
基于知识表示学习的公共计算机课程管理研究
2020-11-06 08:53李昕,秦耕
吉林大学学报(信息科学版) 2020年5期
李 昕, 秦 耕
(吉林大学 a. 公共计算机教学与研究中心; b. 软件学院, 长春 130012)
0 引 言
如何有效抽取知识库中实体和关系的语义信息是知识理解与应用中的一个重要研究问题, 知识表示学习通过向低维向量空间投影, 实现了实体与关系语义信息的表示, 从而可以高效计算其中复杂的语义关联[1], 它是知识推理、知识库构建等下游任务的基础。依赖于三元组结构信息的知识表示学习算法很难解决具有多重属性的实体类型表示[2]。近些年来, 在自然语言处理领域, 采用神经网络模型对文本信息进行编码从而抽取出实体特征, 采用注意力机制[3]提升实体特征的表达能力成为一种选择。笔者为了构建公共计算机课程知识图谱, 提出了一种基于Transformer的文本监督表示学习模型, 该模型可利用文本信息对知识表示过程进行监督, 从而提升知识表示的质量。
笔者的工作主要包括优化实体表示过程和构建针对领域的知识图谱。在优化实体表示过程中, 首先用word2vec[4]对语料进行预训练, 得到文本的向量表示; 其次用Transformer网络[5]对实体描述文本信息进行编码, 其中带有约束性自注意力机制将对文本信息中不同表征进行约束以优化实体特征的获取; 最后将带有描述特征和结构信息的两类实体表示融合, 得到最终表示。在验证了算法能提升知识表示质量的基础上, 构建了针对公共计算机课程的知识图谱。
1 改进的Transformer网络结构
神经网络模型极大地推动了自然语言处理领域研究的发展, 但存在着梯度消失和梯度爆炸等问题。谷歌提出的Transformer网络模型采用完全的注意力机制的网络结构有效地解决了这些问题。
Transformer是一种encoder-decoder结构, encoder结构负责抽取带有描述信息的实体表示。一个transformer的encoder部分包含6个encoder组件, 每个encoder组件由输入层、multi-head attention层、全连接层构成, 结构如图1所示。

图1 Encoder组件Fig.1 The assembly of encoder
Transformer结构主要用于得到带有实体描述信息的实体表示, 实体描述文本在进行向量化(包括word embedding和position embedding)后进入多头注意力层, 层中每个头都为一个自注意力机制结构, 每个自注意力机制结构都能学习到不同表示子空间中的表征。通常每个自注意力机制权重都是相同的, 在这里通过对一些结果较弱的自注意力机制结构进行约束, 降低其权重, 再将其拼接得到融合的表征, 可表示为

(1)

(2)
其中hi为不同的自注意力机制结构,ωi为不同h的权重, Multih为融合的表征。然后将其送入前向全连接层进行处理, 整个过程重复n次得到输入序列的中间状态, 由于实体表示会受到实体描述中间状态的影响, 因此实体的文本表示由输出序列的每个单词的词向量均值构成。
2 基于Transformer的文本监督表示学习方法
笔者设计了一种基于Transformer的文本监督表示学习模型, 将带有实体描述和三元组结构的两种实体表示相结合, 形成实体的最终表示, 而关系表示在这两种情况下是共享的。TBTS模型结构如图2所示。

图2 TBTS模型架构图Fig.2 The architecture of the TBTS model
分别定义三元组结构信息的打分函数(采用TransE)和实体描述信息的打分函数。最终得到结合两者的总得分函数
Ye=Y+αYd=‖h+r-t‖L1L2+
α(‖hd+r-td‖L1L2+‖hd+r-t‖L1L2+‖h+r-td‖L1L2)
(3)
其中α为模型超参数, 最优值由训练获得。并通过不断的联合训练, 将融合了实体描述信息和结构信息的实体和关系都映射到低维度的向量空间中。得到模型的损失函数为

(4)
3 负例样本生成策略
在训练过程中, 传统的负样本生成策略采用伯努利采样[6], 这种方法容易出现如下问题: 1) 负样本实际上是一个真实存在于知识库中的真样本, 这样的负样本会导致模型的训练出现偏差, 即假负例; 2) 负样本与实际相差过大, 模型可轻易分辨出该负样本, 导致模型训练效率不佳, 即零损失。因此笔者采用了对抗生成网络[7]的思想, 利用一个生成器生成负样本, 然后用判别器对负样本进行打分并反馈给生成器, 从而促使生成器可生成更优质的负样本提高模型训练的效率。这里将每次生成的负样本中得分第2的负样本作为优质负样本送给模型训练, 以规避假负例问题。负样本生成策略如图3所示。
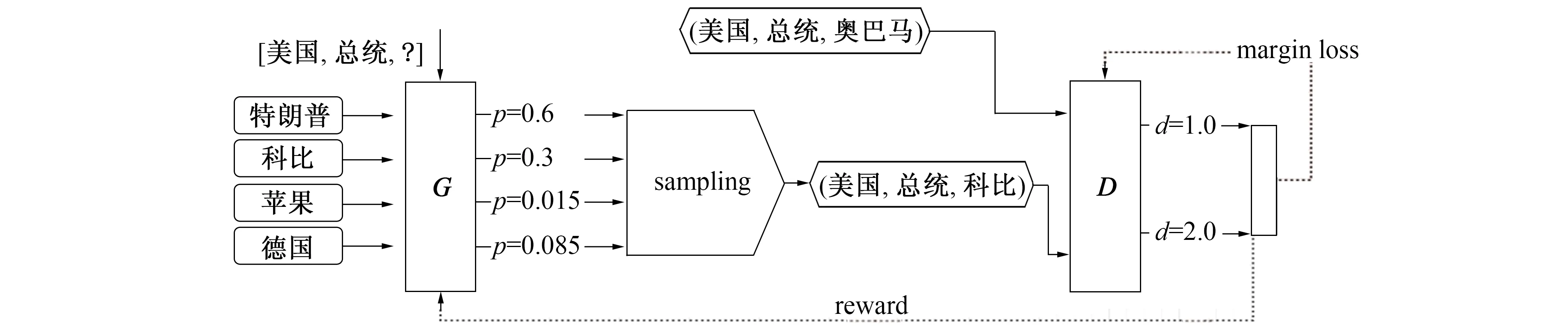
图3 对抗生成负样本模型架构Fig.3 Adversarial generation of negative sample model architecture
4 实 验
为了验证模型的有效性, 笔者在FB15K[8]和WN18[9]两个数据集上进行链接预测和三元组分类任务作为评价指标。
WN18数据集中包含40 943个实体和18种关系, 这些实体和关系组成了151 442个三元组。FB15K数据集中包含14 951种实体和1 345种关系, 这些实体和关系组成了592 213个三元组。通过数据预处理去掉一些实体描述不符合要求的数据, 剩下的数据采用10折划分方式的变形, 训练集、测试集、验证集的比例为8 ∶1 ∶1, 处理后的数据如表1所示。

表1 实验数据集
4.1 实验结果与分析
4.1.1 链接预测任务
为了验证采用三元组结构信息、融合实体描述信息、考虑对抗网络产生负样本等几种策略组合的有效性, TBTS模型做了多次对比试验, 以证明该方法对模型的提升能力。
1) TransE模型: 只考虑三元组结构信息;
2) TB模型: 实体表示来自实体描述信息、关系信息来自于三元组结构信息中的关系;
3) TBTS-模型: 实体表示来自于实体描述信息表示与三元组结构信息中的实体表示融合, 关系信息来自于三元组结构信息中的关系;
4) TBTS模型: 在TBTS-模型基础上加入了采用对抗网络思想的负样本采样策略。
在验证笔者算法策略有效性同时, 对其他一些有代表性的改进方法, 如TransD[10]、TransH[11]和 DKRL(Description-Embodied Knowledge Representation Learning)模型[12], 直接采用文献中数据结果作为对比, 结果如表2、表3所示。

表2 FB15K上的实体链接预测结果
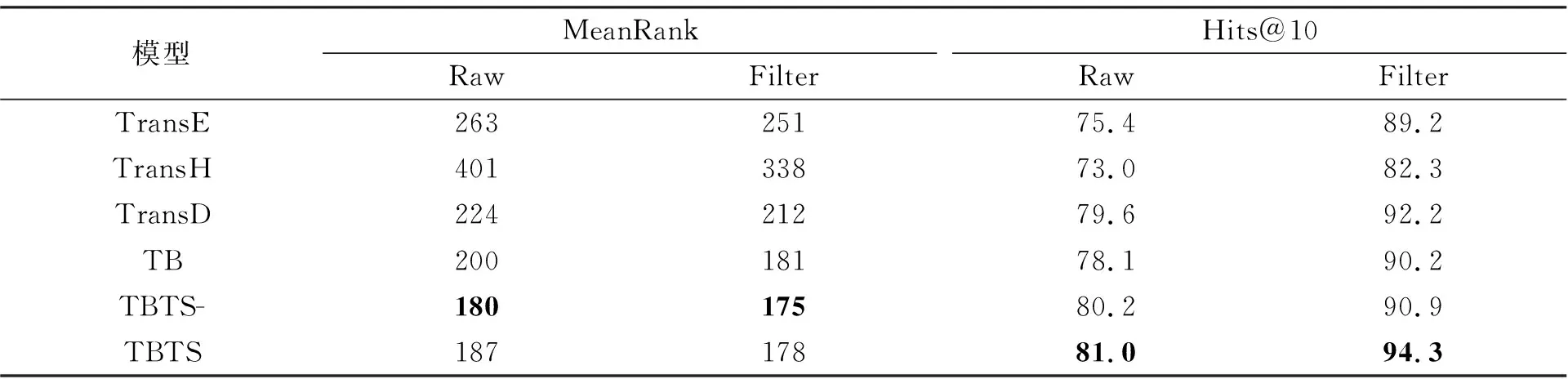
表3 WN18上的实体链接预测结果
实验结果显示, 在两个数据集上, TB、TBTS-和TBTS模型在MeanRank指标上都优于原始的TransE模型, 表明实体描述信息提升了模型的表示能力, 可见采用对抗生成网络的思想构建负样本的策略具有切实的意义, 如果能对细节进一步优化有可能获得更好的效果。在Hits@10指标上, 对有噪声干扰的数据集, 加入优质负样本训练后达到70%以上。特别是在数据样本是无噪声的WN18数据集表现尤为突出。
4.1.2 三元组分类任务
在此任务对比试验中增加一个使用了文本信息的DKRL模型, 实验结果如表4所示。

表4 FB15K和WN18上的三元组分类任务结果
由表4可知, 笔者模型都取得了更好的结果, 反映出模型提升了分类能力。但发现在子集中关系众多的FB15K数据集上添加负样本的策略效果不明显, 结合实体链接预测实验结果, 得出负样本生成策略未能在关系分类后进行针对性地调整是其造成模型学习能力降低的重要因素。
5 工程应用
知识表示学习技术对知识图谱的构建起到指导作用, 知识表示是整个知识图谱构建的第1步, 贯穿整个知识图谱的构建和应用全过程。笔者提出的TBTS算法可应用于领域知识图谱构建中, 利用知识表示学习技术习得实体和关系的分布式表示, 在构建过程中可显著提升计算效率并有效地解决数据稀疏性, 完善知识图谱的构建和应用。
公共计算机基础课程的建设是科教兴国战略的重要体现, 是培养跨世纪人才的重要保证。因此构建公共计算机基础课程领域的知识图谱有助于提升基础建设的进度, 利用知识图谱技术可更好的挖掘出学科与学科之间, 学科内部不同知识, 以及学科和教师学生等角色之间的潜在联系, 再用可视化技术表现, 便于推进公共计算机基础课程在高校中的发展。因此笔者提出的TBTS算法可以用在构建公共计算机基础课程领域的知识图谱上, 将领域中的不同实体和关系进行标记和语料收集后整合成为领域数据集并加以训练, 得到了领域中实体和关系的表示。最后利用知识图谱构建技术进行构建并用可视化技术进行知识图谱展示。具体过程如下。
1) 数据定义。考虑到计算机基础课程中对知识点会从不同角度讲解等特点, 将知识点实体类型分为概念、算法、结构, 知识点实体之间分为前序、并序、包含、相同和相关。
2) 数据获取。数据来自两个方面: 一部分来自若干课程建设项目积累的数据; 另有大部分来自网络爬取。
3) 数据预处理。对数据进行分句、分词等处理, 并完成部分文本数据的人工标注。
4) 命名实体与关系识别。采用了经典的方法与笔者提出的TBTS算法结合。
5) 知识图谱存储。采用通用的Neo4j图数据库实现知识图谱的存储与可视化展示。
公共计算机课程知识图谱的构建, 对在知识点层面明晰课程内在关系, 对课程进行有效管理、指导课程设置与进度安排, 引导学生学习具有十分重要的意义。
6 结 语
笔者提出了一种基于文本监督的知识表示学习框架, 在知识表示中引入文本信息增强实体的表示, 并采用约束性自注意力机制保证文本信息的抽取质量; 在训练中采用一种新的负样本的生成策略提升模型效果。实验结果显示, 模型在三元组分类和知识库补全方面有较好的效果, 表明模型能有效地学习到实体和关系的表示。将该模型引入到在公共计算机基础课程知识图谱构建领域中, 在实际工程应用中取得了出色的成果, 解决了实际问题。
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
