
基于改进3D 卷积神经网络的代价聚合算法∗
2020-11-02 09:00宋天中于修成
计算机与数字工程 2020年9期
李 航 宋 燕 宋天中 于修成
(上海理工大学光电信息与计算机工程学院 上海 200093)
1 引言
立体视觉技术广泛应用于三维场景重建、目标跟踪、机器人导航以及智能驾驶等领域。自20 世纪80 年代Marr[1]首次提出了一种视觉计算理论并应用在双目匹配上,使两张有视差的平面图产生具有深度的立体图形,从而奠定了双目立体视觉发展的理论基础。Szeliski[2]等将立体视觉分为一下四个步骤:图像获取、立体矫正、立体匹配和三维重建。立体匹配为其中最关键也是最困难的一个环节,逐渐成为计算机视觉中的研究热点和焦点。立体匹配的核心是从两个视点观察同一景物以获取立体像对,匹配出相应像点,从而计算出视差并获得三维信息。然而,由于遮挡、光照等多种因素的影响,如何从立体图像信息中得到稠密精准的深度信息成为困扰国内外研究者的一个难题。
由于匹配的不确定性,立体匹配问题始终没有统一的解决方式,对此许多研究人员作了大量研究,Scharstein[3]等深入研究了一些典型的立体匹配算法,将立体匹配划分为匹配代价计算、代价聚合、视差计算和视差精化四个步骤。传统立体匹配算法主要可划分为局部方法和全局方法两类:局部方法利用窗口内邻域信息来进行单像素匹配,具有速度快,易于实现的优点,但是支持窗口大小的选取和匹配代价的计算是个难题;全局方法通过能量函数最小化来获得匹配结果,精度较高但效率较低,不能满足实时性应用。
近年来,我们见证了深度学习在计算机视觉中的“革命”,卷积神经网络(CNN)在目标检测、图像分割等任务中得到了良好的应用。最近,CNNs 已被应用于立体匹配中的匹配代价计算中。Zbontar和LeCun[4]提出了匹配代价计算网络(MC-CNN),用于计算图像块之间的准确关系,通过计算块与块之间的相似度确定视差。网络主体框架为孪生网络结构(Siamese Network),左、右输入分别为来自左图和右图的尺寸相等的图像块。他们根据不同的应用需求设计了快速结构(fast MC-CNN)和准确结构(acrt MC-CNN)。Z.Chen[5]等借鉴了文献[18]中的中心环绕双流网络框架的思想,提取两个网络分流的特征进行相似性度量,两个分流输入分别为图像中心信息和图像下采样信息。W.Luo[6]等为减少计算冗余,避免正负样本不均衡现象,以点乘操作替代全连接层,并设置左右输入图像块尺寸不一致,使网络可以一次性提取所有视差对应图像块的特征。Jiaren Chang[7]等提出了一种新的金字塔立体匹配网络(PSMNET),将像素级特征扩展到具有不同接收域尺度的区域级特征,利用得到的全局和局部特征组合形成用于可靠视差估计的代价空间。
上述相关文献均是将CNN 用于匹配代价计算步骤,尽管CNN 在精度和速度方面都比传统方法有显著的提高,但是在诸如遮挡区域、重复图案、无纹理区域和反射表面等固有不适定区域中仍然难以找到精确的对应点。仅仅应用不同视点之间的强度一致性约束通常不足以在这种不适定区域中进行精确的对应估计,并且在无纹理区域中是无用的。因此,必须将全局信息纳入立体匹配的计算中。Jiaren Chang[7]设计了一种网络结构(stacked hourglass 3D CNN),将3D CNN 用于视差精化,以自底向上的方式重复处理代价空间,进一步提高全局上下文信息的利用率。
受到文献[8]的启发,针对于代价聚合,我们提出了一种基于改进3D卷积神经网络的立体匹配视差精化算法。本文的主要贡献有以下三点:
1)采用3D卷积对匹配代价进行聚合;
2)将3D 残差网络和3D 密集连接网络模型用于代价聚合;
3)通过实验验证了3D 卷积神经网络对代价聚合的有效性,并且基于3D 卷积神经网络的视差精化算法相比传统方法准确率更高、运行速度更快。
2 代价聚合
2.1 代价空间获取
本文采用带有反卷积的孪生网络(Siamese Network)作为获取代价空间的基本网络[19],其结构如图1所示。
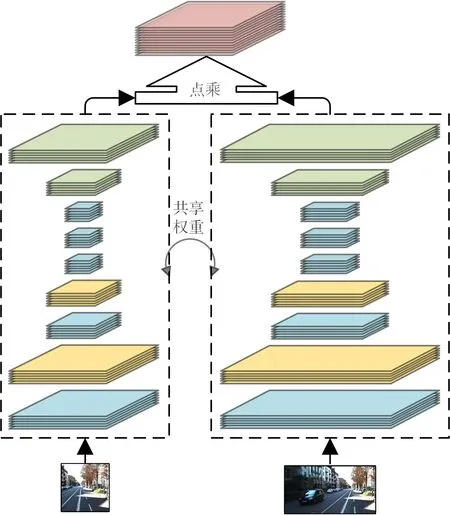
图1 匹配代价计算网络结构框架
该网络框架前半部分为一个共享参数的特征提取模块,保证左图与右图提取相同特征,特征提取模块由若干层卷积、池化、反卷积组成。左图与右图的输入尺寸不相同,以减少冗余计算,提高匹配准确率。
2.2 3D卷积神经网络
代价空间是具有一定深度的代价图的集合,为三维的特征图,3DCNN 可以沿着视差维度和空间维度聚合特征信息。
深度残差网络(Deep Residual Network)是何恺明等在2016 年提出的一种极深的卷积神经网络模型,可以有效避免传统卷积神经网络模型的梯度消失或爆炸以及模型退化问题[9]。深度残差网络中的残差结构如图2(b)所示,深度残差网络由一系列该残差结构堆砌而成。假设最优解映射表示为H(X)=X,传统卷积神经网络是直接拟合H(X)=X,而残差网络则是去拟合残差映射:

在残差网络训练过程中,只要使得F(X)=0,即完成了一个恒等映射H(X)=X。显然,用网络去拟合一个确定的函数F(X)=0相较于逼近某个不确定的函数H(X)更加容易[10]。因此,深度残差网络更容易优化,在增加网络深度时,深度残差网络性能也能明显提升。
密集连接网络(Densely connected convolution network)是由Huang 等在2017 年提出的一种新型的卷积神经网络结构[11]。密集连接网络的核心思想是每一层卷积都接受其之前所有卷积层的输出作为输入。密集连接网络中的第l层的输入可以表示为
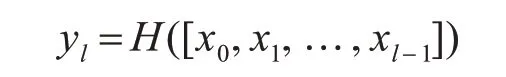
其中[ ]x0,x1,…,xl-1表示0,1,…,l-1 层的输出。H表示串联操作,将0,1,…,l-1 层的输出串联到一起后作为第l层的输入。密集连接结构如图2(c)所示。由于密集连接网络所有层都是两两相连的,卷积特征得到了大量的复用,网络的特征提取能力得到极大提升,提高了卷积神经网络的参数利用率[11]。除此之外,Huang 等还通过减少密集连接网络每层卷积的卷积核数目,加快网络的计算速度。
为了沿视差维度和空间维度聚合特征信息,我们提出了三种用于计算视差的3D卷积神经网络模型:普通3D 卷积神经网络、3D 残差网络以及3D 密集连接网络,总体模型如图2 所示。普通3D 卷积神经网络包含5 层3×3×3 的3D 卷积用于聚合特征,然后通过双线性插值将特征图尺寸恢复到输入尺寸大小,最后我们使用视差回归计算最终的输出视差图。3D 残差网络由5 个3D 残差结构组成,3D密集连接网络由5 个3D 密集连接残差结构组成,然后将它们用于聚合特征,后续步骤与普通3D 卷积神经网络保持一致。
2.3 视差回归
本文使用文献[12]提出的视差回归方法来估计视差图。通过计算得到的匹配代价值和softmax算法计算每个视差d对应的概率值。视差预测值d'通过下式计算获得:
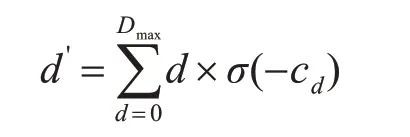
其中Dmax表示最大视差,在本文实验中取为128;cd表示匹配代价模块计算得到的代价值;σ表示softmax 函数。根据文献[12]所述,该视差回归方法优于一般的基于分类的立体匹配方法。

图2 基于3D卷积神经网络的视差精化网络结构
2.4 损失函数
根据视差回归的结果,我们参考文献[7]采用Smooth L1loss作为网络的损失函数。 由于Smooth L1损失函数具有良好的鲁棒性以及一定的抗噪声能力,因此被广泛用于边界框回归任务中[13]。Smooth L1损失函数定义如下:

其中N表示标注的像素点总数,d表示该像素点的真实视差值,d'表示预测得到的视差值。
3 实验及结果分析
3.1 实验环境
本文的实验环境如下,CPU:Intel Xeon E5-1630 v4;内存:32G DDR4;GPU:Nvidia Geforce GTX1080 Ti;操作系统:Ubuntu16.04 LTS;利用Py⁃thon 语言对所提算法进行编程实现,实验框架为Keras(TensorFlow backend)开源框架。本文的测试实验皆在此环境下完成。
3.2 实验数据集
本文的实验数据集采用了KITTI2012 和KITTI 2015立体匹配数据集。
KITTI 2012[14]是一个以真实行驶中的车辆视角获取的街道视图。它由使用激光雷达获取的具有视差标注的194 对立体图像组成,所有图像的尺寸为376*1240。在本文实验中,我们将整个数据集分为训练集(160 个图像对)和验证集(34 个图像对)。
KITTI 2015[15]也是一个以真实行驶中的车辆视角获取的街道视图。它包含200 对由激光雷达获得的具有视差标注的立体图像对和另外200 对没有标注的测试图像,所有图像的尺寸为376*1240。在本文实验中,我们进一步将整个训练数据中80%的样本作为训练集,20%样本作为验证集,以此来进行实验。
数据处理方面,首先通过Siamese network 计算图像代价空间,然后采用与文献[7]中对KITTI 数据集一致的处理方式:在训练阶段,从每个代价空间块中随机裁剪出大小为256*512 的子代价空间块对作为视差精化网络的输入。在测试阶段,测试样本均以原始尺寸输入到视差精化网络中。
3.3 实验结果
本文使用Adam[16]优化方法对网络进行优化,初始学习率设为0.001,在迭代12000 次后将学习率降为0.0001,之后再迭代训练12000 次得到最终模型。在训练过程中,网络输入样本的批大小(batch size)固定为4。

图3 本文算法进行视差精化的视差结果
由于本文算法是基于文献[7]的改进,将本文算法与其的误差指标结果比较列在表1,其中传统方法为KITTI 数据集中准确率排名最高的SPS-St,MC-CNN 系列[4]是指以MC-CNN 获取的匹配代价进行传统方法的代价聚合和视差精化后最优结果。值得一提的是,传统方法[17]每对图像的运行速度为200s,本文算法运行时间只需0.22s。为保证文献[7]的视差精化的输入与本文方法相同,我们使用上述代价空间获取方法得到的代价空间作为文献[7]输入。
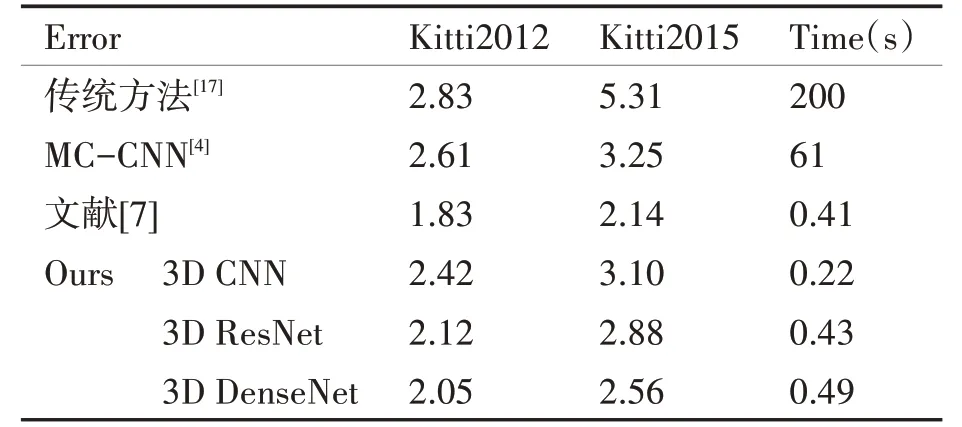
表1 不同方法的匹配错误率对比
经过视差精化的视差图如图3 所示。从上至下分别是原始输入左图以及普通3DCNN、3D ResNet、3D DenseNet 对应的预测视差图。从预测的视差图可以看出,在真实道路场景下,本文算法均能得到光滑稠密的视差图,特别是在目标物边缘区域,较为明显地保留了原目标的边缘信息,匹配效果较好。
4 结语
本文提出了一种基于改进3D 卷积神经网络的立体匹配方法,以孪生网络为基础提取图像对的代价空间,然后用3D 卷积神经网络对代价空间进行聚合,并在此基础上将3D 残差网络3D 密集连接网络引入代价聚合的计算中。最后使用视差回归对经过3D卷积处理得到的特征图估计出视差图。
实验结果表明,在KITTI2012 和KITTI2015 数据集上本文算法的平均匹配率优于当前主流的局部匹配算法和全局匹配算法,并且本文算法在GPU平台的运行速度远远优于传统方法,因此本文算法具有良好的应用前景。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
计算机应用与软件(2022年1期)2022-01-28
小型微型计算机系统(2022年1期)2022-01-21
海峡姐妹(2017年12期)2018-01-31
语文世界(初中版)(2017年5期)2017-06-22
作文与考试·初中版(2017年12期)2017-04-19
科技视界(2016年6期)2016-07-12
作文大王·中高年级(2008年12期)2008-12-19
