
基于股吧情感本体与传播的股市短线预测*
2020-11-02 12:13赵明清赵义军
经济数学 2020年3期
高 森,赵明清,赵义军
(山东科技大学 数学与系统科学学院,山东 青岛 266590)
1 引 言
影响股市走向的因素有很多,其中包括宏观经济形势、当前政策、企业策略、股民情感等[1],前三者均是对整个行业的长期影响且在短时间内少有较大变动,难以基于此对股市的走向进行预测.而在面对复杂且具有不确定性的股市投资决策问题时,股民情绪很容易受到自身以及外部的影响,包括公开新闻、小道消息、股市短线走势动荡、其他股民言论等,在短时间内变化较大,且在一定程度上也反映了前三者的变化影响.但是,其影响来源五花八门真假难辨,单一股民获取的信息有限,面对各类信息无法快速有效地做出正确判断,极易对股民的投资造成无法挽回的损失.
随着互联网+时代的到来,大数据概念深入人心,越来越多的互联网用户尝试通过大数据手段来挖掘数据背后的深层含义.据2019年中国互联网络信息中心(CNNIC)发布的第44次《中国互联网络发展状况统计报告》统计显示,截至2019年6月,我国互联网用户已有8.54亿人,普及率达61.2%,其中移动互联网用户有8.47亿[2].互联网用户的激增使各类社交媒体飞速发展,人们更乐于足不出户,在网络上发表自己的观点,交流彼此的心得.
股吧作为股民的专业社交平台,包括股票推荐、走势分析、个股研究等不同板块,虽然有专业人士的指导意见,但更多的是普通股民发表的观点看法.对于股民而言,专业性很强的股吧就是其获取、交流信息的重要“根据地”,股民在其中发帖表达自己的观点,同时也浏览别人的帖子接收他人想法,更新自己的观点,这就体现了其对股市的情感表达.当股民的情感表达经过“从众”心理和“跟风”心理的放大,会逐渐发展成总体趋于一致的群众情感表达,最终对股市走向产生影响.一个典型的案例就是发生在2016年1月4日的“千股熔断”事件,两次熔断后的提前休市冲击导致在接下来的几天时间里,恐惧惊慌的情绪在股民中蔓延,大量投资者从众跟风抛售股票,近2000股跌停,股市震荡持续数月后随着股民情绪稳定而趋于平缓.
由于股民基数大、情绪复杂多样且具有不确定性,收集股民情绪并进行有效量化就是分析研究股民情感与股市走势之间关系的首要问题.现有的情绪量化指标主要有直接情感指数和间接情感指数[3]:直接情感指数通常由调查问卷的形式收集情感计算得出,由于中国股民基数过于庞大且参与积极性不一,收集的情绪难以代表真实的情感;间接情感指数由专家选取间接指标来代替股民情感计算得出,包括封闭式基金折价率、成交量等,但由于选取指标的范围无法固定,间接情感指数也难以准确表达股民情感.
而基于文本情感分析的方法则直接以股吧文本作为数据来源,使用情感分析技术量化股民情感,从而有效避免直接情感指数和间接情感指数中出现的问题[4].在大数据技术的支持下,收集一段时期内所有股民的情感表达,进行文本情感分析,可以得到这段时期的股民情感信息,进而考察股吧文本中蕴含的股民情感对股市短线走势的影响变化.
2 研究现状
现有的情感分析技术,主要基于机器学习技术或统计语义方法[5].基于机器学习技术的情感分析技术需要大量语料库的支持来对训练样本进行反复训练,其效率较低;基于统计语义方法的情感分析技术需要一个相对完整且专业的词库支持,在前期构建方面要花费较长时间.
在国外,情感分析技术兴起于20世纪90年代.Riloff等(1997)提出了一种基于语料库的方法,可以用来构建语义词典的具体类别[6].Hatzivassiglouv等(1997)认为形容词表达的情感会受到前后修饰词的影响,并以此为依据对英文文本做出情感倾向判断[7].Turney等(2003)将点互信息法(Pointwise Mutual Information,PMI)引入到情感分析中,用于判断词义的褒贬性[8].Martineau等(2009)使用TF-IDF法来计算词汇权重,构建情感词典进行情感分析[9].Hassan等(2017)提出使用卷积神经网络(CNN)和长短时记忆模型(LSTM)进行情感分析,实验结果要优于传统的方法[10].
在国内,因为中文相较于英文的特殊性,例如分词困难、词意模糊程度高,情感分析技术还处在一个探索的阶段.近年来,朱嫣岚等(2006)提出了基于Hownet的语义倾向方法,通过计算词汇与Hownet基准词之间的相似度来对词汇进行相应赋值,进而判别文本的情感极性[11].李钝等(2008)则是在Hownet词库的基础上,再次建立种子词库,将词汇与种子词汇进行相似度计算来确定词汇的情感类别[12].柳位平等(2009)也是以Hownet为基础建立中文情感词典,使用TF-IDF法来计算词汇权重并进行赋值,实验结果显示新词典的准确性要优于Hownet基础词典[13].陈晓东(2012)使用点互信息法获得新情感词来扩充原始词库,同时考虑到文本中感叹号、特殊表情、否定词以及副词的情感表达,通过加权计算获得文本的情感倾向[14].徐小阳等(2018)利用文本挖掘技术处理金融文本舆情信息,进而考察投资者情绪对投资决策的影响[15].
目前在情感分析技术上国内外学者均取得了一定成果,一些学者也将此技术应用于股票的预测方面.Antweiler等(2004)研究了Yahoo!上发布的150万条消息的影响,发现社交媒体上的股票消息有助于预测市场波动[16].Schumaker等(2009)更新了专业名词词库,使用支持向量机(SVM)分析估计一篇新闻发布20分钟后的离散股票价格,发现使用专业名词词库比使用原始词库的预测效果要好[17].王超等(2009)将金融信息作为外部变量加入时间序列模型中进行预测,发现股票的价格波动与金融信息有密切关系[18].宋泽芳等(2012)通过构建情绪变量分析情绪与股票价格之间的关系,发现我国A股市场上规模大、波动率高、市净率高的股票更易受股民情绪所影响[19].吴玉霞等(2016)通过建立ARIMA模型对"华泰证券"250期的股票收盘价进行了短期股市预测,效果良好[20].赵明清等(2019)引入了词汇频数调整函数,综合考虑百度指数、微博情感与微博影响力,用信息增益确定微博权重建立股市加权预测SVM模型,结果表明该模型可以明显提高预测的准确率[21].
总结目前相关研究可知,情感的表达会影响投资决策的产生,因此使用情感分析技术预测股市走向是可行的.现有的基于文本情感分析方法对投资者情绪的研究思路主要是收集带有投资者感情色彩的文本信息,使用统计语义方法或机器学习技术加以整理、归纳和分析,识别文本中蕴含的情感信息,将主观性的文本信息量化,利用文本倾向性分析对文本情感进行正负判定,然后分别统计正负情感的数量利用差值、比值或对数化来计算极性情感指数,进而考察投资者情绪对股市的影响.但是由于中文表达的复杂性,基于中文文本情感对投资者情绪的研究还存在以下的局限:1)情感分析中用到的情感词典时效性差、针对性不强,许多新兴情感词汇和针对股市的专有词汇未被收入;2)语义表达因素考虑较少,现有文献一般仅考虑否定词与程度词对情感表达的影响,而较少考虑符号语言的影响;3)仅对情感进行正向或负向的判定而忽略了强度判定;4)现有研究大都集中在情感本体的计算上而忽略了来源的质量问题,情绪经过传播与放大很容易影响大多数人的情感倾向,缺失此部分的计算会加大信息的损失.因此,本文在已有研究的基础上,更新情感词典并考虑前置词与符号语言的影响构建情感得分,考虑情感强度问题,将情感进行量化赋值代替对情感的正负极性判断,同时考虑情感来源的质量与传播问题并进行赋分处理,构建综合情感指数用以评价情感波动,进一步建立股市预测模型并与已有预测模型进行对比分析.
3 情感词典构建
情感的识别需要使用专业的情感词典,常用的中文情感词典包括:知网(Hownet)情感词典、大连理工情感词汇本体库、台湾大学NTUSD词库等.以上词库均包括了大部分中文常见词汇,但词库对金融股票专业词汇的收入仍有不足,因此本文在这三者的基础上,使用情感倾向点互信息算法(Semantic Orientation Pointwise Mutual Information,SO-PMI)更新金融股票专业词汇与股票市场情感表达词汇,提高专业词汇识别效果.
情感倾向点互信息算法的思想是寻找文本中的词汇并与基准的倾向褒贬词组进行对比,统计同时出现的概率,如果概率越大,也就认为两者相关度就越大,再根据得到的点互信息差值即可判断其情感倾向[8].首先计算词汇间的点互信息值:
(1)
其中,N为文本总数,wordn是文档中的词汇,df(wordn)是包含wordn的文本数,df(wordn&wordm)是同时包含wordn与wordm的文本数.接着使用基准倾向褒贬词组与文本中的词汇进行对比并做差处理:
(2)
其中,word是需情感定位的词汇,Pwords与Nwords是基准的倾向褒贬词组.
(3)
通过SO-PMI算法,将得到情感倾向定义的词汇加入情感词典.而股民在股吧中的情感表达按中文语言逻辑表达可分为4类:
1)股民对经济形势、行情环境、政策分析、股票涨跌所发表的专业词汇.本文结合搜狗金融专业词库与人工筛选识别,新增7002个专业词汇.目的是用于在文本预处理阶段,使之能更为精准的定位词汇,提高识别效果.
2)股民对股市的主观情感词汇,表达股民对股市的肯定、否定或怀疑.本文在专业论坛中爬取股民在线评论数据,进行分词处理,使用SO-PMI算法在语料库中筛选得到高频情感词汇,结合人工识别的方法,新增主观褒义情感词汇43个,主观贬义情感词汇54个.
3)股民在进行情感表达时语句前后所用到的程度词汇,用来夸大削弱或翻转情感表达,使之更符合心中所想.此类词汇知网(Hownet)情感词典已收入较完整,因此不做更新修改.
4)股民在发帖中用到的符号语言词汇,用于辅助情感的表达,本文结合搜狗原有颜文字词库与emoji词库并通过TF-IDF法在语料库中找到股民常用特殊字符表达,新增184条特殊符号语言词汇.目的在于适应网络用语表达,更为准确地识别情感.
部分新增词汇如表1所示.

表1 部分新增词汇
4 模型构建与预测
基于股吧文本情感分析的股市短线预测模型构建步骤如图1所示,包括3个部分:1)收集股民在股吧中发表的文本数据,并进行文本预处理与文本表示,通过情感分析得到以小时为变化单位的情感指数;2)爬取上证综指分时数据,经过数据整理后建立ARMA-GARCH模型;3)将情感指数作为外生变量加入ARMA-GARCH模型中进行预测,分析情感因素与股市走向之间的关系,并与其他经典模型进行比较.
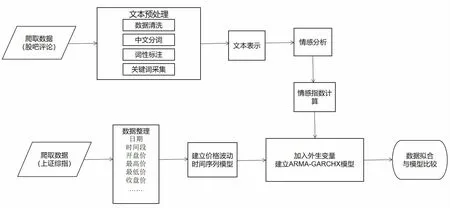
图1 基于股吧文本情感分析的股市短线预测模型构建步骤
4.1 文本预处理
本文爬取东方财富网旗下股票社区上证指数吧(http://guba.eastmoney.com/list,zssh000001.html)2018年7月27日到2019年7月23日共计361天121322条帖子的文本数据,包括发帖时间、阅读数、评论数、发帖平台、发帖人吧龄、发帖人等级、帖子标题以及帖子正文内容等.东方财富网作为中国访问量最大的财经证券门户网站之一,日均页面浏览量超过1亿次,在股民社区影响力巨大,因此选择此网站作为爬取数据的来源具有一定的代表性.
因本文文本数据来源于互联网社区,相对于书面用语来说表达不规范程度大,在预处理阶段需要对其进行删减整理,去除无用信息使之更易被机器识别分词,包括以下步骤:
1)进行数据清洗,去除文本中的脏数据,包括乱码、链接、不常用符号等;
2)识别文本中的特殊词句,包括广告、停用词句、无意义语句等,进行删减;
3)根据专用词典进行分词处理;
4)将词汇数据进行词性标注、关键词采集.
上述步骤涉及中文分词、词性标注、关键词采集等技术.目前国内已有较为成熟的技术,如中国科学院计算技术研究的汉语词法分析系统ICTCLAS、哈尔滨工业大学社会计算与信息检索研究中心开发的“语言技术平台LTP”以及结巴(jieba)中文分词工具.其中,结巴中文分词工具的优势在于其是完全开源的,词库可以由使用者进行二次更新使用.本文即在结巴中文分词工具自带的分词包中加入了股市专业词汇,使其更适应于专业分词.部分处理数据如表2所示.

表2 部分处理数据
4.2 文本表示与特征提取
可以看到如表2所示,语料库中发帖时间、阅读数、评论数等数据是单独列出且词性确定,机器可直接识别,只有帖子标题以及帖子正文内容两项因中文语言的复杂性需要进行分词处理,这两部分数据经分词处理后用向量空间模型(Vector Space Model,VSM)[1]来表示.
将文本集中的第i条文本按分词结果分为多个特征项,不同的特征项表示为tk(k=1,2,…,n),那么此文本即可表示为序列Ti=T(t1,t2,…,tk,…,tn),再使用布尔权重赋值匹配权值wk(k=1,2,…,n),将该文本序列表示为向量di=d(t1,w1,t2,w2,…,tk,wk,…,tn,wn)(i=1,2,…,m),简记为di=(w1,w2,…,wk,…,wn)(i=1,2,…,m),其中wk为特征项tk的权重,最后将每条文本依次按以上方法表示,组成矩阵D,即为此文本集的向量空间模型.经此完成由字符型数据到数字数据的结构化处理,将文本数据转化为机器可以识别的有序数据.
但向量空间模型中文本集特征项的维度往往过高而不便于直接处理,因此需要进一步降维[9]:通过TF-IDF法筛选出低频词汇并配合人工识别去除低频无意义词汇以达到降维的目的,其中TF表示词频,计算公式为
(4)
其中ni,j表示第i个特征项在第j条文本中出现的次数,Nj表示第j条文本的词条数;IDF表示逆向文件频率,由文本集中总文件数目与包含该特征项的文本数目的比值再取对数表示,计算公式为
(5)
其中N为文本集中总文件数目,Ni表示出现第i特征词的文本数.然后,计算TF与IDF的乘积
TFIDFi,j=TFi,j×IDFi,j.
(6)
综上,特征项如在特定文本中有低词频且在整个文本集中有高词频,即会有较小的TF-IDF值,也就代表这个特征项对情感区分没有帮助,即可以筛选剔除.据此设定特定阈值后,TF-IDF法即可以过滤掉低于阈值的常见特征项,从而保留重要的特征项,向量空间模型特征项的维度也将大大降低,再结合人工识别,约41.67%的数据被筛除.
4.3 情感指数计算
文本数据经过向量空间模型结构化处理,可以被机器识别从而进行情感得分计算,首先计算股民情感本体得分,步骤如下:
1)定位di中的基本情感词汇,包括评价词与主观情感词,再以每个标志词为基准向前定位临近程度词与否定词.
2)使用主观情感词汇词典判断情感类别并对基本情感词汇进行赋分,正向情感为1,负向情感为-1.
3)使用知网程度词典对程度词、否定词进行赋分,对基本情感词得分进行放缩或转换,规则如表3所示.

表3 知网程度词典
4)对di中的每个基本情感词的得分作求和运算.
5)判断di是否为感叹句,是否存在特殊符号,如果存在则在第4步得分基础上进行增减.
6)对D中所有di得分进行累加,即得到股民通过文本数据表达出的情感本体的量化得分Si.
对股吧贴子数据来说,更多的阅读评论量意味着有更多的人参与传播,发帖人吧龄和星级越大意味着其发表的言论在相对意义上来说更为重要,普通股民也更为愿意阅读此类贴主的文字.因此,本文选以上4个指标来构建情感来源质量得分Ei,公式如下:
Ei=ln(Nbrowse+1)×ln(Ncomment+1)×ln(Nage+1)×ln(Nstar+1).
(7)
其中,Nbrowse,Ncomment和Nage,Nstar分别为股吧帖子的阅读数、评论数、发帖人的吧龄、星级.可以看到,情感表达的越激烈那么其对应情感本体得分Si绝对值就会越大,而更高的情感来源得分Ei也就意味着这种表达的情感受到更多人的认可,也代表了更多人的共同感受,将两者进行汇总得到综合情感指数:
Xt=Si×Ei.
(8)
汇总一段时期内所有的综合情感指数并做差处理,即得到该时段的综合情感指数变动:
(9)
其中p即为该时段向量空间模型D总数,t为给定的时间段,计算结果如表4所示.
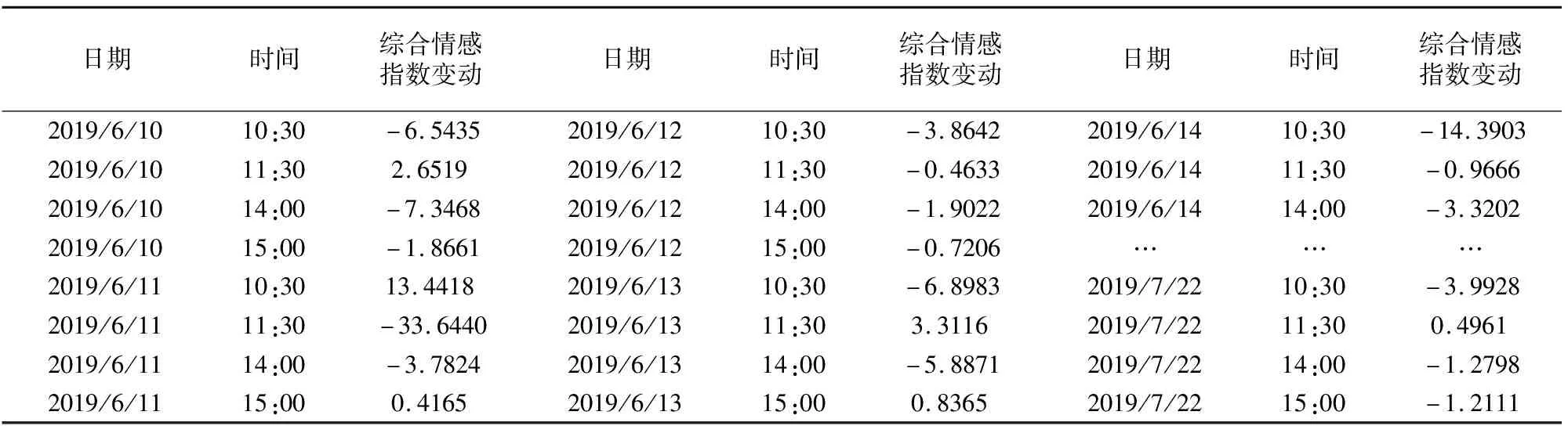
表4 股吧综合情感指数变动
5 预测分析
本文爬取了2019年6月10日到2019年7月22日的上证综指分时数据,包括日期、时间段、开盘价、最高价、最低价、收盘价、成交额、成交量、涨跌额、涨跌幅等共124组数据,并以当期收盘价作为股票价格计算收益率,如表5所示.
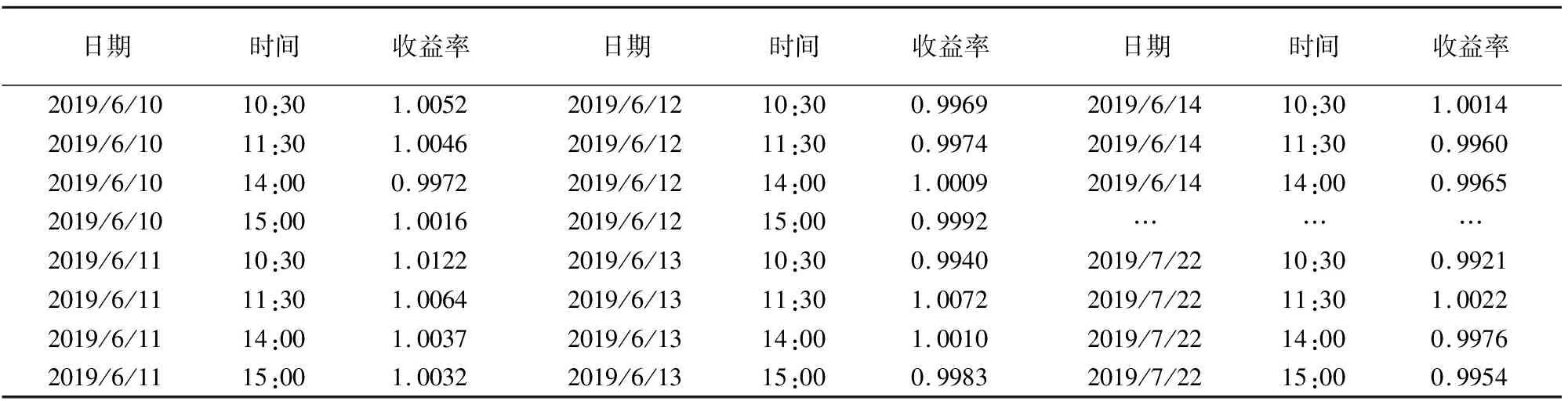
表5 上证指数数据变化
按照4.3节计算方法,选取2019年6月10日到2019年7月22日的上证综指股吧贴文进行情感指数计算得到综合情感指数Xt,由于股票价格变动大都有自相关、异方差、尖峰厚尾的特性[22],因此本文将综合情感指数Xt作为外生变量加入ARMA-GARCH模型进行股票走势的预测:
(10)
其中,yt表示小时收益率(已验证其平稳性和ARCH效应),μt为独立误差项,Xt为外生变量.
通过建立股票价格变动与综合情感指数变动的柱状图(见图2)可以看出,股票价格变动与情感变化方向大体一致,仅因数量级差异而变化幅度有所不同,说明通过情感的变化可以看出股票价格的变化.
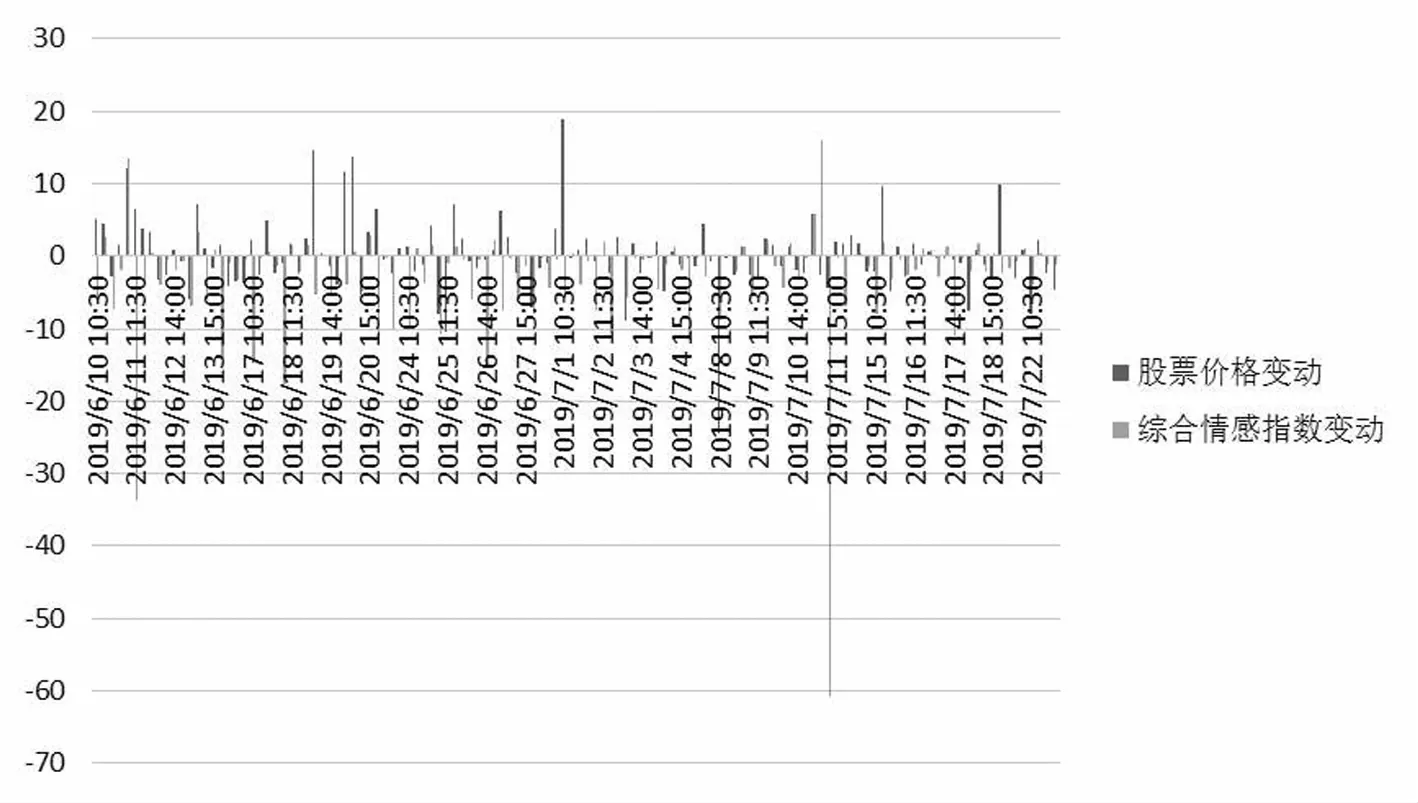
图2 股票价格变动与综合情感指数变动柱状图
作为对比,建立使用传统判断情感极性的方法计算情感得分作为外生变量的ARMA-GARCHX模型,分别计算以上模型的对数似然函数值L、AIC值、BIC值,如表6所示.

表6 模型比较
根据经验比较拥有较大似然函数值L、较小AIC值、BIC值的综合情感ARMA-GARCHX模型更优.然后,给出使用两种情感分析方法得出的后4期预测结果并与真实值比较,如表7所示.

表7 预测结果
由此可见,使用本文提出的改进的情感分析方法比使用传统的情感极性分析方法更能对股市的短线预测做出准确判断,且预测效果有明显提升.
6 结 语
从情感分析角度出发,通过构建面向股市的情感词典,综合考虑股民情感本体与情感传播问题建立加权股吧文本情感倾向得分模型,分析预测股民情感与股市短线走势之间的关系,研究结果表明:新词典具有更强的适应性,加入综合情感得分后建立的预测模型具有更高精度.本文的创新点在于:1)使用经更新过的专业词库进行情感分析,更具针对性;2)考虑情感的强度问题,比传统的情感分析方法更具准确性;3)同时考虑情感本体和情感来源质量问题,避免情感表达的损失.在今后的工作中可进一步考虑提高词汇的识别精度,扩充专业词库,考虑更多的传播影响因素,最终建立一个比较完善的中文语义股市情感分析系统.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
动漫界·幼教365(大班)(2020年7期)2020-06-26
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电脑爱好者(2017年5期)2017-05-04
金山(2016年3期)2016-11-26
英语知识(2016年1期)2016-11-11
小说月刊(2016年4期)2016-03-23
职工法律天地·上半月(2014年7期)2014-11-11
外语学刊(2011年3期)2011-01-22
