
基于机器学习的智能TWAP和VWAP算法的研究及应用*
2020-11-02 10:21郑继翔洪轩儒李怡洁
经济数学 2020年3期
郑继翔,陈 卓,柯 军,黄 钰,洪轩儒,李怡洁
(招商证券股份有限公司 信息技术中心,广东 深圳 518000)
1 引 言
算法交易(Algorithm Trading)最早起源于美国,它采用量化分析手段,由计算机根据算法模型决定交易委托的下单时机,委托价格,交易数量与委托笔数等,自动发出指令实现证券买卖和资产组合管理、算法交易的主要目的是通过设计合理的交易策略,最大限度降低投资者交易成本,减弱市场影响,提高投资收益.算法交易中有TWAP,VWAP和IS等交易策略,在证券市场上,近50%的机构投资者的交易订单采用VWAP策略[1],TWAP与VWAP算法基础框架逻辑是将大额订单切分成slice,TWAP将大额订单在交易时间内等分,VWAP则是以历史成交量为权重进行订单切分,再将各个slice的分配量在对应的时间内进行二次切分成subslice,并根据算法的成交进度制定每个subslice具体的委托方式,进行下单,通过二次切分的方式降低大额订单带来的冲击成本.
关于TWAP与VWAP算法的改进研究主要有两方面.第一方面集中在交易量分布的预测问题上,方兆本和镇磊[2]提出一种考虑非对称效应的ACD模型来选择交易时点,利用分时的VWAP算法来决定委托量,最后利用股票价格波动预测来修正交易量和委托价格.Le和Mercier[3]采用主成分分析法将成交量分解为共同部分和特殊部分,Bialkowski、Darolles和Le[4]联合运用主成分分析法和因子模型分解成交量,采用ARMA模型和SETAR模型对特殊部分建模,并首次提出动态调整的VWAP策略.夏晖和杨岑[5]则从个股与市场成交量变化趋势的关系角度出发,推导个股成交量与市场趋势之间的关系,预测成交量日内分布并构建动态VWAP策略.LIU Xiaotao和LAI Kin Keung[6]将日内交易量分为日平均成交量与异常残差成交量,通过使用移动平均的方法预测日平均成交量,使用SVM的方法预测残差成交量,提高了VWAP策略的跟踪性能.第二方面是改进交易策略.曹力、曹传琪和邵立夫[7]利用价格信息提出了一种改进的VWAP策略,该策略通过分析交易日内各个决策点前的股票价格变化对传统VWAP策略的决策进行调整,从而提高了执行稳定性,并节省了交易成本.镇磊[8]利用高频数据处理方法提出了一种适合A股市场交易规则的交易算法,以及一种基于自相关的分时的VWAP算法,并实证检验了其有效性.
通过以上综述可知,目前关于交易量的研究十分充足和完善,研究重点多放在通过预测交易量的分布来提升算法交易的绩效上,存在以下几点值得关注的问题:
1)特殊市场环境下成交量预测的准确度.大多日内成交量分布的预测方法所选择的因子为历史的成交量信息,预测的准确率严重依赖于市场交易惯性的保持,基于此方法所优化的交易算法,对市场突发状况的变化缺乏足够的灵活性.在这类较为特殊的市场环境下,模型捕捉不到市场交易行为的变化,使算法的下单分布与市场相去甚远.
2)数据来源与因子类型.传统方法中,预测模型所构建的因子类型,多集中于传统的技术面原始因子,诸如历史价格与收益率(日级、分钟级、tick级)、历史成交量(日级、分钟bar级别)等,数据来源为Level I的市场行情.由于数据来源有限,故而因子种类较为单一,难以刻画市场中的博弈性交易对未来行情走势的影响.
3)预测模型的输出结果对交易算法优化方式.传统的模型大多提供的是对于未来交易量或价格的数值或变动方向的预测结果,从而提供择时性质的交易策略.事实上很多预测模型在预测的过程中会提供很多重要的中间信息,譬如对所预测未来事件的概率分布,此类信息能更好地指导算法下单.
4)预测模型与算法的结合方式.市场行情预测模型、算法本身的交易逻辑二者构成算法两大核心模块,但传统的预测模型与算法本身的交易逻辑割离,无法针对每一类算法的独特逻辑框架与短板进行改进优化.以TWAP与VWAP算法为例,传统的预测方法大多只涉及日内交易行情的预测,根据其结果指导算法在优势时点采取相应的策略,却没有精确结合到算法本身切片、切片量转移、执行结果实时反馈等逻辑层面上的优化.
鉴于以上几点,本文提出了一种新的算法优化机制,将算法交易与机器学习相结合,改进TWAP与VWAP算法,达到帮助投资者隐藏交易意图、降低交易成本与市场影响的目标.该方法主要包括以下几个方面:
1)利用基于逐笔成交合成的1分钟粒度高频实时资金博弈数据构建预测因子库,采用机器学习的方法,通过Logistic回归训练分钟价格预测模型,输出时间区间的价格概率分布,较为精准、及时地捕捉实时市场交易信息并加以利用,并在模型有效期过后及时更新模型.
2)引入铺埋单机制,利用短期价格预测模型得到的概率分布,以最优化期望执行均价为目标,保证一定期望完成度的基础上,求解不同价格档位下铺埋单的比例系数的最优解,在对原算法订单进行拆分后,进行埋单、铺单,以被动成交的方式减小交易成本.铺单:TWAP或VWAP算法执行过程中,在subslice启动前,预留一定比例的委托量提前在优势价格档位下限价单,若该限价单在subslice生命周期内不成交,则该委托量转移至后续subslice进行委托.埋单:在slice启动前,预留一定比例的委托量提前在优势价格档位下限价单,若该限价单在slice生命周期内不成交,则该委托量转移至后续slice进行委托.
3)针对不同证券的特点训练出不同的模型及铺埋单参数,使得执行参数与标的特征紧密相关.
4)减小随机切片量对算法的影响,在隐藏交易意图的同时,保证各个价格档位的委托量符合预期.
2 智能算法概述
2.1 算法执行架构
图1为智能TWAP与VWAP算法执行的架构,本文所论述的绩效优化模型均在此架构上进行执行和测试,它主要包含以下几个部分.
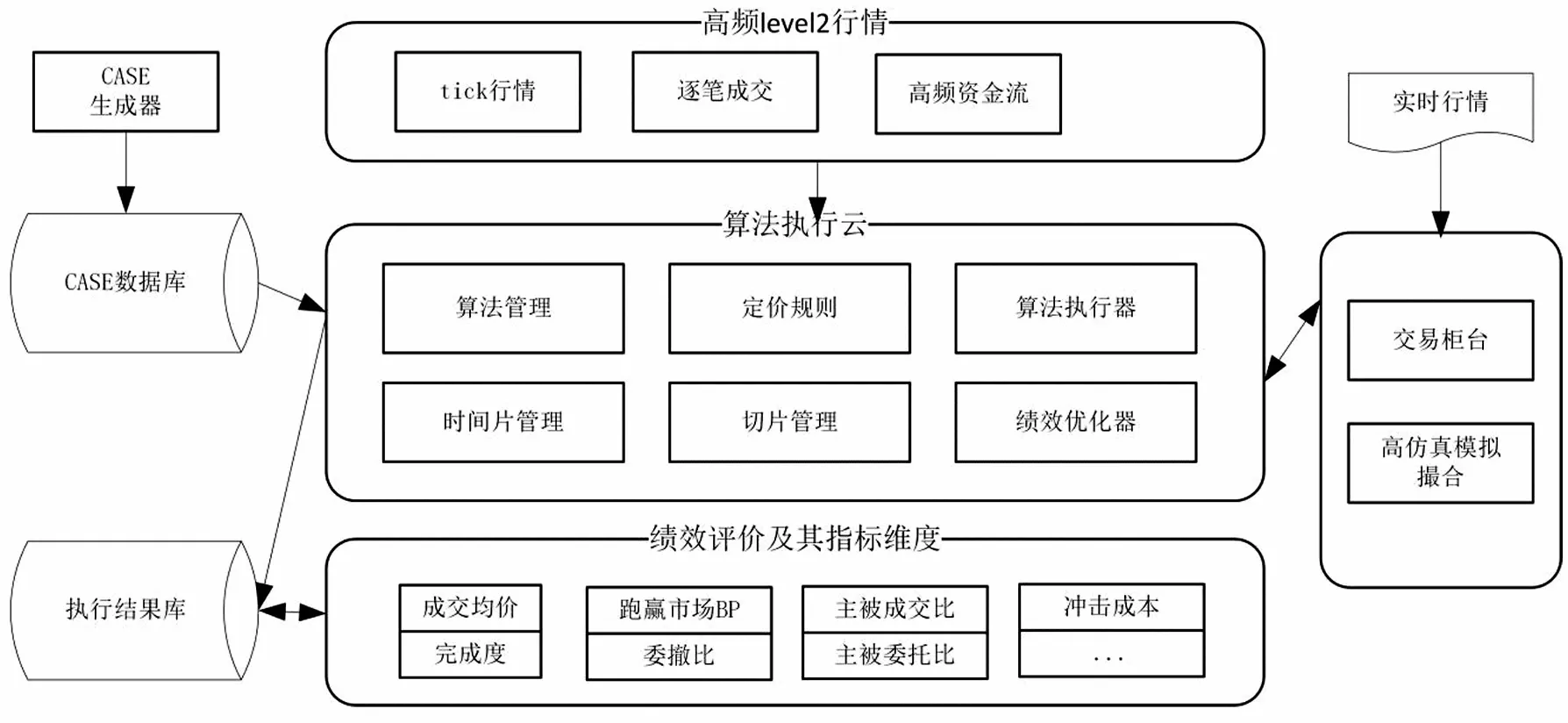
图1 算法执行架构
2.1.1 算法执行云
它包含了算法管理、时间片管理、定价规则、切片管理、算法执行器、绩效优化器等子模块,通过加载订单CASE,自动构造订单请求,并按CASE指定的算法参数执行,其中核心执行逻辑如下:
Step 1将大额订单进行首次分割,根据输入的切片时长将设定的交易时间切分为若干slice,无法整除部分归入最后一个slice.
Step 2slice继续切分,形成subslice,对subslice的时长、开始时间、分配量进行随机处理,控制分配量满足最低佣金的限制,同时控制subslice运行时间均匀铺满整个slice.
Step 3每个subslice启动之前计算订单真实完成度,同时计算当前时间的目标完成度,根据真实完成度与目标完成度之差确定subslice的定价规则,若执行进度超过预期,委托价格会偏保守,反之,委托价格会偏激进.
在算法执行过程中,会利用绩效优化模型输出的最优化订单参数,优化算法执行绩效.
2.1.2 高仿真测试
通过使用交易所的level 2实时逐笔行情,按照市场的实际流动性情况,对柜台报送的订单进行高仿真模拟撮合,当价格到达委托价格时,根据订单的排队情况以及市场对手方委托量,对订单进行撮合成交,以提高仿真测试的真实性.
2.1.3 绩效评价
它通过对算法订单执行过程中产生的委托、成交等数据进行计算和统计,输出成交均价、完成度、跑赢市场BP(basis point)、委托撤单比例、冲击成本等评价指标,完成交易闭环.
2.2 算法优化架构
如图2所示,为算法优化的架构,它主要包含两个核心的模块,也是本文将要论述的重点模块.

图2 算法优化架构
2.2.1 离线训练
该模块主要是对证券的短期价格走势进行建模,首先获取所有证券的历史分档资金流数据,并按一定的规则进行样本筛选,输出模型的支持证券集合,然后对过滤后的样本进行统计,输出证券波动的Tick Size,该Tick Size将决定了模型的分类变量跳动范围,最后通过从标的证券的资金流数据里提炼因子,并与短期价格区间分类之间的关系进行建模,寻找出最优的模型,并输出模型文件.
2.2.2 在线预测和优化
该模块通过加载离线训练的模型文件、Tick Size文件、并利用实时获取的资金流数据,预测证券的短期价格区间,并转换为成交概率,输入到铺埋单优化器中,对铺埋单比例参数进行优化,其中优化器以最小化子切片的VWAP作为目标函数,并限定参数比例、子切片完成度、铺埋单期望收益等作为约束条件,根据SLSQP(Sequential Least SQuares Programming)来进行最优化求解,最终输出铺埋单委托价格、委托比例等参数,达到优化算法切片订单的目的,以便指导云端算法执行服务进行最优化下单.
3 算法绩效优化模型
算法绩效优化流程如图3所示.

图3 算法绩效优化流程简图
3.1 短期价格预测模型
按照前述切片规则,在各个子单的启动时,引入短期价格预测模型,通过输入历史量价数据,对未来子单生命周期内的价格波动情况进行预测,根据得到的价格分布在不同的价格档位铺埋单,使子单能以更优的价格委托并成交.预测模型训练器考虑使用分类器,完成数据预处理后,通过基尼系数方法从因子库中筛选出评分靠前的衍生因子与时间序列滞后期数,最后使用Logistic回归得到符合要求的模型.
3.1.1 自变量——因子定义(factor definition)
目前在短期价格预测分类模型的研究与实践方法上,大致有两种方向:①根据经验,选取传统的具有普遍经济学解释性的解释变量作为模型因子,辅以机器学习模型筛选出其中符合建模情境的有效因子进行模型训练;②完全依赖机器学习的方法,只输入基础因子(量价数据),不人为构造中间衍生因子,通过训练器得到测试效果优异的因子,而完全忽略生成的衍生因子的实际解释意义.本文将以上两种方法结合,通过输入基础因子数据,根据快照行情数据特征、历史统计数据与相关性分析,人为构造一系列中间衍生因子g(·),如式(1),构建该预测模型的因子库,再利用机器学习模型筛选出衍生因子中的优异因子,既减小了因子的局限性,又保证了因子的实际解释意义.
X=[g0(vol,price),g1(vol,price),g2(vol,price),…,gn(vol,price)]
(1)
在因子的选择方面,模型使用分钟粒度实时高频分档资金流数据(以下简称扩展分钟bar数据),并选取高开低收以及主买主卖量数据作为基础因子,以此为基础构造一系列不同类别的衍生因子,包括交易量类、资金流类以及收益损失率类等.基础因子与部分衍生因子定义如表1与表2.

表1 基础因子定义

表2 衍生因子定义
由于篇幅局限,上表中仅列举了模型因子库中的部分因子.因子库构造完毕后,通过随机森林的因子评价体系筛选出表现突出的因子进行模型训练.
3.1.2 因变量——类别定义(class definition)
价格预测的最终目的是为了获得切片的委托指令,即铺埋单在各个档位的委托量,因此需要以前一个扩展分钟bar的收盘价为基准,对每个bar根据价格的最高最低点进行类别划分,而买方铺埋单与卖方铺埋单分别关注价格在预测期内的下跌量与上涨量的问题,故买卖模型的类别分别定义如表3所示.

表3 类别定义
其中n为起始的铺埋单档位.本文设定如下:对于铺单而言,n=1,即从上个bar收盘价的下(上)一个档位开始考虑铺单;对于埋单而言,n=3,即从上个bar收盘价的下(上)3个档位开始考虑埋单.tick size为档位价格差,过对每支标的统计得出.
通过该分类模式,实现了对每个分钟bar价格峰值情况的归类刻画,为后续铺埋带参数优化求解提供价格情况输入.
3.1.3 模型训练
图4为模型训练的结构,下面对各个模块进行逐个介绍:

图4 模型训练结构
1)数据集构造与预处理
因子库中分别存在交易量、收益率等衍生因子类别,其中交易量类因子为二维序列(档位维度与时间维度),收益率类因子为一维时间序列,故需要对交易量因子的档位维度进行处理,处理后训练模型输入的因子与因变量数据结构如表4所示.
表4中P0列为该bar中的收盘价,Pi(i=…-2,-1,0,+1,+2…)为距该bar收盘价i个档位的价格,即(…P-2,P-1,P0,P+1,P+2…)为该bar的交易价格以P0=close为中心的一个从小到大的排列,为基础因子序列(basic factor);(R0,R1,…)为不同定义类型的收益率衍生因子(derivative factor)[9].除了基础交易量因子,输入的因子数据还包含衍生因子(如上衍生因子变量表定义)及其各自的滞后项,该表不一一列出,基础因子与衍生因子共同构成模型因子库;Y为bar的类别标记时间序列.数据集表明,模型利用t时刻所获取的所有历史信息预测未来bar的价格分布情况.
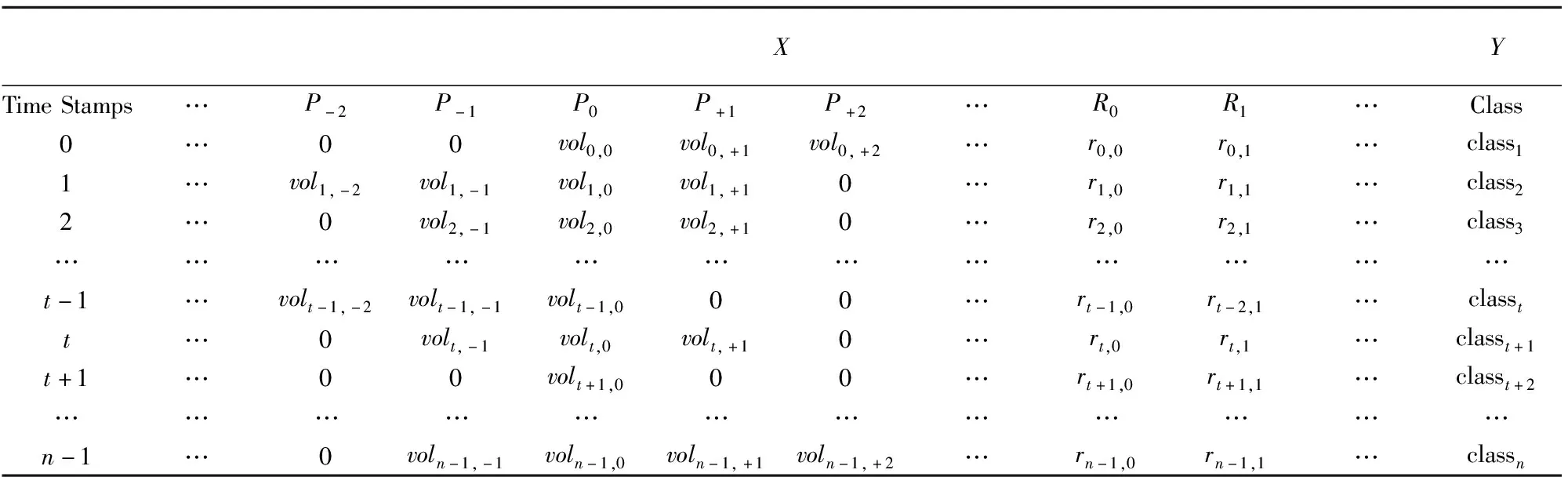
表4 数据结构
数据预处理方面,模型采用因子变量时间序列标准化的方法,排除因子选取与回归训练中量纲问题对结果造成的影响.
2)因子选取
完成因子库构建后,需要筛选出对未来bar的类别指标具有解释性的因子.考虑在多分类模型因子选取中,需要测试比较很多训练模型以评估因子效果,测试准确度(test error)对于比较不同训练模型的错分类程度敏感性不足,故本文采用随机森林分类模型库中的基尼系数(Gini index)方法对模型因子库的因子进行重要性(Feature Importance)评分并根据得分排序,基尼系数计算如公式为
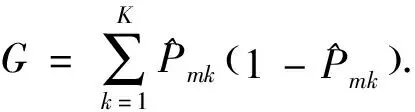
(2)

待选因子包括因子库中的所有基础因子、衍生因子及其各自的时间滞后项(lag).基尼系数反映了信息熵值,即训练得到的各个类别的纯度,故因子的评分值能敏感地评估因子的有效性,从而更好地筛选分类模型中的有效因子.因子库中各因子的评分如图5(只列举因子库中的一部分):

图5 因子评分
3)回归训练器
通过前述步骤,得到如表4所示的数据结构.根据因子重要性排序图,本次模型筛选出的基础因子变量

表5 上涨预测

表6 下跌预测
由表5与表6的结果表明无论在上涨还是下跌测试中,主板市场的模型预测准确度均比较高,所选因子解释力度较强,中小板次之,创业板最小.说明主板市场的量价关系较为明显,中小板与创业板市场资金量较少,证券流动性较小,容易受到其他外生变量的影响,故因子解释力度稍弱.
3.2 铺埋单参数优化模型
由训练器训练得到预测出模型后,在TWAP或VWAP算法运行过程中,通过实时输入的扩展分钟bar行情数据,可由分类器输出各个预测类别的预测概率,即未来价格(未来分钟bar)在预测期内能达到各个铺埋单档位的概率,该概率可指导铺埋带参数的生成.
P=(p1,p2,p3)T子切片计划量为vol,铺埋单比例向量为r=(r1,r2,r3)T,l=(1,1,1)T,D为买卖方向,买为1,卖为-1.优化模型如如下公式
(3)
s.t.rTpl>M,
其中,目标函数f(r)为切片的期望VWAP;M为要求的期望完成度,对于铺单,M=0.8,对于埋单,M=0.95.最后一个约束条件代表铺埋单带来的期望收益必须超过拆单所增加的手续费.由以上模型可求解出子单的铺埋单比例系数,进而确定铺埋单的委托量.
短期价格预测模型与铺埋单参数优化模型的结合将算法改进得更加智能和有效.训练得到预测周期内的市场量价关系,优化模型则对大额订单进行拆分以降低对市场冲击,使得算法的执行绩效得到较为显著的优化.
4 算法评估与结论
4.1 测试方法
对各个测试标的在波动市、顺单边市、逆单边市等不同行情下进行测试,发现算法在波动市下有较好的表现,在顺、逆单边市下表现略差;此外,在传统算法与智能算法对比测试中,发现智能算法的执行绩效显著优于传统算法;最后,针对不同板块、不同市场的标的进行测试,发现主板的执行绩效能够稳定地跑赢市场均价,中小板和创业板执行绩效的波动略大于主板,国债及基金的表现也十分稳定.
4.2 算法表现
通过生成大量case进行3个月的全市场仿真测试,将传统算法与智能算法跑赢市场的BP进行统计分析后得到如图6所示(仅以股票为例)。图6左右侧的子图为传统算法(original)与智能算法(AI)跑赢市场BP的统计,从上往下的子图分别为主板(Main board)、中小板(SME board)、创业板(Second board)相应的统计结果.从图中可以看出,传统算法由于其简单的大比重随机切片模式,跑赢市场BP的分布在大数量case测试下呈现出类似正态分布的特征;智能算法的表现均优于传统算法,说明对随机切片量的控制、引入量价预测模型等措施在各种市场行情、各类不同股票下均取得了显著的改进效果,表现在以下方面.
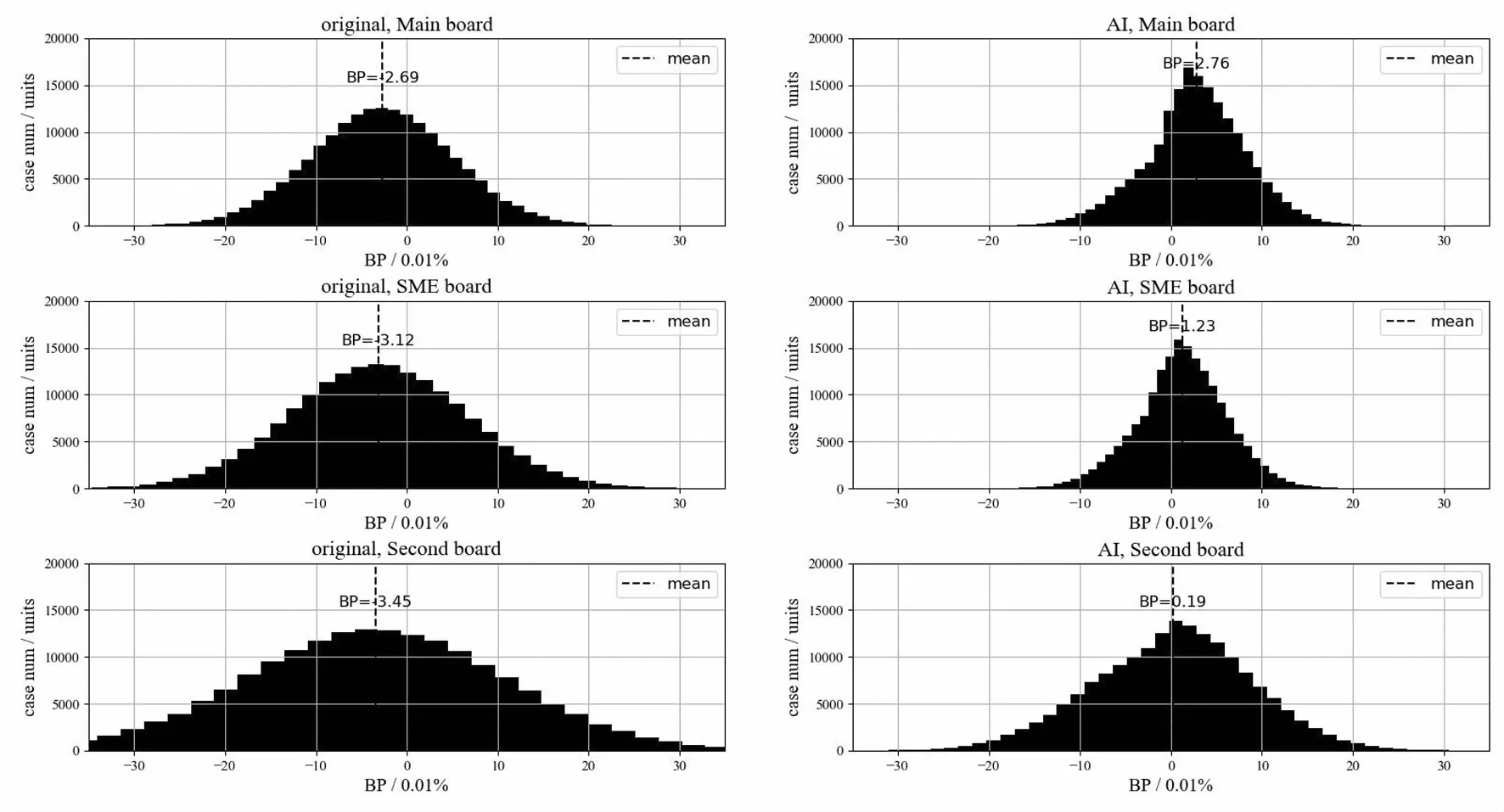
图6 传统算法与智能算法跑赢市场BP统计
1)在跑赢市场的平均BP层面(均值层面),无论是传统算法还是智能算法,根据图中虚线所示均值可以看出,跑赢市场的BP均值均是主板>中小板>创业板,且智能算法的改进效果也是主板最明显,创业板最弱.这说明了随着市场资金流动性、资金量等因素的增强,交易算法的表现均得到提升,价格预测模型所反映的量价关系更加准确.
2)在稳定性层面(方差层面),无论是传统算法还是智能算法,根据测试case分布的中心集中度可以看出,稳定性均是主板>中小板>创业板,且智能算法不仅对跑赢的BP均值进行改进,还显著地提升了算法的稳定性.这说明智能算法不只相对于原算法能跑赢市场更多BP,而且能更加稳定地跑赢市场.
3)在跑赢市场BP的集中度层面(偏度层面),传统算法跑赢的BP量集中于均值,分布趋近对称;而智能算法方面,主板与中小板市场的测试表明,BP分布为正偏态分布.这说明跑赢的BP多集中于均值附近的某个低点,即右半部分的曲线比较平缓,并且其尾线比起左半部分的曲线更长、表现极佳的case数目比表现极差的多,算法表现的上限较高,而创业板的情况则相反.
4.3 总 结
本文对在传统TWAP与VWAP算法上加入短期价格预测模型与铺埋单参数优化模型进行了实证研究,利用logistic分类器训练量价模型,以该预测结果为入参构建铺埋单参数优化模型,并针对各个标的、不同行情进行了全市场高仿真测试,对比分析了传统TWAP与VWAP算法与加入模型的智能TWAP与VWAP算法的表现,研究结果表明,加入了智能模型的TWAP与VWAP算法框架能准确把握证券价格波动产生的局部优势以及时间片内的全局优势,在保证算法完成度的同时,显著提升算法整体的执行效果,改进后的智能TWAP与VWAP算法不仅明显优于传统TWAP与VWAP算法,而且能稳定地跑赢市场均价,该结论表明本文构建的加入了短期价格预测模型与铺埋单参数优化模型的算法框架能够帮助投资者降低交易成本,提高投资收益.
猜你喜欢
大电机技术(2022年1期)2022-03-16
中国海上油气(2021年2期)2021-06-09
智富时代(2018年9期)2018-10-19
智富时代(2018年9期)2018-10-19
数码世界(2017年5期)2017-12-29
价值工程(2016年32期)2016-12-20
无锡职业技术学院学报(2015年2期)2015-02-28
河南科技(2015年2期)2015-02-27
中国工程咨询(2015年2期)2015-02-14
电测与仪表(2014年15期)2014-04-04
