
基于文本化简的实体属性抽取方法
2020-11-10 07:10王朝坤王沐贤
计算机工程与应用 2020年21期
吴 呈,王朝坤,王沐贤
1.清华大学 软件学院,北京 100084
2.哈尔滨工业大学 计算机学院,哈尔滨 150001
1 引言
随着信息技术的发展,电子数据日益增多。为了更好地组织和维护信息,Google 在2012 年提出知识图谱的概念。知识图谱是知识库的一种组织形式,具有很强的数据描述能力,尤其是在描述现实世界中的实体及实体间的关系上。
基于非结构化文本构建知识图谱,需要从文本中抽取实体、实体属性以及实体关系。目前,实体[1-2]和实体关系[3-6]抽取的研究工作已有很多,但实体属性抽取则相对较少。虽然一些实体属性可以以实体关系的形式体现(如出生地属性可以表示为人物实体和地点实体间的关系),然而很多属性是对实体的直接描述,不宜将对应的属性值视为实体(如人物的职位属性和年龄属性),因此需要专门研究针对实体属性的抽取方法。
开放信息抽取[7]旨在基于文本的语法和语义信息,根据一定规则从开放领域文本中抽取关系三元组。本文尝试采用类似想法进行实体属性抽取。不同之处在于,在抽取属性时,不仅关注文本中的动词,还考虑与实体相关的形容词,这使得属性的抽取规则更复杂。而且由于文本中长难句的存在和文本表述的多样性,适用于某一场景的规则可能在另一种场景下并不适用。为了解决这个问题,本文引入文本化简作为实体属性抽取的预处理过程:对于待抽取信息的文本,先使用一个针对文本化简设计的神经网络将其转化为一系列的简单句,再用简洁的规则从简单句中抽取实体的属性信息。
本文的主要贡献包括:
(1)针对实体属性抽取问题提出先化简后抽取的策略,并设计和实现了一个新的基于递归神经网络的编码器-解码器文本化简模型。模型采用常用词汇表、词性标注和化简评分函数的优化策略。
(2)针对化简后的文本设计了信息元组抽取算法和实体属性抽取算法。这两个算法以简洁的规则从文本中抽取信息。
(3)设计实验对所提文本化简方法和信息抽取方法进行评估。实验结果表明先化简再抽取的流程能够有效提升实体属性的抽取效果。
2 相关工作
2.1 开放信息抽取
开放信息抽取(Open Information Extraction,Open IE)是一种面向开放领域的信息抽取方式。与传统信息抽取方法不同,Open IE 无需预先指定词典,仅利用文本的语法和语义信息,即可从不同领域的大量语料中抽取关系三元组[7]。
经典的Open IE系统大多是围绕英文设计的,包括TextRunner[8]、WOE[9]、Reverb[10]、DepIE[11]、OLLIE[12]、ClauseIE[13]等。因为中英文语言模型存在差异,所以上述系统均无法直接用于中文信息抽取。
目前存在少量专门针对中文的Open IE 系统[14-15],然而这些系统所用方法适用范围有限,在长难句和复杂句上的效果并不理想。
2.2 文本化简
文本化简(Text Simplification,TS)旨在通过长句拆分、句法删简和释义转换等方法对复杂难懂的文本进行化简。现有主流方法将TS建模为从复杂句到简单句的单语言翻译过程,并借用机器翻译技术加以实现[16-17]。然而,由于缺乏中文TS数据集,尚未见这类方法用于中文文本化简的报道。
目前已有个别针对中文文本拆分的研究工作,包括基于逗号的中文句子分割[18]和文言文断句[19]。然而,还远远不能满足中文文本化简的需求。
2.3 序列到序列神经网络
序列到序列(sequence to sequence,seq2seq)神经网络模型用于将一种序列转化为另一种序列。最经典的seq2seq模型采用基于两个递归神经网络(RNN)的编码器-解码器架构[20]。为了克服RNN网络无法并行训练的缺点,文献[21]和[22]分别提出基于CNN和注意力机制的编码器-解码器模型。相关实验结果表明这两个模型在机器翻译上的训练开销及效果均优于RNN网络。
3 基本定义和处理流程
3.1 基本定义
定义1(信息元组)信息元组为一个三元组,形如“(s,v,o)”。其中s为主语项,表示信息描述的主体;v为谓语项,表示主体的动作或状态;o为宾语项,表示主体动作的作用对象。
信息元组分为合规和噪声两种。合规的元组需满足以下条件:
(1)元组的主语项和谓语项不能为空。
(2)元组的每一项(若存在)需是短语,不能为句子。
(3)元组每一项(若存在)的描述必须明确,不能含有指示代词,也不能缺乏限定词。
不满足合规元组条件的信息元组即为噪声元组。
合规元组举例:“(秋田美术馆,位于,日本秋田县)”“(门德里西奥建筑师学院,于1996年在瑞士成立,)”。
噪声元组举例:①“(首都,是,罗马)”不合规,因为主语项不明确,缺乏限定词;②“(,威廉·安德斯于1963年被选中,)”不合规,其主语项为空,且谓语项不为短语。
定义2(实体属性)实体E的属性记为A(E)=(As(E),Ad(E))。其中,As(E)为E的表征属性集合,即实体特征描述词的集合;Ad(E) 为E的键值属性集合。键值属性形如“k→V”,k表示属性的类别,V为一个集合,表示实体在类别k下的属性值集合。
如信息元组主语“小学教师张三”中的“小学教师”即为“张三”的表征属性。信息元组“(张三,1980年出生于,北京)”中,关于实体“张三”可以抽出“出生于”→“{1998年”,“北京”}的键值属性。再如信息元组“(张三的国籍,是,中国)”中,可以抽出“张三”的键值属性:“国籍”→ “{中国”}。
3.2 处理流程
基于文本化简的实体和实体属性抽取的处理流程如图1所示。对于一段输入的文本,先进行文本化简转化为一系列的简单句,再进行信息元组抽取和实体及实体属性抽取,得到一系列的实体及对应的表征属性集合与键值属性集合。

图1 处理流程
在图1中,文本化简和信息抽取是决定实体及属性抽取效果的关键模块。下面两章分别阐述针对文本化简模块和信息抽取模块的具体设计。
4 文本化简
本文将文本化简视为一个序列到序列的转换过程,并使用一个基于RNN 的编码器-解码器模型来实现。此外,针对文本化简任务的特点,本文尝试对该模型进行不同层面的改进。
4.1 基本模型
基于RNN编码器-解码器(seq2seq-RNN)模型[20],本文给出的文本化简基本模型如图2所示(相关符号说明见表1)。该模型主要包括编码器、解码器和预测器三个部分。
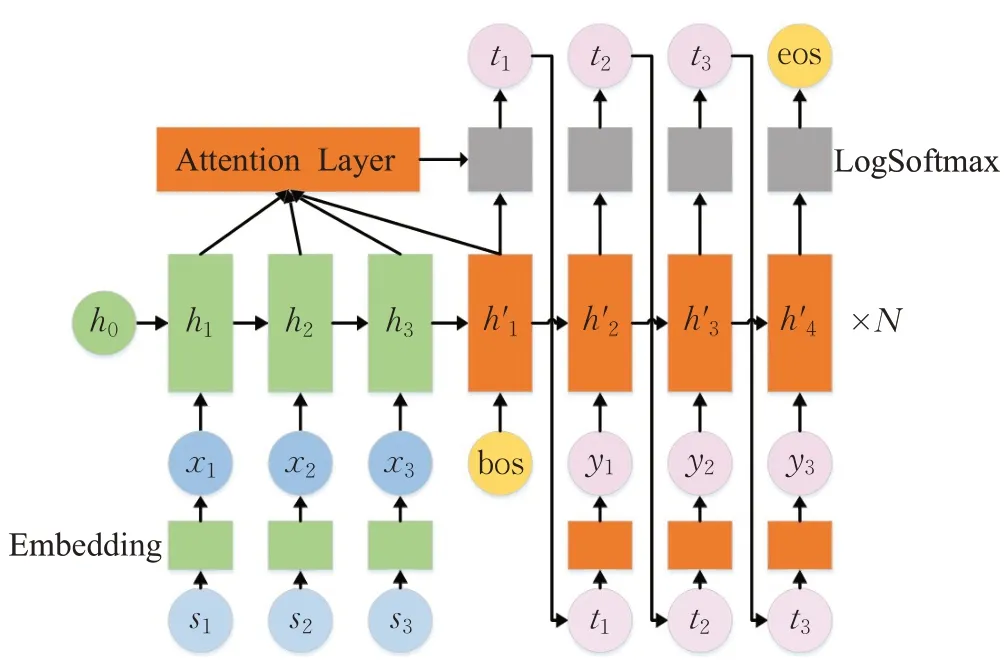
图2 基本模型

表1 图2相关符号说明
(1)编码器。编码器对输入的词序列{x1,x2,…,xn}进行编码。首先,构造词汇表对训练集和测试集中的词进行编号。为了限制词汇表的规模,出现的词按词频降序排序后保留前Nv个,余下的统一编为特定序号,表示未知词。每个词有对应的序号后,通过Embedding 层(词向量矩阵)获取对应的词向量。然后,将词序列对应的词向量序列依次输给递归神经网络(双层LSTM 网络),获取对应的输出和隐藏状态。
(2)解码器。解码器由LSTM网络和注意力机制层组成。解码器中的LSTM 网络与编码器中的基本类似。不同的是,解码器中LSTM网络的第k步输入为当前目标词的词向量与解码器第k-1 步输出,连接后的向量(k为1 时与编码器的输出连接)。注意力机制层使用的是全局注意力机制[23]。
(3)预测器。预测器包括全连接层和LogSoftmax层。对解码器的每一步输出,预测器输出词汇表中每个词作为输出序列下一个词的对数概率。
训练时,输入序列经编码器编码后,由解码器进行解码,再通过预测器计算对数概率,根据其与目标序列的 NLL Loss(Negative Log Likelihood Loss[24])值,对模型进行反馈调节。
化简时,输入序列由编码器编码后(h3),与句子起始符号(
此外,由于限定了词汇量的大小,一些词语会被识别为未知词(unk)。于是,用输出unk 时注意力最大的输入词替换unk,得到最后的输出词序列。
为使seq2seq-RNN 进一步捕获文本化简中的句法转换,第4.2、4.3、4.4 节分别引入常用词汇表、词性标注和化简评分函数。
4.2 预训练词向量和常用词汇表
预训练词向量能够有效提升模型的学习效果,因此本文在基本模型的基础上引入词向量模型。
为缓解特殊词过拟合的现象,本文考虑从给定语料中抽取前N个词形成常用词汇表,并用于不同数据集的文本化简。该语料包含100 万个句子,词汇量为932 597。对该语料中的词按词频降序排序,得到的不同词汇表规模及在中文WikiEdit 数据集(详见6.1.1 节)的覆盖率如表2所示。其中,选择前50 000个词时即可达到90%以上的覆盖率。于是,本文选这50 000个词作为常用词汇表。

表2 常用词汇表的覆盖率
使用常用词汇表后,特殊词均被映射为unk。因此,seq2seq-RNN主要学习常用词间的映射关系,缓解了特殊词过拟合的情况。然而序列中的unk词也因此增加,且彼此间缺乏区分度,容易出现模型预测输出一直为unk的情况。对此,本文提出如下解决方法:
(1)合并输入词序列中相邻的unk 词,确保序列中无连续的unk词,防止出现unk预测unk的情况。
(2)引入位置编码,使合并后的序列中不同的unk词有区分度。编码方式为词向量与正弦函数及余弦函数相乘[21]。
4.3 词性标注的引入
为进一步捕获语法转换信息,本节将词性标注引入到模型中。词性标注(Part-Of-Speech tagging,POS tagging)指识别序列中词语的词性,并进行编码标注,如“a(形容词)”“n(名词)”“v(动词)”“vn(动名词)”等。中文文本的词性可以通过pyhanlp 工具(https://github.com/hankcs/pyhanlp)获得。
引入词性标注后的seq2seq-RNN 模型及相关符号分别见图3 和表3。首先,对词性序列进行嵌入来获得对应的词性向量,将其与词向量连接后作为编码器和解码器的输入,以使LSTM 网络能够捕获词性信息。然后,修改模型的预测器,使用两个不同的LogSoftmax层分别用于输出不同词作为下一个输出的对数概率,及该词为不同词性的概率(ti和qi分别表示概率最大的词及对应的词性)。最后,使用NLL Loss[24]将词性的预测差异反馈到网络中。

图3 引入词性标注的seq2seq-RNN模型

表3 图3相关符号说明
针对化简阶段,本文提出词性替换机制,即在获取预测词及对应的词性时,若该词在输入序列中出现,则用输入序列中对应的词性替换预测的词性。通过这种自引导方式进行化简,可在BLEU 指标上获得1.5 的提升(见6.4节)。
4.4 化简评分函数
为进一步优化文本化简效果,本节提出化简评分函数。该函数能对4.3节中seq2seq-RNN模型预测出的词性序列的简化程度进行打分,并将复杂的序列以loss的形式反馈给化简网络,以加速化简网络的收敛过程,使模型倾向于输出更简化的句子。
化简评分函数采用一个二分类神经网络进行实现。该网络接受一个词性序列,输出其为简单句和复杂句的概率。本文将序列为复杂句的概率作为简化程度的评分,分值越高,句子越复杂,对化简网络产生的loss越大。
分类网络的结构如图4 所示(相关符号说明见表4)。输入的词性序列经过embedding 层后转换成对应的词性向量,再依次输入到一个单层LSTM 中进行编码。编码后的向量经过两个全连接层后,输出一个长度为2 的向量。该向量经sigmoid 函数激活后得到输入序列为简单句或复杂句的概率。最后,根据BCELoss(Binary Cross-Entropy Loss,二分类交叉熵损失函数)用随机梯度下降(SGD)对网络进行训练。

图4 化简评分函数的网络模型

表4 图4相关符号说明
化简评分函数的二分类网络是独立预先训练的,且训练好的分类器在不同的数据集之间可以复用。实验结果表明,化简评分函数能正确找出部分复杂序列,并反馈给化简网络(见6.3节和6.4节)。
5 信息抽取
5.1 信息元组抽取
经典的开放信息抽取系统是基于语法和语义规则的。由于抽取的效果依赖于规则的完备性,这些系统往往具有庞大的规则库。本节给出一个规则简洁且有效的针对化简文本的信息抽取算法。
算法1信息关系抽取
Input:待抽取的信息元组的句子sentence
Output:信息元组列表tuples
1.tuples=[]
2.dep_zh=pyhanlp.parseDependency(sentence)
3.verb_list=[dep_zh.核心词]
4.i=0
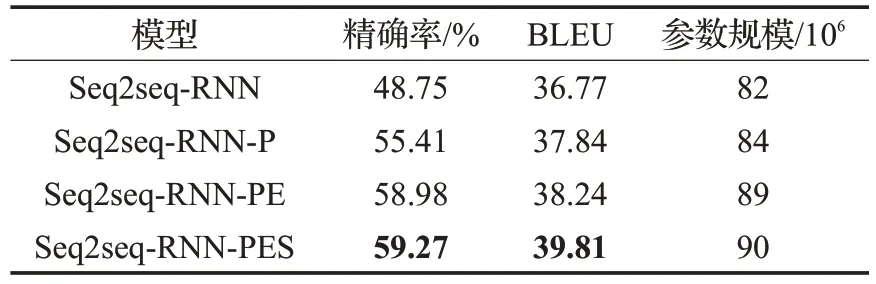
5.while i 6.verb_list.extend(verb_list[i].并列关系词列表) 7.i+=1 8.for v in verb_list://寻找主谓宾结构 9.tuples.append((v.主语,v,v.宾语)) 10.for t in tuples://处理共同主语 11.if t.主语为空and t有父节点: 12.t.主语=t.父节点.主语 13.return tuples 如算法1所示,信息抽取算法的步骤为: (1)使用pyhanlp对文本进行依存关系分析(第2行)。 (2)找到依存关系的核心词(第3 行),并递归查找所有与核心词并列的词,构成谓语列表(第4~7行)。 (3)对谓语列表中的每一个谓语,根据依存关系寻找其主语和宾语(若存在),构成信息元组(第8~9行)。 (4)对于没有主语的信息元组t,寻找与其谓语并列且存在主语的父级信息元组tf(由直接并列到间接并列递归寻找父级元组)。若tf存在,则将t的主语设为tf的主语(第10~12行);否则不做处理。 (5)结束抽取过程,返回抽取结果(第13行)。 上述算法抽取文本中的主谓宾结构,且处理了并列谓语的情形,适用于绝大多数文本的信息元组抽取。算法时间复杂度为O(ns),其中ns为句子长度。需要注意,虽然该算法存在抽取信息粒度较大,无法处理复杂句式的情况,但是考虑到本文信息抽取针对的是化简后的文本,因此其足以满足抽取需要。 实体属性是基于信息元组抽取的。在抽取属性前,本文使用pyltp(语言技术平台的python接口,由哈工大社会计算与信息检索研究中心研发)中的命名实体识别工具进行实体抽取。Pyltp 能够识别文本中的人物实体、地点实体及组织实体。本文用pyltp 从信息元组的主语中抽取人物实体(地点和组织实体类似,本文只关注人物实体),将人物实体及对应的信息元组作为实体属性抽取算法的输入。 算法2实体属性抽取 Input:实体e,信息元组(s,v,o) Output:实体e的表征属性集合args与键值属性集合kwargs 1.args={}//即As(e) 2.kwargs={} //即Ad(e) 3.dep_s=pyhanlp.parseDependency(s) 4.if dep_s.核心词==e: 5.args.extend(e.定语) //定语为表征属性 6.dep_v=pyhanlp.parseDependency(v) 7.// 谓语与其状语和宾语形成键值属性 8.kwargs[dep_v.核心词].extend(dep_v.核心词.状语列表) 9.kwargs[dep_v.核心词].append(o) 10.else if e 为dep_s.核心词k的形容词: 11.// 主语核心词与谓语宾语形成键值属性 12.if v为“是”或“为”等:kwargs[k].append(o) 13.else:kwargs[k].append(v+o) 14.return args,kwargs 如算法2所示,实体属性抽取算法的关键步骤为: (1)用pyhanlp 对信息元组的主语进行依存关系分析(第3行)。若输入实体为核心词,则跳转到步骤2(第4~9行);若输入实体为核心词的形容词,则跳转到步骤4(第10~13行);否则结束抽取,返回空表征属性集合和空键值属性集合。 (2)检查实体是否有定语。若有,则将其加入实体的表征属性集合中(第5行)。然后跳转到步骤3。 (3)对信息元组的谓语进行依存关系分析(第6行)。将核心词作为键值属性的键,将核心词的状语(若存在)加入该键对应的值的集合(第8行)。若信息元组的宾语存在,则将宾语也加入该键对应的值的集合(第9行)。结束抽取过程,返回对应的表征属性集合和键值属性集合。 (4)将信息元组主语的核心词作为实体键值关系中的键。若信息元组的谓语不为简单解释词(如“是”、“为”等),则将信息元组的谓语和宾语连接后加入该键的值集合(第12 行);否则将信息元组的宾语作为值加入该键的值集合(第13 行)。结束抽取过程,返回对应的表征属性结合和键值属性集合。 上述算法的时间复杂度为O(nt),其中nt为信息元组主语和谓语的长度之和。 以上是从单个信息元组抽取实体及属性的方法。针对一段文本(通常可抽出多个信息元组)抽取时,需要将所有信息元组的实体及对应的属性进行集合的“并”操作,以获得所有的实体及属性。 实践中,由于文本表述的多样性,实体对应的形容词与动词未必是实体的属性,需进行筛选或限定。如提取实体的出生地时,仅关注“出生”和“诞生”之类的动词。 6.1.1 数据集 鉴于目前尚无中文文本化简数据集,本文采用翻译的方法进行构造。然而,现有英文文本化简数据集(PWKP[25]、SWKP[26]、Newsela[27])侧重于通过句法删减和用词简化来提高句子的可读性和易读性,因此不宜用于信息抽取。考虑到信息抽取需尽可能多地保留句子中的有用信息,不能因化简而丢失信息。于是,本文选择两个英文文本拆分的数据集作为原始数据集,利用百度翻译的接口翻译后获得中文WikiEdit 数据集和中文SPRP数据集。 (1)中文WikiEdit 数据集。该数据集由Google 的WikiSplit 数据集[28]翻译而来。原数据集根据维基百科公开的编辑历史记录自动构建形成。数据集中存在一些固有噪声。 (2)中文SPRP数据集。该数据集由“Split and Rephrase”[29]论文中使用的基准(benchmark)数据集翻译而来。原数据集从WebNLG 挑战(网页自然语言生成挑战)的数据中提取形成,是一个较为理想的文本化简数据集。然而,该数据集的规模较小,复杂句只有5 546句(一个复杂句对应多个简单句),且涉及的词汇量只有4 107个。 两个数据集的统计信息如表5 所示。其中“复杂句”表示不同的复杂句的数量。 表5 数据集的统计信息 103 6.1.2 评估指标 针对文本化简,实验使用精确率指标和BLEU指标进行评估。其中,精确率指化简句子中正确的词语(即在目标句子中出现的词语)占化简句子中所有词语的百分比。精确率可以从用词层面衡量文本化简的效果,但无法评估化简句子在句子长度、词语顺序关系和用词完整性上的效果。BLEU[30]是IBM 于2002 年提出的机器翻译评估指标,经过多次改良升级后,其数值的高低能较为准确地反映人类对翻译效果评估的好坏。BLEU对序列到序列转换过程中的用词完整性,词语顺序及句子长度等进行了综合评估,能够作为良好的文本化简评估指标。 针对信息抽取,采用人工评估的方式对信息元组抽取的数量及合规性进行衡量。方法如下: (1)选定测试句子,对原始句子和化简句子分别进行信息元组抽取。 (2)对所抽信息元组进行人工评估,统计合规且表达意思不脱离原句的信息元组的数量。 (3)计算抽取的精确率,召回率和F1 值。 本节对不同神经机器翻译(NMT)模型在文本化简上的效果进行对比。选用模型如下: (1)Seq2seq-RNN:seq2seq-RNN基本模型(见第4.1节)。 (2)Seq2seq-CNN:Facebook 于2017 年提出的基于CNN的编码器-解码器翻译模型[21]。 (3)Seq2seq-ATTN:Google于2017年提出的基于注意力机制的Transformer模型[22]。 具体实验在中文WikiEdit数据集上进行,结果如表6所示。得益于递归神经网络对序列长期依赖的捕获能力,seq2seq-RNN 模型更好地捕捉了化简中的句法变换,在两个文本化简指标上均优于其他两个模型,化简效果最好。同时,该模型参数规模较小,训练时间也较短。这表明Seq2seq-RNN是一个良好的文本化简模型。 表6 NMT模型在文本化简上的实验结果 本节尝试对比以下不同改进层面的seq2seq-RNN模型的化简效果: (1)Seq2seq-RNN:seq2seq-RNN基本模型(见4.1节)。 (2)Seq2seq-RNN-P:seq2seq-RNN+词性标注。 (3)Seq2seq-RNN-PE:seq2seq-RNN-P+预训练词向量和简单词汇表。 (4)Seq2seq-RNN-PES:seq2seq-RNN-PE+化简评分函数。 不同模型在中文WikiEdit 数据集上进行50 次迭代训练,其中词向量维度和LSTM 的隐藏层大小均设为128。如表7所示,实验结果表明第4章中所提使用常用词汇表、引入词性标注、设计化简评分函数的文本化简改进思路能够提升模型的化简效果,且包含所有改进的seq2seq-RNN-PES效果最好。此外,虽然改进使得参数规模变大,但所有模型的训练时间均为8~10 s,这表明上述改进没有引入过多的时间开销。 表7 不同seq2seq-RNN模型的实验结果 另外,对比表6 可见,参数规模减小会导致模型效果下降。因此,条件允许时可适当增加词向量维度及LSTM隐藏层大小来提升化简效果。 本节探索化简评分函数在文本复杂度判定上的正确性。化简评分函数的二分类神经网络使用中文SPRP数据集训练。数据集中的复杂句标记为(1,0),简单句标记为(0,1),数值依次表示为复杂句和简单句的概率。 充分训练后,二分类网络在测试集上的分类结果如表8所示。数据表明,化简评分函数对简单句的召回率高达99.9%,说明化简函数基本不会将简单句误判为复杂句。此外,其能识别出51.5%的复杂句。这表示化简评分函数可以在不引入噪声的前提下,改善模型的效果。 表8 化简评分函数效果 本节对比seq2seq-RNN、seq2seq-RNN-E(seq2seq-RNN+预训练词向量)与seq2seq-RNN-P(seq2seq-RNN+词性标注)在中文SPRP数据集的化简效果,以探索不同优化策略的作用。 如表9 所示,在实验结果中,使用预训练词向量的seq2seq-RNN-E的效果最好。此外,虽然seq2seq-RNN-P的精确率低于seq2seq-RNN,但其BLEU 高于seq2seq-RNN。这说明引入词性标注后,模型对词语对应关系的学习能力减弱,对句法转换的学习能力增强。 表9 不同优化策略的实验结果 为进一步阐述不同优化策略的作用,本文对部分模块在seq2seq-CNN 和seq2seq-ATTN 上的优化效果进行评估。需注意,这两个模型的设计初衷是去除文本长期依赖,所以它们的训练单位为词语(token),而非文本(text)。在缺乏词语顺序的情况下,无法直接获取模型对整个文本(token 序列)的输出,化简评分函数难以引入。因此,本文只对其余两个优化策略在seq2seq-CNN和seq2seq-ATTN上的效果进行评估(分别记为seq2seq-CNN-PE和seq2seq-ATTN-PE)。 对比表10与表6可见,引入常用词汇表与词性标注后,seq2seq-CNN和seq2seq-ATTN的文本化简效果有所提升。这表明论文所提的优化策略是有效的。 表10 Seq2seq-CNN和seq2seq-ATTN上的实验结果 本节对信息元组抽取算法(见5.1节)在原始句子及化简句子上的抽取效果进行对比。实验在72个测试句子上进行,人工评估后的结果如表11所示。易知,文本化简能有效提升信息抽取的效果。 表11 信息抽取的实验结果 下面展示一个基于文本化简的实体属性抽取(见5.2节)例子。 原句:1955年毕业于德州大学奥斯汀分校的美国试飞员艾伦·比恩1932年3月15日出生于德克萨斯州惠勒市: 化简:艾伦·比恩的国籍是美国。飞行员艾伦·比恩出生于1932 年3 月15 日。艾伦·比恩的出生地是德克萨斯州惠勒。艾伦·比恩1955年毕业于德州大学奥斯汀分校。 信息元组:(艾伦·比恩的国籍,是,美国)、(飞行员艾伦·比恩,出生于,1932年3月15日)、(艾伦·比恩的出生地,是,德克萨斯州惠勒),(艾伦·比恩,1955 年毕业于德州大学奥斯汀分校,) 实体:艾伦·比恩 表征属性:飞行员 键值属性: 国籍:“美国” 出生于:“1932年3月15日” 出生地:“德克萨斯州惠勒” 毕业:“1995年”,“德州大学奥斯汀分校” 上述例子表明论文所提方法能够有效提取出文本中的实体及属性信息。 为了在知识图谱构建过程中更好地抽取实体及属性,本文提出一种基于文本化简在中文文本上进行实体属性抽取的方法。本文工作只是相关研究的开始。在化简文本上抽取信息时,还可以考虑跳过信息元组抽取,而基于神经网络直接抽取实体及属性的方法。这要求有对应的高质量中文数据集,且网络本身的设计也是一个挑战。5.2 实体属性抽取
6 实验
6.1 实验配置

6.2 不同文本化简模型的对比

6.3 不同seq2seq-RNN模型的对比
6.4 化简评分函数的效果

6.5 优化策略的作用


6.6 信息抽取效果

7 结束语
猜你喜欢
小学生学习指导(高年级)(2022年10期)2022-11-04
小学生必读(低年级版)(2021年10期)2022-01-18
电脑报(2021年14期)2021-06-28
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
软件学报(2019年11期)2019-12-11
家庭影院技术(2019年8期)2019-12-04
计算机与生活(2019年5期)2019-07-18
吉林大学学报(理学版)(2018年2期)2018-03-29
中学生数理化·七年级数学人教版(2017年3期)2018-01-20
