcement Learning,RRL)和Q-learning组合的学习算法,训练交易系统,通过返回的差分夏普比率做风险调整,实验结果显示RRL 系统明显优于监督学习系统,同时发现了Q-learning可能遭受维数灾难,该研究的训练数据使用单一指数产品、较长周期和月线行情,适用面较窄。Deng等[29]构建了DRL模型,在参数初始化、特征学习、去噪等过程采用机器学习技术,以提高随机序列的预测准确率,对股票和商品期货市场进行交易决策和验证。该研究的期货类产品数量单一,针对期货类高频交易使用分钟周期,依据收盘价单一指标,不适合其他周期类型。齐岳等[4]首次把深度确定性策略梯度方法DDPG应用到投资组合管理,动态调整投资组合中资产的权重到最优。投资组合是随机选取的16只股票,输入的收盘价数据信息量少,没有提出合理选择投资组合的方法,缺乏较大规模的组合对照实验。胡文伟等[30]将强化学习算法和协整配对交易策略相结合,解决投资组合的选择问题,使用索提诺比率作为回报指标,实现了模型参数的自适应动态调整,收益率和索提诺比率大幅提高,最大回撤明显下降,交易次数明显减少。但债券品种较少,数据集规模小,状态指标较少。
针对当前研究普遍存在的股票交易品种少、输入状态少、测试周期短等问题,本文基于深度强化学习的最新成果,与传统量化理论结合,提取更丰富的股票交易特征,采用更全面的市场数据、更准确评估模型性能的指标,端到端训练模型,以适应不同类型金融产品的投资操作并获得更大收益。
已有文献在训练CNN 和LSTM 模型时,把数据加工成图片模式输入,本质上增加了无关的背景噪声,有效信息稀疏,导致只能提取特定的图片形状特征。本文直接使用数据和指标构建多日滑动窗口,可更灵活地添加特征和扩展历史天数,噪声少、收敛快。针对股票行情,取消DDQN模型训练时的价值网络预测输出各个动作回报、目标网络预测输出最大Q值,而直接使用模型的收盘价准确计算回报,加快模型训练速度。
3 ISTG模型
3.1 目标
ISTG 智能操盘手模型主要目标是在某个市场中,根据历史(多日)行情,进行当日的买卖操作,找到最优的行动策略,使指定周期范围的最终收益最大化。
为增强操盘手对市场的把握能力,理论上应利用市场所有股票的全部历史数据。
本文基于经典的DQN方法,利用CNN网络学习和输出动作价值,Q-learning方法与环境不断交互,获得有回报标签的训练数据,建立存储上百万帧的记忆队列,随机采样小批量数据进行模型训练。ISTG的总体架构如图2所示。

图2 ISTG的总体架构
3.2 设计
强化学习的理论基础是马尔科夫决策过程MDP。MDP 的模型为一个五元组 <S,P,A,R,γ> ,其中包括:有限状态集S,状态转移概率P,有限行动集A,回报函数R,计算未来回报折现后的折扣因子γ。强化学习的目标是找到最优策略π使得累积回报的期望最大。积累回报Gt定义为:

本文定义股市操作的优化目标为最大化一个周期的总收益TR,控制单个动作的幅度风险SR,控制操作次数风险TO。从量化投资分析角度,可对应到年化收益率、最大回撤率和夏普比率三个量化指标,评估一个阶段的操作效果。可直接利用行情数据,计算指标折算后的回报值。
策略π是给定状态s的情况下行动a的分布:

一个策略π定义了智能体的行为,因此:

操盘手的操作策略有:控制单次买卖数量、控制风险仓位、控制涨跌成交的幅度、控制止损止盈,可以根据经验设置智能代理的这些控制参数。智能代理应能够全面分析和选择优质股票,在合适时机买入卖出,使投资组合获得最大上涨可能的同时,尽可能减少操作次数。
MDP 过程可以采用Bellman 方程(Bellman Expectation Equation)计算策略π获得的两个价值函数,状态值函数vπ和状态动作值函数qπ:

两个价值目标的最优函数为:

通过找最大化q∗(s,a)对应的行动,并迭代,可以找到最优策略,得到可存储值函数、迭代的Bellman最优方程(Bellman Optimality Equation):
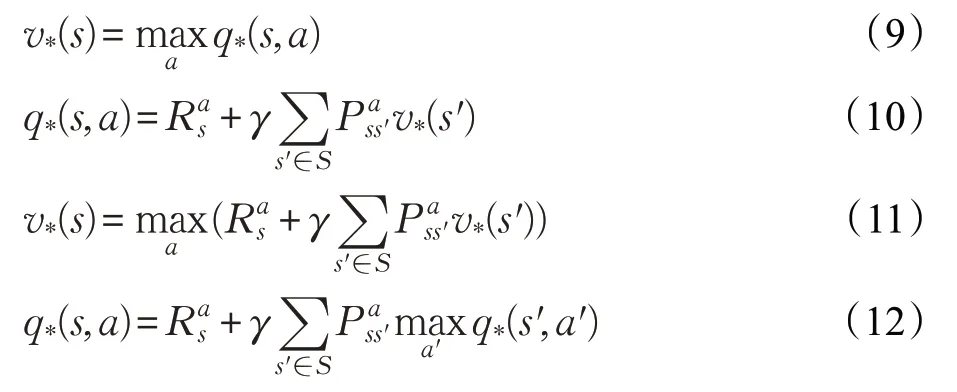
Bellman 最优方程实现了迭代的分解,价值函数v存储和再利用。按照动态规划原理,如果已知子问题的最优解v∗(s′),那么对于后继状态是s′的状态s,均可找到最优解:

本文设计了图3 所示系统工作流程实现上述求最优解原理。在图3中的原始数据整理模块,预先收集加工相关数据,形成以下输入信息:智能代理状态、环境状态、序列状态,形成多日的时间窗口矩阵。通过DQN网络模型,迭代计算策略的最优解。由于股市具有不同周期特点,数据加工模块可针对各种典型周期数据,加工后进行学习和分析结果。AGENT模块每天优选回报最优的产品,按大概率获利策略操作,形成实际的最优投资组合。

图3 系统工作流程
具体迭代过程为:已知下一步的信息v∗(s′),递推当前的信息v∗(s),从后往前计算,形成最优动作,构成整个策略。如果采用贪心算法,每次策略π都选到该状态下qπ(s,a)值最大时所对应的行动a,当Q值不能再改进时,模型收敛:

此时满足bellman最优方程:

对于所有的s∈S,都满足vπ(s)=v∗(s),此时π为模型学会的最优策略。设计了一个复盘环境SGYM,即ISTG 中的Stock GYM 模块。它回放过程,形成充足的状态s,准确计算状态s的回报,训练智能代理搜索和存储策略π。智能代理不断主动行动和存储经验,学习一个行动生成模型,不断减少当前策略和最优策略的回报差距,最终每次都能选择类似状态下的一个最优行动A,其回报qπ(s,a)最大(公式(15))。
SGYM 的回报设计,体现总收益TR目标的最大化,单步收益SR目标的时机、价格幅度、买卖数量三者最优化,操作次数TO目标的上涨概率、交易成本、波动风险三者最优化,针对不能成交操作、反向的错误判断成交增加额外惩罚。实现多目标最优方程如下:

目前在AGENT模块中的状态加工和量化策略控制基于规则实现,这一方面能直接利用现有的优秀量化控制策略,减少失误,另一方面便于发现优秀策略的操作特征,总结经验。其中经验参数优化问题,后续可通过强化学习解决。
3.3 实现
为了建立SGYM,本文把股票信息分为四个部分:智能代理发出操作前的状态、对应股票的行情状态、指标状态、宏观经济状态,共37个特征,如表1~4所示。

表2 股票行情状态的特征描述

表3 行情分析指标状态的特征描述

表4 宏观经济指标状态的特征描述
AGENT 针对一个股票执行买卖操作后,SGYM 根据操作计算返回表1 中6 个状态字段,直接使用第二天的行情、行情的分析指标、宏观经济的分析指标,返回表2~4的相关特征。
在加工好上述数据后,SGYM可指定一个目录下的股票数据,创建环境对象。每个回合初始化时,使用随机策略选择一个股票,初始化AGENT 该股票账户的总价值和指定比率的股票,返回初始状态。有0至20共21个行动标签,分别为卖出10手到买入10手。AGENT发出行动,SGYM 执行一步操作,调整智能代理状态和输出下一日状态,计算回报值。回报可以是下一日的总价值的增减,或是收益率增减,或是本次操作股票成交后的价值增减。针对成交情况,扣减千分之一手续费,针对不能成交情况做千分之三的惩罚,针对反向操作(买入第二天下跌,卖出第二天上涨)追加百分之一的惩罚。AGENT 使用百万帧空间存储<s,a,r,s′>的每次经验数据,异步随机采样训练模型,打破样本相似性,减少模型不稳定对行动预测的影响。ISTG的经验回放策略采用了一些优化技巧:开始时随机执行空操作(NO_OP),等待状态窗口中有效历史数据的积累;间隔5 步行动、累积较充分经验后,训练模型一次;存储到5 万个随机策略后,再开始训练;超过10%损失掉命重新开始回合,这样经验池可保存更多的优秀策略。这种离策略模型可以发现利用优先级高的经验、发现利用高分的回合、注入人类加工的优秀策略,总结经验、加快智能代理的学习。
DQN模型的网络结构如图4所示,由3个卷积层和2个全连接层构成,网络参数与经典的DQN一致。使用连续滑动4 日的窗口作为输入的4 个通道,每个窗口帧为20 天的37 个特征组成的矩阵。输出为21 个动作的Q值。本文建立了模型保存和恢复机制,可以阶段性保存成果,重入后使用新的匹配参数继续训练网络。
DQN 模型的关键是针对Q值函数学习,最终能够收敛、准确预测各种状态下每个动作的Q值。根据Bellman期望方程可计算Q值:


图4 网络结构
其中,r为回报,Q*为下一步的最大Q值,γ为折现因子,γ设为0时,模型只关心当前收益,γ设为1时,模型均衡考虑当前收益和下一步的最大Q值,初始值设为0.95。模型预测能力越强,γ越应趋向1。AGENT决策行动时,使用模型预测各步的Q值,每次都按最大Q值的动作行动。AGENT 离策略训练模型,随机提取经验池中小批量数据,根据经验记忆中的状态预测各动作Q值,根据下一个状态,预测获得下一步最大Q值并折扣累加到当前动作的Q值上,即r+γmaxQ(s′,a′)作为期望的Q值。根据方程(17)使用 (r+γmaxQ(s′,a′)-Q(s,a))2作为损失,梯度下降训练模型,预测结果更接近综合了下一个状态情况的Q值。
探索和开发过程是强化学习不断试错,获得环境回报标签和利用经验数据学习的交替过程。模型初期预测Q值不准确,与随机动作效果类似,随着各种状态的学习,Q值越来越准确后,预测结果变平稳,从而会减少探索到新的有效策略的能力。DQN采用了e贪心选择,有e概率选择随机动作,否则按预测的最大Q值选择动作,初始e为1,最终稳定到0.1,差值0.9 按照百万帧平均到每个帧上,随着训练过程线性衰减e。记录初始的5万个随机动作过程时,无需训练。
算法1智能代理探索和开发过程
输入:环境env,代理agent
输出:模型结果model,训练过程的reward、maxq、return rate
1.for 在指定回合内
2.环境env.reset获得当前股票和初始状态state
3.组织初始窗口,state重复20次形成20*37矩阵states
4.while当前股票周期未完成
5.代理ε贪心选择动作agent.ac(tstates)
6.环境执行动作env.step(action)
7.states窗口滑入一天数据作为下一天状态
8.代理记忆经验数据 <s,a,r,s′>
9.价值损失超过10%结束当前回合
10.agent 记忆内存超过 5 万帧并每隔 5 帧,replay 训练模型一次
11.end
12.end
由于股票具有可复盘历史数据和直接计算第二天收益的特点,原DDQN方法训练模型时需要使用目标网络T预测最大Q值的处理,ISTG 模型改成直接使用SGYM 计算出准确的动作回报和动作的最大Q值,使得每步都可以获得确定性的动作值,加快模型的收敛速度。
4 实验和性能
4.1 环境
实验的硬件环境为Intel i7-6700HQ 4C/8T,主频2.6 GHz(MAX 3.5),16 GB内存,显卡NVIDIA GeForce GTX 960M,2 GB GPU内存。软件环境为Windows 10操作系统,Python 3.6开发平台,keras和tensorflow深度学习框架。
4.2 数据准备
收集的数据有中国2007 年至2018 年的1 479 只股票的行情数据,上证综指和宏观经济数据。经过加工后,形成了37个特征。
数据预处理模块对缺失字段,进行填充零值处理。针对宏观经济数据按日重新采样插入每日记录,货币供应量增长率M1和M2后取值、插值到下一个月末,其他诸如利率和汇率前取值、插值到下一个变更点。由于相关字段数据范围稳定,本文统一归一化到0~1 之间,对日期和股票代码字段进行0~n个类标签的整数编码。最终按时间拆分数据成2007—2014 年的训练数据集TN1,2015—2017年测试数据集TS1,还提取了2015年大幅波动趋势RG2015和2018年总体下降趋势RB2018的两个典型数据集,用于对比不同周期情况下的模型效果。
4.3 实验结果
为了评估本文提出的智能股票交易手的性能,设计了四种实验方案:买入持有策略ev_hold,使用每日资产收益回报和目标网络计算Q值ev_tq,初始时股票占一半的ev_tqh,使用 SGYM行情数据计算Q值ev_mq。
第1 种ev_hold 方案,所有股票初始化同样的资金后,每次1手买入直到使用完资金。各数据集复盘后平均收益率如表5所示。

表5 ev_hold方案数据集的复盘结果
第2 种是ev_tq 方案,所有股票初始化同样的充足资金。训练阶段分别运行1 000、2 000、5 000、10 000 个回合,使用TN1 数据集进行四次训练,获得四个不同能力的模型和训练过程数据。可灵活根据上次训练情况,动态调整超参数,装载上次训练的结果模型后进入下一次训练。多轮训练的资产收益率、平均最大Q值、回报的学习情况趋势如图5所示。经过一千多回合后,平均最大Q值开始稳定下降,趋向17 000。可以看出增加回合数,回报值逐步稳定,5 000 回合后资产收益率变平稳,学习阶段收益率可达最大5 000%,最小值-24%,均值22%。
在TS1 测试集上,ev_tq 方案使用训练获得的四个DQN,分别测试1 479只股票的分布情况见图6,可以看出2 000回合后模型收益率差异不大。

图5 ev_tq训练的资产收益率、平均最大Q 值、回报趋势

图6 ev_tq测试的各股票资产收益率、平均最大Q 值、回报情况
ev_tq 方案测试的关键评估指标情况见表6,对比ev_hold方案,其收益率和夏普比率的均值高。

表6 ev_tq和ev_hold方案测试集上关键指标对比%
分析ev_tq 方案最终的资产总收益率情况,发现测试集TS1 中的股票,如亨通光电、贝瑞基因、分众传媒、水井坊、南京新百等,收益可达4~5倍,比买入持有的收益更高。控制最大回撤在20%~30%区间时,恒瑞医药、五粮液、贵州茅台、南极电商等保存了2~3 倍的高收益率,同时回撤风险也较小。
实验验证了ISTG 在资产收益率和夏普比率方面结果较好。为进一步对比时序上的总体操作效果,本文分析了ev_hold 和ev_tq 方案在测试集上的总收益率变化过程。通过计算1 479个股票的每日资产均值和标准差,显示总收益率在3 年中的变化趋势,如图7 所示,可以看出ev_tq在各时间段都超过ev_hold,两个方案均在2015 年5 月达到最大收益水平。而阴影表示的标准差,随时间推移逐步扩大,显示了模型的稳定性在逐步下降。

图7 资本总收益率对照
由于ev_tq 方案的全部初始化持有资金处理,导致模型学习的动作偏向买入,图7 显示资金用完后,方案效果与买入持有的完全一样。本文设计了第3种ev_tqh方案,尝试初始化一半股票,初始时买入和卖出动作都可以获利。同样进行四轮训练后,发现模型能够学会减少频繁操作,买卖操作也更均衡。在训练集上的收益率达到最大7 000%,远超全部初始化成资金的效果。在测试集上进行验证,ev_tqh 与买入持有ev_hold 的对照效果如图8所示。

图8 初始化一半股票情况下资本总收益率对照
再对比分析两种不同初始化效果的图8 和图7,在2016年至2018年之间,ev_tqh方案的资产收益很稳定,阴影表示的标准差区间更小、也更稳定。最终的总体平均收益率为24.43%,超过全部初始化成资金的13.73%。
在观察到ev_tq 模型的loss 值较大后,实验第4 种ev_mq 方案,采用单个动作操作计算回报,实现SGYM直接计算Q值、取消目标网络的策略,使用logcosh做损失函数,减少异常样本的影响。
4.4 性能分析
最终针对四种实验测试方案:ev_hold、ev_tq、ev_tqh和ev_mq,统计分析总收益率趋势capital rate、最大回撤率withdraw rate 指标,结果如图9 所示。总收益率、最大回撤率两个指标都是ev_tqh效果最好,而ev_mq的效果不佳,还需要研究更好的回报计算方法。

图9 四种方案总收益率和回撤率对照
为对比模型的泛化能力,使用2015 牛市和2018 熊市进行实验收益情况对比。发现ev_tq 的2015 年平均收益率49.60%远高于买入持有ev_hold的15.42%,2018年的平均收益率-30.27%,低于ev_hold的-18.07%。分析原因为:训练数据集TN1 为中国经济快速增长的周期,模型习得策略更适合诸如数据集RG2015 的趋势增长年份,而且数据集RB2018 离训练数据集TN1 较远,模型表现更不稳定,影响测试效果。
4.5 问题分析
本文在实验过程中发现了三个问题:
(1)使用累计收益作为回报而不是当前操作股票的回报,会使模型缺乏短期操作策略。
(2)DQN模型输出较多不能成交操作,比如不能发现资金不足和股票不足的状态。操作也比较频繁。
(3)ev_tq 方案的 loss 值远超过模型的输出Q值,波动大,状态的影响远超过单个动作的回报。而ev_mq方案只有单个动作回报,又缺失了状态价值影响。
针对上述问题,后续可进一步优化模型。随机初始化资金和股票占比,可进一步提高操作灵活性。要提高模型的泛化能力,可在随机初始化状态、更长周期数据、更多不同周期特征数据集的加工等方面开展研究。
5 结束语
本文提出的智能股票操盘手ISTG 模型采用DQN深度强化学习技术,选择中国股市的12 年有效行情数据,8年数据进行训练学习,3年数据测试模型的整体操作策略效果,1年典型周期数据进行对比。该模型可观察到股票市场大量产品的价格变化,随机操作,发现规律,形成操作策略,较好地适应这个市场环境。
ISTG 模型学习-10 至10 手的较大范围操作动作,考虑了不能成交操作和交易手续费的惩罚,使用CNN深度网络学习20 天37 个特征的滑动窗口数据,输出最大Q值动作,比绘制图片方式做输入数据的效率更高。
针对股市操作有延迟奖赏和部分状态可观测问题,利用智能代理本身的收益增长情况累计回报,学习较长期的有效策略。在三年较长测试数据集上收益率实现了超越买入持有模型。
后续研究将逐步增加深度强化学习的最新技术,不断增强模型学习策略能力。寻找高层抽象逻辑记忆和控制住智能代理的方法。
猜你喜欢
小学生作文(低年级适用)(2019年5期)2019-07-26
小学生作文(低年级适用)(2018年3期)2018-04-17
读友·少年文学(清雅版)(2018年12期)2018-04-04
债券(2016年11期)2017-01-12
债券(2016年11期)2017-01-12
债券(2016年10期)2016-11-28
债券(2016年10期)2016-11-28
山东青年(2016年3期)2016-02-28
少儿科学周刊·少年版(2015年4期)2015-07-07
