
深层多级残差网络的图像超分辨率重建
2020-11-04 10:37吴从中魏雪琦
合肥工业大学学报(自然科学版) 2020年10期
吴从中, 魏雪琦, 詹 曙
(合肥工业大学 计算机与信息学院,安徽 合肥 230601)
图像超分辨率(super-resolution,SR)重建作为图像复原领域的一个重要分支,是指利用一幅或多幅同一场景下的低分辨率(low resolution,LR)重建出一幅接近真实图像的高分辨率(high resolution,HR)。图像超分辨率重建是一个典型的病态问题[1],具有不适定性,导致重建出的HR图像不唯一。为了克服图像SR重建问题的不适定性,研究者开始关注图像的先验信息。在传统SR算法中,主要通过重建约束和稀疏先验的方式研究图像本身固有的先验信息。文献[2]将稀疏编码引入到图像的SR重建问题上,通过把稀疏约束加到低分辨率图像块字典和高分辨率图像块字典的训练过程中,使得能够用相同的稀疏系数和对应的字典分别表示低分辨率图像和高分辨率图像;文献[3]提出了锚定领域回归(anchored neighborhood regression,A+)的方法,该方法在稀疏字典学习时结合邻域嵌入方法,用回归量固定字典原子实现快速超分辨率重建;文献[4]通过把几何补丁转化模型分解为透视变形来增加内部字典的大小,引入仿射变换适应图像中几何形状的变化,不需要使用任何外部训练图像,但在自然风景图像处理中,效果与其他方法相比并无明显优势。近几年,深度学习方法在计算机视觉领域表现出巨大潜力,它可以通过建立强有力的模型和设计高效的学习策略更好地解决问题。文献[5]中的超分辨率重建卷积神经网络(super-resolution convolutional neural networks,SRCNN)成功地将深度学习方法应用于超分辨率重建中,提出用卷积神经网络以一种端到端的方式,从低分辨率图像到高分辨率图像直接学习一个非线性映射,并且获得更好的重建图像质量; 文献[6]提出用一个很深的卷积神经网络(very deep convolutional networks for super-resolution,VDSR)来学习残差,并且结合多尺度方法进一步提高重建质量; 文献[7]成功地用一个深度递归卷积网络(deeply-recursive convolutional network,DRCN)完成了图像的超分重建过程,利用递归监督和捷径连接来提高性能,并且没有为网络引入新的参数。
本文受到深度残差网络(ResNet)[8-9]的启发,提出深层多级残差网络用于解决SR重建问题。首先利用预处理网络提取低分辨率图像的特征;然后用残差网络逐渐近似于图像退化模型的逆过程,以学习先验知识,让残差单元去拟合残差映射,而不是直接学习残差映射,这样网络可以得到更快的收敛速度。考虑到超分辨率重建问题的特性,把网络结构设计成流线型网络结构,相比于ResNet的一级捷径连接,深层多级残差网络相对更复杂,采用多级捷径连接,在残差网络部分,有3个相互交叉的残差单元,而在这3个残差单元的最外层,直接在HR图像和LR图像之间额外添加了另一级捷径连接,深层多级残差网络直接把输入的低分辨率图像信息携带到最后一个卷积层中,大大增加图像细节信息量,最后再重建得到高分辨率图像。综上所述,本文的主要贡献如下:
(1) 不同于以往的SR重建算法,本文所用网络直接利用残差网络学习低分辨率图像和高分辨率图像之间的映射,可以大大降低计算复杂度,使得网络更容易优化。
(2) 深层多级残差网络并不是简单的单级残差网络,而是在原始的ResNet网络上进行改进,添加了额外的多级恒等映射,实验证明,该方法应用于图像超分辨率问题产生的高分辨率图像具有良好的重建效果。
1 相关工作
因为深层多级残差网络是利用残差网络去模拟图像退化模型的逆过程,所以本节首先介绍图像退化模型,然后简单介绍经典的深度残差网络模型ResNet。
1.1 图像退化模型
通常单幅图像超分辨率重建都会涉及到一个问题,对于给定的低分辨率图像X,如何重建出具有更高分辨率的图像Y,观察到的X是Y的模糊下采样版本的图像,该问题表示为:
X=SHY
(1)
其中,S为下采样算子;H为模糊滤波器。
因为使用深度学习方法,通过卷积神经网络学习不到用来建模块空间的字典和流形,所以可以从另一个角度理解图像退化过程,(1)式简化为:
Y=X+I
(2)
其中,I为输入低分辨率图像X与输出高分辨率图像Y之间的损失信息,(2)式正好与残差单元公式相符合,见下节(3)式。
1.2 深度残差网络
近年来的研究成果表明网络深度的至关重要性,但是神经网络越深,愈加难以训练。而ResNet作为一个具有相当深度的网络结构呈现出令人信服的精度和很好的收敛行为,他们推测用一些叠层优化残差映射比优化原本引用的映射更容易,基于此,他们在每个堆叠层外采用残差学习,“Residual Unit”被表示成一般的形式,即
yi=F(xi,{Wi})+Wsxi
(3)
其中,xi、yi分别为第i个单元的输入向量和输出向量;函数F(xi,{Wi})为被学习到残差映射;Ws仅仅是被用来解决维数匹配问题的线性预测。操作F+xi是通过捷径连接实现元素级(Element-wise)加法运算,有2个特征映射:一个是逐层输入得到的映射;另一个是跳过一个或者多个卷积层的捷径连接。
在ResNet中,捷径连接被简单地表示成恒等映射,他们的输出被添加到堆叠层的输出,相加以后再一起输入到下一层,恒等捷径连接既不添加额外参数也不增加计算复杂性。
简而言之,ResNet的中心思想就是学习一个关于F和xi的加法残差函数,其关键在于使用了恒等映射。ResNet(超过100层)通过堆叠多个残差单元构造出整个网络,实验结果在一些具有挑战性的识别任务中显示出高水平的准确性。即使它具有一个很深的网络结构,整个网络仍然可以利用随机梯度下降法(stochastic gradient descent, SGD)与反向传播进行端对端的训练[10],并且能够得到较快的收敛速度。
2 深度多级残差网络的SR重建
本文网络模型的全部结构如图1所示,整个网络有14个卷积层,包括预处理网络、残差网络、重建网络3个部分。预处理网络用来进行特征提取和表示;残差网络是整个网络结构的核心和解决超分辨率重建问题的关键;重建网络是后处理步骤,把通过残差网络学习得到的高分辨率图像块聚合形成最终的高分辨率图像。

图1 深层多级残差网络的网络结构
2.1 预处理网络
在预处理网络中,具体参数设置为:一个卷积核大小为3×3的卷积层,并将其通过修正线性单元(rectified linear unit, ReLU)[11]增加网络非线性来实现图像块的提取和表示。需要说明的是每个卷积层后面都会通过ReLU对其进行处理,篇幅有限,下面不再赘述。预处理网络具体是指将输入的灰度图像或者RGB图像转换成一组特征图,即将图像块从图像空间映射到特征空间。每个输入图像块经过预处理网络得到一个高维向量,这些向量构成一组特征图,此操作的计算公式为:
x1=ReLU(0,W0*X+B0)
(4)
其中,W0、B0分别为卷积层的权重和偏差;*为卷积操作;ReLU(max(0,x))为滤波响应。简单地说,这些通过预处理网络学习到的特征图是为接下来的残差网络而准备的。
2.2 残差网络
本文中提出深层多级残差网络,残差网络部分是整个超分辨率重建网络模型最核心的部分,位于图1中的中间位置。它共有12个3×3的卷积层,每个卷积层后都跟随着一个ReLU激活函数(由于篇幅问题,激活函数没有在图1中表示出来),此部分网络由4个残差单元组成,其中3个残差单元结构类似,另一个残差单元位于整个多级残差网络的最外层,并且涵盖3个残差单元,其中一个残差单元如图2所示。
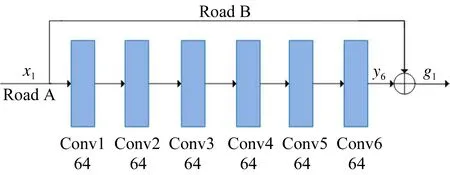
图2 残差网络部分结构
用xi、yi分别表示第i个卷积层的输入向量和输出向量,gl表示第l个残差单元的输出,3个类似的残差单元分别标注为第1、2、3个残差单元,最外层的残差单元为第4个残差单元,则有:
yi=F(xi,{Wi})
(5)
其中,yi=xi+1。
图2中的6个3×3的卷积层作用和结构完全一致,即用来学习低分辨率图像块和高分辨率图像块之间的残差映射(这相当于图像退化模型中损失的信息),换句话说,在图2中,用Road A来学习残差映射f(x),Road B即表示捷径连接,将输入的低分辨率图像块线性传递到残差单元的尾部,和Road A产生的残差映射融合用来输出本单元的预测高分辨率图像块。位于残差单元末端的g1为:
g1=y6+x1
(6)
比较(2) 式、(3) 式、(6) 式,虽然三者之间并不完全一样,但是确有相同的形式,(6) 式中的y6、x1分别与(2) 式中的I、X相对应。因此,网络反向传播过程在近似模拟图像退化模型,而前向传播过程则是通过模拟图像退化模型的逆过程来学习残差表示。同理可得其余3个残差单元的输出,即
g2=y9+y3
(7)
g3=y12+g1
(8)
g4=g3+y0
(9)
2.3 重建网络
最终残差网络输出的特征映射代表高分辨率图像块特征图,需要经过重建网络融合成高分辨率预测图像,并将它们从特征空间转换回图像空间,即将特征图由多通道变成1通道的自然图像。因此,在这部分本文定义一个3×3的卷积层来形成最后的高分辨率图像,即
Y=Wend*yend+Bend
(10)
其中,Y为最后整个网络的预测高分辨率图像;yend为残差网络中最外层残差单元的输出。
2.4 训 练
为了更好地训练网络,本文采用均方根误差(mean square error,MSE)作为损失函数。MSE更接近于人类视觉感知,而且客观实验结果显示使用MSE获得的图像质量也得到了显著的提升。MSE的计算公式为:
(11)
小行星撞击地球的过程如图12所示。在能够对近地小行星提前预警的前提下,将小行星分裂成碎片或者改变小行星轨道是避免其撞击地球的两种基本方式。根据防御技术的作用时间以及目标小行星尺寸的不同,安全防御技术可分为3大类[38-39]:1)利用核爆炸摧毁小行星或者改变行星轨道,防止尺寸较大且预警时间较短的PHAs撞击地球;2)利用航天器直接撞击小行星改变其轨道,此方法适用于防御尺寸较小且预警时间较短,或者尺寸较大且预警时间较长的PHAs;3)利用长期作用力改变小行星轨道,通过接触式或非接触式作用使小行星产生微小速度变化,随着时间推演进而演化为极大的轨道变化。
3 实验与分析
不同的文献采用不一样的学习方法,使用的训练集也可能不一样,例如文献[12]使用的是2个训练集,其中一个来自于文献[2]提出的包含91幅图像的训练集(91 images),另一个则是在此基础上增加200幅来自伯克利分割数据集(BSD200)[13](291 images)。而SRCNN使用了更大的包含395 909幅图片的ImageNet数据集作为其训练集。本文使用的训练集则是对文献[2]的91幅图像进行扩充,先将训练集原始图片进行镜像垂直翻转,得到182幅图像,再对这182幅图像分别进行逆时针旋转0°、90°、180°、270°,因此最后本文所使用的训练集包括728张图片。
本文采用的是现在比较常用的3个测试集:Set5[13]、Set14[14]、BSD100[15]。3个测试集分别包括5、14、100张图片,数据集的作用也不尽相同,Set5、Set14通常被用来评估传统图像处理方法的优劣,而BSD100则是对应着变化多端的自然场景。
实验环境包括硬件设备和软件配置,相应的硬件参数为Intel Core i7-4790K 4.0 GHz,1×NVIDIA Titan X GPU,软件配置为Ubuntu 14.04平台上的深度学习开源平台Caffe[16]以及Matlab 2014a。
3.1 参数设置
原始的ResNet使用了152个卷积层来完成分类任务,达到了顶尖的效果,但是其对硬件平台的要求也很高,因此,根据实际实验条件,只能缩减残差网络的层数,使用一个相对“浅层”的残差网络。
由上节描述可知,本文采用的深层多级残差网络一共包含14个卷积层,用Xavier方法[17]对所有卷积层进行权重初始化。考虑到本文的网络结构较为“浅层”,因此把此网络的全部卷积核大小统一设置为3×3,预处理网络与残差网络中的滤波器个数均为64,最后的重建网络部分的滤波器个数为1。本文使用随机梯度下降法来训练网络,根据经验,网络的动量参数(momentum parameter)仍然设置为0.9,学习率大小固定为0.000 01,填充值为1,步长大小也设置为1。分别把扩展因子Scale设为×2、3、4,使用Set5、Set14、BSD100这3个测试集分别测试,整个训练过程中,实验超过3 000 000个迭代次数(大约1 000次训练)。
值得注意的是,相对于颜色,人类的眼睛对图像细节的亮度更加敏感,因此在进行图像预处理时,首先将RGB通道的图像转换为YCbCr通道的图像,然后对Y通道使用深层多级残差网络进行超分辨率重建,而对Cb和Cr通道均使用与其他方法[2-5]相类似的双三次插值算法,直接产生高分辨率的Cb、Cr通道图像。
3.2 结果与分析
本文把深层多级残差网络和SRCNN[5]的实验结果进行比较,首先用91幅图像分别训练这2个网络结构,这个过程耗时12 h左右,然后使用Set5测试集,扩展因子为3时,分别对比2个模型随着时间和训练次数的增加测试损失函数的情况,结果分别如图3所示,其中深层多级残差网络用Ours表示,其他图表中类似。
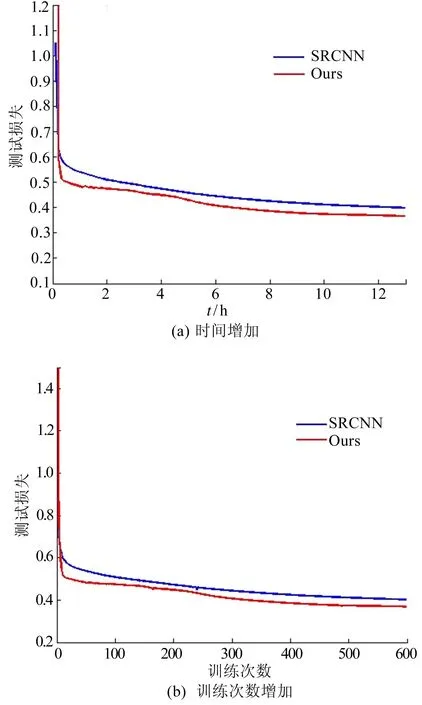
图3 2个模型随着时间和训练次数的增加测试损失函数结果
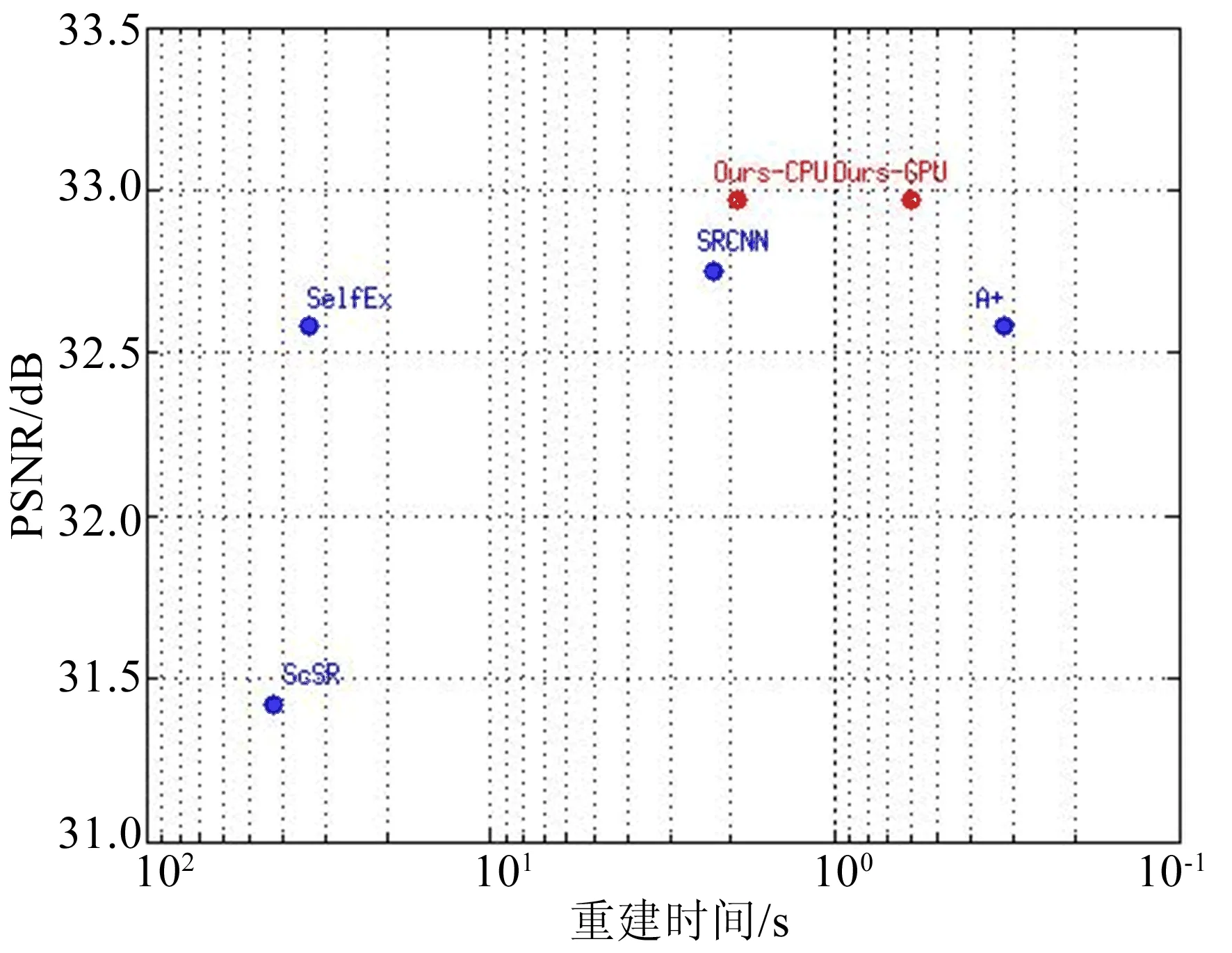
图4 在Set5训练集上各个算法的重建时间
图像客观评价指标主要是峰值信噪比(peak signal to noise ratio,PSNR)和图像结构相似性(structurnal similarity,SSIM)。前者对处理后的结果与原图相比的误差进行定量计算,PSNR愈高,说明失真愈小;SSIM越逼近1,说明处理后的结构与原图结构极为近似,即生成的结果图更好。本文对深层多级残差网络和比较典型的超分辨率重建方法进行了定性和定量的比较,算法包括Bicubic算法、ScSR算法、A+算法、SelfEx算法、SRCNN算法及SRCNN-L,因为本文用91幅图像训练了SRCNN算法,而SRCNN-L是由ImageNet训练得到的,所以两者的结果有些不同。在Set5、Set14、BSD100这3个不同测试集上,扩展因子分别设为×2、×3、×4,计算各个PSNR和SSIM的平均值见表1所列,表1括号内为SSIM平均值,PSNR的单位为dB。
由表1可知,深层多级残差网络虽然在BSD100上的结果不是最佳的,但是在Set5、Set14的PSNR和SSIM的值基本均优于其他方法。Set5、Set14通常被用来评估处理传统图像方法,而BSD100则对应着变化多端的自然场景,这说明深层多级残差网络在处理传统图像上占很大优势。
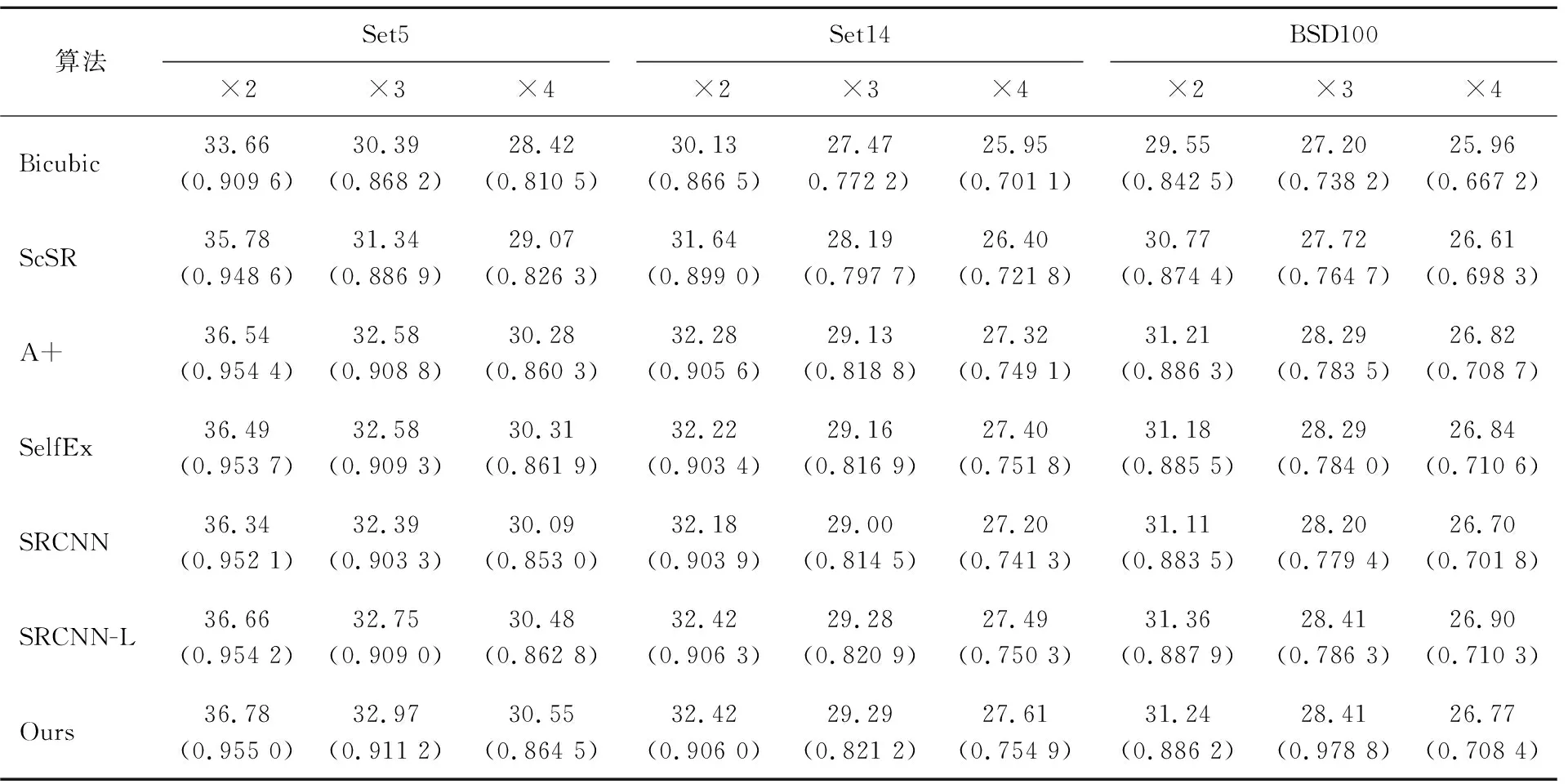
表1 PSNR和SSIM指标对比
主观视觉对比如图5所示,图5中从左到右图片依次来自于Set5、Set14、B100;从上到下方法依次为ScSR、A+、SRCNN、深层多级残差网络。
从图5可以看出,ScSR方法虽然对图像质量有了一定的提升,但仍存在噪声和模糊。A+和SRCNN方法则很好地恢复了边缘信息,但去除噪声仍然不是很好。从对比结果来看,深层多级残差网络重建结果不仅在客观评价上有明显的质量提升,而且在主观视觉上更加清晰,也很好地去除了噪声。
4 结 论
本文研究了一种图像超分辨率重建方法,即深层多级残差网络。其关键步骤是通过网络直接学习高分辨率图像和低分辨率图像之间的残差映射,在原始简单的残差结构中使用多级捷径连接,对于单幅图像超分辨率重建来说,这是一个高效的方法,且因为网络具有较少的预/后处理,便于优化,因此相对于其他深度学习算法,网络结构更加轻量化。采用PSNR和SSIM对各种算法进行定量测试,结果表明本文算法能够产生具有较好视觉效果的高分辨率图像。由于网络层数的加深可以增加网络的性能,因此下一步应该构建更深层的残差网络解决图像的超分辨率重建问题。
猜你喜欢
红外技术(2022年11期)2022-11-25
建材发展导向(2021年7期)2021-07-16
健康体检与管理(2021年10期)2021-01-03
计算机应用(2020年7期)2020-08-06
马克思主义哲学研究(2020年2期)2020-07-21
雷达学报(2020年3期)2020-07-13
水利规划与设计(2020年1期)2020-05-25
艺术科技(2018年2期)2018-07-23
太空探索(2016年3期)2016-07-12
太空探索(2015年8期)2015-07-18
