
面向HPC的高性能微处理器研究进展
2020-11-05 04:42王耀华
计算机工程与科学 2020年10期
王耀华,郭 阳
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
当今世界,高性能计算HPC(High Performance Computing)被广泛应用于石油勘探、天气预报、金融信息以及科学研究等关乎国计民生的重要领域,已经成为国家竞争力的一个重要组成部分,也是各国竞相争夺的技术高地。而高性能微处理器作为HPC系统中的算力源泉,被称为高性能计算技术高地上的一颗明珠。可以说,高性能微处理器的设计技术对HPC系统的总体算力起着决定性的作用。
面向HPC的高性能微处理器设计的关键技术点主要包括:(1)内核结构中的并行性开发技术,主要指如何通过有效的运算资源组织方式,实现运算资源间的高效协同,从而高效开发程序中的数据级并行和指令级并行;(2)数据供给机制,主要涉及存储子系统的设计,重点关注如何通过存储层次设计、数据局部性挖掘以及数据使用方式预测等技术为运算资源提供高带宽、低延迟的数据供给;(3)互连机制,随着多核已经成为芯片性能持续提升的重要因素,如何通过高效的核间互连,以及处理器核与存储系统互连有效提升整体算力,对高性能微处理器的性能发挥至关重要。
为此,本文分别从计算资源组织方式、存储子系统设计和核间互连技术3个方面对包括NVIDIA[1,2]和Intel[3 - 7]以及AMD[8 - 10]在内的主流处理器厂商面向HPC的高性能微处理器芯片进行了分析和探讨,并在此基础上总结了当前高性能微处理器设计的技术现状和技术趋势:(1)在运算资源组织方面,技术同质化现象较为明显,呈现出以Vector-SIMD(Vector Single Instruction Multiple Data)为主,辅以多调度机制、定制加速部件以及不同SIMD(Single Instruction Multiple Data)宽度等支持,提升计算效率以及对不同应用的适配性。(2)在存储子系统设计方面,各厂商都采用了HBM2(High Bandwidth Memory)存储技术,在此基础上不同厂商根据各自的结构特点,提出了不同的优化策略,呈现出百花齐放的特征。可以预见的是,未来随着存储系统的瓶颈效应不断加剧,存储系统将成为高性能微处理器设计成败的关键因素。(3)在多核互连方面,一方面chiplet技术正逐渐兴起,另一方面以NVlink、CXL(Compute eXpress Link)、IF(Infinity Fabric)为代表的直连技术正通过不断的技术更新,逐步推高互连带宽。
本文的分析内容将有助于对高性能微处理器技术趋势的准确把握,对自主研制面向HPC的高性能微处理器设计具有一定的指导意义和参考价值。本文主要贡献如下所示:
(1) 从计算资源组织方式、存储子系统设计和核间互连技术3个方面对主流微处理器厂商的高性能微处理器进行了研究与分析。
(2) 总结展望了当前高性能微处理器的技术特点和设计趋势。
2 计算资源组织方式
计算资源组织方式对芯片算力具有决定性作用,同时还影响着存储和互连方面的设计,是高性能处理器设计的核心。本节通过分析NVIDIA、Intel、AMD处理器中的核心计算单元的运算单元组织方式,给出当前的主流技术特征。
2.1 NVIDIA A100 GPU
NVIDIA作为GPU领域的领航者,其GPU结构对HPC和AI领域都有较好的支持。NVIDIA GPU主要包含多个GPC(GPU Processing Cluster)和存储控制器。GPC采用层次化结构,内部包含多个TPC(Texture Processing Clusters),每个TPC又进一步划分为多个SM(Streaming Multiprocessor),SM作为GPU中最基本的运算核心,是GPU算力的主要来源。
Ampere100 (A100)[1,2]是NVIDIA于2020年最新推出的面向HPC和AI的最新款GPU。图1给出了A100中SM的内部结构示意图。SM包含了INT8、BP16、 FP16、FP32、FP64等多种类型的运算单元FU(Function Unit)阵列。A100 GPU中还引入了为AI算法特别定制的特殊数据类型TF32,以增强对AI运算的支持。

Figure 1 Block diagram of NVIDIA A100 GPU SM图1 NVIDIA A100 GPU SM结构框图
为了高效利用SM中密集的FU阵列,NVIDIA GPU引入了单指令流多线程SIMT(Single Instruction Multiple Threads)的编程模型,使得程序员只需专注于单个线程的程序编写,降低了并行编程的难度。基于SIMT编程模型的程序映射到SM时,多个线程(一般为32)会被打包为一个Warp,以单指令流多数据流(SIMD)的方式执行,因此,GPU中FU阵列的核心组织方式实际上是SIMD的方式。为了区别于Intel、TI等芯片厂商提出的子字SIMD扩展(比如将一个64 bit的计算扩展为4组16 bit的并行计算),本文把GPU中的SIMD定义为向量SIMD(Vector-SIMD),即单条指令流驱动多个向量元素进行并行计算(比如单一指令驱动32路64 bit数据的运算)。
Vector-SIMD的组织方式能够有效实现多路数据在指令控制层面的共享,从而较为高效地开发应用中的数据级并行。在此基础上,为了进一步提升性能,充分利用FU的计算潜力,GPU中还引入了多调度机制,实现多个Warp在FU阵列中的并行执行,使得不同类型的FU能够同时得到利用,实现了对应用中指令级并行性的开发。依靠Vector-SIMD和多调度机制,最新款的NVIDIA A100 GPU中双精度浮点的性能高达9.7 TFLOPS,单精度浮点的性能达到19.5 TFLOPS[2]。
值得一提的是,除了上述以Vector-SIMD和多调度组织的FU阵列结构,A100 GPU的SM还引入了第3代Tensor Core单元,用于实现对GEMM(GEneral Matrix-matrix Multiplication)的定制化加速。GEMM是很多HPC和AI算法中的核心计算模式,具有广泛的应用基础。GEMM的核心计算模式为:D=A*B+C,其中A、B、C、D分别为m*k、k*n、m*n、m*n的矩阵。第3代Tensor Core中每个时钟周期可支持256个FP16的乘加运算,也即每个时钟周期能够完成最大m=8,k=4,n=8的GEMM运算。结合对稀疏矩阵结构的特殊优化支持,相比上一代Tensor Core,第3代Tensor Core的吞吐率能够实现20倍的提升。定制化的设计和优化损失了部分可编程性,但使得Tensor Core的双精度(FP64)计算性能达到了19.5 TFLOPS,半精度(FP16)计算性能达到了312 TFLOPS,INT8类型的性能更是高达1 248 TOPS。对稀疏矩阵的优化设计,使得Tensor Core对FP16和INT8类型的计算支持分别等效于624 TFLOPS和2 496 TOPS的计算性能。
小结:NVIDIA GPU中的核心计算单元SM:(1)以Vector-SIMD加多调度的方式组织FU阵列,从而可以高效地开发应用中的数据级并行和指令级并行;(2)引入了面向特殊且具有宽泛应用基础的运算模式GEMM的定制加速单元,有效提升了单位面积和功耗下的计算资源密度。
2.2 Intel Ponte Vecchio GPU
Intel一直都有基于X86架构流水线结合高位宽SIMD运算支持打造高端GPU的计划,预计将于2021年为Argonne实验室推出E级超算系统Aurora,其最初的性能担当被设定为具有上述特征的Intel Xeon phi (Knights Hill)处理器,Knights系列处理器支持宽度高达512 bit的SIMD运算,应用于很多超算系统中[3]。
然而Intel在进行人员架构调整以后,于2017年发布消息,将研究面向HPC的全新GPU架构用于下一代超算系统。2019年末,Intel 在一次HPC开发者大会上透露了这款代号为Ponte Vecchio的全新GPU架构的部分信息。据介绍,全新GPU的最高配置版本的双精度浮点性能可高达36 TFLOPS,功耗约为400 W/500 W[7]。由于没有官方白皮书,本文对Ponte Vecchio的介绍主要来自Intel的报告和学界的相关推测[3 - 6]。
图2给出了Ponte Vecchio GPU的结构框图,可以看出Ponte Vecchio GPU内核主要包含SIMT和SIMD 2种类型的运算单元。这样的设计完全秉承了Intel对于GPU的设计理念,即:(1)GPU的性能源泉来自其向量(Vector-SIMD)处理能力。(2)单一的Vector-SIMD宽度难以满足所有应用,且为不同宽度的Vector-SIMD所编写的代码之间存在极大的兼容性难题(摘自Intel GPU的首席架构师Koduri在HPC 开发者大会上的发言)。基于上述2个方面的考虑,Ponte Vecchio GPU中的SIMT单元主要对应较大宽度Vector-SIMD,在此基础上,作为对大宽度Vector-SIMD的补充,进一步继承了Intel CPU中medium尺寸子字SIMD(M SIMD)和Large尺寸子字SIMD(L SIMD)单元,从而进一步丰富了对Vector-SIMD的向量宽度的补充支持。Ponte Vecchio GPU中还添加了SIMT和不同尺寸SIMD单元之间的协同计算支持,即SIMT单元负责应用中较为规整的并行性开发,在此基础上,通过SIMD单元进一步加速串行部分的执行[6]。
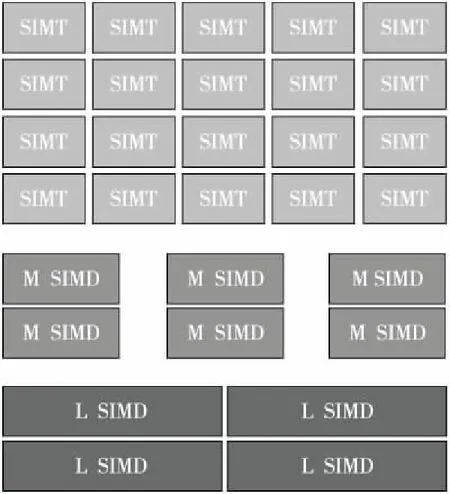
Figure 2 Block diagram of Intel Ponte Vecchio GPU图2 Intel Ponte Vecchio GPU的结构框图
Ponte Vecchio的另一个特征是支持内核计算能力的可扩展性设计,可以根据不同应用对相应SIMT+SIMD的功能单元进行增加或删减。此外,有推测认为,SIMT单元中存在面向特定应用的专用加速部件[6]。
小结:Intel Ponte Vecchio采用Vector-SIMD加子字SIMD的方式用于协同提升性能及适应应用中对不同向量宽度的需求。
2.3 AMD Instinct GPU
AMD公司在高性能领域日渐活跃,目前其最新的动态是和美国能源部、橡树岭实验室以及Cray公司共同打造的新一代超算Frontier将于2021年上线。Frontier的核心算力担当为AMD的Radeon Instinct GPU,该GPU基于Vega20架构实现,可提供7.4 TFLOPS的双精度浮点算力[8]。
Vega20架构[9,10]中包含面向图形图像处理的定制Geometry Engine和Pixel Engine阵列,提供可编程计算支持的Compute Engine阵列,以及Cache等部分。其中Compute Engine阵列是AMD GPU算力的主要组成部分。每一个Compute Engine包含多个计算单元NCU(Next-generation Compute Unit)。
图3给出了NCU内部的结构框图。从图3中可以看出,NCU主要采用Scalar加Vector-SIMD的方式进行运算资源的组织。其中Scalar部分用于应用中的串行处理,Vector-SIMD部分则提供对并行部分的加速。
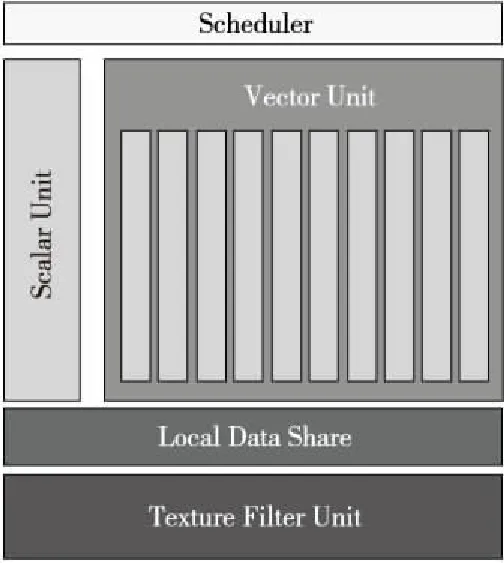
Figure 3 NCU structure of AMD Instinct GPU图3 AMD Instinct GPU中的NCU结构框图
小结:AMD GPU采用Scalar加Vector-SIMD的方式在支持并行加速的同时,兼顾对串行部分的处理。
综上所述,综合当前面向HPC的主流处理器制造商的最新款高性能处理器结构可以看出,在运算资源组织方面存在较明显的同质化特征,Vector-SIMD已经成为不二之选,在此基础上,不同厂商还通过提供诸如多调度机制、定制加速部件以及不同SIMD宽度等支持,进一步提升处理器的计算密度,以及对不同应用的适配性。
3 存储子系统设计
存储子系统为运算单元提供必要的数据供给,由于存储技术与计算逻辑之间巨大的速度差,如何有效提升存储带宽,降低存储延迟,通过充分开发数据访问模式的特征,设计高效的存储子系统对微处理器整体性能的发挥至关重要。本节分析总结了NVIDIA、Intel、AMD GPU中存储子系统设计的关键技术。
3.1 NVIDIA A100存储子系统
A100中的存储层次如图4所示,从上到下分别为寄存器文件RegFile、L1/Shared Memory、L2和HBM[2]。为了提升存储性能,A100在存储子系统设计上进行了如下所述的一些革新设计:

Figure 4 Block diagram of A100’s sub-memory system图4 A100的存储子系统框图
(1)L1和Shared Memory的融合设计:A100继承了V100中L1和Shared Memory融合设计的结构,将L1 Cache和Shared Memory放置到同一存储载体上,通过灵活配置,实现二者之间的空间划分,从而可以满足程序的不同需求,例如对于不需要Shared Memory的程序,可以将整个空间配置为L1 Cache,从而有效提升程序性能。
(2)L2 Cache数据驻留及压缩机制:A100处理器提供高达40 MB的L2 Cache空间。L2提供对数据驻留和替换的控制能力,可以有效防止具有较大重用性数据或关键数据被非关键数据替换出Cache的情况发生,从而保证程序的性能。此外L2 Cache还可以配合A100中提供的数据压缩机制,进一步提升L2的有效带宽。
(3)基于HBM2的内存系统:HPC和AI算法对存储空间和带宽的需求日渐增加。从Tesla开始,GPU就采用HBM作为其内存的载体。HBM通过2.5D集成技术,在提供超高带宽的同时,相比GDDR5/6能够有效降低面积和功耗。A100 GPU中的HBM2存储空间高达40 GB,带宽高达1 555 GB/s,相比上一代V100 GPU,内存带宽提升了1.7倍。
(4)Asynchronous Copy:A100的存储子系统中引入了由L2或HBM向Shared Memory直接搬移数据的操作,区别于以往数据需要通过L1进入寄存器文件以后,再被存储到Shared Memory,最新的直接搬移策略一方面能够消除不必要的数据搬移,节约存储带宽,另一方面还减少了对寄存器文件的冗余占用,从而能够有效提升存储子系统的效率。
小结:A100 GPU在采用HBM2、增大内存和Cache空间等常规优化的基础上,引入了包含数据驻留、直接搬移等策略,进一步减少非必要数据搬移,实现了存储带宽资源的有效利用。
3.2 Intel Ponte Vecchio XeMF存储子系统
为了配合Ponte Vecchio GPU中的海量运算单元,支持其性能可扩展性,Intel为Ponte Vecchio设计了一款名为XeMF(Xe-HPC Memory Fabric)的存储架构[6]。
图5给出了XeMF的结构框图。从图5中可以推测出,在该框架下:(1)Ponte Vecchio GPU通过XeMF与HBM及其他可能的存储器相连,其中存储带宽与计算单元带宽比为3∶1;(2)相邻GPU之间,以及相邻HBM之间存在直连通路。

Figure 5 Block diagram of Ponte Vecchio’s sub-memory system图5 Ponte Vecchio的存储子系统框图
此外,Ponte Vecchio GPU中还引入了名为Rambo的Cache结构,旨在为运算单元提供更高带宽数据。XeMF中HBM与计算单元之间的带宽比也进一步凸显了Rambo的数据预取和缓冲的重要意义。Rambo Cache通过名为Foveros的interposer和计算单元进行互连。Intel给出的关于双精度矩阵运算的性能评测显示,在没有Rambo时,矩阵规模从8*8增加到4096*4096的过程中,总体性能受限于数据供给会极大下降,Rambo Cache则可以极大改善这种状况,在增加矩阵规模时,能够通过高效数据供给将性能维持在一定的水平。
XeMF、计算单元(XeCore)和HBM控制器之间采用逐渐兴起的chiplet的方式进行集成,Ponte Vecchio将包含16个计算核、8个XeMF和8个HBM控制器。
由于Intel没有透露更多关于存储子系统的设计,因此有关存储子系统的许多细节目前还无法获悉。
小结:Ponte Vecchio GPU中引入了包含XeMF和Rambo Cache在内的存储优化,用于支持运算单元与存储器之间的高效数据通信,值得一提的是基于interposer的集成技术也被用在了Cache和计算单元的互连技术中。
3.3 AMD Instinct GPU的存储子系统
Instinct GPU(Vega架构)中的存储层次如图6所示[8],从上到下为寄存器文件RegFile、L1 Cache、L2 Cache、HBM2和DRAM。

Figure 6 Block diagram of AMD GPU’s sub-memory system图6 AMD GPU的存储子系统框图
Instinct GPU的存储子系统具有如下所述的2个技术亮点:
(1)基于HBM2的HBCC(High Bandwidth Cache Controller)。HBCC的主要功能是当所请求的数据不在GPU的本地存储时,不同于传统模式中GPU需要暂停流水线,将整个数据集导入本地存储,HBCC能够以Page为单位从远程存储(DRAM)中将数据取回,在完成单个Page的取数之后即可开启GPU流水线。实际上HBCC将GPU中的local memory变成了Last Level Cache,而将远程存储转化为本地存储,从而大幅增加了local memory的有效空间,消除了原有的local memory空间对计算任务的限制,并且有效隐藏了访存延迟。HBM2的高带宽特点进一步增强了HBCC设计的高效性。
(2)以L2 Cache为中心的Cache结构。Instinct GPU中消除了以往定制的像素引擎拥有私有Cache的分散式Cache架构,使得各计算引擎直接从L2 Cache获取数据,一方面为增大L2 Cache尺寸提供了空间,另一方面增强了不同计算引擎之间的数据共享,为更大规模的数据重用提供了可能。
小结:AMD GPU中通过HBCC以及L2 Cache为中心的Cache策略,有效实现了访存延迟的隐藏和数据重用性的开发,从而提升了存储子系统的数据供给效率。
综上所述,在当前的高性能微处理器设计中,与计算资源组织大多采用Vector-SIMD的同质化特点不同,存储子系统的设计除了都采用HBM2存储外,在存储系统的优化策略上呈现出百花齐放的特征,不同厂商根据各自的结构特点提出了不同的优化策略。可以预见的是,随着计算资源运行速度与存储器速度和带宽之间的不匹配进一步加剧,存储子系统性能将成为决定高性能微处理器设计成败的关键因素。
4 互连技术
依靠多核提高芯片性能,继续维持摩尔定律已经成为行业共识,使得片上互连技术成为核与核之间通信,处理器核与存储器之间通信的关键点,对芯片的总体性能具有十分关键的影响。本节分析了NVIDIA、Intel和AMD的核心互连技术。
4.1 NVIDIA 3rd NVlink
NVlink是由NVIDIA提出的核间互连技术,在提供高速互连的同时,还支持错误检查、数据包重发等技术,以保证互连性能。A100 GPU中采用了第3代NVlink技术,总共12条NVlink链路可提供高达600 GB/s的带宽[1,2]。
基于NVlink技术,NVIDIA推出了包含8个A100核的DGX A100超算结点,8个A100 GPU通过12条NVlink链路连接到NVswitch上。多个DGX A100结点可以进一步通过Mellanox InfiniBank/Ethernet进行互连,以构建更大规模的超算系统。
4.2 Intel Slingshot
Intel通过基于Faveros和EIMB interposer以chiplet的方式实现Ponte Vecchio GPU的性能可扩展性,在多GPU互连方面则主要依赖基于CXL技术的XeLink。基于该技术,Intel预计于2021年发布包含6个Ponte Vecchio GPU和2个Xeon CPU的Aurora计算结点[3 - 7]。不过Intel目前并未给出具体的带宽指标。在XeLink的基础上,Intel通过Slingshot技术实现结点间的互连。Slingshot是Cray的第8代互连技术,支持包扩拥塞控制、3-hop Dragonfly拓扑和流量分类等功能,通过与Rosetta的高带宽switches配合,能够提供25 GB/s的带宽。
4.3 AMD Infinity Fabric Link
AMD于2017年左右在其Zen系列CPU中提出了第1代IF技术,该技术主要被用作芯片内部多个chiplet之间的互连;在Rome和Zen2系列芯片中,提出了第2代IF技术,在第1代的基础上进一步提升了速度,并提供GPU到GPU的互连,对标NVlink技术,目前在AMD Instinct M50系列GPU中,包含2条Infinity Fabric Link,可提供高达184 GB/s的GPU间的直连带宽。然而,第2代IF技术无法支持CPU和GPU之间的互连,CPU与GPU之间仍然采用PCIe进行互连。有报导指出,AMD将于2022年左右推出连接一切的第3代IF技术[9],用于完成CPU与CPU、CPU与GPU以及GPU与GPU之间的完整互连[10]。
综上所述,在多核互连方面,一方面chiplet技术正逐渐兴起,使得面向不同应用领域的芯片设计能够以搭积木的方式完成;另一方面以NVlink、CXL、IF为代表的互连协议,正通过不断的技术更新,逐步推高芯片间的互连带宽。
5 结束语
本文分别从计算资源组织方式、存储子系统设计和核间互连技术3个方面对包括NVIDIA、Intel和AMD在内的主流处理器厂商面向HPC的高性能微处理器芯片进行了分析和探讨,并在此基础上总结了当前高性能微处理器设计的主流趋势。本文的分析内容有助于对高性能微处理器技术趋势的准确把握,对自主高性能微处理器的设计具有一定的指导意义和参考价值。
本文工作感谢国防科技大学计算机学院微电子与微处理器研究所的文梅、李晨、张洋、刘胜、陈小文、雷元武等同事对高性能体系结构的研讨,同时也感谢相关人员对论文的建议。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
科学技术创新(2021年18期)2021-06-23
铁道通信信号(2020年3期)2020-09-21
微型电脑应用(2019年10期)2019-10-23
铁道通信信号(2018年8期)2018-11-10
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
电子制作(2017年19期)2017-02-02
山东工业技术(2016年15期)2016-12-01
汽车维护与修理(2015年1期)2015-02-28
