
基于Adaboost-SVR模型的我国碳排放强度分析与预测*
2020-11-02 12:13梁小林陈敏茹
经济数学 2020年3期
梁小林,秦 欢,陈敏茹,许 奇,梁 曌
(长沙理工大学 数学与统计学院,湖南 长沙 410114)
1 引 言
大量研究表明气候变暖的主要原因是全球温室气体的排放,尤其是二氧化碳气体的排放,积极采取应对措施全面控制和减少二氧化碳气体排放迫在眉睫.改革开放以来,中国经济快速发展,中国成为世界第一大碳排放国,其碳排放的未来发展趋势也成为世界关注的焦点.在第21届联合国气候变化会议协议中,中国提交的国家自主贡献目标为:到2030 年单位 GDP 的二氧化碳排放量比 2005 年下降 60%~65%.为了实现这一目标,需要对未来碳排放走势进行分析与预测,并在此基础上,制定合理减排措施.
目前,有关碳排放研究的相关文献大致可分为两部分,一部分是基于碳排量的研究,另一部分是基于碳排放强度的研究.在碳排放量方面,朱勤等[1]基于改进的Kaya恒等式建立因素分解模型,应用LMDI分解方法分析中国1980-2007年的能源消费碳排放,其研究结果为国家产业结构调整提供了理论依据;Wei[2]采用投入产出分析法,计算了北京工业能源相关的 CO2排放量,并且从技术、部门关联、经济结构和经济规模等方面对驱动因素进行了结构分解分析(SDA);宋杰鲲[3]使用偏最小二乘回归方法选取多项因素建立中国碳排放预测的STIRPAT模型,分析各个因素对碳排放的解释作用,明确了碳减排应为重点关注的因素.Sun 和 Xu[4]提出了基于改进粒子群算法优化的BP神经网络模型,对1978-2012年中国河北省的二氧化碳排放及其影响因素进行了实证分析, 通过与其他两种方法的结果比较证明该模型的拟合和预测精度较高.梁一鸣等[5]利用STIRPAT模型分析中部六省 2000-2012 年碳排放量及其影响因素之间的关系,并且运用灰色 GM(1,1)模型,预测中部六省 2015 年、2020 年碳排放量.从上述文献可以看出对于碳排放的研究大多是基于碳排放影响因素分析,并且侧重于应用因素分解法.在碳排放强度研究方面,“碳强度”这一概念并不如碳排放一样普及,自我国使用碳排放强度指标制定减排目标以来,有关碳强度的研究日趋增多.林伯强等[6]研究了如何在保障经济增长条件下实现碳排放强度目标.寇静等[7]建立Arima模型,研究我国碳排放强度时间序列数据,对其长期变动趋势预测,发现仍呈下降趋势,但下降幅度与政府的期望存在一定差距.赵成柏等[8]将碳排放强度的时间序列的数据结构分解为线性和非线性残差部分之后,利用BP神经网络与Arima组合模型预测碳排放强度变化趋势.王锋等[9]运用协整分析和马尔可夫链方法对碳排放强度进行预测,并分析了能源结构优化对降低碳排放强度的作用.王彩飞[10]在分析确定碳强度的影响因素后提出了基于改进粒子群优化的极限学习机算法,对全国及9个典型省市的碳强度进行实证预测,预测结果显示该模型具有良好的拟合性能.目前,由于碳排放强度和碳排放的关联性,关于碳强度的研究基本上还是沿袭碳排放的研究方式.
上述文献分别使用不同方法从不同角度研究了我国碳排放量以及碳排放强度,但较少文献使用机器学习方法,本文提出Adaboost-SVR模型预测碳排放强度,支持向量机是基于统计学习理论和结构风险最小化原理的算法,在解决回归问题上效果很好[11,12],通常用于处理非线性问题,也擅长处理小样本数据集,对小样本有较好的拟合作用[13,14],适用于目前年碳排放量数据较少的现状.但是支持向量回归不足之处在于预测效果依赖于所选择的核函数和核参数,且目前没有很好的关于参数选择的理论支持.Adaboost算法可以提升任意弱学习器的性能,通过多次迭代降低预测结果的偏差,在训练过程中也不易发生过拟合[15],将Adaboost算法与支持向量回归结合,既可以对支持向量回归训练的学习器进一步提升,也可以降低参数选择带来的误差,在保证模型精度的前提下进一步提升模型的泛化能力.
2 研究方法
2.1 支持向量机回归
支持向量机(Support Vector Machine,以下简称SVM),作为传统机器学习的一个非常重要的算法,由Cortes和Vapink于1995年提出.支持向量机(SVM)本身是针对分类问题提出的,而支持向量回归(Support Vector Regression Machine, 以下简称SVR)是支持向量机原理在回归预测领域的运用[16-18],其相关原理如下.
设样本(xi,yi),i=1,2,…,n,xi∈Rn为输入量,yi∈R为输出量,SVR要求构建非线性映射φ(x),将原始数据映射至高维甚至是无穷维的特征空间中,然后在高维空间中建立样本的线性回归函数为
f(x)=wTφ(x)+b.
(1)
为避免过拟合,由式(1)可以得到式(2)的代价函数:
(2)
式中,C被称为惩罚函数,决定函数对于数据的拟合程度,|yi-f(xi)|为实际数据与预测数据的偏差.引入不敏感损失函数ε,只有当|yi-f(xi)|>ε时才计算损失,则式(2)的代价函数转化为式(3)和式(4)形式的目标函数.
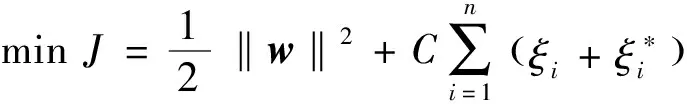
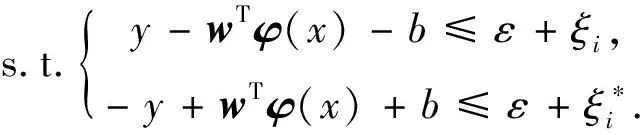
(3)
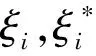
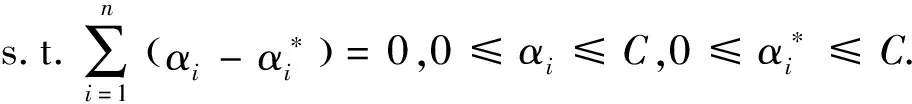
(4)
其中,K(xi,xj)=φ(xi)φ(xj)为核函数,其作用为将高维空间的内积运算转换为低维空间的核函数运算.最终得到的支持向量回归函数为:
(5)
2.2 Adaboost算法
Adaboost算法[19]是Boosting提升算法中最具代表性的一种算法,由Yoav Freund和Robert Schapire在1995年提出.该算法的核心思想是:对于指定的样本集数据,通过多次迭代反复修改样本权重分布训练一系列的基学习器,最终将各个基学习器组合建立一个强学习器.在每次迭代过程中,根据训练集中各个样本是否被正确学习以及上一次训练过程中样本权重来更新权重.对于正确被学习的样本,降低其权重,而错误学习的样本则要增大权重,之后根据新的样本权值分布再次迭代,这使得在下次迭代过程中,更加凸显错误学习的样本,如此重复进行,直到基学习器数达到事先指定的数目,最终将这T个基学习器通过各自权重进行整合,最终得到理想学习器.
2.3 Adaboost-SVR模型
支持向量回归的预测精度很好,但是其性能在很大程度上依赖于核函数以及其他参数的选择.一般惩罚系数C,不应过大也不应过小,过小会造成欠拟合,过大则过拟合.而在样本数量较少的条件下,惩罚系数C的取值不应过大,保证模型在样本外的泛化能力.针对任意的弱学习器,Adaboost算法可以提升其性能,使用SVR作为Adaboost的基学习器,既可以在一定程度上提高模型的预测精度,又可以降低参数选择带来的影响.
Adaboost-SVR算法的步骤为:
输入:m个样本数据训练集{Xi,yi}(i=1,2,…,m),迭代次数T
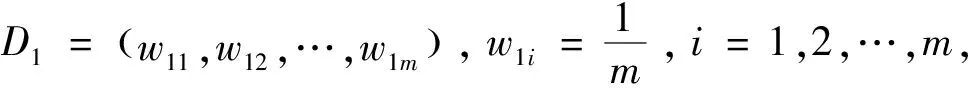
Step2训练SVR基学习器:对于迭代次数t=1,2,…,T;根据样本权重分布Dt(x)训练第t(x)个SVR基学习器Ht(x);计算训练集上的最大误差Et、每个样本的相对误差eti、以及学习器的回归误差率et.
Et=max|yi-Ht(xi)|,i=1,2,…,m.
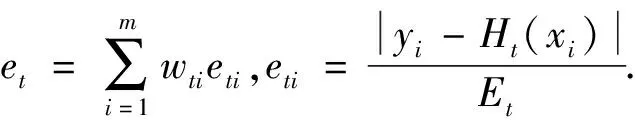
计算基学习器的权重需要的αt,
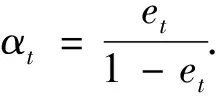
更新训练数据集的权值分布:
D(t+1)=(wt+1,m,wt+2,m,…,wt+1,m);
输出:最终学习器H(x)=Ht*(x).
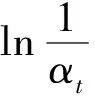
3 实证分析
3.1 数据来源与描述
由于不同研究机构的统计口径不同以及某些年份的碳排放量数据未公布,考虑可获得的碳排放量数据完整性,本文中碳排放量数据采用美国橡树岭国家实验室CO2信息分析中心[20]公布的数据,GDP数据来源于世界银行,能源消耗总量和人口数据来源于国家统计年鉴.
碳排放强度是指每单位国民生产总值的增长所带来的二氧化碳排放量,该指标主要是用来衡量一个国家经济发展同碳排放量之间的关系,反映了经济增长过程中的能源消耗情况.若国家在经济增长的同时,单位国民生产总值所排放的二氧化碳在下降,则说明该国实现了低碳发展模式.根据1960-2017年期间我国每年的二氧化碳排放总量以及1960-2017年国内生产总值,二者相除,可以计算1960-2017年碳排放强度,其结果如图1所示.由图1可知我国碳排放强度的趋势是阶段性变化的,第一阶段为1960-1967年,碳排放强度急剧下降,从1960年的130.44 t/万美元下降至1967年的59.30 t/万美元.第二阶段为1968-1978年,此阶段为缓慢上升阶段,碳排放强度从66.0 t/万美元,上升至97.31 t/万美元,虽然在1971年开始出现急剧下降,但仅在三年后又极速攀升,在这10年间碳排放强度上升31.31 t/万美元.第三阶段为1979-2002年,碳排放强度呈现稳步下降趋势,从1979年83.42 t/万美元的下降至2002年的25.71 t/万美元,其中1979-1993年的下降速度低于1993-2002年.第四阶段为2003年至今,该阶段前期碳排放强度出现了轻微的反弹,上升到26.82 t/万美元,随后便继续逐渐下降.虽然在不同时期存在波动,但长期来看,我国碳排放强度呈现逐步下降趋势.
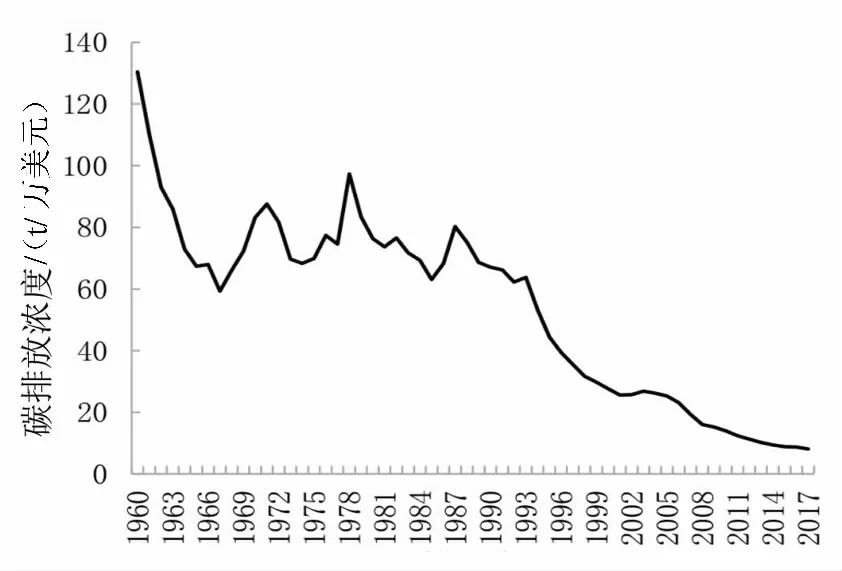
年份/年
3.2 数据预处理
3.2.1 平稳性检验
在对时间序列数据建模时,模型要求时间序列数据具有平稳性.从图1可以看出该序列具有明显的长期趋势,是非平稳时间序列,因此在建立模型之前需要对原数据差分使其平稳.
若将原始时间序列记为{xt,t=1,2,…,n},其中xt为每个时刻的序列观察值,则相距一期的两个序列值之间的减法运算称为1阶差分运算.记xt为xt的1阶差分:xt=xt-xt-1,通常1阶差分可以使时间序列平稳.
本文采用单位根检验,结果见表1,根据ADF值以及P值均可以看出原变量经过一次差分后,ADF检验值为-6.485,低于各显著水平下的临界值,且P值近似为0,可以拒绝原假设,差分后时间序列已经平稳.

表1 单位根检验
3.2.2 数据形式转换
在使用Adaboost-SVR对时间序列数据进行预测时,需要将数据转化为监督学习所需要的数据形式,通常采用滑动窗口法将数据{xt,t=1,2,…,n}转换为矩阵形式,构造样本{Xt,Yt},其中Xt={xt-m,xt-m-1,…,xt-1},Yt={xt},m为滑动窗口的大小,代表着用前m个数据预测第m+1个数据[21].在本文中通过对模型反复实验比较,取m=2,即用前两年的碳排放强度预测第三年的碳排放强度.
3.3 预测结果对比分析
根据已有的1960-2017年碳排放强度数据,经过数据预处理后,划分训练集和测试集,1960-2000年的数据集用于训练模型,2001-2017年的数据用做测试,做连续滚动预测检验模型性能.为了比较模型Adaboost-SVR的预测能力,同时也用相同数据训练了SVR、Adaboost-DT以及BP神经网络作对比分析,其中Adaboost-DT是以决策树回归[22,23]作为基学习器训练得到的模型.
本文选用均方根误差(RMSE),平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、MSE(均方误差)4类指标作为评价准则对误差进行度量,计算方式如式(6)~(9).
(6)
(7)
(8)
(9)
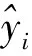
表2列出了各个模型的评价指标值,根据RMSE,MAPE,MAE和MSE的值大小来看,Adaboost-SVR模型的RMSE,MAPE,MAE和MSE均低其他3种方法,预测效果明显优于其他3种方法.若单从RMSE来看模型预测性能,Adaboost-SVR与Adaboost-DT相比性能提升了44%;与SVR相比提升了29%;与BP相比提升了45%.

表2 不同模型比较结果
图2给出了不同方法下对碳排放强度的预测结果.实际的碳排放强度值用红色线表示.从这个比较中可以看出,Adaboost-SVR明显优于Adaboost-DT;与BP相比,虽然在2002年和2003年BP的预测值更加贴合实际值,但总体来说Adaboost-SVR预测效果更好;与SVR相比,虽然SVR模型也较好地拟合出了碳排放强度的下降趋势,但预测精度低于Adaboost-SVR,说明Adaboost算法确实提升了SVR的预测精度.
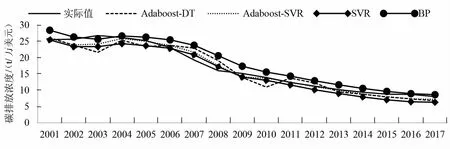
年份/年
综上所述,本文提出的Adaboost-SVR模型总体来说优于其他模型,可以很好地预测我国碳排放强度,在预测精度上较BP、Adaboost-DT和SVR模型有显著提高,说明了该预测模型是切实有效的,可以通过预测结果调整国家宏观政策,进而在2030之前实现我国提出的 “自主贡献”目标.
利用Adaboost-SVR模型对我国未来几年的碳排放强度进行预测,预测结果见表3.

表3 未来几年碳排放强度预测值
根据预测结果显示,2018年碳排放强度为7.268 t/万美元,2022年预测值则降至5.488 t/万美元,相对于2017年下降了2.614 t/万美元.总体来看,未来几年我国碳排放强度仍保持平缓下降趋势.
3.4 节能减排
当前我国经济进入转型期,处于后城市化和后工业化阶段,因此经济发展仍然需要消耗大量化石能源,进而导致碳排放量增加.虽然根据图1可以看出我国的碳排放强度下降趋势,但从图3可以明显看出国内生产总值增长曲线明显比碳排放量曲线陡峭,因此碳排放强度下降主要原因在于我国经济发展迅速,使得二氧化碳排放量的增长速度小于经济增长速度.为了确保实现国家自主贡献目标,即到2030 年单位 GDP 二氧化碳排放量比 2005 年下降 60%~65%,必须采取措施降低碳排放量.
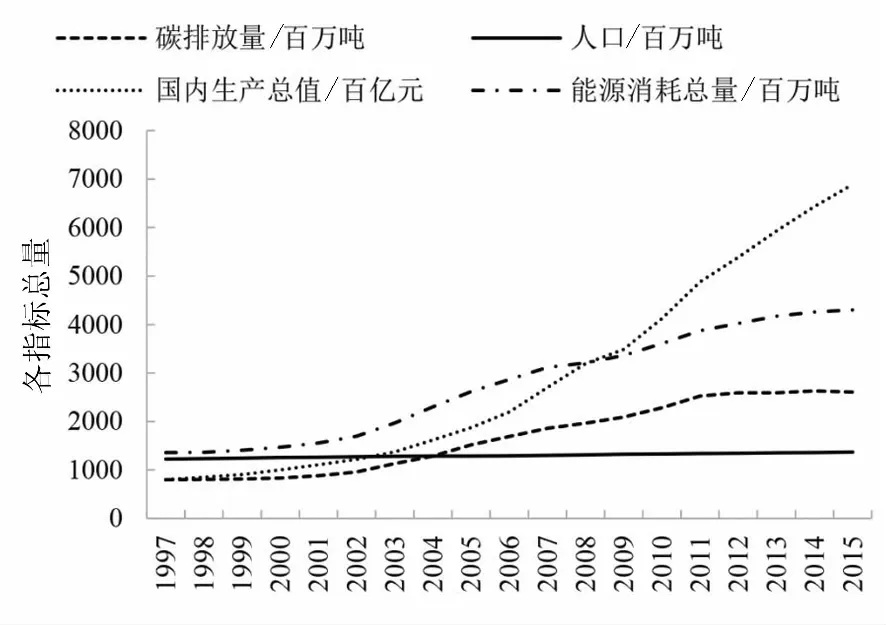
年份/年
3.4.1 碳排放量驱动因素分析
根据LMDI模型,本文将我国每年碳排放变化量分解为四种效应[24],即人口规模效应、能源结构效应、能源消费强度效应以及经济发展效应,这4种效应代表着影响我国碳排放的4种驱动因素.
根据图4可以看出,4种碳排放驱动因素中,能源消费强度效应为负效应,是使碳排放量减少的关键因素,通过提高可再生能源的技术开发将有效降低碳排放量问题.在能源结构效应、经济效应、人口效应3种效应中,经济发展效应影响最大,表明我国要发展经济能源需求极大;能源结构效应分解值时正时负,说明我国的产业调整力度还不够大,煤炭在化石燃料中仍占较大比重,如果不对产业结构进行调整,碳排放量将持续上升,从2012年开始,能源结构效应出现了负值,说明能源结构有望成为抑制碳排放的强力因素;人口规模对碳排放有正向驱动作用,主要是因为人口增加导致的能源消耗增加,而且城市化导致大规模建造城市道路等基础设施的水泥需求增长,这些都会直接产生碳排放.
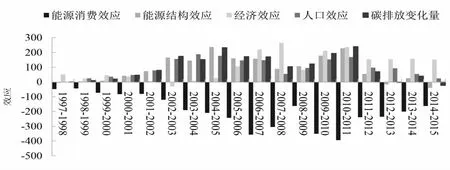
年份/年
3.4.2 相关政策建议
从能源结构层面来说,我国应调整能源产业结构,鼓励低碳经济发展.政府部门应该从宏观上调控政策,制定相应的碳管制措施,我国现有三大产业,第二产业带来的污染最多,应尽快将我国产业结构从第二产业向第三产业转变,强化人们的低碳理念,合理消费、绿色消费,不断发展绿色农业,减少高含碳量生产资料的使用,减少以煤炭为主的能源消耗,大力实施“煤改电、煤改气”政策.
从能源消费强度层面来讲,应大力提高对可再生能源的技术开发,大力发展资源节约型新型能源,加大技术投资力度,我国技术型人才应积极参与低碳开发,国家应根据其贡献给予相应奖励,刺激高技术企业发展,其次可以引进其他国家的先进技术,与我国的实际情况相结合,构建属于我们国家的低碳经济发展技术.
从经济发展来看,经济发展势必导致能源消耗,可以寻找合适的能源替代品,国家一级企业应考虑在不减缓经济发展的前提下,最大程度减少碳排放,应促进天然气应用,促进可再生能源利用,减少对化石能源的依赖.
4 结 论
自从我国提出以碳排放强度作为节能减排目标以来,有关于碳排放强度的研究已经成为热点问题,本文对碳排放强度时间序列的研究转化为监督学习,采用Adaboost-SVR模型预测长期趋势,既保证了小样本情况下的模型预测精度,又用Adaboost算法进一步提升了模型的泛化能力,MAPE,RMSE,MAE和MSE四个评价指标从多个角度表明组合模型优于Adaboost-DT模型、SVR模型、BP神经网络模型,可以用来预测我国未来的碳排放强度.而在如何制定减排措施方面,从我国碳排放量的LMDI分解结果看,能源消费强度效应抑制碳排放量增长,而能源结构效应、经济效应、人口效应是导致碳排放量增加的原因,应该据此实施合理高效的减排方案,例如调整产业结构,推动低碳工业发展,转变能源利用结构,提高能源使用效率等具体减排措施.
猜你喜欢
核科学与工程(2021年4期)2022-01-12
煤气与热力(2021年6期)2021-07-28
今日农业(2020年19期)2020-12-14
高师理科学刊(2020年2期)2020-11-26
————不可再生能源
家教世界(2019年4期)2019-02-26
中学物理·高中(2016年12期)2017-04-22
知识经济·中国直销(2017年3期)2017-04-16
——《2013年中国机动车污染防治年报》(第Ⅱ部分)
环境与可持续发展(2014年1期)2014-08-14
电力工程技术(2014年1期)2014-03-20
