
一种计算互连融合网络体系结构
2020-11-05 04:42陆平静赖明澈王博超常俊胜
计算机工程与科学 2020年10期
陆平静,赖明澈,王博超,常俊胜
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
随着芯片设计技术的进步,单处理器/加速器的性能快速提升,其所要求的网络端端传输延迟随之降低。但实际应用中,网络传输延迟基本保持在1 μs左右,在现有技术框架下,进一步降低延迟存在较大困难。当前一般通过网络接口芯片NIC(Network Interface Chip)将处理器/结点接入到系统互连网络中,而该结构中所用PCIe接口上的延迟占传输总延迟的比例较大(约60%),如能使互连通信接口更加靠近处理器,实现网络与计算深度融合,是实现低延迟、低功耗、高密度互连的重要手段,也是下一代互连网络重要发展趋势[1,2]。计算与互连紧耦合是一种低延迟IO架构,缩短通信内存之间距离能显著降低延迟,有利于优化工作负载并降低功耗。
2015年甲骨文推出了一款面向企业级工作负载的低成本SPARC处理器,整合了SPARC M7处理器及InfiniBand接口[3,4];同年富士通公司在K超级计算机中升级了Tofu2互连技术,相对Tofu第一代技术将互连接口、交换部件和SPARC处理器集成在单个芯片中,显著改善了密度能效,并且提出Cache缓冲推送机制将延迟降低至800 ns[5]。2016年Intel下一代高速网络构架Omni-Path也宣布了计算与互连紧耦合框架,分2个阶段实现多裸片封装和单芯片集成,主要为降低延迟并改善传输效能[6,7]。
本文提出一种以片内互连形式直接将计算内核和网络接口等通过互连总线集成至计算内核的计算互连融合体系结构FCI(Fusion network architecture for Computing and Interconnection),取代现有PCIe互连接入方式,以降低通信延迟,提高集成密度,降低互连功耗。并对该融合互连结构搭建了FPGA验证平台进行性能测试,结果表明相对于传统的经由PCIe相连的互连系统,FCI结构具有更好的通信带宽与更低的通信延迟。
2 计算互连融合网络体系结构设计
FCI总体结构如图1所示,其中涉及的关键技术主要包括:(1)单周期转发特征的XBAR结构,可为组织架构提供更低传输延迟、更高通信带宽;(2)设计网络链路层LLP(Link Layer Protocol),用来实现报文的可靠传输;(3)低延迟物理加扰编码子层PCS(Physical Coding Sublayer),用于增加码率扰动,提高信号传输质量,减少信号传输延迟。
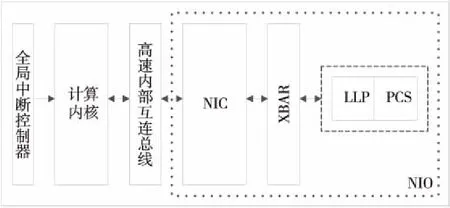
Figure 1 Structure of FCI图1 FCI结构总体
2.1 单周期转发特征的XBAR结构
内存网络对传输延迟有较高的要求,在整个内存网络中报文传输经过多个中间结点会造成传输延迟问题更加突出。瓦片组织架构中XBAR如果采取传统5级与4级流水线的微体系结构,将会带来较深的流水线,不利于控制整个内存网络的传输延迟。这主要是由于在传统路由器中,报文需要串行执行路由计算、通道仲裁、传输仲裁等操作,明显增加了网络延迟。为此,FCI采取一种具有单周期转发特征的XBAR结构,只要多个输入端口报文之间没有冲突发生便能实现单周期转发操作,适应于各类路由算法与流量负载,其硬件复杂度较低,可为瓦片组织架构提供更低传输延迟与更高通信带宽。
图2为快速单周期交换结构。输入端口接收报文之后,将根据报文输出方向和交叉开关配置来具体判断传输路径是否空闲。如果传输路径空闲,输入端口将为报文分配快速通道,旁路正常的通道开关仲裁和开关传输两级流水过程,直接将报文输出。路由器的每个输入端口都配置了一个快速通道,它的结构与虚拟通道配置相同,但仅缓存了与其他报文无冲突的报文,并发送快速仲裁信号给快速仲裁部件。快速仲裁设计复杂度低,只负责对快速通道的传输请求进行仲裁;快速传输仲裁的获胜者不需要等待,将立即通过交叉开关流出,因此整个传输过程仅需一个时钟周期。同时,由于报文的路由计算和开关传输难以在一个周期内完成,因此还设计了超前路由计算部件来对路由计算和开关传输过程进行解耦合。报文在传输之前先提前发送超前路由信号给下级路由器,等待报文到达下级路由器时,路由计算已执行完毕,报文可以直接在超前路由计算部件处查询路由计算结果后从交叉开关输出,避免了较长的路由计算耗时。
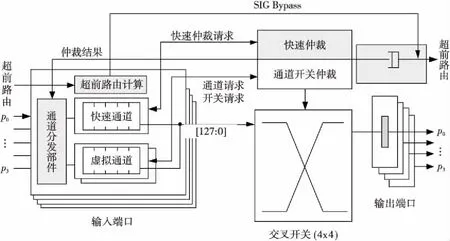
Figure 2 Fast single-period switching structure图2 快速单周期交换结构
2.2 网络链路层的设计
数据链路层用来实现报文的可靠传输,可靠性传输通过CRC(Cyclic Redundancy Check)检错和重传机制实现,与具体采用的物理通道类型和通道数量无关。数据链路层中的逻辑分为3大部分,分别是发送模块、接收模块和控制模块。LLP总体结构如图3所示。

Figure 3 Structure of LLP module图3 LLP模块总体结构
(1)LLP初始化握手机制:复位撤销以后,接收端接到对端发来的初始化帧,同时也向对端发送相同的初始化帧。初始化状态机根据初始化帧的计数和相关信号逐一跳转,最后握手成功,并输出链路正常(link_normal)状态,此时表示可以正常接发数据。在握手的过程中会通过初始化帧将本地配置的结点号(node id)和结点端口(node port)放入初始化帧发送至对端,对端将抽取node id和node port字段放入状态寄存器供查询。
(2)CRC校验:采用多种CRC校验方式,链路层报文采用CRCH、CRCL保护;数据报文除了采用端到端的CRC32外,在链路层还提供了CRCH、CRCL保护。
(3)重传机制:重传基于滑动窗口机制,发送端设置超时机制,接收端CRC出错的数据可以等待对端重新发送。
(4)序列号与ACK(ACKnowledge character)应答管理:LLP发送端报文携带发送序号,需要对端返回ACK应答,以确认发送端的数据成功发送。
(5)基于链路的BIST检查:内建自测试模块,可配置BIST使能,自动产生伪随机序列,可检查数据传输的正确性,测试与对端的连接质量。
(6)发送端和接收端报文完整性检查:报文完整性检查包括HT标识和报文长度检查,当LLP在工作中出现异常错误时,错误将会被处理,同时会记录错误现场,以便于后期调试。
(7)发送数据错误插入功能:对发送数据进行错误插入,可检测对端的CRC校验功能。在BIST测试时该功能无效。
2.3 低延迟物理加扰编码子层设计
PCS是一个具有高带宽、低延迟、高可靠和高灵活特点的物理编码子层,用于将上层数据链路层的数据,经Serdes传播到接收端并进行数据的对齐和重组。内存互连网络需要很高的传输质量并且要求较低的传输延迟,故本文在高速串口中设计了一种用于物理编码子层的加扰装置,用于增加码率扰动,提高信号传输质量,减少信号传输延迟。
本文通过一个移位寄存器接收本轮加扰数据,该数据是按物理介质分组传输的每一个分组数据,且每一个周期将移位寄存器中存储的线性序列向左移动一个分组数据的长度,根据标准加扰多项式将移位寄存器中存储的线性序列进行加扰,并通过状态机插入边界标记,能够在使用相同加扰多项式的情况下实现以一个分组数据为粒度的加扰,因此无需像IEEE802.3ae标准扰码器那样等待60位数据全部到齐,而只需等待一个分组数据即可进行加扰操作,从而解决了标准扰码器延迟太大的问题,具有加扰效率高、延迟低的特点。每个单lane编码具体划分为如图4所示,其各模块功能如表1所示。

Table 1 Module function for single lane in PCS表1 PCS单个lane结构各模块功能
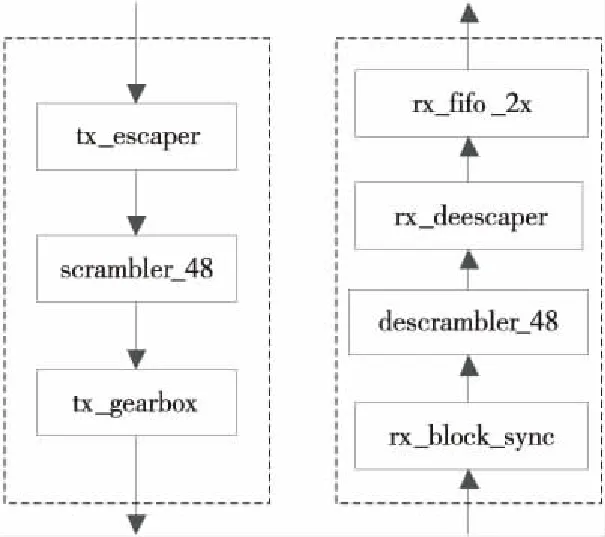
Figure 4 Structure for single lane in PCS图4 PCS单个lane的结构
PCS的每个lane以48位数据为编码单位。由于48位已经被完全占满,为避免浪费带宽又不允许使用额外的有效位,本文选择使用逃逸机制(escaping)来编码特殊的控制字符。在接收端,rx_deescaper负责完成正常数据、IDLE字符以及控制字符SYNC等变换的逆变换。tx_gearbox模块维护一个小型缓冲区,将上层给出的48位加扰结果转变为40位的Serdes接口数据。同时,该缓冲区的空满信号将被作为上层逻辑的反向刹车信号,以免上层逻辑产生超过Serdes发送能力的数据流。当上层逻辑长时间没有数据时,该模块还负责产生IDLE字符插入缓冲区。由于48位数据并不是64位数据的边界,因此为了能够在接收端正确地恢复64位数据边界,本文使用了如图5所示的编码格式:每个大型矩形为一个8位数据,每6个相邻同色的大型矩形组成一个48位数据单位。每行右侧的01或者10代表64位数据的边界。

Figure 5 Coding structure for tx_gearbox图5 tx_gearbox的编码结构
3 FPGA验证平台测试
3.1 实验设置
本文完成了计算互连融合体系结构验证平台的搭建与测试,验证平台如图6所示。采用Xilinx ZYNQ ZCU102 FPGA板搭建该原型验证系统,在Cortex-A53上建立了交叉编译环境,vivado内生成位流和硬件描述文件导入到交叉编译环境,用petalinux编译内核生成镜像,以SD卡启动模式启动Linux操作系统,网络接口部分NIO驱动在交叉编译环境内编译后加载入Linux内核。

Figure 6 FPGA prototype for the fusion network system图6 融合互连系统FPGA原型验证平台
3.2 测试情况
对于前述计算互连融合原型验证系统进行测试,其中NIC端口物理带宽为25.6 Gbps,主要对其与传统PCIe接口互连系统的双向通信端口带宽以及点点通信延迟情况进行对比,基本测试情况与结果如表2所示。
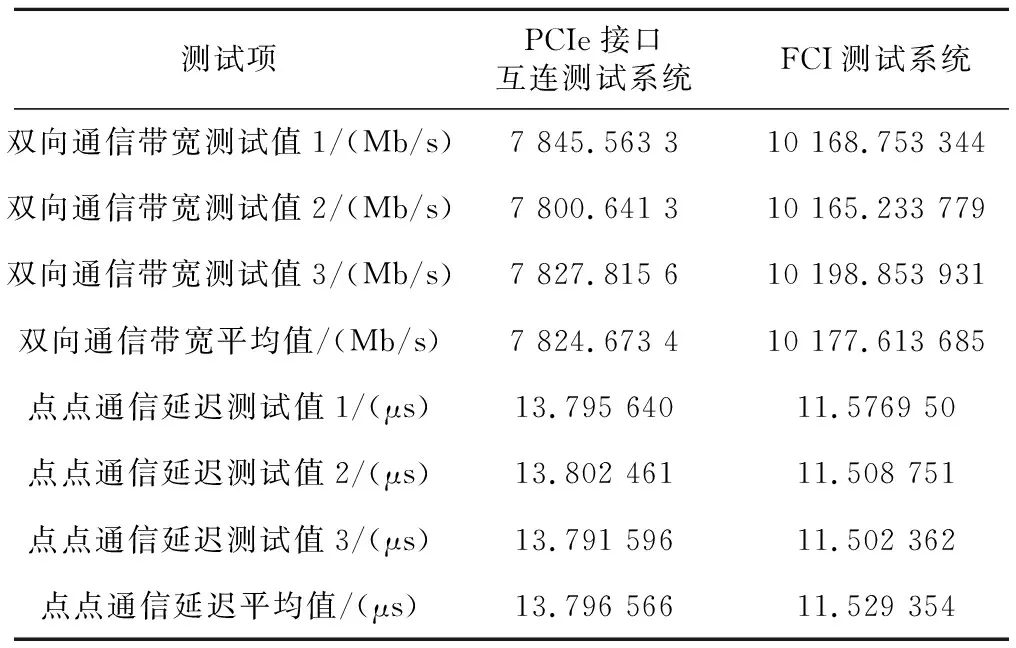
Table 2 Test results comparison of FCI with PCIe 表2 FCI与PCIe接口互连测试结果对比
测试结果显示,FCI相对于传统的经由PCIe相连的互连系统,其在通信带宽上提升了约30%,而在延迟上则降低了约16.7%,由此可以看出FCI融合体系结构具备更高带宽、更低延迟的优势。
4 结束语
本文提出一种以片内互连形式直接将计算内核和网络接口等通过互连总线集成至计算内核的计算互连融合体系结构FCI,该方式可取代现有PCIe互连接入方式,有效降低通信延迟,提高集成密度,降低互连功耗。其中,主要研究了该计算互连融合系统中具有单周期转发特征的XBAR结构,该结构适应于各类路由算法与流量负载,其硬件复杂度较低,可为瓦片组织架构提供更低传输延迟与更高通信带宽;对系统中的网络链路层进行了设计,用以实现报文的可靠传输,并在高速串口中设计了一种用于物理编码子层的加扰装置,用于增加码率扰动,提高信号传输质量,减少信号传输延迟,该结构具有加扰效率高、加扰延迟低的优点。最后,搭建了FPGA验证平台对该计算互连融合系统进行了性能测试,与PCIe接口互连系统相比,其通信带宽提升了约30%,通信延迟则降低了约16.7%,这表明了该系统具有更高的通信带宽,更低的通信延迟。
猜你喜欢
汽车电器(2022年9期)2022-11-07
宁夏师范学院学报(2021年7期)2021-09-27
现代电子技术(2021年1期)2021-01-17
铁道通信信号(2020年4期)2020-09-21
无线互联科技(2020年7期)2020-05-15
铁道通信信号(2020年9期)2020-02-06
太原学院学报(自然科学版)(2019年3期)2019-09-23
中国外汇(2019年11期)2019-08-27
太原科技大学学报(2019年3期)2019-08-05
科技与创新(2018年1期)2018-12-23
