
一种基于NVMeoF存储池的分域共享并发存储架构
2020-11-05 04:42宋振龙谢徐超
计算机工程与科学 2020年10期
李 琼,宋振龙,袁 远,谢徐超
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
高性能计算HPC(High Performance Computing)技术是信息时代世界各国竞相争夺的技术制高点,是一个国家综合国力和科技创新力的重要标志。Exascale (1 018 FLOPS)超级计算机已经成为了各国争夺的下一个战略制高点。
E级超级计算机在数百万结点上运行达数十亿个进程,如此之多的进程并发I/O、数百PB的容量和数十TB/s的带宽需求给存储系统的可扩展能力、容错能力、实用效率带来前所未有的技术挑战,存储系统将成为E级计算机系统设计的一个关键环节,I/O性能将成为制约整个系统性能的一大关键因素[1]。同时,随着HPC高性能计算、高性能大数据分析HPDA(High Performance Data Analysis)和智能应用的融合,运行在HPC计算系统上的工作负载类型更加复杂多样,大数据容量大、速度快、模态多等特性对超级计算机的存储系统提出了新的技术挑战[1]。具体表现在以下几个方面:(1) E级计算能力,单位时间内的数据处理能力增强,导致对存储系统性能的要求提高。(2) 计算精度提高,数据量增大。计算性能的不断提升使得之前无法进行的高精度计算变得可行,而高精度计算使得需要处理的数据量增多,从而增大了存储系统的压力。(3) 数据密集型应用越来越多,I/O与计算比增大。大数据时代,越来越多的大数据应用等运行在超级计算机上,大数据应用的I/O时间和计算时间占比高,I/O性能对并行应用的影响尤为突出。(4) E级系统数百万结点规模,故障率高,检查点(CheckPoint)应用需求巨大。预测E 级系统的平均无故障时间将小于1小时,CheckPoint必须限时尽快完成,对Burst I/O带宽需求将达到100~200 TB/s。
E级计算时代存储墙和I/O瓶颈问题日益突出[2,3],问题产生的主要原因在于:(1)处理器和存储器件技术发展的不均衡,在过去的十多年中,CPU性能每年增长超过了60%,而磁盘性能每年仅有4%~7%的增长。尽管有SSD等新型存储器件,但受经费限制难以在E级系统中全面取代磁盘。(2)HPC存储系统的扩展能力严重滞后于计算架构并发度的爆发式增长,同时也跟不上应用I/O模式复杂性和数据规模的增长,现有HPC架构加重了I/O存储与计算速度的失配性。(3)现有I/O软件栈不适应新型存储器件,存在效率问题,即使底层硬件裸带宽充足,应用程序可获得的实际I/O带宽依然会受限于顶层数据模型和底层物理存储方法的匹配度。
新型存储技术的发展为解决I/O瓶颈问题提供了机遇[4]。近年来,闪存作为最成熟的新型存储介质已得到广泛应用,多种新型非易失存储介质NVM(Non-Volatile Memory,也称为SCM,Sto- rage Class Memory)相继推出[5,6]。Intel 和 Micro合作研发的3D XPoint被认为是最具大规模商用潜力的 NVM 存储产品,目前基于3D XPoint的PCIe SSD-Optane产品,存储延迟小于10 μs,I/O吞吐率均在50万IOPS以上。同时,研究人员针对新型存储介质制定了新的控制器和接口标准。NVMe(Non-Volatile Memory express)协议是针对闪存、3D-XPoint等非易失型存储器NVM量身定制的新型主机控制器接口规范,通过与PCIe(Peripheral Component Interconnect express)接口的高效组合,可有效降低存储系统协议栈开销,提升存储系统I/O吞吐率,在数据中心和高性能计算机中应用广泛。受限于PCIe总线的扩展性,NVMe协议不适用于大规模的跨网远程存储访问。将NVMe协议基于RDMA(Remote Direct Memory Access)、Fibre Channel、TCP等网络扩展的NVMeoF存储网络协议应运而生。NVMeoF存储网络实现了主机与远程NVMe存储系统的通信,为构建高性能易扩展的网络存储提供了有效的技术途径。
2 Burst Buffer存储架构分析
国外关于面向E级I/O系统的研究,主要有美国的FastForward计划和Blackbob计划,欧洲的E级计算项目DEEP-ER和ExaNeST等项目,研究如何将新型NVM应用到E级系统,研究存储架构和应用层数据模型,以及覆盖整个I/O栈的应用层、中间层和存储层3个层次的研究设计[7,8]。美国FastForward计划由美国能源部DOE(Department Of Energy)支持,资助7个国家实验室研究Exscale I/O栈,提出了FFSIO(extreme-scale technology acceleration Fast Forward Storage and IO stack project)建议,对超级计算机存储系统设计具有重要影响,重点关注如何使用新存储介质及混合存储技术,重新设计接口、I/O语义、存储模型,覆盖整个I/O栈的3个主题。美国的Blackbob计划是由NVIDIA公司、国家科学基金会NSF(National Science Foundation)、能源部DOE、国防部高级研究计划署DARPA(Defense Advance Research Projects Agency)共同资助的项目,研究如何将新型NVRAM存储介质应用到E级系统,研究存储架构和应用层数据模型。欧洲的E级计算项目DEEP-ER由20多家知名大学和厂商合作,面向HPC设计了BeeGFS文件系统,采用NVM存储和NAM网络存储技术,提高并发I/O性能,解决E级计算I/O带宽扩展问题。
Burst Buffer突发缓冲存储架构成为高性能计算存储领域研究热点[9],该架构采用I/O转发和I/O缓冲区机制,在全局存储和计算结点之间构建转发层,按一定比例将一组计算结点映射到几个I/O转发结点,缓解数万甚至十万计算结点同时与后端存储服务器通信的压力,使后端全局存储层的客户端规模得以缩小,提高存储系统的扩展性。
天河二号、Oakforest-PACS、Shaheen、Titan、Trinity、Cori等一系列超级计算机系统利用闪存构建Burst Buffer,显著提高了系统Burst I/O带宽。现有2种代表性的Burst Buffer存储架构。一种为在计算结点本地的Burst Buffer架构,Burst Buffer位于各个计算结点上,其好处在于总的Burst I/O带宽随计算结点的数量线性增长。科学计算应用程序可以通过使每个进程将其数据写入其本地Burst Buffer来获得可扩展的写带宽。但是,将缓冲的数据刷新到后端并行文件系统时需要占用计算结点的计算能力,可能会对计算结点上的计算任务造成干扰。另一种为远程共享Burst Buffer存储架构,Burst Buffer部署在计算结点和后端并行文件系统之间的专用I/O结点上,数据刷新到后端并行文件系统时不会干扰计算结点上的计算任务,因此该架构实现了出色的资源隔离,不过其I/O带宽取决于网络带宽、Burst Buffer总带宽和I/O结点数等多种因素。Argonne国家实验室的Aurora超算系统具有异构Burst Buffer架构,同时包括结点本地Burst Buffer和远程共享Burst Buffer。现阶段,由于 NVM 价格和容量的限制,以及复杂的编程模式,在实际HPC系统中很少出现纯 NVM 的场景,更多的将还是NVM+SSD+HDD 的层次式混合存储架构。在SSD等NVM存储设备还相当贵的状况下,Burst Buffer与传统并行文件系统各有所长,将长期分工并存。
大数据时代,为了充分利用HPC系统的并行计算能力,许多大数据应用程序正迁移到HPC系统,如何在HPC系统上支持大数据的高时效分布式处理与存储成为重要的研究课题。HPC系统为提高计算刀片集成密度和可靠性,计算结点一般不配备本地盘,这种存储资源与计算结点的分离要求通过网络对并行文件系统进行远程访问,导致高I/O延迟。在计算结点和并行文件系统之间设置突发缓冲区,读取输入数据和读取/写入中间数据,可缩短I/O延迟。开源的Memcached等研究项目采用Burst Buffer来预取大数据或存储中间数据,应对HPC 上大数据应用程序面临的高I/O延迟问题。
3 基于NV-BSP的分域共享并发存储架构
针对E级计算和大数据处理对存储系统的需求与挑战,本文研究设计一种基于NVMeoF存储池的分域共享并发存储架构,既满足E级系统科学计算超高并发度I/O应用需求,又满足大数据分析HPDA和智能应用高时效I/O应用需求。
3.1 基于NV-BSP的分域共享并发存储架构
支持HPC和大数据处理的分域共享并发存储架构如图1所示,从数据访问特性上看,主要包含基于NVMeoF的虚拟本地存储层、基于NVMe存储池的子域共享加速层、大容量全局共享存储层3部分。设计多态存储服务结点,软件上实现高并发NVM存储池NV-BSP(Burst Storage Pool)、Burst I/O缓冲加速功能和并行存储功能,可根据系统规模或者应用的I/O特性在多态存储服务结点上进行动态配置,实现可适配多种应用模式、混合存储资源的柔性配置,以及数据的动态部署。
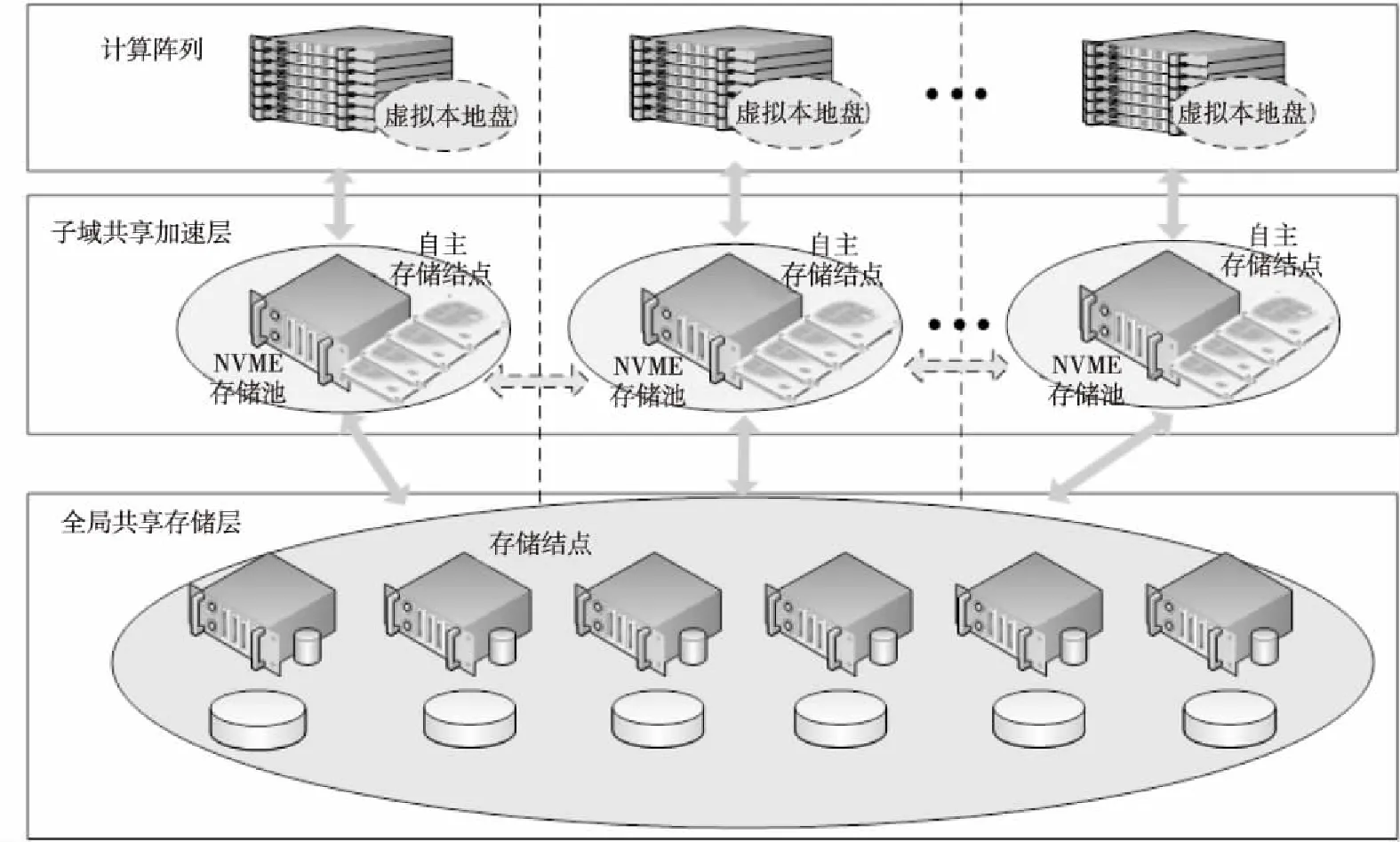
Figure 1 Regional shared and high concurrent storage architecture based on NV-BSP图1 基于NV-BSP的分域共享并发存储架构
伴随着计算任务的运行,计算任务占据的结点形成了一个逻辑分区,资源管理系统在任务调度时,可以将一个逻辑分区内的加速存储资源整合起来,形成一个面向任务的子域共享的Burst Buffer存储加速空间,通过该局部加速空间和全局存储空间之间的有机融合,可以有效支持面向特定计算任务的突发I/O缓冲加速和低延迟存储访问。
面向大数据和智能应用,可以将存储服务结点上所有NVMe SSD进行池化管理,通过基于自主高速互连网的NVMeoF网络存储技术,为计算结点提供低延迟突发缓冲设备:NVMeoF虚拟本地盘,高效支持低延迟的本地I/O访问模式,来应对远程访问全局共享并行文件系统的高I/O延迟问题,提高大数据实时处理能力。针对具有巨大输入数据量且多次执行的大数据应用程序,采用控制I/O干扰的提前预读、异步滞后写策略,重叠大数据应用程序的I/O和计算阶段,以进一步隐藏远程数据访问的高延迟。
面向科学与工程计算,NV-BSP存储池将所有NVMe SSD统一管理构成NVMe存储加速层,实现应用和传统并行文件系统之间的Burst I/O缓冲加速,支持E级系统数十万结点并发I/O,满足应用程序瞬时并发I/O操作的性能需求,减少对后端全局并行文件系统的I/O压力。另一方面,采用I/O存储结点和大量存储设备构成大容量存储池,支持高性价比、超大容量的数据存储,全局存储可灵活部署各种类型的存储系统,主要为应用程序提供足够的存储空间,为各种数据后处理提供数据共享支持。
面向不同应用模式的差异化I/O需求,这种I/O存储架构支持灵活配置存储资源,作业管理和资源调度软件可根据数据密集度动态分配存储资源,并采用针对性的I/O优化策略为CheckPoint、纯数据流、混合负载、带宽敏感型或延迟敏感型等各类I/O应用提供有效的QoS服务保障。
计算结点运行全局并行文件系统的客户端进程,在支持传统POSIX接口的同时,提供了HDF/MPI-IO接口以及针对定制化应用的API接口。采用挖掘I/O局部性的分区域I/O策略,设计轻量级用户态文件系统协议和I/O请求转发技术,利用存储服务结点处理并转发一组计算结点的I/O请求,使并行文件系统的客户端数目得以适度调控,提供可均衡扩展的快速I/O能力。
存储服务结点实现NV-BSP存储池,同时连接高速互连网和后端存储局域网,通过后端存储局域网挂接大容量存储池。本文采用层次式融合存储管理技术维护所有NV-BSP存储池的存储空间,采用一种基于非确定性DHT(Distributed Hash Tables)映射规则的数据布局与组织方法,实现了高效的数据布局和I/O调度,提供弹性可扩展的数据和元数据访问能力。采用多模式的数据同步技术,对2个层次之间的数据存储及一致性进行有效管理,构造高效、可靠、统一的融合虚拟存储空间,有效提高E级系统复杂应用条件下整体I/O性能。
存储网络传输带宽和延迟是影响并行存储系统性能的重要因素,本文针对E级计算并行存储需求,研究存储与网络融合的网络实现架构和NVMeoF网络存储通信技术,增强存储系统的横向扩展能力和柔性可配置能力,支持NV-BSP存储池和大容量存储池的可定义配置,整个存储系统的规模柔性可扩展。通过扩充NV-BSP存储池数目,可以实现系统瞬发I/O带宽的持续扩展,支持并发操作客户端数量到十万结点规模,并支持平滑扩展到E级系统规模。
本文基于天河高速互连网络实现NVMeoF网络存储协议,实现网络与存储的协同性能优化,降低远程存储访问延迟。NV-BSP存储池支持天河高速互连网络接口,可以方便地部署到天河超级计算机系统中,并通过NVMeoF存储网络技术实现计算子域与NV-BSP存储池的互连,加快计算子域与存储池的RDMA数据交换。
3.2 NV-BSP存储池软硬件设计
本文研究设计支持远程存储直通访问的NV-BSP存储池,实现面向HPC的存储互连融合网络框架,支持零拷贝的聚合、分发和预取,实现高带宽、低延迟存储互连通信与数据传输,减少I/O访问延迟,增强存储系统的横向扩展能力。BSP存储池硬件逻辑结构如图2所示,主要由RDMA网络接口部件(RNIC)、存储缓存Buffer、NVMeoF硬件加速引擎、CPU、内存、PCIe网络和NVMe SSD构成。这种存储互连融合架构支持多个Host(I/O访问发起者)和多个NV-BSP存储池的高效互连互通,在保证低延迟、高带宽等性能指标的前提下,为存储系统提供良好的扩展性。ION(I/O Node)服务结点和计算结点均可作为Host,通过网络接口部件RNIC发送NVMe访问请求,互连网络基于访问目的地址路由到相应NV-BSP的RNIC上,NVMeoF引擎解析接收到的访问请求,并转换成NVMe设备访问命令,NVMe设备基于PCIe交换网络获取访问命令,完成后续的数据访问操作,最后由RNIC将完成应答返回给Host。
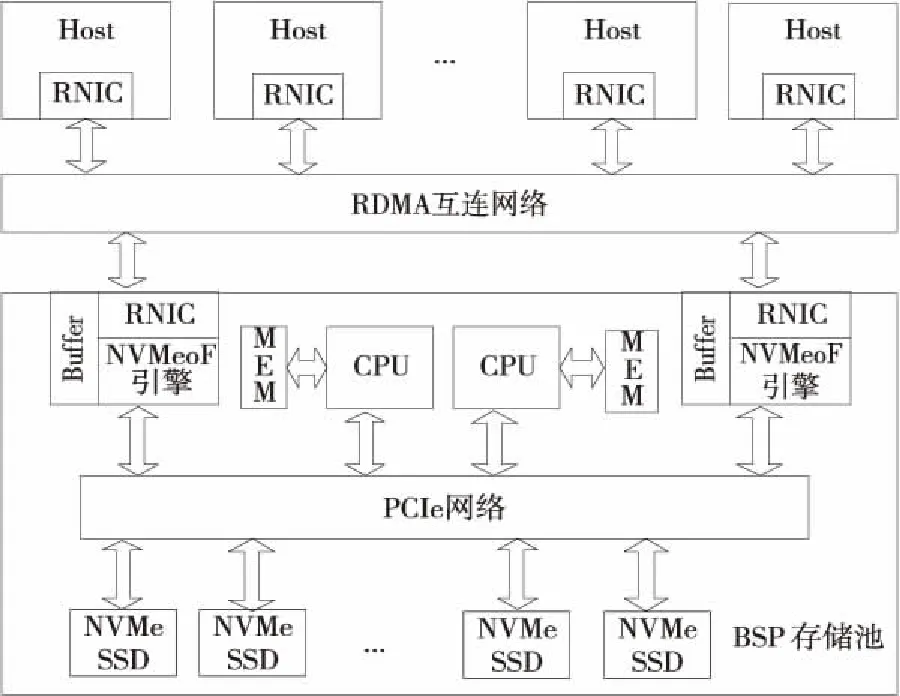
Figure 2 Hardware architecture of NV-BSP图2 NV-BSP存储池硬件逻辑结构
存储池管理软件总体架构如图3所示,主要包括I/O处理模块和存储资源管理模块2大部分,实现对NVMe SSD设备的一体化存储管理和监控。I/O处理模块包括数据读写请求处理、控制命令处理、数据重建处理、错误处理等功能,存储资源管理模块主要包括存储池管理、资源分配、数据保护策略、虚拟盘管理等功能。在提出的基于数据保护域的虚拟化存储池资源管理架构中,每个SSD被切分为多个称为Chunk的物理块,所有的SSD物理资源被池化成一个Storage Pool,池化的物理资源通过Allocator分配给Container存储容器。每个Container由多个Chunk构成,是一个基本的数据保护单元,可按需动态配置不同的数据保护级别。多个Container组成虚拟盘VDisk(Virtual Disk)。这种虚拟化存储池架构将物理资源与数据保护进行了彻底的分离,数据保护不再依赖于物理盘,实现了高效灵活的资源管理和快速数据重构。通过带权重的分配算法、基于图的读写处理模型、无锁I/O并发处理等关键技术,支持存储数据根据NVM存储介质寿命、应用I/O模式、数据可靠性合理分布,达到I/O负载均衡、性能高可扩展的目的。
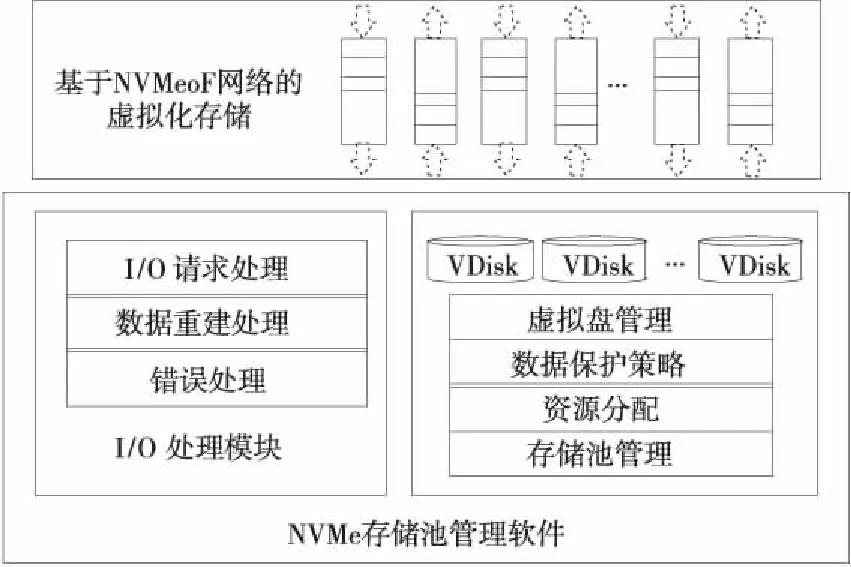
Figure 3 Software architecture of NV-BSP图3 NV-BSP存储池管理软件框架
NV-BSP存储池软件架构包含物理资源管理域、数据保护域和逻辑卷管理3个层次,通过块设备接口对外提供存储服务。针对传统管理技术存在RAID扩容、整盘数据重构、全局磨损均衡难以实现等几个方面的问题,本文提出针对闪存的底层虚拟化技术、带权重的分配算法,支持根据存储介质寿命、应用I/O模式、数据可靠性合理布局数据,达到I/O负载均衡、数据快速重建的目的;设计针对NVMe协议的无锁生产者-消费者算法、多I/O队列的无锁流控算法、基于图的读写处理模型,达到提高存储池I/O带宽和吞吐率,缩短I/O延迟的目的。
3.3 混合应用程序QoS控制策略
大数据应用程序对全局共享并行文件系统引入的大量I/O请求可能会对HPC应用程序的性能产生不利影响,为了在保证HPC应用程序QoS的同时加速大数据应用程序的性能,本文采用一种预取策略,在计算结点仍在处理上一个迭代的大数据输入的同时,获取下一个迭代的大数据输入,允许将大数据输入到计算子域共享的NV-BSP存储池,通过NVMeoF网络存储技术映射给计算结点,实现虚拟本地盘I/O模式,缩短从全局共享并行文件系统读取大数据的远程I/O延迟。但是,在HPC和大数据应用程序混合运行环境下,会在全局共享并行文件系统级别带来I/O干扰问题。
为了分析大数据应用程序的I/O操作对并发HPC应用程序I/O性能的影响,针对典型应用程序建立性能分析模型,以便指导子域共享加速层和大容量全局共享存储层间的存储层次管理和I/O流控策略,在保证HPC应用程序QoS约束的同时优化大数据应用的性能。
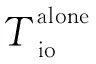
(1)

Ihpc(nBB,nthread)=
TI(nthread)×NI(nBB)×Ihpc(1,1)
(2)
其中,Ihpc(1,1) 是通过使用单个突发缓冲结点和单个线程来离线计算获得的干扰因子。
同理为大数据应用程序建立性能分析模型,给定执行预取的NV-BSP结点数(nBB)和每个结点的预取线程数(nthread)估算预取时间。类似于式(1),预取时间还受到与HPC应用竞争的持续时间和干扰因素的影响。当单独运行大数据应用程序时,对预取时间Tpref建立如下分析模型:
Tpref(nBB,nthread)=
NS(nBB)×TS(nthread)×Tpref(1,1)
(3)
其中,NS(nBB) 和TS(nthread)分别代表结点数和每个结点的线程数的可扩展性。与上述同理推算,例如NS(2)=t2/t1,t1和t2分别是采用1 个和 2个NV-BSP突发缓冲结点执行预取时的预取时间。同样,通过使用单个突发缓冲区结点和单个线程来分析获得Tpref(1,1) 预取时间。当与HPC应用程序混合运行时,对大数据应用程序的预取时间Tpref建立如下分析模型:
(4)
Ibigdata是大数据应用程序的干扰因子,定义为与HPC应用程序混合运行和不混合运行时的预取时间之比,采用类似于式(2)的离线分析方法计算Ibigdata(nBB,nthread)。
大数据应用程序的预取开销定义为不能与计算阶段重叠的预取时间:
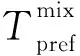
(5)
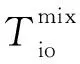

(6)
(7)
对混合应用程序进行QoS控制时,可根据式(6)和式(7)选择大数据预取延迟时间td,在满足HPC应用I/O时间期限约束的同时,尽可能降低预取开销,使Cpref值为0,重叠大数据应用程序的I/O和计算阶段,隐藏读取大数据的I/O延迟,最大程度地减少HPC与大数据应用程序之间的I/O干扰导致的性能下降。
4 性能评测
4.1 实验环境
本文基于小规模验证系统对NV-BSP存储池原型系统的I/O性能进行了评测。NV-BSP存储池原型系统配置2个Intel Xeon Gold 6128 CPU,192 GB DDR4内存,配置8块NVMe U.2接口的SSD硬盘,单盘容量1.8 TB,单盘读写带宽可分别达到2.8 GB/s和1.4 GB/s。操作系统为CentOS Linux 7.7,内核版本为4.19.46。采用FIO测试工具进行性能评估,实验中FIO生成的所有工作负载均使用Linux异步I/O(libaio)模式,并采用直接I/O模式(不进Cache)。
4.2 性能及可扩展性测试
为了评估单个NV-BSP存储池的纵向扩展能力,本文测试分析了配备的NVMe SSD盘数量对NV-BSP存储池性能的影响,测试了配备3~8个NVMe SSD的存储池中VDisk的I/O吞吐率IOPS。实验中,将FIO工作负载配置为4 KB粒度的读密集型(写30%、读70%)和写密集型(70%写、30%读)I/O模式,8个线程,每个线程队列深度为64。图4显示了具有不同NVMe SSD数量的NV-BSP中VDisk的IOPS测试结果。随着NV-BSP中配备的NVMe SSD盘数量越来越多,VDisk的I/O吞吐率IOPS增长趋势明显。具体来说,对于读密集型工作负载,当SSD的数量从3增加到6时,IOPS提高86.94%,而当SSD数量从4增加到8时,IOPS则提高97.82%。对于写密集型工作负载,SSD数量从3增加到6时,IOPS提高了87.04%,SSD数量从4增加到8时,IOPS提高了97.98%。
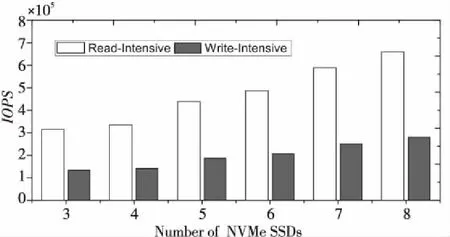
Figure 4 The influence of the number of SSDs configured by NV-BSP on IOPS图4 NV-BSP所配SSD数量对IOPS的影响
为了评估NV-BSP存储池中无锁并发I/O处理技术的效果,针对配备8个NVMe SSD的NV-BSP进行性能测试,配置不同数量的I/O处理线程对VDisk的读写请求进行并发处理,测试了块大小为4 KB的随机读写IOPS,以及块大小为128 KB的顺序读写带宽,测试结果分别如图5和图6所示。图5呈现了VDisk的随机读写性能随I/O处理线程数量递增呈线性增长,直到I/O处理线程数量增加到16,此时VDisk的4 KB随机性能达到了最大值。图6呈现了配备不同的并发I/O处理线程数量条件下VDisk的顺序读写带宽。与随机读写性能测试结果相似,NV-BSP在I/O处理线程数量递增情况下显示出良好的加速比,尤其是对于顺序读性能测试,VDisk的读带宽线性增长趋势明显,最大达到20 GB/s以上,表明NV-BSP具有良好的性能可扩展性。
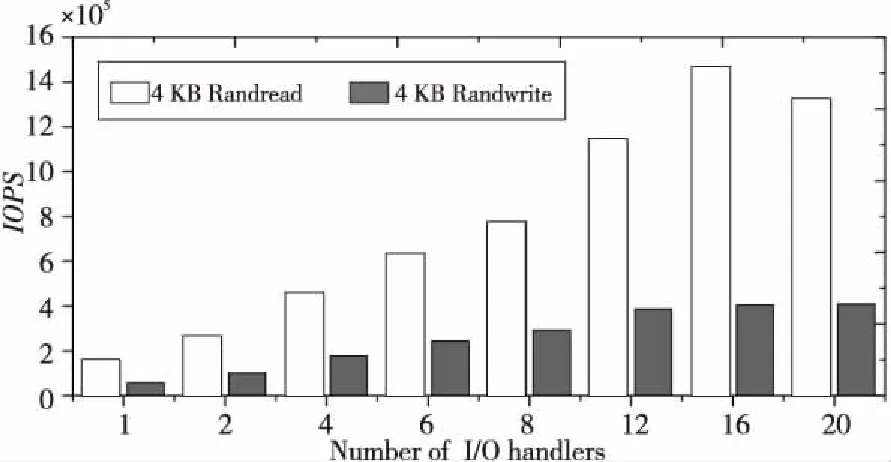
Figure 5 The influence of the number of NV-BSP concurrent I/O handlers on IOPS图5 NV-BSP并发I/O处理线程数量对IOPS的影响

Figure 6 The influence of the concurrent number of NV-BSP concurrent I/O handlers on bandwidth 图6 NV-BSP并发I/O处理线程数对I/O带宽的影响
为了评估NVMeof-GLEX网络存储延迟,针对配备了8个NVMe SSD的NV-BSP进行本地延迟和远程延迟对比测试,测试了块大小为4 KB的随机读写延迟,对比测试结果如图7所示。实验中,将FIO工作负载配置为4 KB粒度的读密集型(写30%、读70%),本地延迟和基于NVMeof-GLEX网络的远程延迟分别为124.31 μs和183.56 μs;写密集型(70%写、30%读)I/O模式下,本地延迟和基于NVMeof-GLEX网络的远程延迟分别为191.53 μs和245.56 μs。相比本地I/O访问,基于NVMeof-GLEX网络的远程存储平均读、写延迟仅增加了59.25 μs和54.03 μs。
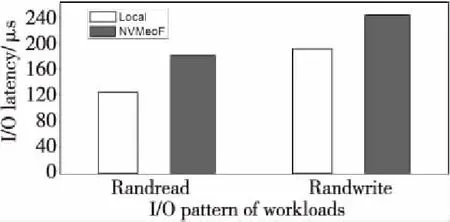
Figure 7 I/O latency comparison between local and NVMeoF图7 远程I/O延迟与本地延迟的对比测试
4.3 与MD-RAID的对比测试
本文将NV-BSP与Linux中内置的MD-RAID进行了性能对比测试。对由NV-BSP和MD-RAID创建的2个不同的VDisk进行性能评测,图8和图9分别展示了不同粒度I/O请求的平均I/O延迟和I/O带宽对比测试结果。如图8所示,来自NV-BSP的VDisk平均I/O延迟远低于MD-RAID的,随着I/O请求大小从4 KB增加到128 KB,NV-BSP的平均I/O延迟明显低于MD-RAID的平均I/O延迟。同样如图9所示,来自NV-BSP的VDisk的I/O带宽远高于MD-RAID的带宽。随着I/O请求大小从4 KB增加到128 KB,NV-BSP的带宽比MD-RAID的带宽高1.64~11.06倍。测试结果表明,与MD-RAID相比,NV-BSP的I/O延迟和带宽都具有明显优势。
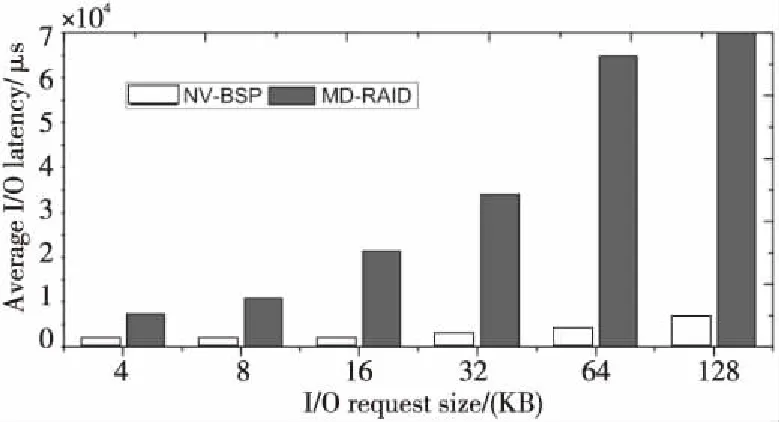
Figure 8 I/O latency comparison between NV-BSP and MD-RAID图8 NV-BSP与MD-RAID的I/O延迟对比测试
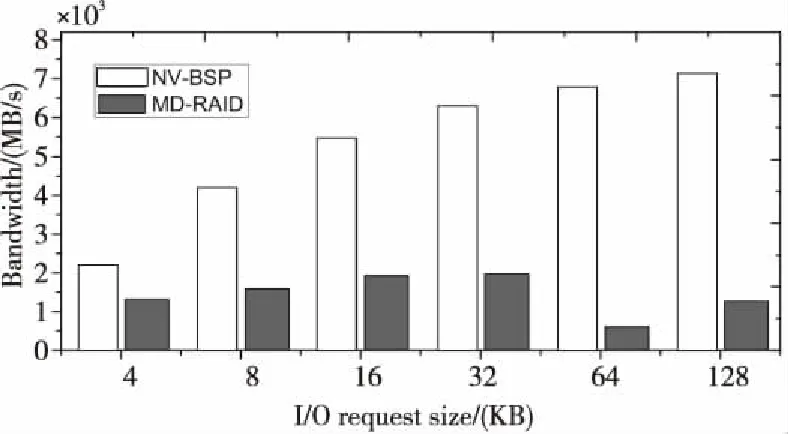
Figure 9 I/O bandwidth comparison between NV-BSP and MD-RAID图9 NV-BSP与MD-RAID的I/O带宽对比测试
5 结束语
本文提出了一种基于非易失存储介质NVM的分域共享并发存储架构,设计了一种支持NVMeoF网络存储的Burst I/O缓冲存储池NV-BSP,实现了虚拟化存储池资源管理、基于天河高速互连网的NVMeoF网络存储通信等关键技术,具有横向和纵向扩展能力,可有效支持面向特定计算任务的Burst I/O加速和低延迟远程存储访问。基于HPC和大数据应用程序混合运行性能分析模型,提出了一种混合应用程序QoS控制策略。小规模验证系统上的性能测评结果表明:NV-BSP存储池的读写性能可随并发I/O处理线程量良好扩展;与Linux 操作系统自带的MD-RAID相比,NV-BSP大幅降低了平均I/O延迟,I/O带宽比MD-RAID高1.64~11.06倍,具有明显的性能优势;相比本地I/O访问,基于NVMeof-GLEX网络的远程存储延迟仅增加了59.25 μs和54.03 μs。NV-BSP存储池支持HPC高速互连网络接口,可以方便地部署到超级计算机系统中,通过NVMeoF网络技术实现计算子域与NV-BSP存储池的互连,加快计算子域与存储池的RDMA数据交换。通过计算与存储分离,NV-BSP 在提供堪比本地存储池性能的同时,提高了系统存储资源动态调配的灵活性和系统可靠性。未来将进一步优化实现多个NV-BSP存储池的动态分配机制,高效支持计算子域内共享存储和高并发I/O。进一步研究HPC和大数据应用混合运行环境下的Qos控制策略,为CheckPoint、纯数据流、混合负载、带宽敏感型或延迟敏感型等各类I/O应用提供有效的QoS服务保障。
猜你喜欢
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
山西电子技术(2021年3期)2021-06-28
哈尔滨轴承(2020年2期)2020-11-06
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
发明与创新·大科技(2019年12期)2019-03-17
中国教育信息化(2015年12期)2015-08-24
客车技术与研究(2014年5期)2014-02-28
计算机教育(2006年4期)2006-04-19
