
面向天河互连网络的可扩展通信框架实现技术
2020-11-05 04:42周恩强
计算机工程与科学 2020年10期
谢 旻,张 伟,周恩强,董 勇
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
互连网络是高性能计算机系统的重要组成部分,其性能指标对并行应用的运行效率有重要影响。并行应用的开发和运行依赖各种并行编程模型,例如消息传递并行编程模型MPI(Message Passing Interface)和PGAS(Partitioned Global Address Space)等。通常每个互连网络平台上都会提供自定义的通信编程接口,并直接基于这些接口实现并行编程模型,以充分发挥互连网络性能。但是,这种开发模式需要花费很多时间和人力成本,造成部分编程模型不能在新型互连网络平台上得到及时和高效的支持,而且在不同互连平台上的编程模型移植需要进行一些软件栈代码的重写,不能很好地实现代码重用。在当前互连网络和体系结构技术快速发展的条件下,这种开发模式面临很多的挑战。
因此,高性能计算社区协同发展了几个开源的通信框架研究项目,其目标是定义满足主流并行编程模型需求的标准化统一通信编程接口,同时又便于高效地在各种互连网络平台上实现,以便更好地在当今和未来互连网络上支持各种编程模型。主要的通信框架包括UCX(Unified Communication X)[1]、OFI(Open Fabrics Interfaces)[2]、CCI(Common Communication Interface)[3]等。UCX和OFI已被移植实现到很多高性能互连网络上,例如InfiniBand、BlueGene/Q、Cray Gemini/Aries等。很多并行编程模型的实现系统,例如MPI的MPICH[4]和Open MPI[5]等,也有了基于UCX和OFI的实现,积累了可直接移植的软件资源。另外,很多高性能并行计算机系统中也开始运行一些大数据或人工智能计算框架,这些计算框架通常利用TCP/IP协议的socket接口实现分布式任务之间的通信,以便提高可移植性,但这带来了通信性能损失,因此一些计算框架也开始尝试基于开源通信框架来提高性能。
天河互连网络[6,7]是国防科技大学自主研制的高性能互连网络系统,在“天河二号”等高性能并行计算机系统中得到了应用,具有同期国际先进水平的网络通信性能。目前通过天河互连网络的自定义通信接口,实现了对几个并行编程模型的高效支持。而本文的研究问题是:在天河互连网络上是否也能移植实现主流开源通信框架,并提供高性能的数据传输服务,支持多种编程模型,以及并行应用的可扩展运行?由于天河互连网络研制的技术积累也是未来E级并行计算机系统互连网络的基础,研究开源通信框架在天河互连网络上的实现技术,以及在其之上运行各种编程模型所获得的测试数据,对扩展天河互连网络上的应用类型,指导未来E级互连网络和通信软件系统的设计,都具有重要的研究意义。
本文主要结构如下所示:第2节对开源通信框架UCX和OFI的系统结构,以及通信接口的类型和功能进行了对比说明;第3节简要介绍了天河互连网络的通信机制和自定义通信接口;第4节详细描述了利用天河互连网络自定义通信接口,为实现通信框架的主要通信操作接口而设计与实现的多通道数据传输协议;第5节是UCX和OFI的对象模型在天河互连网络上的实现细节;第6节是天河互连网络上的通信框架性能测试结果。第7节总结了全文工作。
2 开源通信框架
UCX和OFI开源通信框架均基于Internet协作开发模式,其系统结构和接口功能的设计,都是以先前一些通信接口研究项目的成果为基础,充分考虑了各种并行编程模型的需求,以及面向当前和未来各种互连网络平台实现的可移植性和扩展性。
2.1 UCX通信框架
UCX的主要设计目标包括可移植性,面向未来互连和体系结构的支持能力,以及产品级质量的实现代码等。UCX采用如图1所示的层次式系统结构,主要包括3个组成部分,UCP(UC-Protocol)、UCT(UC-Transports)和UCS(UC-Services)层。每个层次都定义了一组编程接口API,并且是以单独的库形式提供给用户使用,用户可以根据自己的需求,灵活选择不同层次的UCX接口来完成通信功能。

Figure 1 Architecture of UCX图1 UCX系统结构
UCS层提供可移植的系统环境访问控制接口,以及一些公共数据结构和操作接口等,用于支持UCT和UCP层的实现。UCT作为传输层,面向互连网络平台的移植需求,定义了一组适用于各种互连网络特性的基本通信接口和内存管理操作,目标是通过对互连接口硬件资源的直接访问操作,减少软件层开销。UCT的通信操作主要包括AM(Active Message)和RMA(Remote Memory Access)2种,并且在AM和RMA接口中又区分数据长度定义了不同的接口,分别对应直接短数据传输、带数据拷贝的传输和零拷贝传输模式。另外,UCT层也定义了原子操作和Tag消息接口,可以通过在一些新型具有通信卸载功能的互连网络上直接实现这些接口,来优化UCP层接口的实现。UCP层接口的定义则面向编程模型的需求,提供Tag消息传输、RMA操作和原子操作等。UCP层接口基于UCT层接口来实现,但由于特定互连平台上UCT层接口的类型和传输能力差异,因此在运行时UCP层会通过不同的通信协议来完成数据传输。例如,如果UCT层只实现AM和RMA接口,则UCP层的Tag消息传输接口对短消息是直接通过UCT层AM接口来传输数据,而对长消息则采用Rendezvous协议,先通过AM操作进行发送和接收方之间的协同和缓冲区信息交换,再调用RMA接口完成数据传输。
2.2 OFI通信框架
OFI由OpenFabrics Alliance发起,其设计目标是为多种不同的高速互连定义一个抽象的新通信编程接口,覆盖各种互连的主要功能特性,既能够贴近应用的需求,同时又不会影响面向特定互连的实现优化。
OFI的总体结构如图2所示,定义了MSG消息传输、Tag消息传输、RMA通信操作和原子操作等数据传输接口。MSG消息传输是2个通信端点间维护消息数据边界的顺序数据传输,而Tag消息传输则是在MSG基础上加入了基于Tag的消息选择接收。OFI定义了EP_DGRAM、EP_MSG和EP_RDM这几种不同的通信端点类型,分别对应无连接不可靠报文、有连接可靠消息和无连接可靠报文通信模式,每种通信端点上能支持的接口也不同。不同于UCX的明确分层结构,OFI的接口是由各个Provider直接实现的。Provider又区分为Core和Utility 2类,每个Core Provider直接对应一个互连平台,但基于互连网络的功能特性,可以选择只实现部分OFI接口。而Utility Provider则通过软件层的协议仿真操作为Core Provider添加一些其它未实现的接口功能[8],例如RXD为只支持EP_DGRAM端点的Core Provider增加了对EP_RDM端点和相应的Tag消息传输接口等的支持,而RXM为只支持EP_MSG端点的Core Provider增加了对EP_RDM端点和相对应通信接口的支持。
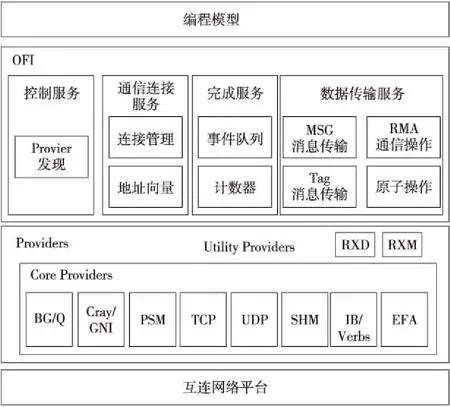
Figure 2 Architecture of OFI图2 OFI系统结构
2.3 UCX和OFI通信框架对比
从定义的通信接口功能来看,UCX和OFI还是相类似的,例如二者都包括基于Tag的消息传输、RMA远程内存访问和远程原子操作等,而且UCX和OFI都支持非阻塞模式通信操作,并提供了通信推进接口,这有助于利用互连平台特性,实现计算与通信重叠执行。但是,UCX对编程模型提供的是抽象程度高的UCP层接口,即使因为互连网络的功能限制无法支持全部UCT层接口,在UCP层也可以通过软件层的协议操作,来完成UCP层的全部数据传输语义。而OFI的接口由Provider直接实现,因此在不同互连网络平台上的接口类型、功能和参数限制等差异情况,都直接展现给编程模型,这既带来了灵活性,也带来了实现复杂性[9]。
UCX和OFI的接口抽象层次和功能差别,对其上编程模型的实现带来了一定的影响。例如,在MPICH的CH4设备抽象层[10]中包含基于OFI和UCX的2个网络传输模块。在UCX模块中,由于UCP层接口是与互连网络的功能特性无关的完整接口,MPI的点点消息传递语义基本上可以直接对应UCP的Tag消息传输接口,因此MPI的消息传递接口被直接转换为对UCP层Tag消息传输接口的函数调用来完成,这极大地简化了CH4层代码。而在OFI模块中,由于运行时OFI选择的Provider可能展现出不同的端点类型和数据传输接口能力,因此OFI模块在初始化时会依据获取的Provider属性参数,按消息长度范围,使用OFI的不同接口实现Eager和Rendezvous消息数据传输协议完成数据传输,代码的复杂性明显高于UCX模块的。
在面向互连网络平台的可移植性方面,UCX内部提供了很多有用的数据结构和操作接口,例如内存缓冲池的分配管理接口、注册内存Cache机制、Hash函数接口、链表操作和指针数组等,有助于运行时减少资源消耗,提高可扩展性。OFI也有类似的数据结构和操作接口,但部分接口的灵活性和功能弱于UCX的实现,例如对内存缓冲池的分配管理等。另外,UCX还包含对GPU等计算加速器的支持,支持在CPU和GPU之间的数据传输,OFI目前还缺乏对此的支持。
3 天河互连网络和通信接口
天河互连网络由2个ASIC专用芯片组成,一个是结点内的主机接口NIC(Network Interface Chip),为各种系统和应用软件提供互连通信服务;另一个是NRC(Network Router Chip),采用高阶路由结构,可以构建结点间光电混合的互连拓扑结构和交换网络。
NIC支持完全用户级通信技术,通过一种虚端口机制,允许多个进程在用户空间受保护地并发访问通信硬件资源,在关键通信路径旁路操作系统的介入和数据拷贝操作,简化通信协议。NIC支持无连接可靠通信模式,虚端口间只要获取对方地址,即可进行MP短报文传输和RDMA通信操作。并且NIC内部有多个数据传输引擎,通过并发执行通信操作来提高数据传输效率。MP短报文传输是无连接多对一的报文数据传输,所有到达虚端口的MP短报文在一条MPQ短报文队列中顺序排队等待接收处理。RDMA通信操作是单边通信模式,通信发起方设定源和目的缓冲区地址和长度信息,源和目的虚端口之间直接以远程DMA方式读写缓冲区数据来完成数据传输。NIC内部设计实现了地址变换机制,使得RDMA可以直接传输用户进程地址空间虚地址连续而物理地址不连续的数据缓冲区。
天河互连网络的NIC自定义实现了一个GLEX(GaLaxy EXpress)通信接口,对NIC的硬件功能与通信机制进行直接的抽象封装,进程在GLEX接口中通过直接控制访问NIC硬件资源来完成通信操作,具有很低的软件层开销。GLEX提供了基于端点(对应NIC的虚端口)的MP短报文传输操作、RDMA通信操作(支持Put/Get 2种模式)和面向RDMA的内存注册管理接口等。通信操作是非阻塞模式,通过一组事件接口来检测通信操作的完成状态,以方便实现计算与通信操作的重叠执行。
4 面向通信框架数据传输服务的多通道通信协议
从第2节的通信框架对比分析中可以看出,在通信框架面向新型互连网络平台需要移植实现的接口中,消息传输和RMA单边通信是其中2类最主要的数据传输服务,因此在天河互连网络上实现通信框架需要解决的主要技术问题,就是如何设计与实现基于GLEX通信接口的高性能数据传输协议,来完成通信框架的消息传输和RMA单边通信操作功能。
通信框架的消息传输服务是维护了消息数据边界的可变长度数据传输方式,GLEX通信接口的MP短报文传输也是一种消息传输方式,但一次传输的数据量很少。GLEX的RDMA接口虽然支持进程缓冲区之间的高速块数据传输,直接对应通信框架的RMA接口功能,但是在传输消息数据前,需要预先获取发送和接收消息缓冲区的描述信息。因此,本文设计了多种结合MP短报文传输和RDMA通信操作的通信协议,来实现满足通信框架可变长度消息传输语义的高性能数据传输。
4.1 可扩展可靠短报文通信协议
对通信框架的短数据消息传输操作,数据可以直接封装在GLEX的MP短报文中完成传输。但是,由于虚端口的MPQ是面向所有发送方共享的MP短报文接收队列,如果MP报文接收处理不及时,则MPQ存在溢出的可能性,会造成报文丢失。考虑到并行应用的规模和通信模式,可以有2种不同的可靠MP短报文传输协议设计原则。
一种是允许出现MPQ溢出。但是,这需要在发送方和接收方之间实现滑动窗口重传机制,在出现接收方MPQ溢出时,通过发送方重传操作实现MP短报文传输的可靠性。这种传输协议为重传而进行的MP报文管理较为复杂,还需要引入超时机制,实现开销较大。
另一种则是避免MPQ溢出的通信协议。本文设计了一种动态信用流控机制,设计思路是为发送方预先分配发送信用,防止MPQ溢出,但每个发送方的发送信用可以按任务间通信密集度动态调整。每个虚端口的MPQ的所有单元在初始化时被分成2个部分:一部分是为每个发送方预留的少量初始发送信用单元,而另一部分则是作为动态信用单元扩展池。发送方消耗一个发送信用,才能向目的方发送一个MP短报文,而接收方会在反方向数据传输时顺带回填信用,或在检测到发送方信用耗尽时主动回填信用。如果发送方密集发送数据,则有可能耗尽发送信用,此时可以触发设置信用请求标记,在后续的短报文传输中携带,接收方在处理MP短报文看到该标记时,就会从动态信用单元扩展池中申请一些单元反馈给发送方,这样就可以动态增加发送方信用,确保频繁通信的任务之间可以使用更多MPQ单元。这种通信协议软件层开销低,因此在通信框架中用于实现结点间可靠MP短报文传输。
4.2 共享RDMA通道(SR)通信协议
对较长消息数据的传输,可以切分成多次可靠短报文传输操作来完成,但传输效率较低,因此可以考虑使用RDMA通信来传输消息数据。但是,RDMA是单边通信,要求预先交换发送方和接收方消息数据区信息,并且消息数据被内存注册锁定后才能进行RDMA传输,这是一个高开销的操作系统内核级操作。对一定长度范围内的数据,CPU的数据拷贝开销低于内存注册操作,因此本文设计了结合数据拷贝与RDMA通信流水执行的通信协议,来实现可变长度的消息传输。
在发送方和接收方都预先设置一组固定长度的缓冲单元,这些单元被内存注册锁定组成RDMA缓冲池。在消息传输操作中,发送方的消息数据按长度被拷贝到一个或多个缓冲池单元中,然后先通过前述可靠短报文传输协议,将发送方缓冲单元的地址和长度信息传输到接收方,接收方收到MP短报文后也在本地RDMA缓冲池中分配对应数目的单元,然后启动RDMA Get操作在发送方和接收方对应的缓冲池单元间传输数据。RDMA传输完成后在双方都触发通知事件,发送方处理事件回收缓冲池单元,而接收方处理事件则将数据从RDMA缓冲池拷贝到接收消息缓冲区,然后再回收缓冲池单元。可以看出,这是通过发送方和接收方的数据拷贝,再结合RDMA数据传输来仿真的消息传输语义,但多组消息传输操作中的数据拷贝,以及MP和RDMA通信是流水重叠执行的,以便提高传输效率。
由于这是由接收方启动的RDMA数据传输,多对一消息传输下的RDMA缓冲池单元竞争由接收方解决,因此该通信协议中的RDMA缓冲池可以共享用于和所有其它任务之间的通信,成为每个任务和其它所有任务间消息通信的共享通道。
4.3 独占RDMA通道(ER)通信协议
共享RDMA通道通信协议需要MP和RDMA Get 2个阶段的操作才能完成消息数据传输,这样增加了通信延迟。而RDMA Put操作可以直接将数据从发送方传输到接收方,但如何协调双方消息数据区的地址和长度信息是需要解决的技术问题。
本文设计了如图3所示的一种基于RDMA Put的消息传输协议。发送方和接收方各预先在内存注册一个同样长度的RDMA缓冲区,通过RDMA Put操作将这2个RDMA缓冲区构造成一个发送方管理的远程FIFO结构。发送方消息数据被顺序拷贝到发送方的RDMA缓冲区中,然后通过RDMA Put传输到接收方RDMA缓冲区的相同位置,再利用远程事件通知接收方将数据从RDMA缓冲区拷贝到接收消息缓冲区中。对较短的消息数据传输,还可以使用立即数RDMA Put操作,这是一种将源数据嵌入RDMA通信描述符中的通信机制,具有更低的通信延迟。理论上,这种远程FIFO结构可以按字节顺序使用,但考虑到RDMA Put传输在对齐Cacheline边界时效率更高,所以切分成Cacheline长度的单元。每次消息传输按数据长度使用连续数个单元,只有最后1个单元会浪费少量内存未被使用。消息的第1个单元里面预留消息头,在接收方消息头里面的数据长度域由RDMA Put远程事件来更新,这样接收方可以获知消息数据的长度。多个消息传输对应的数据拷贝和RDMA Put操作也是流水重叠执行的,可以提高消息数据的传输带宽。这种远程FIFO采用静态流控机制,RDMA缓冲区切分出的Cacheline单元数就是最大发送信用值。接收方可以通过向发送方的反向消息传输操作顺带回填信用,或在接收处理了足够的单元时触发阈值,再主动通过MP短报文回填信用。

Figure 3 Data transfer protocol of exclusive RDMA channel图3 独占RDMA通道消息传输协议
但是,因为这是发送方主导的数据传输协议,所以这种远程FIFO结构只能成为2个特定发送方和接收方之间的独占消息传输通道,是以通信内存资源的消耗来换取通信性能的提升的。
4.4 零拷贝RDMA通道(ZC)通信协议
共享和独占RDMA通道传输协议因为存在发送方和接收方的数据拷贝,所以会影响长消息传输的带宽,增加CPU的占用率。因此,可以采用Rendezvous协议传输长消息,先对发送方和接收方的消息数据进行内存注册,然后使用SR或ER通道完成双方消息缓冲区地址和长度信息交换,再利用RDMA Get或Put操作直接进行消息数据的零拷贝传输。对消息传输完成的状态检测也是利用在发送方和接收方触发的RDMA事件来实现,并且长消息的顺序处理和流控,也依赖于SR或ER通道的相应处理来完成。而通信框架的RMA接口,也可以直接对应到零拷贝RDMA通信操作。
RDMA操作前的内存注册过程是高开销的操作系统内核级操作,但很多并行应用通常会进行消息和RMA数据缓冲区的重用,因此需要通过一个注册Cache机制,将已注册数据区的地址和长度等信息缓存起来,并延迟解除内存注册的操作。这样多次的RDMA数据传输如果仍然重复使用已注册的内存区域,就可以不再进行内存注册相关操作,从而减少了开销。
4.5 面向可扩展通信的组合通道消息传输
从上文可以看出,SR和ER通道有不同的性能特性和通信资源消耗,考虑到很多并行应用会展现出近邻通信模式[11],因此在通信框架的实现中,可以通过组合通道传输方式,在密集通信的并行任务间建立一组ER通道进行消息传输,而其它任务间的消息传输则采用同一个SR通道来完成,这样可以在确保并行应用性能的前提下,减少通信资源内存消耗,提高并行应用的可扩展性。
因为GLEX采用非阻塞通信模式,因此需要专门的通信推进过程推动各个传输通道的消息处理。但是,GLEX接口中虚端口MPQ和事件队列始终是MP短报文数据和通信操作状态的单一轮询点,和并行应用的任务规模无关,而且在通信推进过程的实现中,可以只将那些实际发生通信状态变化的传输通道加入通信推进处理流程中。在大规模并行应用运行时,这种单一轮询点和动态通道推进方法有助于减少通信延迟,提高应用运行的扩展性。
5 基于天河互连网络的通信框架对象模型实现
虽然UCX和OFI的系统结构不同,但都采用了面向对象技术的思想,在系统实现代码中通过对象模型描述互连网络资源,定义通信实体,以及提供各种服务接口。因此,在一个新型互连网络上的实现,需要解决对象模型如何对应到互连网络硬件资源的技术问题。本节将描述在天河互连网络上实现UCX和OFI通信框架时,通信框架对象模型和互连网络硬件资源的映射实现问题。
5.1 基于天河互连网络的UCX对象模型
基于天河互连网络的UCX实现集中于UCT层接口的实现。如图4所示,UCX的UCT层接口定义,是围绕几个抽象数据对象实现的各种通信操作。

Figure 4 UCT object model on GLEX图4 基于GLEX的UCT对象模型
图4中uct_md对象是内存注册域,用于对用户数据缓冲区进行内存注册管理;uct_worker对象是通信推进引擎和资源上下文,用于推动各种数据传输操作,以及在多线程间协同对通信资源的使用;uct_iface对象表示通信接口,基于一个uct_md和uct_worker对象创建,代表用户进程在互连接口上的一个入口点,用于接收处理到达的各种消息,UCT的所有通信接口也定义在uct_iface对象中。基于uct_ifac对象,可以创建uct_ep对象,每个uct_ep对应和一个远程uct_iface对象的通信连接,绑定远程uct_iface的地址信息。
基于天河互连网络平台实现时,因为GLEX接口的端点glex_ep是用户进程对互连网络接口的访问点,通过glex_ep可以进行内存注册和全部无连接模式的通信操作,因此在创建uct_md对象时,会分配一个glex_ep,这样和uct_md关联的其它UCT对象都继承使用这个glex_ep端点完成各种通信操作。所有的uct_ep都共享相同的glex_ep完成AM消息传输和RMA通信操作。uct_ep和远程uct_iface之间优先尝试使用ER通道传输协议进行AM消息传输,只有在通信资源使用达到限额时,才转为使用所有uct_ep共享的SR通道传输协议传输AM消息数据。零拷贝RMA接口则直接使用ZC通道传输协议来实现,UCS层提供了注册Cache接口,可以减少内存注册开销。
由于MPI等并行编程模型假定并行任务间是全连接模式,因此基于UCX的MPICH等实现系统会在初始化时为COMM_WORLD通信器内每个任务都建立一个uct_ep。为减少内存开销,将uct_ep为实现ER或SR通道协议而维护的协议状态和流控数据结构设置在另外的虚连接VC结构中,只有在uct_ep进行首次通信时才动态创建,结合应用的通信模式,可以显著降低uct_ep对象的内存消耗。而对所有uct_ep上通信操作状态的跟踪与处理,是通过uct_worker对象的通信推进过程来完成的,通过推动对glex_ep的MPQ和事件队列的处理,完成所有uct_ep关联的各种ER、SR和ZC通道传输协议。
总体来说,由于UCX的UCT层的接口相对较少,而且UCS层提供了一些具有良好扩展性的数据结构和操作接口,例如mpool注册内存管理接口,可以用于ER或SR通道RDMA缓冲池的分配和管理,这都能简化UCT在天河互连网络上的实现代码。
5.2 基于天河互连网络的OFI对象模型
OFI的对象模型如图5所示,其中各个对象的详细功能说明可参考文献[2]。虽然和UCX的UCT对象结构不同,但OFI的domain和endpoint等对象的作用和UCX的uct_md和uct_ep相差不多。在OFI中domain也对应于互连接口的一个入口点,注册内存的管理(Memory Regions)和通信完成状态的检测(Completion Queues/Counters)都通过domain进行。因此,在天河互连网络上,GLEX接口的端点glex_ep也是在domain对象创建时分配。而endpoint代表和一个远程实体通信的通信操作入口点,和UCX的uct_ep类似,所有的endpoint共享domain对象的glex_ep完成全部通信操作。
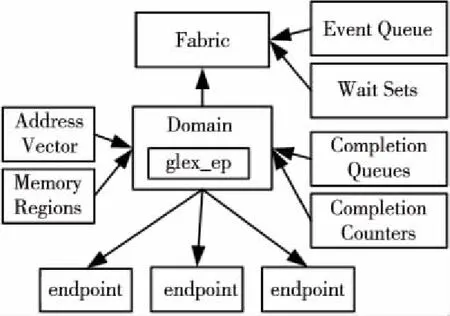
Figure 5 OFI object model on GLEX图5 基于GLEX的OFI对象模型
由于GLEX接口是无连接的可靠传输服务,因此可以实现OFI的无连接EP_DGRAM和EP_RDM端点类型。OFI的MSG消息传输接口在运行时也可以使用ER或SR通道传输协议来实现。但是,只有EP_RDM类型的端点才能支持Tag消息传输和RMA操作。实现EP_RDM端点类型有2种途径:一是直接在Provider中实现,但是OFI没有可重用的Tag消息传输协议代码,需要Provider自己实现,代码复杂性较高;二是只在Provider中实现EP_DGRAM端点类型,然后利用OFI的RXD Utility Provider,通过软件层仿真协议的方式实现EP_RDM端点类型,以及Tag消息传输和RMA接口等,但这种形式的RMA接口目前是软件仿真操作,不能直接对应到互连网络的RDMA传输接口,传输性能受到一定的影响。
目前在天河互连网络上的OFI实现,采用了一种更为简化的实现方式,支持EP_RDM端点和Tag消息传输操作。使用UCX的UCP接口实现了一个Core Provider,将OFI的Tag消息转化成UCP 的Tag消息传输操作来实现。这种方式只是初步的原型实现,还不能实现最优的传输性能,后续将直接使用GLEX通信接口完善Core Provider的功能和实现代码。
6 通信性能测试
本节对基于天河互连网络的开源通信框架进行了性能测试,测试所用的天河互连网络的端口速率是14 Gbps,结点CPU是Intel Xeon E5-2692,主频2.2 GHz,结点主存64 GB,NIC互连接口通过PCIe 3.0 x16和结点CPU相连。
UCX和OFI的通信性能使用其自带的性能测试程序进行,由于基于GLEX的UCX实现较完善,而OFI还是初步原型实现,所以MPI测试使用MPICH3.3版本,在编译时选择CH4抽象设备接口和UCX网络传输模块,性能数据由OSU Micro Benchmarks测试集获得。另外,也使用现有的天河MPI实现系统进行性能对比,天河MPI也是以MPICH 3.3为基础,但是通过CH3抽象设备层的Nemesis通道[12]接口实现的GLEX网络模块,主要的消息数据传输协议也是前述的ER/SR/ZC通道传输协议。由于CH3层是和互连网络特性无关的抽象接口,基于CH3的MPI消息传递接口需要实现Eager和Rendezvous等通信协议[6,7],还需要面向这些协议定义复杂的协议请求和应答报文格式,实现代码较为复杂。
图6是最短长度消息传输延迟的对比结果,这里列出了ER和SR 2种传输协议的延迟。在ER通道中作为基准的GLEX延迟是使用立即数RDMA Put操作传输1 B数据的延迟,在SR通道中则是MP短报文传输1 B的延迟。UCT是AM接口传输8 B数据的延迟(这是UCX测试程序的限制),UCP是Tag消息传输接口传输1 B数据的延迟,CH4-UCX则是MPI消息传递接口1 B数据的传输延迟,而OFI则是Tag消息的最低延迟。从测试结果可以看出,UCT层ER通道的最低延迟是0.89 μs,相对GLEX层增加的延迟少于200 ns。这些增加的开销来自于发送方和接收方的数据拷贝操作、RDMA描述符的构造处理过程,以及AM协议消息的处理等。而在UCP层Tag消息传输接口的协议设计中,短消息传输基本上就是直接调用UCT层AM short接口完成的,只是在接收方有针对消息Tag的处理过程,而且UCP采用一种结合Hash技术的链表结构进行消息Tag的匹配处理优化,所以UCP在UCT上只增加了约20 ns的延迟,最低延迟是0.91 μs。而在OFI的原型实现中,Tag消息传输接口在进行参数检查和目的地址查找后,就转为UCP的Tag消息接口来完成,所以只增加约10 ns的延迟。而基于CH4层的MPI消息传递,除了基本的参数检查和数据类型转换外,直接调用UCP的Tag消息传输接口进行数据传输,最低延迟是0.95 μs,相对UCP层也只增加了很少的软件层开销。
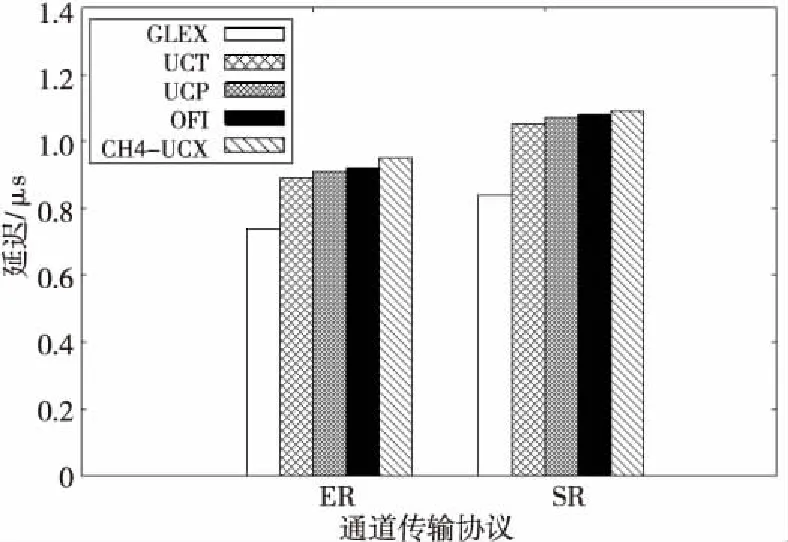
Figure 6 Comparison of message transfer latency图6 消息传输延迟比较
图7是MPI消息传递延迟的测试结果,CH4-ER-UCX是基于CH4层UCX网络模块的MPI延迟,使用ER通道协议,而CH4-SR-UCX则是SR通道协议的延迟。CH3-ER-GLEX是现有天河MPI中基于CH3层GLEX网络模块实现的ER通道协议延迟,CH3-SR-GLEX是SR通道协议的延迟。测试数据表明,即使存在数据拷贝操作,SR和ER通信协议传输短消息仍具有很低的延迟,并且基于CH4层接口的UCX网络模块MPI延迟,不管是ER通道协议还是SR通道协议,都优于现有的基于CH3层的实现。CH4-ER-UCX的延迟是0.95 μs,而CH3-ER-GLEX的延迟是1.07 μs。延迟的降低来自于几个方面:一是在CH4层的实现中,MPI的消息传递接口被直接转化成了UCP的Tag消息接口函数调用,对应很少的指令条数,并且也不再需要传输原来CH3层复杂的协议报文,在发送方和接收方都减少了内存拷贝的数据量;二是通过使用UCP的Tag消息接口,MPI原来的消息信封匹配比对过程被简化为对Tag值的比对,UCP还通过结合Hash的链表结构,提高了Tag消息匹配处理效率。本文也在天河互连网络上测试了基于UCX的Open MPI,由于Open MPI模块结构也是通过一个简化的PML软件层将MPI消息传递接口转化成UCP的Tag消息接口,所以最低消息延迟和基于UCX的MPICH基本相当。

Figure 7 Comparison of MPI message transfer latency图7 MPI消息传输延迟比较
图8是MPI消息传递带宽的测试结果。在基于UCX的MPICH实现中,主要的数据传输协议都是在UCP的Tag消息接口中完成的。UCP的Tag消息接口,对短消息使用Eager协议,通过UCT层的AM接口直接传输消息数据。对长消息则使用Rendezvous协议,先内存注册发送缓冲区,然后通过AM传输发送缓冲区地址和长度信息,由接收方的AM处理函数内存注册接收缓冲区,再调用UCT层的RMA零拷贝接口完成消息数据的传输。CH3层基于GLEX的网络模块实现,是利用Nemesis通道的LMT接口,实现了类似的传输流程。因此,在带宽测试中,两者的性能差别不大,都可以达到互连硬件峰值性能。但是,在短消息传输带宽上,CH4层基于UCX的实现还是略好于CH3层基于GLEX的实现。从测试数据也可以看出,使用ER通道协议,短消息传输可以用更短的数据长度实现1/2峰值带宽,这也反映出本文设计的ER通信协议具有很低的软件层实现开销。
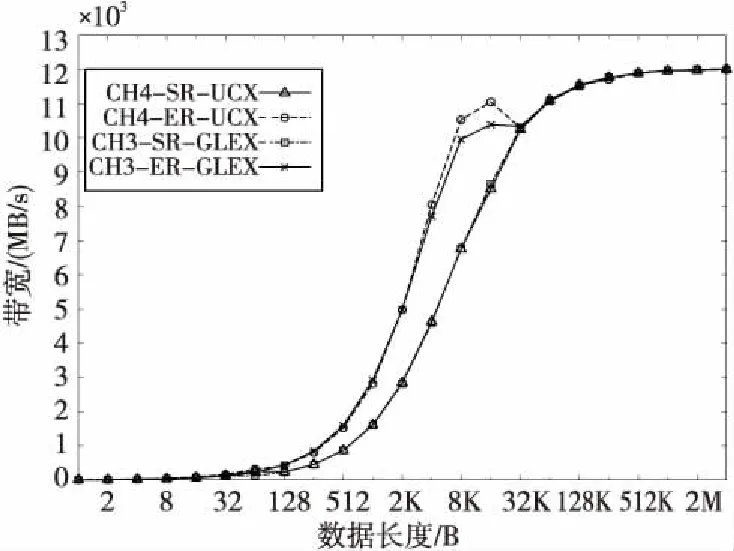
Figure 8 Comparison of MPI message transfer bandwidth图8 MPI消息传输带宽比较
图9是使用单处理器核基于ER通道传输协议的消息速率测试结果。可以看出,因为基于UCX的MPI实现简化了软件层开销,提高了网络报文中有效消息数据的比率,所以相对现有的天河MPI实现,使用立即数RDMA Put的短消息传输速率有明显提高,最高消息传输速率约为540万messages/s,而CH3层基于GLEX的实现最高传输速率约为380万messages/s。当转换为使用RDMA Put传输数据时,在128 B~4 KB范围内,基于CH3的MPI传输消息速率稍好。这是因为在CH3层的MPI实现中,ER通道协议可以自行根据消息数据长度进行发送数据的拷贝操作,这使得在RDMA缓冲区单元回绕处理过程中,可以更快地利用已有单元启动数据传输。而在UCT的ER通道协议实现中,数据拷贝是由AM接口参数中的打包函数完成的,打包函数调用完成时才能获知数据长度,所以RDMA缓冲区单元回绕处理的过程要更复杂一些,这对消息传输速率产生了一点影响。ER通道协议的最小传输单元长度是Cacheline长度,因此RDMA缓冲区的有效数据利用率还是比较高的,这使得ER通道可以用较短的RDMA缓冲区长度,高效地支持变长消息的数据传输。对一个大规模并行应用来说,在通信内存资源使用上限范围内,可以在应用中为并行任务间通信创建更多的ER通道,从而在保证并行应用可扩展性的前提下,确保任务间的数据传输性能。
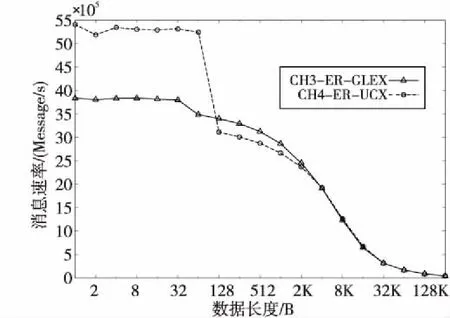
Figure 9 Comparison of MPI message transfer rate图9 MPI消息传输速率比较
7 结束语
开源通信框架为在互连网络平台上提高各种并行编程模型的开发效率,实现软件代码的重用提供了较好的解决方案。本文描述了UCX和OFI开源通信框架在天河互连网络上的实现技术,通过设计与实现多通道数据传输协议实现了通信框架的高性能通信服务,并通过组合通道传输技术提高了并行应用的可扩展性。虽然通信框架在天河互连网络自定义通信接口上又增加了一个软件层次,但编程模型的性能测试结果仍然展现出很低的软件层开销。目前多种MPI和PGAS并行编程模型的实现系统均可以基于开源通信框架在天河互连网络上高效地运行。开源通信框架面向未来的E级并行计算平台也做了很多针对性的设计,在天河互连网络上实现通信框架的一些经验将有助于指导未来对天河互连网络的改进工作,例如将更多的通信功能卸载到互连网络接口自主执行,可以获取更好的通信性能,同时提高计算与通信重叠执行能力。
猜你喜欢
汽车电器(2022年9期)2022-11-07
中国水利(2022年1期)2022-02-13
东坡赤壁诗词(2021年1期)2021-03-24
铁道通信信号(2020年4期)2020-09-21
中国外汇(2019年11期)2019-08-27
北方音乐(2019年13期)2019-08-21
计算机系统应用(2018年3期)2018-04-21
空中之家(2017年11期)2017-11-28
铁道通信信号(2016年8期)2016-06-01
中国工程机械学报(2016年5期)2016-03-07
